引入:unordered_set /map是什么?
庫里面除開set和map,還有unordered_set 和?unordered_map,區別在于:
①:set和map的底層結構是紅黑樹,而unordered_set和unordered_map的底層是哈希表
②:unordered_set和unordered_map迭代器遍歷出來的結果是無序的,這也是為什么前綴是unordered(譯為無序?)
一:哈希是什么?
1:理解哈希和哈希表的區別
哈希是一種思想,而哈希表是通過這種思想創建的數據結構
就好比:左子樹小于根節點,右子樹大于根節點,而紅黑樹則是基于這種思想構建的一種數據結構
2:哈希的概念
那么哈希是一種怎么樣的思想?
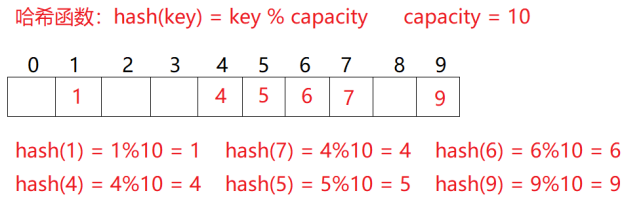
3:哈希沖突
既然有哈希沖突,那肯定就有解決的方法~
4:哈希沖突的解決方法
解決哈希沖突兩種常見的方法是:閉散列和開散列
閉散列:
開散列:
5:哈希表的結構
template<class K, class V, class Hash = HashFunc<K>>class HashTable{public://哈希表的構造函數 默認大小為10HashTable(size_t size = 10){_tables.resize(size);}//.....各種函數private://哈希表需要一個vector和一個反映實際存儲的數據個數nvector<HashData<K, V>> _tables;size_t _n = 0; // 實際存儲的數據個數};
解釋:
這里只用先知道哈希表是在vector的基礎上的數據結構 ,外加一個n(實際存儲的元素個數)
二:閉散列的實現(開放定址法)
1:閉散列概念

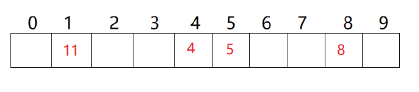 ?
?
此時再插入15, 本來應該放在下標為5的位置,但是由于被占了(哈希沖突),所以就要放到下一個空位置去,也就是如下所示,放到了下標為6的位置

此時再插入6,由于哈希沖突,所以6放在了7的位置,如下所示:
 以上就是閉散列的思路。
以上就是閉散列的思路。
2:總結閉散列的思路
插入時:
i = key %表的大小
如果i位置已經有值了,就線性往后走找到空位置,放進去
查找時:
i = key %表的大小
如果i為不是要查找的key就線性往后查找,直到找到或者遇到空(空代表該值不在哈希表內)
注意:
這種行為(當插入或查找數據時,如果哈希函數計算出的目標位置已被占用(發生沖突),就順序向后探測(一次走一步),直到找到下一個空位置為止。)叫作線性探測~
思路理解起來很簡單,但是需要完善很多細節!
3:負載因子
Q①:vector全部插滿了,效率會怎么樣?
Q②:空位置一定會有嗎?
A①②:vector全部插滿了,效率嚴重下降,比如查找一個值,從哈希函數計算得到的下標開始找,結果發現它存放在了該下標的前一個位置,我們的線性探測只能老老實實的找完所有的數據,此時的時間復雜度為O(N);并且插滿了空位置就沒有了。
所以我們需要一個東西:負載因子
負載因子:插入到哈希表中的元素個數 / 哈希表的長度

比如上圖,負載因子就是6/10 = 0.6;
C++中一般將負載因子設置為0.75,沒超過0.75代表可以繼續插入,反之超過了,則需要擴容
總結:負載因子讓哈希表變得高效!
4:狀態變量

問題①:假設先刪除15 再查找6 ?會出現找不到6的情況!
因為我們查找6,根據哈希函數得知,該從下標為6的位置開始找,結果6的位置就為空,按照線性探測的規矩,此時就代表找不到了,但是6在哈希表中
問題②:如何表示一個位置,本來就是空和是被刪除后的才變成的空
如果問題①中,我們知道了刪除15后,下標為6的位置是被刪除后才變成的空,那我們就能繼續往后找了
綜上所述:狀態變量即可解決!
vector中的每個位置可能的狀態:空,存在,刪除
空:代表該位置的空是因為沒有值,插入和查找遇到這種狀態,會停下
存在:代表該位置存有值
刪除:代表該位置是空,該空是因為原本存儲的值被刪除后形成的,插入和查找遇到這種狀態,不會停下
到此,閉散列的思路就講完了,將其轉換為代碼即可:
5:仿函數的必要性
我們要將pair類型中的K值,對應一個整形值。然后該整形值,再通過哈希函數,轉換得到哈希表中存儲的起始下標(叫起始,是因為有可能由于哈希沖突不存儲在這里)
Q1:K值不是整形值,而是字符串這種怎么轉換成整形?
A1:仿函數解決即可,不同的類型的K值,都可以自己寫對應的仿函數來讓這個K值得到一個對應的整形值
比如字符串"abcd",我們以一個該字符串的ascll碼值的和,去映射一個整形
Q2:這方法不還是會有哈希沖突嗎?比如"acbd"和"abcd"映射出的整形一樣啊!
A2:哈希沖突是不能避免的,我們只能用一種哈希函數來讓哈希沖突大大的降低~
大佬們創建了很多的優秀的哈希函數去降低哈希沖突,這里博主直接介紹最優秀的一種:BKDR!
BKDR哈希函數
BKDRHash?是一種簡單高效的字符串哈希算法,由?Brian Kernighan 和 Dennis Ritchie(即 C 語言經典的 K&R 著作作者)提出。它的核心思想是?“種子乘累加”,通過一個不斷擴大的種子值(通常取素數)來計算字符串的哈希值,有效減少沖突。
例子:
hash = 0
seed = 31 // 經典種子值,也可用 131, 1313, 13131...
for (char c in str) {hash = hash * seed + c
}
return hash關鍵點:
-
seed?的選擇:通常取?31、131、1313?等素數,目的是讓哈希值分布更均勻。 -
逐字符累加:每個字符的 ASCII 值(或 Unicode 值)都會影響最終的哈希值。
6:閉散列代碼及其剖析
1:仿函數的實現
template<class K>
//仿函數 用于得到kv對應的哈希值
//默認的是能直接轉換成整形值的 比如int 地址 指針 這種
struct HashFunc
{size_t operator()(const K& key){return (size_t)key;}
};//特化
//string比較通用,所以特化
//采取DKBR
//使用循環遍歷字符串中的每個字符e。
//將字符的ASCII值加到hash上,然后乘以一個常數131。
template<>
struct HashFunc<string>
{size_t operator()(const string& s){size_t hash = 0;for (auto e : s){hash += e;hash *= 131;}return hash;}
};解釋:
Q:為什么把K值為字符串的單獨拿出來進行特化?
A:因為pair類型的K值為字符串的場景實在是太多,太常見了,所以進行特化;而且庫中也是如此做的,所以我們用庫中的unordered_set去對K值為字符串的類型進行操作的時候,也不用自己寫對應的仿函數,因為庫已經對其進行了特化
總結:
我們對能夠自動轉換為整形的類型和字符串轉換為整形的類型進行了實現,第一個仿函數就是面對本身就是int,size_t,指針,地址,這種能直接映射一個整形值的類型
2:狀態變量的實現
//表示一個位置的狀態enum State{EMPTY,//空EXIST,//存在DELETE//刪除};解釋:
使用?enum?定義槽位狀態(EMPTY、EXIST、DELETE)的好處:
a:直接用?EXIST、EMPTY、DELETE?等命名取代數字(如?0、1、2),避免含義不明確,降低理解成本。
if (state == EMPTY) // 直觀
vs
if (state == 0) // 需查文檔或注釋b:調試友好
調試時直接顯示狀態名(如?EXIST),而非數字,快速定位問題。
3:哈希表的框架
//閉散列 也叫開放定址法//參數除開kv 還有一個仿函數類用于讓k值對應一個整形值template<class K, class V, class Hash = HashFunc<K>>class HashTable{public://哈希表的構造函數 默認大小為10HashTable(size_t size = 10){_tables.resize(size);}private://哈希表需要一個vector和一個反映實際存儲的數據個數nvector<HashData<K, V>> _tables;size_t _n = 0; // 實際存儲的數據個數};解釋:
Q1:哈希表初始化大小為10的好處?
A1:算插入數據的下標的時候 去模上size(),其為0怎么辦?hashTable中的構造直接先給10個空間 這樣szie不會為0了
Q2:成員變量n的意義?
A2:用于計算負載因子,n/哈希表的大小 == 負載因子
4:查找函數的實現
//查找函數->用于對用戶輸入的pair類型的值進行查找HashData<K, V>* Find(const K& key){//仿函數實例對象 用于得到kv對應的哈希值Hash hs;// 線性探測size_t hashi = hs(key) % _tables.size();//key值對應的整形模上空間大小,得到了存放 在vector中的初始查找位置的下標值hashi 但是由于線性探測 不一定就在該下標處//只要當前下標位置的狀態不是EMPTY,就繼續循環。//等于空代表查找失敗 返回nullptr//所以從下標到空的前一個 這段區級找到了就是有 找不到就是不存在while (_tables[hashi]._state != EMPTY){//檢查當前下標位置的鍵是否與要查找的鍵相等,并且狀態為EXIST(表示存在有效數據)。if (key == _tables[hashi]._kv.first&& _tables[hashi]._state == EXIST){return &_tables[hashi];//找到了}++hashi;//確保下標值不會超出哈希表的大小,使用模運算使其循環回到起始位置。//讓探測位置在超出哈希表末尾時循環回到開頭hashi %= _tables.size();}//如果循環結束仍未找到對應的鍵值對,表示哈希表中不存在該鍵,返回nullptr。return nullptr;}解釋:
①:Find函數就會用到仿函數了,因為我們函數接受到的K類型的key值,?此時我們不知道K類型是是什么類型,所以我們要用仿函數示例出的對象去觸發()的重載,得到其映射的整形值;當然,我們自己測試肯定使用一般的整形或者字符串,因為這兩種類型我們寫好了對應的仿函數
②:找的時候,我們不僅要找與函數參數中的key吻合的值,且該槽位的狀態應該是存在EXIST才行,滿足二者,才叫有效數據;因為我們刪除的時候,僅僅是將該槽位的狀態置為DELETE
Q:為什么刪除的時候,僅僅把該槽位的狀態置為DELETE,而不是真正的刪除置空?
A:這樣做的目的是?保持線性探測的連續性(避免因直接置為?EMPTY?導致后續鍵值對查找中斷)。
5:插入函數的實現
//插入函數bool Insert(const pair<K, V>& kv){//在插入之前,首先調用Find函數檢查kv是否已經存在于哈希表中。//如果存在,則不需要插入,直接返回false。if (Find(kv.first))return false;//來到這 則代表一定需要插入 先檢測是否需要擴容//檢查哈希表的負載因子//問題:負載因子為0.7,但是整數相除不可能為小數,也不可能剛好為0.7//以下兩個if都可以解決//if ((double)_n / (double)_tables.size() >= 0.7)->強轉一個分數的類型為double ,然后>=0.7if (_n * 10 / _tables.size() >= 7)//->某個分數*10 就不用強轉了{//創建一個新的哈希表對象newHT 大小是原表的兩倍//遍歷原哈希表中的所有元素,將狀態為EXIST的元素插入到新哈希表中//使用swap函數將新哈希表的表與原哈希表的表交換,實現擴容HashTable<K, V, Hash> newHT(_tables.size() * 2);// 遍歷舊表,插入到新表for (auto& e : _tables){if (e._state == EXIST){newHT.Insert(e._kv);}}_tables.swap(newHT._tables);}//仿函數實例對象 用于得到kv對應的哈希值Hash hs;//線性探測去插入//使用仿函數hs計算鍵的哈希值,并取模得到初始插入位置hashi。//如果該位置已經存在元素(狀態為EXIST),則進行線性探測,即逐個檢查后續位置,直到找到空位置或刪除位置。size_t hashi = hs(kv.first) % _tables.size();while (_tables[hashi]._state == EXIST){++hashi;hashi %= _tables.size();//用于確保哈希索引 hashi 始終在哈希表的有效范圍內}//在找到的空位置或刪除位置插入鍵值對kv。將該位置的狀態設置為EXIST。增加哈希表中已存儲元素的數量_n。_tables[hashi]._kv = kv;_tables[hashi]._state = EXIST;++_n;return true;}解釋:
①:插入前的檢查
在插入之前,首先調用Find函數檢查kv是否已經存在于哈希表中;如果存在,則不需要插入,直接返回false。因為我們的unordered_set和set一樣,都是有著去重的效果的
②:負載因子計算的問題
Q:我們計算負載因子的時候,假設負載因子為0.7,但是整數相除不可能為小數,也不可能剛好為0.7,那怎么辦?
A:兩種方法
方法一:強轉一個分數的類型為double ,然后>=0.7
方法二:前面個分數*10 就不用強轉了(70/10==7)
③:擴容的本質
創建一個新的且是原本大小2倍的哈希表對象newHT(hashtable<k,v> ),然后從舊哈希表對象的_tables中讀取元素,若此元素的狀態是存在,則復用哈希表類的插入函數去插入到新的哈希表。最后再交換兩個哈希表中的vector成員變量!(說白了就是從舊的vector對象中讀取數據,插入到新的更大的vector對象)
該方法的好處:因為創建的是哈希表的新對象,所以自己復用自己的插入函數,不用再寫具體~
Q:那為什么不單純創建一個新的更大的vector對象,然后讀取舊的到新的,最后再把新的vector對象和哈希表中的vector對象交換
A:因為我們要復用插入函數,不用自己去寫去計算每個元素在新表中的位置,所以才采用者方法去創建新的哈希表對象
④:插入的邏輯
使用仿函數對象hs計算鍵的哈希值,并取模得到初始插入位置hashi;如果該位置已經存在元素(狀態為EXIST),則進行線性探測,即逐個檢查后續位置,直到找到空位置或刪除位置。
6:刪除函數的實現
//刪除函數bool Erase(const K& key){//調用查找函數Find來查找給定鍵的鍵值對。如果找到,Find函數返回指向該鍵值對的指針;如果未找到,返回nullptr。HashData<K, V>* ret = Find(key);if (ret){ //減少哈希表中已存儲元素的數量_n。 更改該槽位的狀態 返回true_n--;ret->_state = DELETE;return true;}else{return false;}}解釋:
先Find函數看一下在不在,在則改變槽位的狀態即可?
7:閉散列總代碼
template<class K>
//仿函數 用于得到kv對應的哈希值
//默認的是能直接轉換成整形值的 比如int 地址 指針 這種
struct HashFunc
{size_t operator()(const K& key){return (size_t)key;}
};//特化
//string比較通用,所以特化
//采取DKBR
//使用循環遍歷字符串中的每個字符e。
//將字符的ASCII值加到hash上,然后乘以一個常數131。
template<>
struct HashFunc<string>
{size_t operator()(const string& s){size_t hash = 0;for (auto e : s){hash += e;hash *= 131;}return hash;}
};namespace open_address
{//表示一個位置的狀態enum State{EMPTY,//空EXIST,//存在DELETE//刪除};//哈希表中的一個槽位所存儲的值 換成鏈表來說就是一個節點的值//所以除開kv 還應該有狀態 初始化為EMPTYtemplate<class K, class V>struct HashData{pair<K, V> _kv;State _state = EMPTY; // 標記};//閉散列 也叫開放定址法//參數除開kv 還有一個仿函數類用于讓k值對應一個整形值template<class K, class V, class Hash = HashFunc<K>>class HashTable{public://哈希表的構造函數 默認大小為10HashTable(size_t size = 10){_tables.resize(size);}//查找函數->用于對用戶輸入的pair類型的值進行查找HashData<K, V>* Find(const K& key){//仿函數實例對象 用于得到kv對應的哈希值Hash hs;// 線性探測size_t hashi = hs(key) % _tables.size();//key值對應的整形模上空間大小,得到了存放在vector中的初始查找位置的下標值hashi 但是由于線性探測 不一定就在該下標處//只要當前下標位置的狀態不是EMPTY,就繼續循環。//等于空代表查找失敗 返回nullptr//所以從下標到空的前一個 這段區級找到了就是有 找不到就是不存在while (_tables[hashi]._state != EMPTY){//檢查當前下標位置的鍵是否與要查找的鍵相等,并且狀態為EXIST(表示存在有效數據)。if (key == _tables[hashi]._kv.first&& _tables[hashi]._state == EXIST){return &_tables[hashi];//找到了}++hashi;//確保下標值不會超出哈希表的大小,使用模運算使其循環回到起始位置。hashi %= _tables.size();}//如果循環結束仍未找到對應的鍵值對,表示哈希表中不存在該鍵,返回nullptr。return nullptr;}//插入函數bool Insert(const pair<K, V>& kv){//在插入之前,首先調用Find函數檢查kv是否已經存在于哈希表中。//如果存在,則不需要插入,直接返回false。if (Find(kv.first))return false;//來到這 則代表一定需要插入 先檢測是否需要擴容//檢查哈希表的負載因子//問題:負載因子為0.7,但是整數相除不可能為小數,也不可能剛好為0.7//以下兩個if都可以解決//if ((double)_n / (double)_tables.size() >= 0.7)->強轉一個分數的類型為double ,然后>=0.7if (_n * 10 / _tables.size() >= 7)//->某個分數*10 就不用強轉了{//創建一個新的哈希表對象newHT 大小是原表的兩倍//遍歷原哈希表中的所有元素,將狀態為EXIST的元素插入到新哈希表中//使用swap函數將新哈希表的表與原哈希表的表交換,實現擴容HashTable<K, V, Hash> newHT(_tables.size() * 2);// 遍歷舊表,插入到新表for (auto& e : _tables){if (e._state == EXIST){newHT.Insert(e._kv);}}_tables.swap(newHT._tables);}//仿函數實例對象 用于得到kv對應的哈希值Hash hs;//線性探測去插入//使用仿函數hs計算鍵的哈希值,并取模得到初始插入位置hashi。//如果該位置已經存在元素(狀態為EXIST),則進行線性探測,即逐個檢查后續位置,直到找到空位置或刪除位置。size_t hashi = hs(kv.first) % _tables.size();while (_tables[hashi]._state == EXIST){++hashi;hashi %= _tables.size();//用于確保哈希索引 hashi 始終在哈希表的有效范圍內}//在找到的空位置或刪除位置插入鍵值對kv。將該位置的狀態設置為EXIST。增加哈希表中已存儲元素的數量_n。_tables[hashi]._kv = kv;_tables[hashi]._state = EXIST;++_n;return true;}//刪除函數bool Erase(const K& key){//調用查找函數Find來查找給定鍵的鍵值對。如果找到,Find函數返回指向該鍵值對的指針;如果未找到,返回nullptr。HashData<K, V>* ret = Find(key);if (ret){ //減少哈希表中已存儲元素的數量_n。 更改該槽位的狀態 返回true_n--;ret->_state = DELETE;return true;}else{return false;}}private://哈希表需要一個vector和一個反映實際存儲的數據個數nvector<HashData<K, V>> _tables;size_t _n = 0; // 實際存儲的數據個數};
8:閉散列代碼的測試
①:測試刪除對槽位狀態的影響
void TestHT1(){int a[] = { 1,4,24,34,7,44,17,37 };HashTable<int, int> ht;for (auto e : a){ht.Insert(make_pair(e, e));}for (auto e : a){auto ret = ht.Find(e);if (ret){cout << ret->_kv.first << ":E" << endl;}else{cout << ret->_kv.first << ":D" << endl;}}cout << endl;ht.Erase(34);ht.Erase(4);for (auto e : a){auto ret = ht.Find(e);if (ret){cout << ret->_kv.first << ":E" << endl;}else{cout << e << ":D" << endl;}}cout << endl;}解釋:
代碼邏輯:
①:
插入使得哈希表中存儲的鍵值對為?{1:1, 4:4, 24:24, 34:34, 7:7, 44:44, 17:17, 37:37}。
②:
Find(e)?查找鍵?e,鍵存在,輸出?鍵:E(E?表示 Exist);鍵不存在,輸出?鍵:D(D?表示 Delete)。第一次打印所有鍵都應輸出 鍵:E(因為剛插入,全部存在)
③:
從哈希表中刪除鍵?34?和?4。后再次查找;如果鍵是之前刪除的(34?或?4),Find(e)?會返回?nullptr(因為狀態為?DELETE),輸出?鍵:D。其他鍵仍存在,輸出?鍵:E。
運行結果:
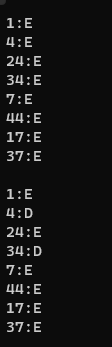 符合預期~
符合預期~
②:測試插入
//測試字典插入void TestHT2(){HashTable<string, string> dict;dict.Insert(make_pair("sort", "排序"));dict.Insert(make_pair("string", "字符串"));dict.Insert(make_pair("left", "左面"));dict.Insert(make_pair("left", "右面"));}預期結果:
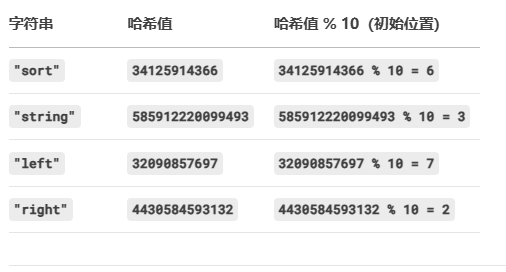
應該在監視窗口中的dict對象中的下標2是"right",下標3是"string",下標6是"sort",下標7是"left",
運行結果:
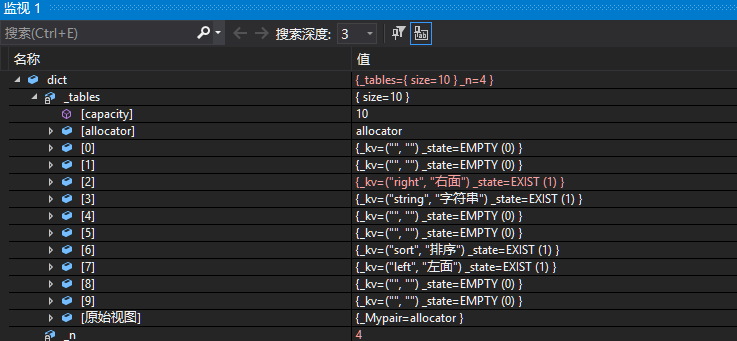
一模一樣,完美~?
注意:
若你的監視窗口不是這樣,有可能是size_t在不同平臺的編碼不同,一個是8字節,一個是4字節;所以哈希計算的值就不一樣了
三:開散列的實現(哈希桶)
1:開散列的概念
????????又叫哈希桶,首先對關鍵碼集合用哈希函數計算哈希地址,具有相同地址的關鍵碼歸于同一子集合,每一個子集合稱為一個桶,各個桶中的元素通過一個單鏈表鏈接起來,各鏈表的頭結點存儲在哈希表中。
如圖所示:
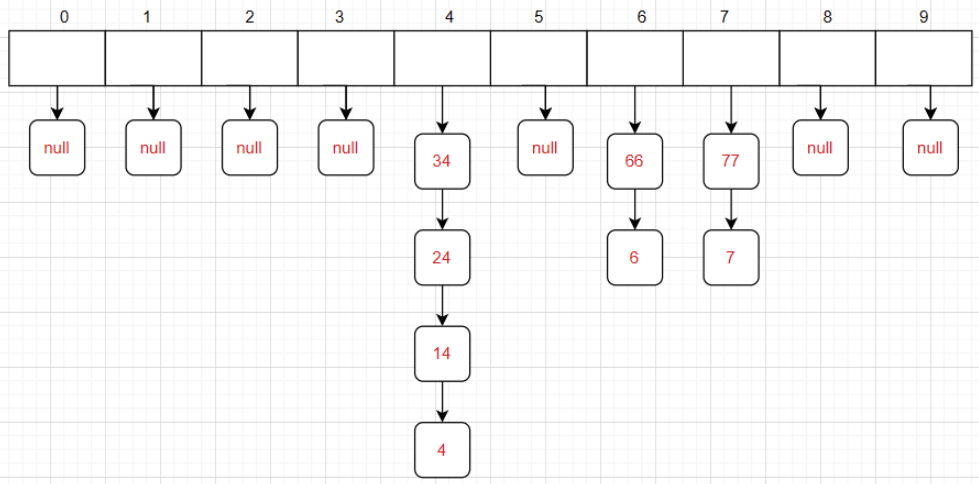
?2:總結開散列的思路
哈希沖突的時候,我們不再往后放,而是就頭插在該下標所對應的鏈表中;若是查找比如24,通過哈希函數得到下標為4,然后對應的鏈表里面找就好了
Q1:哈希表的成員變量vector中存儲的是什么
A1:存儲的節點指針,為nullptr或一個鏈表的首節點的地址;當某個下標處沒有鏈表的時候,該下標處就存儲nullptr,反之存儲鏈表的首節點的地址。
Q2:鏈表應該選擇什么結構?單向雙向?帶頭嗎?循環嗎?
A2:
選擇單向,因為雙向優勢在于任意位置插入刪除,而在這里我們只需頭插即可,而不需要任意位置的插入刪除;
選擇不帶頭,因為沒必要;
選擇不循環,因為也沒必要;
Q3:為什么插入時頭插
A3:因為不必遵循后插入的值就一定要插入到后面,畢竟大家被找的概率又不確定
所以:當我們哈希表是用開散列來實現的時候,我們的成員變量vector如下:
vector<Node*> _tables;注意:
負載因子和閉散列類似,不再多說;
狀態變量在開散列不需要了,因為我們會直接插入到下標處對應的鏈表;
仿函數也是與閉散列類似,不再多說;
重點是節點類,構造函數,以及插入函數,刪除函數,析構函數
3:節點類的實現
//這里叫HashNode 因為值存在鏈表中的一個個節點中哦~template<class K, class V>struct HashNode{HashNode<K, V>* _next;//指向下一個節點的指針pair<K, V> _kv;//存儲的鍵值對//節點的構造HashNode(const pair<K, V>& kv):_next(nullptr)//next默認為空, _kv(kv){}};解釋:
閉散列每個元素里面存儲的是pair和一個狀態變量
開散列由于元素存儲在鏈表的節點中,所以元素存儲pair和一個指向下一個節點的指針
4:構造函數的實現
HashTable(){_tables.resize(10, nullptr);_n = 0;}解釋:因為vector下標處沒鏈表的時候,應該存儲nullptr,所以我們一開始直接默認全是nullptr
?5:析構函數的實現
//析構 用于釋放vector下面掛著的鏈表 //外層for循環->遍歷vector//內層while循環->遍歷每一個桶中的節點~HashTable(){for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_tables[i] = nullptr;}}解釋:
Q1:為什么閉散列沒有實現哈希表的析構函數?
A1:因為閉散列的成員變量中的vector,是一個單純的vector,vector會自己調用庫中的析構函數;而開散列中的vector的某些位置下面掛著一個鏈表(vector的元素是一個節點指針,指向一個鏈表的首節點),所以析構函數用于釋放vector下面掛著的鏈表
Q2:鏈表不是list嗎,不是也會自己調用自己的析構函數嗎?
A2:這個鏈表使我們自己實現出來的鏈表,它的析構函數?不會遞歸調用下一個節點的析構函數(除非手動實現)。
6:插入函數的實現
//插入bool Insert(const pair<K, V>& kv){//在插入之前,首先調用Find函數檢查kv是否已經存在于哈希表中。//如果存在,則不需要插入,直接返回false。if (Find(kv.first))return false;//仿函數實例化Hash hs;// 負載因子到1就擴容if (_n == _tables.size()){//不再是開一個新哈希表對象了,而是一個新的2倍大小的vector//這樣效率更高vector<Node*> newTables(_tables.size() * 2, nullptr);//依舊是外層for循環->遍歷原來的vector//內層while循環->遍歷每個桶內的節點for (size_t i = 0; i < _tables.size(); i++){// 取出舊表中節點,重新計算桶的位置掛到新表桶中Node* cur = _tables[i];while (cur){//保存下一個節點Node* next = cur->_next;// 頭插到新表//計算新位置size_t hashi = hs(cur->_kv.first) % newTables.size();//讓當前節點的 next 指向新表的桶頭cur->_next = newTables[hashi];//把當前節點設為新表的桶頭。newTables[hashi] = cur;cur = next;}//清空舊表的桶_tables[i] = nullptr;}//交換兩個vector_tables.swap(newTables);}//走到這里代表已經擴容完畢 或者不需要擴容//直接仿函數對象得到哈希值hashisize_t hashi = hs(kv.first) % _tables.size();Node* newnode = new Node(kv);//然后頭插即可 切記vector里面放的是節點指針 指向一個桶的首節點newnode->_next = _tables[hashi];_tables[hashi] = newnode;//插入n記得++++_n;return true;}解釋:
開散列的插入邏輯依舊是:
①:插入前的檢查
②:是否擴容的判斷
③:擴容的本質
④:插入的邏輯
開散列的③需要講一下,其余和閉散列道理類似
Q1:為什么開散列的實現中的負載因子設置的是1,比閉散列大?應該設置成多少合適?
A1:

一般是設置為1。
?2:擴容的本質
和閉散列有所不同,不再使用閉散列的方法:創建一個新的且是原本大小2倍的哈希表對象,然后讀取舊對象復用inset函數,最后交換兩個對象的vector!
因為:開散列采用的哈希桶方法,按照閉散列方法擴容時候會再開辟一次同樣的節點(假設成千上萬個節點),空間消耗相當高!;而閉散列的方法,不需要開辟新的東西(只用拷貝int)所以空間消耗低....
所以我們采取的擴容:把原來的節點按照擴容后的映射規則,放進新的vector中,然后再交換新的vector和舊的哈希表對象中的vector;也就是搬運擴容前的節點,而不是開辟新的節點
搬運:重新計算掛到新表對應的桶
代碼如下:
// 負載因子到1就擴容if (_n == _tables.size()){//不再是開一個新哈希表對象了,而是一個新的2倍大小的vector//這樣效率更高vector<Node*> newTables(_tables.size() * 2, nullptr);//依舊是外層for循環->遍歷原來的vector//內層while循環->遍歷每個桶內的節點for (size_t i = 0; i < _tables.size(); i++){// 取出舊表中節點,重新計算桶的位置掛到新表桶中Node* cur = _tables[i];while (cur){//保存下一個節點Node* next = cur->_next;// 頭插到新表//計算新位置size_t hashi = hs(cur->_kv.first) % newTables.size();//讓當前節點的 next 指向新表的桶頭cur->_next = newTables[hashi];//把當前節點設為新表的桶頭。newTables[hashi] = cur;cur = next;}//清空舊表的桶_tables[i] = nullptr;}//交換兩個vector_tables.swap(newTables);}解釋:
//讓當前節點的 next 指向新表的桶頭cur->_next = newTables[hashi];//把當前節點設為新表的桶頭。newTables[hashi] = cur;①:我們從舊表拿到一個節點cur,此時要讓cur頭插進新表下標為[hashi]的位置,所以cur的_next應該指向vector下標為[hashi]處的鏈表的首節點,而vector中下標[hashi]處存儲的元素就是一個Node*(鏈表頭節點的指針),指向的就是首節點~
②:然后再把把當前節點設為新表的桶頭
③:cur的nect是一個Node*,用[hashi]處的Node*賦值沒問題~
7:刪除函數的實現
和閉散列不同的是,我們不能再find+delete,因為單向鏈表刪除節點后 無法鏈接前后節點!
//刪除函數//不能像閉散列那樣find+delete 因為我們單向鏈表刪除后還要鏈接刪除節點的前后節點//易錯:得看前驅是否為空 即需要以防刪除的就是首節點bool Erase(const K& key){Hash hs;size_t hashi = hs(key) % _tables.size();Node* prev = nullptr;Node* cur = _tables[hashi];while (cur){if (cur->_kv.first == key){// 情況1:刪除的是中間或尾節點if (prev)//前驅不為空 {prev->_next = cur->_next;// 前驅節點直接跳過當前節點}//情況2:刪除的是頭節點else//前驅為空{_tables[hashi] = cur->_next;// 讓桶頭指向下一個節點}//釋放delete cur;//n-1--_n;return true;}//沒找到則繼續遍歷prev = cur;cur = cur->_next;}//遍歷結束仍未找到 return false;}解釋:
①:我們隨時都是用prev指針,記錄前一個節點
②:通過對prev指針是否為空的判斷,若為空,代表刪除的就是首節點,因為此時prev還未賦值,所以我們單獨處理成?
_tables[hashi] = cur->_next;// 讓桶頭指向下一個節點反之不為空,代表刪除是其余的節點
prev->_next = cur->_next;//前驅節點直接跳過當前節點這樣能完美避免空指針的解引用~
8:開散列總代碼
template<class K>
//仿函數 用于得到kv對應的哈希值
//默認的是能直接轉換成整形值的 比如int 地址 指針 這種
struct HashFunc
{size_t operator()(const K& key){return (size_t)key;}
};//特化
//string比較通用,所以特化
//采取DKBR
//使用循環遍歷字符串中的每個字符e。
//將字符的ASCII值加到hash上,然后乘以一個常數131。
template<>
struct HashFunc<string>
{size_t operator()(const string& s){size_t hash = 0;for (auto e : s){hash += e;hash *= 131;}return hash;}
};//這里叫HashNode 因為值存在鏈表中哦~template<class K, class V>struct HashNode{HashNode<K, V>* _next;//只想下一個節點的指針pair<K, V> _kv;//存儲的鍵值對//節點的構造HashNode(const pair<K, V>& kv):_next(nullptr)//next默認為空, _kv(kv){}};//哈希表類 依舊是一個仿函數用于得到kv對應的哈希值template<class K, class V, class Hash = HashFunc<K>>class HashTable{typedef HashNode<K, V> Node;public://哈希表的構造 默認開存儲10個空指針的vector//相比于閉散列的構造 多了置nullptr這一步HashTable(){_tables.resize(10, nullptr);_n = 0;}//析構 用于釋放vector下面掛著的鏈表 //外層for循環->遍歷vector//內層while循環->遍歷每一個桶中的節點~HashTable(){for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_tables[i] = nullptr;}}//插入bool Insert(const pair<K, V>& kv){//在插入之前,首先調用Find函數檢查kv是否已經存在于哈希表中。//如果存在,則不需要插入,直接返回false。if (Find(kv.first))return false;//仿函數實例化Hash hs;// 負載因子到1就擴容if (_n == _tables.size()){//不再是開一個新哈希表對象了,而是一個新的2倍大小的vector//這樣效率更高vector<Node*> newTables(_tables.size() * 2, nullptr);//依舊是外層for循環->遍歷原來的vector//內層while循環->遍歷每個桶內的節點for (size_t i = 0; i < _tables.size(); i++){// 取出舊表中節點,重新計算桶的位置掛到新表桶中Node* cur = _tables[i];while (cur){//保存下一個節點Node* next = cur->_next;// 頭插到新表//計算新位置size_t hashi = hs(cur->_kv.first) % newTables.size();//讓當前節點的 next 指向新表的桶頭cur->_next = newTables[hashi];//把當前節點設為新表的桶頭。newTables[hashi] = cur;cur = next;}//清空舊表的桶_tables[i] = nullptr;}//交換兩個vector_tables.swap(newTables);}//走到這里代表已經擴容完畢 或者不需要擴容//直接仿函數對象得到哈希值hashisize_t hashi = hs(kv.first) % _tables.size();Node* newnode = new Node(kv);//然后頭插即可 切記vector里面放的是節點指針 指向一個桶的首節點newnode->_next = _tables[hashi];_tables[hashi] = newnode;//插入n記得++++_n;return true;}//查找函數//找到返回該節點的指針 反之nullptrNode* Find(const K& key){Hash hs;size_t hashi = hs(key) % _tables.size();Node* cur = _tables[hashi];while (cur){if (cur->_kv.first == key){return cur;}cur = cur->_next;}return nullptr;}//刪除函數//不能像閉散列那樣find+delete 因為我們單向鏈表刪除后還要鏈接刪除節點的前后節點//易錯:得看前驅是否為空 即需要以防刪除的就是首節點bool Erase(const K& key){Hash hs;size_t hashi = hs(key) % _tables.size();Node* prev = nullptr;Node* cur = _tables[hashi];while (cur){if (cur->_kv.first == key){// 情況1:刪除的是中間或尾節點if (prev)//前驅不為空 {prev->_next = cur->_next;// 前驅節點直接跳過當前節點}//情況2:刪除的是頭節點else//前驅為空{_tables[hashi] = cur->_next;// 讓桶頭指向下一個節點}//釋放delete cur;//n-1--_n;return true;}//沒找到則繼續遍歷prev = cur;cur = cur->_next;}//遍歷結束仍未找到 return false;}//測試我們寫的哈希桶 測試內容如下/*負載因子(load factor)總桶數量(all bucketSize)非空桶數量(bucketSize)最長鏈表長度(maxBucketLen)平均鏈表長度(averageBucketLen)*/void Some(){size_t bucketSize = 0;size_t maxBucketLen = 0;size_t sum = 0;double averageBucketLen = 0;for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];if (cur){++bucketSize;}size_t bucketLen = 0;while (cur){++bucketLen;cur = cur->_next;}sum += bucketLen;if (bucketLen > maxBucketLen){maxBucketLen = bucketLen;}}averageBucketLen = (double)sum / (double)bucketSize;printf("load factor:%lf\n", (double)_n / _tables.size());printf("all bucketSize:%d\n", _tables.size());printf("bucketSize:%d\n", bucketSize);printf("maxBucketLen:%d\n", maxBucketLen);printf("averageBucketLen:%lf\n\n", averageBucketLen);}private://與閉散列不同的是 vector里面存儲的是節點指針了vector<Node*> _tables; // 指針數組size_t _n;};?解釋:
????????其中的some()函數是用來測試的,測試內容如下:
?? ??? ?負載因子(load factor)
?? ??? ?總桶數量(總的節點的個數)(all bucketSize)
?? ??? ?非空桶數量(vector中元素不為nullptr的個數)(bucketSize)
?? ??? ?最長鏈表長度(maxBucketLen)
?? ??? ?平均鏈表長度(averageBucketLen)
9:開散列代碼的測試
①:測試開散列的插入刪除
//測試自己寫的哈希桶的插入刪除是否正確void TestHT1(){HashTable<int, int> ht;int a[] = { 1,4,24,34,7,44,17,37 };for (auto e : a){ht.Insert(make_pair(e, e));}ht.Insert(make_pair(5, 5));ht.Insert(make_pair(15, 15));ht.Insert(make_pair(25, 25));ht.Erase(5);ht.Erase(15);ht.Erase(25);ht.Erase(35);HashTable<string, string> dict;dict.Insert(make_pair("sort", "排序"));dict.Insert(make_pair("string", "字符串"));}解釋:和預期一致,這個監視窗口不好展示
②:測試some()函數
//測試自己寫的哈希桶的Some();void TestHT2(){const size_t N = 30000;HashTable<int, int> ht;vector<int> v;v.reserve(N);srand(time(0));for (size_t i = 0; i < N; ++i){//v.push_back(rand()); // N比較大時,重復值比較多v.push_back(rand() + i); // 重復值相對少//v.push_back(i); // 沒有重復,有序}// 插入數據到哈希表for (auto e : v){ht.Insert(make_pair(e, e));}ht.Some();}解釋:插入了3萬個數據,運行結果如下:?
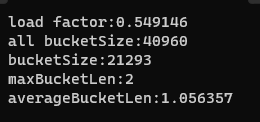
負載因子:0.549
總的桶(總的節點):40960
非空桶(vector中不為空的槽位):21293
最長的桶(最長的鏈表):2
平均桶長度(平均鏈表長度):1.05
可以看出,開散列是一個非常優秀的結構,這也是庫中的哈希表也是用的開散列的原因
四:總測試
測試自己寫的哈希桶 ?和 ?庫中的哈希桶 ?和 ?庫中的set
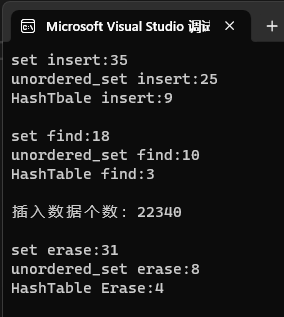
//測試 自己寫的哈希桶 和 庫中的哈希桶 和 庫中的setvoid TestHT3(){const size_t N = 30000;unordered_set<int> us;set<int> s;HashTable<int, int> ht;vector<int> v;v.reserve(N);srand(time(0));for (size_t i = 0; i < N; ++i){//v.push_back(rand()); // N比較大時,重復值比較多v.push_back(rand() + i); // 重復值相對少//v.push_back(i); // 沒有重復,有序}// 21:15size_t begin1 = clock();for (auto e : v){s.insert(e);}size_t end1 = clock();cout << "set insert:" << end1 - begin1 << endl;size_t begin2 = clock();for (auto e : v){us.insert(e);}size_t end2 = clock();cout << "unordered_set insert:" << end2 - begin2 << endl;size_t begin10 = clock();for (auto e : v){ht.Insert(make_pair(e, e));}size_t end10 = clock();cout << "HashTbale insert:" << end10 - begin10 << endl << endl;size_t begin3 = clock();for (auto e : v){s.find(e);}size_t end3 = clock();cout << "set find:" << end3 - begin3 << endl;size_t begin4 = clock();for (auto e : v){us.find(e);}size_t end4 = clock();cout << "unordered_set find:" << end4 - begin4 << endl;size_t begin11 = clock();for (auto e : v){ht.Find(e);}size_t end11 = clock();cout << "HashTable find:" << end11 - begin11 << endl << endl;cout << "插入數據個數:" << us.size() << endl << endl;ht.Some();size_t begin5 = clock();for (auto e : v){s.erase(e);}size_t end5 = clock();cout << "set erase:" << end5 - begin5 << endl;size_t begin6 = clock();for (auto e : v){us.erase(e);}size_t end6 = clock();cout << "unordered_set erase:" << end6 - begin6 << endl;size_t begin12 = clock();for (auto e : v){ht.Erase(e);}size_t end12 = clock();cout << "HashTable Erase:" << end12 - begin12 << endl << endl;}運行結果如下:
 ?
?
解釋:
Q:庫中的unodered_set比庫中的set快,能理解,為什么我們自己寫的哈希表比這兩個都快?
A:我們只是實現了一個非常簡略的版本,考慮的因素遠遠比不上庫中的實現,所以顯得快。
五:閉/開散列的總代碼
①:HashTable.h
#pragma once
#include<iostream>
#include<vector>
#include<unordered_set>
#include<unordered_map>
#include<set>
using namespace std;template<class K>
//仿函數 用于得到kv對應的哈希值
//默認的是能直接轉換成整形值的 比如int 地址 指針 這種
struct HashFunc
{size_t operator()(const K& key){return (size_t)key;}
};//特化
//string比較通用,所以特化
//采取DKBR
//使用循環遍歷字符串中的每個字符e。
//將字符的ASCII值加到hash上,然后乘以一個常數131。
template<>
struct HashFunc<string>
{size_t operator()(const string& s){size_t hash = 0;for (auto e : s){hash += e;hash *= 131;}return hash;}
};namespace open_address
{//表示一個位置的狀態enum State{EMPTY,//空EXIST,//存在DELETEe//刪除};//哈希表中的一個槽位所存儲的值 換成鏈表來說就是一個節點的值//所以除開kv 還應該有狀態 初始化為EMPTYtemplate<class K, class V>struct HashData{pair<K, V> _kv;State _state = EMPTY; // 標記};//閉散列 也叫開放定址法//參數除開kv 還有一個仿函數類用于讓k值對應一個整形值template<class K, class V, class Hash = HashFunc<K>>class HashTable{public://哈希表的構造函數 默認大小為10HashTable(size_t size = 10){_tables.resize(size);}//查找函數->用于對用戶輸入的pair類型的值進行查找HashData<K, V>* Find(const K& key){//仿函數實例對象 用于得到kv對應的哈希值Hash hs;// 線性探測size_t hashi = hs(key) % _tables.size();//key值對應的整形模上空間大小,得到了存放在vector中的初始查找位置的下標值hashi 但是由于線性探測 不一定就在該下標處//只要當前下標位置的狀態不是EMPTY,就繼續循環。//等于空代表查找失敗 返回nullptr//所以從下標到空的前一個 這段區級找到了就是有 找不到就是不存在while (_tables[hashi]._state != EMPTY){//檢查當前下標位置的鍵是否與要查找的鍵相等,并且狀態為EXIST(表示存在有效數據)。if (key == _tables[hashi]._kv.first&& _tables[hashi]._state == EXIST){return &_tables[hashi];//找到了}++hashi;//確保下標值不會超出哈希表的大小,使用模運算使其循環回到起始位置。hashi %= _tables.size();}//如果循環結束仍未找到對應的鍵值對,表示哈希表中不存在該鍵,返回nullptr。return nullptr;}//插入函數bool Insert(const pair<K, V>& kv){//在插入之前,首先調用Find函數檢查kv是否已經存在于哈希表中。//如果存在,則不需要插入,直接返回false。if (Find(kv.first))return false;//來到這 則代表一定需要插入 先檢測是否需要擴容//檢查哈希表的負載因子//問題:負載因子為0.7,但是整數相除不可能為小數,也不可能剛好為0.7//以下兩個if都可以解決//if ((double)_n / (double)_tables.size() >= 0.7)->強轉一個分數的類型為double ,然后>=0.7if (_n * 10 / _tables.size() >= 7)//->某個分數*10 就不用強轉了{//創建一個新的哈希表對象newHT 大小是原表的兩倍//遍歷原哈希表中的所有元素,將狀態為EXIST的元素插入到新哈希表中//使用swap函數將新哈希表的表與原哈希表的表交換,實現擴容HashTable<K, V, Hash> newHT(_tables.size() * 2);// 遍歷舊表,插入到新表for (auto& e : _tables){if (e._state == EXIST){newHT.Insert(e._kv);}}_tables.swap(newHT._tables);}//仿函數實例對象 用于得到kv對應的哈希值Hash hs;//線性探測去插入//使用仿函數hs計算鍵的哈希值,并取模得到初始插入位置hashi。//如果該位置已經存在元素(狀態為EXIST),則進行線性探測,即逐個檢查后續位置,直到找到空位置或刪除位置。size_t hashi = hs(kv.first) % _tables.size();while (_tables[hashi]._state == EXIST){++hashi;hashi %= _tables.size();//用于確保哈希索引 hashi 始終在哈希表的有效范圍內}//在找到的空位置或刪除位置插入鍵值對kv。將該位置的狀態設置為EXIST。增加哈希表中已存儲元素的數量_n。_tables[hashi]._kv = kv;_tables[hashi]._state = EXIST;++_n;return true;}//刪除函數bool Erase(const K& key){//調用查找函數Find來查找給定鍵的鍵值對。如果找到,Find函數返回指向該鍵值對的指針;如果未找到,返回nullptr。HashData<K, V>* ret = Find(key);if (ret){ //減少哈希表中已存儲元素的數量_n。 更改該槽位的狀態 返回true_n--;ret->_state = DELETEe;return true;}else{return false;}}private://哈希表需要一個vector和一個反映實際存儲的數據個數nvector<HashData<K, V>> _tables;size_t _n = 0; // 實際存儲的數據個數};//測試刪除是否影響槽位的狀態void TestHT1(){int a[] = { 1,4,24,34,7,44,17,37 };HashTable<int, int> ht;for (auto e : a){ht.Insert(make_pair(e, e));}for (auto e : a){auto ret = ht.Find(e);if (ret){cout << ret->_kv.first << ":E" << endl;}else{cout << ret->_kv.first << ":D" << endl;}}cout << endl;ht.Erase(34);ht.Erase(4);for (auto e : a){auto ret = ht.Find(e);if (ret){cout << ret->_kv.first << ":E" << endl;}else{cout << e << ":D" << endl;}}cout << endl;}//測試字典插入void TestHT2(){HashTable<string, string> dict;dict.Insert(make_pair("sort", "排序"));dict.Insert(make_pair("string", "字符串"));dict.Insert(make_pair("left", "左面"));dict.Insert(make_pair("right", "右面"));}}//開散列(哈希桶)的實現
namespace hash_bucket
{//這里叫HashNode 因為值存在鏈表中哦~template<class K, class V>struct HashNode{HashNode<K, V>* _next;//只想下一個節點的指針pair<K, V> _kv;//存儲的鍵值對//節點的構造HashNode(const pair<K, V>& kv):_next(nullptr)//next默認為空, _kv(kv){}};//哈希表類 依舊是一個仿函數用于得到kv對應的哈希值template<class K, class V, class Hash = HashFunc<K>>class HashTable{typedef HashNode<K, V> Node;public://哈希表的構造 默認開存儲10個空指針的vector//相比于閉散列的構造 多了置nullptr這一步HashTable(){_tables.resize(10, nullptr);_n = 0;}//析構 用于釋放vector下面掛著的鏈表 //外層for循環->遍歷vector//內層while循環->遍歷每一個桶中的節點~HashTable(){for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_tables[i] = nullptr;}}//插入bool Insert(const pair<K, V>& kv){//在插入之前,首先調用Find函數檢查kv是否已經存在于哈希表中。//如果存在,則不需要插入,直接返回false。if (Find(kv.first))return false;//仿函數實例化Hash hs;// 負載因子到1就擴容if (_n == _tables.size()){//不再是開一個新哈希表對象了,而是一個新的2倍大小的vector//這樣效率更高vector<Node*> newTables(_tables.size() * 2, nullptr);//依舊是外層for循環->遍歷原來的vector//內層while循環->遍歷每個桶內的節點for (size_t i = 0; i < _tables.size(); i++){// 取出舊表中節點,重新計算桶的位置掛到新表桶中Node* cur = _tables[i];while (cur){//保存下一個節點Node* next = cur->_next;// 頭插到新表//計算新位置size_t hashi = hs(cur->_kv.first) % newTables.size();//讓當前節點的 next 指向新表的桶頭cur->_next = newTables[hashi];//把當前節點設為新表的桶頭。newTables[hashi] = cur;cur = next;}//清空舊表的桶_tables[i] = nullptr;}//交換兩個vector_tables.swap(newTables);}//走到這里代表已經擴容完畢 或者不需要擴容//直接仿函數對象得到哈希值hashisize_t hashi = hs(kv.first) % _tables.size();Node* newnode = new Node(kv);//然后頭插即可 切記vector里面放的是節點指針 指向一個桶的首節點newnode->_next = _tables[hashi];_tables[hashi] = newnode;//插入n記得++++_n;return true;}//查找函數//找到返回該節點的指針 反之nullptrNode* Find(const K& key){Hash hs;size_t hashi = hs(key) % _tables.size();Node* cur = _tables[hashi];while (cur){if (cur->_kv.first == key){return cur;}cur = cur->_next;}return nullptr;}//刪除函數//不能像閉散列那樣find+delete 因為我們單向鏈表刪除后還要鏈接刪除節點的前后節點//易錯:得看前驅是否為空 即需要以防刪除的就是首節點bool Erase(const K& key){Hash hs;size_t hashi = hs(key) % _tables.size();Node* prev = nullptr;Node* cur = _tables[hashi];while (cur){if (cur->_kv.first == key){// 情況1:刪除的是中間或尾節點if (prev)//前驅不為空 {prev->_next = cur->_next;// 前驅節點直接跳過當前節點}//情況2:刪除的是頭節點else//前驅為空{_tables[hashi] = cur->_next;// 讓桶頭指向下一個節點}//釋放delete cur;//n-1--_n;return true;}//沒找到則繼續遍歷prev = cur;cur = cur->_next;}//遍歷結束仍未找到 return false;}//測試我們寫的哈希桶 測試內容如下/*負載因子(load factor)總桶數量(all bucketSize)非空桶數量(bucketSize)最長鏈表長度(maxBucketLen)平均鏈表長度(averageBucketLen)*/void Some(){size_t bucketSize = 0;size_t maxBucketLen = 0;size_t sum = 0;double averageBucketLen = 0;for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];if (cur){++bucketSize;}size_t bucketLen = 0;while (cur){++bucketLen;cur = cur->_next;}sum += bucketLen;if (bucketLen > maxBucketLen){maxBucketLen = bucketLen;}}averageBucketLen = (double)sum / (double)bucketSize;printf("load factor:%lf\n", (double)_n / _tables.size());printf("all bucketSize:%d\n", _tables.size());printf("bucketSize:%d\n", bucketSize);printf("maxBucketLen:%d\n", maxBucketLen);printf("averageBucketLen:%lf\n\n", averageBucketLen);}private://與閉散列不同的是 vector里面存儲的是節點指針了vector<Node*> _tables; // 指針數組size_t _n;};//測試自己寫的哈希桶的插入刪除是否正確void TestHT1(){HashTable<int, int> ht;int a[] = { 1,4,24,34,7,44,17,37 };for (auto e : a){ht.Insert(make_pair(e, e));}ht.Insert(make_pair(5, 5));ht.Insert(make_pair(15, 15));ht.Insert(make_pair(25, 25));ht.Erase(5);ht.Erase(15);ht.Erase(25);ht.Erase(35);HashTable<string, string> dict;dict.Insert(make_pair("sort", "排序"));dict.Insert(make_pair("string", "字符串"));}//測試自己寫的哈希桶的Some();void TestHT2(){const size_t N = 30000;HashTable<int, int> ht;vector<int> v;v.reserve(N);srand(time(0));for (size_t i = 0; i < N; ++i){//v.push_back(rand()); // N比較大時,重復值比較多v.push_back(rand() + i); // 重復值相對少//v.push_back(i); // 沒有重復,有序}// 插入數據到哈希表for (auto e : v){ht.Insert(make_pair(e, e));}ht.Some();}//測試 自己寫的哈希桶 和 庫中的哈希桶 和 庫中的setvoid TestHT3(){const size_t N = 30000;unordered_set<int> us;set<int> s;HashTable<int, int> ht;vector<int> v;v.reserve(N);srand(time(0));for (size_t i = 0; i < N; ++i){//v.push_back(rand()); // N比較大時,重復值比較多v.push_back(rand() + i); // 重復值相對少//v.push_back(i); // 沒有重復,有序}// 21:15size_t begin1 = clock();for (auto e : v){s.insert(e);}size_t end1 = clock();cout << "set insert:" << end1 - begin1 << endl;size_t begin2 = clock();for (auto e : v){us.insert(e);}size_t end2 = clock();cout << "unordered_set insert:" << end2 - begin2 << endl;size_t begin10 = clock();for (auto e : v){ht.Insert(make_pair(e, e));}size_t end10 = clock();cout << "HashTbale insert:" << end10 - begin10 << endl << endl;size_t begin3 = clock();for (auto e : v){s.find(e);}size_t end3 = clock();cout << "set find:" << end3 - begin3 << endl;size_t begin4 = clock();for (auto e : v){us.find(e);}size_t end4 = clock();cout << "unordered_set find:" << end4 - begin4 << endl;size_t begin11 = clock();for (auto e : v){ht.Find(e);}size_t end11 = clock();cout << "HashTable find:" << end11 - begin11 << endl << endl;cout << "插入數據個數:" << us.size() << endl << endl;ht.Some();size_t begin5 = clock();for (auto e : v){s.erase(e);}size_t end5 = clock();cout << "set erase:" << end5 - begin5 << endl;size_t begin6 = clock();for (auto e : v){us.erase(e);}size_t end6 = clock();cout << "unordered_set erase:" << end6 - begin6 << endl;size_t begin12 = clock();for (auto e : v){ht.Erase(e);}size_t end12 = clock();cout << "HashTable Erase:" << end12 - begin12 << endl << endl;}
}②:test.h
#define _CRT_SECURE_NO_WARNINGS 1
#include"HashTable(未封裝).h"
using namespace std;int main()
{//閉散列的測試// ↓//在閉散列實現中測試刪除后對枚舉中狀態的影響//open_address::TestHT1();//在閉散列實現中測試字典插入//open_address::TestHT2();//哈希桶的測試// ↓ //測試自己寫的哈希桶的插入刪除是否正確//hash_bucket::TestHT1();//測試 自己寫的哈希桶的Some函數 體現桶的平均//hash_bucket::TestHT2();//測試 自己寫的哈希桶 和 庫中的哈希桶 和 庫中的set//hash_bucket::TestHT3();return 0;
}哈希思想很美好,前輩們雖然沒有完美的復刻實現出這種美好的思想,但是也創造出了一種相對與之前更優秀的數據結構!
正所謂:"理想如星辰,雖未摘得,卻已在追光途中淬煉出更璀璨的自己。"

(文末有下載方式))
 堆棧寄存器實驗)







![Astral Ascent 星界戰士(星座上升) [DLC 解鎖] [Steam] [Windows SteamOS macOS]](http://pic.xiahunao.cn/Astral Ascent 星界戰士(星座上升) [DLC 解鎖] [Steam] [Windows SteamOS macOS])








