????????知識蒸餾是一種模型壓縮技術,主要用于將大型模型(教師模型)的知識轉移到更小的模型(學生模型)中。在大語言模型領域,這一技術特別重要。
????????知識蒸餾的核心思想是利用教師模型的輸出作為軟標簽(soft labels),來指導學生模型的訓練。與傳統的硬標簽(hard labels)不同,軟標簽包含了更多的信息,不僅告訴學生模型每個樣本屬于哪個類別,還提供了關于不同類別之間相似性的額外信息。通過學習這些軟標簽,學生模型可以更好地捕捉到數據中的潛在規律和特征,從而提高其性能。
一、知識蒸餾的基本框架
? ? ? ? 三個核心組成部分:知識、蒸餾算法以及師生架構。
- 知識:代表從教師模型中提煉出的有效信息,這可能包括輸出層的概率分布(通常稱為軟標簽)、中間層的特征表示等;
- 蒸餾算法:關注的是如何高效地將這些寶貴的知識從教師模型轉移到學生模型的具體方法與策略;
- 師生架構:則定義了教師模型和學生模型之間的互動方式。這樣的結構確保了學生模型不僅能學習到教師模型的精髓,還能在保持較低復雜度的同時實現性能的提升。
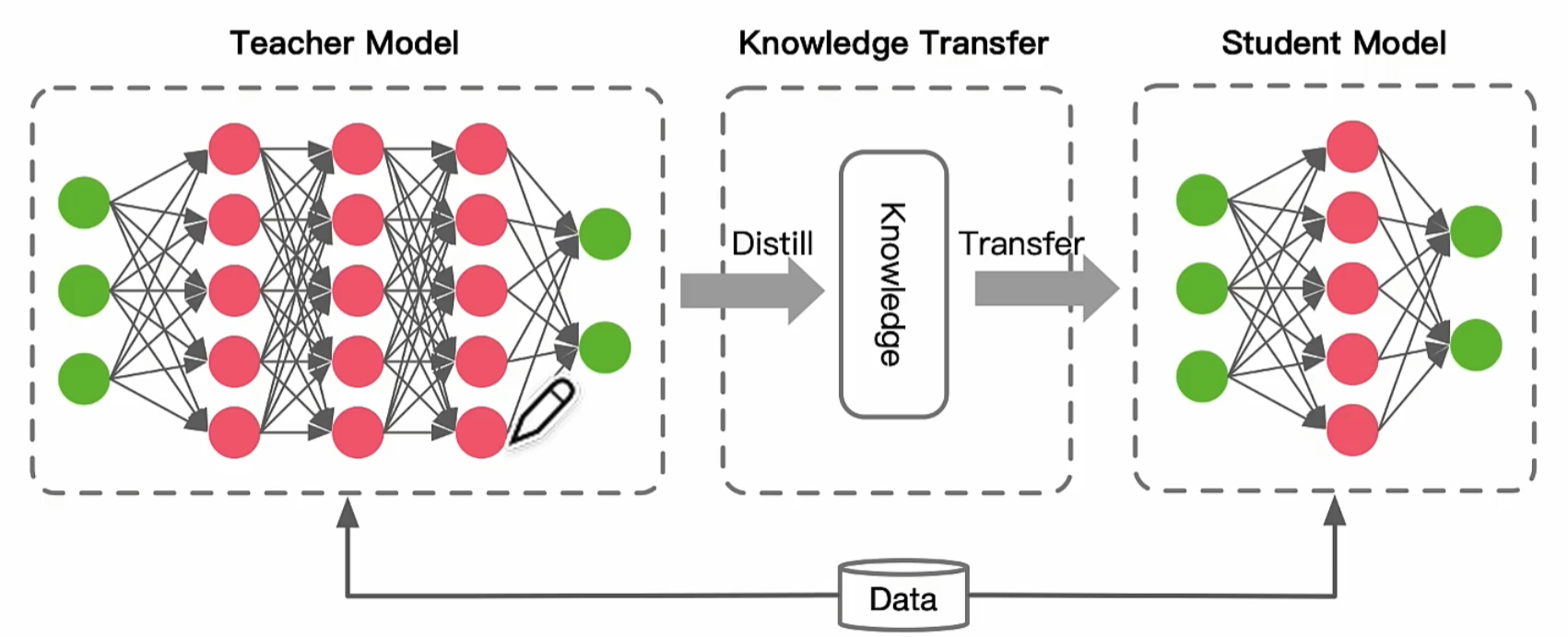
知識蒸餾能夠在保持高性能的同時,降低模型的復雜性和計算需求。
二、知識的來源
????????知識蒸餾中的知識來源方式有很多種,常見的幾種有從軟標簽中獲取,還有從特征表示里面獲取還可以從注意力機制中獲取。
(1)軟標簽
????????借用子豪哥的圖來說明什么是軟標簽,一個圖形分類模型在訓練的時候,想讓他學會分辨什么是馬。軟標簽是一組概率分布,反映了教師模型對輸入屬于各個類別的置信度。這些概率值不僅顯示了最可能的類別,還揭示了其他類別的可能性。

????????硬標簽是分類任務中的一組離散值,表示每個類別的絕對歸屬情況。通常是一個one-hot向量,其中正確類別的位置標記為1,其余類別標記為0。硬標簽只傳達了模型預測的最終結果,沒有提供關于其他類別的任何信息。
| 類別 | 硬標簽 (Hard Targets) | 軟標簽 (Soft Targets) |
|---|---|---|
| 馬 | 1 | 0.7 |
| 驢 | 0 | 0.25 |
| 汽車 | 0 | 0.05 |
????????軟標簽不僅能指出最有可能的類別(如“馬”),還能指示出其他類別(如“驢”和“汽車”)的可能性,幫助學生模型學習到更多的背景知識。由于軟標簽包含了更多關于數據分布的信息,它們可以幫助學生模型更好地泛化到未見過的數據上。
(2)特征表示
????????特征表示是指教師模型中某一層的激活值或特征向量,這些特征向量捕捉了輸入數據的高級語義信息。特征表示通常包含了豐富的語義信息,可以幫助學生模型學習到更抽象、更高級的特征。可以選擇教師模型中不同層次的特征表示進行蒸餾,從而提供多層次的知識轉移。
????????由于教師和學生的網絡結構可能不同,采用特征表示來得到知識要注意維度對齊,它包括通道數對齊和空間分辨率對齊。
三、蒸餾溫度T
????????蒸餾溫度(Temperature, T)是一個重要的超參數,用于調節教師模型輸出的軟標簽的平滑程度。通過調整溫度參數,可以控制軟標簽中不同類別概率的分布,從而影響學生模型的學習重點和蒸餾效果。
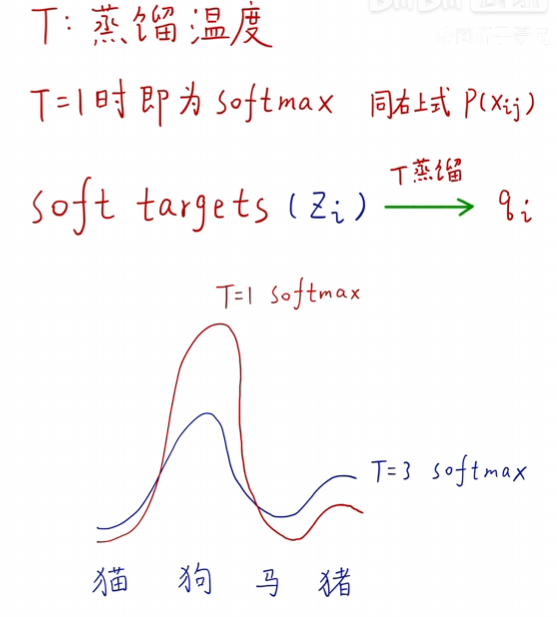
????????在知識蒸餾中,溫度參數?T?通常用于調整教師模型輸出的Logits(即未經Softmax處理的輸出值)。具體來說,使用溫度參數調整后的Softmax函數可以表示為:
其中:
表示調整后第
個類別的概率。
表示第
表示溫度參數。
????????當?T=1?時,上述公式即為標準的Softmax函數。當?T>1?時,概率分布會變得更加平滑;當?T<1?時,概率分布會變得更加尖銳。過高的溫度值可能導致模型過于關注于那些概率值較小的類別,從而降低模型的判別能力;而過低的溫度值可能導致模型過于關注于那些概率值較大的類別,從而降低模型的泛化能力。
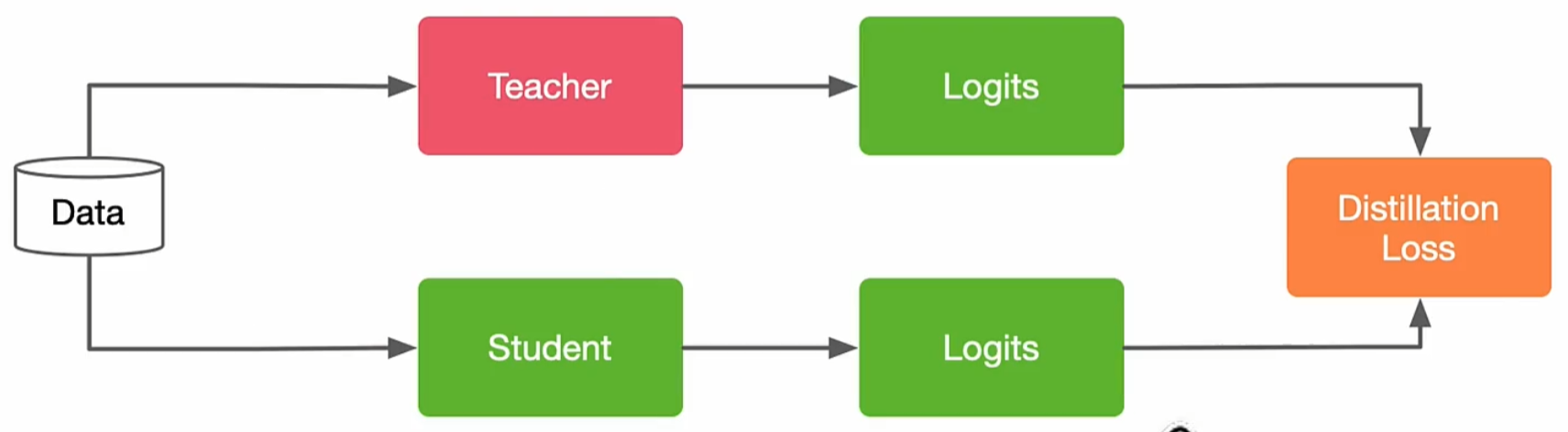
四、知識蒸餾的方式
????????就只介紹一下最常常見的知識蒸餾方式——離線知識蒸餾。其基本流程是先訓練好一個大型、復雜的教師模型,然后利用該教師模型的輸出來指導小型、簡單的學生模型的訓練。在學生模型的訓練過程中,教師模型的參數是凍結的,即教師模型的參數不再更新。
結合上面這個圖來介紹一下,離線知識蒸餾的主要步驟:
第一步:訓練教師模型
????????首先,使用大量的訓練數據和適當的損失函數(如交叉熵損失)訓練一個高性能的教師模型。教師模型通常是一個大型、復雜的模型,具有較多的參數和較高的計算復雜度。
第二步:生成軟標簽
????????在教師模型訓練完成后,使用該模型對訓練數據進行預測,得到每個樣本的軟標簽。軟標簽是教師模型輸出的概率分布,通過調整蒸餾溫度可以控制其平滑程度。
第三步:訓練學生模型
????????使用教師模型生成的軟標簽作為目標,訓練一個小型、簡單的學生模型。在訓練過程中,教師模型的參數保持不變(凍結狀態),僅更新學生模型的參數。學生模型的訓練目標包括硬標簽(真實類別標簽)和軟標簽(教師模型的輸出),通常使用KL散度(Kullback-Leibler Divergence)來衡量學生模型輸出與教師模型軟標簽之間的差異。
KL散度,也稱為相對熵(Relative Entropy),是信息論中用于衡量兩個概率分布之間差異的一種度量方式。它量化了從一個概率分布?P?轉換到另一個概率分布?Q?時所損失的信息量。
- 在知識蒸餾中,KL散度用于衡量學生模型的輸出概率分布與教師模型的軟標簽之間的差異。通過最小化KL散度,學生模型可以更好地學習教師模型的知識。
- 具體來說,學生模型的訓練目標包括最小化KL散度和硬標簽損失(如交叉熵損失)。
第四步:評估和優化
????????使用獨立的驗證集對學生模型進行評估,比較其性能與教師模型的差異。如果性能不理想,可以嘗試調整溫度參數、改變學生模型的結構或進行微調等操作,以優化蒸餾效果。
參考知識蒸餾開山之作:Distilling the Knowledge in Neural Network
)

詳解)

)


和線程的關系】)







)



)