原文地址:https://arxiv.org/abs/2502.15016
發表會議:暫定(但是Star很高)
代碼地址:無
作者:Juntong Ni (倪浚桐), Zewen Liu (劉澤文), Shiyu Wang(王世宇), Ming Jin(金明), Wei Jin(金衛)
團隊:埃默里大學(Emory),格里菲斯大學(Griffith)
同時本文在實驗部分我也結合了這篇文章的借鑒:TimeDistill:跨架構知識蒸餾,使用 MLP 實現高效長程時間序列預測-騰訊云開發者社區-騰訊云 https://cloud.tencent.com/developer/article/2503439
https://cloud.tencent.com/developer/article/2503439
摘要
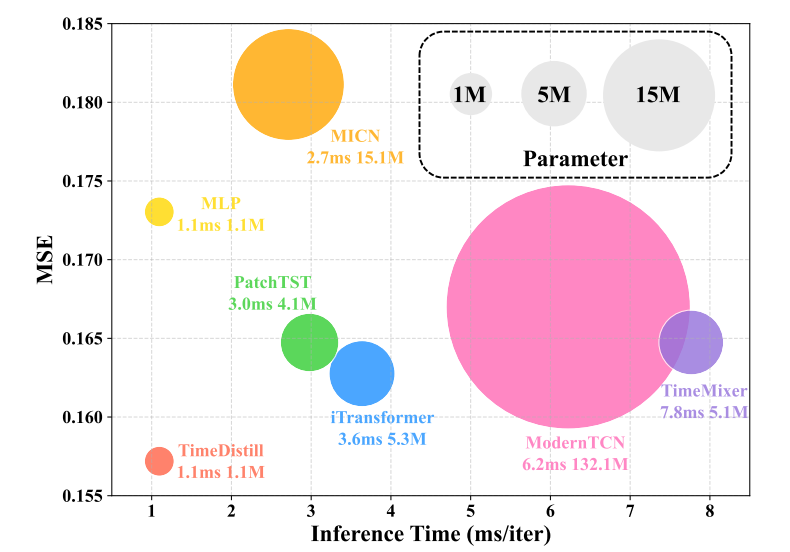
本文提出了一種跨架構知識蒸餾(KD)框架TimeDistill,用于提高輕量級多層感知機(MLP)模型在長期時間序列預測任務上的性能。作者觀察到,盡管先進的架構如Transformer和CNN在性能上表現出色,但由于計算和存儲需求高,在大規模部署中面臨挑戰。相比之下,簡單的MLP模型具有更高的效率,但性能較低。TimeDistill的關鍵思想是從教師模型(如Transformer、CNN)中提取補充模式,特別是時間和頻域中的多尺度和多周期模式,并將其蒸餾到學生MLP模型中。作者從理論上分析了TimeDistill的優勢,表明所提出的蒸餾過程可以視為一種特殊的mixup數據增強策略。實驗結果表明,TimeDistill在所有數據集上都能顯著優于獨立的MLP模型,最高可提升18.6%,并且在大多數情況下也優于教師模型,同時實現了高達7倍的推理加速和高達130倍的參數減少。
此外,作者還探討了TimeDistill的versatility,包括使用不同的教師模型、學生模型以及不同的歷史窗口長度。結果表明,TimeDistill能夠從各種教師模型中有效地學習知識,并且能夠顯著提升其他輕量級模型(如TSMixer和LightTS)的性能。同時,TimeDistill在不同歷史窗口長度下都能保持優于教師模型的性能。
總之,本文提出的TimeDistill框架為長期時間序列預測任務提供了一種高效且通用的解決方案,在保持輕量級模型架構的同時,能夠顯著提升預測性能,并且具有良好的適應性。
科普
- KD(知識蒸餾)的概念:一種將知識從更大更復雜的模型(教師)轉移到更小更簡單的模型(學生)的技術,同時保持可比的性能。
- transformer的做法:利用了捕捉成對依賴關系和提取順序數據中的多級表示的強大能力
教師模型里的什么“知識”應該提煉到MLP?
利用不同架構的互補能力的價值,主要聚焦于兩個關鍵的時序模式:
- 多尺度模式 : 現實世界的時間序列通常在多個時間尺度上顯示變化。表現良好的模型在最細粒度尺度上也能準確地在更粗糙的尺度上表現, 而 MLP 在大多數尺度上都失敗。
- 多周期模式?: 時間序列通常表現出多個周期性。表現良好的模型能夠捕捉與真實數據相似的周期性, 但 MLP 無法捕捉這些周期性。
TimeDistill和傳統KD的區別,以及它的處理辦法和優點?
TIMEDISTILL專注于對齊MLP和教師之間的多尺度和多周期模式,而不是僅僅匹配傳統KD中的預測:首先對時間序列進行下采樣以進行時間多尺度對齊,并應用快速傅立葉變換(FFT)來對齊頻域中的周期分布。KD過程可以離線進行,將繁重的計算從延遲關鍵的推理階段(毫秒級問題)轉移到對時間不太敏感的訓練階段,在那里可以接受更長的處理時間。
?與之前只關注預測輸出的LightTS(另一篇KD論文)不同
?1?? LightTS(舊方法):就像專門給「學霸小組」(集成分類器)設計的教學大綱,只能讓組內學霸互相學習。
但問題是:
- 只適用于特定班級(集成模型)
- 無法推廣到其他類型的學生(比如普通學生MLP)
2?? 本文方法(新方法):更像針對「時間科目」的定制教學,專門攻克兩類難題:
- 多尺度題(比如同時分析每小時+每天的交通數據變化)
- 多周期題(比如識別天氣中的日循環+年循環規律)
并且允許:
? 跨班級教學(如讓Transformer學霸教MLP學渣)
? 提煉學科專用技巧(而非通用解題套路)
為什么選擇蒸餾?
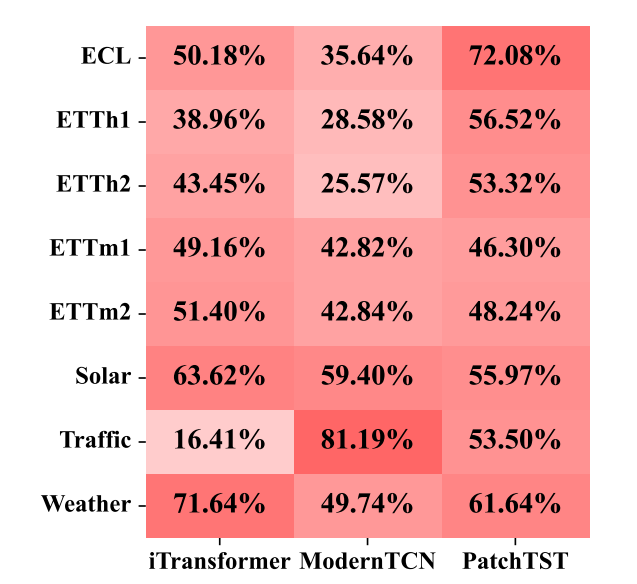
????????MLP(多層感知機)在效率上的優勢以及其在性能上的局限性,并提出知識蒸餾(KD)作為一種可能的解決方案。盡管MLP在整體性能上可能不如Transformer或CNN等復雜模型,但它在特定樣本上可能表現更好。通過分析MLP與教師模型的預測誤差,可以發現MLP在某些子集上具有優勢,這為知識蒸餾提供了潛在的價值。
????????關鍵點 MLP的效率與性能權衡: MLP在效率上表現優異,但在整體性能上通常不如Transformer和CNN模型。 盡管如此,MLP在某些樣本上可能優于教師模型,這表明它們在特定任務上具有不同的優勢。
????????勝率的計算: 通過比較MLP和教師模型的預測誤差,計算MLP優于教師模型的比例(勝率)。 實驗表明,盡管MLP總體上不如教師模型,但它在某些數據集(如Traffic)上表現出較高的勝率(81.19%),說明不同模型在不同子集上的表現存在差異。
????????知識蒸餾的潛力: 從教師模型中提取互補知識到MLP中,可以彌補MLP的不足,同時利用其在特定樣本上的優勢。
知識蒸餾的局限性:
- 過擬合噪聲:直接對齊預測可能過擬合教師模型中的噪聲,導致知識不穩定。
- 復雜模式的復制困難:MLP可能難以直接復制教師模型預測中的復雜模式(如季節性、趨勢等)。
- 忽略中間特征:僅對齊預測忽略了教師模型中間特征的有價值知識。
KD應該提取什么?
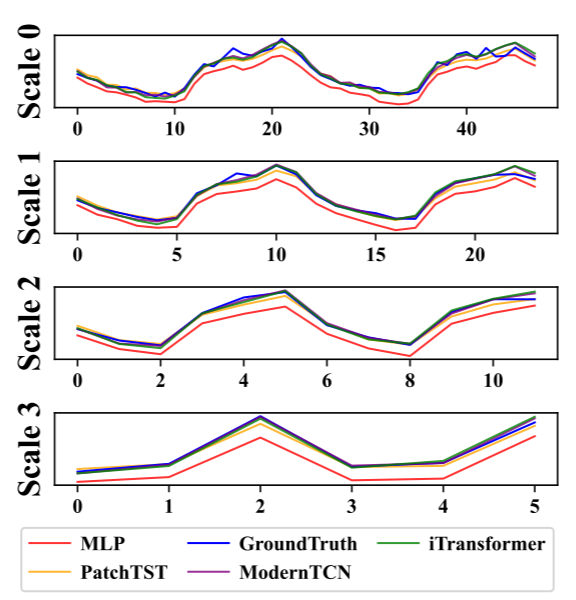
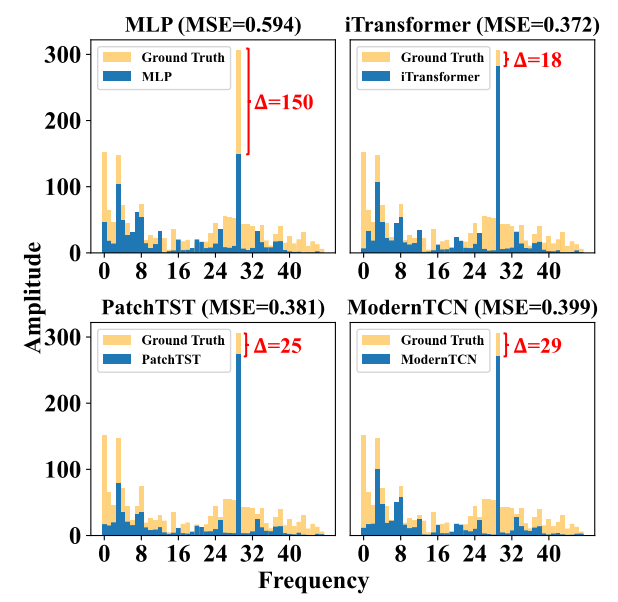
MLP因難以捕獲時間序列的多尺度趨勢和周期性模式導致預測偏差。實驗顯示,教師模型在粗粒度趨勢(如尺度3)和主頻周期性上表現優異,而MLP顯著落后。因此,需通過知識蒸餾將教師模型的這些互補模式引入MLP,以提升其時間序列預測能力。
時間序列中的周期性在頻域中通過將時間序列轉換為頻譜圖來顯現,其中x軸表示頻率,周期性計算為時間序列長度 S 除以頻率。
下采樣(Downsampling)?是指通過降低時間序列的分辨率(如減少數據點的數量),提取更粗粒度的數據表示。其核心目的是捕捉數據的宏觀趨勢或長期依賴,同時過濾掉高頻噪聲或細節波動。常用方法包括:
- 平均池化:將相鄰多個數據點取平均,合并為一個點。
- 最大/最小池化:取相鄰點的最大值或最小值。
- 卷積操作:使用低通濾波器(如移動平均)平滑數據后,按步長跳過部分點。
知識蒸餾(KD)在時間序列中的演進
1???傳統KD(Hinton, 2015): 核心:將復雜教師模型的知識遷移至輕量學生模型 局限:依賴輸出分布對齊,未針對時序特性設計
2???時序領域現有方法: CAKD(Xu等, 2022):結合對抗學習+對比學習的兩階段蒸餾(特征級+預測級) LightTS(Campos等, 2023):專為集成分類器設計,架構兼容性差 ? 共性缺陷:未聚焦時序特有模式(如多尺度、多周期)
3???本文創新: 時序模式蒸餾:顯式提取多尺度(時間域)與多周期(頻域)關鍵模式 跨架構突破:首次實現異構模型間KD(如Transformer→MLP),解決架構差異挑戰 (對比:傳統KD通用但粗放 → 本文定向提煉時序核心規律 + 跨架構兼容性)
方法
背景與目標
????????提出了一個新穎的知識蒸餾(KD)框架 TIMEDILL,用于時間序列。其核心思想是將知識從一個固定的、預訓練的教師模型?轉移到學生 MLP 模型?
?。
模型結構
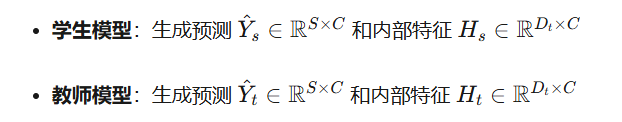
優化目標
整個框架的優化目標是通過監督損失和知識蒸餾損失
和
來最小化學生模型的預測誤差和特征誤差。

pipeline
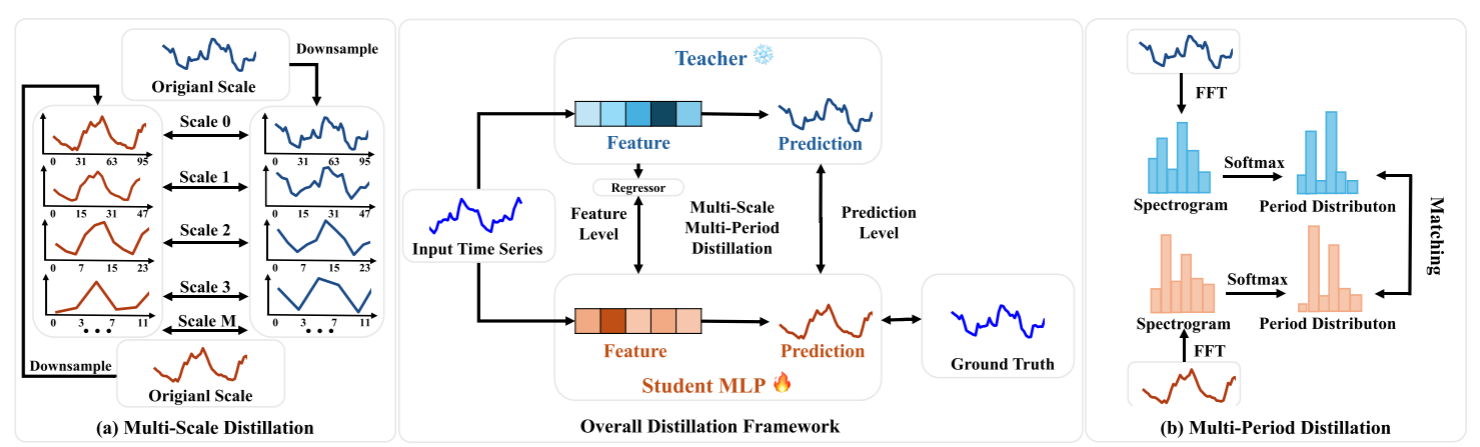
(a)多尺度蒸餾涉及將原始時間序列下采樣為多個較粗尺度,并在學生和教師之間調整這些尺度。
(b)多周期蒸餾應用FFT將時間序列轉換為譜圖,然后在應用softmax之后匹配周期分布。
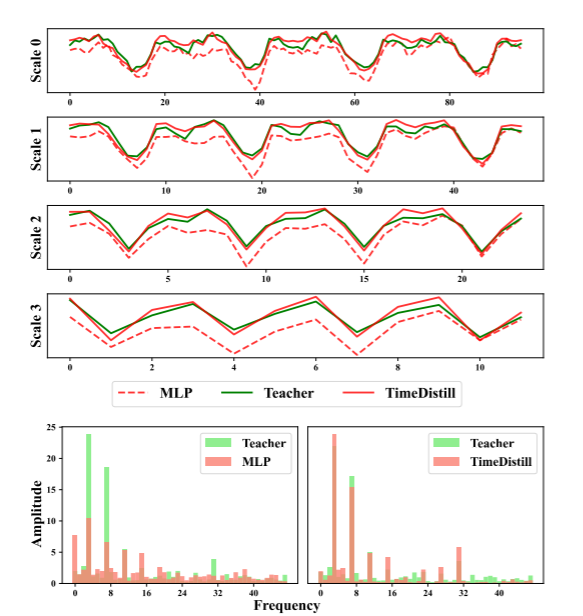
解釋圖(a)
????????多尺度蒸餾的過程,用于將教師模型的多尺度模式知識轉移到學生模型中 教師模型和學生模型的比較:
- 教師模型(藍色曲線)在所有尺度上都能較好地捕捉時間序列的趨勢和模式。
- 學生模型(棕色曲線)在較細的尺度(如Scale 0)上可能表現較好,但在較粗的尺度(如Scale 3)上表現較差,顯示出其在處理多尺度模式上的局限性。
多尺度蒸餾
核心概念
TimeDistill 的核心組件之一是多尺度蒸餾,通過不同采樣率表示同一時間序列,使 MLP 能有效捕捉粗粒度和細粒度模式。通過預測級別和特征級別的聯合蒸餾,確保 MLP 不僅復現教師模型的多尺度預測,還能對齊其中間層的內部表示。


多周期蒸餾
預測層面

特征層面


總體優化與理論分析
總體訓練損失

理論解釋
????????從數據增強的角度理解多尺度和多周期蒸餾損失,其類似于mixup策略。這種蒸餾方法通過混合真實值和教師預測來增強數據,為時間序列預測帶來以下好處:增強泛化能力、顯式整合模式、穩定訓練動態。這些優勢有助于減輕過擬合、提供隱藏模式見解,并支持更平滑的優化和更好的收斂。
- ????????通過同時優化監督損失(學生直接學真實值)和多尺度蒸餾損失(學生學教師的多尺度特征),實際上就相當于在優化這些“增強樣本”上的損失。
- ????????通過同時優化監督損失(學生直接學真實值的周期分布)和多周期蒸餾損失(學生學教師的周期分布),實際上就相當于在優化這些“增強樣本”上的KL散度損失。 好處:這種混合策略讓學生的訓練目標更平滑,幫助它更好地捕捉周期性模式,從而提高預測的穩定性。
想象一下,你在教一個學生做數學題,但直接教他可能會有些吃力。于是,你決定用一種特別的方法來輔助教學:把原題(原始數據)和標準答案(教師模型的預測)混合起來,形成一個“增強版”的題目。同時,你希望學生不僅能做對原題(監督損失),還能從標準答案里學到解題思路(周期蒸餾損失)。

實驗
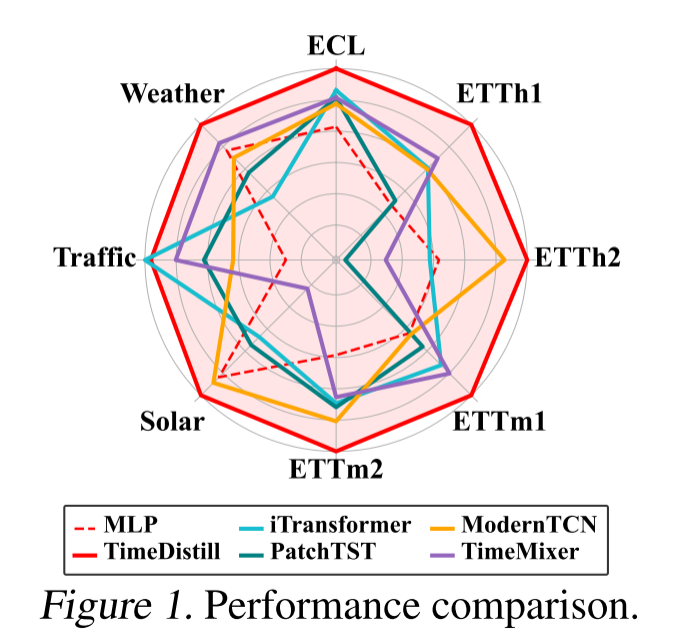
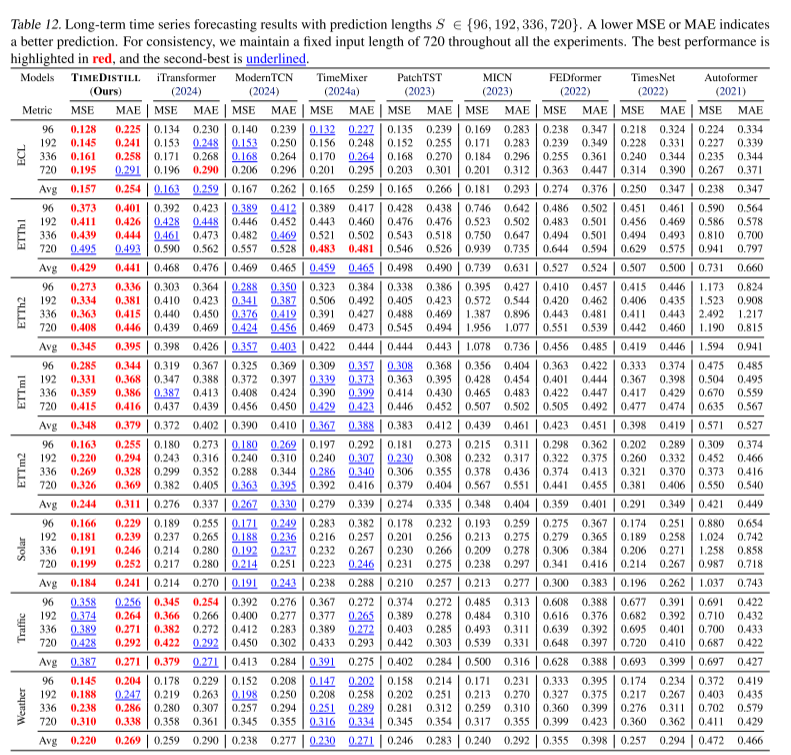
效果全面領先
TimeDistill在8個時序數據集上進行實驗,其中7個數據集的MSE指標優于基線教師模型,在所有數據集的MAE指標上均取得最佳表現,展現出卓越的預測能力。
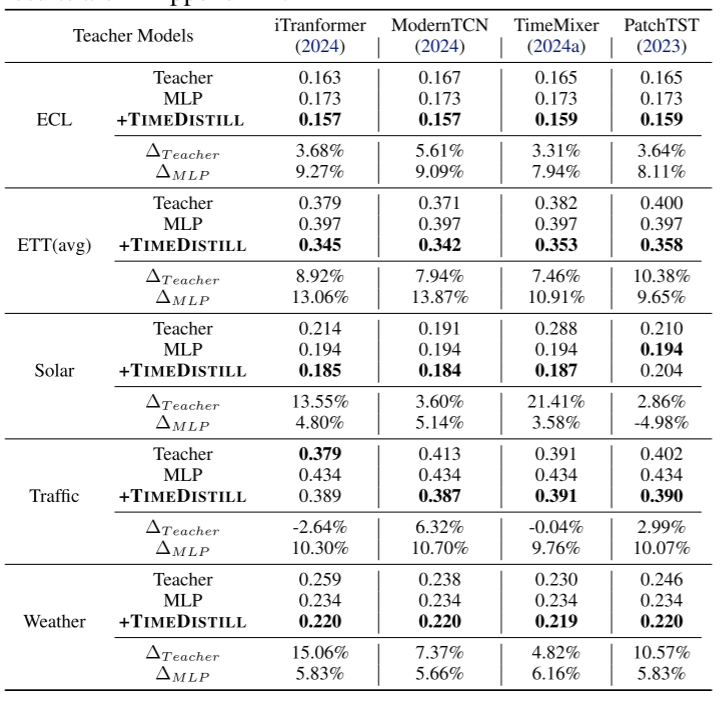
兼容多種教師模型
TimeDistill適用于多種教師模型,能夠有效蒸餾知識并提升MLP學生模型的性能,同時相較教師模型本身也有顯著提升。
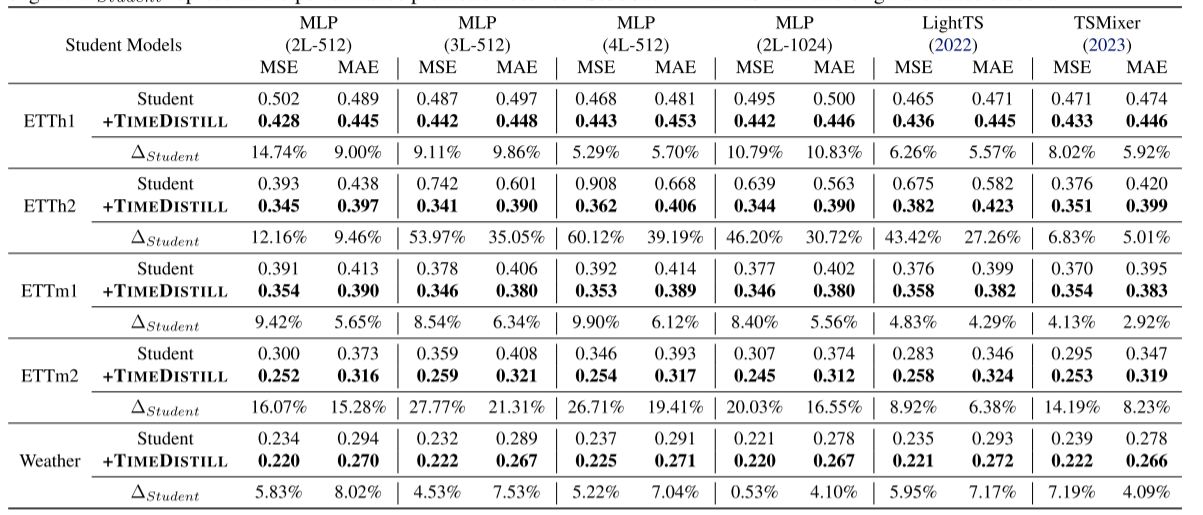
兼容多種學生模型
TimeDistill不僅適用于 MLP 結構,還可以增強輕量級學生模型的性能。例如,在以ModernTCN作為教師模型的實驗中,TimeDistill使兩個輕量模型TSMixer和LightTS的MSE分別降低6.26%和8.02%,驗證了其在不同學生模型上的適應性。
兼容多種回溯窗口長度
時序模型的預測性能往往隨回溯窗口(歷史觀測長度)變化而波動,而 TimeDistill在所有窗口長度下均能提升MLP表現,甚至超越教師模型,體現出對不同時間依賴模式的強大適應能力。
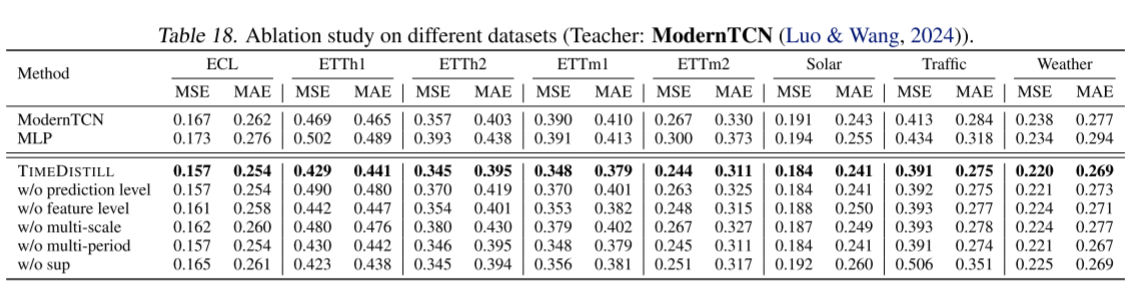
消融實驗
TimeDistill通過消融實驗進一步驗證了模型設計的合理性。值得注意的是,即使去掉Ground Truth監督信號(w/o sup),TimeDistill仍然能夠顯著提升MLP預測精度,表明其可以從教師模型中有效學習到豐富的知識。
idea
從先進的時間序列模型中提取,例如時間序列基礎模型,并結合多變量模式。













在視頻模型中的幀間依賴建模)





