文章目錄
- 1 背景
- 2 三個核心概念
- 3 Launch層:特性發布的專用機制
- 4 流量分發策略和條件篩選
- 4.1 四種流量分發類型
- 4.2 條件篩選機制
- 5 工具鏈與監控體系
- 6 實驗設計原則
- 7 培訓
- 參考與推薦
1 背景
谷歌(Google)以數據驅動著稱,幾乎所有可能影響用戶體驗的改動,無論是 UI 界面調整還是背后算法變更,都要通過在線實驗(A/B 測試)來驗證。實驗的目標是更好地評估新方案的效果,從而加速產品迭代。傳統的單層實驗系統中,每個請求最多只能屬于一個實驗。谷歌早期采用Cookie Mod和隨機流量分流的單層方案:首先按 Cookie 模劃分流量給某些實驗,其余流量再做隨機分配。這種設計雖然實現簡單易用,但存在兩個嚴重的問題:
- 前端代碼(上游服務)先行“搶占”流量后,下游服務很可能流量匱乏,導致實驗流量饑餓和偏差。
- 更重要的是,這樣的單層體系無法支撐大量并發實驗,難以滿足谷歌數據驅動的需求。
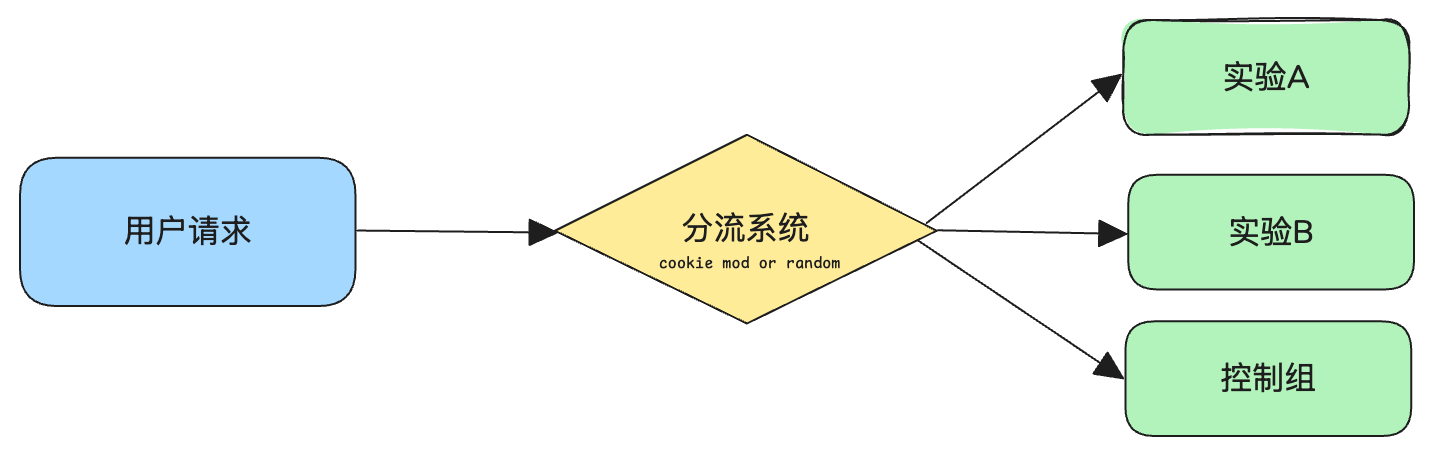
隨著迭代需求激增,單一實驗平臺的可并行實驗數量成為瓶頸:如果同時只能運行很少實驗,就無法支撐快速的創新節奏。因此,谷歌需要一個架構來支持“更多、更好、更快”的實驗。
💡 A/B 測試
A/B 測試是一種數據驅動的在線實驗方法,用于評估產品改動(如界面、功能或算法)對用戶行為或業務指標的影響。通過將用戶隨機分配為兩組:實驗組(使用新方案)和控制組(保持現狀),對比兩組在關鍵指標上的差異,判斷新方案是否有效。其核心優勢是通過隨機化控制干擾因素,使因果推斷更可靠。
實驗設計需遵循以下原則:
- 隨機分配:確保用戶特征在兩組中均衡分布,避免系統性偏差;
- 一致分流:同一用戶始終進入相同分組,保持實驗穩定性;
- 樣本量充足:便于檢測小幅度變化,提高統計顯著性。
常見的評估指標包括:
類型 示例 用途說明 用戶行為 點擊率(CTR)、轉化率(CVR)、跳出率 衡量改動是否改善用戶互動與留存 商業指標 收入、下單率、ARPU 直接與業務增長掛鉤,是決策重點 系統性能 加載時間、錯誤率、耗時 反映改動對系統穩定性與響應效率的影響 長期價值 留存率、生命周期價值(LTV) 評估改動對用戶長期使用的積極或負面影響 不同實驗目標對應不同核心指標。以推薦算法為例,可能關注點擊率、推薦命中率、長時間停留等;而注冊流程優化則更看重轉化率、漏斗流失率等。
此外,為防止“指標漂移”或過度追求短期提升,谷歌等公司還會設定一組保底指標(guardrail metrics),確保實驗不會在某些維度上造成退化(如用戶滿意度或系統穩定性下降)。
為解決單層架構的局限性,谷歌提出了重疊實驗基礎設施。這一創新架構的核心思想是:將系統參數劃分到不同層(Layer),并允許一個用戶請求同時參與多個不同層的實驗。與傳統的單實驗(每請求僅一個實驗)不同,每個請求可同時參加多個實驗,但每個實驗只能修改其對應層的參數。這樣,系統可在不同維度上“交叉”運行實驗,而不互相干擾。
2 三個核心概念
重疊實驗架構的基礎由三個核心概念組成:
- 域(Domain):對請求流量的分段(Segmentation),定義了一組實驗的運行范圍
- 層(Layer):系統參數的邏輯子集,每層包含互不重疊的參數組
- 實驗(Experiment):在特定域內的特定層上,對一部分流量給予替代參數值的嘗試
域和層是可嵌套的:域中包含多個層,層中可以包含實驗,也可進一步嵌套域。默認域包含所有流量、所有參數。我們可以在默認域內設計多種結構:例如將參數簡單劃分為三個層,則每個請求最多參加3個實驗,各層互不重疊。
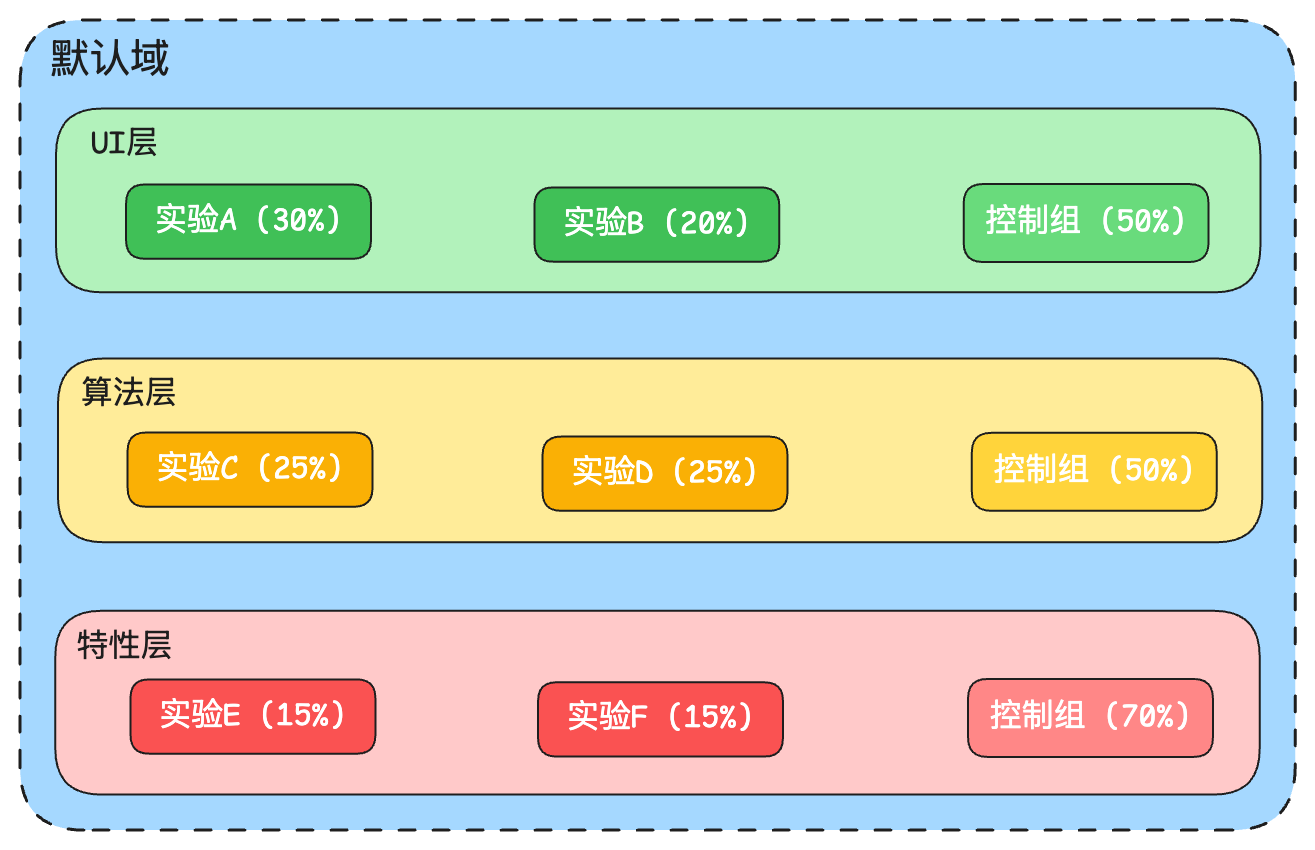
或者先將流量分到兩個域:一個非重疊域(流量分配到此域的請求最多參與一個實驗,可以改變任意參數),另一個重疊域(流量分配到此域的請求可分別進入多個層的實驗,每層實驗僅修改該層參數)。
下圖示意了一個簡單的域/層結構示例。整個系統由一個默認域包含所有流量,然后分為兩個主要的子域:
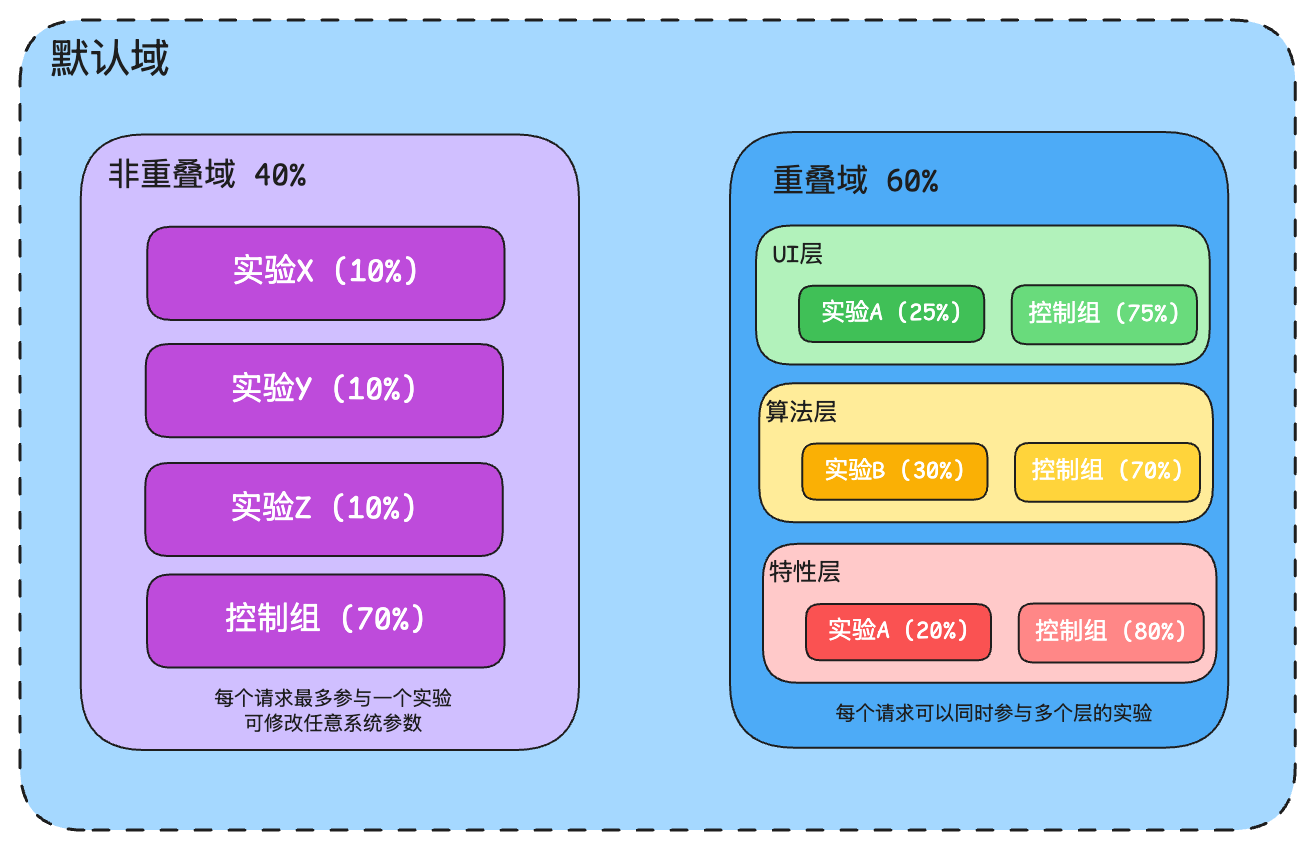
左側的非重疊域占據40%的流量,其特點是每個請求最多只能參與一個實驗,但這個實驗可以修改系統中的任意參數。這個域中包含三個獨立實驗(X、Y、Z),每個占10%流量,剩余70%為控制組。右側的重疊域占據60%的流量,其特點是請求可以同時參與多個不同層的實驗。這個域被劃分為三個功能層:UI層、算法層和特性層,每層管理不同的參數集。每層都有自己的實驗組和控制組,且流量分配各不相同:UI層的實驗A占25%,算法層的實驗B占30%,特性層的實驗C占20%。
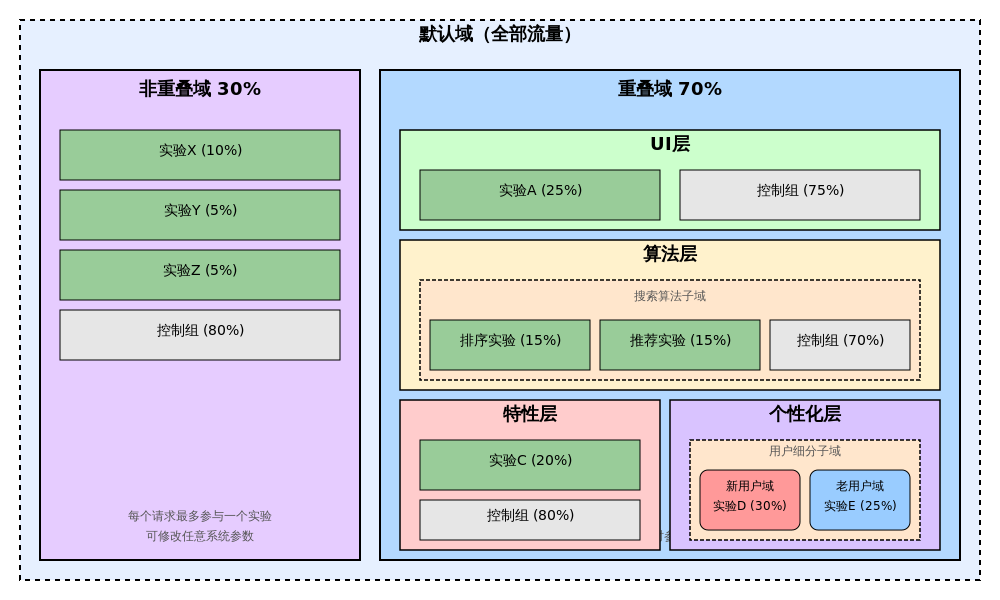
下圖中展示了更復雜的嵌套關系:算法層內嵌套了搜索算法子域,包含排序和推薦兩個并行實驗;個性化層內部嵌套了用戶細分子域,再進一步細分為新用戶域和老用戶域,實現精細化實驗控制。通過這種多級嵌套方式,對參數的不同組合劃分和流量層次劃分可以靈活配置,大大提升并行實驗的靈活性和效率(下圖示意了一個復雜的域/層嵌套結構示例)。
3 Launch層:特性發布的專用機制
除了常規的實驗層外,谷歌還引入了"Launch層"(發布層)的概念,專門用于新特性的漸進式發布。Launch 層總是在默認域中(即覆蓋全量流量),與“普通”層使用不同的參數劃分方式。在 Launch 層中,實驗指定的是參數的新默認值:如果在其他層沒有覆蓋這些參數,實驗中的默認值生效;如果已有層覆蓋,則繼續沿用普通層的值。
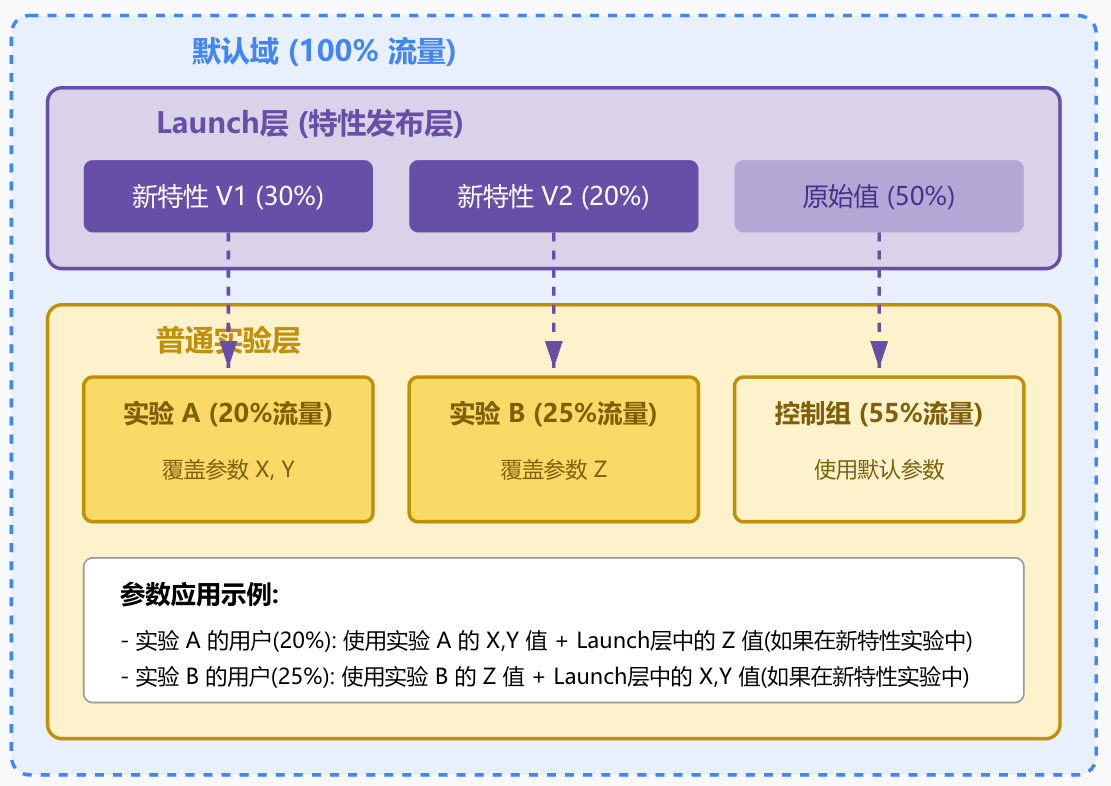
Launch層為特性發布提供了強大的控制機制,使產品團隊能夠:
- 逐步放量新特性,確保平穩過渡
- 測試不同特性版本間的交互影響
- 在同一個實驗框架內統一管理特性發布和常規實驗
- 在發現問題時快速回滾,通過調整 Launch 層的參數分配
4 流量分發策略和條件篩選
實驗中如何決定每個請求進入哪些實驗?這依賴于流量分發類型(Diversion)和條件篩選。
4.1 四種流量分發類型
谷歌的實驗平臺支持四種主要的流量分發(Diversion)方式,按優先級依次為:
- 用戶 ID 分發(User ID Mod):使用用戶登錄 ID 做 Hash 切分流量。
- Cookie 分發(Cookie Mod):使用瀏覽器 Cookie 做 Hash 切分流量。
- Cookie+日期分發(Cookie-Day Mod):對 Cookie 結合日期做 Hash,使得同一用戶在不同日期可能進入不同實驗。這種方式適合短期測試或需要日常變化的場景。
- 隨機分發(Random):對請求做全局隨機采樣,不保證同一用戶的一致性。適用于無需用戶連續體驗的后端服務測試。
這些分發方式依次按順序應用:先嘗試 User ID 分發,其次是 Cookie 分發,之后是 Cookie+日期,最后才是隨機。一旦請求被某種分發方式選中并匹配到一個實驗,就不再參加后續的分發。這樣確保了測試的一致性(同一用戶/Cookie 會持續進入同一類型實驗),但也會導致例如 1% 的隨機流量實驗實際上接收的請求遠少于 1% 的 Cookie 實驗。
4.2 條件篩選機制
在流量分發的基礎上,谷歌的實驗平臺還支持通過各種條件進一步篩選流量:
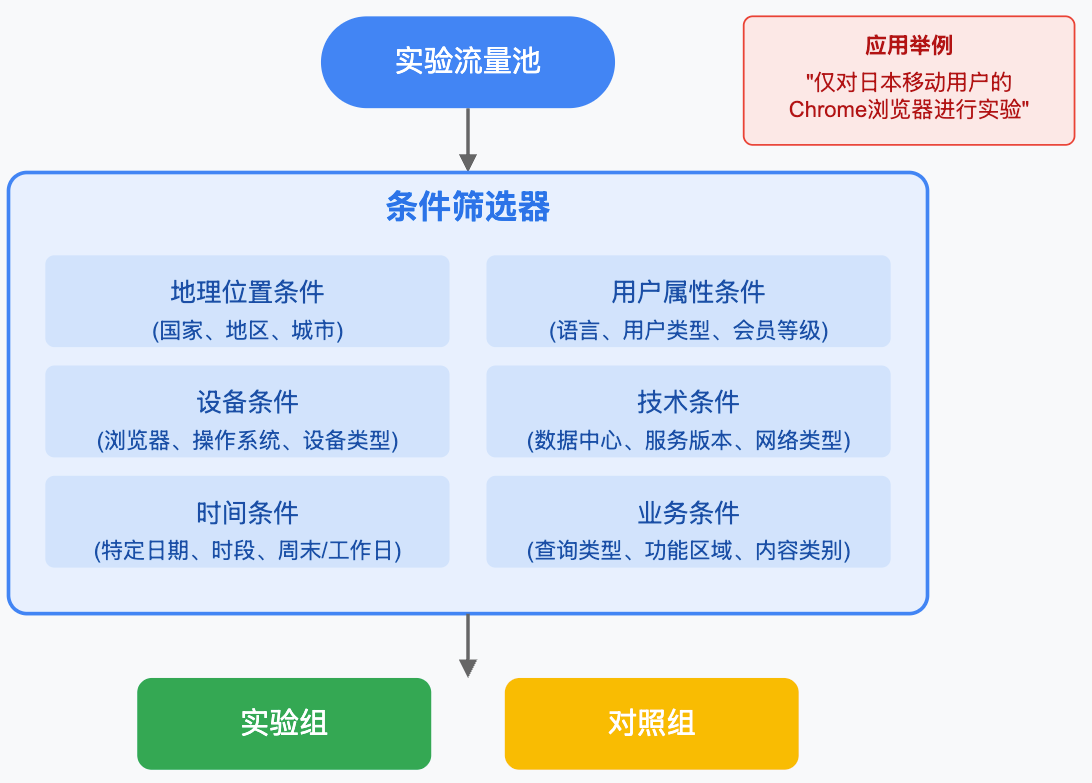
條件篩選**(如國家、語言、瀏覽器、機房等)**可應用于所有類型的流量分發之上。例如,針對“僅對日本用戶”做實驗時,可在 Cookie 分流后添加“日本”條件,以避免與英文實驗沖突。篩選條件還可以用于灰度發布:如僅在特定機房做金絲雀測試,觀察新代碼穩定性。
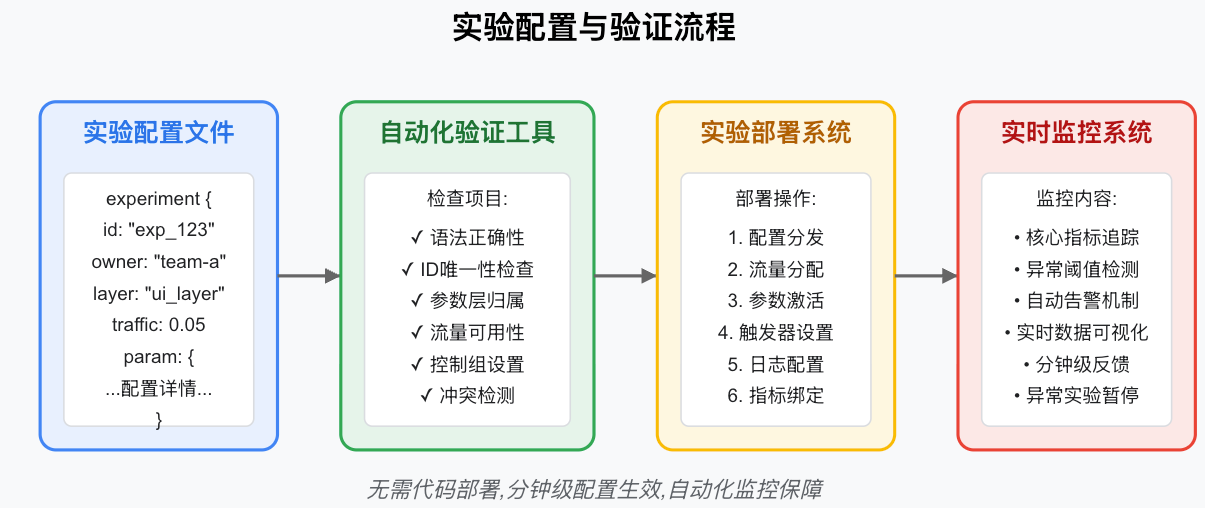
5 工具鏈與監控體系
重疊實驗基礎設施依賴完善的工具鏈和監控流程來保障可靠性。
- 首先,所有實驗配置都以數據文件形式管理,可由非工程師(如產品經理)編輯,數據文件通過自動化校驗工具進行檢查,驗證語法、ID 唯一性、參數所屬層是否一致、所請求的流量量級是否可用、實驗設計是否合規(如是否包含控制組)等。
- 其次,配置更新無需重新部署代碼,而是通過自動化部署系統將驗證通過的配置分發至線上環境,包括流量分配、參數激活、觸發器設置和日志配置等。
- 最后,使用實時監控系統跟蹤實驗指標(如點擊率 CTR 等)。實驗者可為關鍵指標設置期望范圍,監控系統實時計算度量值,如果超出預期范圍則自動告警。這樣可以讓實驗者在實驗跑出異常時立即干預,例如暫停實驗或修正參數,從而盡量避免流量浪費或線上問題。
6 實驗設計原則
在重疊實驗框架下,為確保獲得高可信度和高質量的實驗結果,需要遵循以下幾項核心設計原則:
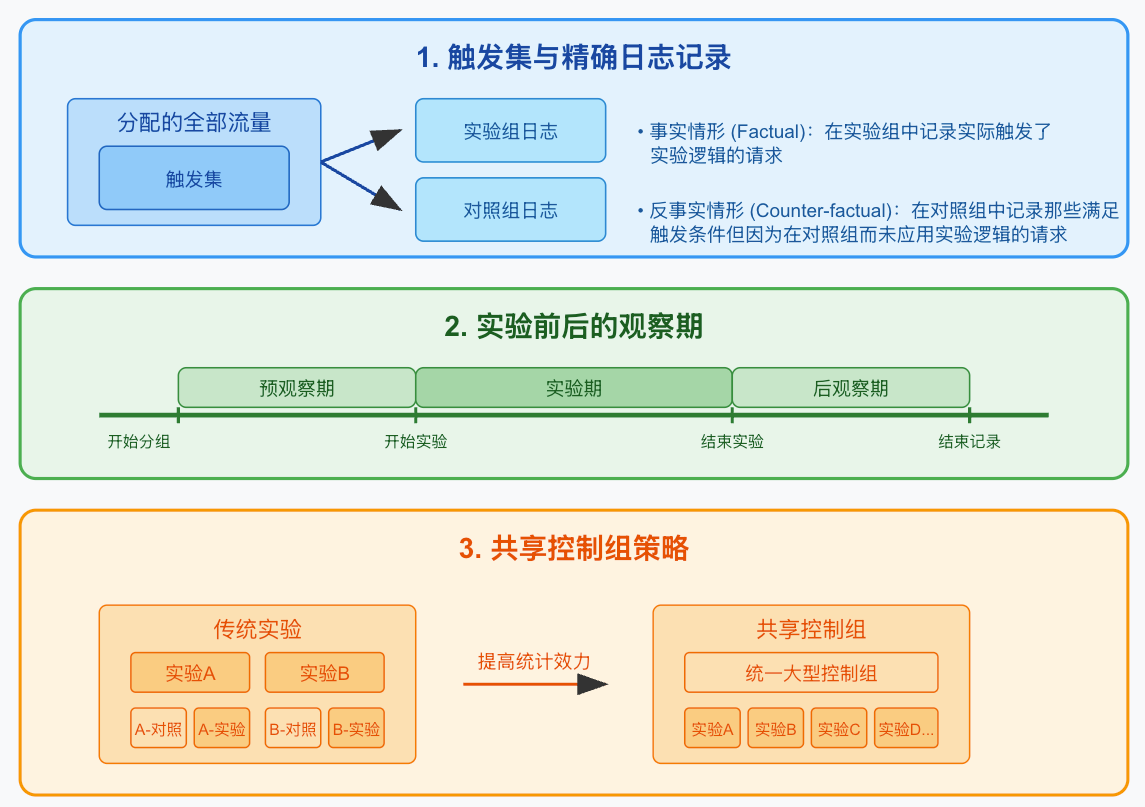
-
并非所有被分流到實驗中的請求都會實際觸發實驗邏輯。例如,某個關于天氣信息的實驗可能只在用戶搜索特定地點或與天氣相關的查詢時才會觸發顯示邏輯,這部分真正觸發實驗條件的請求就構成了該實驗的"觸發集"。
為獲得準確的實驗評估,系統需同時記錄兩種情況的日志:
- 事實情形(Factual):在實驗組中記錄實際觸發了實驗邏輯的請求
- 反事實情形(Counter-factual):在對照組中記錄那些滿足觸發條件但因為在對照組而未應用實驗邏輯的請求
有了這兩個日志,才能準確計算實驗真實影響,并避免將未觸發的請求稀釋掉指標變化。通過分析觸發集效果,可提升統計效率(同樣的流量下因為效果更明顯而更容易檢測出差異)。
-
高質量的實驗設計應包含實驗前后的觀察窗口:
- 預觀察期(Pre-period):在正式實驗前設置一段時間窗口,此時已完成流量分組,但尚未應用實驗邏輯變更,所有組別仍保持原有行為。
- 后觀察期(Post-period):實驗結束后,繼續保持一段時間的分組記錄,但所有組別均恢復到原始行為。
預觀察期幫助確認所分配的實驗流量與控制組具有可比性,可有效檢測潛在的實驗偏差(如機器人流量、爬蟲干擾或其他異常流量分布)。后觀察期則用于檢測實驗結束后的用戶行為變化,特別是學習效應或延續效應是否存在。這兩種觀察期在基于用戶ID或Cookie的實驗中尤為重要,已成為谷歌實驗設計的標準實踐。
-
共享控制組:在傳統實驗中,每個實驗需要獨立分配控制組和實驗組流量。而在重疊架構下,同一層內的多個實驗可以共享一個統一的、規模較大的控制組。每個層內只需設置一個大型控制實驗,即可同時作為該層多個具體實驗的對照。只要共享控制組的規模遠大于單個實驗組,其統計效力可提升至相當于雙倍獨立樣本,甚至更高。此機制可顯著降低了每個實驗所需的流量量級,提升了整體流量利用效率。
-
由于不同實驗可以并行進行,重疊設置允許一個層內建立共享的超大控制組。例如,在每個層里只需要一個大的控制實驗,就可服務于多個具體實驗的對照。只要共享控制組遠大于單個實驗組,其統計效力相當于雙倍獨立樣本乃至更高,從而顯著降低每個實驗所需的流量規模。從統計學角度看,控制組共享使重疊架構在同等流量條件下獲得更高的統計檢驗效力,是實現"更多、更好、更快"實驗目標的關鍵策略之一。
除了以上特定機制外,每個實驗還必須滿足以下基本要求:
- 明確假設:清晰定義實驗假設和預期效果
- 適當的分流策略:根據實驗性質選擇合適的流量分發類型
- 合理的分析指標:預先確定主要指標和次要指標
- 統計工具支持:確保分析工具能自動計算置信區間、執行A/A測試等統計驗證
7 培訓
技術平臺之外,谷歌也通過制度和培訓確保實驗質量。
其一是實驗委員會(Experiment Council):實驗發起者在投放實驗前需填寫一份檢查表,由一個跨團隊工程師小組審查。檢查表內容包括:
- 基本的實驗特性(比如,實驗測試什么?它們的假設是什么?)
- 實驗的建立(比如,要修改哪些參數,每個實驗或實驗集合分別要測試的是什么?在哪一層?)
- 實驗的流量分配和觸發條件(比如,使用什么分配類型和什么分配條件,在多大比例的流量觸發實驗)
- 實驗分析(比如,關注哪個指標?實驗者要檢測的指標敏感度是什么?)
- 實驗規模和時間跨度(即保證,給定一定的流量,實驗是有足夠的統計量來檢測指標敏感度)
- 實驗設計(比如,是否要用預時期和后時期來保證,是否反事實日志正確被記錄等等)
對于新手來說,這是學習實驗設計的過程;對經驗者則是快速自查,有問題可提前解決。所有審核過程都有記錄,新人可參考已有案例,專家也能借此及時傳播最新最佳實踐。
其二是數據解讀會議:實驗結束后,團隊會將結果帶到一個開放的討論會,由各領域專家(基礎設施、日志、指標、統計分析等)共同參與。會議目標是:
- 確認結果正確(有時實現細節出錯或數據異常需要排查)
- 挖掘全面洞見(補充指標、不同切片分析等)
- 評估是否上線(在綜合業務視角和數據結果后達成一致)。
這種復盤機制不僅能糾偏,還讓經驗豐富的同事將知識傳遞給新人,不斷提高全員的實驗素養。
參考與推薦
美團點評效果廣告實驗配置平臺的設計與實現
美團—如何提供一個可信的AB測試解決方案
谷歌是如何高效做AB實驗的
Athena-貝殼流量實驗平臺設計與實踐
Overlapping Experiment Infrastructure: More, Better, Faster Experimentation 原文
Overlapping Experiment Infrastructure: More, Better, Faster Experimentation 中文翻譯
)
】)








![class path resource [] cannot be resolved to absolute file path](http://pic.xiahunao.cn/class path resource [] cannot be resolved to absolute file path)
、位圖的實現和布隆過濾器的介紹)

)

)



