YOLOv3:深度學習中的目標檢測利器
引言
在計算機視覺領域,目標檢測是一項核心任務,它涉及到識別圖像或視頻中的物體,并確定它們的位置。隨著深度學習技術的快速發展,目標檢測算法也在不斷進步。YOLO(You Only Look Once)系列算法以其速度快、易于實現而受到廣泛關注。本文將深入探討YOLOv3,這是YOLO系列中的一個重要版本,它在準確性和速度之間取得了很好的平衡。
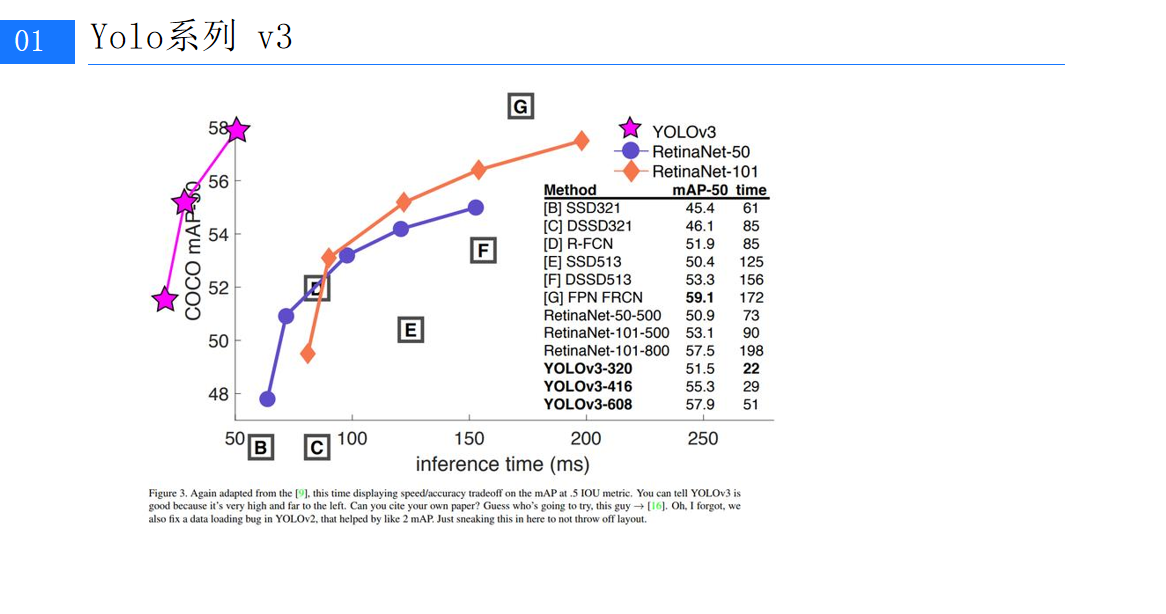
YOLOv3的特點
YOLOv3在前兩個版本的基礎上進行了多項改進,主要包括:
- 多尺度檢測:YOLOv3能夠同時在三個不同的尺度上檢測物體,這使得它能夠同時檢測到大和小的物體。
- 更深的網絡結構:YOLOv3使用了更深的網絡結構,這有助于提高檢測的準確性。
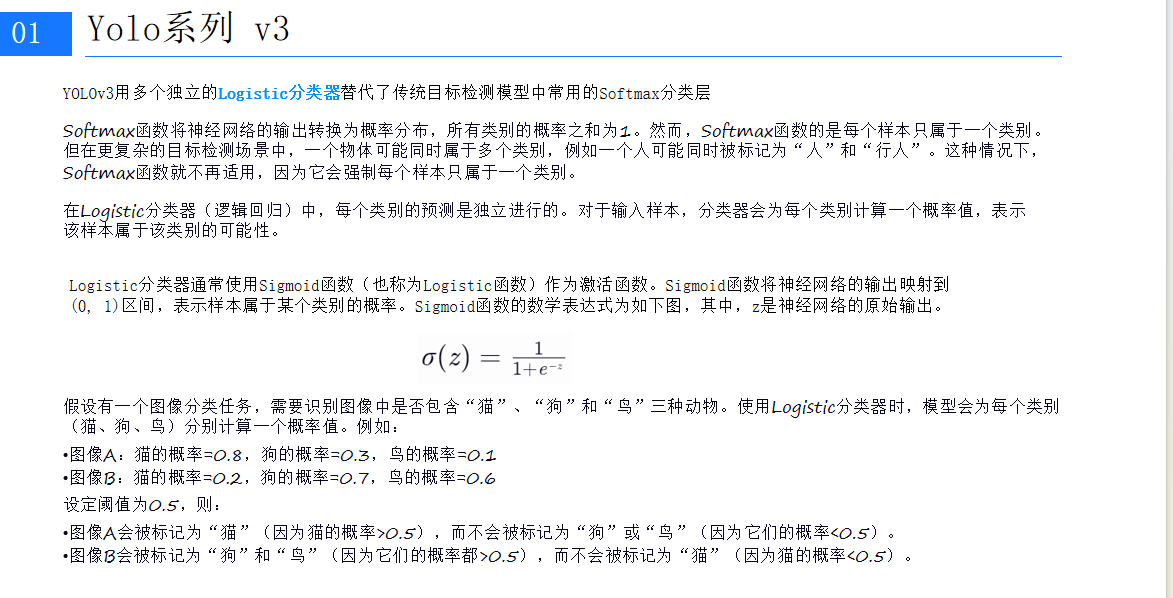
- 更好的類別預測:YOLOv3采用了多個獨立的Logistic分類器來預測類別,這比傳統的Softmax層更靈活,允許一個物體屬于多個類別。
YOLOv3的網絡架構
YOLOv3的網絡架構由多個卷積層和殘差塊組成,這些殘差塊有助于緩解深層網絡中的梯度消失問題。網絡的輸入是一張圖像,輸出是多個邊界框和對應的類別概率。
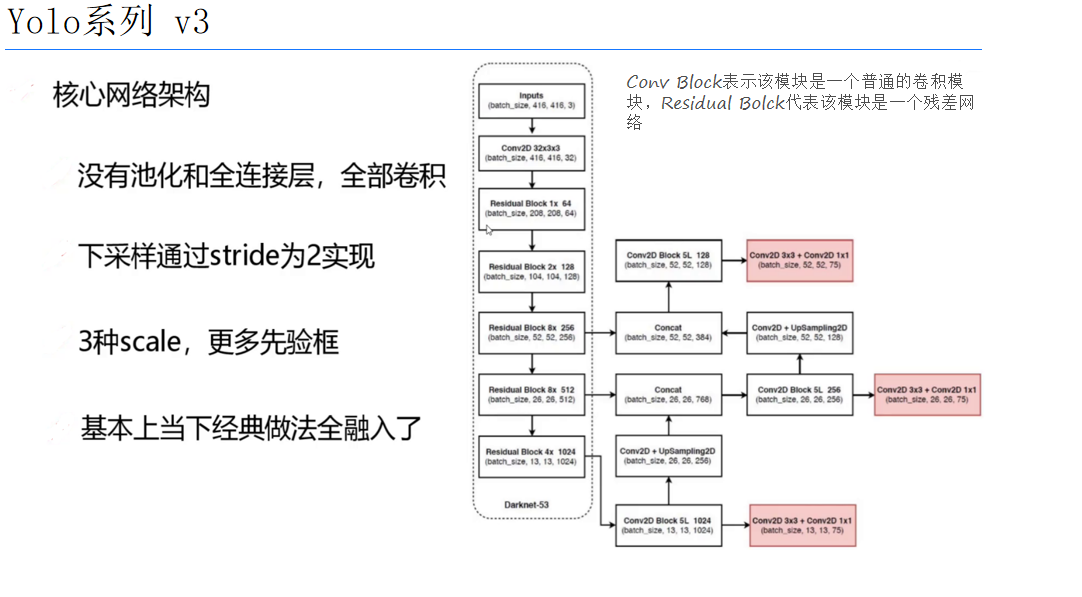
- 卷積層:用于提取圖像特征。
- 殘差塊:通過跳躍連接來提高網絡的訓練效率。
- 特征金字塔:YOLOv3使用特征金字塔來處理不同尺度的特征圖,從而實現多尺度檢測。
網絡結構詳解
YOLOv3的網絡結構可以分為以下幾個部分:
- 基礎網絡:YOLOv3的基礎網絡通常采用Darknet-53,這是一個深度卷積神經網絡,用于提取圖像的特征。
- 特征融合:通過特征金字塔網絡(FPN)結構,YOLOv3能夠融合不同尺度的特征圖,提高檢測的準確性。
- 預測層:在網絡的最后,YOLOv3有三個預測層,分別對應三個不同的尺度,用于預測邊界框和類別概率。
YOLOv3的損失函數
YOLOv3的損失函數由三部分組成:位置誤差、置信度誤差和分類誤差。位置誤差衡量預測框和真實框之間的差異,置信度誤差衡量預測框包含對象的概率,分類誤差衡量預測類別和真實類別之間的差異。
損失函數詳解
- 位置誤差:使用平方誤差來衡量預測框和真實框之間的差異。
- 置信度誤差:使用二元交叉熵損失來衡量預測框包含對象的概率。
- 分類誤差:使用二元交叉熵損失來衡量預測類別和真實類別之間的差異。
YOLOv3的實戰應用
在實際應用中,YOLOv3可以用于各種目標檢測任務,如自動駕駛、視頻監控和圖像分析。以下是使用YOLOv3進行目標檢測的基本步驟:
- 數據準備:收集并標注數據集,可以使用Labelme等工具進行標注。
- 模型配置:設置模型配置文件,包括類別數量、輸入尺寸等。
- 訓練模型:使用訓練代碼和配置文件訓練模型。
- 測試模型:使用測試代碼和模型權重進行檢測。
- 結果分析:分析檢測結果,調整模型參數以提高準確性。
實戰步驟詳解
- 數據標注:使用Labelme等工具對數據集進行標注,生成YOLO格式的標簽文件。
- 模型配置:根據數據集的類別數量和圖像尺寸,配置YOLOv3的模型文件。
- 訓練:使用YOLOv3的訓練腳本和配置文件,對模型進行訓練。訓練過程中,可以調整學習率、批次大小等超參數。
- 測試:使用訓練好的模型對測試集進行檢測,評估模型的性能。
- 調優:根據測試結果,調整模型結構或超參數,以提高檢測的準確性和速度。
結論
YOLOv3是一個強大的目標檢測算法,它在速度和準確性之間取得了很好的平衡。隨著深度學習和計算機視覺技術的不斷進步,YOLOv3及其后續版本將繼續在目標檢測領域發揮重要作用。無論是在學術研究還是在工業應用中,YOLOv3都證明了其價值和潛力。
。











總結,很清晰,很好理解!!)







