30歲程序員學習Python的第二天之網絡爬蟲的信息提取
BeautifulSoup庫
地址:https://beautifulsoup.readthedocs.io/zh-cn/v4.4.0/
1、BeautifulSoup4安裝
在windows系統下通過管理員權限運行cmd窗口
運行pip install beautifulsoup4
測試實例
import requests
from bs4 import BeautifulSoup
r = requests.get('https://python123.io/ws/demo.html')
print(r.text)
demo = r.text
soup = BeautifulSoup(demo, 'html.parser')
print(soup.prettify())
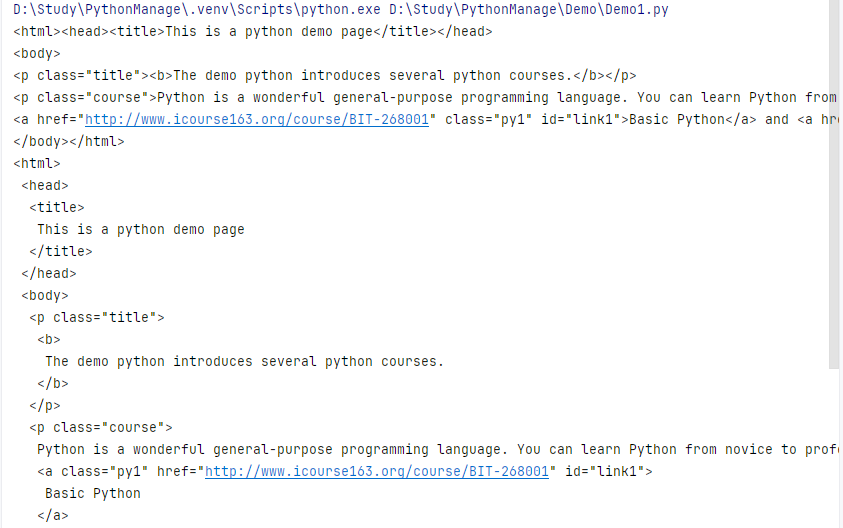
注:prettify() 方法將Beautiful Soup的文檔樹格式化后以Unicode編碼輸出,每個XML/HTML標簽都獨占一行
2、BeautifulSoup庫基本信息
Beautiful Soup庫是解析、遍歷、維護“標簽樹”的功能庫
BeautifulSoup庫是標簽Tag進行解析的。
例:<p calss=“title”> … </p> 每個標簽都是成對出現的,并且在第一個標簽上可以有多個屬性值
可通過以下語句導入beautiful Soup庫
from bs4 import BeautifulSoup
或
import bs4
BeautifulSoup的解析器

BeautifulSoup類的基本元素

如何通過解析獲取每個標簽內容
1、獲取Tag的名字:<tag>.name
soup = BeautifulSoup(demo, 'html.parser')
print(soup.title.name)

2、獲取Tag的attrs(屬性):<tag>.attrs
soup = BeautifulSoup(demo, 'html.parser')
print(soup.a.attrs)
print(soup.a['href'])
print(soup.a['id'])

3、獲取Tag內的NavigableString(非屬性字符串):<tag>.string
soup = BeautifulSoup(demo, 'html.parser')
print(r.text)
print(soup.a.string)

4、獲取Tag內字符串的注釋部分Comment:
newsoup = BeautifulSoup("<b><!--這是注釋--></b><p>這不是注釋</p>", "html.parser")
print(newsoup.b.string)
print(type(newsoup.b.string))
print(newsoup.p.string)
print(type(newsoup.p.string))

Comment是一種特殊的類型,可通過這個判斷非屬性字符串是否是注釋。
3、基于bs4遍歷HTML頁面的內容
HTMl頁面按標簽劃分是二叉樹的形式
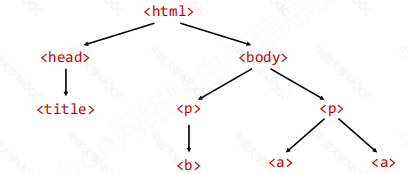
所以在進行HTML內容遍歷時,可分為橫向遍歷和縱向遍歷。
縱向遍歷
向下遍歷

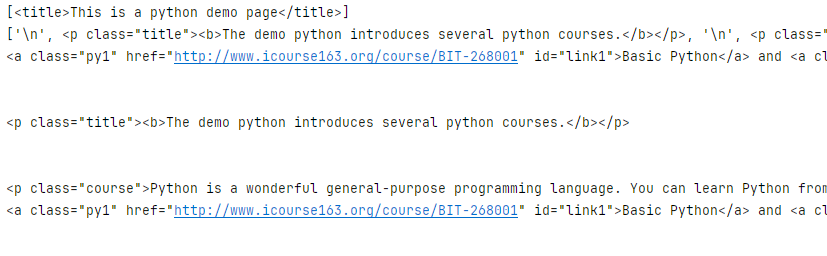
soup = BeautifulSoup(demo, 'html.parser')
print(soup.head.contents)
print(soup.body.contents)
for child in soup.body.children:print(child)
向上遍歷

soup = BeautifulSoup(demo, 'html.parser')
print(soup.title.parent)
print(soup.html.parent)
for parent in soup.a.parents:if parent is None:print(parent)else:print(parent.name)
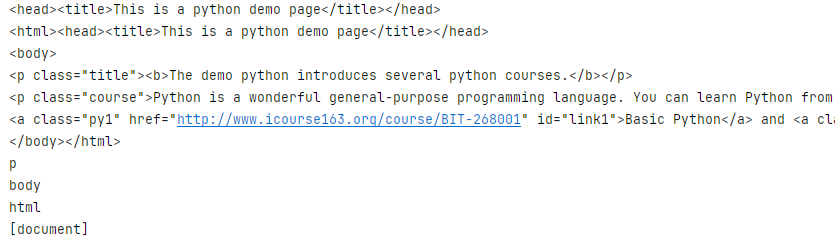
橫向遍歷
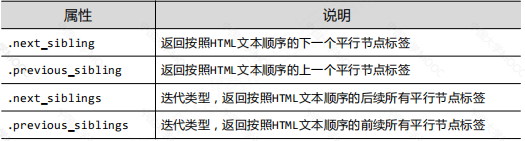
平行遍歷發生在同一個父節點下的各節點間
soup = BeautifulSoup(demo, 'html.parser')
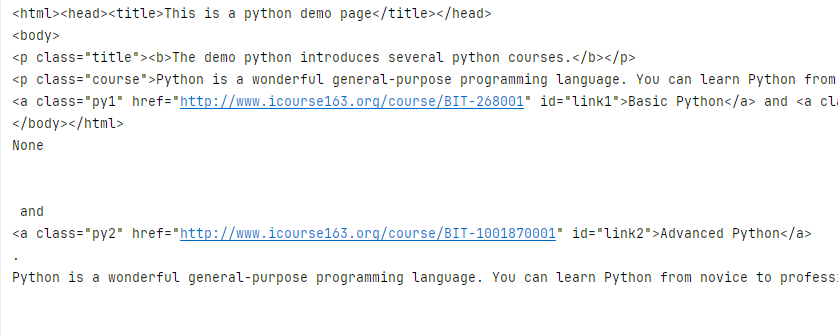
print(soup)
print(soup.title.next_sibling)
print(soup.body.previous_sibling)
for sibling in soup.a.next_siblings:print(sibling)
for prev in soup.a.previous_siblings:print(prev)
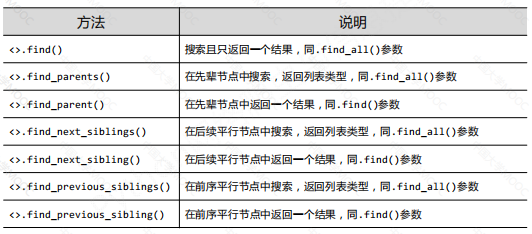
4、基于bs4的HTML的內容查找
搜索方法:find() 和 find_all()
find_all()
<>.find_all(name, attrs, recursive, string, **kwargs)
返回一個列表類型,存儲查找的結果
name 對標簽名稱的檢索字符串
可通過name參數進行html頁面進行標簽名稱檢索,也可傳True,檢索全部的標簽信息
soup = BeautifulSoup(demo, 'html.parser')
print(soup.find_all('a'))

attrs: 對標簽屬性值的檢索字符串,可標注屬性檢索
soup = BeautifulSoup(demo, 'html.parser')
print(soup.find_all('p','course'))
print(soup.find_all(id='link1'))

recursive: 是否對子孫全部檢索,默認True
soup = BeautifulSoup(demo, 'html.parser')
print(soup.find_all('p'))
print(soup.find_all('p', recursive=False))

string: <>…</>中字符串區域的檢索字符串
soup = BeautifulSoup(demo, 'html.parser')
print(soup.find_all(string='Basic Python'))

擴展方法:


技能系統 投劍技能(上)基礎實現)




使用大語言模型進行時間序列理解和推理)











