- 🍨 本文為🔗365天深度學習訓練營 中的學習記錄博客
- 🍖 原作者:K同學啊
從 tensorflow.keras 中導入 layers 模塊,包含了常用的神經網絡層,用來搭建模型結構。
檢查并列出系統中可用的物理 GPU 設備,返回一個 GPU 列表。
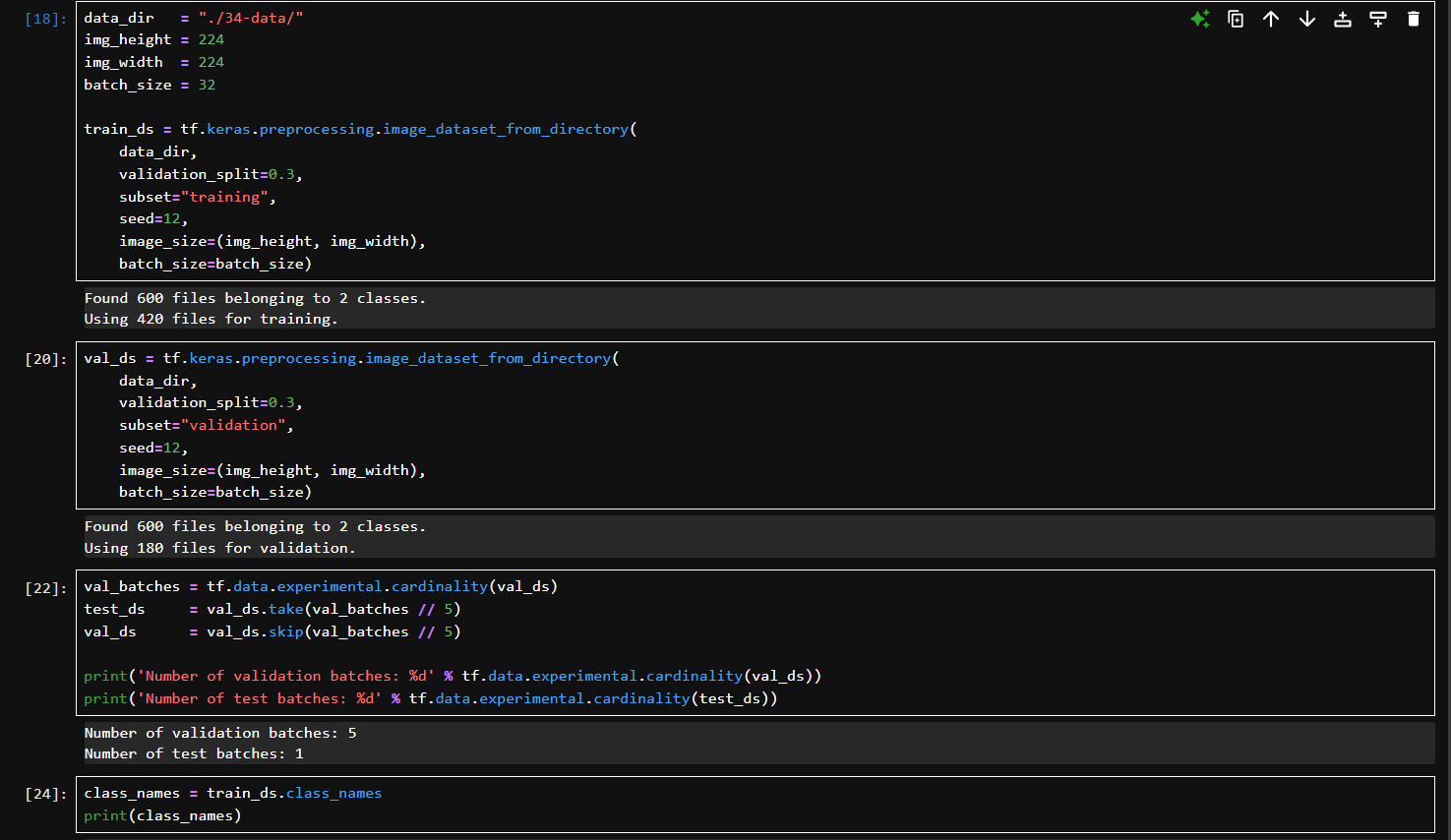
img_height, img_width:圖片統一 resize 成 224x224。
batch_size:每個訓練 batch 中的樣本數為 32。
validation_split=0.3:把 30% 數據預留為驗證用;
subset=“training”:表示當前提取的是訓練數據;
seed=12:用于保證訓練/驗證劃分一致;
自動讀取所有圖像并打標簽,resize 到指定大小,分成批次。輸出:總共 600 張圖像,420 用于訓練。
subset=“validation”:這次提取的是驗證集;同樣參數以確保訓練驗證劃分方式一致。
輸出:驗證集為 180 張圖像。
cardinality():獲取 val_ds 中 batch 的總數(為 5);val_ds.take(n):取前 n 個 batch 作為 test_ds;val_ds.skip(n):剩余部分留作 val_ds。相當于把驗證集的 20% 再切出來當 test 集(180 張圖中約 36 張是測試集,剩余 144 張繼續作驗證集)。
每個 batch 有 32 張圖像。
獲取類別名稱,[‘cat’, ‘dog’]。
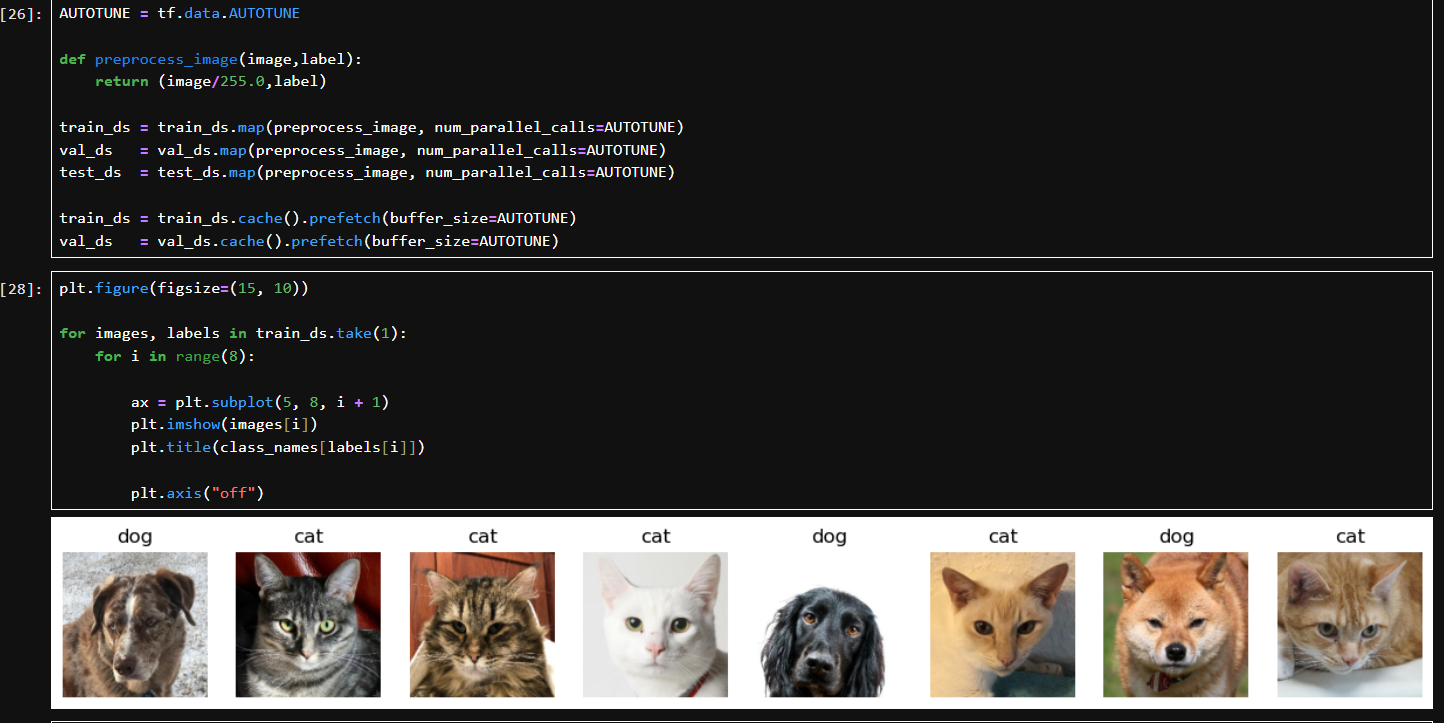
自定義預處理函數:
把圖像像素值歸一化到 [0, 1](原始值是 0~255);保留原標簽。
map():將上面定義的預處理函數應用到數據集中每個元素;num_parallel_calls=AUTOTUNE:啟用多線程并行處理。
.cache():將數據緩存到內存中,加快讀取速度;
.prefetch():訓練時提前準備好下一個 batch,減少訓練等待時間。
take(1):從訓練集中取出 1 個 batch(共 32 張圖);迭代取出其中的圖像和標簽。
只顯示前 8 張圖片;plt.subplot(5, 8, i + 1):在 5x8 的網格中放置圖像;plt.imshow():顯示圖片;plt.title():顯示類別;plt.axis(“off”):隱藏坐標軸。
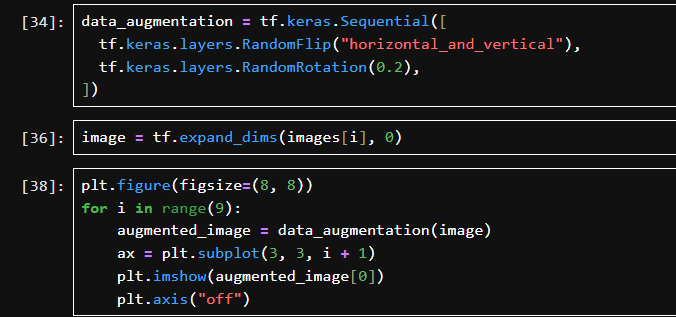
RandomFlip(“horizontal_and_vertical”)
隨機水平 & 垂直翻轉圖像。
RandomRotation(0.2)
隨機將圖像旋轉 ±20% 的角度。
images[i] 是單張圖像的張量,形狀是 [height, width, channels];模型要求輸入帶有 batch 維度,即 [1, height, width, channels];所以expand_dims(…, 0) 在最前加了一個維度,構成一個 batch。
創建一個 3x3 網格畫布;每次對同一張圖 image 進行數據增強;用 plt.imshow() 顯示增強后的圖像;隱藏坐標軸。
使用 Keras 增強層對圖像進行隨機翻轉和旋轉,并將同一張原始圖片經過 9 次增強后的結果可視化。
data_augmentation表示訓練時自動進行數據增強;Conv2D(16, 3, …):卷積層,16 個 3x3 的卷積核,激活函數 ReLU;MaxPooling2D():池化層,降低特征圖空間維度。將數據增強模塊嵌入訓練數據集(用 training=True 激活增強);map() 函數在 TensorFlow Dataset 中遍歷每個樣本 (x, y);設置 num_parallel_calls=AUTOTUNE 自動調節線程數。train_ds 數據會自動帶數據增強。
Conv2D + ReLU,三層卷積提取空間特征;MaxPooling2D,每層后面做降采樣,減小計算量;Flatten,將多維張量展平,連接到全連接層;Dense(128),全連接隱藏層,128 個神經元,ReLU 激活;Dense(len(class_names)), 輸出層,單元個數 = 類別數,未加激活函數。
使用 Adam 優化器;SparseCategoricalCrossentropy:適用于標簽是整數編碼;from_logits=True:表示最后一層未經過 softmax,loss 會自動處理;指標使用 accuracy 來評估性能。
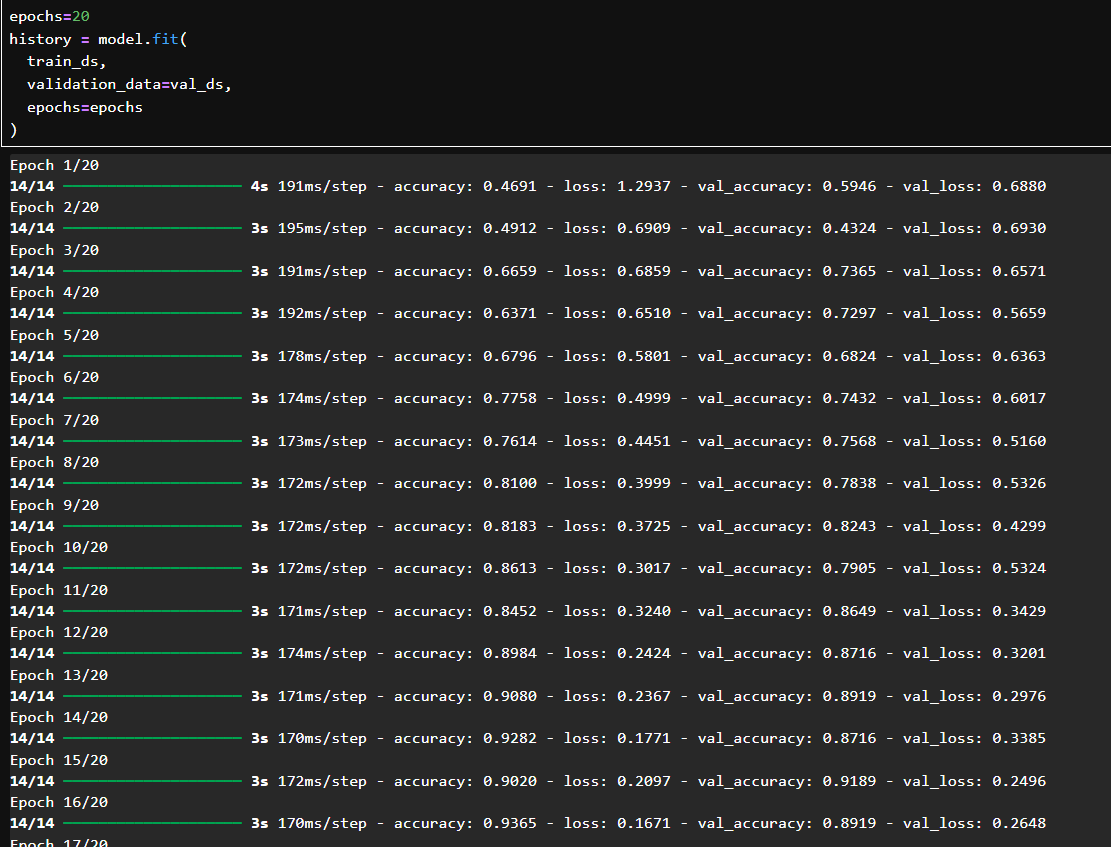
用 train_ds 訓練,val_ds 驗證;總共訓練了 20 輪(epoch);
每一輪都輸出了:
accuracy:訓練集準確率;
loss:訓練損失;
val_accuracy:驗證集準確率;
val_loss:驗證損失。
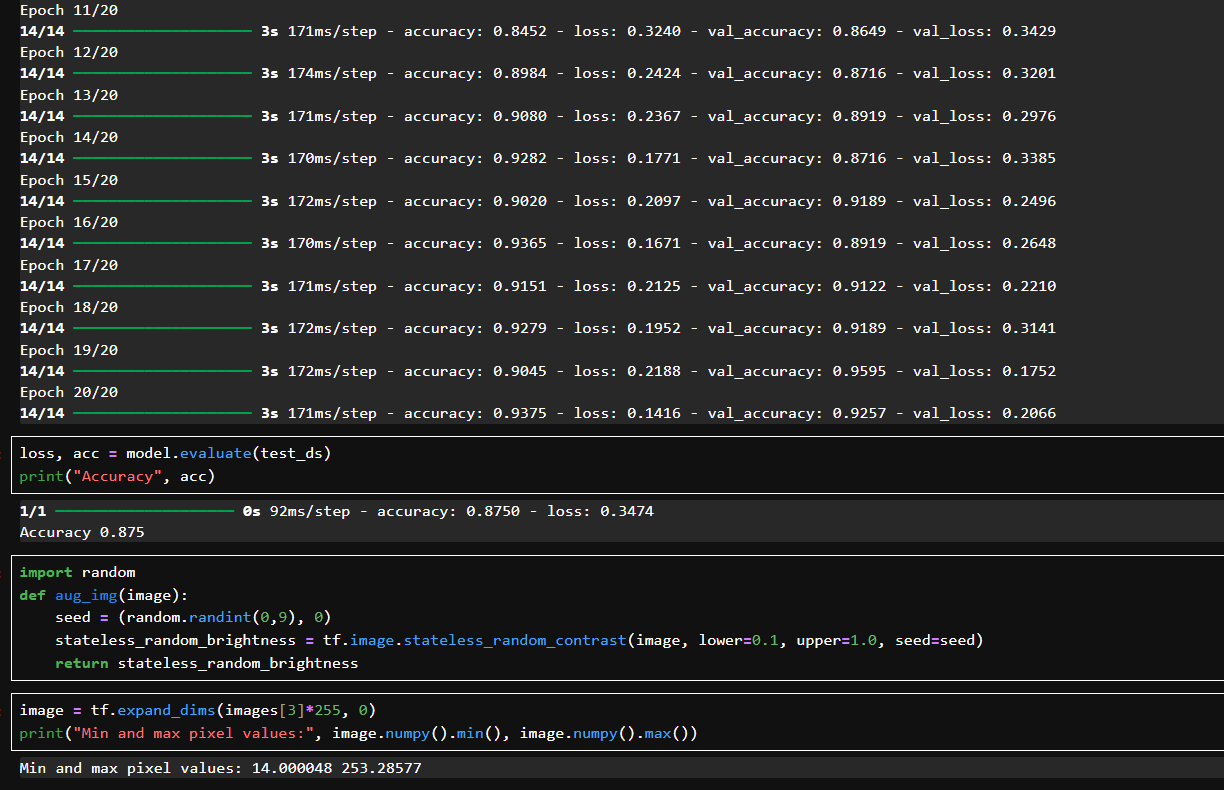
初始 val_accuracy 為 59.4%,逐輪提升,最終達到 92.5%;
loss 和 val_loss 都穩定下降,沒有過擬合;從第 10 輪開始準確率就提升很高。
用分離出來的測試集 test_ds 評估最終模型性能,表示模型在從未見過的數據上仍能達到 87.5% 的分類準確率。
使用 stateless_random_contrast:給圖像加入對比度增強;使用固定種子 (seed, 0):可以控制隨機性、實現復現。
將訓練圖像 [3] 乘回 255,還原為原始像素;使用 expand_dims 添加 batch 維;打印最小/最大像素值:表明增強后圖像仍保持合理亮度范圍,沒有過度偏暗或偏亮。
創建一個新的圖像窗口,大小為 8x8 英寸。
對同一張圖像 image 進行 9 次增強;每次調用 aug_img() 函數,使用tf.image.stateless_random_contrast() 添加隨機對比度。
創建一個 3x3 網格的子圖,把當前增強圖像放在第 i+1 個位置。
augmented_image 的 shape 是 [1, h, w, c],取出 [0] 表示取出圖像本身;
.numpy():將 Tensor 轉為 NumPy 數組;.astype(“uint8”):把圖像像素轉回標準的 8-bit 整數格式,然后去除坐標軸。







(文末有下載方式))









)

