文章目錄
- 前言
- 1.Flink系統架構
- 2.編程模型(API層次結構)
- 3.DataSet和DataStream區別
- 4.Flink的批流統一
- 5.Flink的狀態后端
- 6.Flink有哪些狀態類型
- 7.Flink并行度
前言
提示:下面是根據網絡或AI整理:
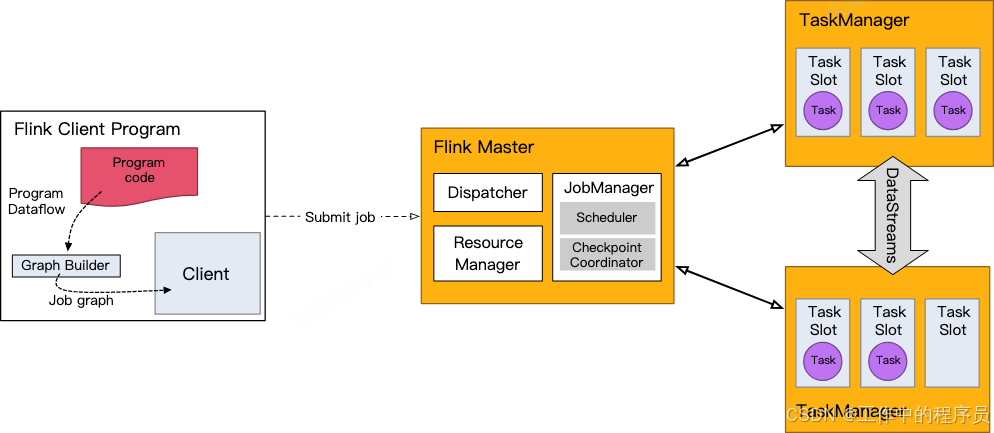
1.Flink系統架構
- 用戶在客戶端提交作業(Job)到服務端。
- 服務端為分布式的主從架構。
- Dispatcher 服務負責提供 REST 接口來接收 Client 提交的 Job,運行 Web UI,并負責啟動和派發 Job 給 JobManager。
- Resource Manager 負責計算資源(TaskManager)的管理,其調度單位是 slots。
- JobManager 負責整個集群的任務管理、資源管理、協調應用程序的分布執行,將任務調度到 TaskManager 執行、檢查點(checkpoint)的創建等工作。
- TaskManager(worker)負責 SubTask 的實際執行,提供一定數量的 Slots,Slots 數就是 TM 可以并發執行的task數。當服務端的 JobManager 接收到一個 Job 后,會按照各個算子的并發度將 Job 拆分成多個 SubTask,并分配到 TaskManager 的 Slot 上執行。
2.編程模型(API層次結構)
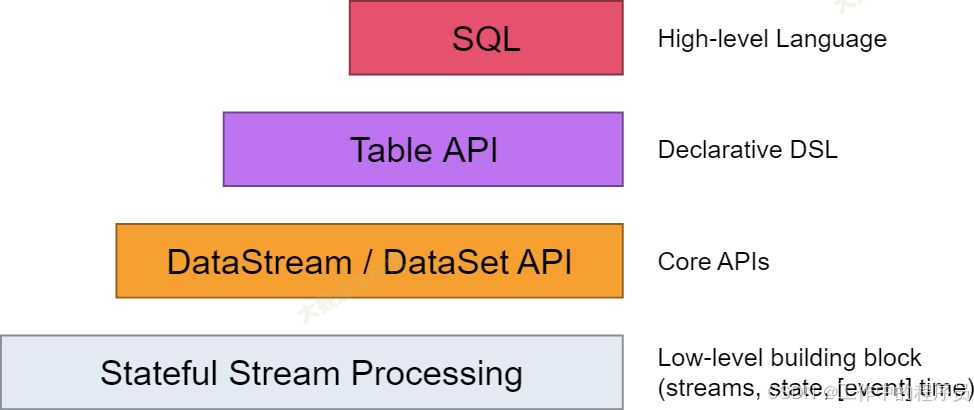
- 最底層提供了有狀態流:可以自定義狀態信息和處理邏輯,但是也需要你自己管理狀態的生命周期,容錯,一致性等問題。
- 核心開發層:包括 DataStream API 和 DataSet API,它們提供了常見的數據轉換,分組,聚合,窗口,狀態等操作。這個層級的 api 適合大多數的流式和批式處理的場景。
- 聲明式 DSL 層:是以表為中心的聲明式 DSL,其中表可能會動態變化(在表達流數據時)。Table API 提供了例如 select、project、join、group-by、aggregate 等操作
- 結構化層:SQL API,它是最高層的 api,可以直接使用 SQL 語句進行數據處理,無需編寫 Java 或 Scala 代碼。這個層級的 api 適合需要快速響應業務需求,縮短上線周期,代碼可移植性和可閱讀性高,和自動調優的場景,但也最不靈活和最不具有表現力。
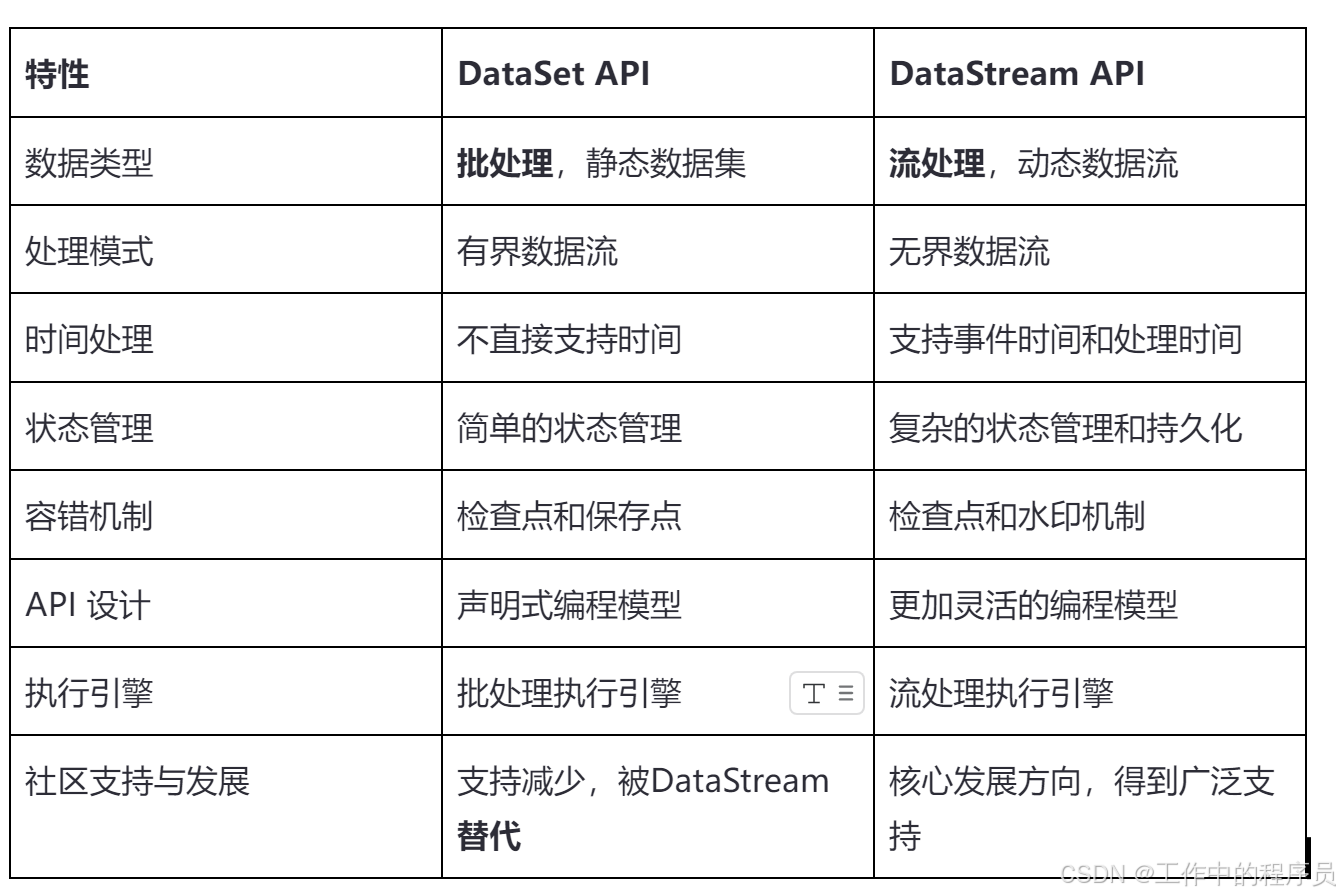
3.DataSet和DataStream區別
4.Flink的批流統一
概念: 批流統一是指Flink提供了一種統一的API和執行引擎,使得批處理(Batch Processing)和流處理(Stream Processing)可以使用相同的API進行編程,并且共享相同的執行計劃和優化策略。這一特性簡化了開發流程,減少了代碼重復,同時提高了系統的靈活性和性能(一套代碼處理流或批數據)。
體現在以下幾個方面:
- 統一的API:無論是處理有限的數據集(批處理)還是無限的數據流(流處理),開發者都可以使用同一套API進行編程。
- 統一的執行引擎:Flink的執行引擎能夠自動識別輸入數據是批數據還是流數據,并選擇合適的執行模式。
- 統一的狀態

)















)

