一、摘要
? ? ? ? 本文介紹2024年12月字節跳動牽頭發表的大模型論文《ChatTS: Aligning Time Series with LLMs via Synthetic Data for Enhanced Understanding and Reasoning》。論文提出了 ChatTS 模型,用合成數據提升對時間序列的理解和推理能力。作者在紐約出租車乘客數量、廣告 CPC 數據、交通占用率等真實數據上進行案例研究,ChatTS 能準確分析形狀、統計特征和識別異常波動。在數據庫操作和 Twitter 話題討論強度分析等實際應用中,ChatTS 也展現了強大的分析和推理能力。

譯文:
????????理解時間序列對于其在現實場景中的應用至關重要。最近,大語言模型(LLMs)越來越多地應用于時間序列任務,利用其強大的語言能力來增強各種應用。然而,針對時間序列理解與推理的多模態大語言模型(MLLMs)的研究仍然有限,這主要是由于缺乏能將時間序列與文本信息對齊的高質量數據集。本文介紹了ChatTS,這是一種專為時間序列分析設計的新型多模態大語言模型。ChatTS將時間序列視為一種模態,類似于視覺多模態大語言模型處理圖像的方式,使其能夠對時間序列進行理解和推理。為了解決訓練數據稀缺的問題,我們提出了一種基于屬性的方法,用于生成帶有詳細屬性描述的合成時間序列。我們進一步引入了時間序列進化指令(Time Series Evol-Instruct),這是一種生成多樣化時間序列問答的新方法,可增強模型的推理能力。據我們所知,ChatTS是首個將多變量時間序列作為輸入進行理解和推理的時間序列多模態大語言模型,并且它僅在合成數據集上進行了微調。我們使用包含真實世界數據的基準數據集評估其性能,包括六項對齊任務和四項推理任務。結果表明,ChatTS顯著優于現有的基于視覺的多模態大語言模型(如GPT - 4o)以及基于文本/智能體的大語言模型,在對齊任務中提升了46.0%,在推理任務中提升了25.8%。
二、核心創新點
1、總覽
? ? ? ? 由于高質量的將時間序列與文本信息對齊的數據集稀缺,作者選擇了生成合成的文本-時間序列對來進行模型的訓練。然而,用于時間序列-多模態大模型的數據需要有足夠的準確率,且能夠全面涵蓋時間序列屬性以及具有足夠的任務多樣性。為了實現這一目標,作者提出了一種基于屬性的方法來生成時間序列+文本數據:
- 屬性選擇器:為了生成具有精確屬性且高度可控的時間序列數據,作者使用詳細的特征集來描述時間序列。通過大模型選擇,這些屬性與現實世界的設置保持一致。
- 基于屬性的時間序列生成器:使用基于規則的方法構建與屬性池完全對應的時間序列。
- 時間序列進化指令:一種新穎的時間序列錦華化指令模塊,用于創建大規模、多樣化且準確的時間序列與文本問答對數據集,以支持復雜推理。
- 模型設計:為處理多時間序列,作者設計了一種針對多時間序列輸入的上下文感知多模態大模型編碼,以及一種保值時間序列編碼方法。
- 模型訓練:進行大規模訓練和監督微調,以實現語言對齊并提高與時間序列相關的推理能力。
2、基于屬性的時間序列生成器(attribute-based time series generator)
? ? ? ? 多樣的時間序列以及精確、詳細的文本屬性描述對于實現準確的時間序列-語言對齊至關重要。作者將時間序列屬性分為四大類:趨勢、周期性、噪聲和局部波動,以構建相應的時間序列屬性集。
? ? ? ? 基于此,作者提出了一種屬性選擇器和基于屬性的時間序列生成器,用于生成合成的時間序列數據。首先,作者定義一個“全屬性集”,它包括不同屬性類別下的許多特定屬性。全屬性集包括4種趨勢類型、7種季節性類型、3種噪聲類型和19種局部波動類型。同一類別中的不同屬性可以組合。通過組合相同類型的屬性,一個時間序列可以包括多個趨勢段和幾個局部波動。此外,通過組合正弦波,可以生成各種各樣的周期性波動模式。因此,所提出的時間序列生成器理論上可以生成無限數量的不同時間序列,確保了屬性的豐富性。
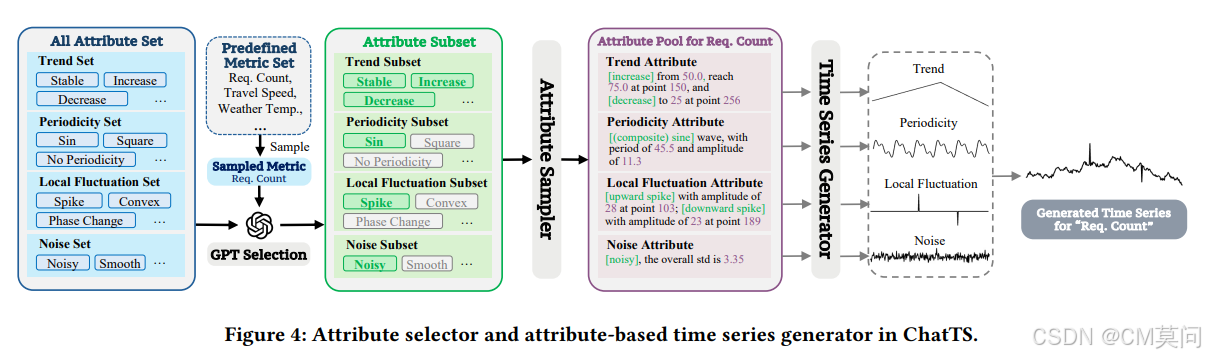
? ? ? ? 作者還引入了一個GPT選擇器。具體來說,在為時間序列生成屬性集時,從一個包含567個來自實際場景的預定義指標名稱的大型“指標集”中隨機采樣一個指標,并根據該指標的實際物理意義和預定義場景,使用GPT從全屬性集中選擇一個屬性子集。這有助于使時間序列與實際物理意義保持一致。
????????然后,屬性采樣器從屬性子集中隨機采樣屬性組合。它還根據GPT選擇器的規則和約束分配特定的數值,如位置和幅度。這些細節存儲在“屬性池”中,該池記錄了關于時間序列的所有詳細信息。時間序列生成器最終以基于規則的方式創建與屬性池中的屬性完全匹配的時間序列數組。這個過程使我們能夠生成具有精確屬性描述的多樣化合成時間序列。
3、時間序列進化指令設計(time series evol-instruct)
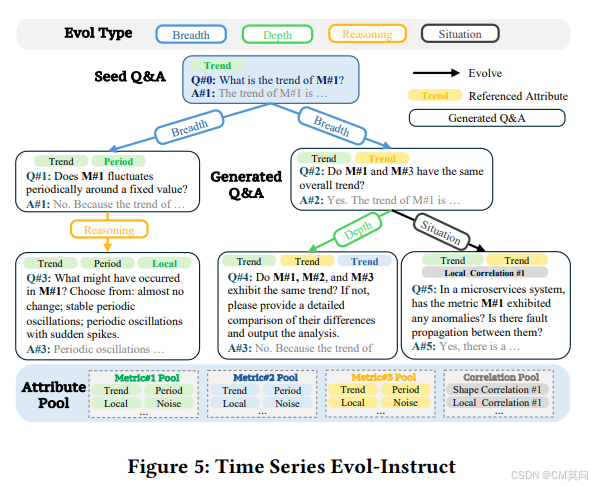
? ? ? ? 為了提升模型的問答和推理能力,擁有格式和任務多樣的高質量監督微調訓練數據至關重要。然而,由于缺乏時間序列+文本數據,直接獲取足夠多樣的與時間序列相關的訓練數據具有較大挑戰。為了生成具有豐富問答格式的準確時間序列+文本監督微調數據,作者提出了時間序列的Evol-Instruct。
????????該方法通過逐步evolve指令prompt及其輸出,來提高大模型訓練數據的多樣性和復雜度。為了增強模型分析相關性的能力,作者引入了一個相關性池,記錄具有相關屬性的時間序列。在evolve的每一步中,從屬性池中隨機選擇一個屬性子集,并將其作為額外的上下文添加,引導大模型根據演化類型生成關于更廣泛的時間序列屬性的問答。
4、時間序列多模態LLM
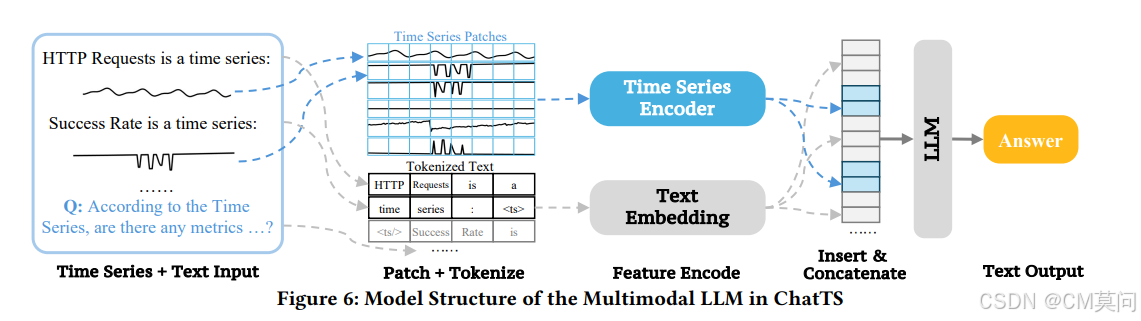
? ? ? ? 為了處理多模態輸入,ChatTS首先將輸入的時間序列數組與文本分離。輸入的時間序列數組被劃分為固定大小的塊,這使得模型能夠更有效地處理和編碼時間模式。由于時間序列本質上具有順序模式,作者采用一個簡單的5層MLP對時間序列的每個塊進行編碼。對于文本輸入,先對其進行標記化處理,然后通過文本嵌入層進行編碼。通過這種方式,時間序列的每個塊和每個文本標記都被映射到同一空間。
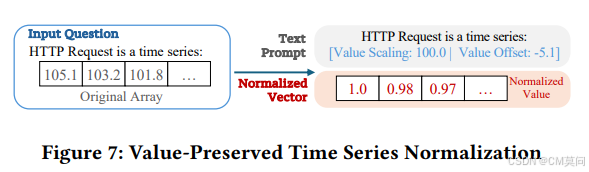
? ? ? ? 為了充分保留多元時間序列的上下文信息,作者基于時間序列在原始輸入中的位置進行了詞元級別的拼接。具體來說,將每個時間序列對應的編碼片段插入到周圍文本詞元之間。然后,這個序列會被輸入到LLM中。傳統的時間序列數據歸一化會導致原始數值信息的丟失。為了解決這個問題,作者提出了一種保值時間序列歸一化框架。首先,對每個時間序列使用標準的最大-最小值歸一化,然后對每個時間序列引入一個“Value Scaling”和“Value Offset”參數,作為prompt的一部分。這樣可以利用大模型的數值理解能力,使得能夠在保留原始數值信息的同時對時間序列特征進行歸一化。
5、模型訓練
? ? ? ? 第一階段是大規模對齊訓練。作者使用基于屬性的合成序列數據進行大規模對齊,以在大模型內建立文本與時間序列模態之間的初始對齊。在對齊階段,作者基于一系列人工設計的模板和大語言模型優化創建了三個數據集用于大規模訓練。單變量時間序列(UTS)數據集包含單變量時間序列基本屬性描述的任務(包括全局和局部屬性任務)。多變量時間序列 - 形狀(MTS-Shape)數據集由具有全局趨勢相關性的多變量數據組成,旨在增強模型分析多變量相關性的能力。多變量時間序列 - 局部(MTS-Local)數據集包含具有相關局部波動的多變量數據,旨在提高模型分析多變量數據局部特征的能力。
????????第二階段,作者使用監督微調(SFT)來提升大語言模型(LLM)執行復雜問答和推理任務的能力。此階段利用兩種主要類型的訓練數據:一種是使用TSEvol生成的數據集,旨在增強模型對時間序列的問答和推理能力;另一種是指令跟隨(IF)數據集,它基于一系列預定義模板構建,旨在增強模型遵循特定響應格式的能力。對于TSEvol,作者使用對齊訓練中的數據集以及大語言模型生成的問答作為種子數據。這些數據集共同訓練多模態大語言模型,使其能夠準確回答特定于時間序列的查詢并遵循任務指令,從而強化其執行復雜的、上下文驅動的問答和推理任務的能力。在對齊和監督微調兩個階段,作者通過一系列數值任務來增強ChatTS的數值處理能力。具體來說,作者明確訓練模型學習各個方面的知識,例如最大值/最小值、分段平均值、局部特征(如峰值位置和幅度)、季節性和趨勢幅度,以及各個時間點的原始數值。

?












(環境搭建))

)




