
- 作者: Mohammad Nazeri 1 ^{1} 1, Anuj Pokhrel 1 ^{1} 1, Alexandyr Card 1 ^{1} 1, Aniket Datar 1 ^{1} 1, Garrett Warnell 2 , 3 ^{2,3} 2,3, Xuesu Xiao 1 ^{1} 1
- 單位: 1 ^{1} 1喬治梅森大學計算機科學系, 2 ^{2} 2美國陸軍研究實驗室, 3 ^{3} 3德克薩斯大學奧斯汀分校計算機科學系
- 論文標題:VERTIFORMER: A Data-Efficient Multi-Task Transformer for Off-Road Robot Mobility
- 論文鏈接:https://arxiv.org/pdf/2502.00543
- 代碼鏈接:https://github.com/mhnazeri/VertiFormer
主要貢獻
- 提出了數據高效多任務Transformer模型VERTIFORMER,其通過統一的多模態潛在表示、可學習的掩碼建模以及非自回歸訓練,能夠在僅使用一小時訓練數據的情況下,同時完成多種越野移動任務,例如正向和逆向運動學建模、行為克隆以及地形塊重建等。
- 對不同的Transformer設計進行了全面評估,包括掩碼建模(MM)、下一步預測(NTP)、僅編碼器以及僅解碼器等,以用于越野運動學表示。
- 在具有垂直挑戰性的復雜越野地形上,進行了物理機器人實驗,驗證了模型在多種越野移動任務上的有效性。
研究背景
- 自主移動機器人在越野環境中面臨著諸多挑戰,如不規則地形造成的車輛翻滾風險、車輪打滑導致的牽引力下降以及對機器人底盤或驅動系統的潛在機械損壞等。精確理解車輛與地形之間的運動學交互是應對這些越野移動挑戰的關鍵。
- 盡管數據驅動的方法在相對平坦的環境中顯示出一定的潛力,但對于復雜越野環境中機器人底盤與垂直挑戰性地形之間的復雜關系,需要更復雜的學習架構來充分捕捉和表示這些細微的運動學交互。
- Transformer架構因其在自然語言處理(NLP)和計算機視覺(CV)中展現的強大能力,為理解復雜關系提供了新的機遇。然而,這些領域的Transformer訓練范式并不完全適用于機器人移動,尤其是越野機器人移動,因為獲取大規模機器人數據集存在困難,且現有的NLP和CV訓練范式可能不適用于機器人移動數據的獨特特征。
VERTIFORMER
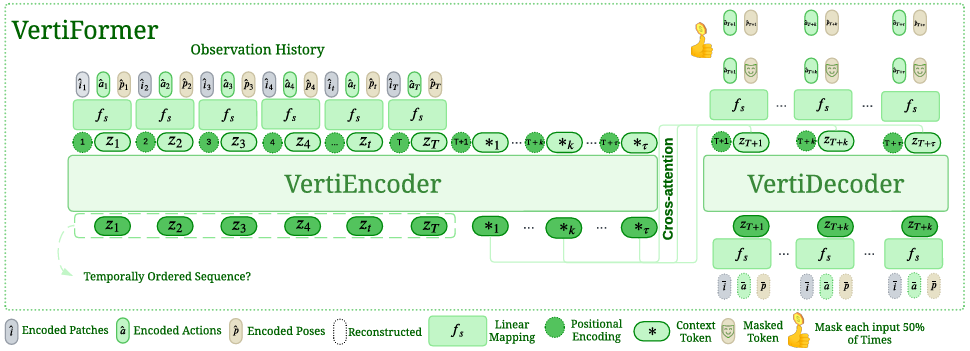
- VERTIFORMER 是一種數據高效的多任務 Transformer 模型,專門用于復雜越野地形上的機器人運動學表示和導航。
- 該模型通過統一的多模態潛在表示、可學習的掩碼建模和非自回歸訓練,能夠在僅使用一小時訓練數據的情況下同時完成多種越野移動任務。
VERTIFORMER訓練
統一多模態潛在表示
- VERTIFORMER 包含 Transformer 編碼器(VERTIENCODER)和 Transformer 解碼器(VERTIDECODER)。
- 模型接收的動作 a 0 : T a_{0:T} a0:T?、機器人姿態 p 0 : T p_{0:T} p0:T? 和地形塊 i 0 : T i_{0:T} i0:T? 首先分別通過獨立的線性映射投影到嵌入空間:
a ^ t = f a ( a t ) = W a a t + b a , a t ∈ a 0 : T , p ^ t = f p ( p t ) = W p p t + b p , p t ∈ p 0 : T , i ^ t = f i ( i t ) = W i i t + b i , i t ∈ i 0 : T , \begin{align*} \hat{a}_t &= f_a(a_t) = W_a a_t + b_a, \quad a_t \in a_{0:T}, \\ \hat{p}_t &= f_p(p_t) = W_p p_t + b_p, \quad p_t \in p_{0:T}, \\ \hat{i}_t &= f_i(i_t) = W_i i_t + b_i, \quad i_t \in i_{0:T}, \end{align*} a^t?p^?t?i^t??=fa?(at?)=Wa?at?+ba?,at?∈a0:T?,=fp?(pt?)=Wp?pt?+bp?,pt?∈p0:T?,=fi?(it?)=Wi?it?+bi?,it?∈i0:T?,?
其中, W a , W p , W i W_a, W_p, W_i Wa?,Wp?,Wi? 為權重矩陣, b a , b p , b i b_a, b_p, b_i ba?,bp?,bi? 為偏置向量。為了在 VERTIFORMER 內部實現有效的跨模態交互,需要將不同模態的嵌入投影到統一的潛在空間中,以減少統計特性上的潛在差異。因此,進一步應用線性變換 f s f_s fs? 將嵌入拼接起來:
z t = f s ( a ^ t , p ^ t , i ^ t ) = W s ( a ^ t ? p ^ t ? i ^ t ) + b s , t ∈ [ 0 : T ] , z_t = f_s(\hat{a}_t, \hat{p}_t, \hat{i}_t) = W_s (\hat{a}_t \cdot \hat{p}_t \cdot \hat{i}_t) + b_s, \quad t \in [0 : T], zt?=fs?(a^t?,p^?t?,i^t?)=Ws?(a^t??p^?t??i^t?)+bs?,t∈[0:T],
其中, W s W_s Ws? 和 b s b_s bs? 分別為 f s f_s fs? 的權重矩陣和偏置向量。最終得到的統一標記 z 0 : T z_{0:T} z0:T? 作為輸入傳遞給 VERTIENCODER。
可學習掩碼建模
結合統一表示,VERTIFORMER 提出了一種隨機可學習的掩碼建模技術,以實現多任務學習。在訓練過程中,模型首先在所有模態上進行預熱,然后以相等的概率應用兩種不同的數據掩碼方法:
-
基于動作的未來姿態預測:
- 在 50% 的訓練實例中,提供人類演示生成的未來 τ \tau τ 步動作 a T + 1 : T + τ a_{T+1:T+\tau} aT+1:T+τ? 作為輸入,同時將對應的未來姿態 p T + 1 : T + τ p_{T+1:T+\tau} pT+1:T+τ? 替換為可學習的掩碼。
- 這使得模型能夠基于提供的未來動作和先前的歷史上下文預測未來的姿態,類似于越野移動中的正向運動學建模(FKD)任務。
-
基于姿態的未來動作預測:
- 在剩余的 50% 的實例中,提供未來姿態 p T + 1 : T + τ p_{T+1:T+\tau} pT+1:T+τ? 作為輸入,而將對應的未來動作 a T + 1 : T + τ a_{T+1:T+\tau} aT+1:T+τ? 使用另一個可學習的掩碼進行掩碼。
- 這促使模型基于提供的未來姿態和歷史上下文預測未來動作,類似于逆向運動學建模(IKD)任務。
-
這種交替掩碼策略與統一表示相結合,促進了能夠解碼動作和姿態信息的聯合表示的學習。可學習掩碼可以被視為一種可學習的門控機制,在訓練期間選擇性地過濾信息流。
-
此外,通過擴展掩碼策略同時掩碼未來的動作 a T + 1 : T + τ a_{T+1:T+\tau} aT+1:T+τ? 和姿態 p T + 1 : T + τ p_{T+1:T+\tau} pT+1:T+τ?,VERTIFORMER 能夠以零樣本的方式執行行為克隆(BC)。
-
在這種配置下,模型僅基于歷史上下文預測動作和姿態,有效地模仿演示的行為,而無需從規劃器那里獲取關于未來動作和姿態的顯式信息。
非自回歸訓練
- 基于相關研究的工作,VERTIFORMER 使用多個上下文標記來表示未來狀態的分布。這些上下文標記用于通知 VERTIDECODER 預測未來的自我狀態和環境的演變。
- 擁有多個上下文標記使得 VERTIFORMER 能夠非自回歸地預測未來。非自回歸方法的動機在于自回歸模型中固有的潛在計算瓶頸,因為自回歸模型需要多次查詢模型,并且容易受到早期步驟中誤差傳播的影響。
- 通過學習多上下文表示,非自回歸方法旨在提高訓練效率和推理速度,這對于實時機器人控制應用來說是一個關鍵考慮因素。
- VERTIFORMER 的訓練通過最小化模型預測與相應真實值之間的均方誤差(MSE)來完成。模型評估是通過計算模型預測與真實值之間在未見數據集上的誤差率來進行的。
VERTIFORMER推理
- 在正向運動學建模(FKD)推理過程中,VERTIENCODER 接收與訓練時相同的輸入歷史。
- VERTIDECODER 接收來自外部采樣式規劃器(例如 MPPI)的采樣動作,同時掩碼對應的姿態,迫使模型僅基于采樣動作(和上下文標記)預測未來的姿態,以便規劃器可以選擇最優軌跡以最小化成本函數。
- 對于逆向運動學建模(IKD),全局規劃器生成期望的未來姿態,通過掩碼動作,促使模型預測實現這些全局規劃姿態的未來動作。通過掩碼動作和姿態,VERTIFORMER 可以執行零樣本行為克隆(BC)。
使用一小時數據高效訓練VERTIFORMER
實驗設置
- 數據集:使用了一小時的人類遙控駕駛數據,這些數據在一個定制的越野測試平臺上采集,包含復雜的地形特征(如巖石、巨石、木板、人工草坪等)。
- 評估指標:通過計算模型預測與真實值之間的誤差率來評估性能,重點關注機器人姿態的三個分量(X、Y、Z)。
實驗結果
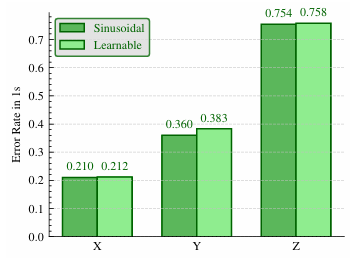
- 位置編碼:正弦位置編碼在預測機器人姿態時表現優于可學習位置編碼。
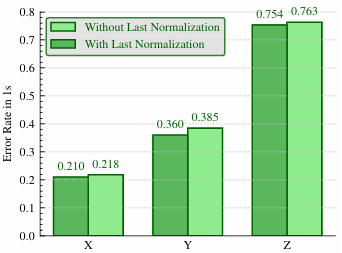
- 歸一化層:在 Transformer 輸出層之前應用 RMSNorm 層可以顯著提高模型性能和訓練穩定性。
- 統一多模態潛在表示:統一表示能夠顯著提高模型對時間依賴性和運動學轉換的理解能力,與分離表示相比,學習損失顯著下降。
- 預測范圍:非自回歸模型(VERTIFORMER)在長時預測中表現出更高的準確性和穩定性,避免了自回歸模型中常見的誤差累積問題。
- 地形塊重建頭:加入地形塊重建頭會降低模型性能,因為越野地形的復雜性使得重建任務非常困難,引入了噪聲。
- 不同訓練范式對比:非自回歸的 VERTIFORMER 在正向運動學建模(FKD)、逆向運動學建模(IKD)和行為克隆(BC)任務中均優于其他模型,包括僅編碼器(MM)、僅解碼器(NTP)和端到端(End2End)模型。
實驗結論
- 數據效率:VERTIFORMER 通過獨特的訓練方法和架構設計,在僅使用一小時數據的情況下,能夠同時完成多種越野移動任務。
- 性能優勢:非自回歸設計和統一的多模態潛在表示顯著提高了模型的準確性和穩定性,尤其是在長時預測和多任務學習方面。
- 泛化能力:模型在未見的測試環境中表現出良好的泛化能力,能夠適應不同的地形和摩擦系數。
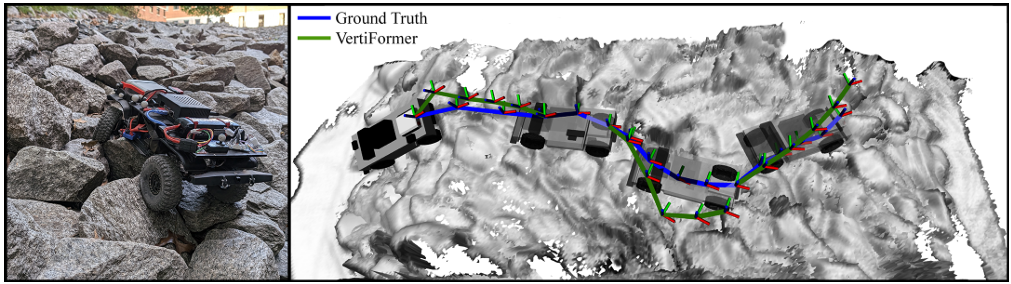
真實機器人平臺實驗
實驗設置
- 機器人平臺:使用了一個開源的四輪越野機器人(Verti-4-Wheeler, V4W),該機器人配備了 Microsoft Azure Kinect RGB-D 攝像頭用于構建地形圖,以及 NVIDIA Jetson Xavier 處理器用于實時計算。
- 測試環境:實驗在一個 4m × 2.5m 的測試平臺上進行,該平臺包含多種復雜地形,如巖石、巨石、木板、人工草坪和可變形泡沫,模擬了具有不同摩擦系數和變形能力的垂直挑戰性地形。
- 任務:實驗驗證了 VERTIFORMER 在三種任務上的性能:
- 正向運動學建模(FKD):與 MPPI 規劃器結合,預測機器人未來的姿態。
- 逆向運動學建模(IKD):與全局規劃器結合,生成實現目標姿態的動作。
- 行為克隆(BC):僅基于歷史數據預測未來動作,無需顯式的目標姿態或動作。

實驗結果
- 性能指標:通過成功率、平均穿越時間、平均側傾角和俯仰角來評估模型性能。
- 實驗結果:
- FKD 任務:VERTIFORMER 與 MPPI 規劃器結合,成功率達到 100%,平均穿越時間為 9.42 秒,平均側傾角為 0.169 弧度,平均俯仰角為 0.096 弧度。
- IKD 任務:VERTIFORMER 與全局規劃器結合,成功率達到 80%,平均穿越時間為 17.16 秒,平均側傾角為 0.136 弧度,平均俯仰角為 0.077 弧度。
- BC 任務:VERTIFORMER 在行為克隆任務中成功率達到 80%,平均穿越時間為 12.64 秒,平均側傾角為 0.154 弧度,平均俯仰角為 0.099 弧度。
實驗結論
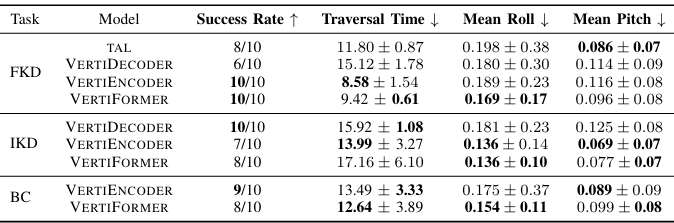
- 模型優勢:VERTIFORMER 在復雜越野地形上表現出色,能夠有效處理多種任務,且在數據稀缺條件下具有良好的泛化能力。
- 性能對比:與現有的先進模型(如 TAL、VERTIENCODER、VERTIDECODER)相比,VERTIFORMER 在成功率、穿越時間和姿態穩定性方面均表現出色。
- 實際應用:實驗結果表明,VERTIFORMER 可以在真實機器人平臺上高效運行,為越野機器人導航和運動學建模提供了一種有效的解決方案。
結論與未來工作
- VERTIFORMER作為一種數據高效多任務Transformer,能夠僅使用有限的訓練數據(一小時)來學習復雜的車輛-地形運動學交互,并在多種越野移動任務上取得了優異的性能,同時提高了模型的泛化能力和對未知環境的適應性。
- 未來的研究可以探索如何進一步提高模型在長時預測和復雜地形上的性能,例如改進掩碼策略、優化模型架構或結合其他先進的訓練技術。
- 此外,還可以將該模型應用于其他機器人領域,如視覺導航或操作任務,以驗證其在不同場景下的適用性和有效性。



)
)


)












