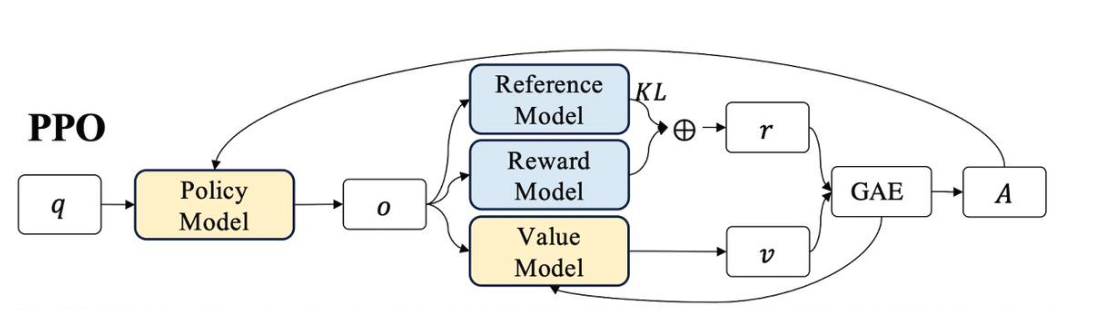
1. 四個模型:
- Policy Model:我們想要訓練的目標語言模型。我們一般用SFT階段產出的SFT模型來對它做初始化。
- Reference Model:一般也用SFT階段得到的SFT模型做初始化,在訓練過程中,它的參數是凍結的。Ref模型的主要作用是防止Actor”訓歪”。(我們希望訓練出來的Actor模型的輸出分布和Ref模型的輸出分布盡量相似,使用KL散度衡量兩個輸出分布的相似度,這個KL散度會用于后續loss的計算)
- Reward Model:用于計算生成token
At的即時收益,在RLHF過程中,它的參數是凍結的。 - Value Model:用于預測期望總收益
Vt,和Actor模型一樣,它需要參數更新。因為在t時刻,我們給不出客觀存在的總收益,只能訓練一個模型去預測它。
2. r,GAE,A
圖中的r或者說rt的獲得:訓練模型的輸出分布和ref模型的輸出分布的KL散度*超參數 + reward 模型的輸出。
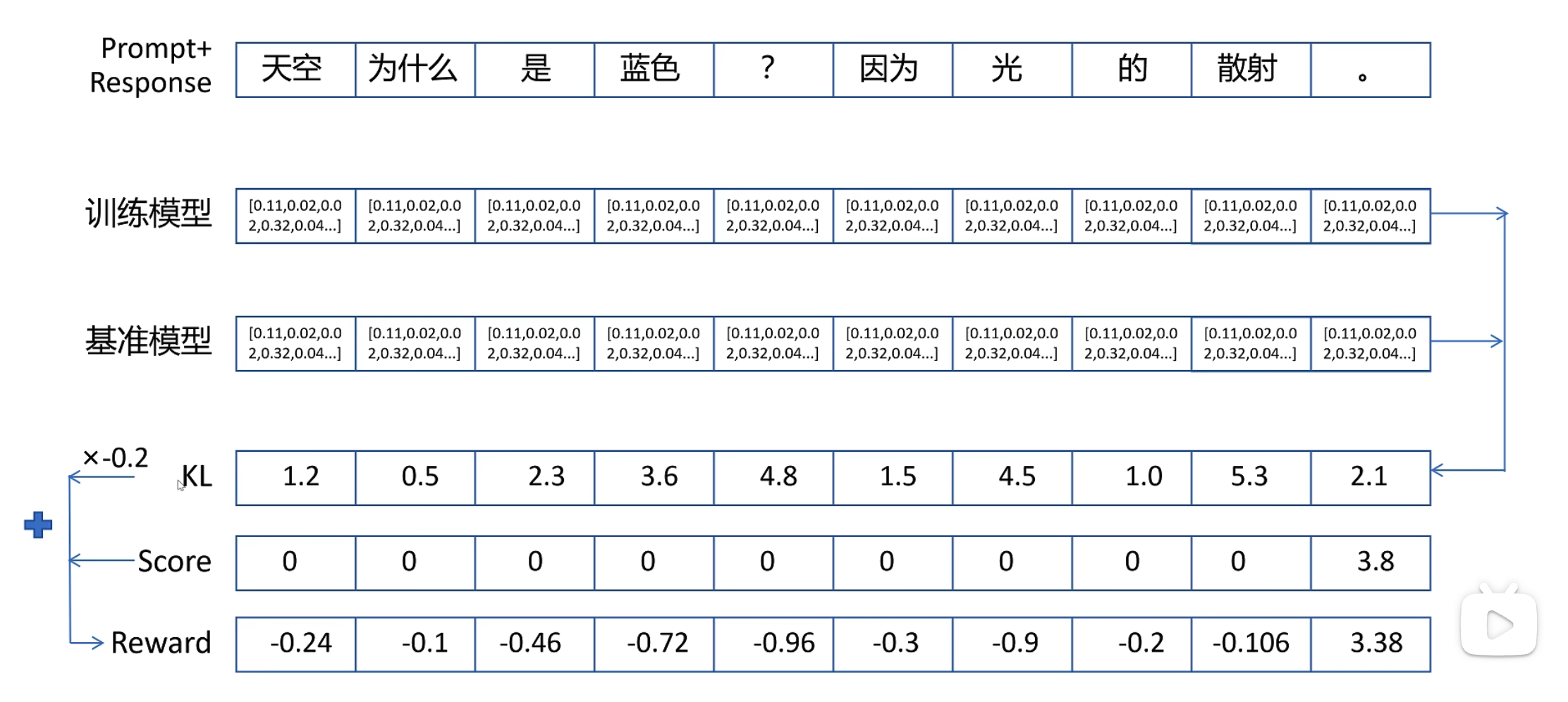

GAE整合獎勵(r)與價值(v),計算優勢函數 A,指導策略優化:

3. 重要性權重(新舊策略概率比)
在PPO算法中,?約束重要性權重 有兩種主要的約束方式?:Clip機制和KL散度懲罰。

3.1 Clip機制

3.2 KL散度懲罰

將這個公式展開也就是:
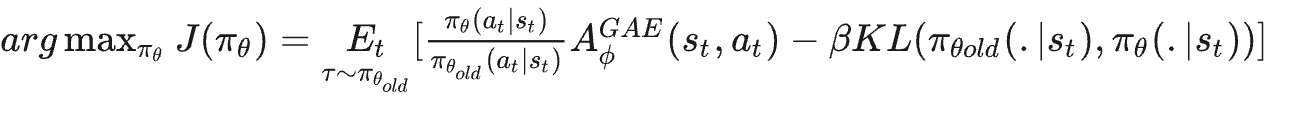
4. actor loss 和 critic loss
這兩個loss 分別用于優化 policy model 和 value model
- 如果用clip限制策略更新的幅度下的actor loss:

- critic loss:

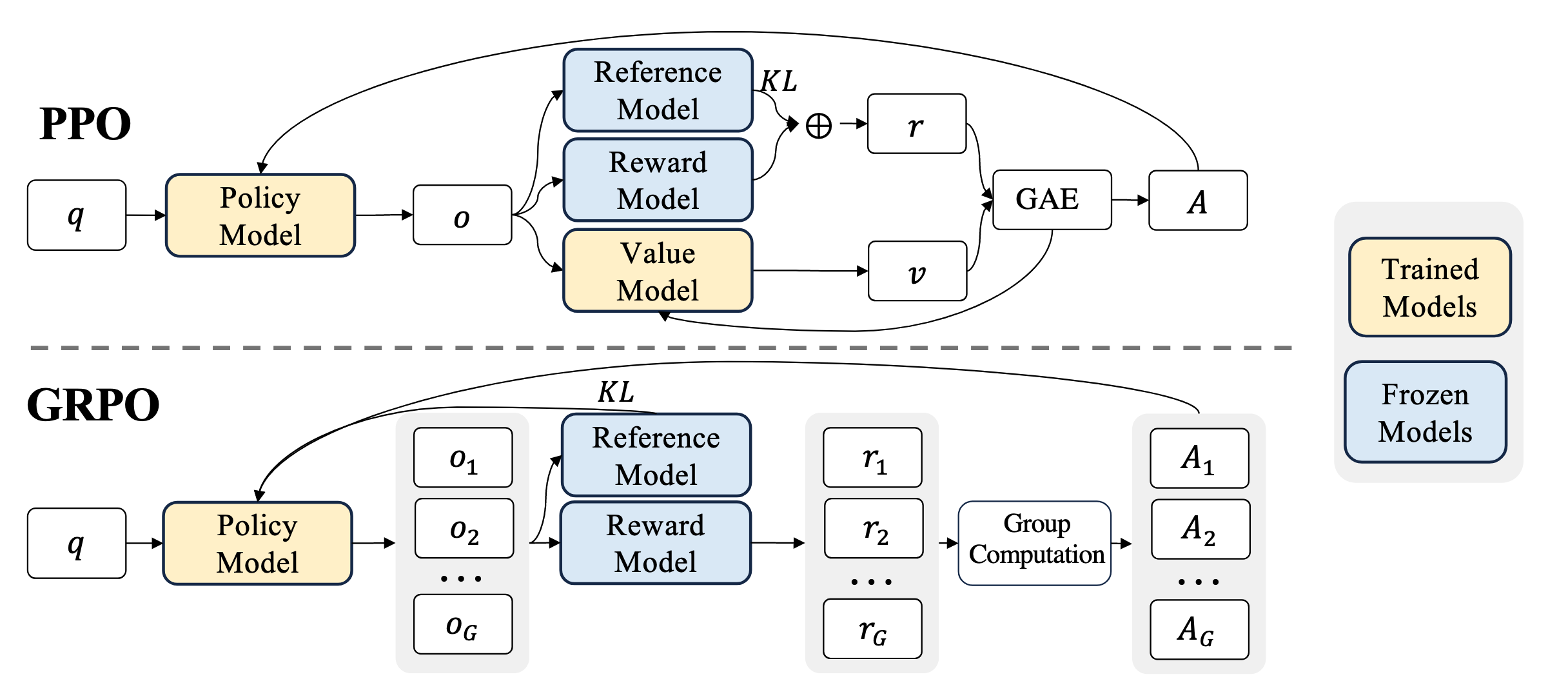
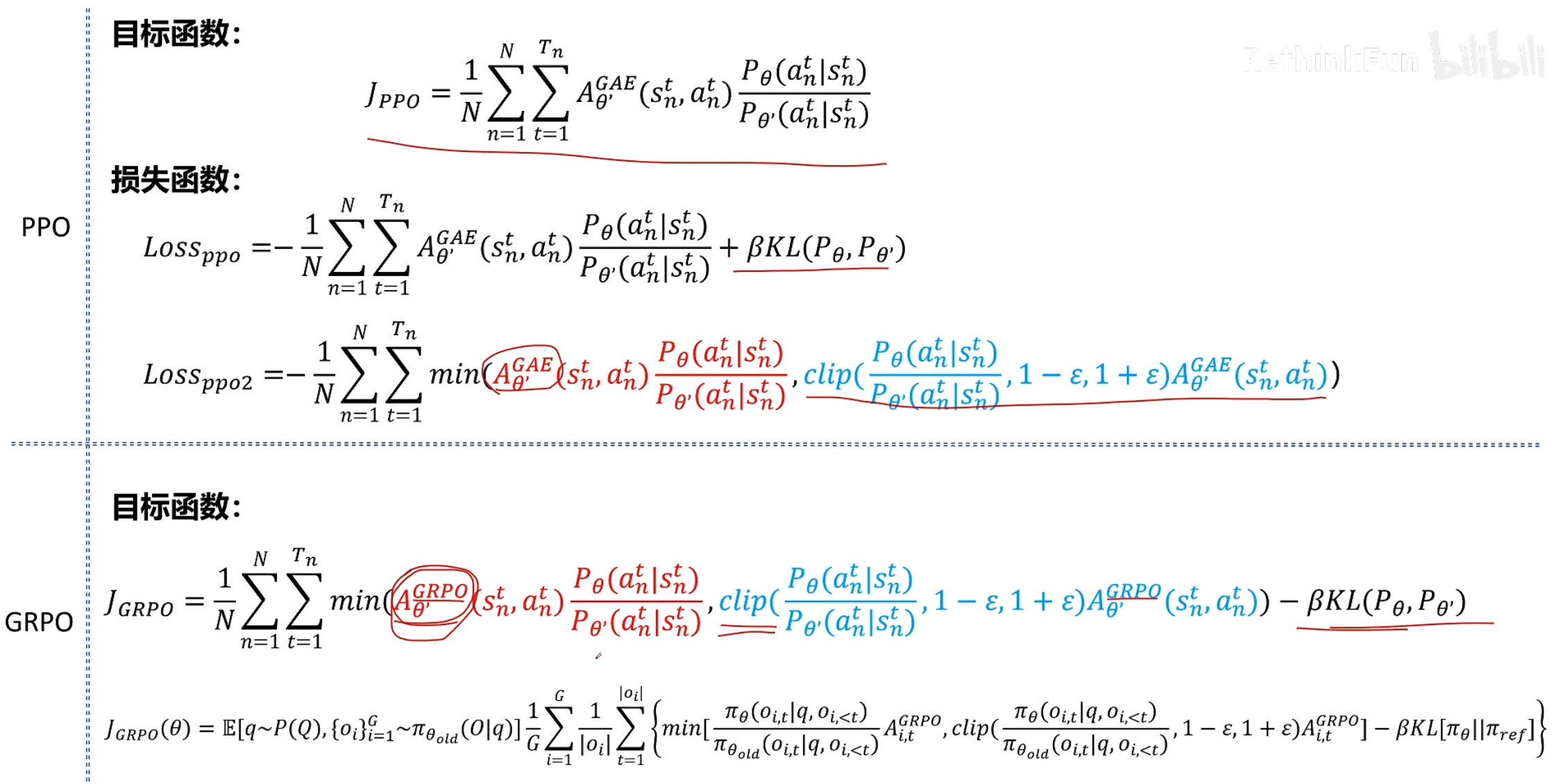
PPO 和 GRPO :
主要區別:提出一個不需要訓練狀態價值網絡,就可以估算出每個token 優勢值的方法,并且這個方法更適合訓練大模型生成強化學習這個場景。














:負載均衡流量分發管理實戰指南)




