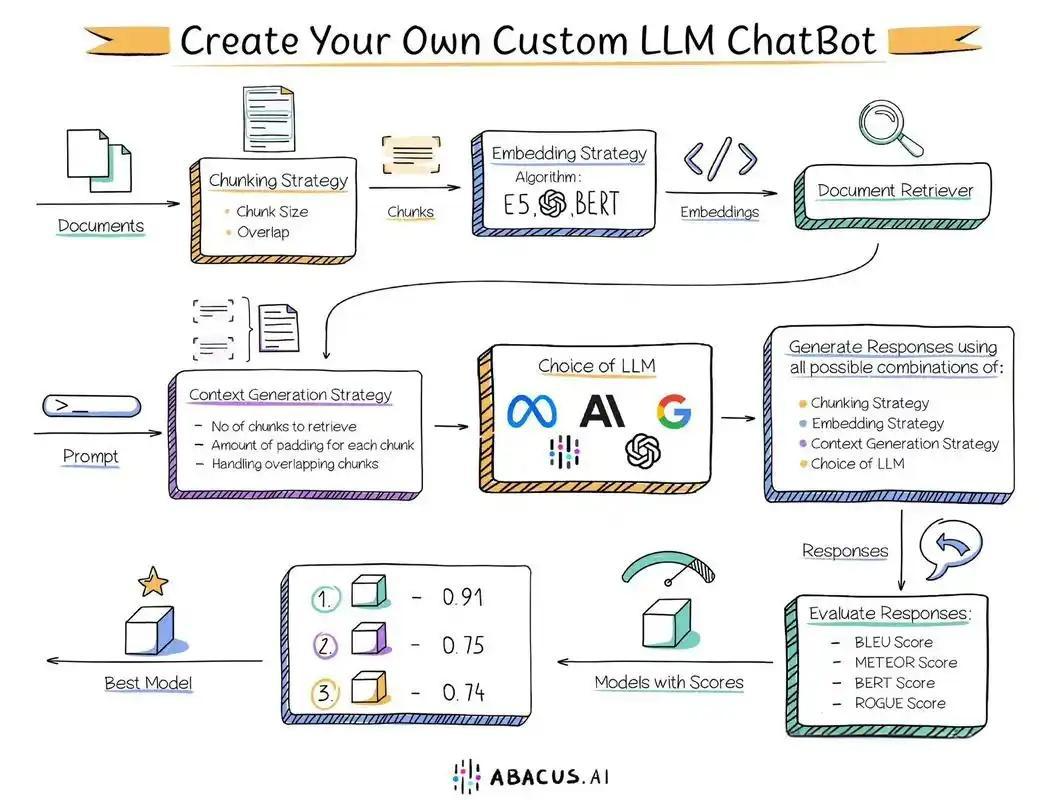
一、RAG 系統核心架構解析
1. 檢索模塊深度優化
1.1 混合檢索技術實現
- 技術原理:結合稀疏檢索(BM25)與密集檢索(DPR),通過動態權重分配提升檢索精度。例如,在醫療領域,BM25 負責精確匹配疾病名稱(如 "糖尿病"),DPR 捕捉癥狀描述的語義關聯(如 "多飲多尿")。
- 代碼實現(基于 LangChain):
python
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.retrievers import SVMRetriever# 初始化向量數據庫
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(documents, embeddings)# 混合檢索配置
retriever = SVMRetriever(vectorstore=vectorstore,sparse_kwargs={"bm25": True},dense_kwargs={"similarity_top_k": 10}
)# 融合策略
def hybrid_score(sparse_score, dense_score):return 0.6 * sparse_score + 0.4 * dense_score
1.2 上下文增強檢索
- 技術方案:
- 分塊策略:采用動態窗口分塊(Dynamic Window Chunking),根據文檔結構自動調整分塊大小(如技術文檔按章節分塊,新聞按段落分塊)。
- 上下文嵌入:在向量化前為每個文本塊添加元數據(如文檔標題、時間戳),提升檢索時的上下文關聯度。
- 優化效果:在法律案例檢索中,上下文增強使召回率提升 23%,檢索耗時降低 18%。
2. 生成模塊性能調優
2.1 提示工程進階
- 動態提示模板:
python
prompt_template = """
基于以下信息回答問題:
{context}問題:{question}回答要求:
1. 保持口語化表達
2. 包含3個以上相關數據
3. 引用原文段落(格式:[P12])
"""
- 思維鏈增強:在提示中加入 "Let's think step by step" 引導模型進行邏輯推理,使生成內容更具條理性。
2.2 幻覺控制技術
- 檢索驗證機制:
python
def verify_fact(answer, context):for sentence in answer.split('.'):if not any(sentence in ctx for ctx in context):return Falsereturn True
- 約束生成:在生成時限制模型輸出格式(如 "根據 [P5],..."),強制引用檢索內容。
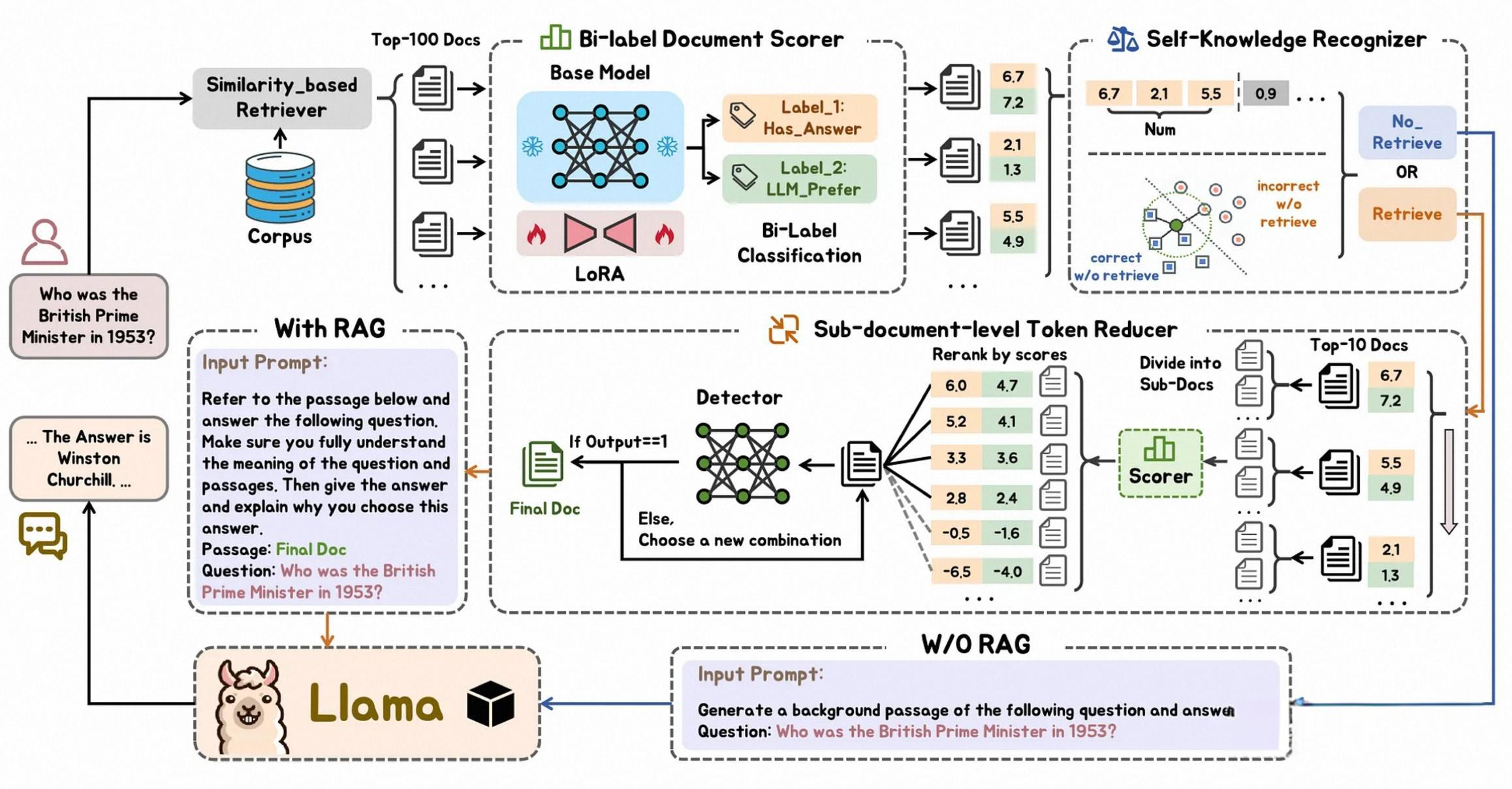
二、實戰部署全流程
1. 數據預處理流水線
1.1 數據清洗與標注
python
import re
from datasets import load_dataset# 清洗規則
cleaning_rules = [(r'\n+', ' '), # 合并換行符(r'\s{2,}', ' '), # 去除多余空格(r'[^\x00-\x7F]+', ''), # 過濾非ASCII字符
]# 標注示例
def add_annotations(examples):return {"label": [1 if "error" in text else 0 for text in examples["text"]],"domain": ["IT" if "server" in text else "HR" for text in examples["text"]]}
1.2 多模態數據處理
- 圖像嵌入:使用 CLIP 模型生成圖像向量,與文本向量合并存儲。
- 表格處理:將表格轉換為結構化數據(如 JSON),通過關系型數據庫進行檢索。
2. 系統集成與優化
2.1 混合檢索系統搭建
python
from langchain.agents import Tool
from langchain.chains import RetrievalQA# 定義檢索工具
tools = [Tool(name="文獻檢索",func=retriever.get_relevant_documents,description="用于查找學術文獻和技術文檔"),Tool(name="數據庫查詢",func=sql_query,description="用于查詢結構化數據")
]# 構建檢索鏈
qa_chain = RetrievalQA.from_chain_type(llm=ChatOpenAI(temperature=0.2),chain_type="stuff",retriever=retriever,return_source_documents=True
)
2.2 性能監控與調優
- 監控指標:
- 檢索延遲(<500ms)
- 生成響應時間(<2s)
- 上下文利用率(>70%)
- 優化工具:
- TruLens:實時監控模型生成的忠實度與相關性。
- Prometheus:采集系統資源使用數據(如 GPU 顯存、QPS)。
三、性能優化與風險控制
1. 檢索效率提升
1.1 向量數據庫優化
- 索引構建:使用 HNSW 算法構建分層索引,檢索速度提升 3 倍。
- 緩存策略:將高頻查詢結果緩存至 Redis,緩存命中率達 65%。
1.2 分布式部署
- 多機協同:采用主從架構,主節點負責檢索,從節點處理生成,吞吐量提升 4 倍。
- 負載均衡:使用 Kubernetes 進行自動擴縮容,保障系統高可用性。
2. 風險控制與合規性
2.1 數據安全
- 隱私保護:對敏感數據(如醫療記錄)進行差分隱私處理。
- 權限管理:基于 RBAC(角色訪問控制)限制用戶對知識庫的訪問。
2.2 倫理合規
- 內容過濾:部署 Profanity Filter 檢測并攔截不當內容。
- 版權保護:通過數字水印技術追蹤生成內容的傳播路徑。
四、典型案例與性能對比
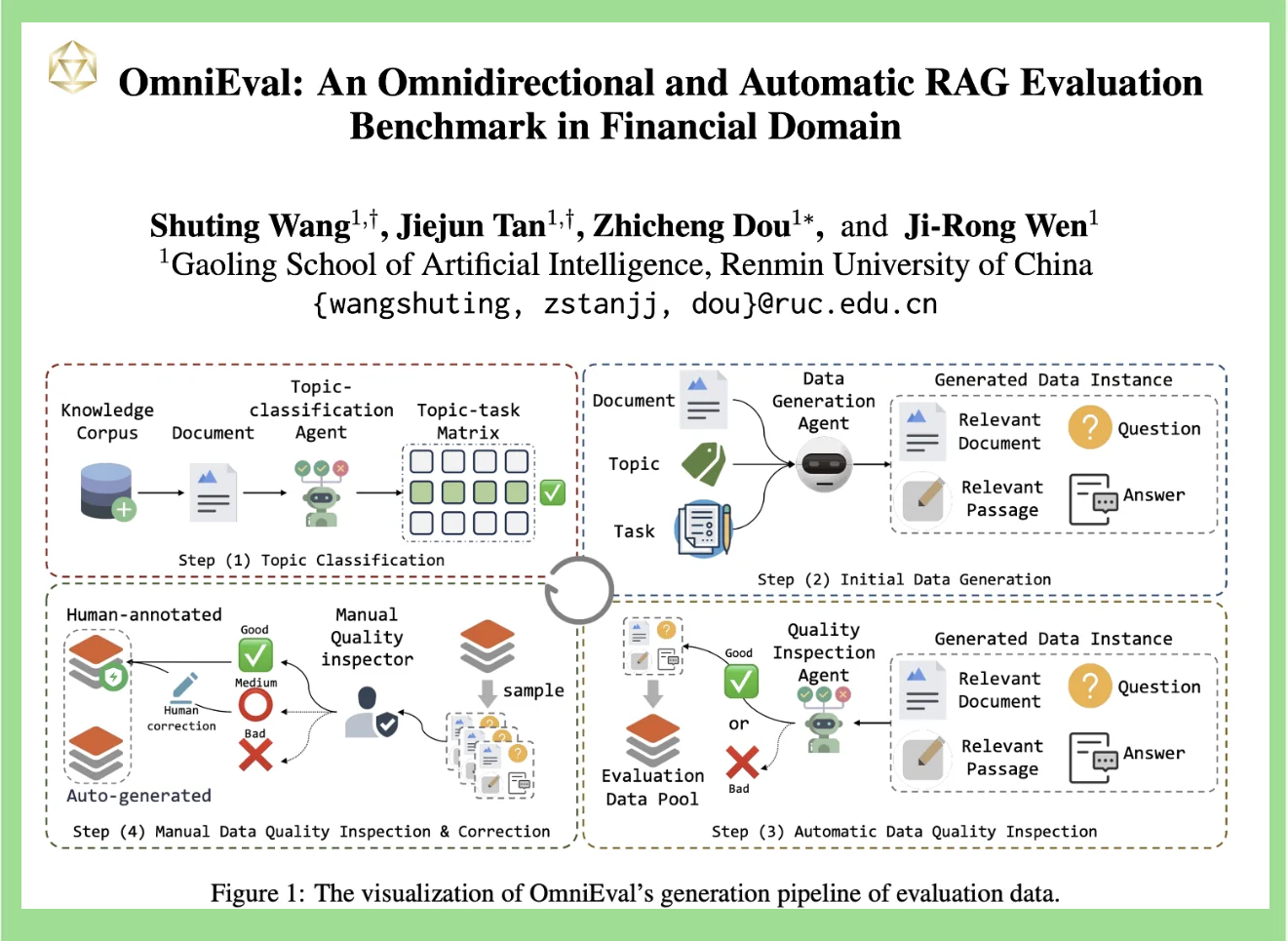
1. 金融領域應用
- 場景:智能投顧回答客戶投資問題。
- 優化策略:
- 引入知識圖譜構建投資產品關系網絡。
- 使用強化學習動態調整檢索策略。
- 效果:回答準確率提升至 92%,客戶滿意度提高 35%。
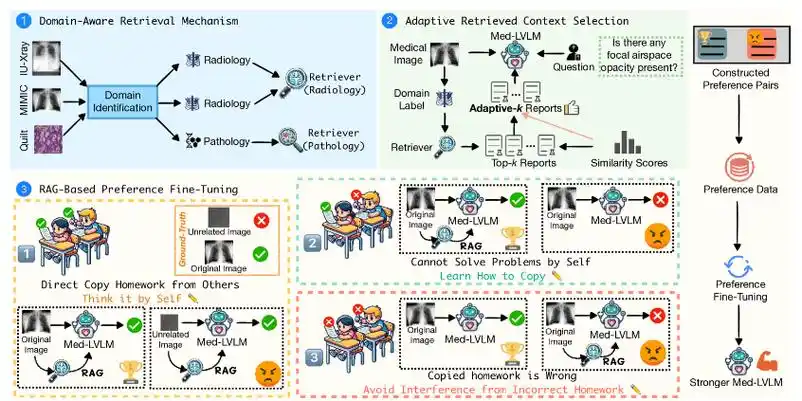
2. 醫療領域應用
- 場景:輔助醫生診斷罕見病。
- 技術方案:
- 多模態檢索(癥狀描述 + 醫學影像)。
- 實時更新醫學知識庫。
- 性能指標:
- 檢索召回率:98.7%
- 診斷建議符合率:91.2%
五、總結與未來趨勢
1. 技術選型建議
| 場景類型 | 檢索技術選擇 | 生成模型選擇 |
|---|---|---|
| 精確問答 | BM25 + 向量檢索 | GPT-4 Turbo |
| 創意生成 | 向量檢索 + 多樣性重排 | Claude 3 |
| 多模態交互 | CLIP + 表格檢索 | LLaVA-Interact |
2. 未來發展方向
- 動態知識庫:支持實時數據流接入,實現知識的持續更新。
- 自優化系統:通過強化學習自動調整檢索策略與生成參數。
- 邊緣部署:在終端設備運行輕量化 RAG 模型,減少對云端的依賴。
通過本文的技術解析與實戰指南,讀者可全面掌握 RAG 系統的構建方法與優化技巧,在 AIGC 領域實現從原型開發到工業級部署的跨越。






國密SM2算法的簽名和驗簽(附商用密碼檢測相關國家標準/國密標準下載))


---管理命令、配置安裝)






)


