一.?kafka和flume的整合
任務需求一:利用flume監控某目錄中新生成的文件,將監控到的變更數據發送給kafka,kafka將收到的數據打印到控制臺
1. 在flume/conf/目錄下添加flume-kafka.conf文件
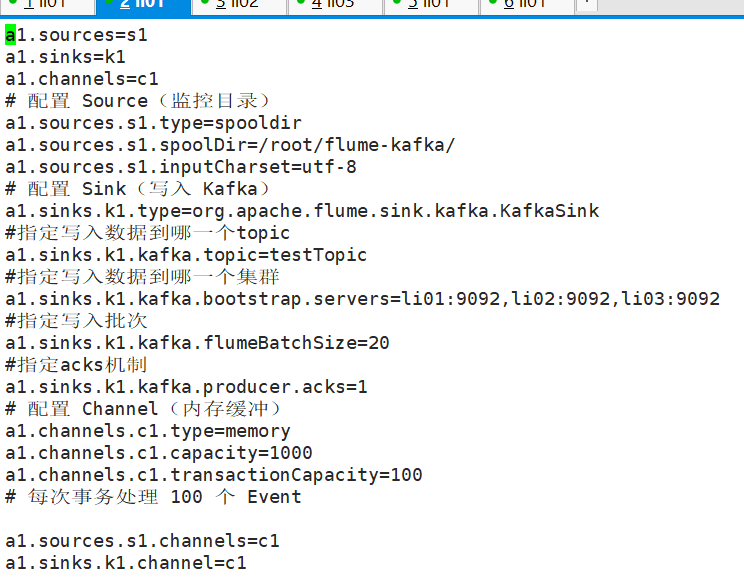
配置文件如下
2. 啟動flume和kafka消費者
![]()
3. 傳入數據
查看flume和kafka控制臺查看結果

![]()
任務需求2:Kafka生產者生成的數據利用Flume進行采集,將采集到的數據打印到Flume的控制臺上。
1.在flume/conf/目錄下配置kafka.flume.conf文件
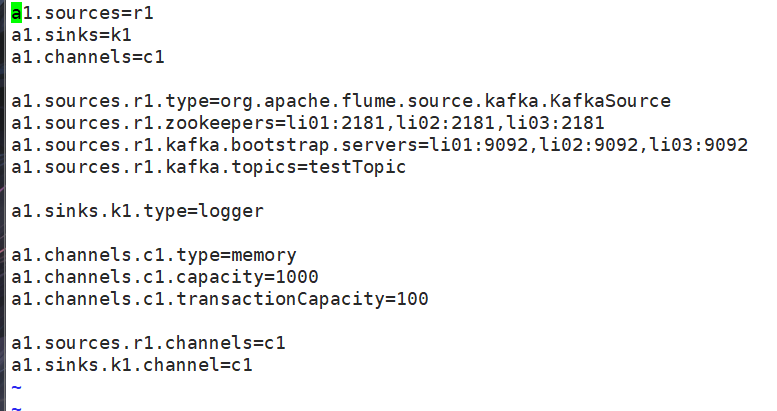
2. 啟動kafka生產者生產數據

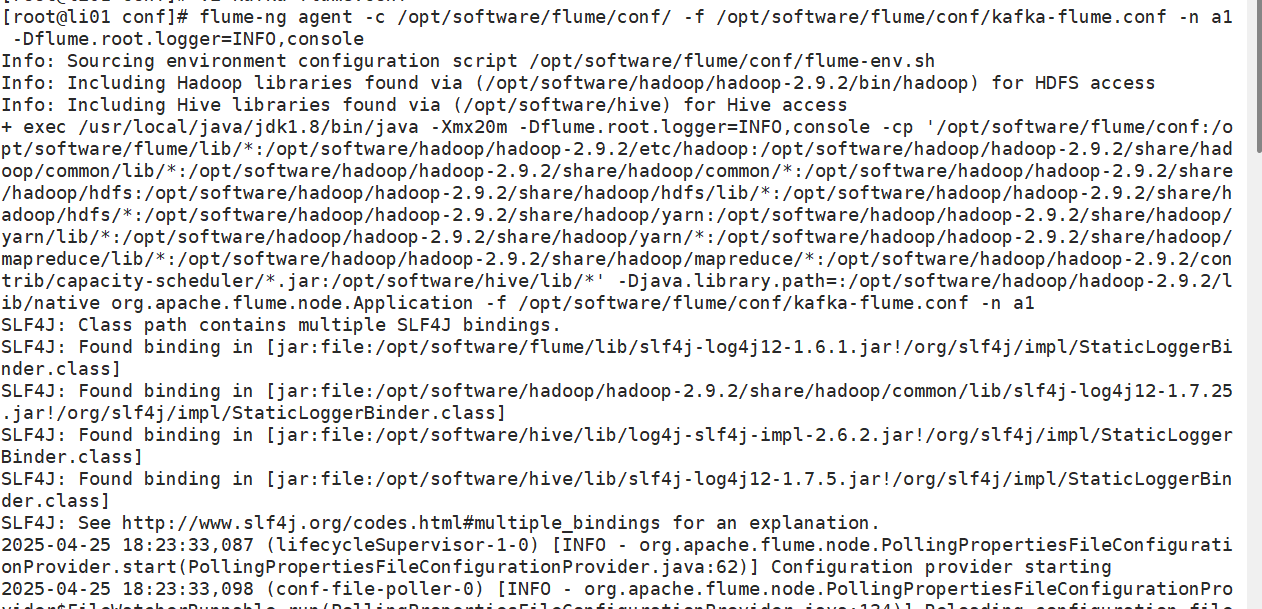
啟動flume采集kafka生產的數據
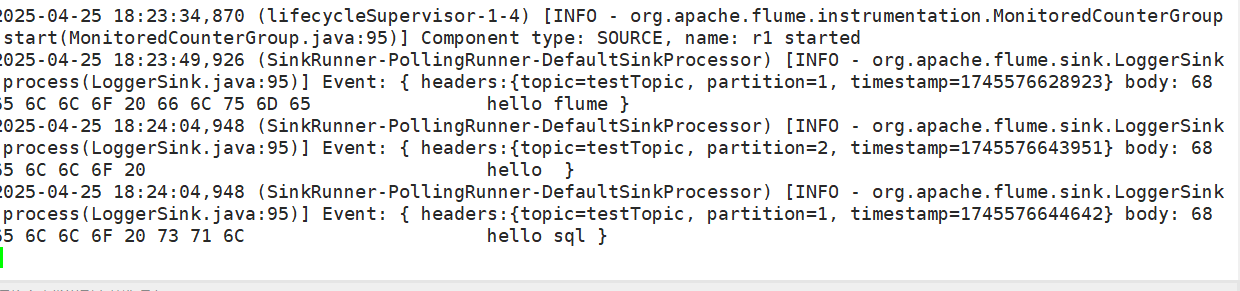
可以看到flume已經成功采集kafka生產者的數據
二.? DStream轉換
DStream 上的操作與 RDD 的類似,分為 Transformations(轉換)和 Output Operations(輸出)兩種,此外轉換操作中還有一些比較特殊的原語
無狀態轉化操作
無狀態轉化操作就是把簡單的?RDD 轉化操作應用到每個批次上,也就是轉化 DStream 中的每一個?RDD。部分無狀態轉化操作列在了下表中。
注意,針對鍵值對的 DStream 轉化操作(比如reduceByKey())要添加
import StreamingContext._才能在 Scala 中使用。

Transform
Transform 允許 DStream 上執行任意的 RDD-to-RDD 函數。即使這些函數并沒有在 DStream的?API 中暴露出來,通過該函數可以方便的擴展 Spark API。該函數每一批次調度一次。其實也就是對?DStream 中的 RDD 應用轉換。
案例演示
1. 編寫代碼
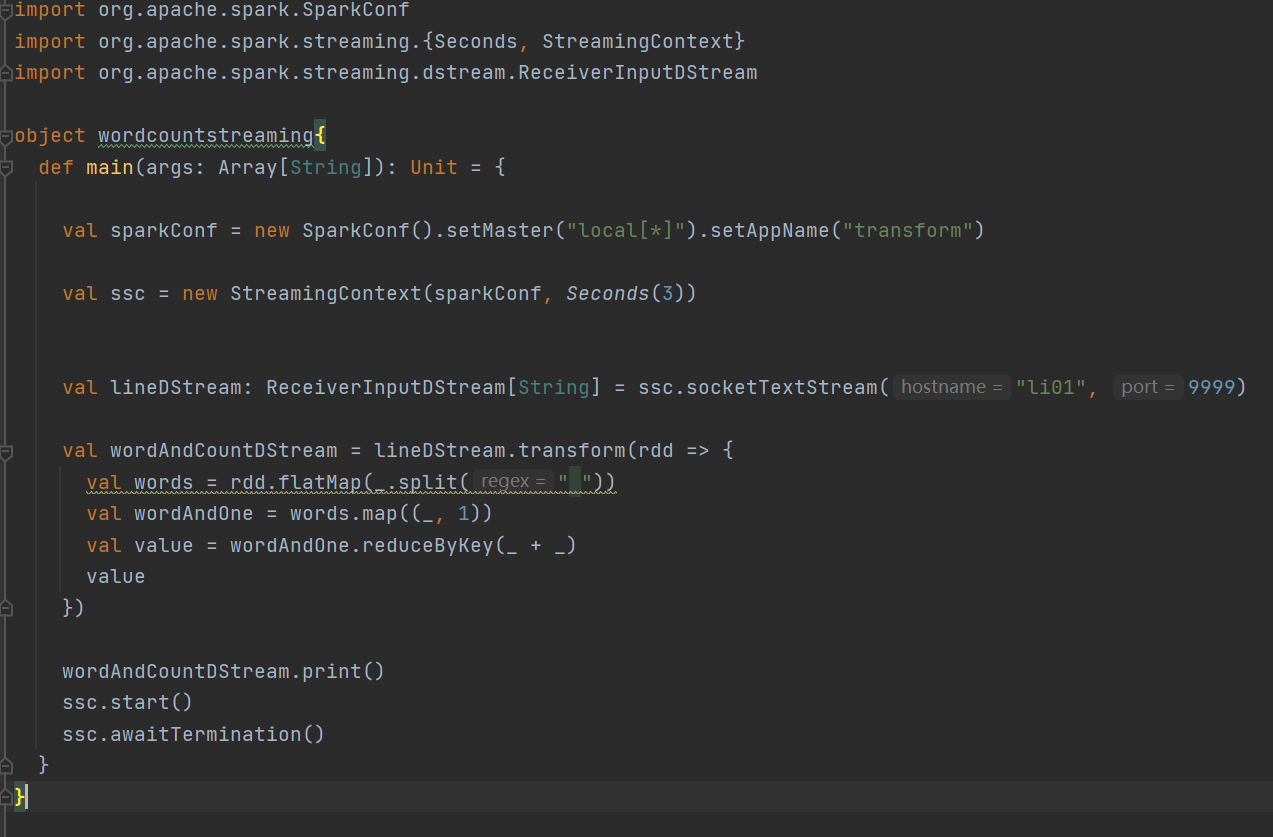
往9999端口傳輸數據
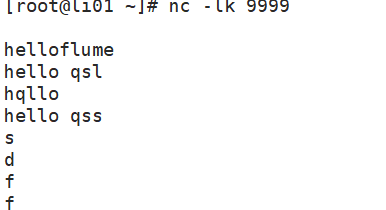
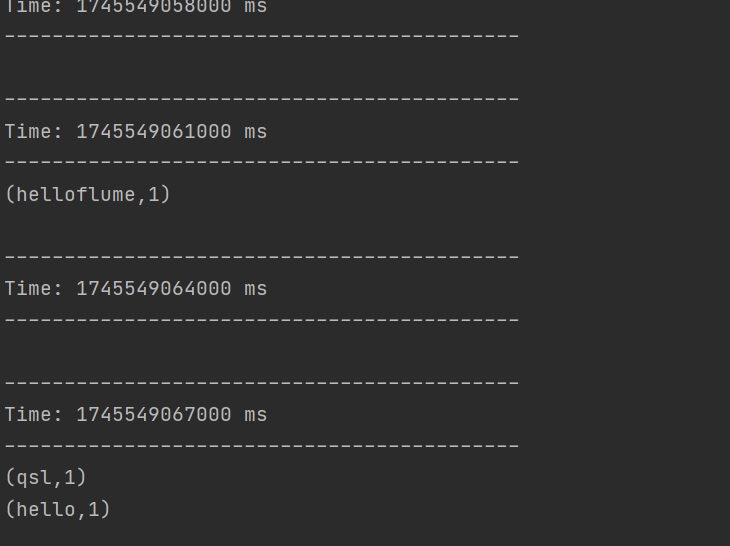
2. 運行代碼打印9999端口數據
join
兩個流之間的?join 需要兩個流的批次大小一致,這樣才能做到同時觸發計算。計算過程就是對當前批次的兩個流中各自的?RDD 進行 join,與兩個 RDD 的 join 效果相同。
案例演示
1 編寫代碼運行代碼
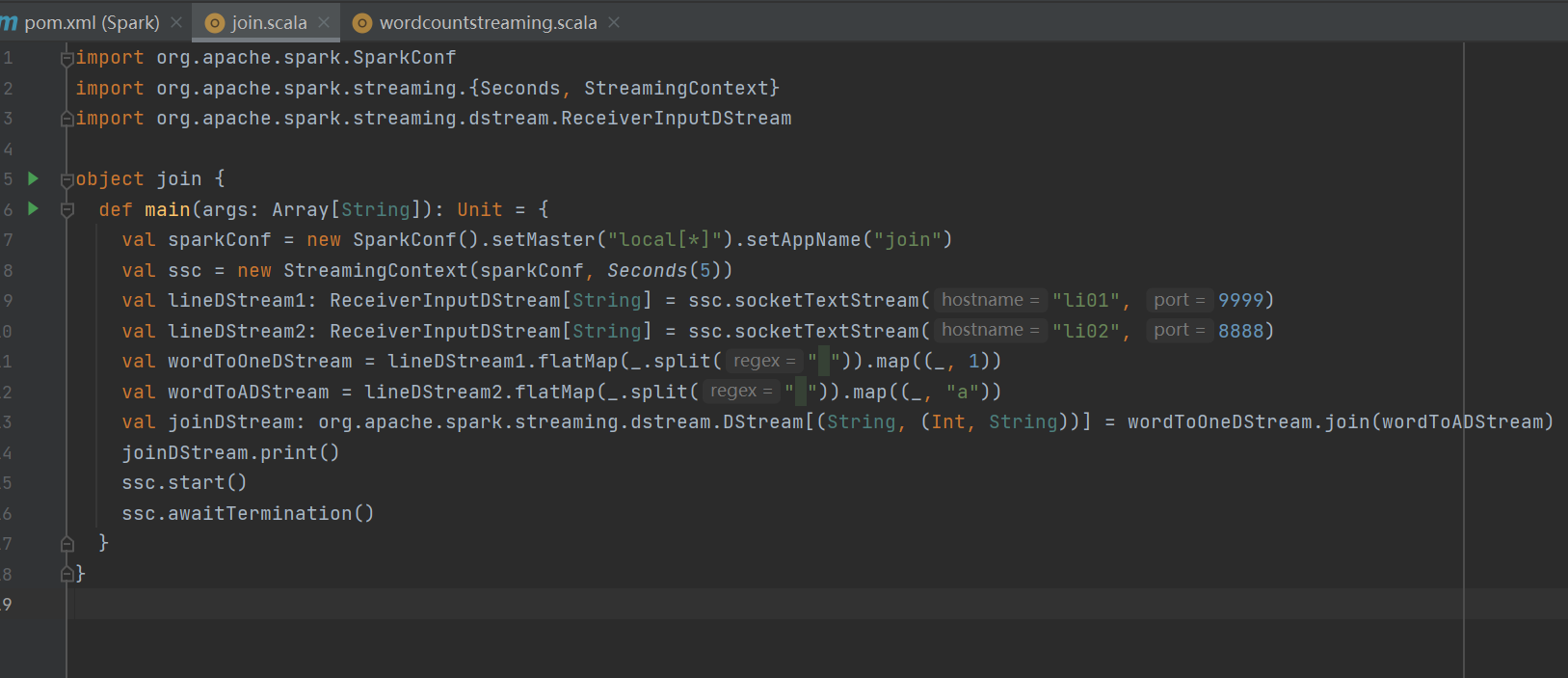
往9999和8888傳輸數據

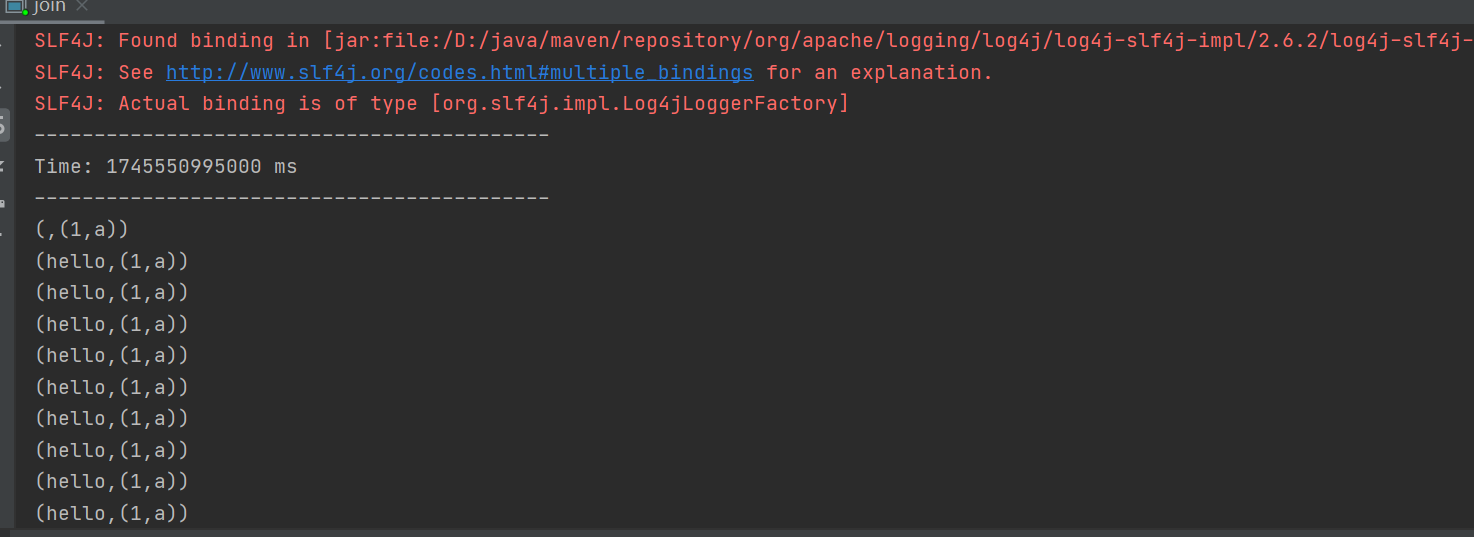
運行結果


和線程的關系】)







)



)
)


)
