java使用CMU sphinx語音識別
- 一、pom依賴
- 1、依賴dependency
- 2、配置倉庫repository
- 二、下載中文資源包
- 1、下載中文資源包(需要其他語言的選擇對應的文件夾即可),中文選擇Mandarin
- 2、將下載后的文件放到項目中
- 3、代碼-識別wav語音文件
- 4、代碼-識別實時輸入(本地pc未成功)
- 4.1 測試端需要有語音輸入設備
一、pom依賴
1、依賴dependency
<!-- CMUSphinx Core Library --><dependency><groupId>edu.cmu.sphinx</groupId><artifactId>sphinx4-core</artifactId><version>5prealpha-SNAPSHOT</version></dependency><!-- CMUSphinx Data Library --><dependency><groupId>edu.cmu.sphinx</groupId><artifactId>sphinx4-data</artifactId><version>5prealpha-SNAPSHOT</version></dependency>
2、配置倉庫repository
<repository><id>snapshots-repo</id><url>https://oss.sonatype.org/content/repositories/snapshots</url><releases><enabled>false</enabled></releases><snapshots><enabled>true</enabled></snapshots></repository>
二、下載中文資源包
進入sourceforge網站下載
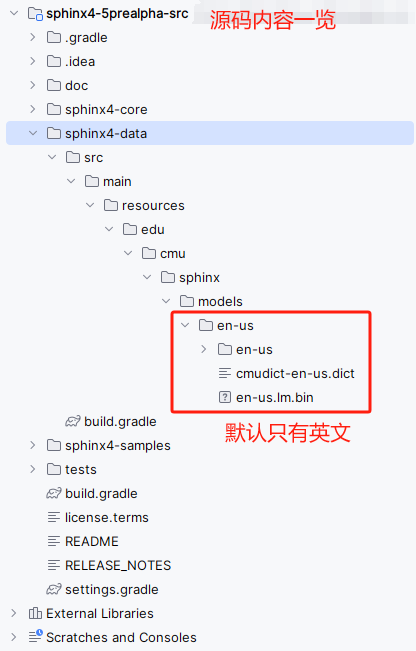
點擊菜單Files,其中Acoustic and Language Models是語言資源包文件夾,下面還有sphinx不同版本的源碼,源碼中默認只包含英文資源包。
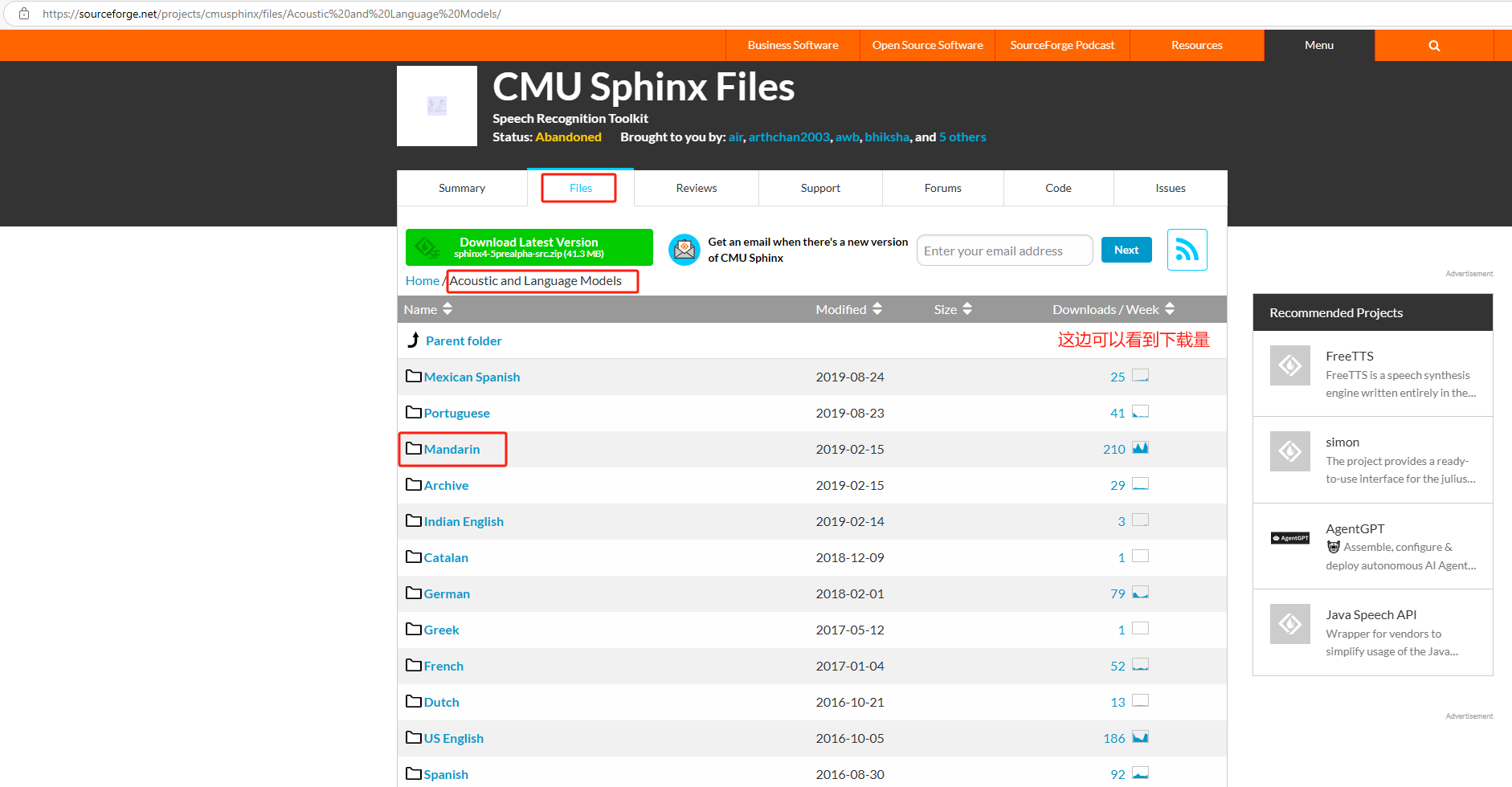
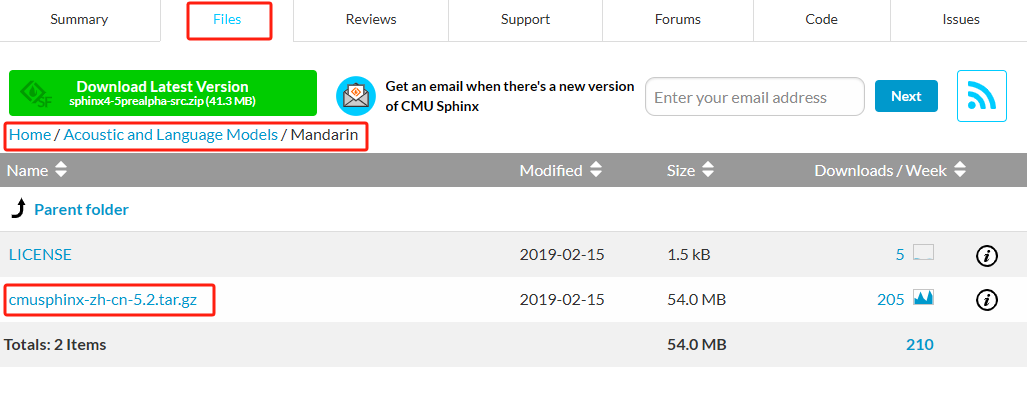
1、下載中文資源包(需要其他語言的選擇對應的文件夾即可),中文選擇Mandarin
2、將下載后的文件放到項目中
解壓后的文件
3、代碼-識別wav語音文件
好像只能識別wav格式的文件,m4a試了不行,可以自行嘗試看下結果
public static void speechToTxt2() throws Exception {// 1、配置Configuration conf = new Configuration();conf.setAcousticModelPath("resource:/sphinx/zh/zh_cn.cd_cont_5000");conf.setDictionaryPath("resource:/sphinx/zh/zh_cn.dic");conf.setLanguageModelPath("resource:/sphinx/zh/zh_cn.lm.bin");System.out.println("Loading models...");// conf.setAcousticModelPath("resource:/edu/cmu/sphinx/models/en-us/en-us");
// conf.setDictionaryPath("resource:/edu/cmu/sphinx/models/en-us/cmudict-en-us.dict");Context context = new Context(conf);context.setLocalProperty("decoder->searchManager", "allphoneSearchManager");Recognizer recognizer = context.getInstance(Recognizer.class);InputStream stream = ParseUtil.class.getResourceAsStream("/sphinx/wav/2.wav");stream.skip(44);// Simple recognition with generic modelrecognizer.allocate();context.setSpeechSource(stream, TimeFrame.INFINITE);Result result;while ((result = recognizer.recognize()) != null) {SpeechResult speechResult = new SpeechResult(result);System.out.format("Hypothesis: %s\n", speechResult.getHypothesis());System.out.println("List of recognized words and their times:");for (WordResult r : speechResult.getWords()) {System.out.println(r);}// System.out.println("Lattice contains "
// + speechResult.getLattice().getNodes().size() + " nodes");}recognizer.deallocate();}
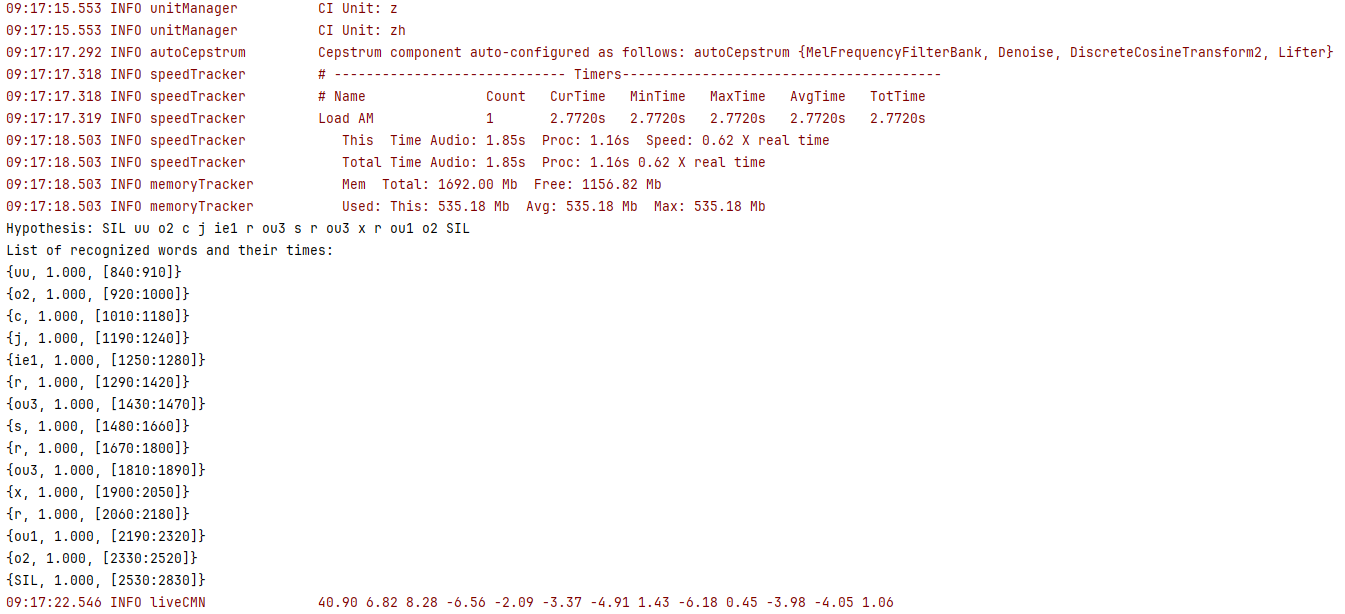
輸出結果如圖
其中 Hypothesis: SIL uu o2 c j ie1 r ou3 s r ou3 x r ou1 o2 SIL 就是需要訓練的內容。
我們下載的資源文件zh_cn.dic中有已經簡單訓練的結果
4、代碼-識別實時輸入(本地pc未成功)
調用時,系統能檢測到在使用麥克風。但在recognizer.getResult()這行總是會報溢出錯誤,也有可能是輸入的設備不支持,各位可以自行嘗試。有結果可以評論學習一下,感謝。
public static void speechToTxt() throws Exception {// 1、配置Configuration conf = new Configuration();conf.setAcousticModelPath("resource:/sphinx/zh/zh_cn.cd_cont_5000");conf.setDictionaryPath("resource:/sphinx/zh/zh_cn.dic");conf.setLanguageModelPath("resource:/sphinx/zh/zh_cn.lm.bin");// 2、語音識別器LiveSpeechRecognizer recognizer = new LiveSpeechRecognizer(conf);// 2.1 開始識別recognizer.startRecognition(true);// 2.2 識別結果SpeechResult result;while ((result = recognizer.getResult()) != null) {System.out.println(result.getHypothesis());}// 2.3 停止識別recognizer.stopRecognition();}
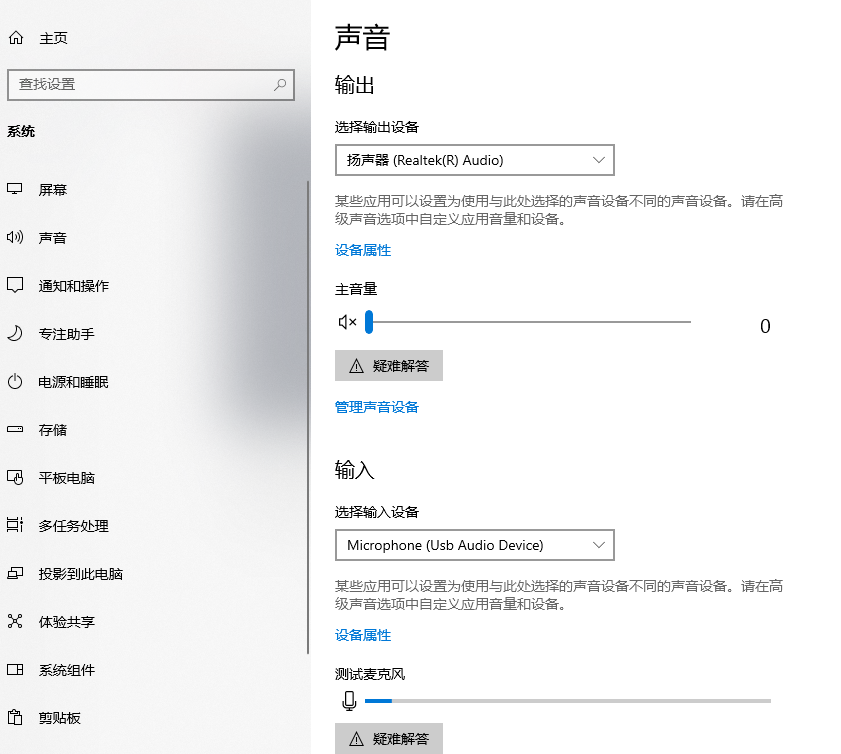
4.1 測試端需要有語音輸入設備
設置-系統-聲音-輸入,輸入配置中需要有輸入設備,測試麥克風可以查看此設備是否可用

)

:股票價格模型、利率模型的構建)
:MCP多服務器協作架構)

![[算法學習]——通過RMQ與dfs序實現O(1)求LCA(含封裝板子)](http://pic.xiahunao.cn/[算法學習]——通過RMQ與dfs序實現O(1)求LCA(含封裝板子))

)



顯示模式設置)


)

內部RTC實時時鐘及實戰含源碼)

