目錄
1.1.定義
1.2.參數
1.3.分類
2.session
4.使用session登錄
1.cookie
????????由于http是一個無狀態的協議,請求與請求之間無法相互傳遞或者記錄一些信息,cookie和session正是為了解決這個問題而產生。
? ? ? ? 例子:當我需要爬取我的微博賬號的粉絲信息的時候,如果直接使用下面的代碼
import requestsbase_url = 'https://weibo.com/u/6320270401'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36',
}
response=requests.get(base_url,headers=headers)
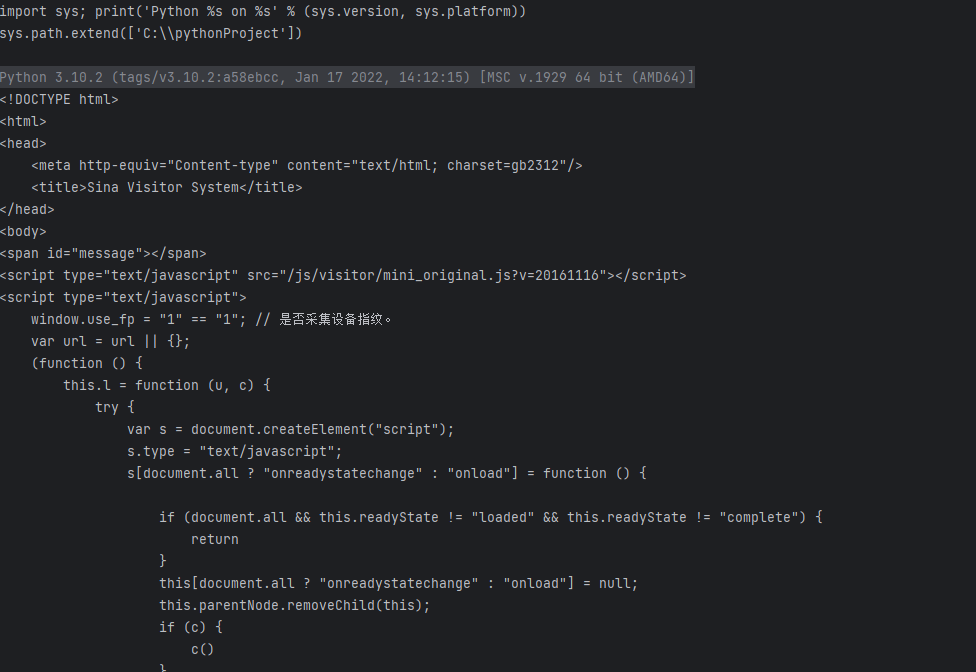
是獲取不到信息的,
這并不是微博的個人信息頁面。這也再一次證明了如果代碼中并沒有攜帶Cookie信息,則并不會進入到個人信息頁面,而是跳轉到了其他頁面。
1.1.定義
定義:cookie指某些網站為例辨別用戶身份,進行會話跟蹤而存儲在用戶本地終端上的數據
1.2.參數
參數:
| 字段 | 作用 |
|---|---|
| Name | Cookie的名稱,創建后不可更改。 |
| Value | Cookie的值。Unicode字符需編碼,二進制數據需BASE64編碼。 |
| Domain | 可訪問該Cookie的域名(如?.zhihu.com?允許所有子域名訪問)。若未指定,默認為當前域名。 |
| MaxAge | 失效時間(秒)。正數表示存活時間;負數表示瀏覽器關閉后失效;0表示立即刪除。與Expires配合使用(優先級高于Expires)。 |
| Path | 限制Cookie的路徑訪問。例如?/path/?僅允許該路徑下的頁面訪問;/?表示全站可訪問。 |
| Size | Cookie的大小(字節)。 |
| HTTP | 若為true,則僅通過HTTP頭傳輸,禁止JavaScript(如document.cookie?)訪問,增強安全性(防XSS攻擊)。 |
| Secure | 若為true,僅通過HTTPS/SSL等安全協議傳輸,防止明文泄露。默認為false。 |
1.3.分類
- 會話cookie
- 持久cookie
- 會話cookie指存在瀏覽器內存的cookie,當瀏覽器關閉,會話cookie會失效。
- 持久cookie是保存在硬盤上的cookie
- 這兩種cookie的分配標準主要是通過maxAge或者expires這個cookie字段
2.session
(議會等的)會議,會期;
Session(會話)是服務端用來跟蹤用戶狀態的機制。核心原理是:
- 服務器為每個用戶創建唯一的Session ID(通常通過Cookie傳遞),并將用戶數據(如登錄信息、購物車)存儲在服務端(內存、數據庫或緩存中)。
- 客戶端僅持有Session ID,實際數據不暴露,安全性更高。
| 維度 | Cookie | Session |
|---|---|---|
| 存儲位置 | 客戶端 | 服務端 |
| 安全性 | 較低(需額外防護) | 較高(依賴Session ID安全) |
| 生命周期 | 可長期或會話級 | 通常會話級 |
| 性能影響 | 增加網絡負載 | 增加服務器負載 |
| 典型應用 | 用戶偏好、跟蹤 | 登錄狀態、敏感操作 |
????????聯系:當客戶端發送一個cookie,服務器會從這個cookie中找到sessionID,再查找出相應的session信息返回給客戶端,來進行用戶頁面的流轉。如果通過sessionID來查找session的時候,發現沒有session(一般第一次登陸或者清空了瀏覽器),那么就會創建一個session。
3.使用cookie登錄微博
獲取cookie:在控制臺輸入:
document.cookie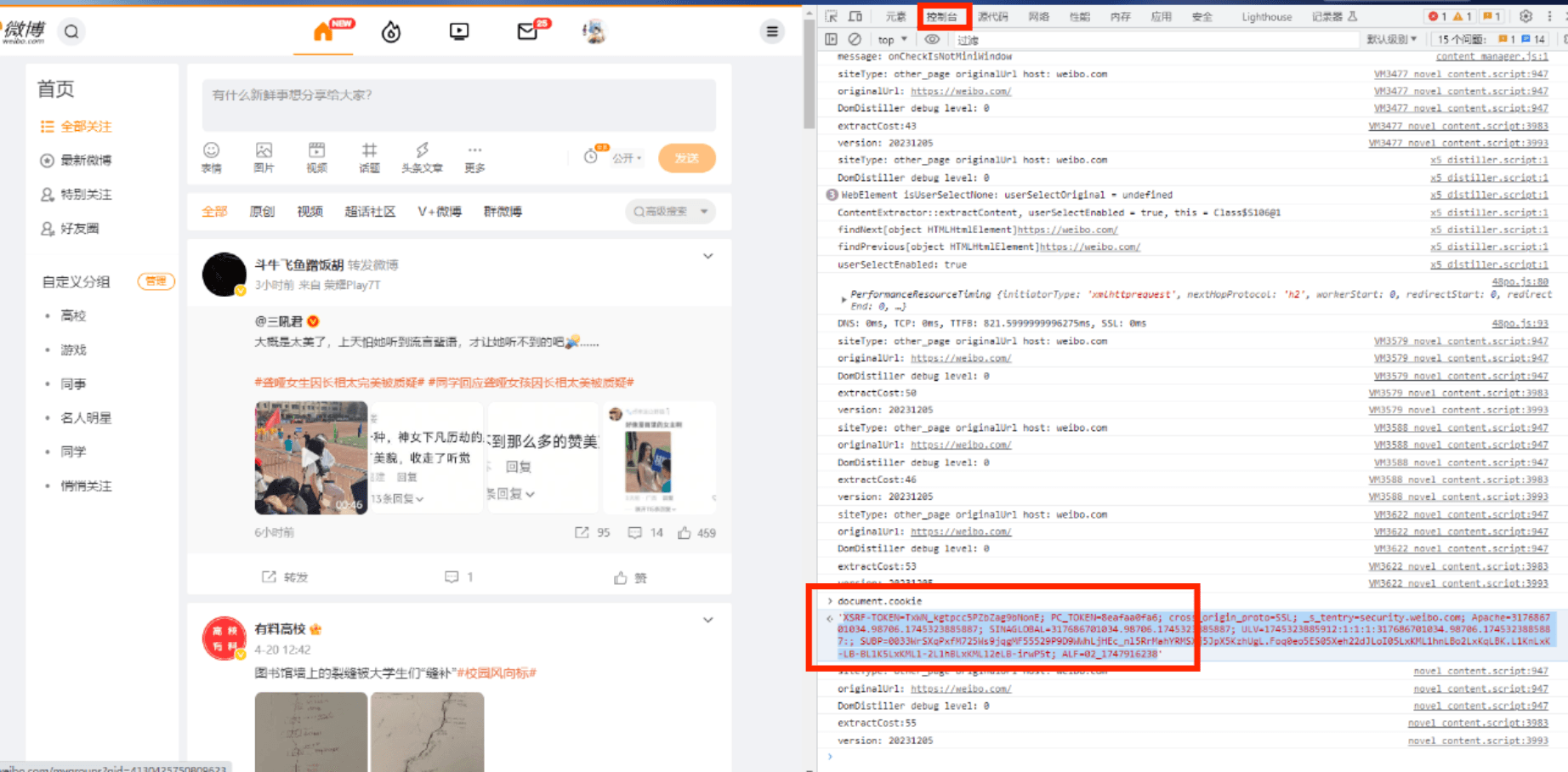
然后把獲取到的cookie復制到代碼中:
import urllibimport requestsurl = 'https://weibo.com/u/6320270401'headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) QQBrowser/11.8.5118.400','cookie':'你的cookie'
}
# 請求對象的定制# request = requests.get(url, headers=headers)
# 請求對象的定制
request = urllib.request.Request(url=url, headers=headers)
# 模擬瀏覽器向服務器發送請求
response = urllib.request.urlopen(request)
# 獲取響應數據
content = response.read().decode("gb2312")
# 打印響應數據
print(content)
# 下載到本地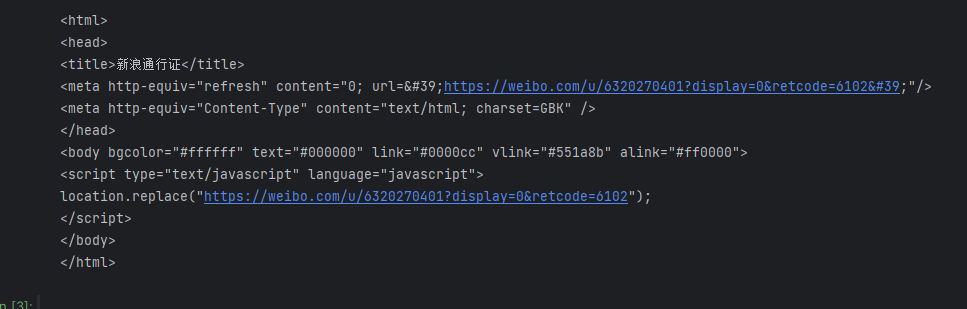
運行網頁直接打開界面:
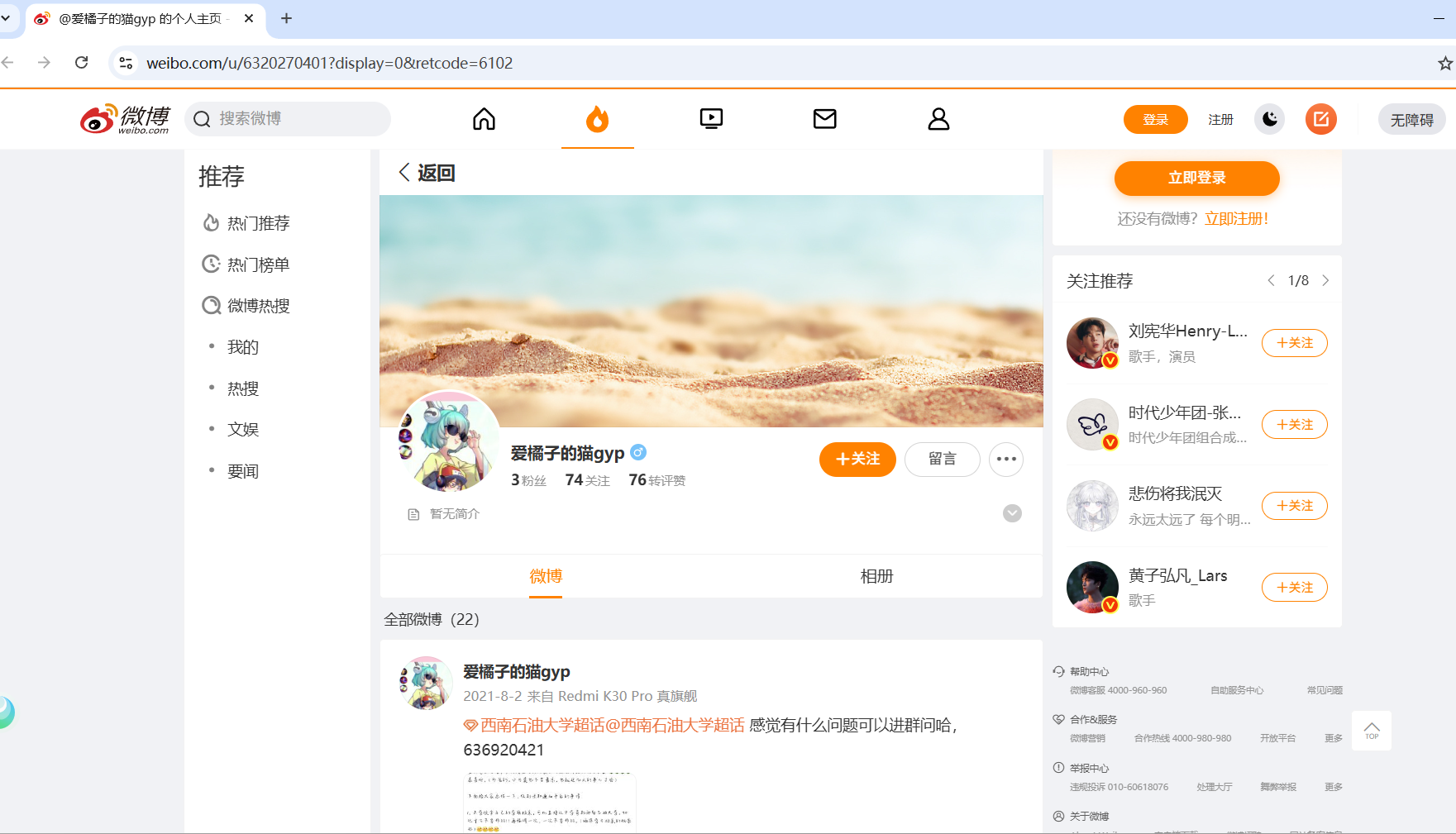
可以看到,得到的是個人信息頁面,但內容并不完整,可以說是完全沒有實際的內容,可能微博這幾年不斷更新,優化了反爬手段,只添加Cookie還不足以成功爬取個人頁面的完整內容。不過,能到這一步就可以了。這里主要講解Cookie的作用。
打開該頁面,只呈現出頁面框架,沒有具體信息,并且顯示不安全。
4.使用session登錄
import requests
from urllib.parse import urljoinBASE_URL = 'https://login2.scrape.center/'
LOGIN_URL= urljoin(BASE_URL, '/login')
INDEX_URL = urljoin(BASE_URL, '/page/1')
USERNAME = 'admin'
PASSWORD = 'admin'session = requests.Session()response_login = session.post(LOGIN_URL, data={'username': USERNAME, 'password':PASSWORD})cookies = session.cookies
print('Cookies', cookies)response_index = session.get(INDEX_URL)
print('Response Status', response_index.status_code)
print('Response URL', response_index.url)
import requestsbase_url = 'http://www.renren.com/PLogin.do'
headers= {'Host': 'www.renren.com','Referer': 'http://safe.renren.com/security/account',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36',
}
data = {'email':郵箱,'password':密碼,
}
#創建一個session對象
se = requests.session()
#用session對象來發送post請求進行登錄。
se.post(base_url,headers=headers,data=data)
response = se.get('http://www.renren.com/971682585')if '死性不改' in response.text:print('登錄成功!')
else:print(response.text)print('登錄失敗!')




)

)
![[Windows] Disk Sorter文件分類管理軟件 v16.7.18](http://pic.xiahunao.cn/[Windows] Disk Sorter文件分類管理軟件 v16.7.18)







![第十六屆藍橋杯大賽軟件賽省賽 C/C++ 大學B組 [京津冀]](http://pic.xiahunao.cn/第十六屆藍橋杯大賽軟件賽省賽 C/C++ 大學B組 [京津冀])




