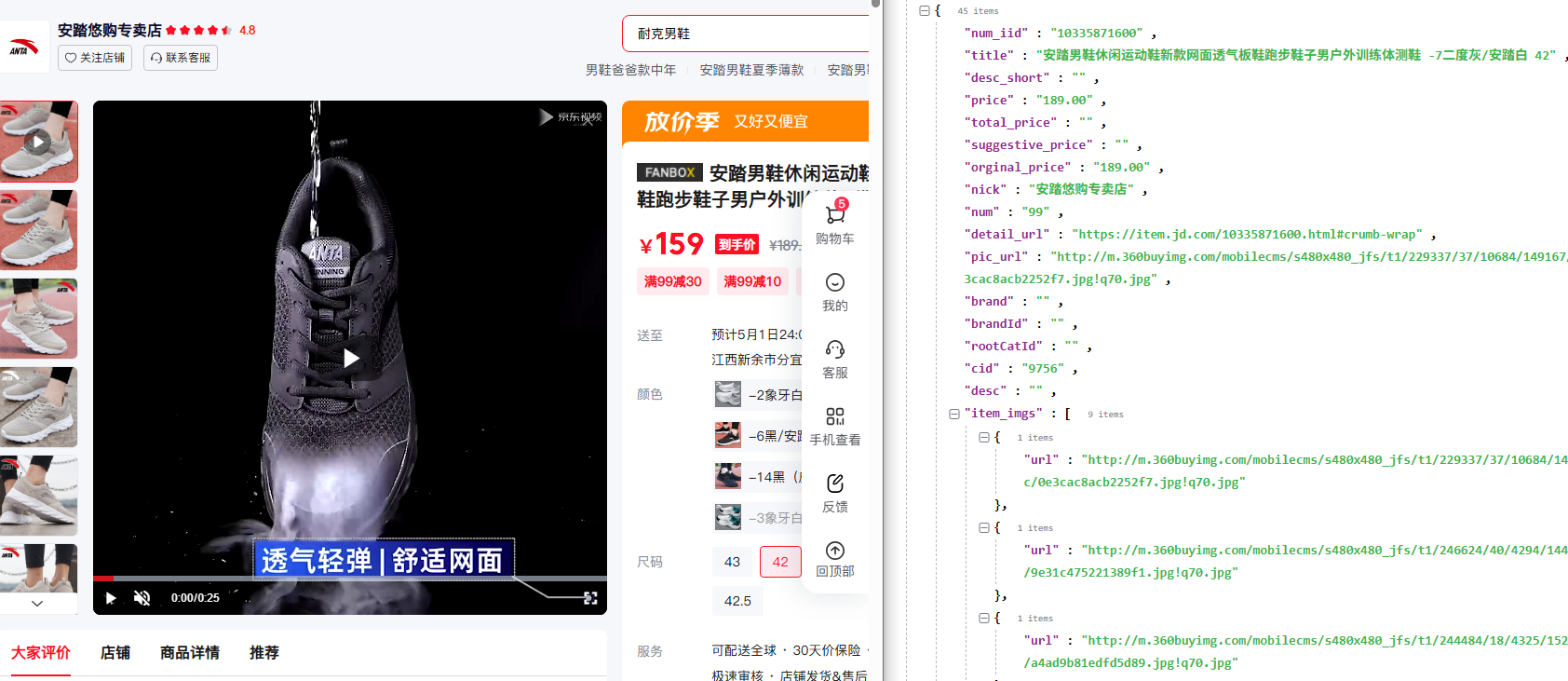
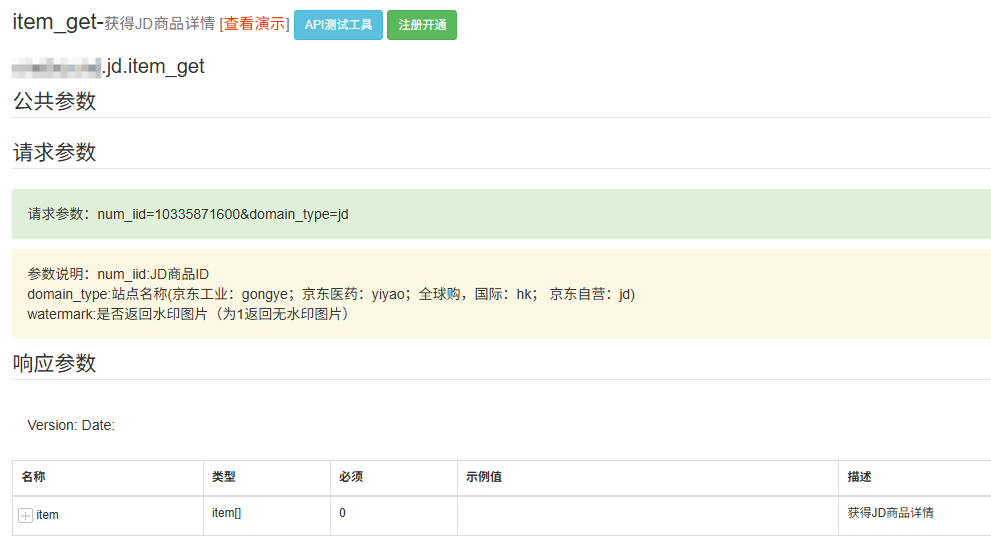
在當今數字化商業時代,電商數據對于市場分析、競品研究、價格監控等諸多領域有著不可估量的價值。京東,作為國內首屈一指的電商巨頭,其商品詳情頁蘊含著海量且極具價值的數據,涵蓋商品價格、庫存、規格、用戶評價等關鍵信息。然而,嘗試從京東平臺爬取這些數據的開發者或數據分析師,往往會面臨一系列棘手的難題,這主要歸因于京東完善且復雜的反爬蟲機制。接下來,讓我們深入剖析京東商品詳情數據爬取過程中的難點,并探討相應的解決方案。京東商品詳情數據已封裝API,可測:Jennifer_20230201(地球chart)
一、爬取京東商品詳情數據的難點剖析
(一)復雜且多元的反爬蟲機制
- IP 封禁策略:京東對同一 IP 地址在短時間內的頻繁訪問極為敏感。一旦檢測到某個 IP 的請求頻率超出正常范圍,便會迅速將其封禁。這種封禁可能是短期的,如幾小時,也可能是長期的,甚至永久性封禁。這使得爬蟲在持續獲取數據時,面臨因 IP 被封而中斷的風險。例如,一個未合理設置請求頻率的爬蟲,可能在短時間內發送大量請求,幾分鐘內就導致 IP 被封禁,無法繼續爬取。
- 驗證碼挑戰:為了區分正常用戶與爬蟲程序,京東在某些情況下會彈出驗證碼。這些驗證碼形式多樣,包括數字字母組合、滑塊拼圖、點選驗證碼等。識別驗證碼對于爬蟲而言是一項艱巨任務。若采用人工識別,效率極低且不現實;借助第三方平臺識別,不僅增加了成本,還涉及到平臺可靠性和數據安全問題;而利用機器學習模型進行識別,需要大量的訓練數據和較高的技術門檻,模型的準確率也并非 100%。
- 動態加載技術應用:京東商品詳情頁的部分關鍵數據并非在頁面初始加載時就全部呈現,而是通過 JavaScript 動態加載。傳統的爬蟲工具,如簡單的基于 HTTP 請求的庫,往往只能獲取到初始靜態頁面內容,無法獲取動態加載的數據。例如,商品的某些規格參數、實時庫存數量等,可能在頁面加載完成后,通過后續的 JavaScript 腳本從服務器獲取并填充到頁面中,常規爬蟲難以捕捉到這些動態更新的數據。
- 數據加密手段:對于一些核心數據,京東采取了加密措施。這意味著即使爬蟲成功獲取到數據,呈現出來的也是加密后的密文,無法直接使用。破解加密算法需要深入分析網頁的 JavaScript 代碼,找出加密函數和密鑰生成機制。然而,京東的加密算法通常較為復雜,且可能會不定期更新,增加了破解的難度和不確定性。
(二)海量且動態變化的數據
京東平臺商品種類繁多,涵蓋了電子數碼、服裝服飾、家居百貨、食品生鮮等幾乎所有品類,這導致 SKU(庫存保有單位)數據量極為龐大。同時,商品的價格、庫存等信息處于實時動態變化中。以價格為例,在促銷活動期間,價格可能每隔幾分鐘甚至幾秒鐘就會更新一次;庫存數量也會隨著用戶下單而實時減少。要實現對如此海量且動態變化的數據進行高效、準確的爬取,對爬蟲的性能、效率以及數據處理能力都提出了極高要求。一方面,需要爬蟲具備快速的數據采集能力,以跟上數據變化的速度;另一方面,要能夠有效處理和存儲大量數據,確保數據的完整性和及時性。
(三)法律合規風險
在網絡數據爬取領域,法律邊界逐漸明晰且嚴格。爬取電商平臺數據存在諸多法律風險,若不謹慎對待,可能會引發嚴重后果。京東作為擁有完善法務體系的企業,非常重視自身數據權益的保護。我國相關法律法規,如《網絡安全法》《電子商務法》等,對未經授權的數據爬取行為有明確約束。未經京東許可,擅自爬取其平臺數據,可能侵犯了京東的商業權益,面臨法律訴訟風險。同時,如果爬取的數據涉及用戶隱私信息,如用戶評價中的個人敏感信息,還可能觸犯關于個人信息保護的法律條款。此外,若將爬取的數據用于不正當競爭,如惡意比價、抄襲商品描述等,也會違反反不正當競爭相關法律。
二、應對京東商品詳情數據爬取難點的解決方案
(一)模擬真實瀏覽器行為
借助 Selenium、Puppeteer 等工具,可以模擬真實用戶在瀏覽器中的操作行為。Selenium 通過控制瀏覽器驅動,能夠打開京東商品詳情頁,模擬鼠標點擊、滾動頁面、輸入內容等操作,使爬蟲的行為更接近真實用戶。Puppeteer 則是基于 Chrome DevTools 協議的 Node.js 庫,同樣可以實現對 Chrome 瀏覽器的自動化控制,執行復雜的頁面交互操作。例如,使用 Selenium 打開京東商品詳情頁后,等待頁面所有資源加載完成,包括動態加載的數據,再進行數據提取,這樣可以有效繞過一些基于頁面加載狀態檢測的反爬蟲機制。同時,模擬用戶在頁面上的停留時間,避免短時間內快速切換頁面或頻繁請求數據,降低被識別為爬蟲的風險。
(二)構建和使用代理 IP 池
為解決 IP 封禁問題,使用代理 IP 池是一種行之有效的方法。代理 IP 池由大量的代理 IP 地址組成,可以通過購買專業的代理 IP 服務,如 Luminati、Oxylabs 等,獲取高質量的代理 IP 資源。在爬蟲程序中,配置代理 IP 池,使每次請求隨機從池中選取一個 IP 地址作為請求的源 IP。當某個 IP 因訪問頻繁被封禁時,爬蟲可以自動切換到其他可用 IP 繼續進行數據爬取。例如,設置每請求 10 次或 20 次就更換一次代理 IP,保持請求源 IP 的多樣性,有效規避京東對單個 IP 的訪問頻率限制。同時,需要定期對代理 IP 池中的 IP 進行可用性檢測,及時剔除不可用的 IP,保證代理 IP 的質量和穩定性。
(三)破解動態加載數據難題
- 分析 JavaScript 代碼定位數據接口:深入分析京東商品詳情頁的 JavaScript 代碼,找出負責動態加載數據的函數和相關邏輯。通過瀏覽器的開發者工具,在 “Network” 標簽下觀察頁面加載過程中的網絡請求,篩選出與動態數據加載相關的請求。這些請求通常指向特定的數據接口,接口地址可能包含商品 ID 等關鍵參數。例如,發現某個請求的 URL 為 “https://api.jd.com/product/detail?id=123456”,其中 “123456” 為商品 ID,該接口可能返回對應商品的詳細規格參數、庫存等動態加載數據。確定數據接口后,爬蟲可以直接向該接口發送請求,獲取所需數據,而無需依賴頁面的完整加載和 JavaScript 執行。
- 使用無頭瀏覽器結合接口請求:在一些復雜場景下,僅通過分析接口可能無法完全獲取所有數據,或者接口請求需要特定的請求頭、Cookie 等信息。此時,可以結合無頭瀏覽器(如 Chrome 無頭模式)與接口請求的方式。首先使用無頭瀏覽器打開商品詳情頁,讓其執行 JavaScript 代碼,完成頁面初始化和必要的登錄、權限驗證等操作,獲取頁面加載過程中生成的 Cookie 等關鍵信息。然后,利用這些信息構造對數據接口的請求,通過接口獲取動態加載的數據。這種方式既能利用無頭瀏覽器模擬真實用戶行為獲取必要的請求參數,又能通過直接請求接口提高數據獲取效率。
(四)攻克數據加密難關
- 逆向分析加密算法:通過對京東商品詳情頁的 JavaScript 代碼進行逆向工程,找出數據加密所使用的算法和密鑰生成邏輯。使用反編譯工具或在線 JavaScript 反混淆平臺,對加密相關的代碼進行解析和還原,使其更易于閱讀和理解。例如,發現加密函數名為 “encryptData”,通過分析該函數的代碼邏輯,確定其使用的加密算法為 AES - 256,并且找到了密鑰是通過某個用戶特定的信息和時間戳經過一系列哈希運算生成的。了解加密算法和密鑰生成機制后,在爬蟲程序中實現相應的解密邏輯,對獲取到的加密數據進行解密,還原出原始的商品信息。
- 跟蹤加密算法更新并及時調整:由于京東可能會不定期更新加密算法以增強數據安全性,爬蟲開發者需要持續關注京東網頁代碼的變化。可以定期使用版本控制工具(如 Git)對京東商品詳情頁的 JavaScript 代碼進行備份和對比分析,一旦發現加密算法有更新,及時進行逆向分析和研究,調整爬蟲程序中的解密邏輯,確保能夠持續獲取解密后的數據。同時,建立與其他爬蟲開發者或技術社區的交流渠道,及時分享和獲取關于京東加密算法更新的信息,共同應對加密難題。
(五)構建分布式爬蟲架構提升效率
針對京東海量商品數據的爬取需求,采用分布式爬蟲架構是提升效率和穩定性的關鍵策略。分布式爬蟲架構將爬蟲任務分解為多個子任務,分配到不同的計算節點(如多臺服務器或云主機)上并行執行。每個計算節點負責爬取一部分商品的數據,最后將各個節點獲取到的數據匯總到一起。通過這種方式,可以充分利用多臺設備的計算資源和網絡帶寬,顯著提高數據爬取速度。例如,使用 Scrapy - Redis 框架構建分布式爬蟲。Scrapy 是一款強大的 Python 爬蟲框架,Redis 則作為分布式任務隊列和數據共享存儲。在該架構下,多個 Scrapy 爬蟲實例從 Redis 隊列中獲取待爬取的商品 URL 任務,各自獨立進行數據爬取,并將爬取到的數據存儲到共享的 Redis 數據庫中。通過合理配置計算節點的數量和任務分配策略,可以根據實際需求靈活調整爬取效率,同時保證系統的穩定性和容錯性,即使部分節點出現故障,其他節點仍能繼續工作,不影響整體爬取任務的進行。
(六)嚴守法律法規確保合規操作
在進行京東商品詳情數據爬取之前,務必仔細研讀京東平臺的 robots 協議,明確哪些數據允許被爬取,哪些是禁止訪問的。robots 協議通常位于京東網站根目錄下的 “robots.txt” 文件中,其中詳細規定了搜索引擎爬蟲和其他自動化程序的訪問權限。例如,協議可能規定某些涉及用戶隱私、商業機密或后臺管理的頁面禁止爬取。同時,深入學習我國相關的法律法規,包括但不限于《網絡安全法》《電子商務法》《民法典》中關于數據保護和不正當競爭的條款。確保爬取行為符合法律要求,不侵犯京東平臺及其用戶的合法權益。在實際操作中,如果爬取的數據僅用于個人學習、研究或內部數據分析等合理使用目的,且不進行數據傳播和商業利用,通常是符合法律規定的。若涉及商業用途,如為企業提供市場調研數據服務等,應考慮通過合法途徑,如申請京東開放平臺的 API 接口權限,獲取所需數據,避免因非法爬取帶來法律風險。


詳解)
)





(根文件系統進emmc,鏡像和設備樹進flash))









