讀書筆記

定義
1. 大數據(Big Data)
? ?- 指傳統數據處理工具難以處理的海量、高速、多樣的數據集合,通常具備3V特性(Volume體量大、Velocity速度快、Variety多樣性)。擴展后還包括Veracity(真實性)和Value(價值)。
2. Hadoop
? ?- 一個開源的分布式計算框架,用于存儲和處理大規模數據集。核心組件包括HDFS(存儲)和MapReduce(計算),具有高容錯性和橫向擴展能力。
3. HDFS(Hadoop Distributed File System)
? ?- Hadoop的分布式文件系統,設計用于**廉價硬件集群**。特點:
? ? ?- 分塊存儲(默認128MB/塊)
? ? ?- 多副本機制(默認3副本)
? ? ?- 主從架構(NameNode管理元數據,DataNode存儲實際數據)
4. MapReduce
? ?- 一種批處理編程模型,分為兩個階段:
? ? ?- Map階段:將任務分割成更小任務交給每臺服務器分別運行,也就是并行處理輸入數據(映射)
? ? ?- Reduce階段:聚合Map結果(歸約)
? ?- 適合離線大規模數據處理,但磁盤I/O開銷較大。
5. Spark
? ?- 基于內存的分布式計算引擎,相比MapReduce優勢:
? ? ?- 內存計算(比Hadoop快10-100倍)
? ? ?- 支持DAG(有向無環圖)優化執行計劃
? ? ?- 提供SQL、流處理、圖形處理、機器學習等統一API(Spark SQL/Streaming/GraphX/MLlib)
6. 機器學習(Machine Learning)
? ?- 通過算法讓計算機從數據中自動學習規律并做出預測/決策,主要分為:
? ? ?- 監督學習(如分類、回歸)
? ? ?- 無監督學習(如聚類、降維)
? ? ?- 強化學習(通過獎勵機制學習)
關鍵區別:Hadoop基于磁盤批處理,Spark基于內存迭代計算,機器學習則是數據分析的高級應用方法。
安裝Hadoop
1.虛擬機軟件安裝(搭建Hadoop cluster集群時需要很多臺虛擬機)
2.安裝Ubuntu操作系統(hadoop最主要在Linux操作系統環境下運行)
3.安裝Hadoop Single Node Cluster(只以一臺機器來建立Hadoop環境)
- 安裝JDK(Hadoop是java開發的,必須先安裝JDK)
- 設置SSH無密碼登錄(Hadoop必須通過SSH與本地計算機以及其他主機連接,所以必須設置SSH)
- 下載安裝Hadoop(官網下載Hadoop,安裝到Ubuntu中)
- 設置Hadoop環境變量(設置每次用戶登錄時必須要設置的環境變量)
- Hadoop配置文件的設置(在Hadoop的/usr/local/hadoop/etc/hadoop的目錄下,有很多配置設置文件)
- 創建并格式化HDFS目錄(HDFS目錄是存儲HDFS文件的地方,在啟動Hadoop之前必須先創建并格式化HDFS目錄)
- 啟動Hadoop(全部設置完成后啟動Hadoop,并查看Hadoop相關進程是否已經啟動)
- 打開Hadoop Web界面(Hadoop界面可以查看當前Hadoop的狀態:Node節點、應用程序、任務運行狀態)
常用命令:
啟動HDFS
start-dfs.sh啟動YARN(啟動Hadoop MapReduce框架YARN)
start-yarn.sh同時啟動HDFS和YARN
start-all.sh使用jps查看已經啟動的進程(查看NameNode、DataNode進程是否啟動)
PS:因為只有一臺服務器,所以所有功能都集中在一臺服務器中,可以看到:
- HDFS功能:NameNode、Secondary NameNode、DataNode已經啟動
- MapReduce2(YARN):Resource Manager、NodeManager已經啟動
jps
監聽端口上的網絡服務:
打開Hadoop Resource-Manager Web界面
http://localhost:8088/?NameNode HDFS Web界面
http://localhost:50070/
4.Hadoop Multi Node Cluster的安裝(至少有四臺服務器,才能發揮多臺計算機并行的優勢。不過我只有一個電腦,只能創建四臺虛擬主機演練)
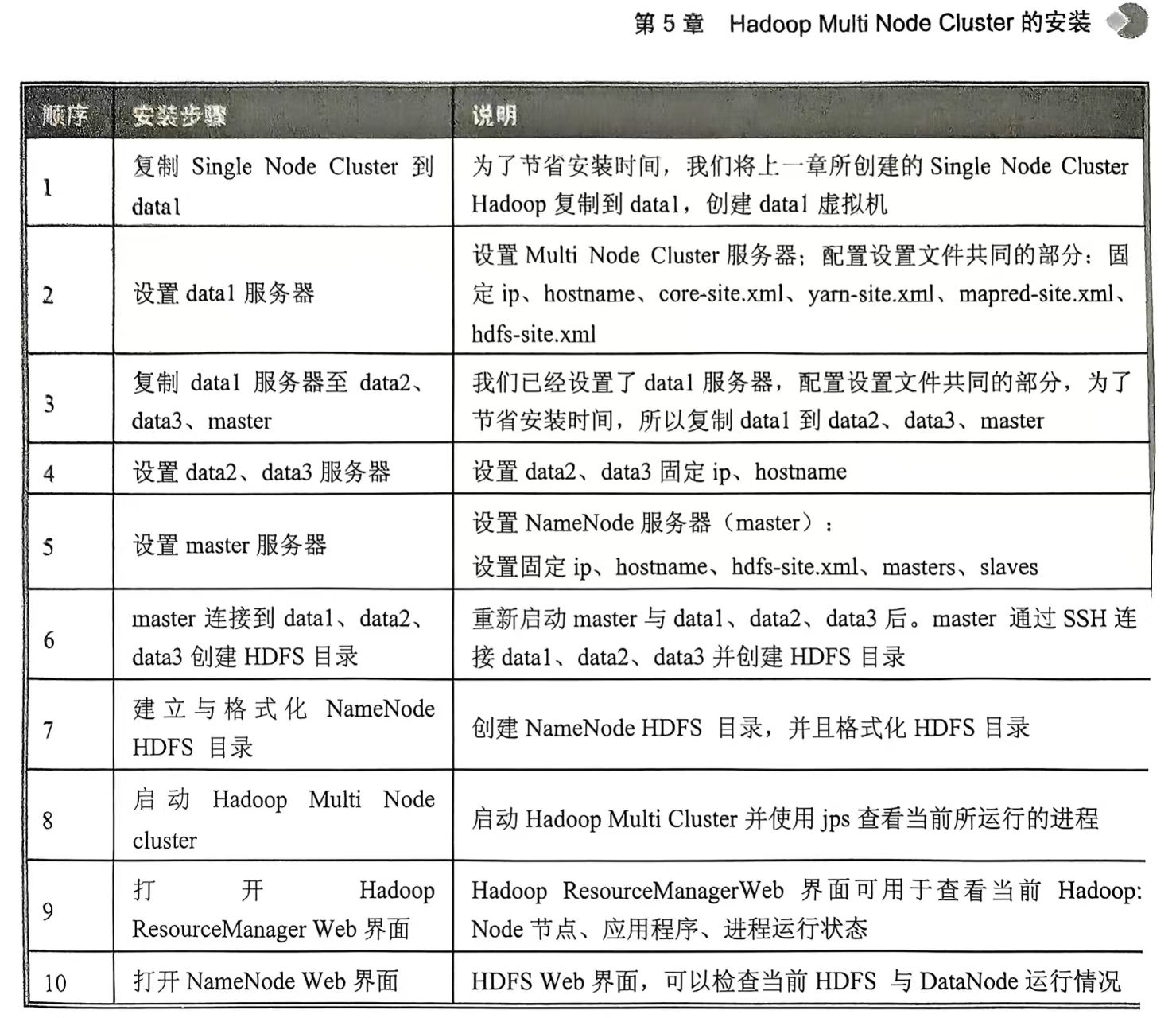
Hadoop的基本功能
1.HDFS
常用HDFS命令:

HDFS 常見命令 -CSDN博客
回頭再寫那些常用命令
2.MapReduce
以批處理為主。

首先使用Map將待處理的數據分割成很多的小份數據,由每臺服務器分別運行。
再通過Reduce程序進行數據合并,最后匯總整理出結果。
單詞計數

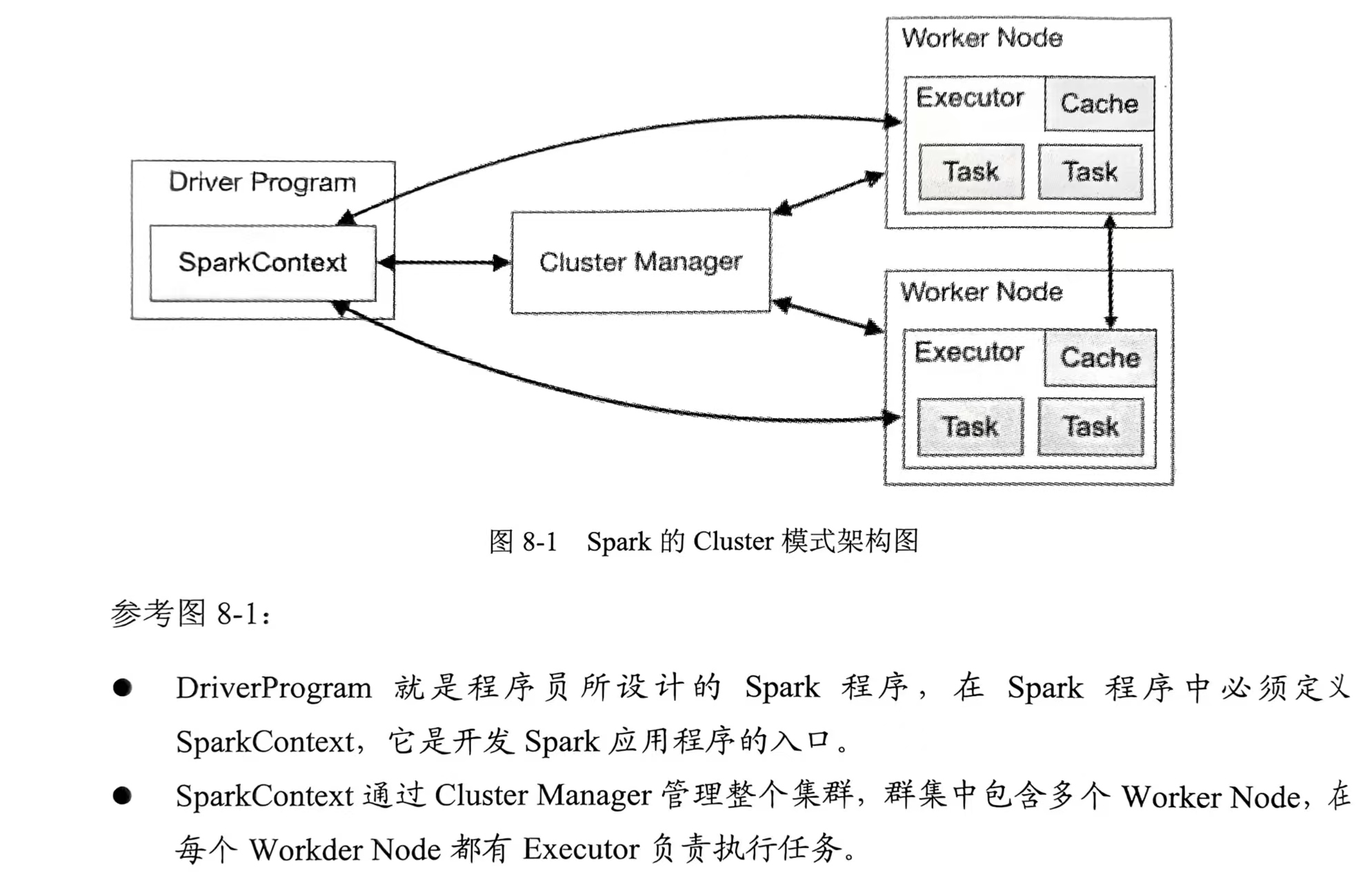
Spark?
Spark的Cluster模式架構圖👇
- 安裝Spark
- 安裝Scale
- 啟動spark-shell交互界面
- 啟動Hadoop(start-all.sh命令)
- 本地運行spark-shell(比如spark-shell --master local[4]->讀取本地文件->讀取HDFS文件)
- 在Hadoop YARN運行spark-shell(spark可以在Hadoop YARN上運行,讓Yarn幫助它進行多臺機器資源的管理。在Hadoop Yarn運行spark-shell->讀取本地文件->讀取HDFS文件->在Hadoop Web界面可以查看spark-shell APP,8080端口)
- 構建Spark Standalone Cluster執行環境(在master虛擬機設置spark-env.sh->復制spark程序到data1、data2、data3->在master虛擬機編輯slaves文件)
- 在Spark Standalone運行spark-shell(啟動Spark Standalone Cluster也就是start-all.sh->在Spark Standalone運行Spark-shell->Spark Standalone Web UI界面->讀取本地文件->讀取HDFS文件->停止Spark stand alone cluster)
Spark本身是以Scala開發的,所以先安裝Scala。試著安裝在master虛擬機上。
安裝:官網下載->解壓縮并移動->配置環境變量->啟動
PS:spark-shell默認顯示很多信息,可以自己手動改,讓它只顯示警告信息。(cp復制log4j.properties.template模板到log4j.properties)👇
spark-shell --master local[4] 其中local[N]表示本地運行,使用N個線程,也就是說可以同時執行N個程序。
讀取本地文件👇
讀取HDFS文件👇


Spark的基本功能




1.RDD的特性
spark的核心是RDD(彈性分布式數據集),屬于一種分布式的內存系統的數據集應用,RDD也是spark的主要優勢。
RDD能與其他系統兼容,可以導入外部存儲系統的數據集,如HDFS、Hbase或其他Hadoop數據源。
RDD的三種基本運算:轉換Transformation、動作Action、持久化Persistence
2.基本RDD“轉換”運算
- 先進入spark-shell
- 創建intRDD
- 創建stringRDD
- map運算
- map字符串運算
- filter數字運算
- filter字符串運算
- distinct運算
- randomSplit運算
- groupBy運算
命令就不寫了,下面也是
3.多個RDD“轉換”運算
- 先創建3個RDD來示范
- union并集運算
- intersection交集運算
- subtract差集運算
- cartersian笛卡爾乘積運算
4.基本“動作”運算
- 讀取元素
- 統計功能
5.RDD Key-Value基本“轉換”運算
- 創建范例Key-Value RDD
- 列出keys值
- 列出values值
- 使用filter篩選key運算
- 使用filter篩選value運算
- mapValues運算
- sortByKey從小到大按照key排序
- sortByKey從大到小按照key排序
- reduceByKey(如(3,4)(3,5)(1,1)相同key進行合并(3,9)(1,1))
6.多個RDD Key-Value“轉換”運算
- 創建Key-Value RDD范例
- Key-Value RDD join運算
- Key-Value leftOuterJoin運算
- Key-Value rightOuterJoin運算
- Key-Value subtractByKey運算
7.Key-Value“動作”運算
- Key-Value first運算
- 讀取第一條數據的元素
- Key-Value countByKey運算
- Key-Value collectAsMap運算
- 使用對照表轉換數據
8.Broadcast廣播變量
9.accumulator累加器
共享變量包括:
- Broadcast廣播變量
- accumulator累加器
10.RDD Persistence持久化
Spark RDD持久化機制,可以用于將需要重復運算的RDD存儲在內存中,以便大幅提升運算效率。
使用方法:
- RDD.persist()——可指定存儲等級
- RDD.unpersist()——取消持久化
11.用Spark創建WordCount
- 創建測試文件(mkdir -p ~workspace/WordCount/data,cd到剛剛創建的文件夾,編輯test.txt)
- 進入spark-shell(~workspace/WordCount/data下輸入spark-shell)
- 執行WordCount spark命令

- 查看data目錄(ll)
- 查看output目錄(cd output,ll,因為結果保存在/data/output)
- 查看part-00000輸出文件(cat part-00000)
Spark的集成開發環境
使用eclipse集成開發環境(IDE)開發Spark應用程序。
- 下載與安裝eclipse Scala IDE,安在master服務器上
- 下載項目所需要的Library
- 啟動eclipse
- 創建新的Spark項目(要添加外部Jar或者創建后像第五步一樣添加,設置scala library版本)
- 設置項目鏈接庫
- 新建scala程序
- 創建WordCount測試文本文件
- 創建WordCount.scala
- 編譯WordCount.scala程序
- 運行Word.scala程序
- 導出jar文件
- spark-submit介紹
- 在本地local模式運行WordCount程序(記得刪除之前的/data/output目錄,切換到WordCount目錄,本地運行WordCount——spark-submit...代碼巴拉巴拉,查看結果/data/output里)
- 在Hadoop yarn-client運行WordCount程序(介紹如何用spark-submit,在Hadoop YARN上運行WordCount Spark程序:啟動集群start-all.sh->在HDFS創建data目錄,復制LICENSE.txt文件到HDFS,查看HDFS->修改環境配置文件bashrc并使其生效->切換到WordCount項目目錄,在Hadoop YARN上運行WordCount(spark-submit),查看HDFS產生的目錄和文件,看完刪除,因為一會還要測試)
- 在Spark Standalone Cluster上運行WordCount程序(仍然是啟動Standalone Cluster->運行程序->看結果)
機器學習(推薦引擎)
幾個概念和目錄,實戰。簡寫,主播也第一次學
- 推薦算法是啥
- 推薦引擎在大數據分析的幾個使用場景:電影推薦
- ALS推薦算法
- ml-100k推薦數據(一個數據集)的下載
- 使用spark-shell導入ml-100k數據
- 查看導入的數據
- 使用ALS.train訓練(ALS.train命令)
- 使用模型進行推薦
- 顯示推薦電影名
- 創建Recommend項目(剛剛是用spark-shell學習的,它的缺點是無法重復使用,這次啟動eclipse演示:啟動eclipse->創建Recommend項目->創建Recommend.scala文件->起個名字吧->創建完成的Scala程序,接下來開始輸入程序代碼)
- Recommend.scala程序代碼(Import導入鏈接庫->main主函數代碼(數據準備、訓練、推薦)->SetLogger可設置不顯示log信息)
- 創建PrepareData()數據準備(創建PrepareData()函數->創建用戶評分數據->創建電影ID與名稱對照表->顯示數據記錄數)
- recommend()推薦程序代碼(recommend()推薦程序代碼、RecommendMovies()針對此用戶推薦電影)
- 運行Recommend.scala
- 創建AIsEvaluation.scala調校推薦引擎參數(前面使用的ALS.train命令訓練,會返回model訓練完成的模型,其中rank、Iterations、lambda這些參數值的設置會影響結果的準確度,以及訓練所需的時間。接下來將進行調校找出最佳的參數組合)
- 創建PrepareData()數據準備(共有4步,前3部與Recommend.scala完全相同:1.創建用戶評分數據;2.創建電影ID與名稱對照表;3.顯示數據記錄數;4.以隨機方式將數據分為3個部分并且返回(以8:1:1比例分成訓練數據、驗證數據、測試數據))
- 進行訓練評估(1.train Validation訓練評估:評估rank參數、評估numIterations參數、評估lambda參數、所有參數交叉評估。2.evaluateParamter評估單個參數。3.Chart.plotBarLineChart繪制出柱形圖與折線圖。4.trainModel訓練模型。5.計算RMSE,表示預測與實際的誤差平均值,通常RMSE越小誤差越小。6.evaluateAllParameter程序將三個參數交叉評估找出最好的參數組合)
- 運行AlsEvaluation(運行AlsEvaluation,評估rank參數,評估lambda參數、所有參數交叉評估找出最好的參數組合)
- 修改Recommend.scala為最佳參數組合(剛剛我們已經找出了最佳參數組合)
機器學習(二元分類)

機器學習(多元分類)

機器學習(回歸分析)

數據可視化

使用Apache Zeppelin數據可視化。






)







技術的實例)
編寫單元測試)
文件存儲服務S3 介紹使用代碼集成)


 是誰提出的)