大家讀完覺得有幫助記得關注和點贊!!!
摘要
隨著無人機(UAV)和計算機視覺技術的快速發展,從無人機視角進行目標檢測已成為一個重要的研究領域。然而,無人機圖像中目標像素占比極小、物體尺度變化顯著以及背景信息復雜等問題給檢測帶來了挑戰,極大地限制了無人機的實際應用。為了解決這些挑戰,我們提出了一種新的目標檢測網絡,即多尺度上下文聚合和尺度自適應融合YOLO(MASF-YOLO),該網絡是基于YOLOv11開發的。首先,為了解決無人機圖像中小目標檢測的難題,我們設計了一個多尺度特征聚合模塊(MFAM),該模塊通過并行多尺度卷積和特征融合,顯著提高了小目標的檢測精度。其次,為了減輕背景噪聲的干擾,我們提出了一種改進的有效多尺度注意力模塊(IEMA),該模塊通過特征分組、并行子網絡和跨空間學習,增強了對目標區域的關注。第三,我們引入了一個維度感知選擇性集成模塊(DASI),該模塊通過自適應地加權和融合低維特征和高維特征,進一步增強了多尺度特征融合能力。最后,我們在VisDrone2019數據集上對我們提出的方法進行了廣泛的性能評估。與YOLOv11-s相比,MASF-YOLO-s在VisDrone2019驗證集上實現了mAP@0.5提升4.6%,mAP@0.5:0.95提升3.5%。值得注意的是,MASF-YOLO-s的性能優于YOLOv11-m,同時僅需要大約60%的參數和65%的計算成本。此外,與最先進的檢測器進行的對比實驗證實,MASF-YOLO-s在檢測精度和模型效率方面都保持著明顯的競爭優勢。
一、 引言
近年來,無人機(UAV)和深度學習技術的快速發展給農業、應急救援和交通監控等多個領域帶來了革命性的變化[1],[2],[3]。無人機憑借其靈活性、成本效益以及進入難以到達區域的能力,已成為數據收集和實時決策的重要工具。同時,深度學習算法在處理復雜的遙感圖像數據方面表現出優于傳統方法的性能,使無人機能夠以更高的效率執行目標檢測和分割等任務。無人機和深度學習的結合為各個領域的信息收集提供了創新的解決方案。
通過空中視覺進行目標檢測是無人機任務中的一個關鍵環節。目前,基于深度學習的圖像目標檢測方法主要可分為兩階段目標檢測算法和單階段目標檢測算法。兩階段目標檢測算法通過“區域提議”和“分類回歸”兩個階段實現目標檢測。代表性算法包括Fast R-CNN [4]、Faster RCNN [5]和Mask R-CNN [6]。它們的優勢在于高精度和多任務能力:通過精細的區域提議和分類回歸。它們的缺點包括計算復雜度高和實時性差,使其不太適合對速度要求高的應用。相比之下,單階段檢測算法在單個前向傳遞中完成目標分類和定位,從而顯著提高了檢測速度。代表性的單階段檢測算法包括YOLO系列[7]、[8]、[9]和SSD [10]。YOLO通過將圖像劃分為網格來實現端到端檢測,其中每個網格負責預測目標的位置和類別。相比之下,SSD采用多尺度特征圖進行檢測,集成了一種錨機制,以有效滿足不同尺度目標的檢測需求。受益于其快速的檢測速度,能夠實現實時推理,單階段檢測器已被廣泛采用作為無人機應用、自動駕駛和其他時間關鍵型系統的首選解決方案。然而,仍需要進一步改進以提高其在復雜場景中的性能。
盡管無人機遙感目標檢測在許多任務中取得了成就,但它仍然面臨著許多技術挑戰。首先,由于無人機拍攝距離較遠,大多數目標在圖像中所占像素比例極小,導致特征提取困難,容易導致漏檢或誤檢。其次,圖像中復雜多樣的噪聲增加了檢測的難度。此外,由于無人機拍攝角度的變化,圖像中物體尺度和形狀的顯著變化進一步復雜化了檢測。此外,在無人機任務中,還需要輕量化和高速的檢測模型。因此,解決這些挑戰是提高無人機目標檢測效率和魯棒性的關鍵途徑。這些研究對于無人機相關應用領域具有重要的理論和實踐價值。
為了應對這些挑戰,本文提出了一種高精度算法,該算法維護了一個輕量級框架,專門為無人機圖像中的小目標檢測而設計,命名為MASF-YOLO。通過嚴格的實證分析和實驗驗證,我們系統地論證了我們的方法中針對此特定任務而包含的多種創新設計概念的有效性。
更詳細地說,我們工作的創新性和貢獻可以列舉如下:
針對小目標因重復下采樣而丟失細節信息的問題,我們構建了一個高分辨率的小目標檢測層。該架構融合了P2級別的細粒度特征圖,以充分利用其保留的豐富空間細節,從而顯著增強了模型對小尺度目標的特征表示能力。此外,頸部網絡中添加了跳躍連接,以保留更多的淺層語義信息,從而有效地減輕了深層網絡中的語義信息損失。
在小目標檢測任務中,目標通常包含有限的像素信息,因此需要更豐富的上下文信息來輔助檢測。為了應對這一挑戰,我們提出了一種新的多尺度特征聚合模塊(MFAM),該模塊能夠有效地捕獲目標的豐富上下文信息。這種架構實現了更有效的特征提取,從而顯著提高了小目標的檢測精度。
[/NT0]?[/NT0] 背景噪聲一直是影響無人機應用中目標檢測性能的關鍵因素。為了有效抑制這種干擾,我們提出了一種改進的高效多尺度注意力模塊(IEMA),其中通過特征分組、并行子網絡和跨空間學習來實現特征交互和增強。它有效地改善了目標區域的特征表示,同時顯著抑制了背景噪聲的干擾,從而提高了復雜場景中的目標檢測性能。
【NT0】?【/NT0】 為了克服無人機(UAV)中小目標檢測中的多尺度特征融合挑戰,我們引入了維度感知選擇性整合模塊(Dimension-Aware Selective Integration Module,DASI),以自適應地融合低維特征和高維特征。它顯著提高了頸部網絡的多尺度表示能力,從而增強了檢測性能。
二、相關工作
A. 無人機遙感目標檢測
與傳統圖像不同,遙感圖像通常從自上而下的角度捕獲,導致目標呈現出任意方向和顯著的尺度變化。這些特性使得為傳統圖像設計的傳統目標檢測方法在處理遙感圖像時效果較差。為了解決這些局限性,研究人員從各個角度改進了這些方法,以更好地適應遙感圖像的獨特屬性。為了解決尺度變化問題,LSKNet [11] 引入了一種大型選擇性內核機制,以動態調整空間感受野,從而更好地建模目標上下文信息。對于小目標檢測,Chen et al. [13] 提出了一種高分辨率特征金字塔網絡 (HR-FPN),以提高小尺度目標的檢測精度,同時避免特征冗余。為了減輕背景干擾,FFCAYOLO [14] 構建了一個空間上下文感知模塊 (SCAM),以建模目標的全局上下文,從而抑制不相關的背景信息并突出目標特征。
B. 上下文特征表示
在計算機視覺任務中,圖像中的對象與其周圍環境密切相關。適當的上下文特征表示可以有效地建模局部和全局信息,從而增強模型的檢測能力。為了捕獲長距離依賴關系,同時避免過度的計算開銷,Guo等人[15]分解了大核卷積,并提出了一種線性注意力機制,從而在網絡性能和計算成本之間實現了平衡。Ouyang等人[16]設計了一種高效的多尺度注意力(EMA)模塊,該模塊有效地建立了短期和長期依賴關系,從而增強了模型捕獲多尺度上下文信息的能力。此外,考慮到單尺度特征在建模上下文信息方面的局限性,Xu等人[17]提出了一種多膨脹通道細化器(MDCR)模塊,該模塊通過設計多膨脹率卷積層來捕獲不同感受野大小的空間特征,從而提高了模型的多粒度語義表示能力。
C. 多尺度特征融合
作為目標檢測領域的重要里程碑之一,特征金字塔網絡(FPN)[18]開創了通過自頂向下路徑進行多尺度特征融合的先河。在FPN的基礎上,PAFPN [19]引入了一個額外的自底向上路徑,從而能夠更好地傳遞來自較低層的詳細信息。此外,BiFPN [20] 結合了可學習的權重來執行不同輸入特征的加權融合,使網絡能夠學習每個特征的重要性并實現高效的特征集成。另外,漸近特征金字塔網絡(AFPN)[21] 采用漸進式方法來逐步融合來自不同層級的特征,避免了非相鄰層級之間的語義差距。
三、提出的方法
本節將詳細闡述所提出的MASF-YOLO。MASF-YOLO網絡的總體架構如圖1所示。具體來說,我們在基線網絡中增加了一個小目標檢測層(P2層),使網絡能夠專注于檢測小目標。其次,考慮到目標尺度變化的影響,我們通過優化PKINet [12],設計了一個多尺度特征聚合模塊(MFAM)。這種特征聚合方法有助于骨干網絡捕獲豐富的上下文信息,從而提高網絡在檢測小目標方面的性能。這些融合為從早期層傳輸高分辨率空間信息建立了直接通路,有效地補償了深度網絡操作引起的語義信息損失。此外,為了減輕背景噪聲的干擾,我們提出了一個改進的高效多尺度注意力(IEMA)模塊,其靈感來自EMA [16]。這種注意力機制通過特征分組、并行子網絡和跨空間學習來實現特征交互和增強,有效地解決了背景噪聲帶來的挑戰。最后,我們引入了維度感知選擇性集成(DASI)[17]模塊,以增強頸部網絡的多尺度特征融合能力。這種融合機制自適應地聚合低維和高維特征,在提高網絡的檢測精度方面起著至關重要的作用。
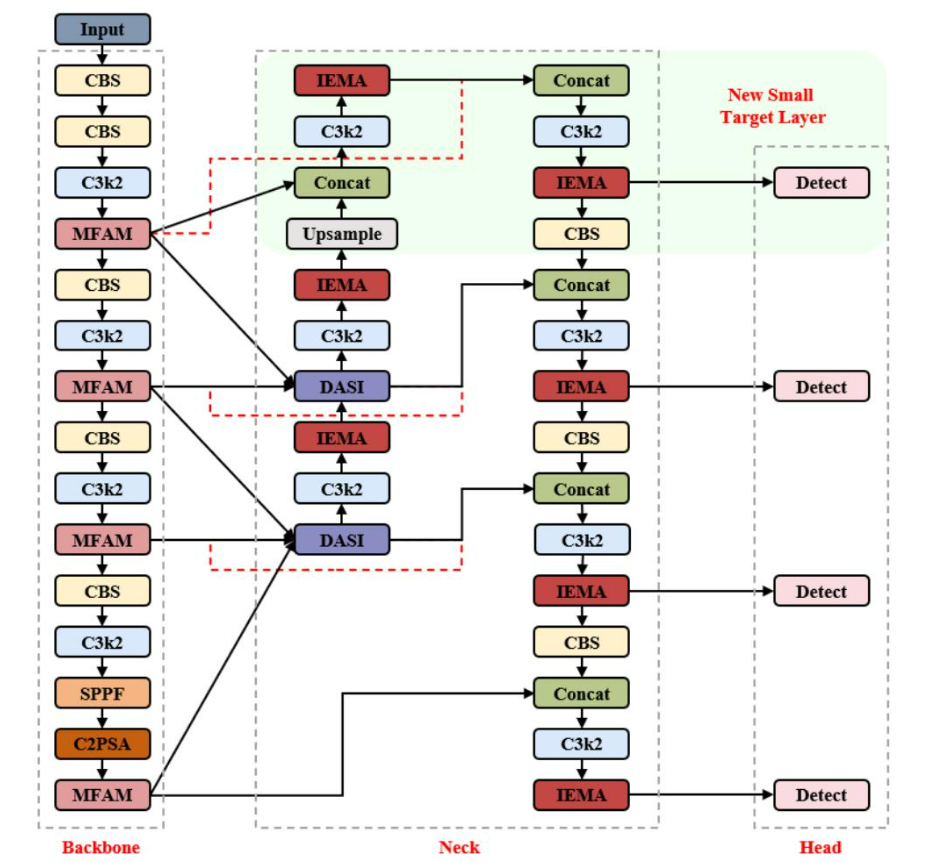
A. 多尺度特征聚合模塊 (MFAM)
與通用目標檢測不同,目標顯著的尺度變化給遙感目標檢測帶來了巨大的挑戰。具體而言,骨干網絡階段提取的有效語義信息有限,使得區分小目標與背景變得困難。為了應對這一挑戰,我們提出了MFAM來捕獲目標豐富的上下文信息,增強骨干網絡提取小目標特征的能力。MFAM的整體結構如圖2所示,它建立在PKINet [12]的基礎上,并采用了優化的設計原則。不同之處在于,MFAM模塊利用兩個條形卷積1 × k和k × 1,以達到類似于大核卷積k × k (k = 7,9) 的效果,同時移除大核卷積11 × 11,從而顯著降低計算成本。MFAM的數學表達式可以寫成如下形式:

其中,DWConvk×k表示核大小為k × k的深度可分離卷積運算。
Conv1×1表示核大小為1 × 1的標準卷積運算。符號⊕表示特征圖的逐元素相加運算。
X是輸入特征圖。Y1,Y2,Y3和Y4表示應用四種不同核大小的深度可分離卷積運算后獲得的輸出特征圖。
Z是由多尺度特征Y1,Y2,Y3,Y4和輸入特征X逐元素相加得到的特征圖。W是MFAM的輸出特征。
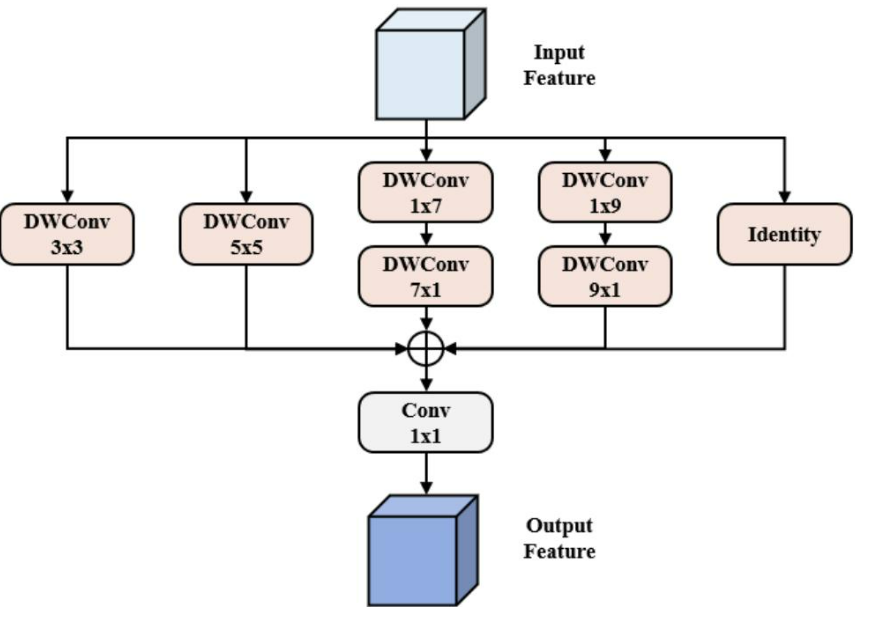
圖 2. MFAM 的結構
與PKI模塊[12]相比,MKAM通過多尺度卷積學習更豐富的上下文特征,顯著增強了小目標的檢測能力,同時保持了更輕量級的結構。
B. 改進的高效多尺度注意力機制(IEMA)
在骨干網絡中經過MFAM后,特征圖已經包含足夠的局部上下文信息。然而,背景噪聲的影響仍然對網絡的檢測性能構成重大挑戰。為了應對這一挑戰,有必要有效地建模目標與背景之間的全局關系。受EMA [16]和InceptionNeXt [22]的啟發,我們構建了IEMA模塊,如圖3所示。與EMA相比,IEMA主要通過引入多尺度深度可分離卷積來優化并行子網絡中的局部特征提取組件,包括3 × 3、1 × 5和5 × 1的卷積核,以及一個額外的恒等路徑。這種優化增強了方向特征提取,使模型能夠更有效地捕獲多尺度表示,從而改進全局目標-背景關系的建模,并加強對復雜背景干擾的抑制。同時,IEMA通過并行子網絡和跨空間學習機制保留了EMA的全局建模能力,從而促進了特征交互和增強。
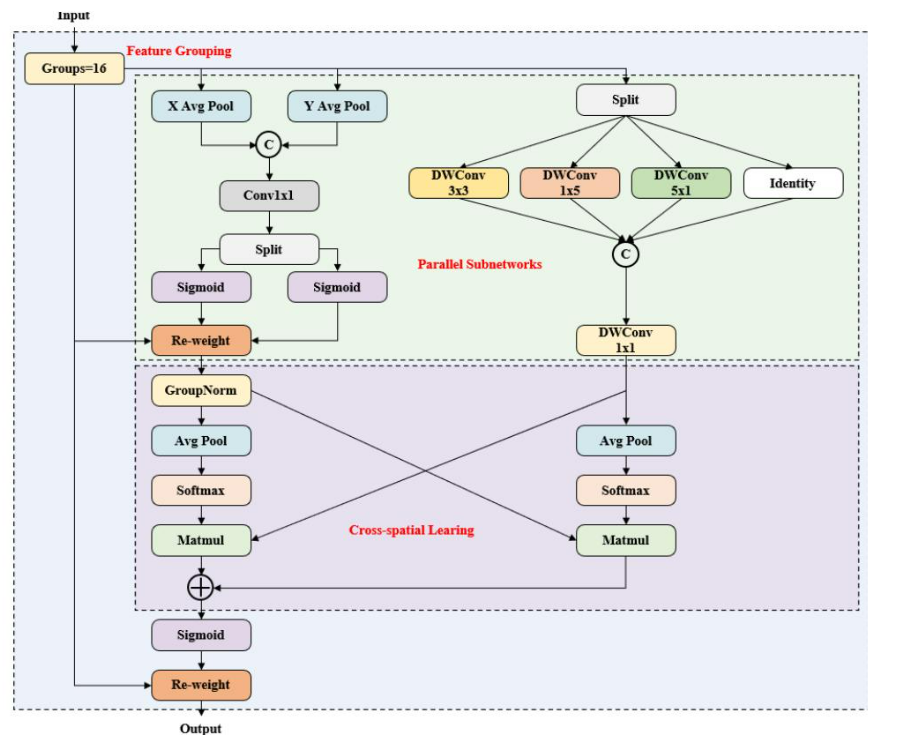
圖3. IEMA的結構
C. 維度感知選擇性整合模塊(DASI)
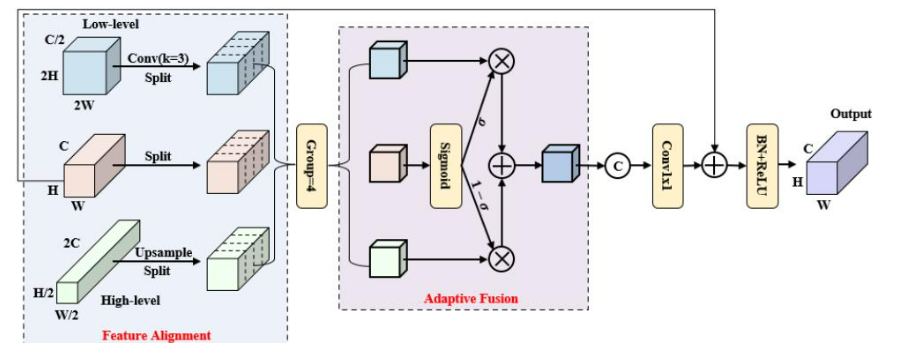
圖4. DASI的結構
在無人機遙感小目標檢測中,特征圖在骨干網絡中經過多次下采樣階段,導致高層特征丟失小目標細節,而低層特征缺乏上下文信息。多尺度特征聚合有效地融合了不同層級的語義信息,顯著提高了小目標的檢測精度。為了解決這個問題,我們引入了維度感知選擇性融合模塊(DASI)[17]。該模塊自適應地融合低維特征和高維特征。如圖4所示,DASI首先通過卷積和插值等操作,將低維和高維特征與當前層的特征對齊。然后,它將三個特征沿通道維度分成四個相等的部分,確保每個部分對應一個分區。在每個分區內,使用sigmoid激活函數獲得當前層特征的激活值,然后使用這些激活值來加權和融合低維和高維特征。通過利用當前層特征自適應地融合低維和高維特征,DASI的多尺度特征融合機制不僅提高了網絡檢測小目標的能力,還增強了其對復雜遙感場景的適應性。
四、實驗
本節首先介紹數據集、實驗設置、訓練策略,以及用于評估模型目標檢測性能的指標。然后以YOLOv11-s為基線,并通過消融實驗驗證每項創新對基線的影響。此外,我們將我們的模型與其他最先進(SOTA)的方法進行比較,以證明其具有競爭力的性能。為了便于直觀評估,我們展示了我們的方法和基線方法之間檢測結果的比較可視化,這些定性演示與定量指標顯示出很強的一致性,共同驗證了我們改進策略的有效性。
A. 數據集
VisDrone2019數據集由天津大學機器學習與數據挖掘實驗室的AISKYEYE團隊開發,是一個大規模的航拍圖像數據集,包含288個視頻片段、261,908幀以及10,209張靜態圖像,這些圖像由各種無人機在不同的場景中拍攝。該數據集覆蓋了中國14個城市,包含城市和鄉村環境,并對行人、汽車和自行車等多個目標類別進行了標注。它包括從稀疏到擁擠場景的圖像,以及不同的光照和天氣條件。由于其包含大量小目標、目標重疊和復雜背景等特點,使得檢測任務極具挑戰性。該數據集為無人機視角下的目標檢測和跟蹤研究提供了高質量的實驗資源,具有重要的學術和實踐價值。
B. 訓練集
本文提出的模型在PyTorch中實現,CUDA版本為11.3,實驗環境包括操作系統Ubuntu 20.04和NVIDIA GeForce RTX 4090D 24G顯卡。隨機梯度下降(SGD)優化器用于模型訓練。初始學習率設置為0.01,動量設置為0.937,并使用余弦退火策略動態調整學習率。訓練階段的批次大小設置為12,epoch數量設置為100。此外,在訓練階段,所有圖像都被調整為640x640像素。
C. 評估指標
為了全面評估我們提出的模型的性能,我們采用了對象檢測任務中常用的幾個關鍵指標:精確率 (P)、召回率 (R)、mAP@0.5、mAP@0.5:0.95、參數量 (Params) 和 GFLOPs。本節概述了用于計算這些指標的公式。
精確率是指正確預測為正例的實例數(TP)與所有預測為正例的實例數(TP與FP之和)的比率。TP代表正確識別的真正例的數量,而FP代表錯誤識別為正例的假正例的數量。精確率的公式如下:

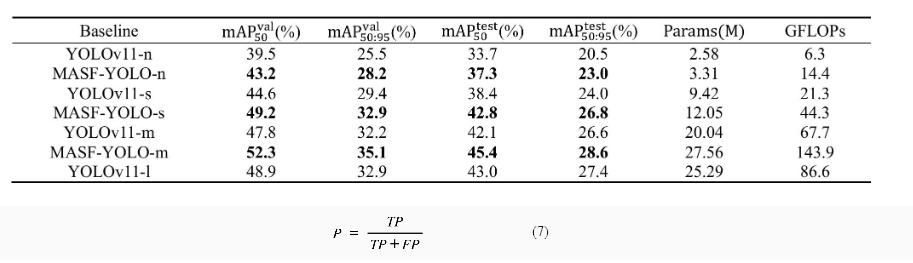
表二. YOLOv11的所有版本和MASF-YOLO在VISDRONE2019數據集上的性能比較
召回率是正確預測為正例的實例(TP)與所有實際正例實例(TP和FN之和)的比率。FN表示被錯誤識別為負例的假陰性數量。召回率的公式如下:

mAP(平均精度均值)是所有類別AP(平均精度)的平均值。在交并比(IoU)設置為常數值的情況下,類別
的平均精度是精確率-召回率(P-R)曲線下的面積。AP和mAP的公式如下:

此處,mAP@0.5是通過計算IoU閾值為0.5時的mAP獲得的,而mAP@0.5:0.95是通過平均IoU閾值從0.5到0.95(步長為0.05)范圍內的mAP值計算得到的。
D. 消融研究
為了驗證本文所提出的模型的有效性,我們選擇 YOLOv11-s 作為基線網絡,并通過消融實驗評估了 P2 層、MFAM、融合、IEMA 和 DASI 模塊對基線網絡的影響。如表 I 所示,當每個模塊添加到基線網絡時,大多數性能指標都呈現出增長的趨勢。因此,這些消融實驗驗證了本文所提出的方法的有效性。
如表二所示,通過調整網絡的深度和寬度,我們在VisDrone2019驗證集和測試集上評估了MASFYOLO和YOLOv11的不同模型尺寸。顯然,我們提出的改進策略在所有版本中都實現了最佳性能。令人驚訝的是,在將我們的貢獻應用于YOLOv11-s之后,其性能甚至超過了YOLOv11-m,這表明在無人機場景中具有卓越的精度-效率權衡。
E. 與現有技術比較
如表三所示,與最先進的目標檢測器相比,所提出的模型保持了卓越的準確性,并表現出強大的競爭力。此外,在圖 5 中,我們展示了兩個具有高度代表性的檢測結果,其中基線模型遺漏的小目標(但 MASF-YOLO-s 成功檢測到的小目標)用紅色邊界框突出顯示。 可以觀察到,MASF-YOLO-s 實現了明顯更準確的檢測。
表三. 不同目標檢測器在THEVISDRONE2019驗證數據集上的比較結果
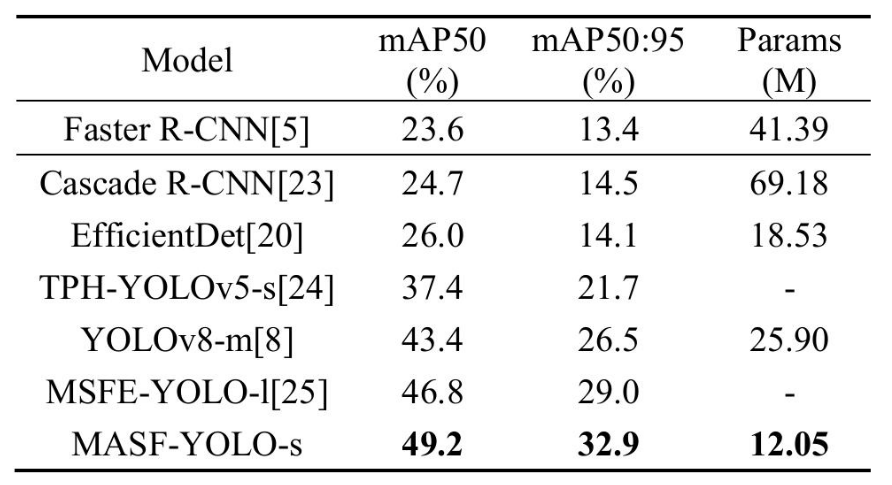

圖 5. YOLOv11-s(奇數行)和 MASF-YOLO-s(偶數行)在 VisDrone2019 上的比較。
五、結論
在這項工作中,我們通過多項增強措施提高了無人機遙感中小目標檢測的準確性。首先,我們引入了一個小目標檢測層,顯著提高了網絡檢測小目標的能力。其次,我們將MFAM模塊嵌入到骨干網絡中,以提取目標豐富的上下文信息。此外,跳躍連接被整合到頸部網絡中,以保留淺層語義并減少深層網絡的信息損失。再者,采用IEMA模塊來增強特征表示,同時減少背景噪聲干擾。最后,采用DASI模塊自適應地融合低級和高級特征,提高頸部網絡的特征融合能力。實驗結果驗證了這種改進策略的有效性和潛力,為進一步研究小目標檢測提供了有價值的見解。



接口測試)



】)











