引言
在大數據時代,高效管理海量數據成為企業面臨的核心挑戰。Hive作為Hadoop生態系統中最受歡迎的數據倉庫解決方案,其分區技術是優化數據查詢和管理的關鍵手段。本文將全面解析Hive分區技術的原理、實現方式及企業級最佳實踐,幫助您構建高性能的數據倉庫。
1 Hive分區基礎概念
1.1 什么是分區
分區(Partitioning)是一種將表數據按照特定列的值進行物理劃分的數據組織方式。從邏輯角度看,分區表仍然呈現為一個完整的表,但在物理存儲層面,數據被組織到不同的目錄結構中。
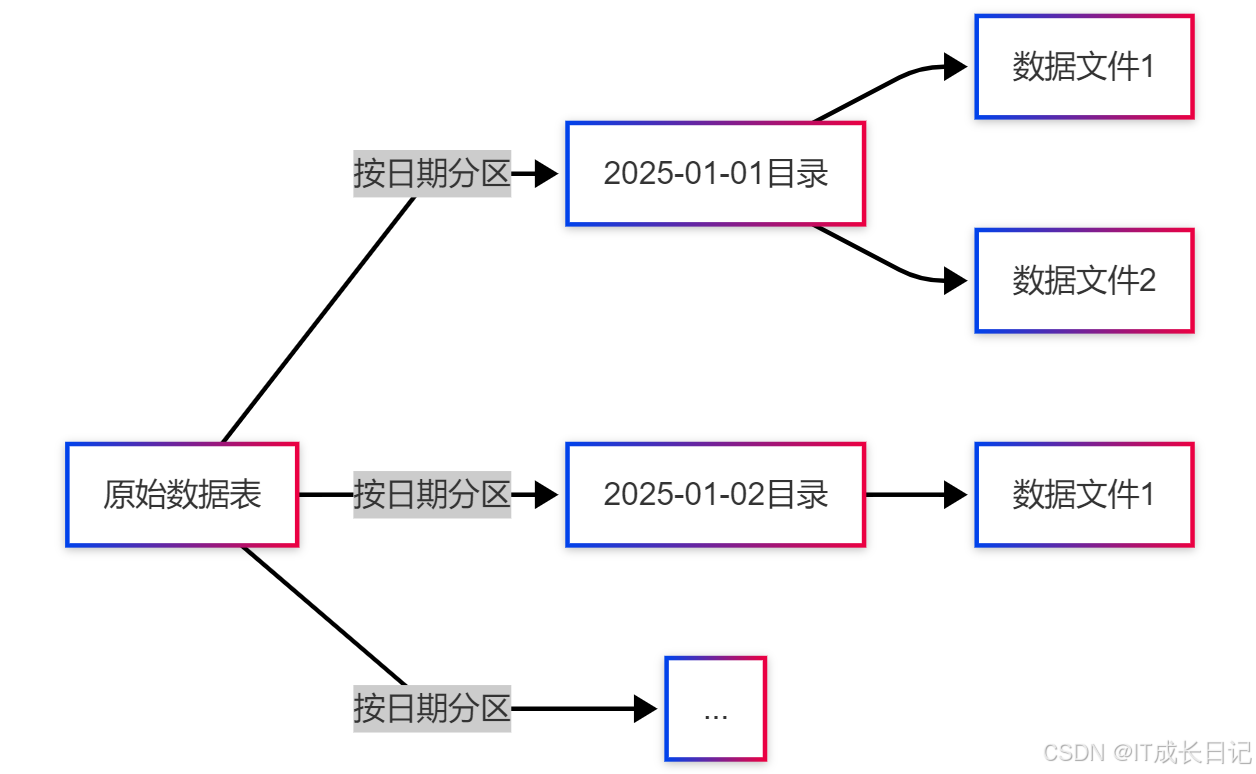
分區核心價值:
- 查詢性能提升:通過分區剪枝(Partition Pruning)避免全表掃描
- 數據管理簡化:可按分區進行備份、刪除等操作
- 成本優化:減少不必要的數據讀取,降低計算資源消耗
1.2 分區 vs 分桶
| 特性 | 分區 | 分桶 |
| 組織方式 | 按列值劃分目錄 | 按哈希值劃分文件 |
| 適用場景 | 高基數列 | 低基數列 |
| 文件數量 | 與分區數成正比 | 固定桶數 |
| 典型應用 | 時間、地域維度 | JOIN優化、數據采樣 |
2 分區表設計與創建
2.1 分區表創建語法
CREATE TABLE partitioned_table (col1 data_type,col2 data_type,...
) PARTITIONED BY (partition_col1 data_type, partition_col2 data_type, ...)
STORED AS file_format;- 示例:
CREATE TABLE user_behavior (user_id BIGINT,item_id BIGINT,behavior_type INT
) PARTITIONED BY (dt STRING COMMENT '日期分區', country STRING COMMENT '國家代碼')
STORED AS ORC;2.2 分區鍵設計原則
- 選擇高頻過濾條件:如時間、地區等常用查詢條件
- 避免過高基數:分區數過多會導致小文件問題
- 考慮未來擴展:預留必要的分區維度
- 命名規范化:采用key=value格式,如dt=20250101
3 分區數據加載與管理
3.1 靜態分區加載
- 適用于分區值已知且固定的場景:
-- 直接加載數據到指定分區
LOAD DATA INPATH '/input/path'
INTO TABLE partitioned_table
PARTITION (dt='2025-01-01', country='US');-- 從查詢結果加載
INSERT INTO TABLE partitioned_table
PARTITION (dt='2025-01-01', country='US')
SELECT user_id, item_id, behavior_type
FROM source_table;3.2 動態分區加載
- 適用于分區值不確定或變化頻繁的場景:
-- 啟用動態分區配置
SET hive.exec.dynamic.partition=true;
SET hive.exec.dynamic.partition.mode=nonstrict;-- 動態分區插入
INSERT INTO TABLE partitioned_table
PARTITION (dt, country)
SELECT user_id, item_id, behavior_type, event_date as dt, country_code as country
FROM source_table;- 動態分區調優參數:
SET hive.exec.max.dynamic.partitions=1000; -- 單個MR作業最大分區數
SET hive.exec.max.dynamic.partitions.pernode=100; -- 單節點最大分區數3.3 分區維護操作
-- 查看分區
SHOW PARTITIONS partitioned_table;-- 添加分區(無數據)
ALTER TABLE partitioned_table ADD PARTITION (dt='2025-01-01');-- 刪除分區
ALTER TABLE partitioned_table DROP PARTITION (dt='2025-01-01');-- 修復分區元數據
MSCK REPAIR TABLE partitioned_table;4 企業級分區優化策略
4.1 多級分區設計
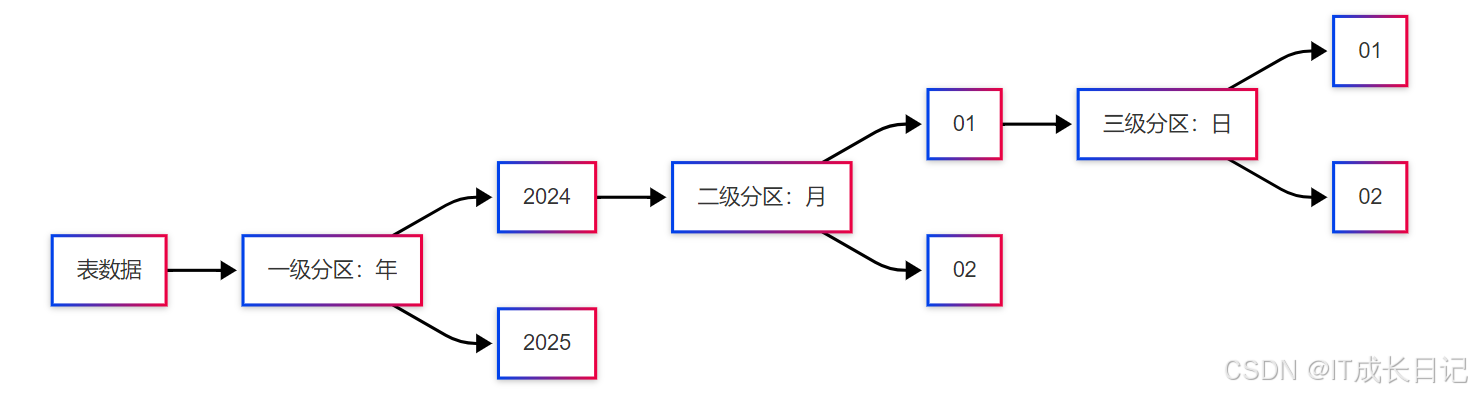
- 實現示例
CREATE TABLE sales (order_id STRING,amount DOUBLE
) PARTITIONED BY (year INT, month INT, day INT);4.2 分區裁剪優化
- 分區剪枝(Partition Pruning)是Hive查詢優化的關鍵技術:
-- 觸發分區剪枝的查詢
EXPLAIN EXTENDED
SELECT * FROM sales
WHERE year=2025 AND month=1; -- 只掃描2025年1月分區- 執行計劃關鍵指標:
Number of partitions read: 1
Total filesystem I/O: 128MB4.3 小文件合并策略

- 具體實現:
-- 創建臨時表存儲合并結果
CREATE TABLE temp_merge LIKE partitioned_table;-- 合并數據
INSERT INTO temp_merge PARTITION(dt='2025-01-01')
SELECT * FROM partitioned_table
WHERE dt='2025-01-01';-- 替換原分區
ALTER TABLE partitioned_table DROP PARTITION (dt='2025-01-01');
ALTER TABLE partitioned_table ADD PARTITION (dt='2025-01-01');
LOAD DATA INPATH '/temp/merge/output'
INTO TABLE partitioned_table PARTITION (dt='2025-01-01');5 高級分區技術
5.1 虛擬列分區
- Hive 2.0+支持基于虛擬列的分區:
CREATE TABLE log_data (ip STRING,request STRING,input__file__name STRING
) PARTITIONED BY (file_date STRING AS (regexp_extract(input__file__name, '.*/([0-9]{8})/.*', 1))
STORED AS TEXTFILE;5.2 動態分區過期
- 自動化管理歷史分區:
-- 創建保留策略
CREATE TABLE partitioned_table (...
) PARTITIONED BY (dt STRING)
TBLPROPERTIES ('partition.retention.period'='90d','partition.retention.policy'='delete'
);5.3 分區統計信息收集
-- 收集分區統計信息
ANALYZE TABLE partitioned_table
PARTITION(dt='2025-01-01')
COMPUTE STATISTICS;-- 收集列級統計
ANALYZE TABLE partitioned_table
PARTITION(dt='2025-01-01')
COMPUTE STATISTICS FOR COLUMNS;6 案例分析
6.1 電商用戶行為分析
- 需求:分析每日活躍用戶行為,保留最近180天數據
- 解決方案:
-- 創建時間分區表
CREATE TABLE user_events (user_id BIGINT,event_time TIMESTAMP,event_type STRING
) PARTITIONED BY (event_date DATE)
STORED AS PARQUET
TBLPROPERTIES ('partition.retention.period'='180d'
);-- 每日增量加載
INSERT INTO TABLE user_events
PARTITION (event_date='2025-01-01')
SELECT user_id, event_time, event_type
FROM raw_events
WHERE DATE(event_time)='2025-01-01';6.2 交易數據歸檔
- 場景:按月歸檔歷史交易數據,實現冷熱數據分離

- 實現代碼:
-- 創建歸檔表
CREATE TABLE trade_archive (trade_id STRING,amount DECIMAL(18,2),...
) PARTITIONED BY (year INT, month INT)
STORED AS ORC;-- 月度歸檔過程
SET hive.exec.dynamic.partition=true;
INSERT INTO TABLE trade_archive
PARTITION (year, month)
SELECT trade_id, amount, ..., YEAR(trade_date), MONTH(trade_date)
FROM current_trades
WHERE trade_date BETWEEN '2025-01-01' AND '2025-01-31';7 常見問題與解決方案
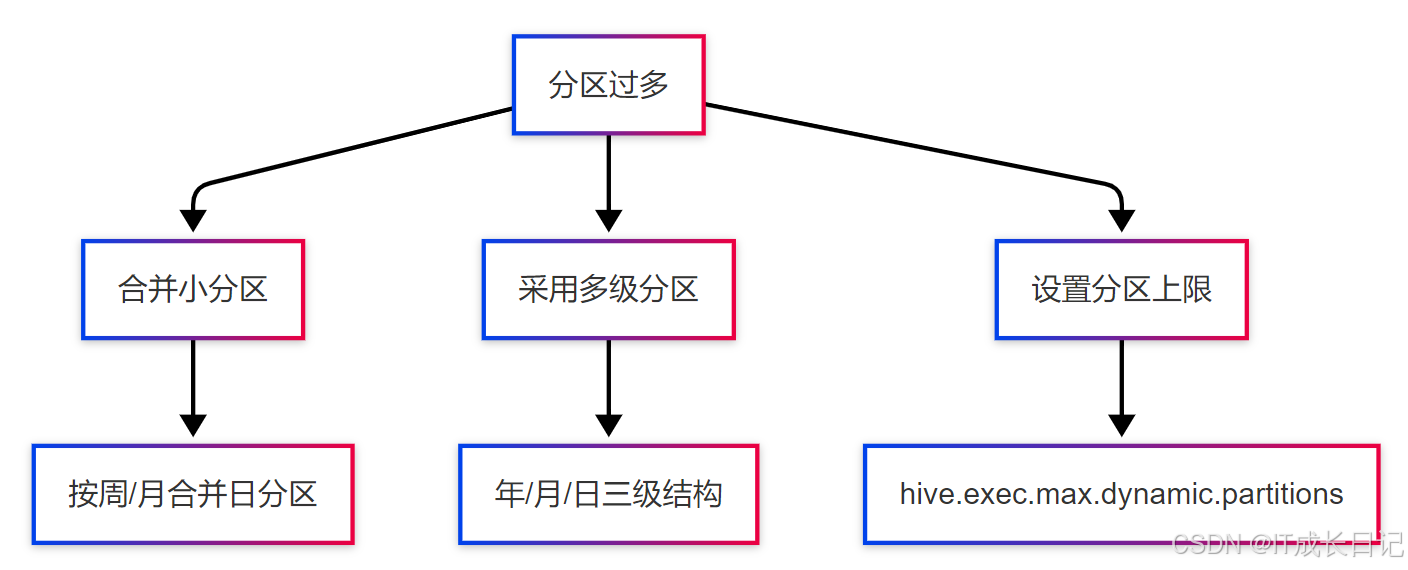
7.1 分區過多問題
問題:
- NameNode內存壓力大
- 查詢計劃生成緩慢
解決方案:
7.2 分區數據傾斜
- 診斷方法:
-- 查看分區大小分布
SELECT partition_col, COUNT(1)
FROM partitioned_table
GROUP BY partition_col
ORDER BY COUNT(1) DESC LIMIT 10;解決策略:
- 重新設計分區鍵
- 對傾斜分區單獨處理
- 使用分桶輔助分區
7.3 元數據不一致
- 修復方案:
-- 修復元數據
MSCK REPAIR TABLE partitioned_table;-- 手動添加分區
ALTER TABLE partitioned_table ADD PARTITION (dt='2025-01-01')
LOCATION '/user/hive/warehouse/db/table/dt=2025-01-01';-- 重建元數據
DROP TABLE partitioned_table;
CREATE TABLE partitioned_table ...;8 總結
設計階段:
- 選擇合適的分區鍵
- 規劃合理的分區粒度
- 考慮多級分區結構
實施階段:
- 使用動態分區簡化加載
- 定期收集統計信息
- 實施分區生命周期管理
運維階段:
- 監控分區數量增長
- 定期優化小文件
- 建立分區維護SOP
Hive分區技術是企業級數據倉庫的核心組件,合理運用可以大幅提升查詢性能和管理效率。隨著數據規模持續增長,掌握分區技術的高級應用將成為大數據工程師的必備技能。

——光流估計)







國密SM2算法的簽名和驗簽(附商用密碼檢測相關國家標準/國密標準下載))


---管理命令、配置安裝)






)