
背景需求:
檢查自即,需要AI一下院內的五次科研培訓記錄。
本次用了豆包

豆包寫的不錯,也是“水字數”的高手
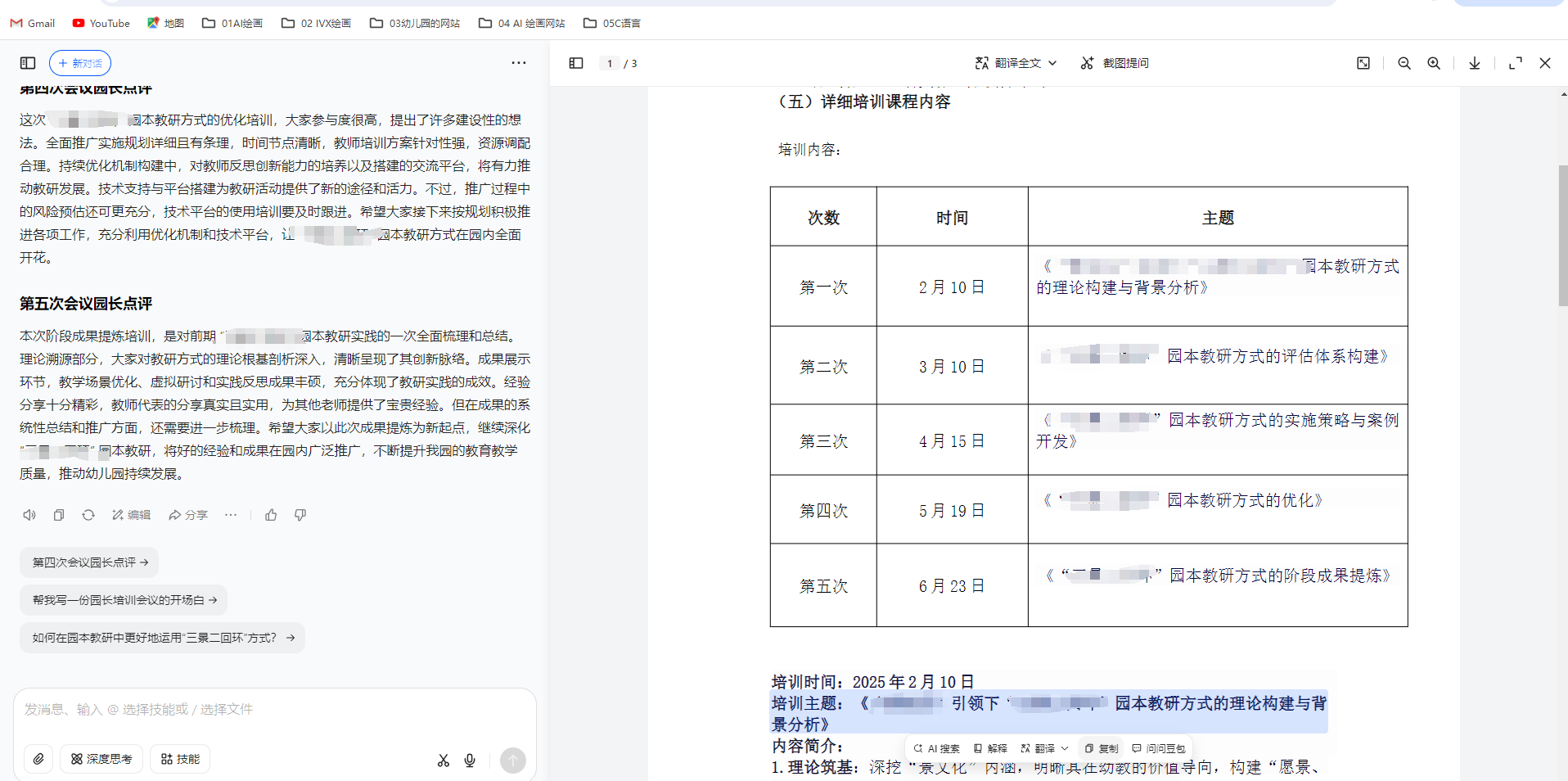
把每次培訓內容貼到WORD里
把AI資料貼到WORD里,發現問題:
1、字體、段落什么都是不統一的,需要統一改成宋體小四,1.5倍行距

2、十個研討人也要改成真人。就找了一份所有老師姓名的名單:做成列表,隨機抽取10個不重復的名字。
用deepseek寫,大致思路就是:
1、讀取00原始文件夾下所有docx,然后清除格式,清除空行、清除空格,
2、把清除格式的文字改成“宋體、小四、1.5行距”,首行縮進2字符(這個實現不了,就是默認段前輸入4個英文字符空格)

3、把教師A-教師F(單行)與下一段文字,用“:”組合
4、獲取幼兒園教師的名單(列表),隨機抽取10個不重復名字,逐一替換掉教師A、教師B……
5、把第一行“科研記錄”改成黑體三號居中,同時清除段前的4個英文空格(用替換)
6、把一些一級標題、二級標題加粗,清除段前的4個英文空格(用替換)

7、添加頁眉“XXX幼兒園”,整段邊框下劃線
……
以上這些反復調試很久,調了快5個小時,太累了。過程就不放圖了,就直接上代碼吧。(只適合本次AI的文字結構,下次再AI要調參數的)
'''
對AI的研討資料,清除格式,統一段落、字體大小、將教師A替換成名單里的隨機名字,,將首行縮進(填寫4個英文字符)
將一些一級標題、二級標題,加粗。
deepseek、阿夏
20250429
'''# import os
# import re
# import time
# import random
# import shutil
# from docx import Document
# from win32com import client as wc
# import openpyxl
# from docx.shared import Pt # 導入Pt單位
# from docx.enum.text import WD_PARAGRAPH_ALIGNMENT # 導入對齊方式枚舉
# from win32com import client as wc
# from docx.oxml.ns import qn # 新增導入用于中文字體
# from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
# from docx.shared import Pt, RGBColor
# from docx.oxml.ns import qn
# from docx.oxml import OxmlElement
# from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
# from docx.enum.table import WD_TABLE_ALIGNMENT
import os
import re
import time
import random
import shutil
from docx import Document
from win32com import client as wc
import openpyxl
from docx.shared import Pt
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.oxml.ns import qn
from docx.oxml import OxmlElement
from docx.shared import RGBColor
from docx.enum.table import WD_TABLE_ALIGNMENT# from docx.enum.border import WD_BORDERdef get_random_names(excel_path):"""從Excel B列讀取所有名字"""wb = openpyxl.load_workbook(excel_path)sheet = wb.activenames = []# 讀取B列內容(從B2開始,跳過空單元格)for row in sheet.iter_rows(min_row=2, min_col=2, max_col=






)








的內容模型)
![52.[前端開發-JS實戰框架應用]Day03-AJAX-插件開發-備課項目實戰-Lodash](http://pic.xiahunao.cn/52.[前端開發-JS實戰框架應用]Day03-AJAX-插件開發-備課項目實戰-Lodash)

