論文鏈接:?Language Models are Few-Shot Learners
點評: GPT3把參數規模擴大到1750億,且在少樣本場景下性能優異。對于所有任務,GPT-3均未進行任何梯度更新或微調,僅通過純文本交互形式接收任務描述和少量示例。然而,我們也發現部分數據集上GPT-3的少樣本學習能力仍有局限,以及一些因依賴大規模網絡語料訓練引發的潛在方法學問題。
?GPT系列:?
| GPT1 | 預訓練+微調, 創新點在于Task-specific input transformations。 | ||
| GPT2 | 15億參數 | 預訓練+Prompt+Predict, 創新點在于Zero-shot | Zero-shot新穎度拉滿,但模型性能拉胯 |
| GPT3 | 1750億參數 | 預訓練+Prompt+Predict, 創新點在于in-context learning | 開創性提出in-context learning概念,是Prompting祖師爺(ICL)是Prompting范式發展的第一階段。 |
GPT模型指出,如果用Transformer的解碼器和大量的無標簽樣本去預訓練一個語言模型,然后在子任務上提供少量的標注樣本做微調,就可以很大的提高模型的性能。GPT2則是更往前走了一步,說在子任務上不去提供任何相關的訓練樣本,而是直接用足夠大的預訓練模型去理解自然語言表達的要求,并基于此做預測。但是,GPT2的性能太差,有效性低。
GPT3其實就是來解決有效性低的問題。Zero-shot的概念很誘人,但是別說人工智能了,哪怕是我們人,去學習一個任務也是需要樣本的,只不過人看兩三個例子就可以學會一件事了,而機器卻往往需要大量的標注樣本去fine-tune。那有沒有可能:給預訓練好的語言模型一點樣本。用這有限的樣本,語言模型就可以迅速學會下游的任務?
Note: GPT3中的few-shot learning,只是在預測是時候給幾個例子,并不微調網絡。GPT-2用zero-shot去講了multitask Learning的故事,GPT-3使用meta-learning和in-context learning去講故事。
網絡結構 Model Construction

GPT-3沿用了GPT-2的結構,但是在網絡容量上做了很大的提升,并且使用了一個Sparse Transformer的架構,具體如下:
1.GPT-3采用了96層的多頭transformer,頭的個數為 96;
2.詞向量的長度是12,888;
3.上下文劃窗的窗口大小提升至2,048個token;
4.使用了alternating dense和locally banded sparse attention
Sparse Transformer:
Sparse Transformer是一種旨在處理高維、稀疏和長序列數據的Transformer拓展版,相比于傳統的Transformer架構,Sparse Transformer通過在自注意力機制中引入稀疏性,減少了網絡中計算的數量,從而可以處理更長的序列數據。具體的:在處理高維、稀疏數據時,Sparse Transformer可以避免對所有輸入的位置進行計算,只計算與當前位置相關的位置,從而提高了計算效率。
GPT3的batch size達到320萬,為什么用這么大的?
首先,大模型相比于小模型更不容易過擬合,所以更用大的、噪音更少的Batch也不會帶來太多負面影響;其次,現在訓練一個大模型會用到多臺機器做分布式計算,機器與機器之間數據并行。最后,雖然批大小增加會導致梯度計算的時間復雜度增加,但是較大的batch size通常可以提高模型的訓練效率和性能。
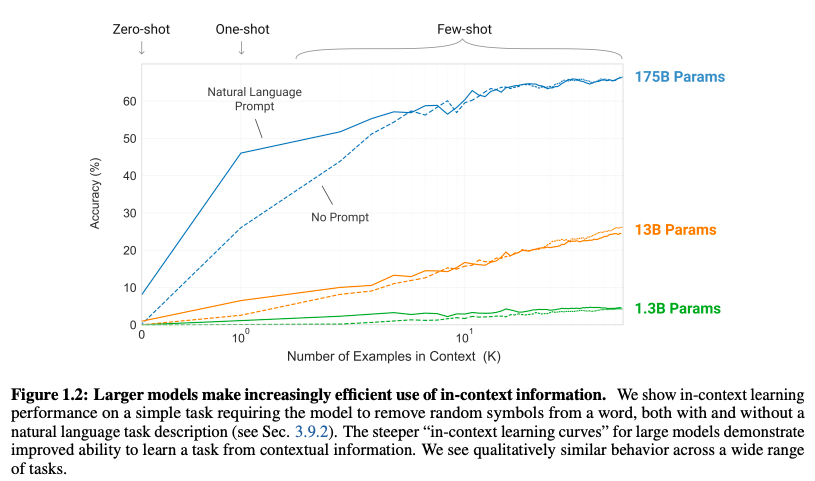
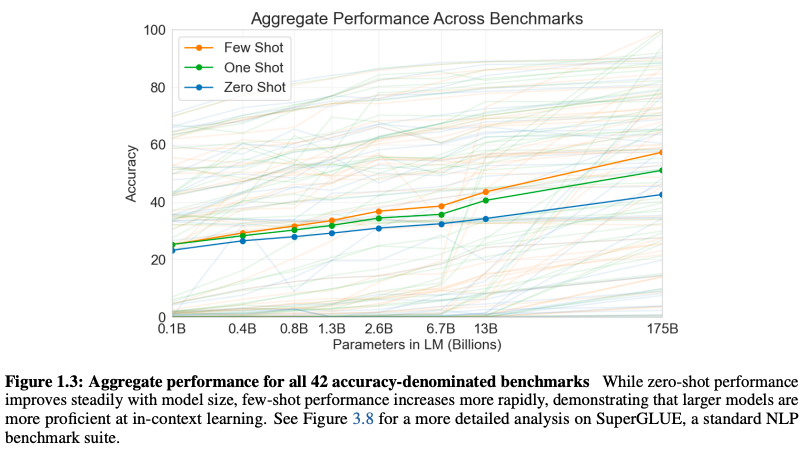
圖1.2:更大的模型擁有更強的利用情境信息能力
圖1.3: 聚合了模型在42個基準數據集上的性能
- 本文的實現與GPT-2的方法相似,預訓練過程的不同只在于采用了參數更多的模型、更豐富的數據集和更長的訓練的過程。本文聚焦于系統分析同一下游任務不同設置情況下,模型情境學習能力的差異。下游任務的設置有以下四類:
- Fine-Tunning(FT):FT利用成千上萬的下游任務標注數據來更新預訓練模型中的權重以獲得強大的性能。但是,該方法不僅導致每個新的下游任務都需要大量的標注語料,還導致模型在樣本外預測的能力很弱。雖然GPT-3從理論上支持FT,但本文沒這么做。
- Few-Shot(FS):模型在推理階段可以得到少量的下游任務示例作為限制條件,但是不允許更新預訓練模型中的權重。FS過程的示例可以看本筆記圖2.1點整理的案例。FS的主要優點是并不需要大量的下游任務數據,同時也防止了模型在fine-tune階段的過擬合。FS的主要缺點是不僅與fine-tune的SOTA模型性能差距較大且仍需要少量的下游任務數據。
- One-Shot(1S):模型在推理階段僅得到1個下游任務示例。把1S獨立于Few-Shot和Zero-Shot討論是因為這種方式與人類溝通的方式最相似。
- Zero-Shot(0S):模型在推理階段僅得到一段以自然語言描述的下游任務說明。0S的優點是提供了最大程度的方便性、盡可能大的魯棒性并盡可能避免了偽相關性。0S的方式是非常具有挑戰的,即使是人類有時候也難以僅依賴任務描述而沒有示例的情況下理解一個任務。但毫無疑問,0S設置下的性能是最與人類的水平具有可比性的。
評估:?
-
單項選擇任務:給定K個任務示例和待測樣本的上下文信息,計算分別選取每個候選詞的整個補全樣本(K個任務示例+待測樣本上下文+待測樣本候選詞)的似然,選擇能產生最大樣本似然的候選詞作為預測。
-
二分類任務:將候選詞從0和1變為False和True等更具有語義性的文本,然后使用上述單項選擇任務的方式計算不同候選項補全的樣本似然。
-
無候選詞任務:使用和GPT-2完全一樣參數設置的beam search方式,選擇F1相似度,BLEU和精確匹配等指標作為評價標準。
論文閱讀 A Survey of Pre-trained Language Models for Processing Scientific Text
????????????????Language Models are Few-Shot Learners



:備份與恢復實戰——從邏輯到物理,增量備份全解析)


: use of undeclared identifier ‘pthread_getname_np‘)
)


)








