
?? 歡迎大家來到景天科技苑??
🎈🎈 養成好習慣,先贊后看哦~🎈🎈
🏆 作者簡介:景天科技苑
🏆《頭銜》:大廠架構師,華為云開發者社區專家博主,阿里云開發者社區專家博主,CSDN全棧領域優質創作者,掘金優秀博主,51CTO博客專家等。
🏆《博客》:Rust開發,Python全棧,Golang開發,云原生開發,PyQt5和Tkinter桌面開發,小程序開發,人工智能,js逆向,App逆向,網絡系統安全,數據分析,Django,fastapi,flask等框架,云原生K8S,linux,shell腳本等實操經驗,網站搭建,數據庫等分享。所屬的專欄:Rust語言通關之路
景天的主頁:景天科技苑

文章目錄
- 通用集合類型
- 1、vector
- 1.1 創建 Vector
- 1.2 添加/更新元素
- 1.3 丟棄 vector 時也會丟棄其所有元素
- 1.4 訪問vector元素
- 1.5 無效引用
- 1.6 遍歷 vector 中的元素
- 1.7 使用枚舉來儲存多種類型
- 1.8 vector容量管理
- 1.9 vector 與其他集合轉換
- 1.10 vector 常用方法
- 2、Rust字符串
- 2.1 什么是字符串?
- 2.2 新建字符串
- 1)String::new()創建
- 2)通過字符串字面量 to_string()創建
- 3)使用 String::from 創建 String
- 4)使用 to_owned 方法
- 5)r#原字符串
- 2.3 字符串操作
- 1)追加內容
- 2)連接字符串
- 3)字符串長度
- 4)遍歷字符串
- 2.4 字符串索引和切片
- 2.5 字符串常用方法
- 1)檢查方法
- 2)轉換方法
- 3)分割和拼接
- 4)替換和修剪
- 2.6 字符串與其它類型的轉換
- 1)數字與字符串
- 2)路徑與字符串
- 2.7 字符串格式化
- 1)使用 format! 宏
- 2)使用 println! 宏
- 2.8 處理 UTF-8 字符串
- 3、 hashmap 儲存鍵值對
- 3.1 HashMap 簡介
- 3.2 創建 HashMap 的多種方式
- 1)使用 new() 創建
- 2)使用 with_capacity() 預分配空間
- 3)從元組向量創建
- 4)從數組創建創建
- 5)使用迭代器創建
- 3.3 插入和更新值
- 1)基本插入
- 2)更新已有值
- 3)只在鍵不存在時插入
- 4)根據舊值更新一個值
- 3.4 訪問值
- 1)使用 get 方法
- 2)使用 get_mut 獲取可變引用
- 3)遍歷hashmap
- 3.5 刪除操作
- 1)使用 remove 刪除
- 2)使用 remove_entry 刪除并返回鍵值對
- 3.6 哈希算法選擇
- 3.7 HashMap的其他一些常見用法
- 1)獲取長度 - len()
- 2)檢查是否為空 - is_empty()
- 3)清空 HashMap - clear()
- 4)獲取鍵或值的集合
- 5)檢查鍵是否存在
通用集合類型
Rust 標準庫中包含一系列被稱為 集合(collections)的非常有用的數據結構。
大部分其他數據類型都代表一個特定的值,不過集合可以包含多個值。
不同于內建的數組和元組類型,這些集合指向的數據是儲存在堆上的,這意味著數據的數量不必在編譯時就已知并且可以隨著程序的運行增長或縮小。
每種集合都有著不同能力和代價,而為所處的場景選擇合適的集合則是你將要始終成長的技能。
在這一章里,我們將詳細的了解三個在 Rust 程序中被廣泛使用的集合:
vector: 允許我們一個挨著一個地儲存一系列數量可變的值
字符串(string):是一個字符的集合。我們之前見過 String 類型,不過在本文我們將深入了解。
哈希 map(hash map):允許我們將值與一個特定的鍵(key)相關聯。這是一個叫做 map 的更通用的數據結構的特定實現。
1、vector
Vector (通常寫作 Vec<T>) 是 Rust 標準庫中最常用的集合類型之一,它是一個可增長的、堆分配的數組類型。
vector 允許我們在一個單獨的數據結構中儲存多于一個的值,它在內存中彼此相鄰地排列所有的值。
vector 只能儲存相同類型的值。它們在擁有一系列項的場景下非常實用。
1.1 創建 Vector
使用 Vec::new() 創建空 Vector
let mut v: Vec<i32> = Vec::new(); // 需要類型注解,因為還沒有插入元素,Rust 并不知道我們想要儲存什么類型的元素。
這是一個非常重要的點。vector 是用泛型實現的。你需要知道的就是 Vec 是一個由標準庫提供的類型,它可以存放任何類型,而當 Vec 存放某個特定類型時,那個類型位于
尖括號中。這里我們告訴 Rust v 這個 Vec 將存放 i32 類型的元素。
在更實際的代碼中,一旦插入值 Rust 就可以推斷出想要存放的類型,所以你很少會需要這些類型注解。
更常見的做法是使用初始值來創建一個 Vec ,而且為了方便 Rust 提供了 vec! 宏。這個宏會根據我們提供的值來創建一個新的 Vec 。
let v = vec![1, 2, 3]; // 自動推斷為 Vec<i32>
let v = vec![0; 5]; // 創建包含5個0的vector: [0, 0, 0, 0, 0]
1.2 添加/更新元素
添加元素
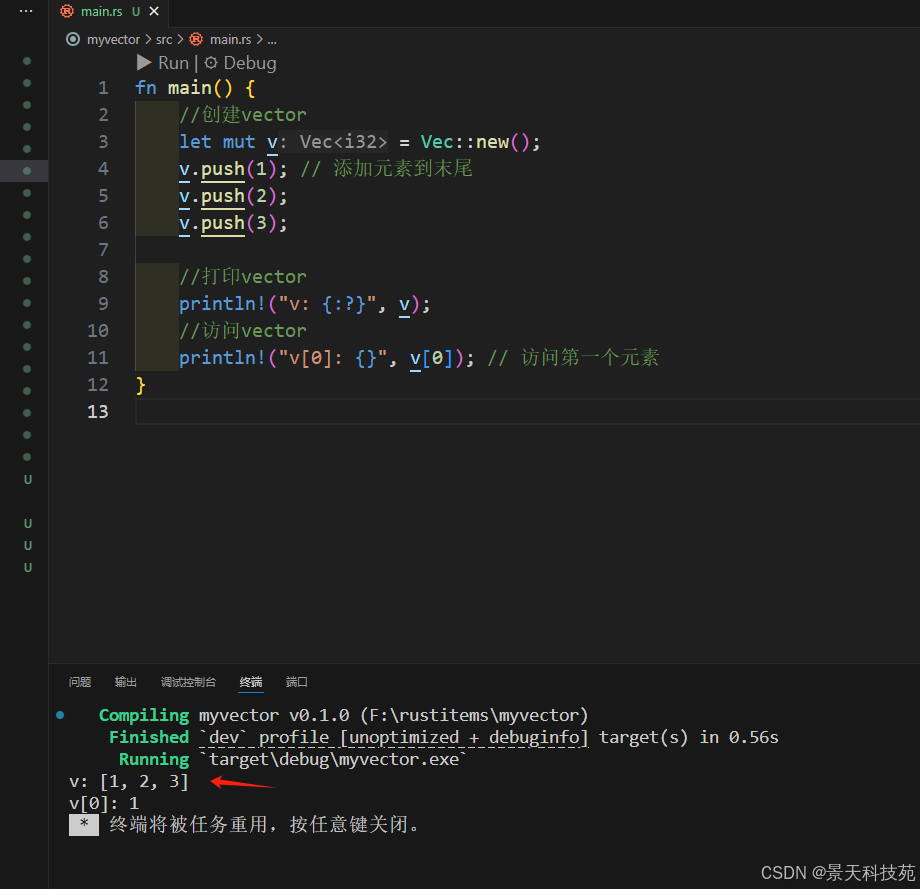
對于新建一個 vector 并向其增加元素,可以使用 push 方法
let mut v = Vec::new();
v.push(1); // 添加元素到末尾
v.push(2);
v.push(3);
更新 Vector
除了 push 方法外,還有:
insert: 在某個位置插入元素
remove: 移出指定索引的元素
pop: 移出并返回最后一個元素
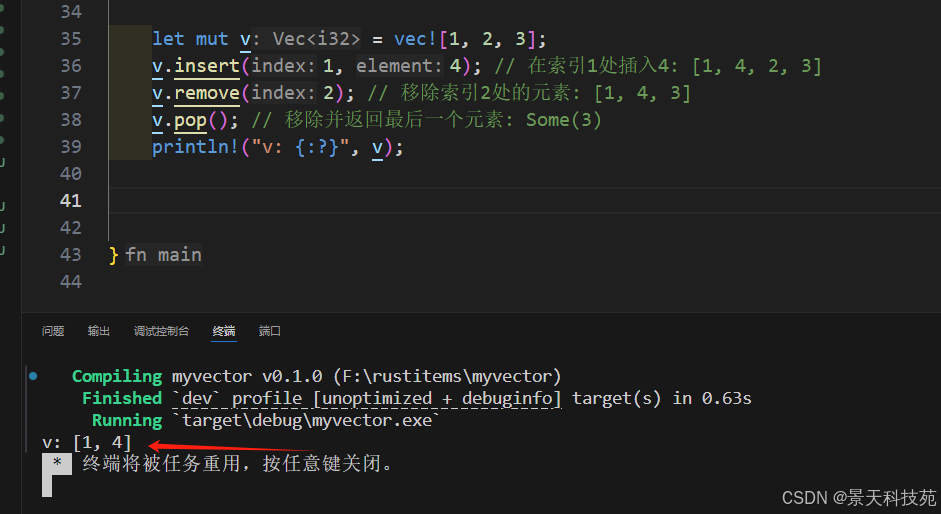
let mut v = vec![1, 2, 3];
v.insert(1, 4); // 在索引1處插入4: [1, 4, 2, 3]
v.remove(2); // 移除索引2處的元素: [1, 4, 3]
v.pop(); // 移除并返回最后一個元素: Some(3)
println!("v: {:?}", v);
1.3 丟棄 vector 時也會丟棄其所有元素
類似于任何其他的 struct ,vector 在其離開作用域時會被釋放
{let v = vec![1, 2, 3, 4];// do stuff with v
} // <- v goes out of scope and is freed here
當 vector 被丟棄時,所有其內容也會被丟棄,這意味著這里它包含的整數將被清理。
這可能看起來非常直觀,不過一旦開始使用 vector 元素的引用,情況就變得有些復雜了。
1.4 訪問vector元素
有兩種方法引用 vector 中儲存的值。為了更加清楚的說明這個例子,我們標注這些函數返回的值的類型。
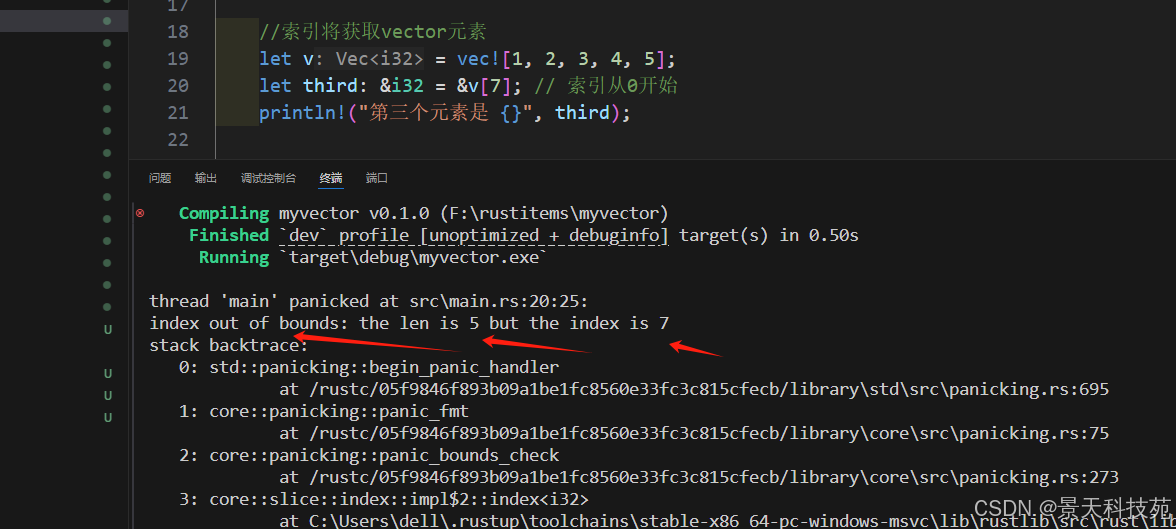
1)使用索引語法
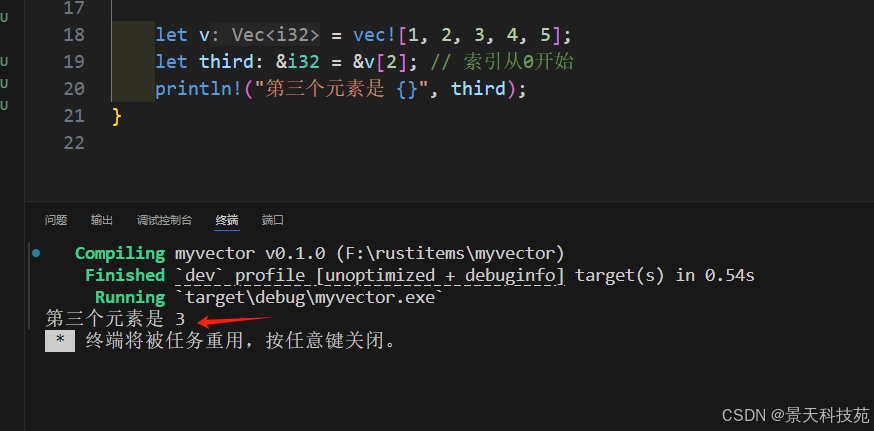
let v = vec![1, 2, 3, 4, 5];
let third: &i32 = &v[2]; // 索引從0開始
println!("第三個元素是 {}", third);
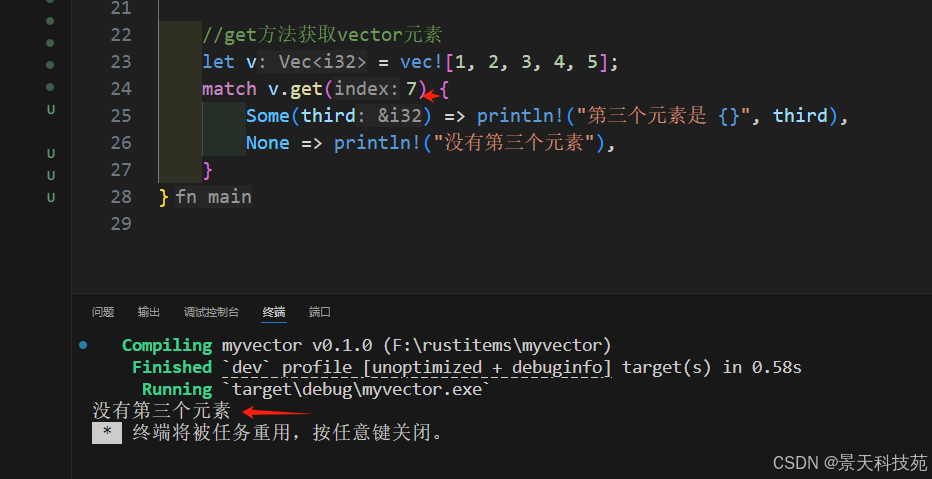
2)使用 get 方法
通過match結合 get(索引)獲取
當 get 方法被傳遞了一個數組外的索引時,它不會 panic 而是返回 None
當偶爾出現超過 vector 范圍的訪問屬于正常情況的時候可以考慮使用它。
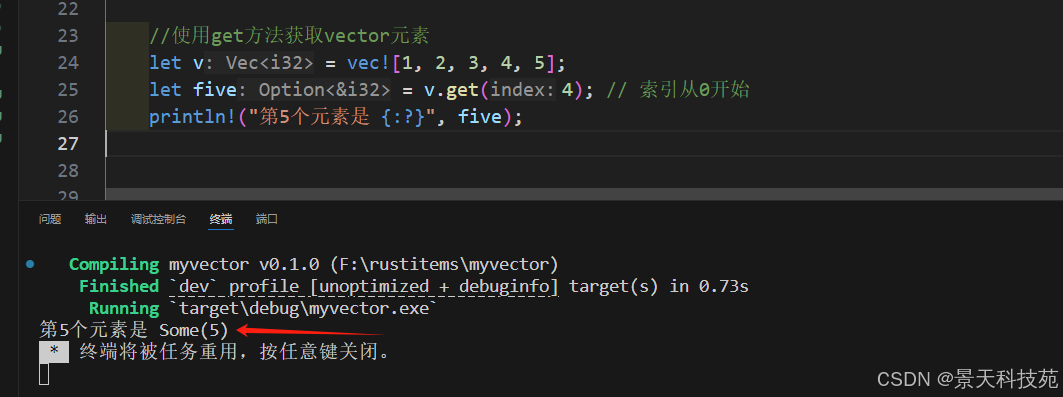
//使用get方法獲取vector元素
let v = vec![1, 2, 3, 4, 5];
let five = v.get(4); // 索引從0開始
println!("第5個元素是 {:?}", five);
得到的是個Option
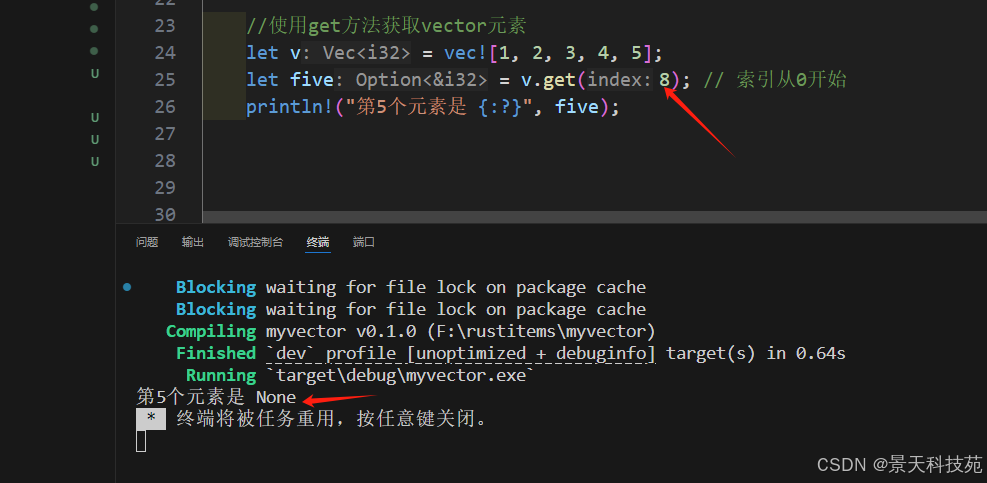
當下標越界時,不會報錯,返回None
結合match,可以獲取Option值
let v = vec![1, 2, 3, 4, 5];
match v.get(2) {
Some(third) => println!("第三個元素是 {}", third),
None => println!("沒有第三個元素"),
}
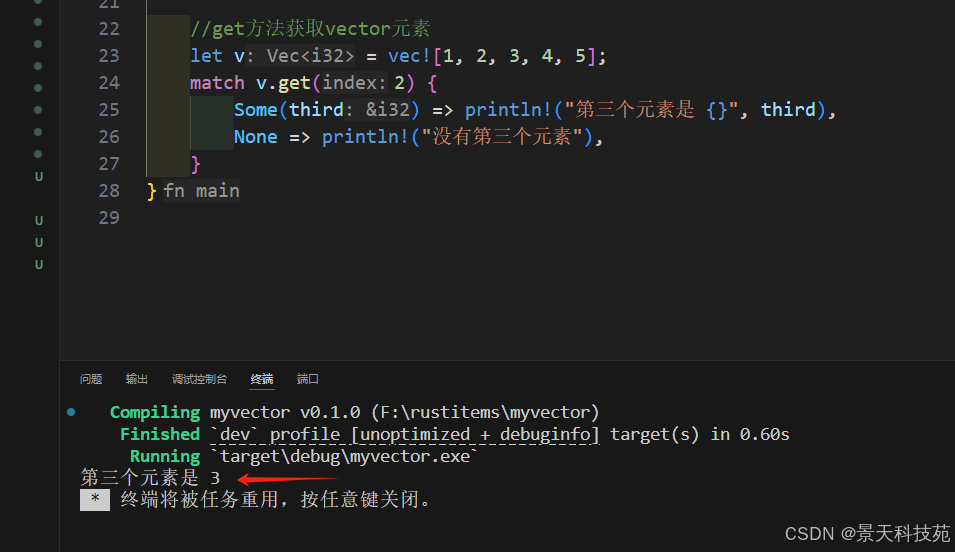
索引獲取與get方法獲取的區別
索引語法在越界時會 panic,而 get 方法返回 Option。
使用索引獲取,下標越界報錯
get方法越界返回None
1.5 無效引用
一旦程序獲取了一個有效的引用,借用檢查器將會執行所有權和借用規則來確保 vector 內容的這個引用和任何其他引用保持有效。
當我們獲取了 vector 的第一個元素的不可變引用,并嘗試在 vector 末尾增加一個元素的時候,這是行不通的
//vector無效引用
let v = vec![1, 2, 3];
let first = &v[0]; // 創建一個對第一個元素的引用
v.push(4); // 錯誤:不能在有引用的情況下修改vector
println!("first: {}", first); // 使用引用
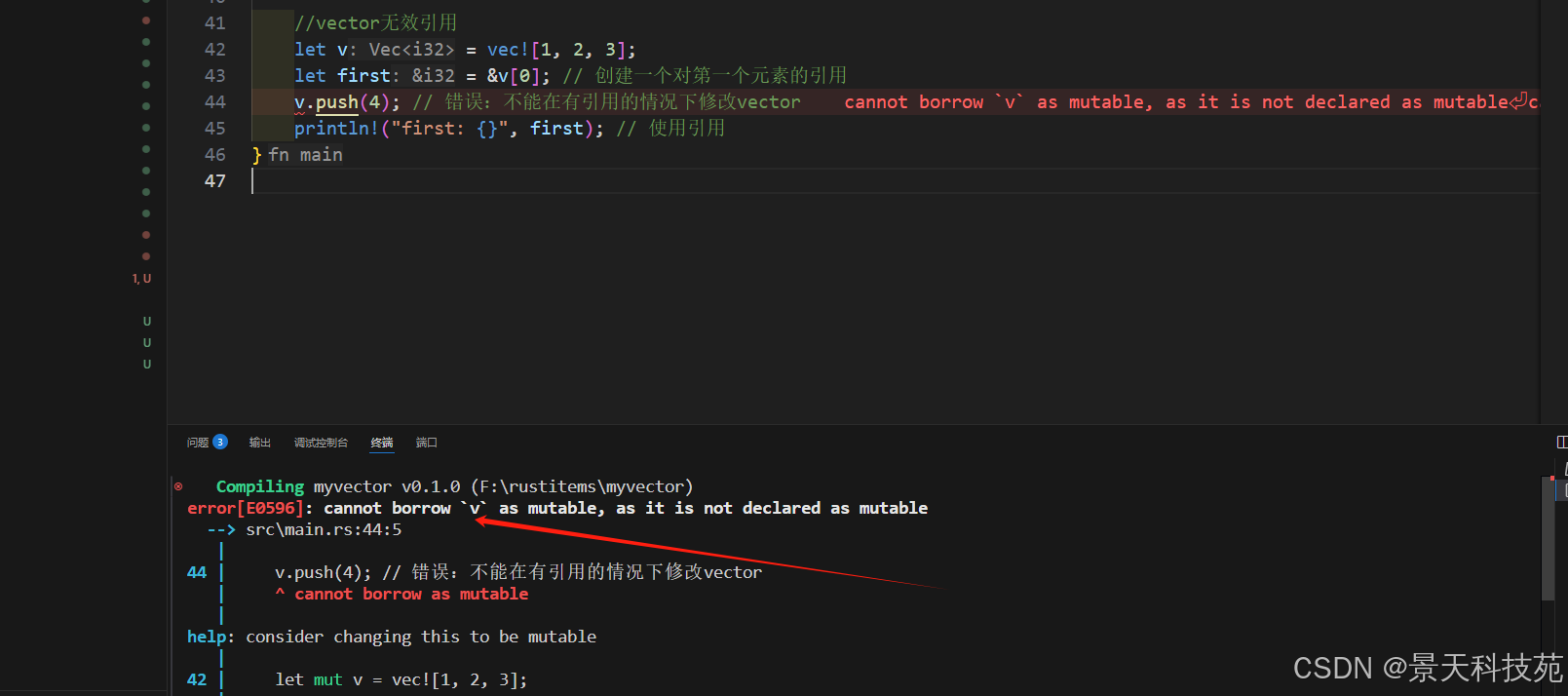
為什么第一個元素的引用會關心 vector 結尾的變化?不能這么做的原因是由于vector 的工作方式。
在 vector 的結尾增加新元素時,在沒有足夠空間將所有所有元素依次相鄰存放的情況下,可能會要求分配新內存并將老的元素拷貝到新的空間中。
這時,第一個元素的引用就指向了被釋放的內存。借用規則阻止程序陷入這種狀況。
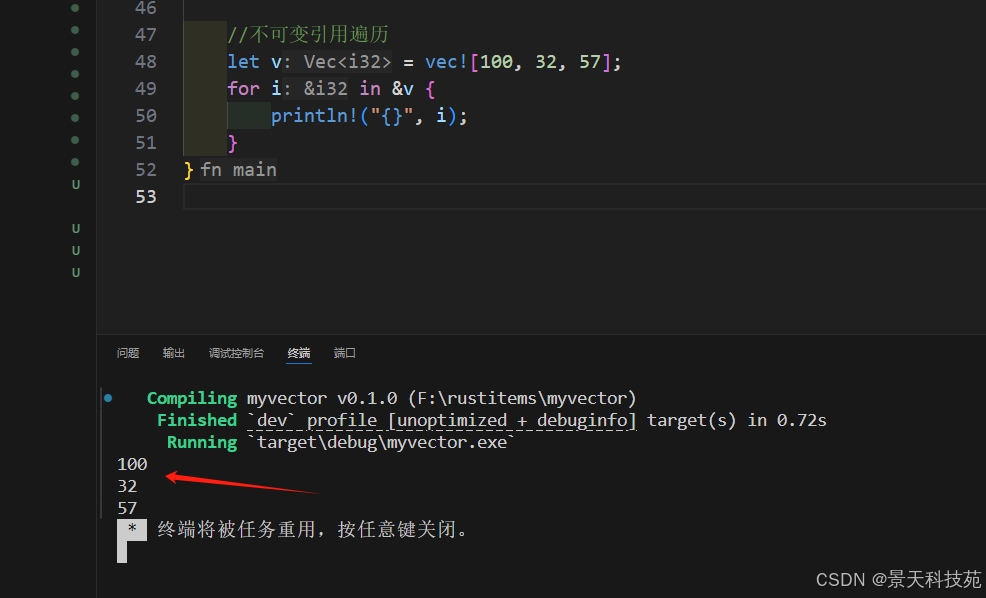
1.6 遍歷 vector 中的元素
如果想要依次訪問 vector 中的每一個元素,我們可以遍歷其所有的元素而無需通過索引一次一個的訪問。
遍歷vector分為不可變引用遍歷和可變引用遍歷
不可變遍歷
let v = vec![100, 32, 57];
for i in &v {println!("{}", i);
}
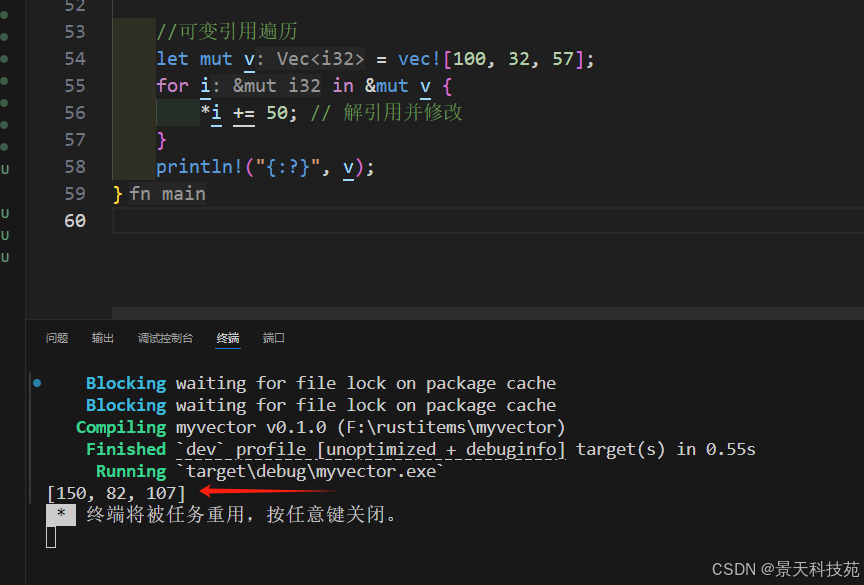
可變遍歷
let mut v = vec![100, 32, 57];
for i in &mut v {*i += 50; // 使用 * 解引用并修改
}
println!("{:?}", v);
為了修改可變引用所指向的值,在使用 += 運算符之前必須使用解引用運算符( * )獲取 i 中的值。
1.7 使用枚舉來儲存多種類型
我們提到 vector 只能儲存相同類型的值。這是很不方便的;絕對會有需要儲存一系列不同類型的值的用例。
幸運的是,枚舉的成員都被定義為相同的枚舉類型,所以當需要在 vector 中儲存不同類型值時,我們可以定義并使用一個枚舉!
這樣最終就能夠儲存不同類型的值了
#[derive(Debug)]
enum SpreadsheetCell {Int(i32),Float(f64),Text(String),
}let row = vec![SpreadsheetCell::Int(3),SpreadsheetCell::Text(String::from("blue")),SpreadsheetCell::Float(10.12),
];
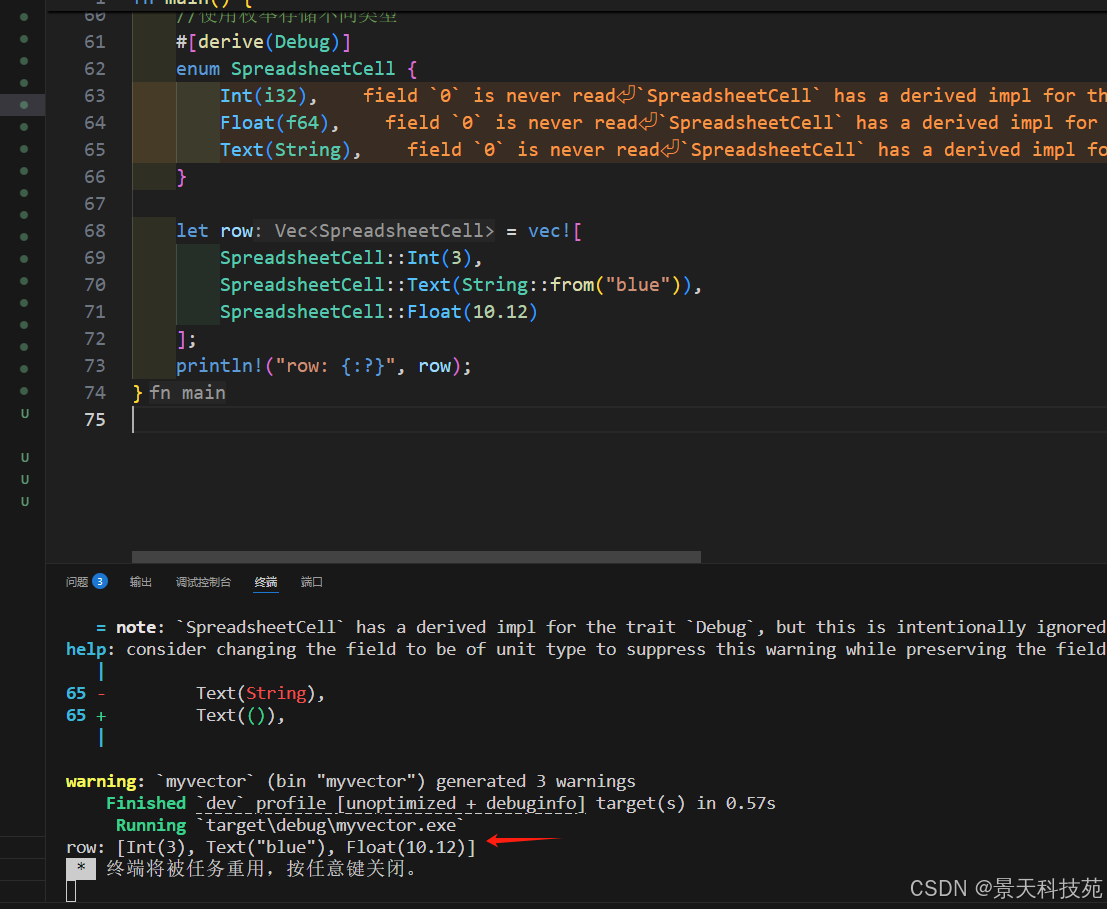
Rust 在編譯時就必須準確的知道 vector 中類型的原因在于它需要知道儲存每個元素到底需要多少內存。
第二個好處是可以準確的知道這個 vector 中允許什么類型。
如果 Rust 允許 vector 存放任意類型,那么當對 vector 元素執行操作時一個或多個類型的值就有可能會造成錯誤。
使用枚舉外加 match 意味著 Rust 能在編譯時就保證總是會處理所有可能的情況。
如果在編寫程序時不能確切無遺地知道運行時會儲存進 vector 的所有類型,枚舉技術就行不通了。但是,你可以使用trait 對象。
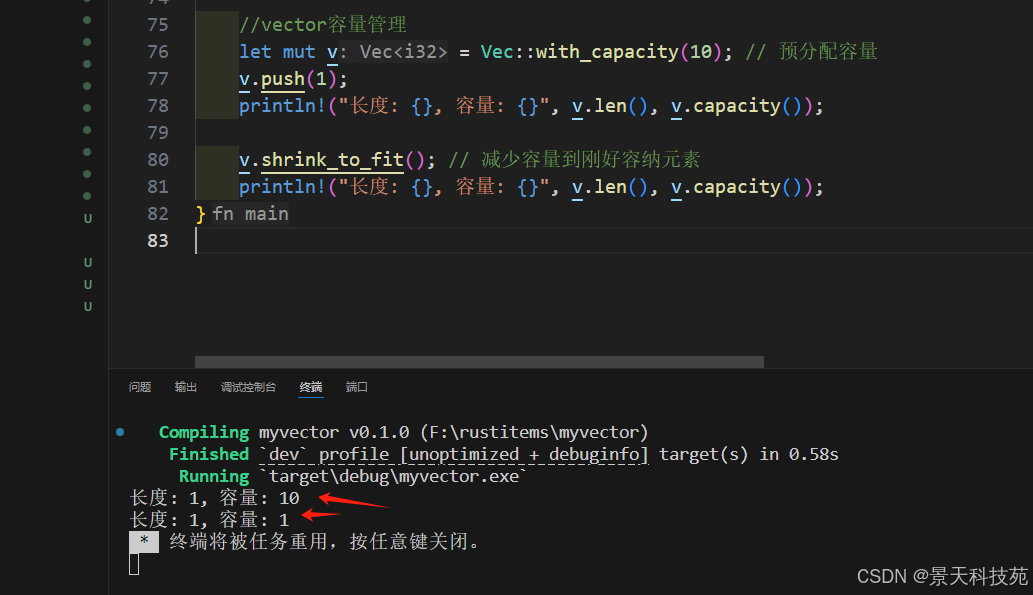
1.8 vector容量管理
//vector容量管理
let mut v = Vec::with_capacity(10); // 預分配容量
v.push(1);
println!("長度: {}, 容量: {}", v.len(), v.capacity());v.shrink_to_fit(); // 減少容量到剛好容納元素
println!("長度: {}, 容量: {}", v.len(), v.capacity());
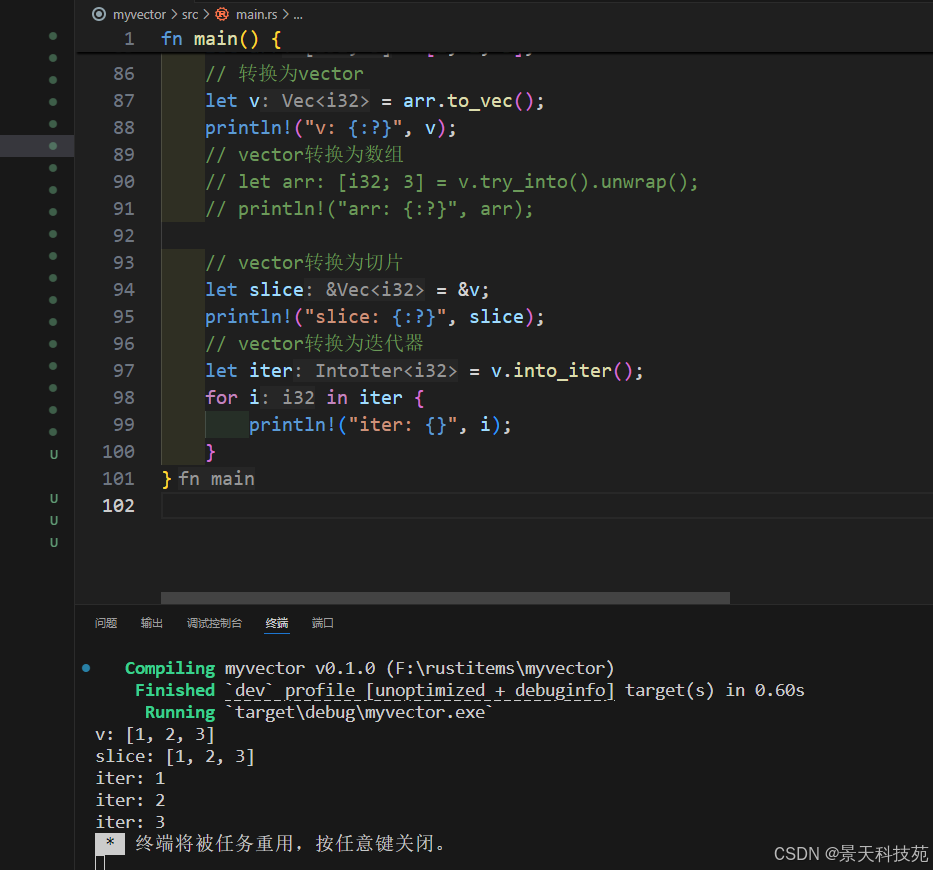
1.9 vector 與其他集合轉換
//vector與其他集合轉換
// 從數組創建
let arr = [1, 2, 3];
// 轉換為vector
let v = arr.to_vec();
println!("v: {:?}", v);
// vector轉換為數組
// let arr: [i32; 3] = v.try_into().unwrap();
// println!("arr: {:?}", arr);// vector轉換為切片
let slice = &v;
println!("slice: {:?}", slice);
// vector轉換為迭代器
let iter = v.into_iter();
for i in iter {println!("iter: {}", i);
}
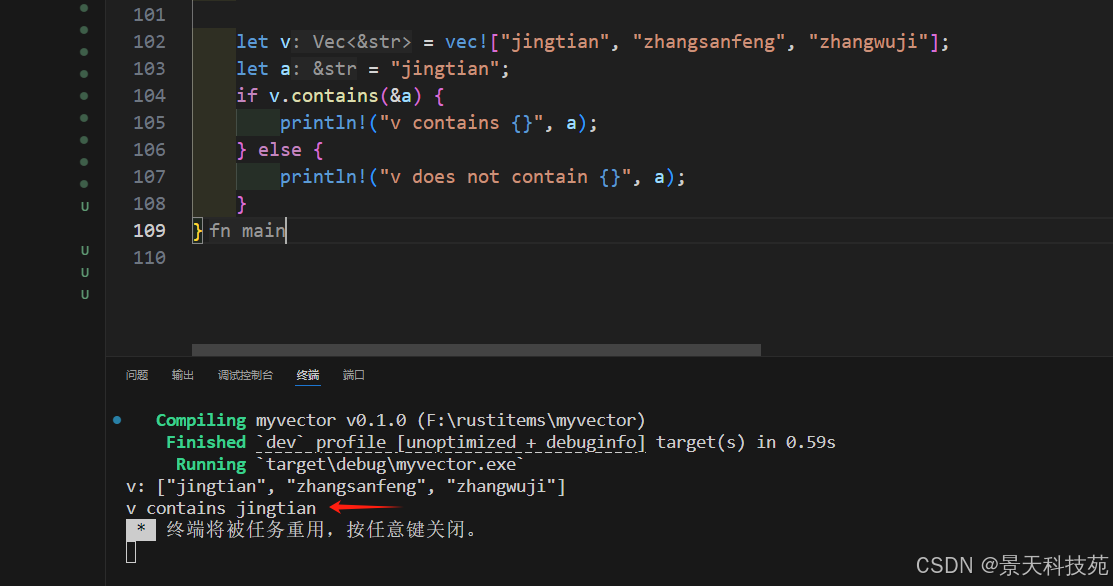
1.10 vector 常用方法
len(): 獲取長度
is_empty(): 檢查是否為空
contains(&value): 檢查是否包含某個值
sort(): 排序
reverse(): 反轉
split_off(at): 分割 vector
append(&mut other): 合并另一個 vector
dedup(): 移除連續重復元素,一般是先排序,后去重
contains使用示例:
let v = vec!["jingtian", "zhangsanfeng", "zhangwuji"];
let a = "jingtian";
if v.contains(&a) {println!("v contains {}", a);
} else {println!("v does not contain {}", a);
}
2、Rust字符串
在這之前,我們已經多次使用到了字符串了,不過現在讓我們更深入地了解它。字符串是新晉 Rustacean 們通常會被困住的領域,
這是由于三方面內容的結合:Rust 傾向于確保暴露出可能的錯誤,字符串是比很多程序員所想象的要更為復雜的數據結
構,以及 UTF-8。所有這些結合起來對于來自其他語言背景的程序員就可能顯得很困難了。
字符串出現在集合章節的原因是,字符串是作為字節的集合外加一些方法實現的,當這些字節被解釋為文本時,這些方
法提供了實用的功能。在這一部分,我們會講到 String 中那些任何集合類型都有的操作,比如創建、更新和讀取。也
會討論 String 與其他集合不一樣的地方,例如索引 String 是很復雜的,由于人和計算機理解 String 數據方式的不同。
2.1 什么是字符串?
Rust 的核心語言中只有一種字符串類型: str ,字符串 slice,它通常以被借用的形式出現, &str 。
它們是一些儲存在別處的UTF-8 編碼字符串數據的引用。比如字符串字面值被儲存在程序的二進制輸出中,字符串 slice 也是如此。
稱作 String 的類型是由標準庫提供的,而沒有寫進核心語言部分,它是可增長的、可變的、有所有權的、UTF-8 編碼的字符串類型。
當 Rustacean 們談到 Rust 的 “字符串”時,它們通常指的是 String 和字符串 slice &str 類型,而不僅僅是其中之一。
雖然本部分內容大多是關于 String 的,不過這兩個類型在 Rust 標準庫中都被廣泛使用, String 和字符串 slice 都是 UTF-8 編碼的。
Rust 標準庫中還包含一系列其他字符串類型,比如 OsString 、 OsStr 、 CString 和 CStr 。相關庫 crate 甚至會提供更多儲存字符串數據的選擇。
與 *String / *Str 的命名類似,它們通常也提供有所有權和可借用的變體,就比如說String / &str 。
這些字符串類型在儲存的編碼或內存表現形式上可能有所不同。
String - 可增長、可修改、擁有所有權的 UTF-8 編碼字符串
&str - 固定大小的字符串切片,通常是對 String 的借用或字符串字面量
為什么 Rust 需要兩種字符串類型?
Rust 的這種設計主要是為了:
性能優化:&str 是輕量級的,不需要堆分配
所有權明確:String 擁有數據,&str 只是借用
靈活性:可以在需要時選擇使用擁有所有權的或借用的字符串
2.2 新建字符串
很多 Vec 可用的操作在 String 中同樣可用,
1)String::new()創建
從以 new 函數創建字符串開始,
let mut s = String::new();
新建一個空的 String
這新建了一個叫做 s 的空的字符串,接著我們可以向其中裝載數據。
通常字符串會有初始數據,因為我們希望一開始就有這個字符串。
為此,可以使用 to_string 方法,它能用于任何實現了 Display trait 的類型,字符串字面值就可以。
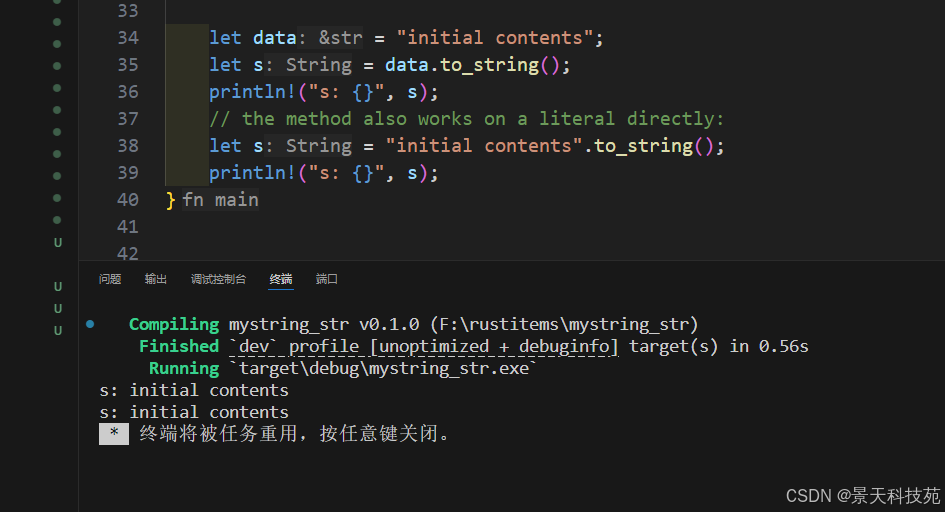
2)通過字符串字面量 to_string()創建
使用 to_string 方法從字符串字面值創建 String
let data = "initial contents";
let s = data.to_string();
// the method also works on a literal directly:
let s = "initial contents".to_string();
3)使用 String::from 創建 String
也可以使用 String::from 函數來從字符串字面值創建 String
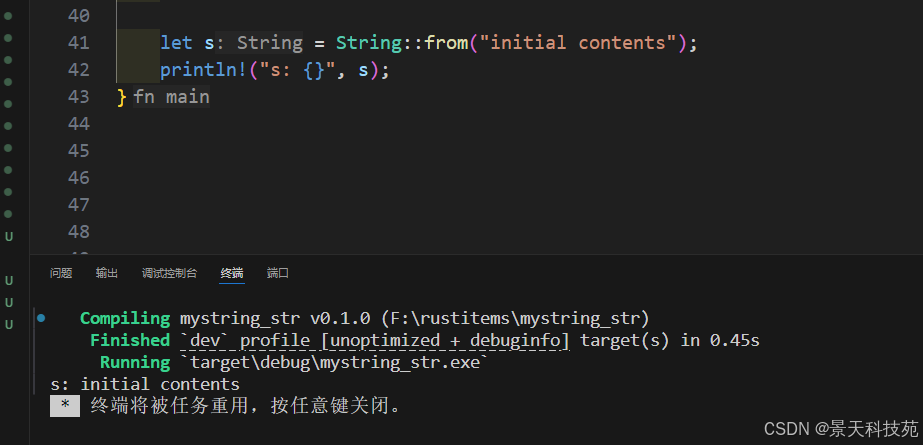
let s = String::from("initial contents");
println!("s: {}", s);
4)使用 to_owned 方法
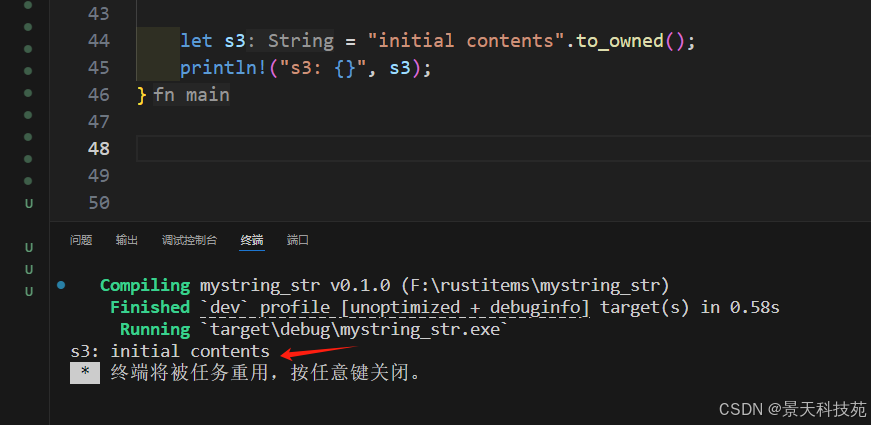
通過字符串字面量的to_owned()方法返回字符串String
let s3 = "initial contents".to_owned();
println!("s3: {}", s3);
5)r#原字符串
Rust的字符串字面量使用反斜杠\作為轉義字符,比如\n表示換行,\t表示制表符等。但是,如果你只是想在字符串中包含一個普通的反斜杠字符,你需要用兩個反斜杠\來表示。
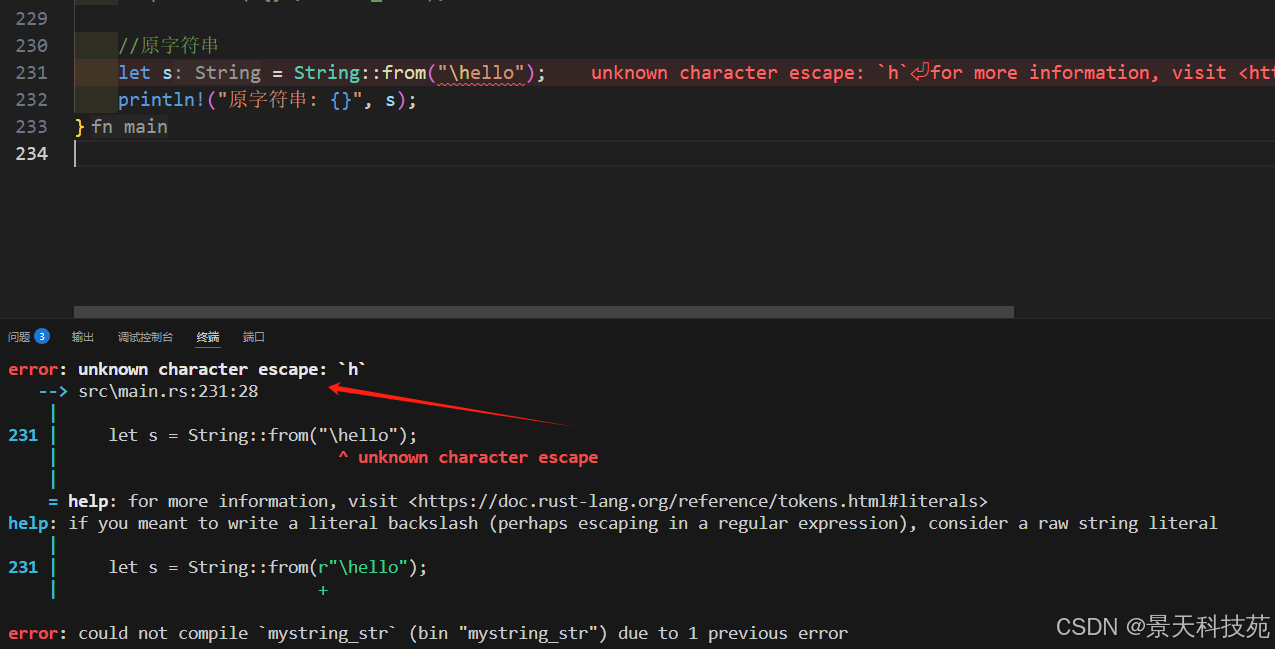
如果字符串中包含\,直接這樣表示是會報錯的
//原字符串
let s = String::from("\hello");
println!("原字符串: {}", s);
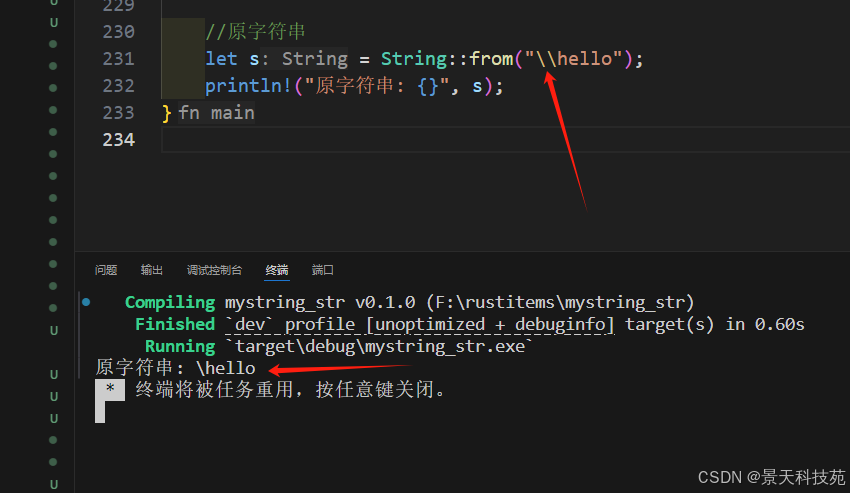
如果想要在字符串中包含\,可以使用轉義符
//原字符串
let s = String::from("\\hello");
println!("原字符串: {}", s);
也可以使用r#,原字符串
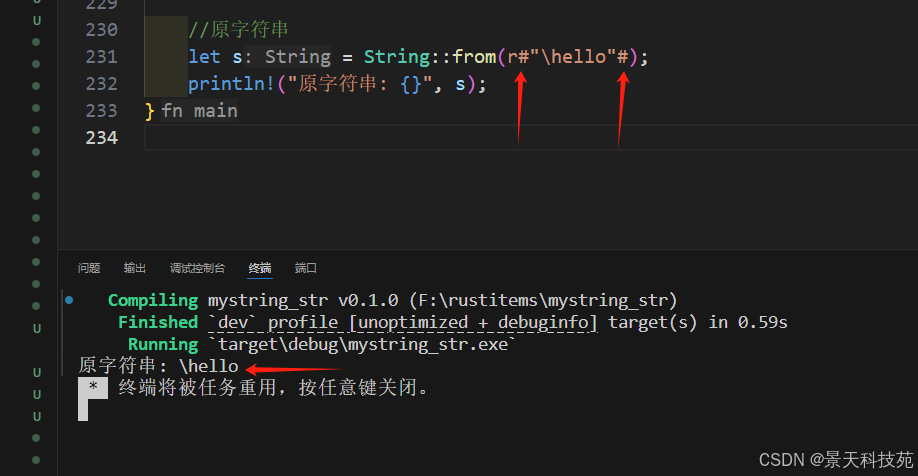
使用了r#“…”#來定義了一個原始字符串字面量,它允許字符串內部包含任意的字符,包括換行符、tab符號和引號等,而不需要使用轉義字符。
//原字符串
let s = String::from(r#"\hello"#);
println!("原字符串: {}", s);
2.3 字符串操作
1)追加內容
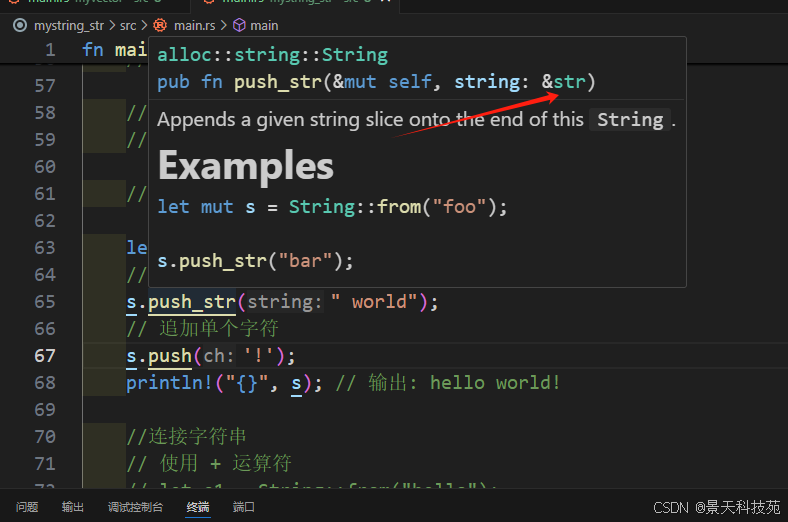
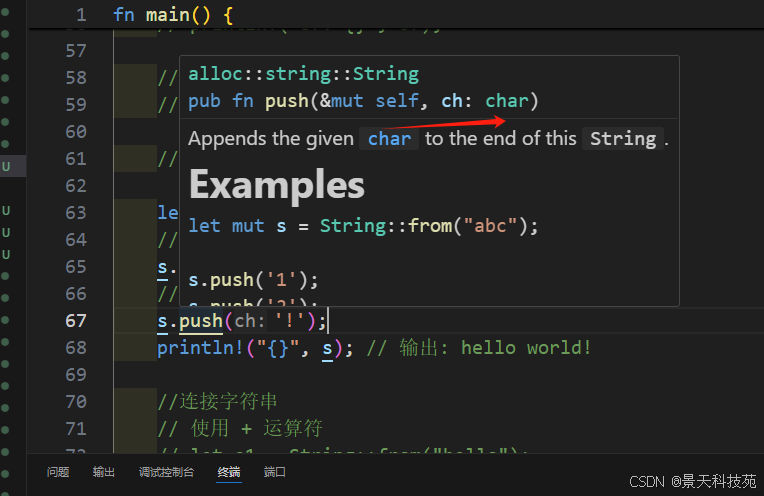
push_str() 追加字符串
push() 追加單個字符
push_str的參數都是&str類型,當然&String可以自動轉換為&str類型
push的參數是char類型
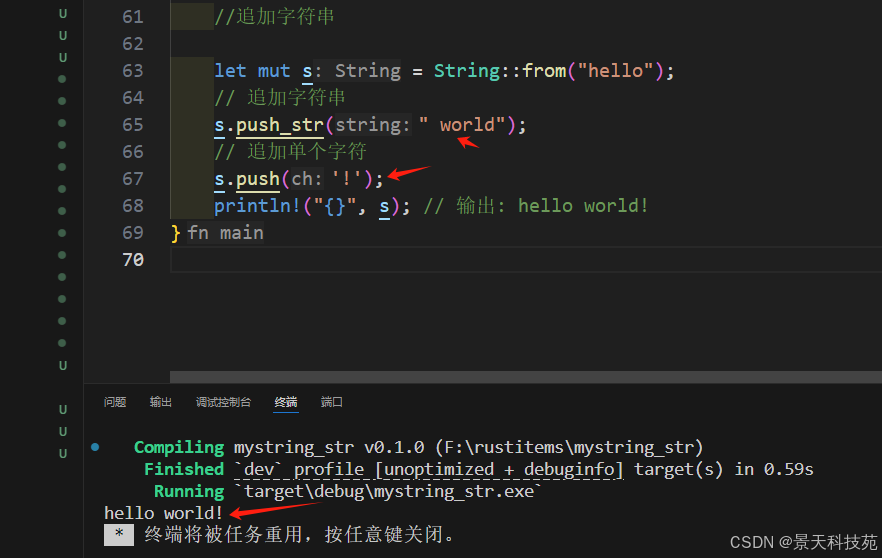
let mut s = String::from("hello");
// 追加字符串
s.push_str(" world");
// 追加單個字符
s.push('!');
println!("{}", s); // 輸出: hello world!
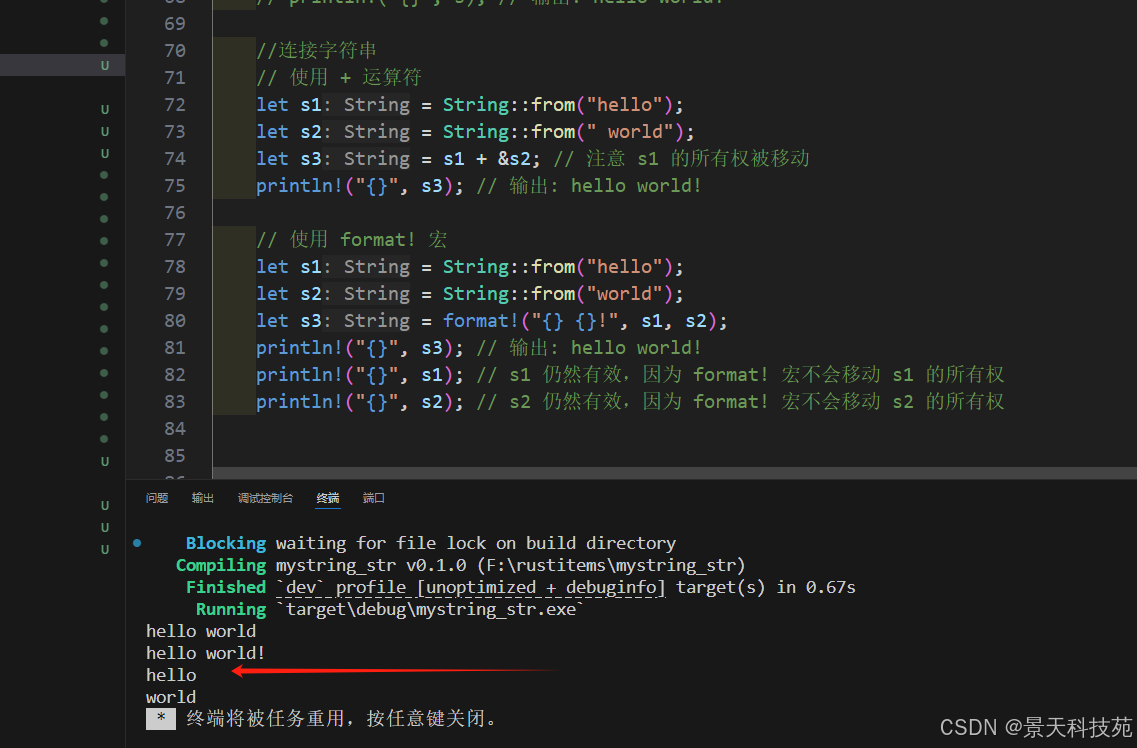
2)連接字符串
使用 + 運算符或 format! 宏連接字符串
使用+連接
通常我們希望將兩個已知的字符串合并在一起。一種辦法是像這樣使用 + 運算符
使用 + 運算符將兩個 String 值合并到一個新的 String 值中
// 使用 + 運算符
let s1 = String::from("hello");
let s2 = String::from(" world");
let s3 = s1 + &s2; // 注意 s1 的所有權被移動,s1的所有權已經給了s3了。此后s1不再有效
println!("{}", s3); // 輸出: hello world!
執行完這些代碼之后字符串 s3 將會包含 Hello, world! 。 s1 在相加后不再有效的原因,和使用 s2 的引用的原因與使用 + 運算符時調用的方法簽名有關,這個函數簽名看起來像這樣:
fn add(self, s: &str) -> String {
字符串運算+,相當于執行了這個add函數,字符串相加第一個必須是String,+后面的都是字符串引用
這并不是標準庫中實際的簽名;標準庫中的 add 使用泛型定義。這里我們看到的 add 的簽名使用具體類型代替了泛型,
這也正是當使用 String 值調用這個方法會發生的。后面我們會討論泛型。這個簽名提供了理解 + 運算那微妙部分的線索。
首先, s2 使用了 & ,意味著我們使用第二個字符串的 引用 與第一個字符串相加。
這是因為 add 函數的 s 參數:只能將 &str 和 String 相加,不能將兩個 String 值相加。
不過等一下——正如 add 的第二個參數所指定的, &s2 的類型是 &String 而不是 &str 。
那么為示例 還能編譯呢?
之所以能夠在 add 調用中使用 &s2 是因為 &String 可以被 強轉(coerced)成 &str ——當 add 函數被調用時,
Rust 使用了一個被稱為 解引用強制多態(deref coercion)的技術,你可以將其理解為它把 &s2 變成了 &s2[…] 。
后面我們會更深入的討論解引用強制多態。因為 add 沒有獲取參數的所有權,所以 s2 在這個操作后仍然是有效的 String 。
其次,可以發現簽名中 add 獲取了 self 的所有權,因為 self 沒有 使用 & 。這意味著上面例子中的 s1 的所有權將
被移動到 add 調用中,之后就不再有效。所以雖然 let s3 = s1 + &s2; 看起來就像它會復制兩個字符串并創建一個新的
字符串,而實際上這個語句會獲取 s1 的所有權,附加上從 s2 中拷貝的內容,并返回結果的所有權。
換句話說,它看起來好像生成了很多拷貝不過實際上并沒有:這個實現比拷貝要更高效。
使用 format! 宏
// 使用 format! 宏
let s1 = String::from("hello");
let s2 = String::from("world");
let s3 = format!("{} {}!", s1, s2);
println!("{}", s3); // 輸出: hello world!
println!("{}", s1); // s1 仍然有效,因為 format! 宏不會移動 s1 的所有權
println!("{}", s2); // s2 仍然有效,因為 format! 宏不會移動 s2 的所有權
format! 與 println! 的工作原理相同,不過不同于將輸出打印到屏幕上,它返回一個帶有結果內容的 String 。
這個版本就好理解的多,并且不會獲取任何參數的所有權。
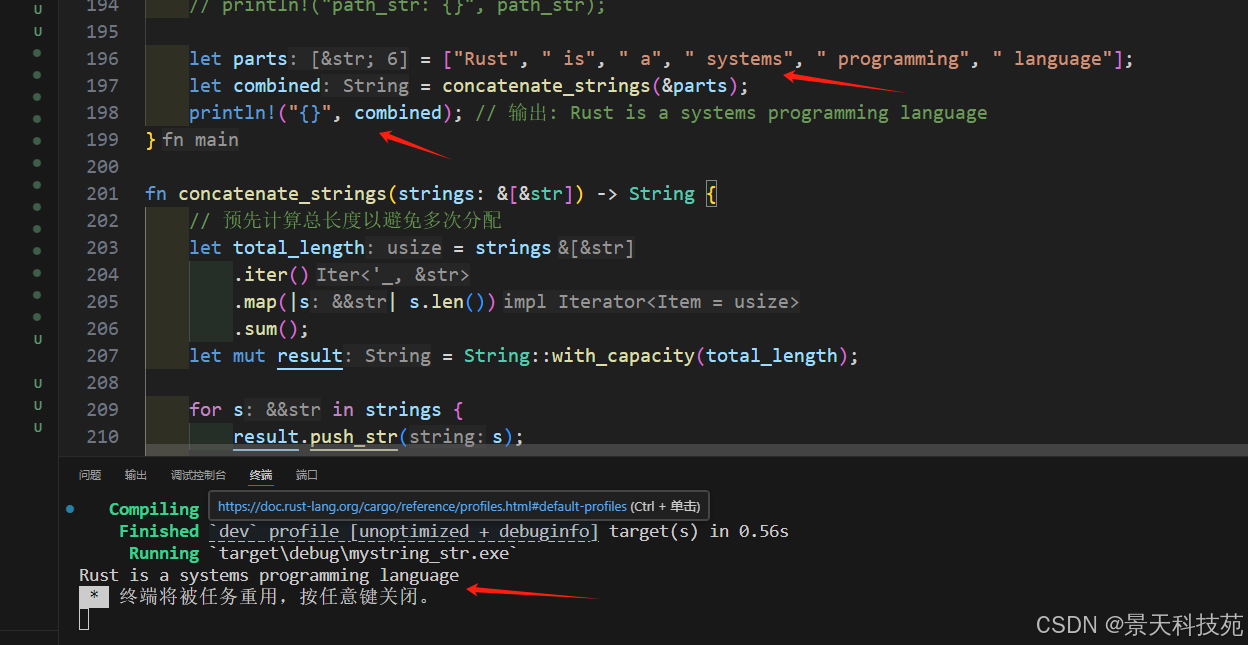
高效連接多個字符串
fn concatenate_strings(strings: &[&str]) -> String {// 預先計算總長度以避免多次分配let total_length = strings.iter().map(|s| s.len()).sum();let mut result = String::with_capacity(total_length);for s in strings {result.push_str(s);}result
}fn main() {let parts = ["Rust", " is", " a", " systems", " programming", " language"];let combined = concatenate_strings(&parts);println!("{}", combined); // 輸出: Rust is a systems programming language
}
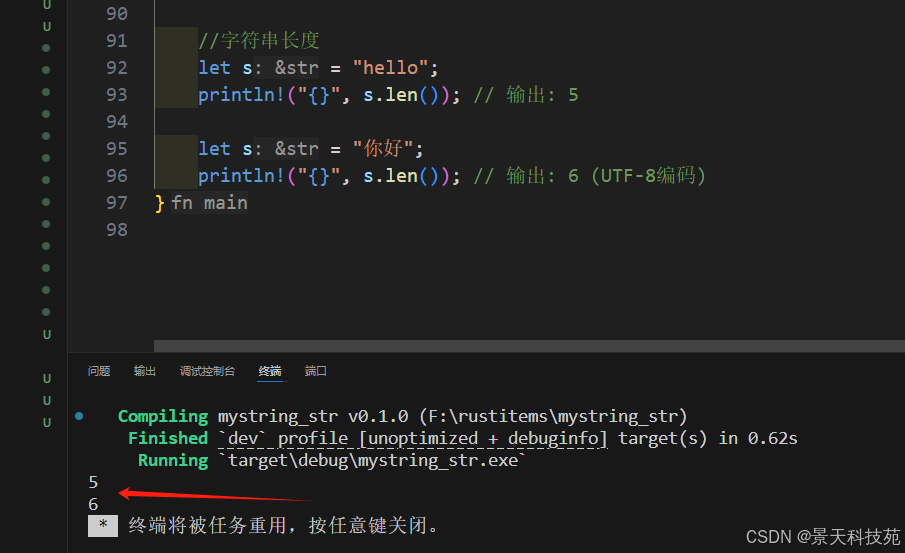
3)字符串長度
let s = "hello";
println!("{}", s.len()); // 輸出: 5let s = "你好";
println!("{}", s.len()); // 輸出: 6 (UTF-8編碼)
根據utf-8編碼中每個字符占的字節來計算長度,每個漢字占3個字節
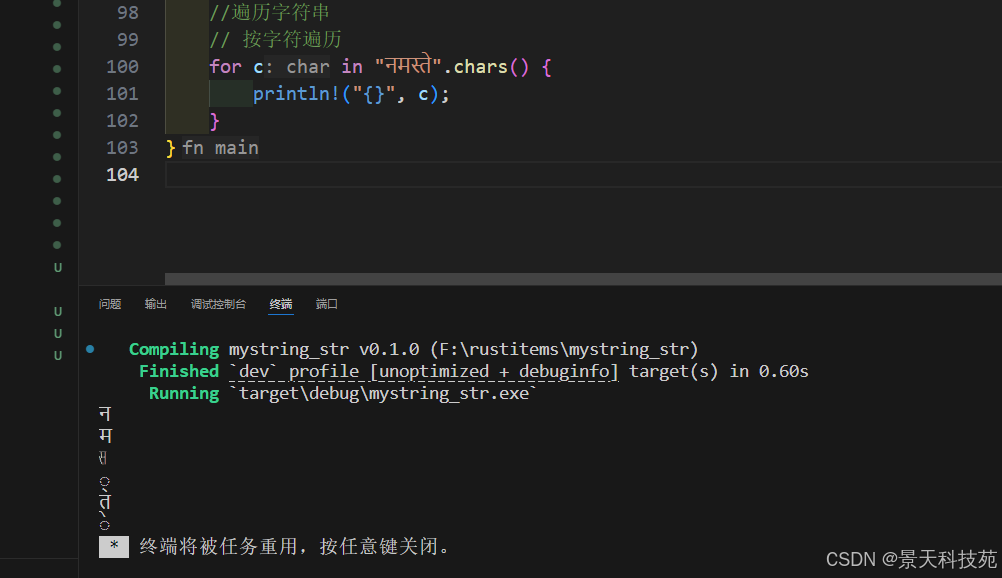
4)遍歷字符串
遍歷字符串可以從兩個方面遍歷,字符方式遍歷和字節方式遍歷
- chars方法遍歷,返回每個字符
// 按字符遍歷
for c in "??????".chars() {println!("{}", c);
}
- 按字節遍歷
bytes 方法返回每一個原始字節// 按字節遍歷for b in "??????".bytes() {println!("{}", b);}
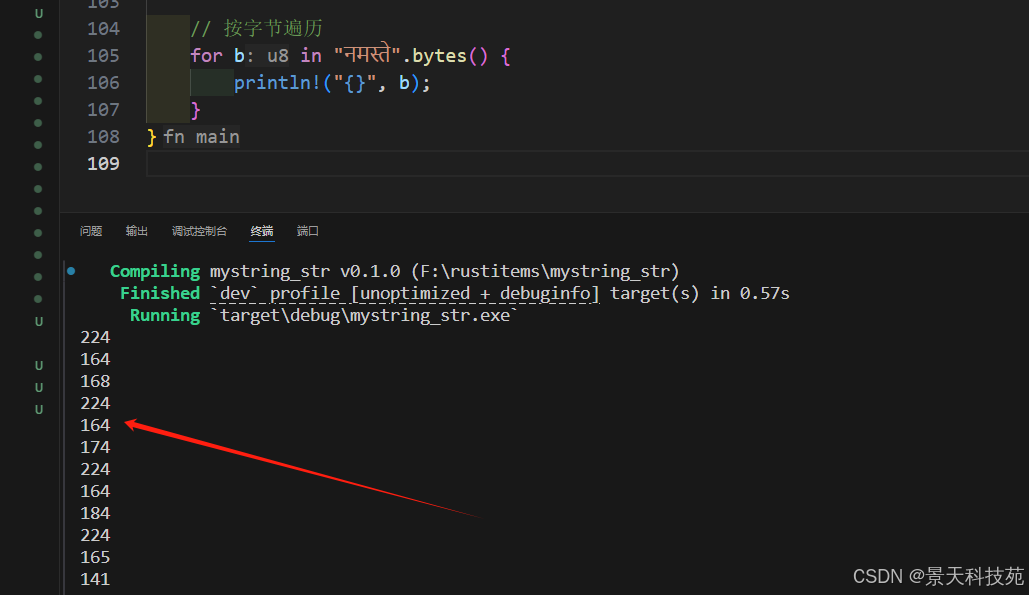
2.4 字符串索引和切片
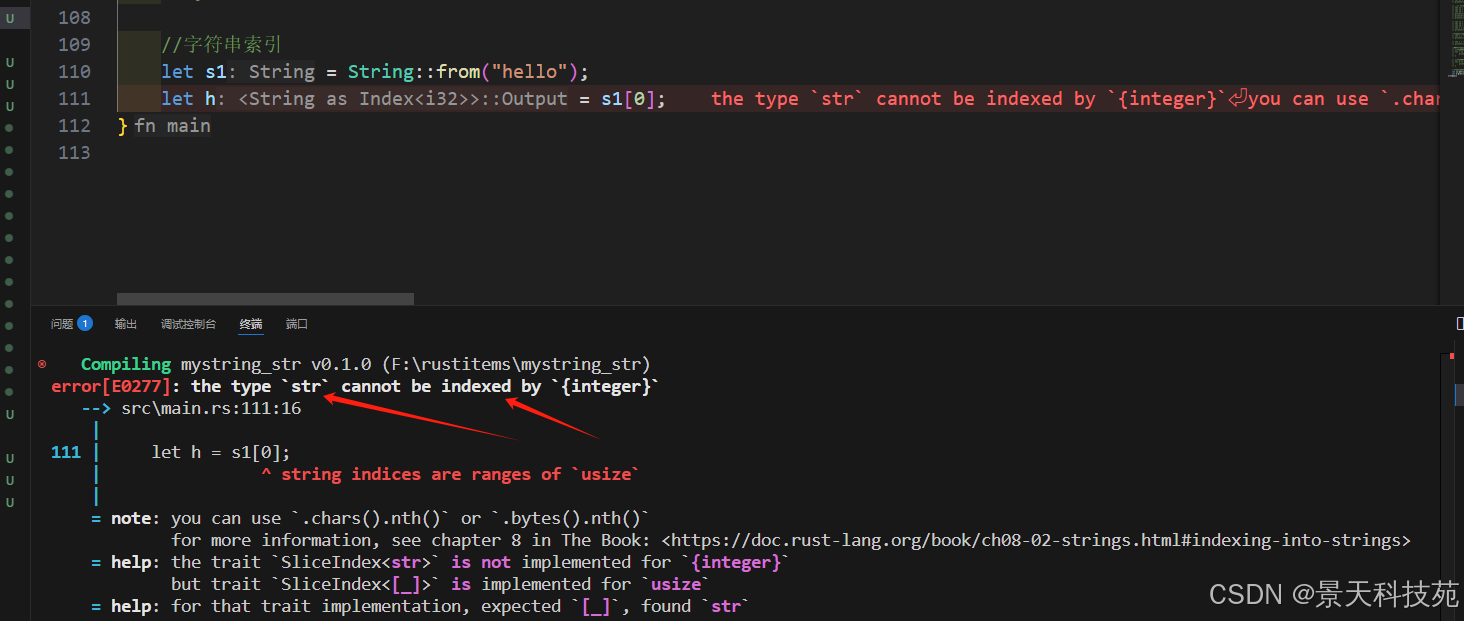
在很多語言中,通過索引來引用字符串中的單獨字符是有效且常見的操作。
然而在 Rust 中,如果我們嘗試使用索引語法訪問 String 的一部分,會出現一個錯誤。
Rust 不允許直接使用索引訪問字符串中的字符,因為字符串是 UTF-8 編碼的,不同語言字符可能占用 字節個數不確定。
let s1 = String::from("hello");
let h = s1[0];
錯誤和提示說明了全部問題:Rust 的字符串不支持索引。
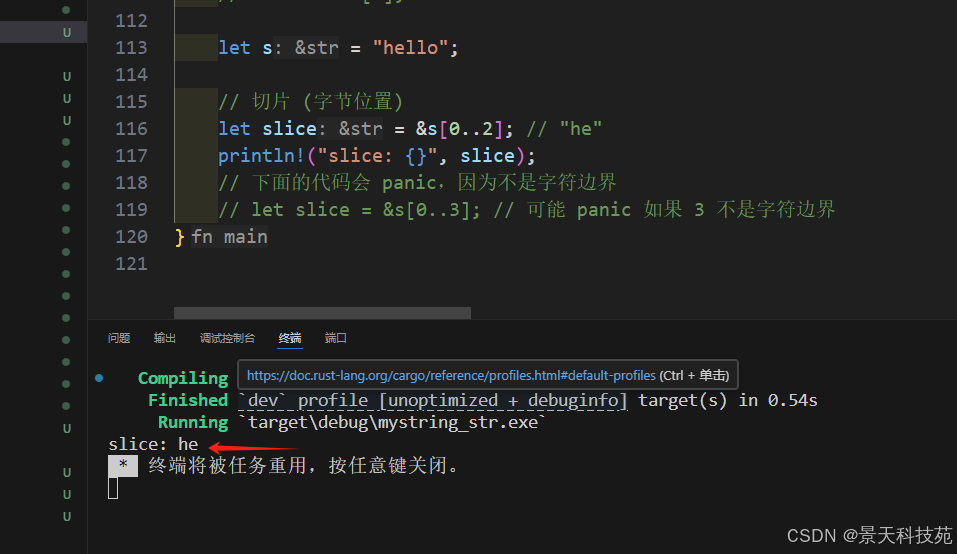
可以使用字符串切片來索引
slice 允許你引用集合中一段連續的元素序列
針對非ASCII碼中的字符,一定要注意邊界,才能索引,否則也會報錯
let s = "hello";
// 切片 (字節位置)
let slice = &s[0..2]; // "he"
// 下面的代碼會 panic,因為不是字符邊界
// let slice = &s[0..3]; // 可能 panic 如果 3 不是字符邊界
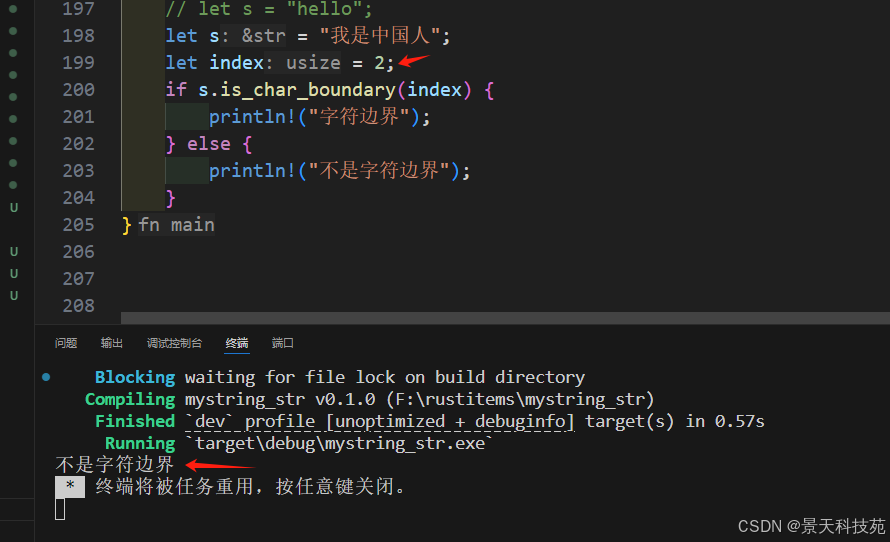
安全使用字符串切片提取子字符串
由于不同的語言,單個字符所占的字節不同,所以用戶輸入的索引可能在字符中間,這樣切片索引就會失敗。
可以根據用戶輸入的是否字符邊界,來判斷輸入的索引是否合法
is_char_boundary(index) 可以判斷索引是否邊界
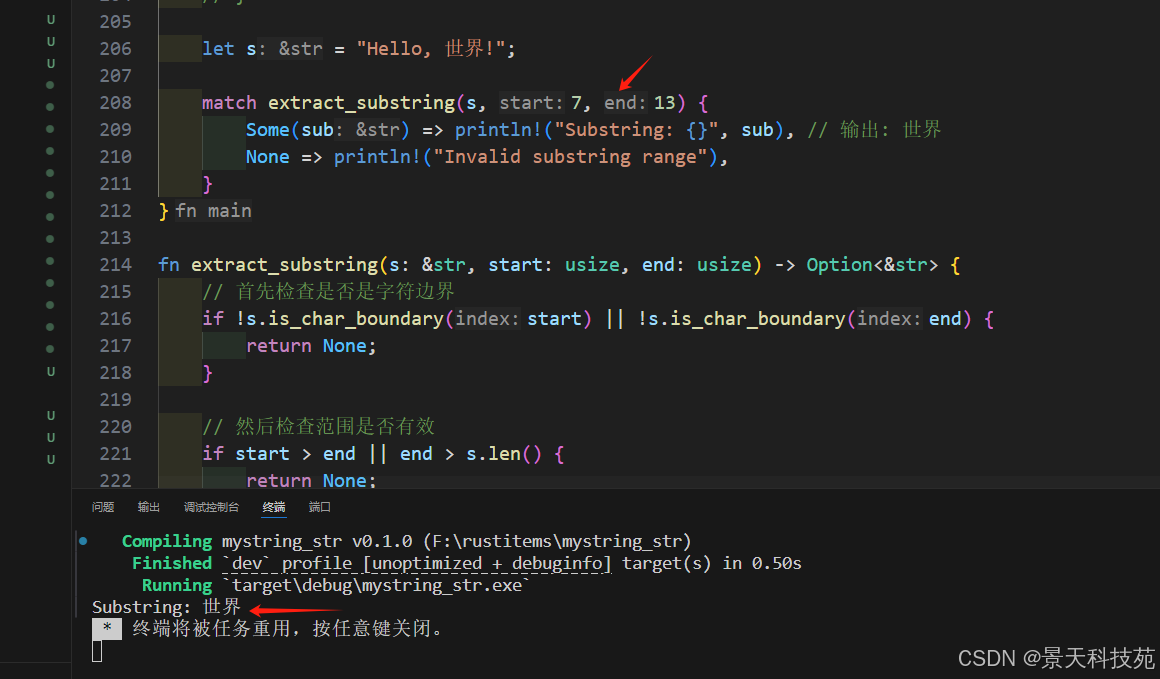
fn extract_substring(s: &str, start: usize, end: usize) -> Option<&str> {// 首先檢查是否是字符邊界if !s.is_char_boundary(start) || !s.is_char_boundary(end) {return None;}// 然后檢查范圍是否有效if start > end || end > s.len() {return None;}Some(&s[start..end])
}fn main() {let s = "Hello, 世界!";match extract_substring(s, 7, 13) {Some(sub) => println!("Substring: {}", sub), // 輸出: 世界None => println!("Invalid substring range"),}
}
2.5 字符串常用方法
1)檢查方法
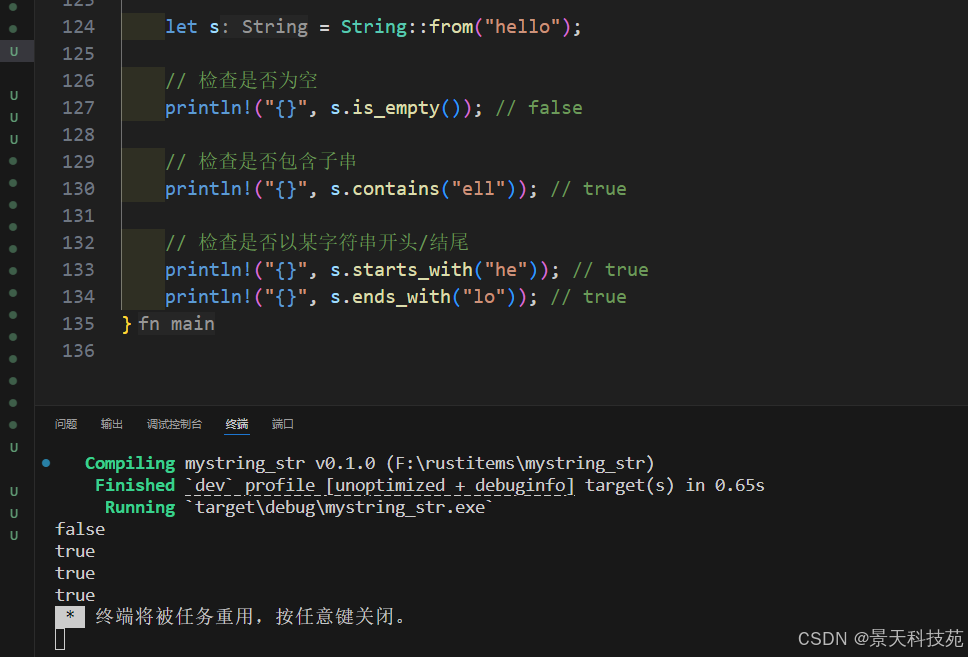
let s = String::from("hello");// 檢查是否為空
println!("{}", s.is_empty()); // false// 檢查是否包含子串
println!("{}", s.contains("ell")); // true// 檢查是否以某字符串開頭/結尾
println!("{}", s.starts_with("he")); // true
println!("{}", s.ends_with("lo")); // true
2)轉換方法
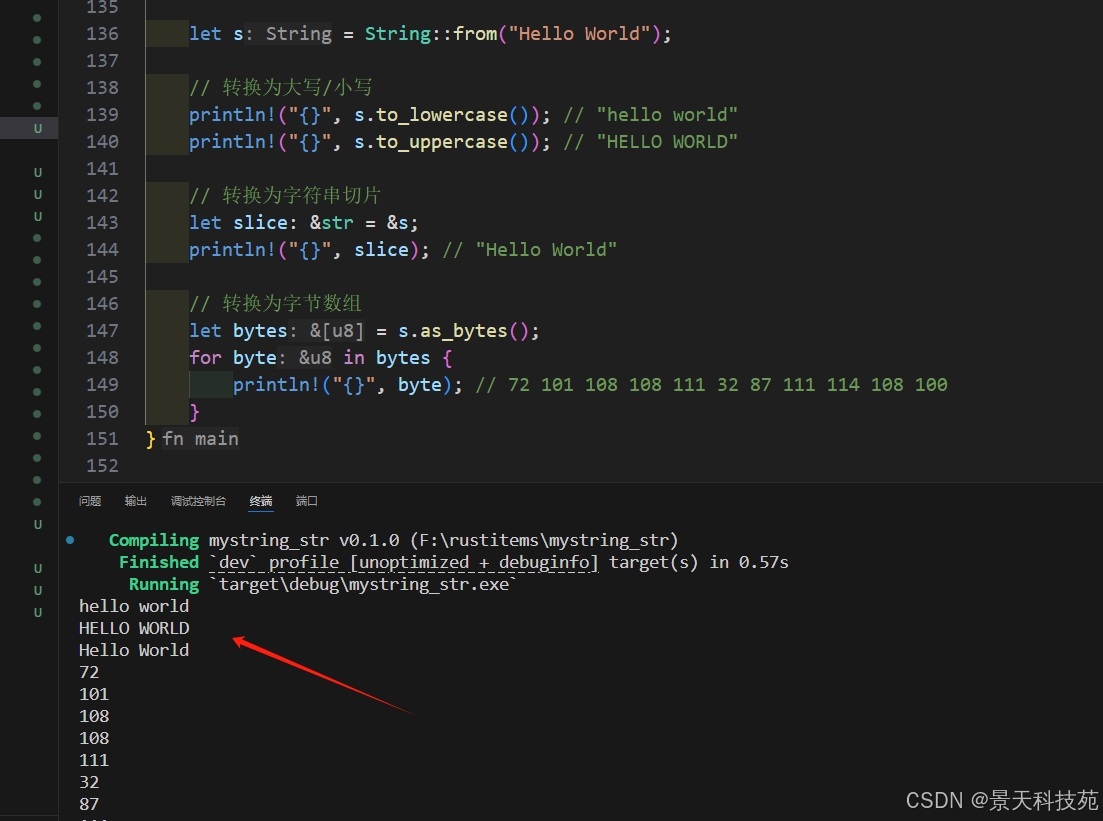
let s = String::from("Hello World");// 轉換為大寫/小寫
println!("{}", s.to_lowercase()); // "hello world"
println!("{}", s.to_uppercase()); // "HELLO WORLD"// 轉換為字符串切片
let slice: &str = &s;// 轉換為字節數組
let bytes = s.as_bytes();
3)分割和拼接
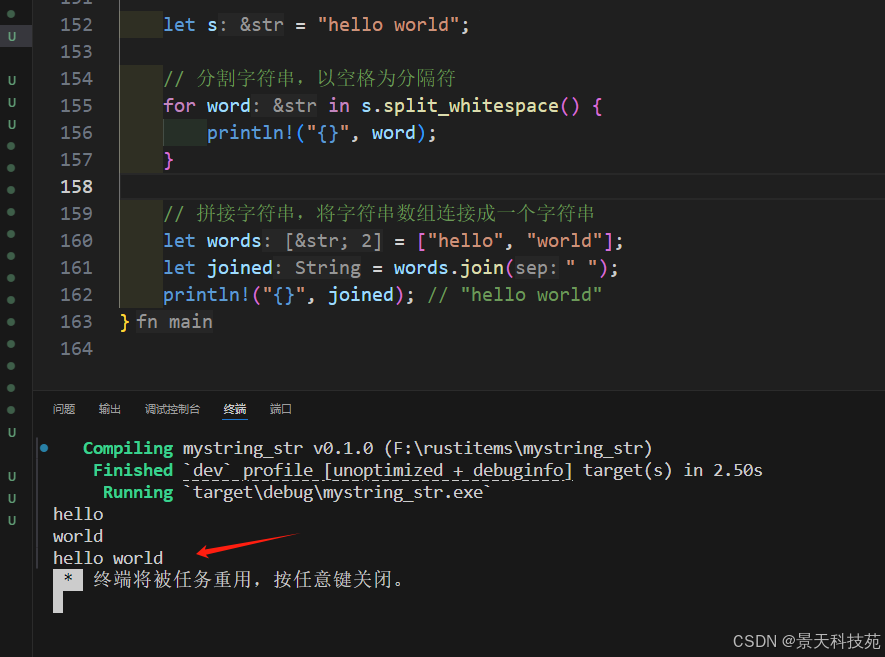
let s = "hello world";// 分割字符串,以空格為分隔符
for word in s.split_whitespace() {println!("{}", word);
}// 拼接字符串,將字符串數組連接成一個字符串。join的參數是合并后的單詞分隔符
let words = ["hello", "world"];
let joined = words.join(" ");
println!("{}", joined); // "hello world"
4)替換和修剪
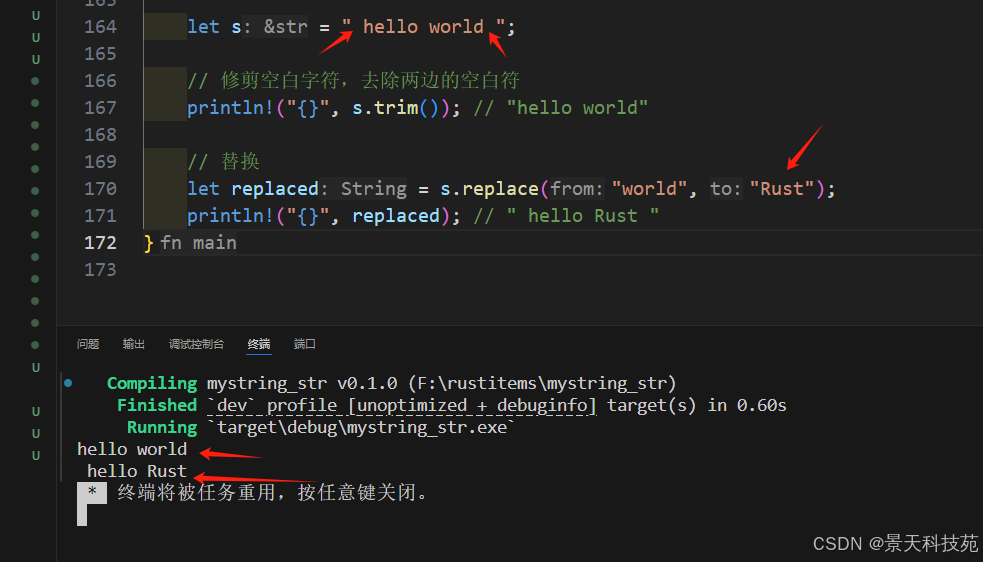
let s = " hello world ";// 修剪空白字符,去除兩邊的空白符
println!("{}", s.trim()); // "hello world"// 替換
let replaced = s.replace("world", "Rust");
println!("{}", replaced); // " hello Rust "
2.6 字符串與其它類型的轉換
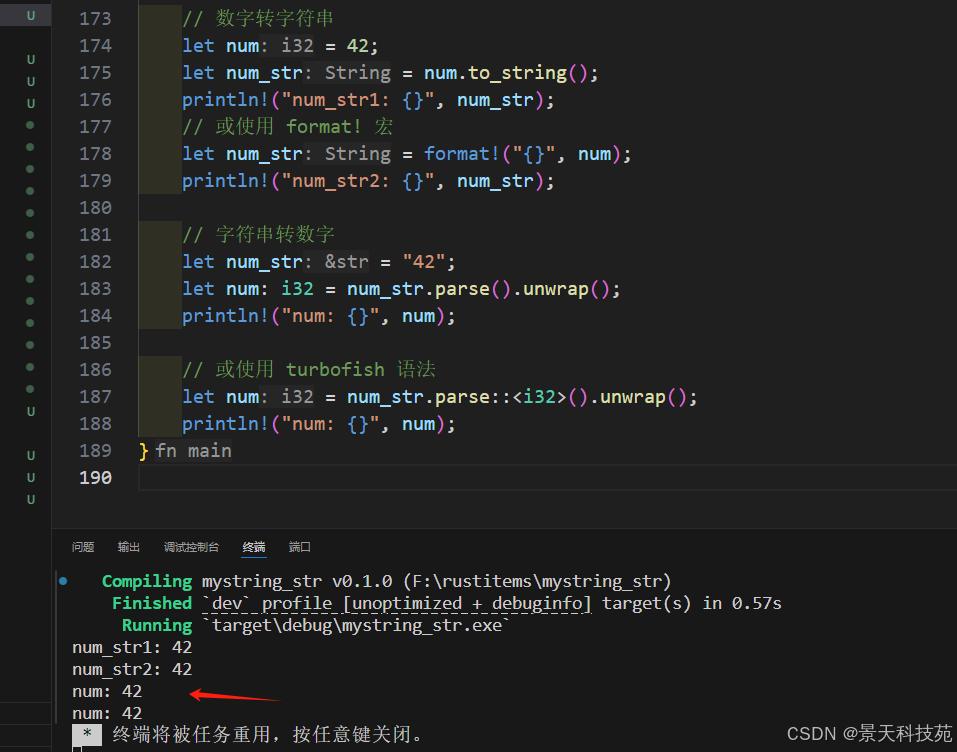
1)數字與字符串
// 數字轉字符串
let num = 42;
let num_str = num.to_string();
println!("num_str1: {}", num_str);
// 或使用 format! 宏
let num_str = format!("{}", num);
println!("num_str2: {}", num_str);// 字符串轉數字
let num_str = "42";
let num: i32 = num_str.parse().unwrap();
println!("num: {}", num);// 或使用 turbofish 語法
let num = num_str.parse::<i32>().unwrap();
println!("num: {}", num);
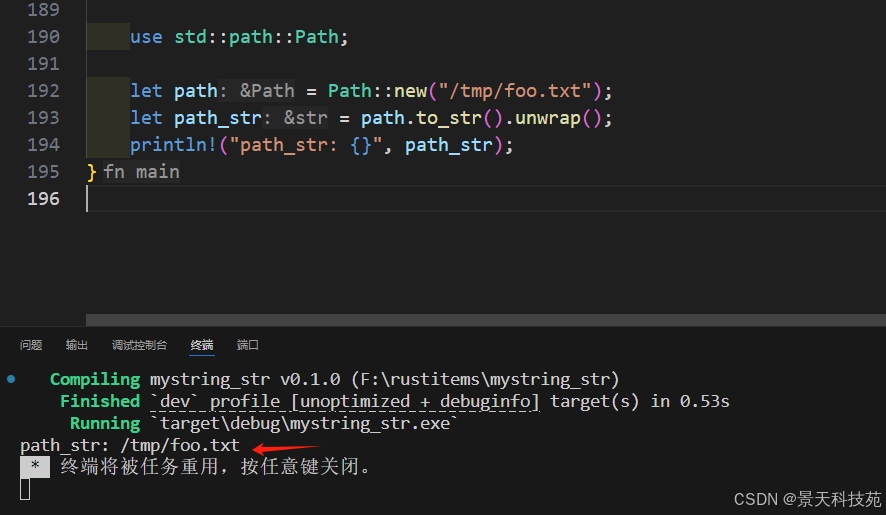
2)路徑與字符串
使用到路徑Path庫
use std::path::Path;let path = Path::new("/tmp/foo.txt");
let path_str = path.to_str().unwrap();
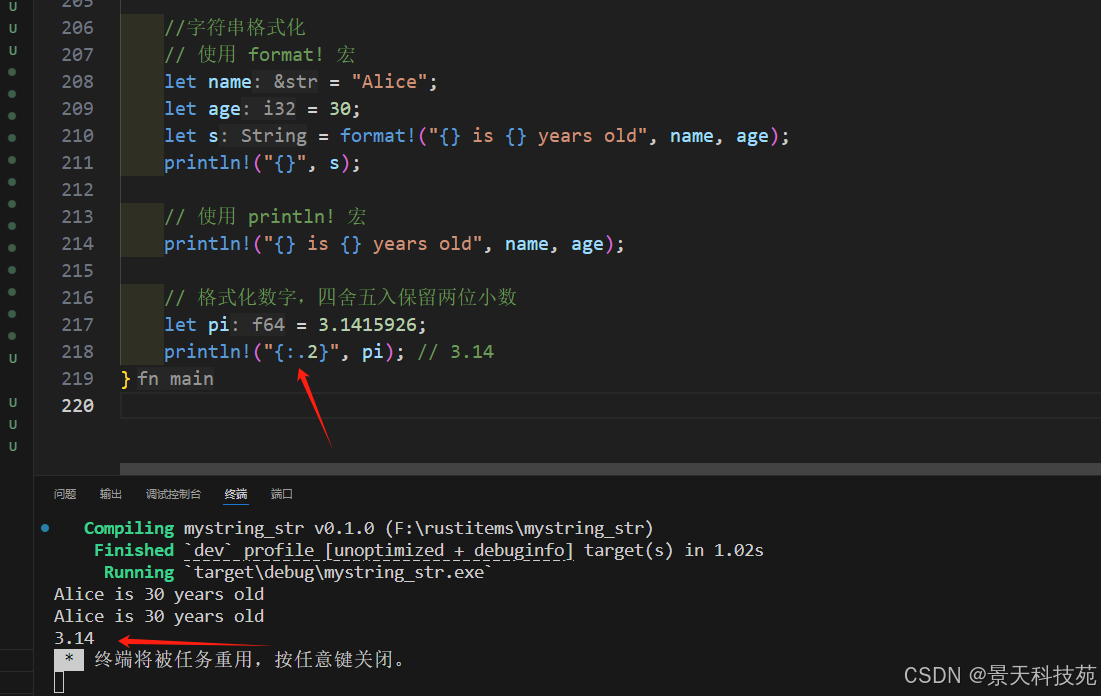
2.7 字符串格式化
1)使用 format! 宏
let name = "Alice";
let age = 30;
let s = format!("{} is {} years old", name, age);
println!("{}", s);
2)使用 println! 宏
println!("{} is {} years old", name, age);// 格式化數字
let pi = 3.1415926;
println!("{:.2}", pi); // 3.14
2.8 處理 UTF-8 字符串
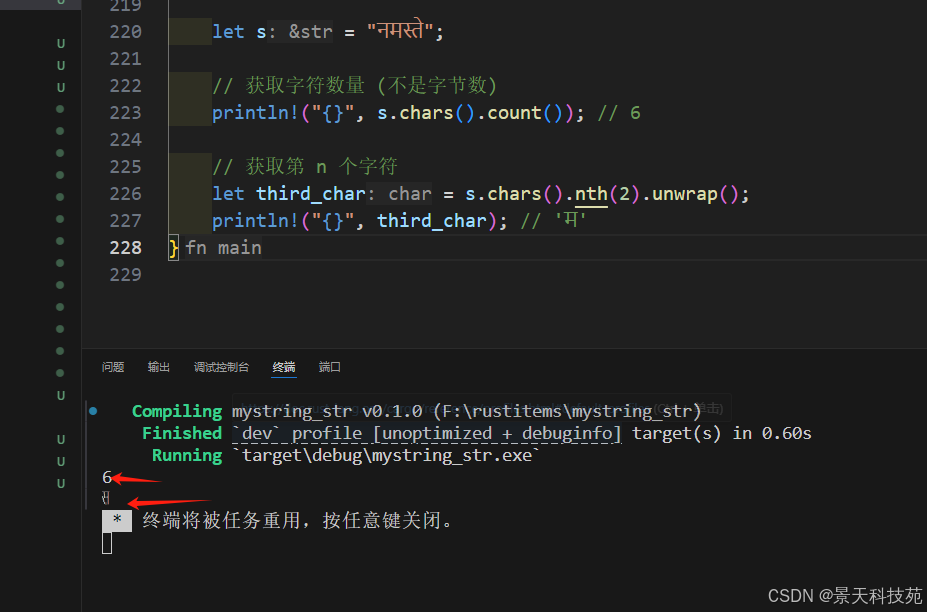
Rust 字符串嚴格使用 UTF-8 編碼,這帶來了一些特殊考慮,字符邊界問題
s.chars().count() 獲取字符個數
s.chars().nth(n).unwrap() 獲取第n個字符let s = "??????";// 獲取字符數量 (不是字節數)
println!("{}", s.chars().count()); // 6// 獲取第 n 個字符
let third_char = s.chars().nth(2).unwrap();
println!("{}", third_char); // '?'
3、 hashmap 儲存鍵值對
3.1 HashMap 簡介
HashMap 是 Rust 標準庫中提供的鍵值對集合類型,基于哈希表實現。它提供了高效的數據查找、插入和刪除操作。
它存儲鍵值對并提供了平均時間復雜度為 O(1) 的查找、插入和刪除操作。
HashMap<K, V> 類型儲存了一個鍵類型 K 對應一個值類型 V 的映射。
它通過一個 哈希函數(hashing function)來實現映射,決定如何將鍵和值放入內存中。
HashMap<K, V> 存儲的是 K 類型的鍵和 V 類型的值的映射關系。
它要求鍵類型 K 實現了 Eq 和 Hash trait,而值類型 V 可以是任意類型。
例如,在一個游戲中,你可以將每個團隊的分數記錄到哈希 map 中,其中鍵是隊伍的名字而值是每個隊伍的分數。
給出一個隊名,就能得到它們的得分。
HashMap特性
- 快速查找:平均 O(1) 的時間復雜度,適用于需要頻繁插入、刪除和查找鍵值對的場景。
- 無序:鍵值對的順序不保證,哈希表的存儲順序是由哈希值決定的。
- 可以動態調整大小,以應對負載因子變化。
HAashMap的桶與槽
在哈希表(例如 Rust 的 HashMap)的實現中,桶(bucket)是用來存儲鍵值對的容器或位置。
每個桶存儲著哈希表中一個特定的“槽”中的元素,多個元素可能會被存放到同一個桶中。
這種設計的目的是為了優化哈希表的性能,使得查找、插入和刪除操作能夠在常數時間復雜度(O(1))內完成。
如何理解桶?
哈希函數:當你插入一個鍵值對時,哈希表首先會通過一個哈希函數計算出該鍵的哈希值。哈希值是一個整數,表示該鍵在哈希表中的位置。
桶的數量:哈希表通常將桶的數量設置為一個固定的大小,這個大小可能是基于哈希表的當前大小動態擴展的。哈希表會根據哈希值將鍵映射到相應的桶。
桶的作用:每個桶是一個容器,桶中可以存放一個或多個鍵值對。哈希表通過哈希值來確定要查找哪個桶,進而查找該桶中的鍵值對。
桶沖突(碰撞):當多個鍵的哈希值相同,或者它們的哈希值被映射到相同的桶時,就會發生哈希碰撞。
為了處理這種情況,哈希表通常會使用一種方法來將多個元素存儲在同一個桶中,常見的解決方案有:
鏈式法(Chaining):每個桶實際上是一個鏈表(或者其他數據結構),多個鍵值對就可以在同一個桶中按鏈表的形式存儲。
開放尋址法(Open Addressing):當發生碰撞時,哈希表會尋找另一個空桶來存儲這個元素。
多次哈希:如果下標位置已被占用,就用另外一個hash函數計算新的下標位置。當然理論上來講,第二個hash函數算出的下標位置仍然可能已經被占用。
工程實踐上,前2種方式比較容易實現。比如Java中的HashMap是用鏈地址法處理哈希沖突;Rust中的HashMap是用開放尋址法中的二次尋址方式處理哈希沖突。
為什么桶重要?
桶的設計使得哈希表能夠有效地組織數據并在平均常數時間內執行操作。如果沒有桶,哈希表可能會退化成一個線性查找的結構,失去哈希表的效率優勢。
在 Rust 的 HashMap 中,桶的數量和哈希函數一起決定了哈希表的性能。當碰撞較多時,哈希表可能會進行擴展,增加桶的數量,以保持較好的性能。
HashMap是無序的,如果要使用有序的map,可以使用BTreeMap
use std::collections::BTreeMap;
-實現
基于平衡二叉樹(通常是紅黑樹)實現,確保鍵按順序排列。
特性
- 有序:鍵值對按鍵的排序順序存儲(默認是升序),可以進行范圍查詢等操作。
- 查找性能較差:查找、插入、刪除的時間復雜度是 O(log n),比哈希表稍慢。
- 適用于需要鍵有順序的場景,如按鍵排序或按范圍查詢。
3.2 創建 HashMap 的多種方式
創建hashmap的時候,首先需要將hashmap的庫導入進來
use std::collections::HashMap;
1)使用 new() 創建
指定hashmap的鍵值類型:HashMap<鍵的類型, 值的類型>
當然,也可以根據插入的鍵值進行自動推導
let mut map: HashMap<String, i32> = HashMap::new();
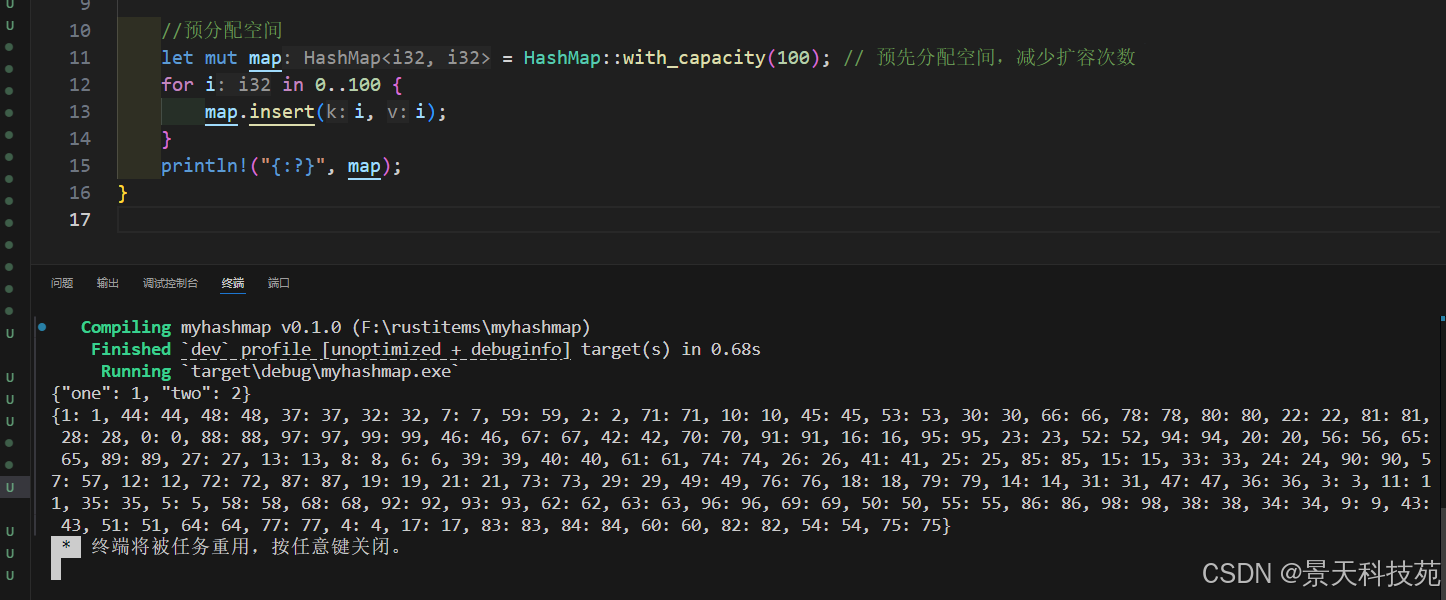
2)使用 with_capacity() 預分配空間
//預分配空間
let mut map = HashMap::with_capacity(100); // 預先分配空間,減少擴容次數
for i in 0..100 {map.insert(i, i);
}
println!("{:?}", map);
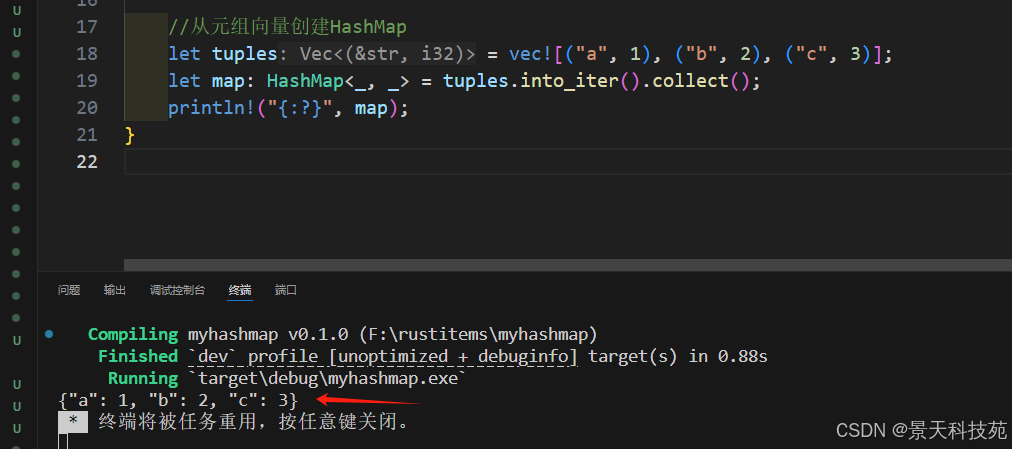
3)從元組向量創建
let tuples = vec![("a", 1), ("b", 2), ("c", 3)];
let map: HashMap<_, _> = tuples.into_iter().collect();
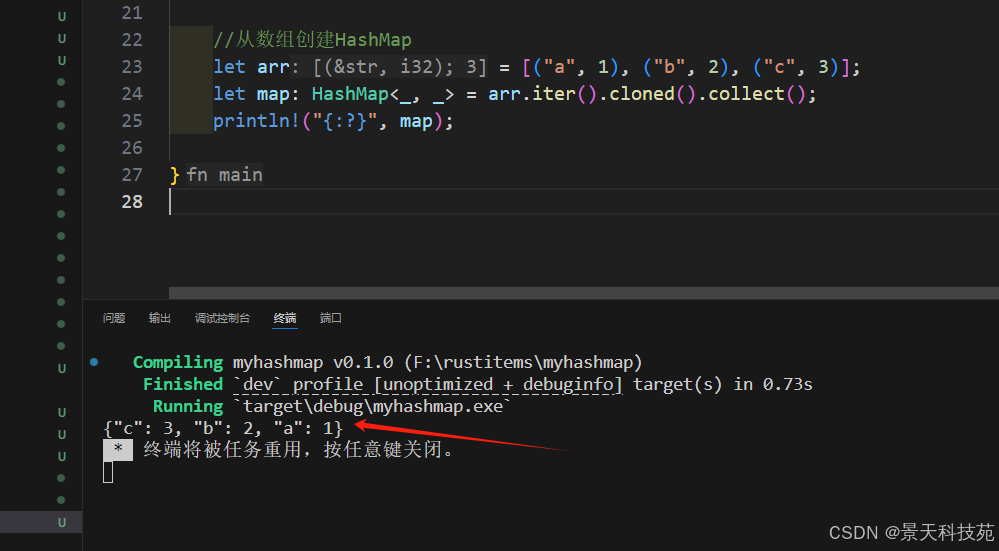
4)從數組創建創建
//從數組創建HashMap
let arr = [("a", 1), ("b", 2), ("c", 3)];
let map: HashMap<_, _> = arr.iter().cloned().collect();
println!("{:?}", map);
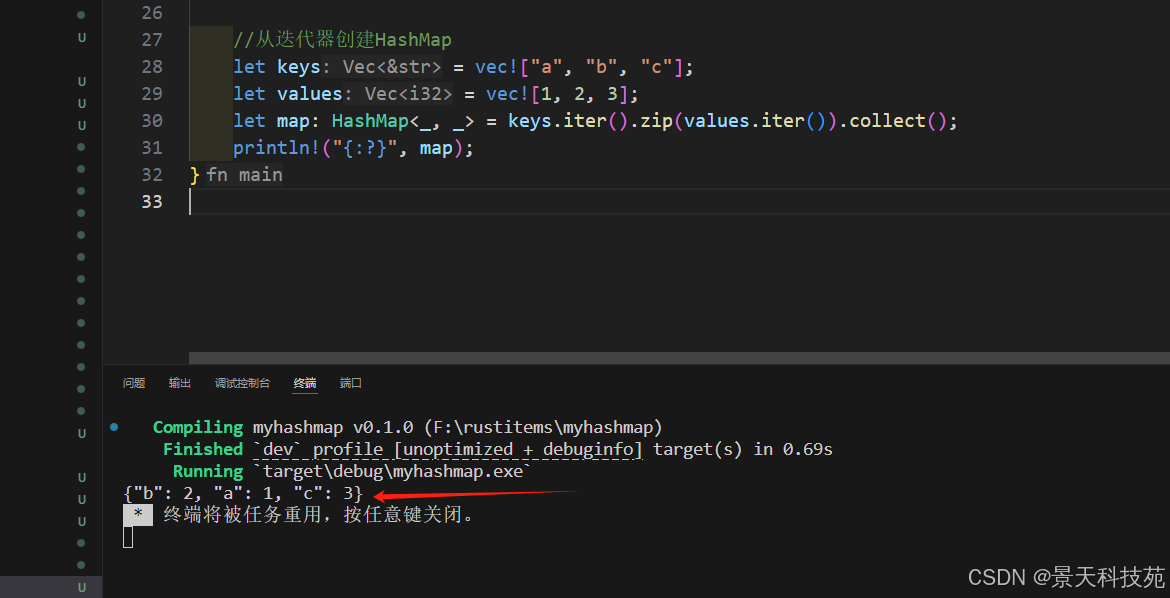
5)使用迭代器創建
let keys = vec!["a", "b", "c"];
let values = vec![1, 2, 3];
let map: HashMap<_, _> = keys.iter().zip(values.iter()).collect();
3.3 插入和更新值
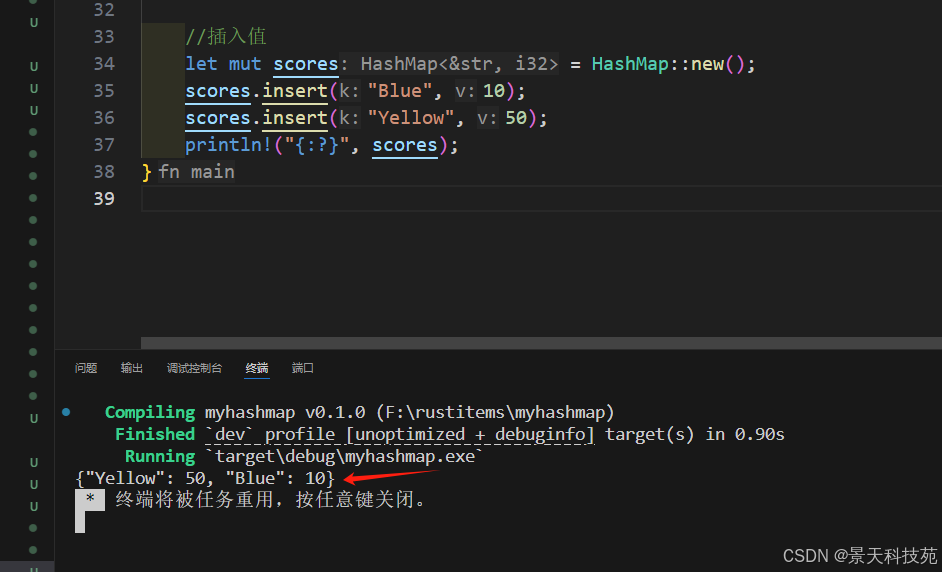
1)基本插入
let mut scores = HashMap::new();
scores.insert("Blue", 10);
scores.insert("Yellow", 50);
println!("{:?}", scores);
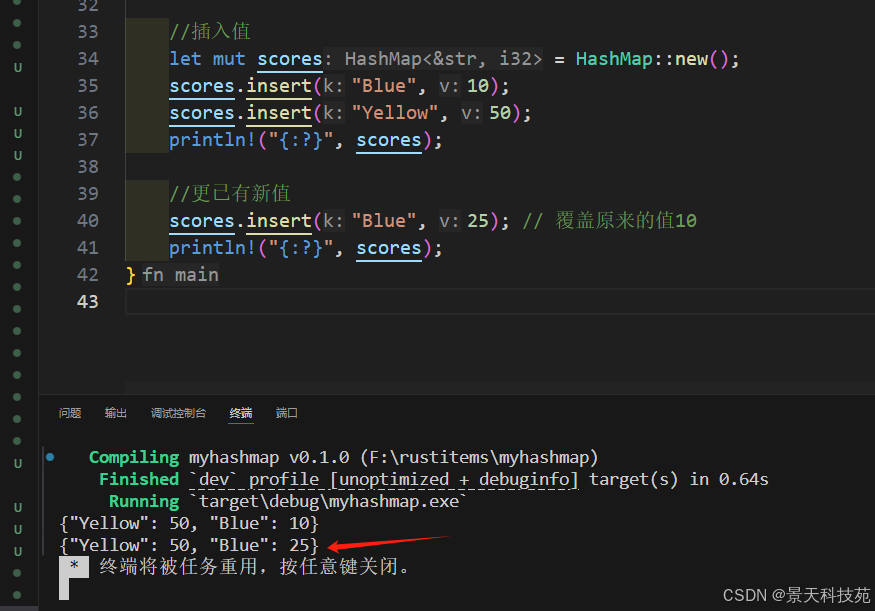
2)更新已有值
對于已經存在的鍵,執行插入操作就是更新已有值
scores.insert("Blue", 25); // 覆蓋原來的值10
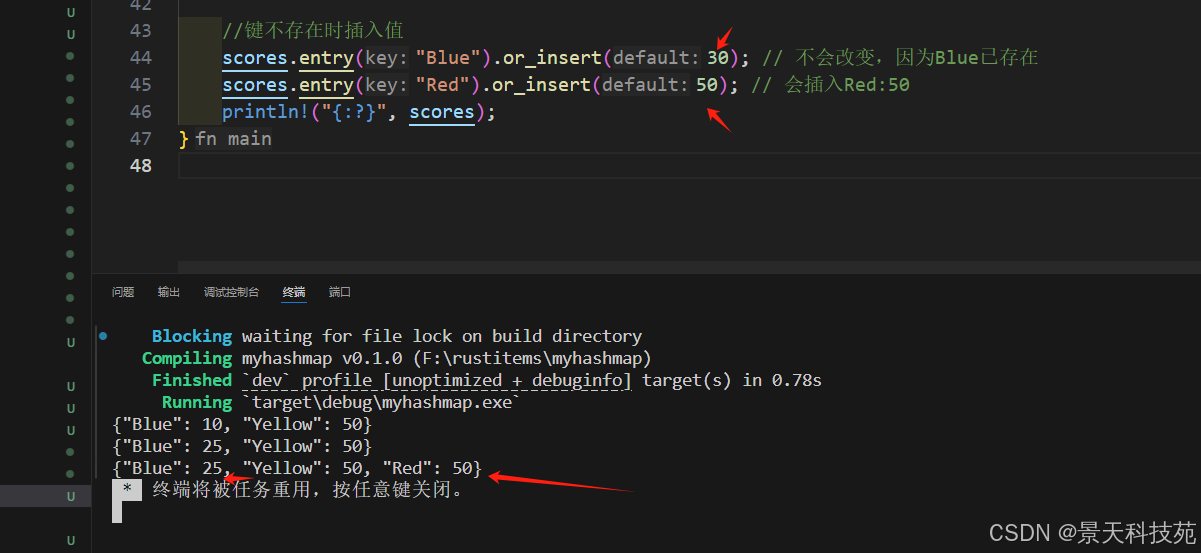
3)只在鍵不存在時插入
scores.entry("Blue").or_insert(30); // 不會改變,因為Blue已存在
scores.entry("Red").or_insert(50); // 會插入Red:50
4)根據舊值更新一個值
另一個常見的哈希 map 的應用場景是找到一個鍵對應的值并根據舊的值更新它
例如: 計數一些文本中每一個單詞分別出現了多少次。我們使用哈希 map 以單詞作為鍵并遞增其值來記錄我們遇到過幾次這個單詞。
如果是第一次看到某個單詞,就插入值 0 。
let text = "hello world wonderful world";let mut map = HashMap::new();for word in text.split_whitespace() {//這里使用的是entry().or_insert() 。只有單詞第一次出現的時候,才將該鍵插入到map,后續就不再繼續插進去修改,而是通過修改count來增加次數let count = map.entry(word).or_insert(0);//只要單詞出現過一次,就將count加上1,從而可以統計單詞出現的次數*count += 1;
}println!("{:?}", map); // 輸出: {"world": 2, "hello": 1, "wonderful": 1}
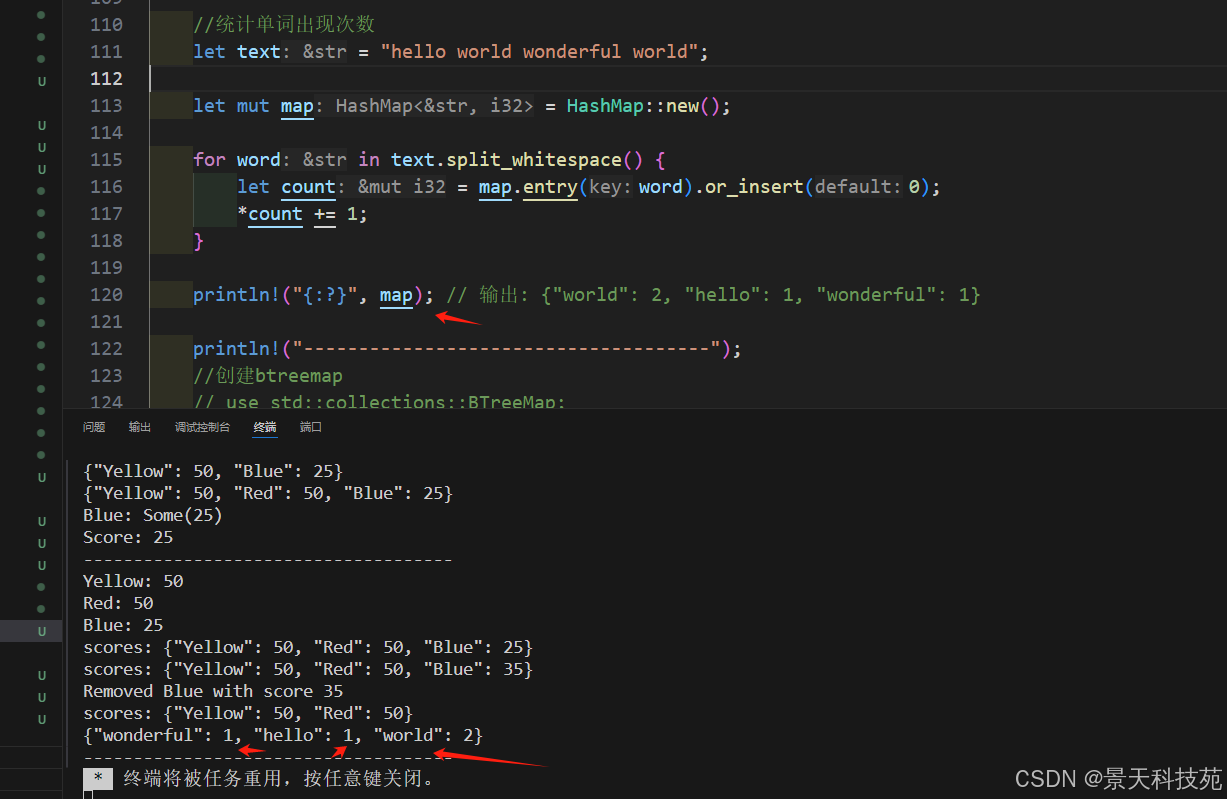
通過哈希 map 儲存單詞和計數來統計出現次數
or_insert 方法事實上會返回這個鍵的值的一個可變引用( &mut V )。
這里我們將這個可變引用儲存在 count 變量中,所以為了賦值必須首先使用星號( * )解引用 count 。
這個可變引用在 for 循環的結尾離開作用域,這樣所有這些改變都是安全的并符合借用規則。
3.4 訪問值
1)使用 get 方法
get的參數是個引用
返回的是Option<&V>
//訪問值
let team_name = "Blue";
let score = scores.get(team_name); // 返回Option<&i32>
println!("{}: {:?}", team_name, score);
//使用match語句處理Option
match score {Some(s) => println!("Score: {}", s),None => println!("Team not found"),
}

可以使用功能if let簡化
//訪問值
let team_name = "Blue";
let score = scores.get(team_name); // 返回Option<&i32>
println!("{}: {:?}", team_name, score);
//使用match語句處理Option
if let Some(s) = score {println!("Score: {}", s);
} else {println!("Team not found");
}
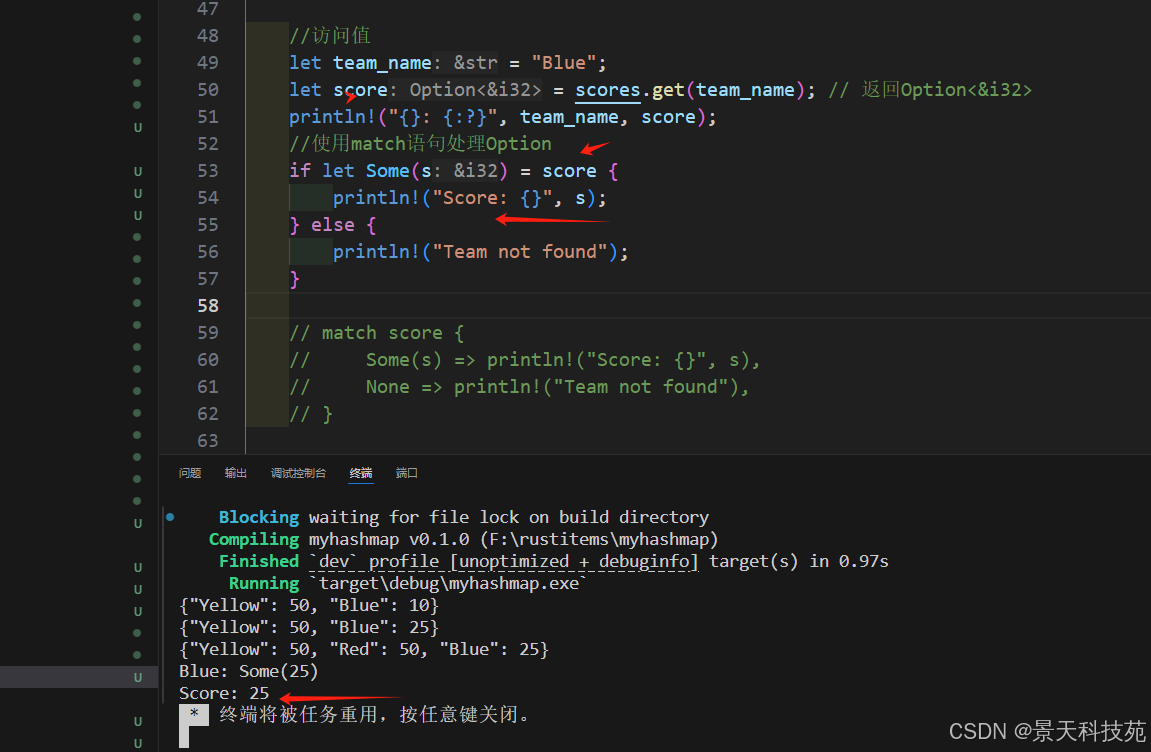
2)使用 get_mut 獲取可變引用
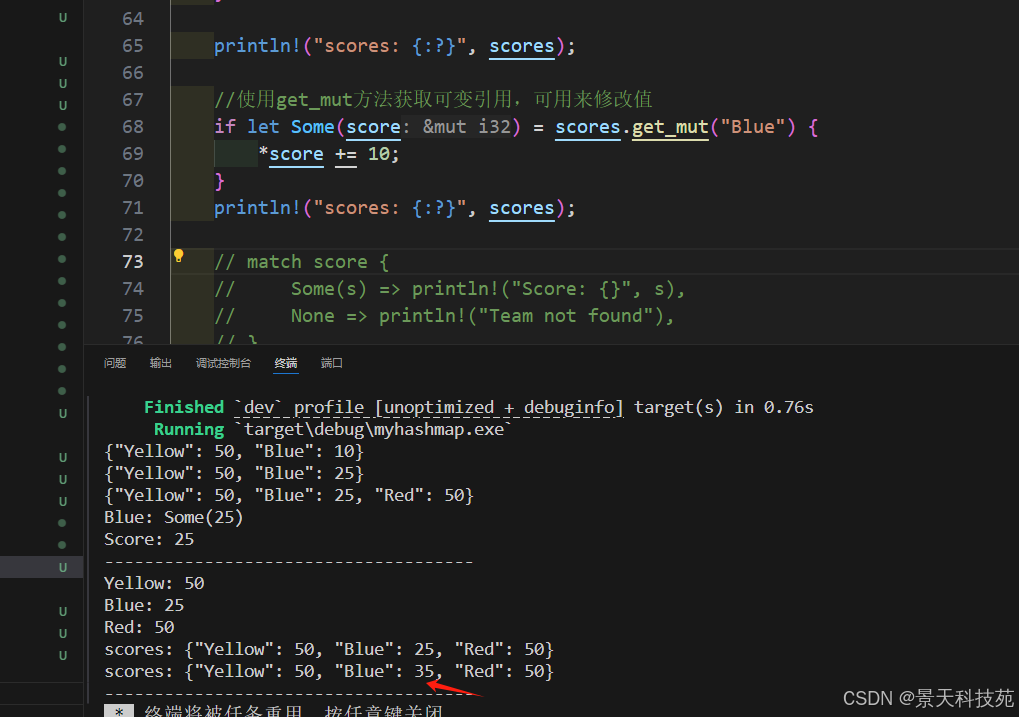
//使用get_mut方法獲取可變引用,可用來修改值
if let Some(score) = scores.get_mut("Blue") {*score += 10;
}
可以看到Blue的值加了10
3)遍歷hashmap
注意:遍歷使用的是hashmap的引用,如果不使用引用,此時的hashmap就被借用,后續就不可以再用這個hashmap了
//遍歷HashMap
for (key, value) in &scores {println!("{}: {}", key, value);
}
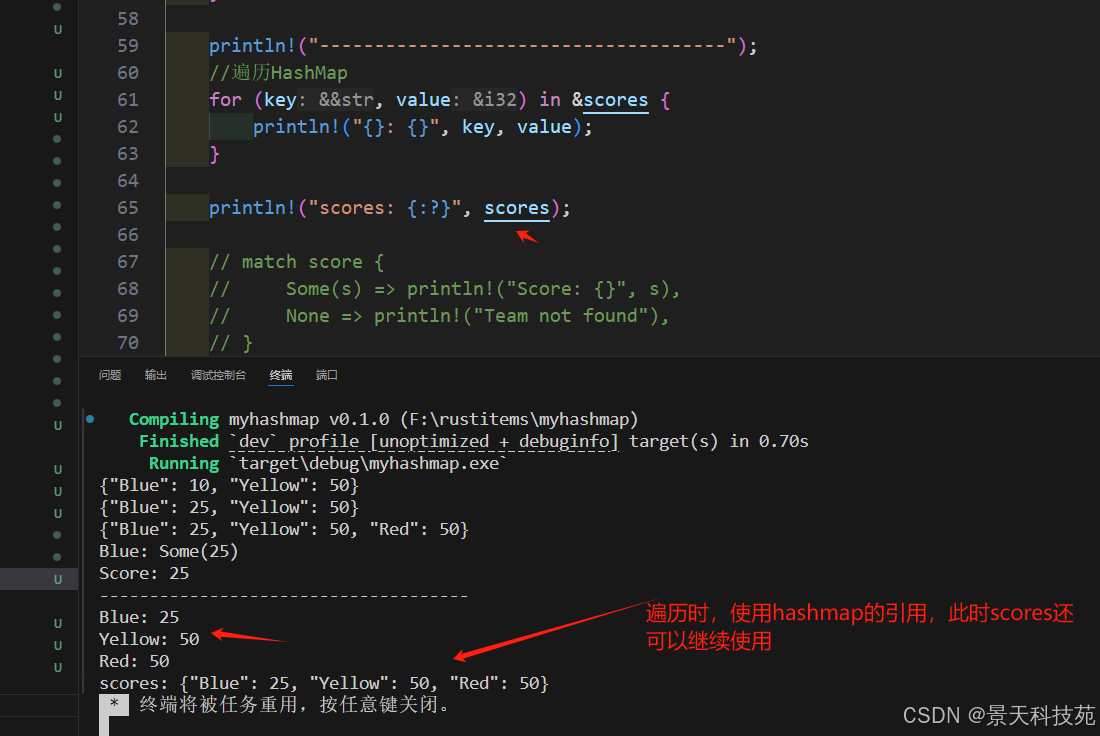
3.5 刪除操作
1)使用 remove 刪除
返回被刪除的值Option<V>
//刪除鍵值對
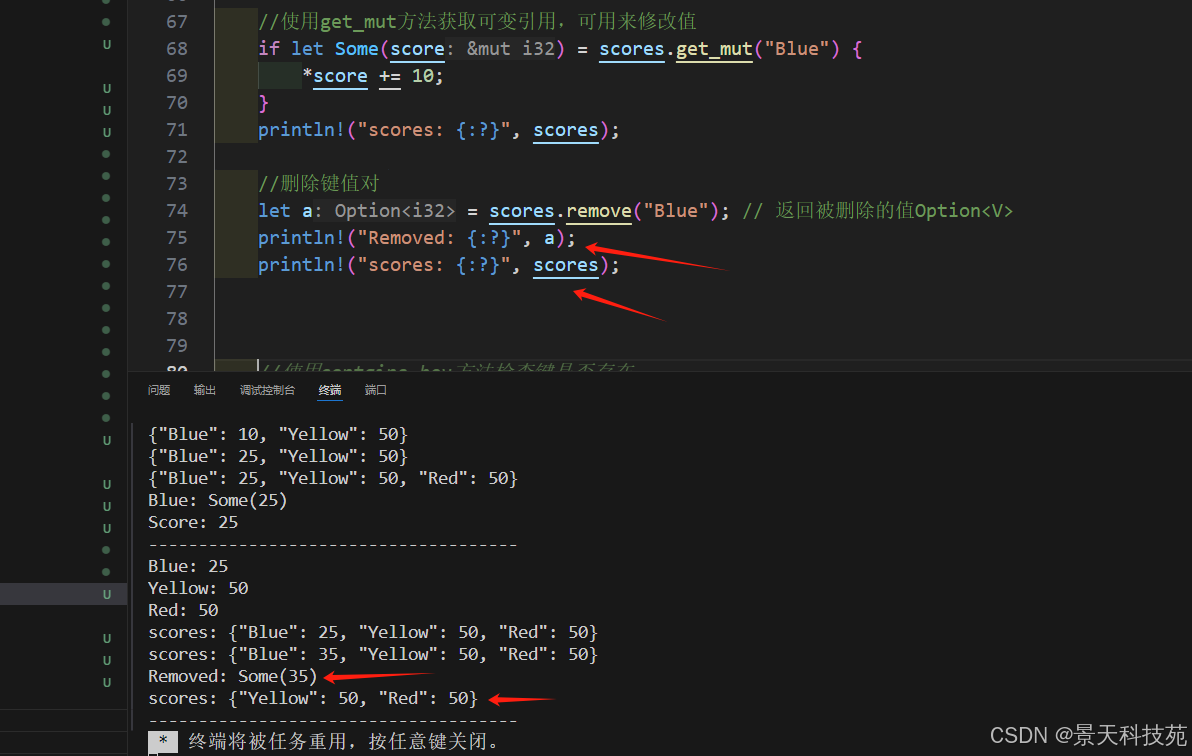
let a = scores.remove("Blue"); // 返回被刪除的值Option<V>
println!("Removed: {:?}", a);
println!("scores: {:?}", scores);
2)使用 remove_entry 刪除并返回鍵值對
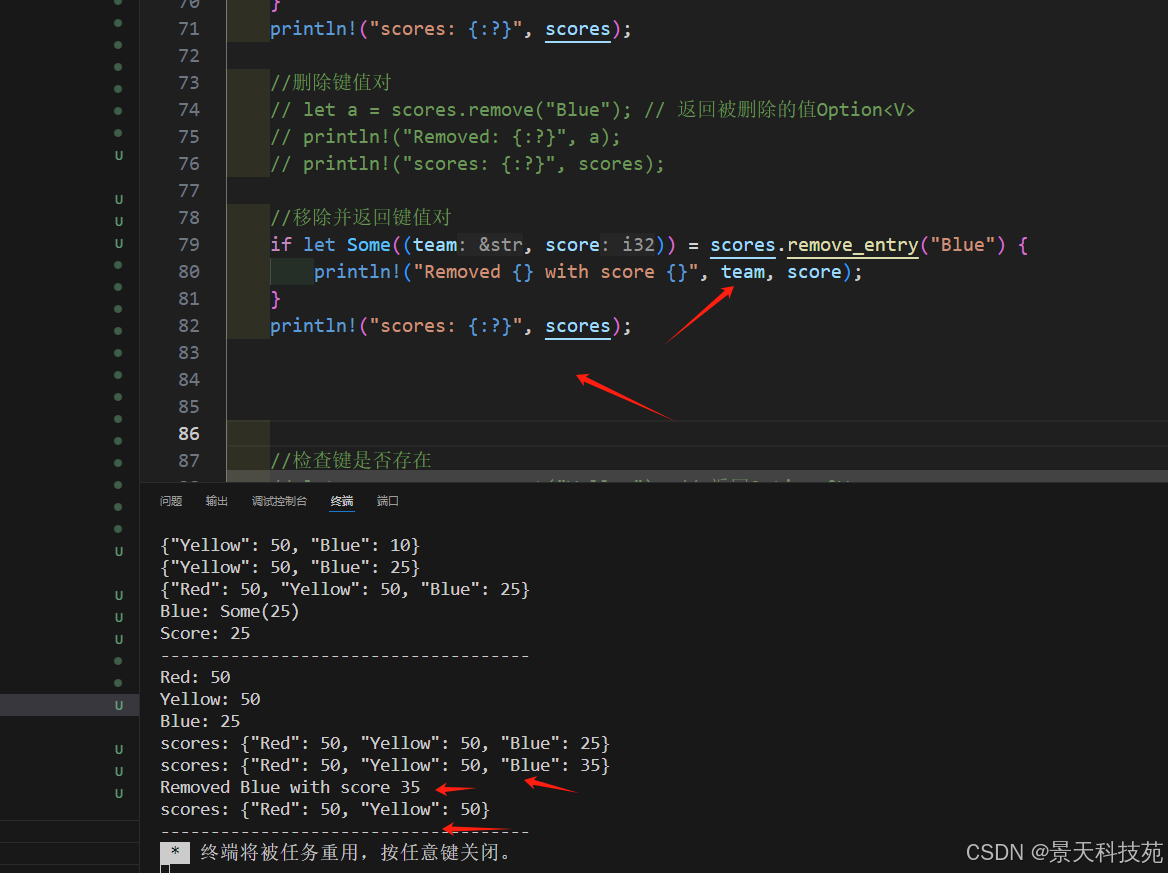
if let Some((team, score)) = scores.remove_entry("Blue") {println!("Removed {} with score {}", team, score);
}
3.6 哈希算法選擇
Rust 默認使用加密安全的哈希算法,但有時我們需要更快的哈希算法。
需要先安裝包
cargo add twox_hash
use std::collections::HashMap;
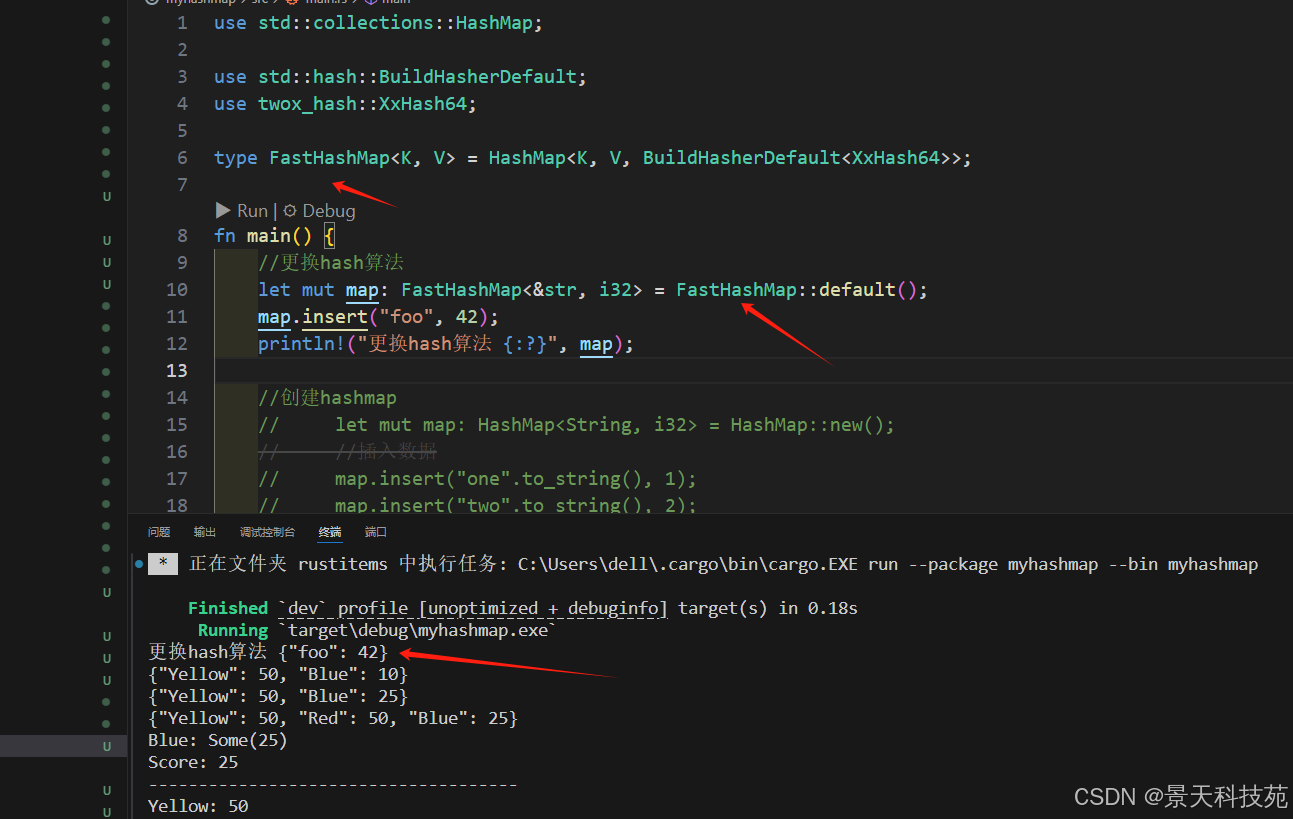
use std::hash::BuildHasherDefault;
use twox_hash::XxHash64;type FastHashMap<K, V> = HashMap<K, V, BuildHasherDefault<XxHash64>>;fn main() {let mut map: FastHashMap<&str, i32> = FastHashMap::default();map.insert("foo", 42);
}
使用更換過hash算法的類型創建hashmap
3.7 HashMap的其他一些常見用法
1)獲取長度 - len()
println!("Number of teams: {}", scores.len());
2)檢查是否為空 - is_empty()
if scores.is_empty() {println!("No teams registered!");
}
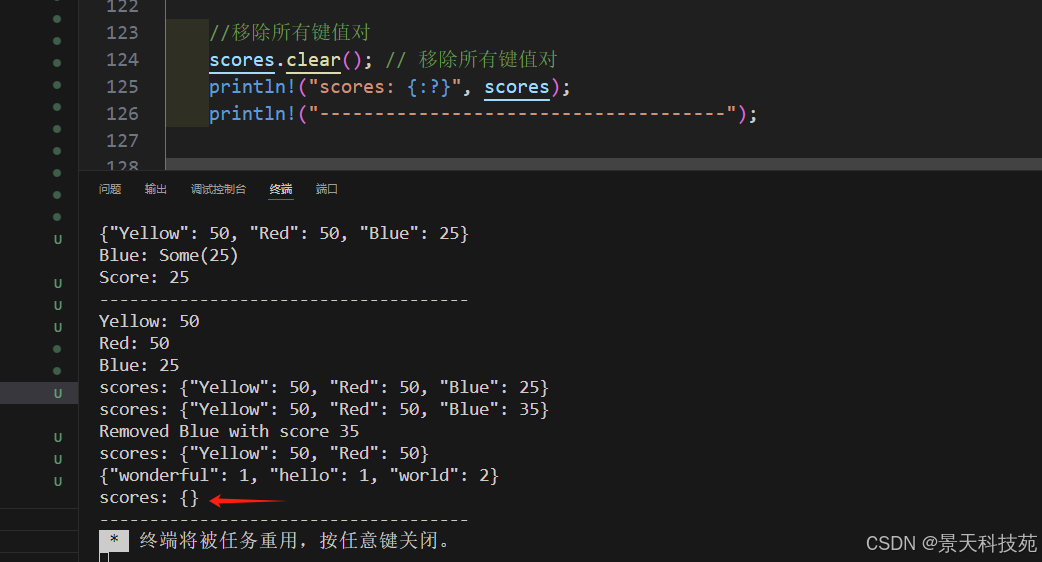
3)清空 HashMap - clear()
scores.clear(); // 移除所有鍵值對
4)獲取鍵或值的集合
let teams: Vec<_> = scores.keys().collect();
let points: Vec<_> = scores.values().collect();
println!("teams: {:?}", teams);
println!("points: {:?}", points);
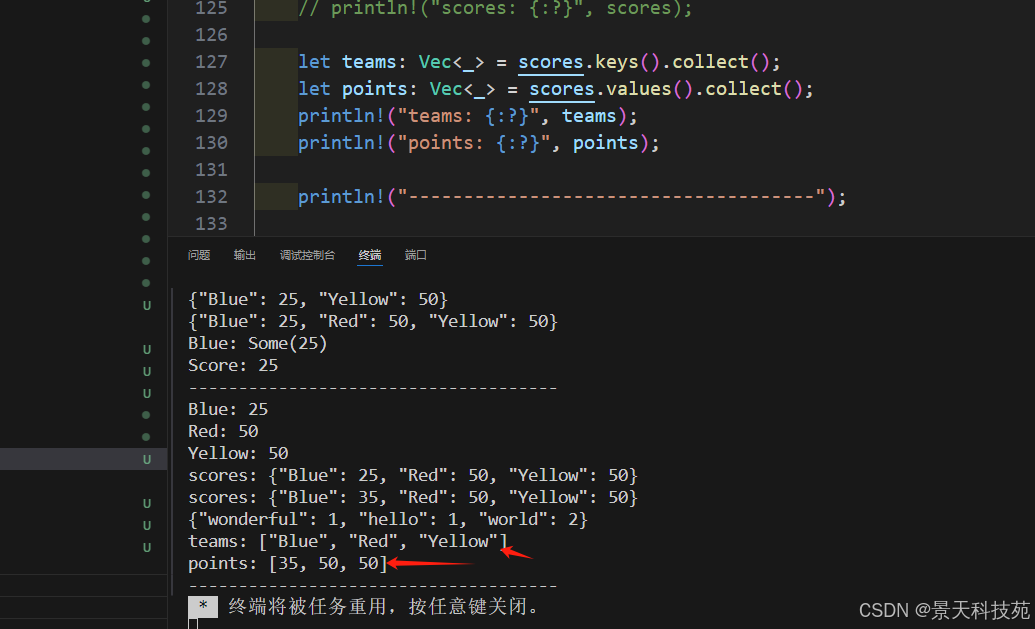
5)檢查鍵是否存在
//檢查鍵是否存在
let score = scores.get("Yellow"); // 返回Option<&V>
if score.is_some() {println!("Yellow team exists");
} else {println!("Yellow team does not exist");
}//使用contains_key方法檢查鍵是否存在
if scores.contains_key("Yellow") {println!("Yellow team exists");
} else {println!("Yellow team does not exist");
}
接口測試)



】)














