文章題目是《A grid‐based classification and box‐based detection fusion model for asphalt pavement crack》
于2023年發表在《Computer‐Aided Civil and Infrastructure Engineering》
論文采用了一種基于網格分類和基于框的檢測(GCBD),其中基于網格分類的部分主要用于對裂縫區域進行細粒度劃分,是同時進行分類和檢測的。
📌文章針對目前存在的問題:
- 網格的局部感受野無法提取裂縫的整體特征難以對橫向裂縫、縱向裂縫的宏觀特征進行判斷
- 目標檢測容易產生大量冗余預測框,并且裂縫獨特的拓撲結構會干擾通用的非極大值抑制算法的篩選過濾,造成裂縫檢測性能的劣化
?論文的主要貢獻:
- 構建了大規模高質量標注瀝青路面病害圖像雙標記數據集
- 模型同時實現分類與檢測
- 提出了基于網格的圖像分類策略,一次性識別整張圖像所有的網格
- 基于改進YOLOv5框的檢測
- 構建了一個集成GCBD的融合模型
- 達到工業級的應用性能水平,符合工程標準(《公路技術狀況評定標準JTG5210-2018》)(基于grid和box都可以計算路面病害的面積)
- 輸出結果可直接用于計算路面狀況指數(PCI)
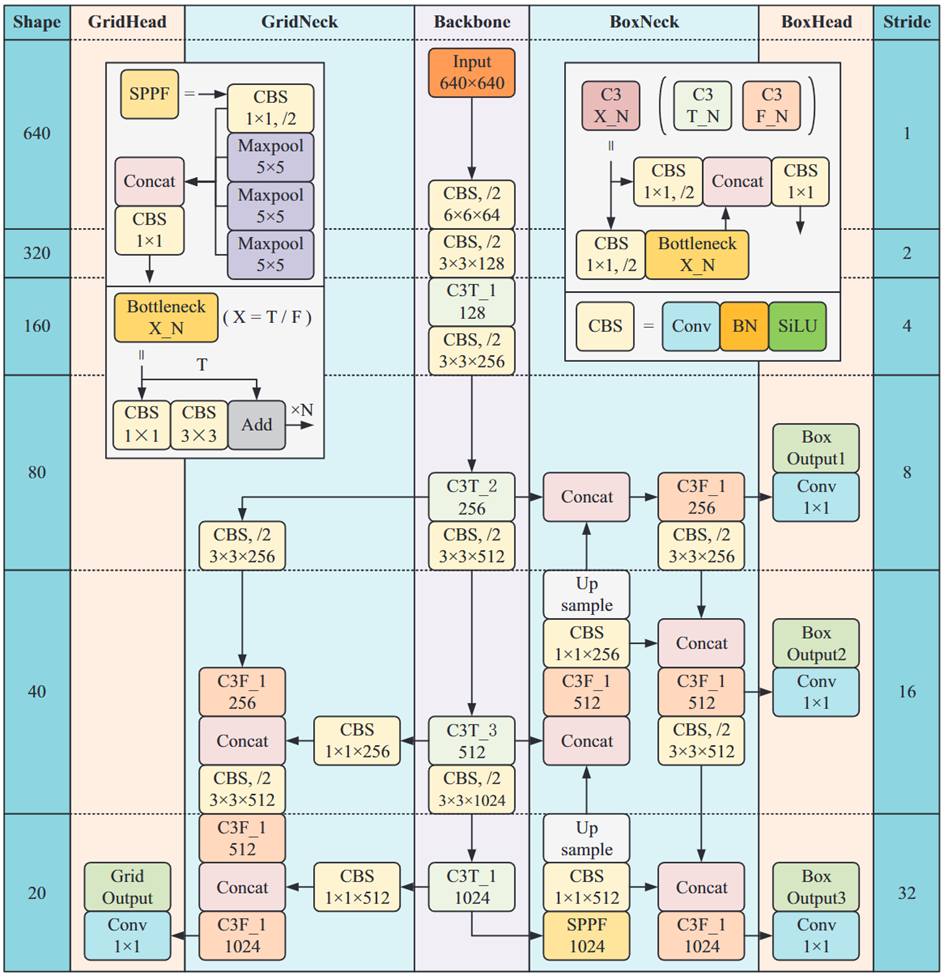
🧠整體的網絡結構非常清晰明了,一共就是四步,其中NMS-ARS和MaM是文章提出的后處理方法,分類頭和檢測頭共享骨干網絡的參數。
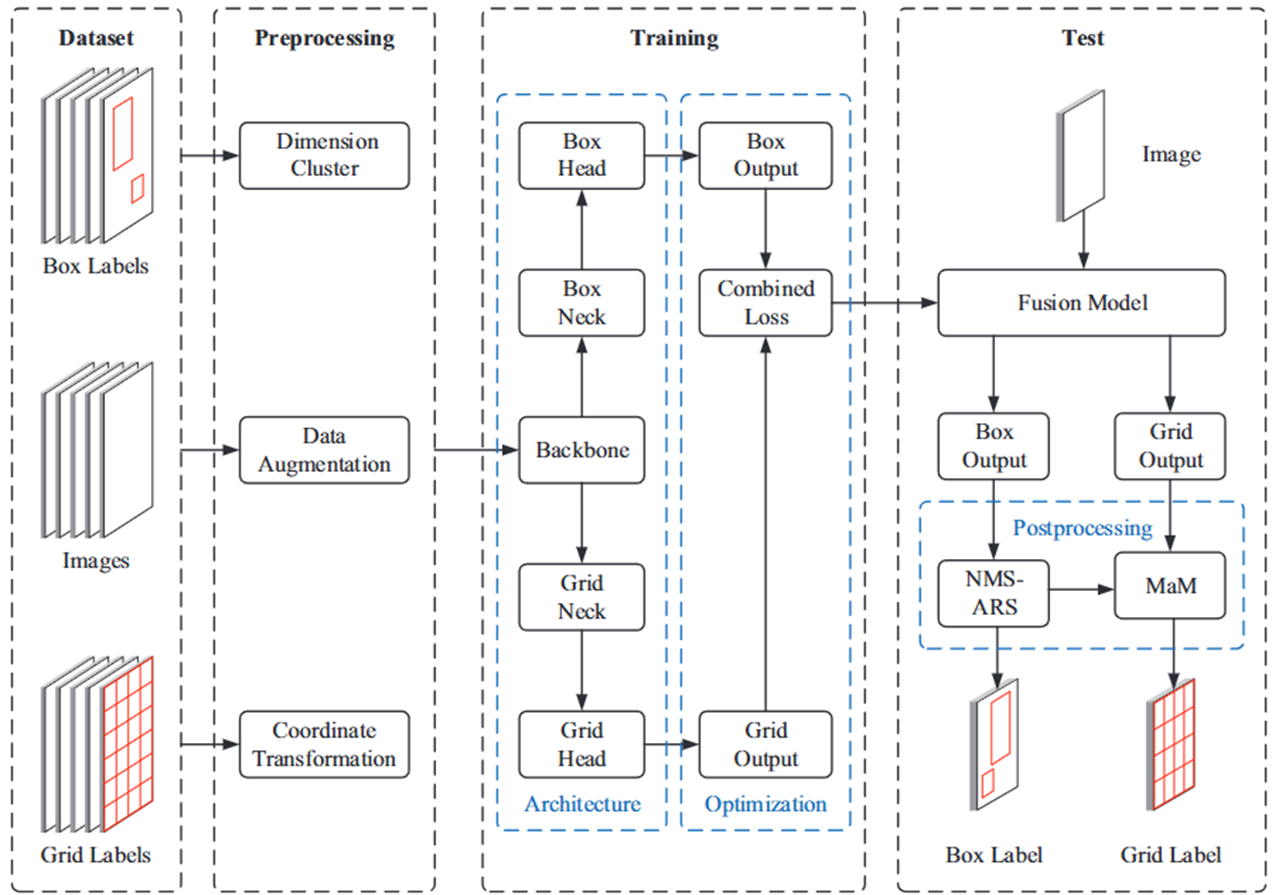 ?🔢關于數據集
?🔢關于數據集
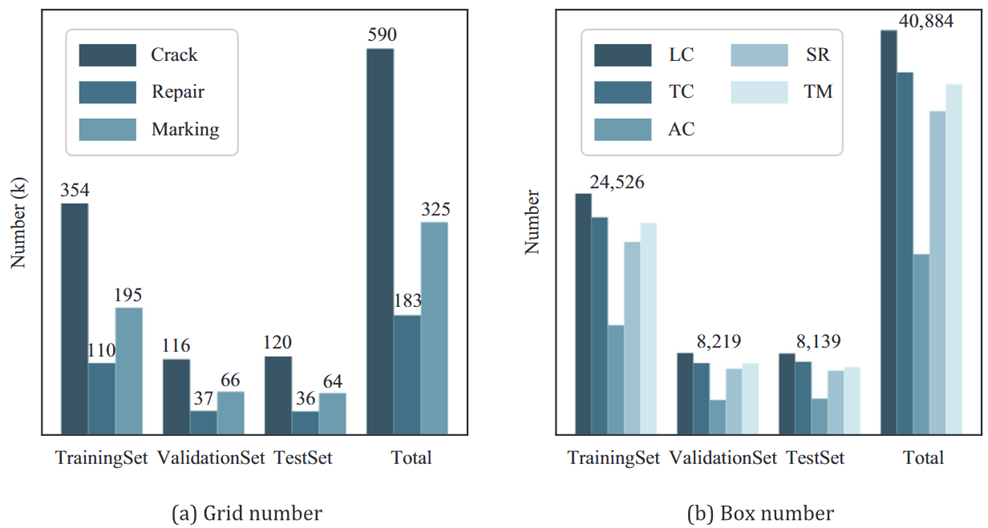
- 圖像大小為2048×2048,20000張,按6:2:2劃分
- 在自上而下的相機視圖中,地面采樣距離約為1毫米
- 圖像來自北京、湖南、廣東、新疆
- 包含多個復雜的場景(如樹葉、沙子、水、陰影)
- 所有圖像都使用所提出的融合模型的雙重方法進行注釋
- 基于網格的方法將圖像分為20 × 20個單元格,那么對于2048*2048大小的圖像來說的話每個單元格就是102.4*102.4像素的,resize到640*640每個單元格就是32*32像素的
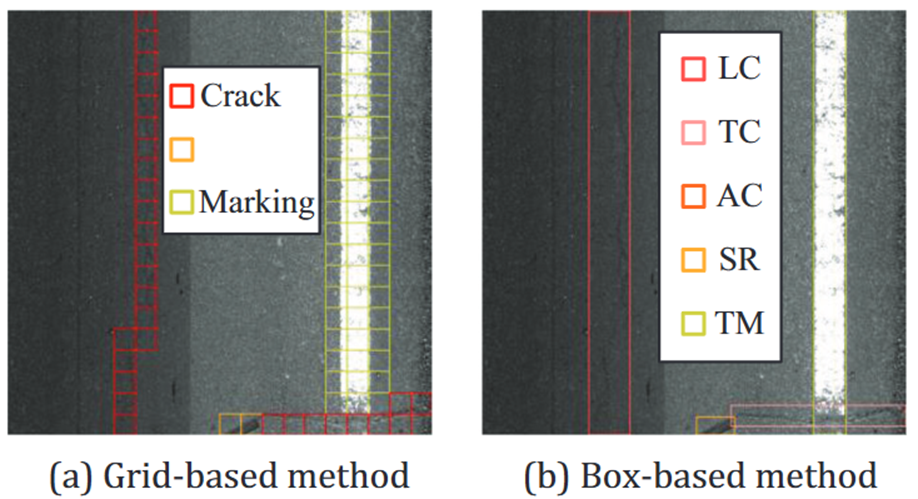
🔔grid和box標注的規范

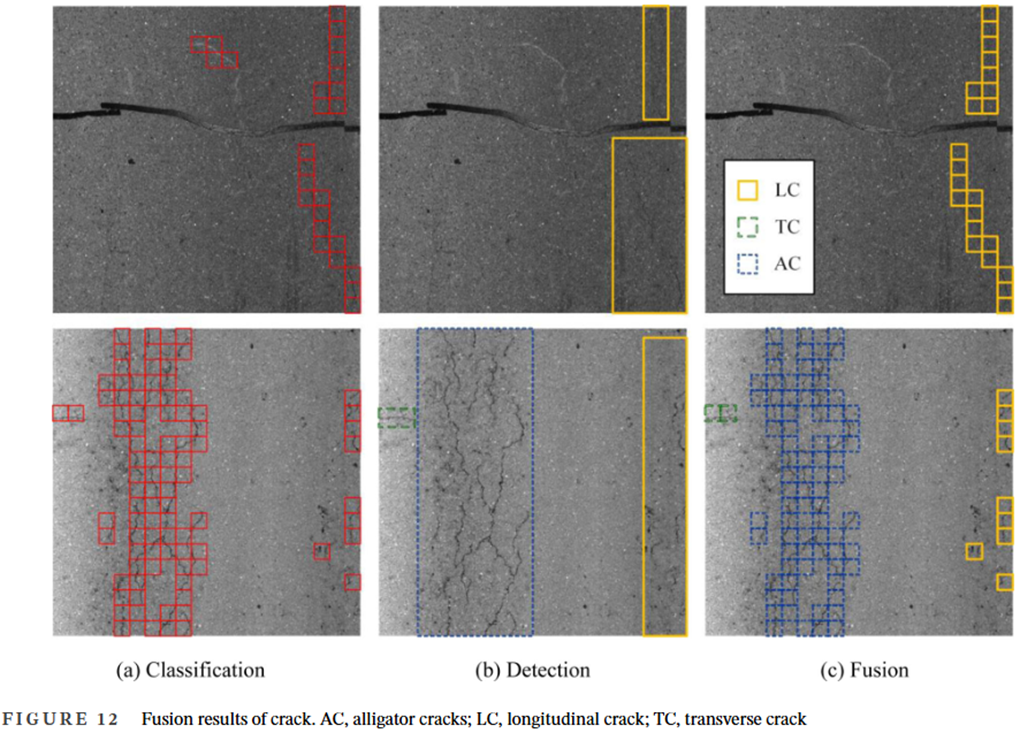
🔁左圖中橙色是修補Repair,LC是縱向裂縫,TC是橫向裂縫,AC是龜裂,SR是條狀修補,TM就是交通標線了,就是道路上的那兩條白色線條

💡Preprocessing-Data Augmentation?
- 將圖像調整為640×640,像素值在0到1之間進行歸一化
- 圖像增強僅在水平和垂直翻轉,概率為50%
- 色調、飽和度和值 (HSV) 顏色空間中的 H、S 和 V 通道中添加擾動來執行顏色抖動
- 路面裂縫圖像的色調相對單一,而飽和度和值隨環境因素(如光照)顯著變化。因此,色調H的干擾系數較小(0.015), 但飽和度S和值V較大(分別為 0.7 和 0.4)
- Mosaic增強用于通過四個圖像來豐富上下文
- 不能使用翻轉,這樣的話會混淆TC和LC的

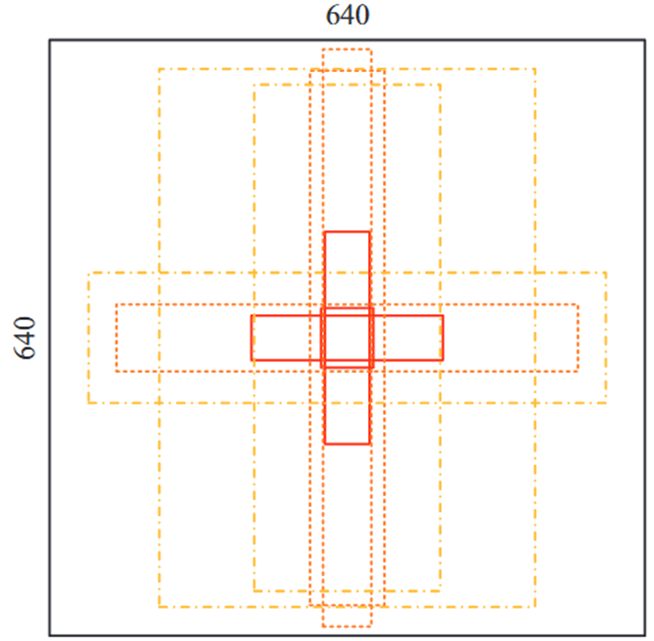
?💡Preprocessing-Dimension Cluster
- 采用K-Means聚類和遺傳算法生成自適應錨點
- anchor box影響預測框的規模和質量
- p在 1000 代進化錨點后,錨點的大小為 (53, 65)、(206, 48)、(49, 228)、(52, 621)、(496, 73)、(80, 576)、(55, 141)、(201, 543) 和 (405, 577),最好的可能召回率為 99.3%,也就是說可以使用上述錨點檢測到最多 99.3% 的對象
?💡Preprocessing-Coordinate Transformation
? ? ? ?🥇這一步就是將網格標簽和檢測標簽建立在同一坐標系上,換句話說就是,網格標簽也采用目標檢測的標簽形式,只不過網格的類別用負數標記,從-1開始。?
3 0.797297 0.350000 0.405405 0.100000
-4 0.851351 0.325000 0.027027 0.050000
-4 0.878378 0.325000 0.027027 0.050000
-4 0.905405 0.325000 0.027027 0.050000
-4 0.932432 0.325000 0.027027 0.050000
-4 0.959459 0.325000 0.027027 0.050000
-4 0.986486 0.325000 0.027027 0.050000
-4 0.608108 0.375000 0.027027 0.050000
-4 0.635135 0.375000 0.027027 0.050000
-4 0.662162 0.375000 0.027027 0.050000
-4 0.689189 0.375000 0.027027 0.050000
-4 0.716216 0.375000 0.027027 0.050000
-4 0.743243 0.375000 0.027027 0.050000
-4 0.770270 0.375000 0.027027 0.050000
-4 0.797297 0.375000 0.027027 0.050000
-4 0.824324 0.375000 0.027027 0.050000
-4 0.851351 0.375000 0.027027 0.050000?
🧶Training
- 共享骨干網絡聯合訓練的多視覺任務模型
- 骨干網絡提取高維深度特征
- 網絡分類分支和標框檢測分支分別整合微觀和宏觀特征
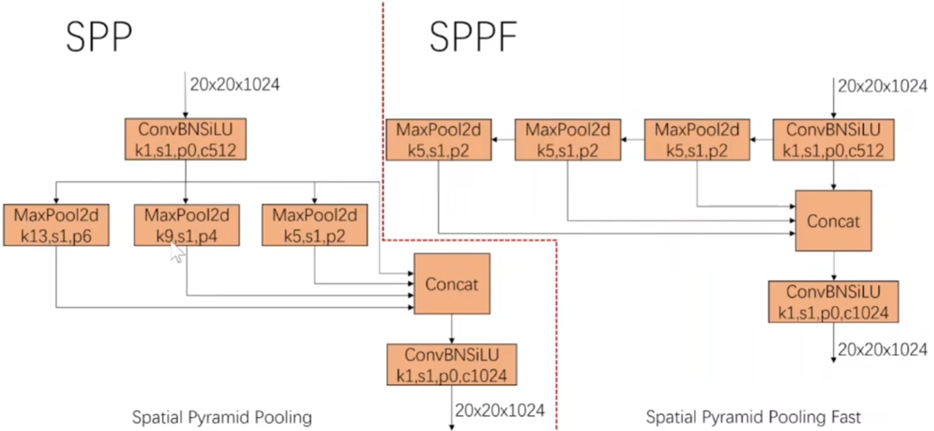
CBS: Conv、BN、sigmoid linear unit(SiLU)對圖像進行五次下采用,最終的特征圖大小是20×20
C3T塊由三個卷積塊和一個瓶頸T_N塊組成,集成了特征映射,消耗的計算資源更少
🎨loss function?

🧱網格和框損失函數的分配系數是0.2,也就是α是0.2,這可以設置為一個超參數。
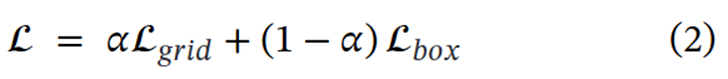
? ? ? ?在進行計算損失的時候,box就按照BBR的損失正常計算就行,grid是先將真實標簽的box轉換為grid網格的形式,用一個常數標記,比如1。基于grid的分類方法可以一次性對一幅圖像上的所有網格單元進行分類。
? ? ? ?📝grid的預測值是一個思維張量,形狀為[B,C,H,W],B就是batch size,C是grid的類別數,H和W是特征圖的高寬。預測張量中的每個值表示對應位置的grid單元屬于特定類別的概率(經過sigmoid激活后)。
🎨超參數
- 模型采用遷移學習和多任務學習。檢測網絡在COCO數據集中的常見對象上進行了預訓練
- 分類網絡和檢測網絡聯合訓練小批量大小為 64
- 100 個 epoch
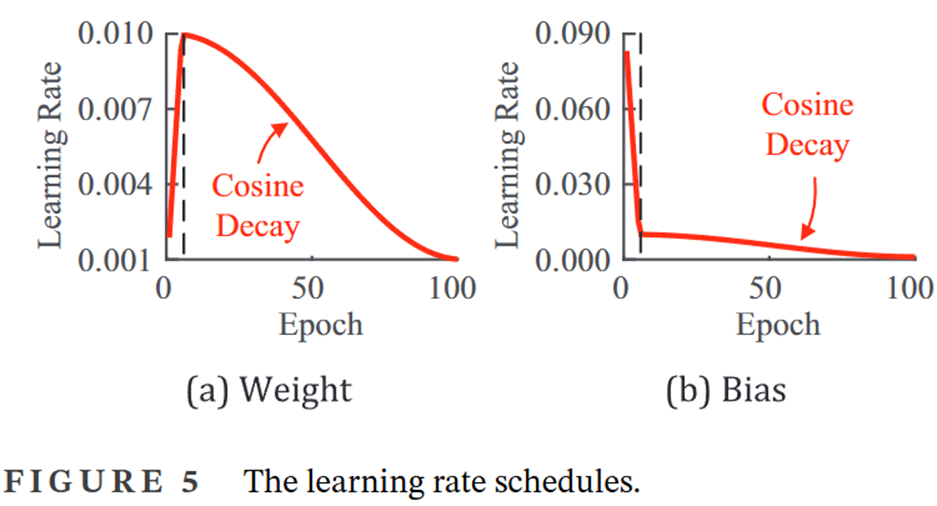
- SGD優化器,學習率是0.01,動量為0.9
- Weight decay為0.0005,學習率采用warm-up和cosine decay
?Postprocessing-ARS
? ? ? ?NMS 以高置信度提出了三個預測框 A、B 和C。任意兩個框之間的空隙低于通常的閾值,因此預測的裂紋被計數兩次。如果IoU值過低,其他裂紋將被錯誤地過濾掉。
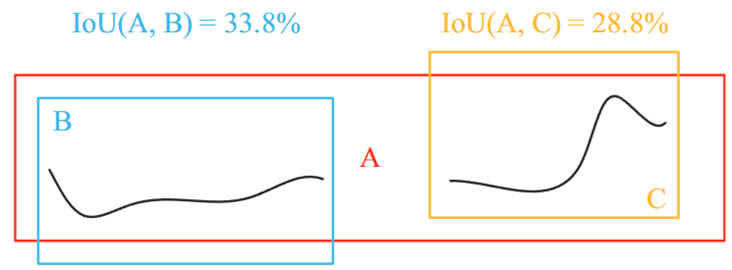
- 針對裂縫自相似性等分形幾何拓撲結構,模型改進了標框目標檢測后處理的NMS算法
- 提出一種面積減少抑制(ARS)增強NMS,保留高置信度的預測框,抑制具有高重疊區域的預測框的置信度
- 先要進行NMS,后再進行ARS


# prediction是經過NMS處理以后預測框的Tensor
def ras(self, prediction):ars_threshold = 0.5 # ars的閾值imgs = 640 # 輸入圖像resize大小output = [torch.zeros((0, 6), device=prediction[0].device)] * len(prediction)for xi, x in enumerate(prediction):n = x.shape[0]_, order = torch.sort(x[:, 4])x = x[order]classes = x[:, 5:6].clone()classes[(classes == torch.tensor(self.crack_classes, device=x.device)).any(1)] = self.crack_classes[0]bias = classes * imgs boxes = x[:, :4] + biasioa = box_ioa(boxes, boxes)mask = torch.arange(n).repeat(n, 1) <= torch.arange(n).view(-1, 1) # mask low conf boxesioa[mask] = 0x = x[ioa.sum(1) < ars_threshold ]output[xi] = xreturn outputdef box_ioa(box1, box2):area = (box1[:, 2] - box1[:, 0]) * (box1[:, 3] - box1[:, 1])return inter(box1, box2) / area.view(-1, 1) ?Postprocessing-MaM
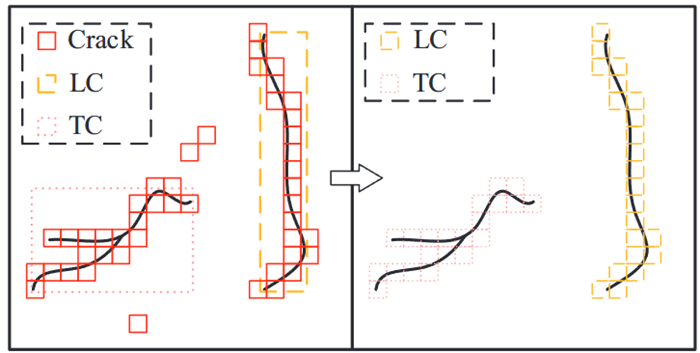
- 提出了MaM來過濾噪聲并確定每個網格單元中捕獲的裂紋類型
- 將檢測盒外的單元格作為噪聲濾除,將檢測盒內的單元格分類為相應的類

- 第一步計算單元格和所有框之間的IoA,如果最大值為零,則該單元格是噪聲過濾。否則,為單元格分配與網格最大值對應的box類
- 當網格和多個方框的IoA變量同時達到最大值時,按照AC優先級最高、LC優先級最低的原則確定單元格的類別
# ratio 列表用于存儲原始圖像與預處理后(調整大小和填充后的)圖像之間的寬高比
# class_grid2box 這個就是grid類別要匹配的box類別
class_grid2box = {0: (0,), 1: (1,), 2: (2,), 3: (3,)}
for i, (d, g, r) in enumerate(zip(box_pred, grid_pred, ratio)):d[:, :4:2] *= r[0]d[:, 1:4:2] *= r[1]g[:, :4:2] *= r[0]g[:, 1:4:2] *= r[1]g_class = g[:, 5]# change crack classesnew_g = []for gc, v in class_grid2box.items():for bc in v:g_tmp = g[g_class == gc].clone()g_tmp[:, 5:] = bcnew_g.append(g_tmp)g = torch.cat(new_g)if g.numel() > 0 and self.match:d_class = d[:, 5:]d_boxes = d[:, :4] + d_class * 4096g_boxes = g[:, :4] + g[:, 5:] * 4096iou = box_ioa(g_boxes, d_boxes)index = iou.max(1)[0] > 0 if d.numel() > 0 else torch.zeros(g.shape[0], device=self.device).bool()g = g[index]box_pred[i] = dgrid_pred[i] = g🥯Results
- 使用兩張內存為80G的NVIDIA A100顯卡
- 在測試集上驗證了GCBD模型的有效性
中的mAP是grid分類的指標,
是box檢測的指標,考慮到分類和檢測任務的學習難度,mAP與mAP50的比例為1:9。這里的
取值為0.1。
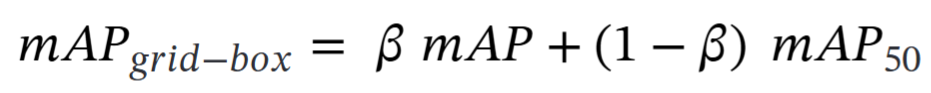
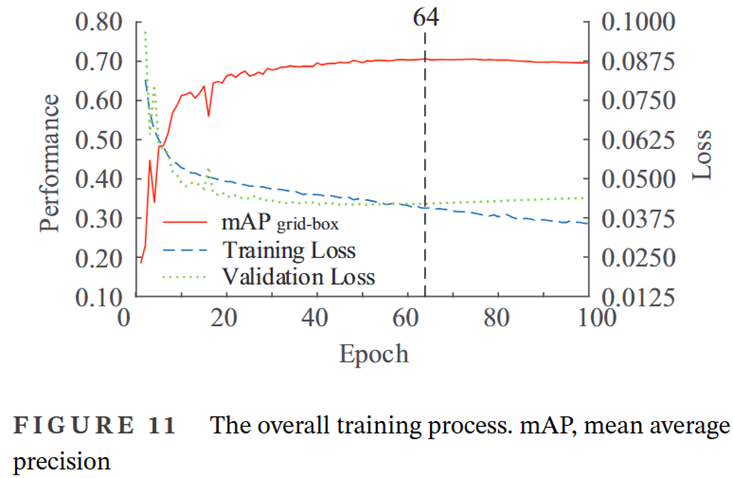
- 對于分類來說,最大F1分數的置信度超過0.8,并且相對接近
- 過擬合階段的網絡主要關注了學習置信度
- 分類混淆矩陣中分別有28%、9%和4%的裂紋、修復和標記與背景沒有區別
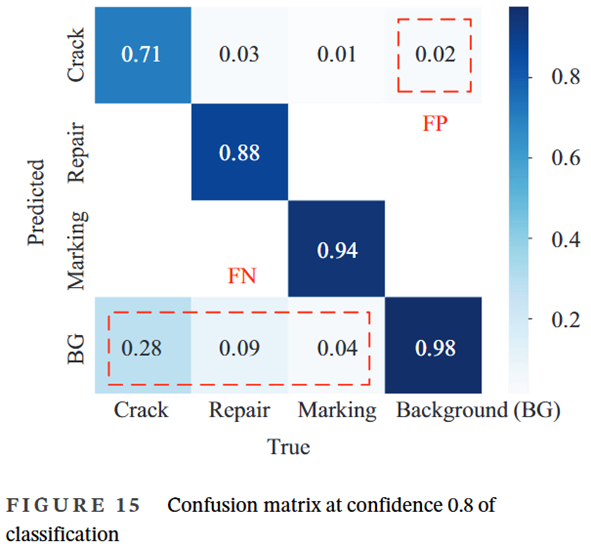
- 對于檢測來說,所有類別的最高F1分數表明置信度較低
- 從背景中分別錯誤地檢測到0.31的LC和0.28的TC,這表明線性裂紋的特征與背景相似。需要一個強大的特征提取網絡來解決這個問題
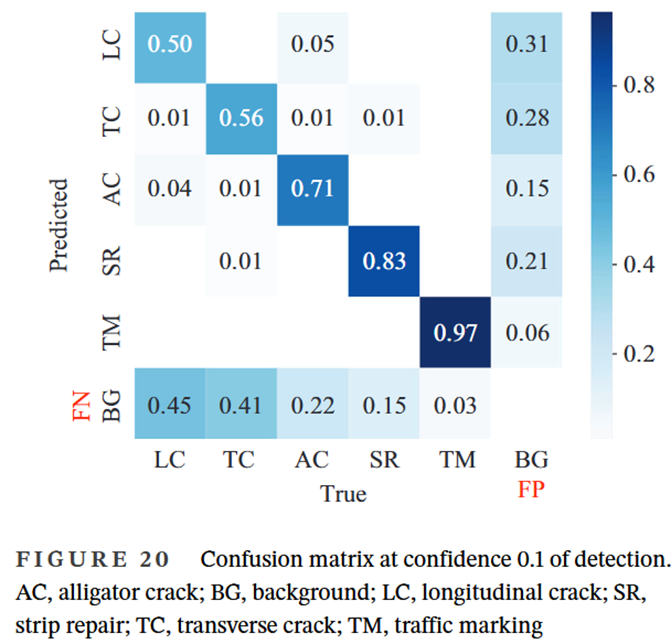
分析聯合損失函數下圖像分類和目標檢測的分配系數,結果表明多視覺任務學習具有較強的魯棒性,在保證精度不損失甚至略微增長的前提下有效提高裂縫識別的效率?
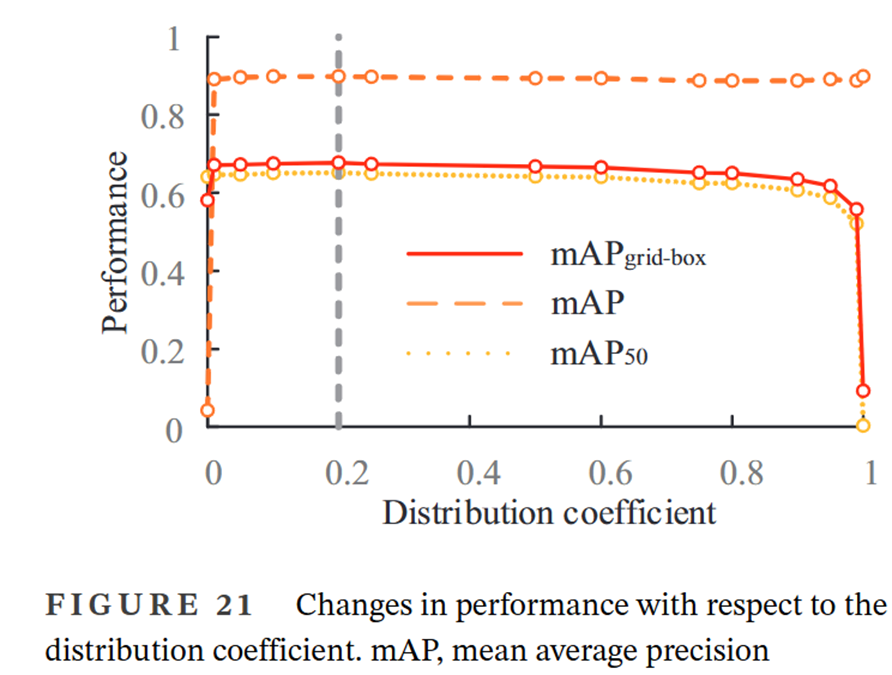
改進的NMS能夠有效過濾目標檢測的冗余預測框,改進模型性能,并且緩解不同非極大值抑制算法之間的差距?
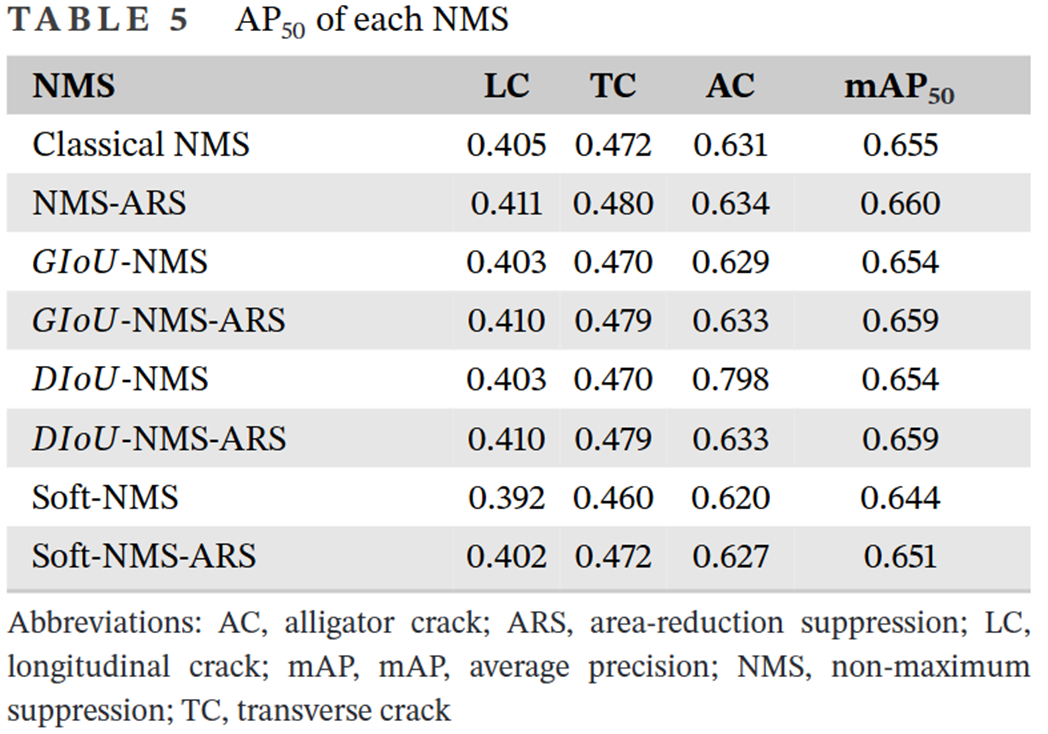
- 基于網格的分類網絡的性能高于基于補丁的分類
- 基于網格的分類方法具有較大的感受野,可以使用帶有注釋裂紋的數據集來訓練直接識別不同類型裂紋的分類網絡
- 檢測網絡有效地對裂紋進行分類和定位。在裂縫中,AC最容易識別,而LC最難識別
- 多任務學習和聯合訓練提高了路面裂縫識別的準確性
- NMS-ARS考慮了裂縫拓撲結構,有效地過濾了冗余的預測框
🔦但是對于一個非常細小的裂縫進行檢測和分類依舊有些困難,再者就是橫向裂縫和縱向裂縫的判斷也應該還有另外一個標準!!!?
)


)
)







![[低代碼 + AI] 明道云與 Dify 的三種融合實踐方式詳解](http://pic.xiahunao.cn/[低代碼 + AI] 明道云與 Dify 的三種融合實踐方式詳解)

![[人機交互]理解與概念化交互](http://pic.xiahunao.cn/[人機交互]理解與概念化交互)

:動態字段、可歸零和默認值)

)
)