引入
通過前面的文章,我們梳理了大數據流計算的核心發展脈絡:
- S4論文詳解
- S4論文總結
- Storm論文詳解
- Storm論文總結
- Kafka論文詳解
- Kafka論文總結
- MillWheel論文詳解
- MillWheel論文總結
- Dataflow論文詳解
- Dataflow論文總結
而我們專欄的主角Flink正是站在前人的肩膀上,不斷迭代,目前已經是實時流計算的最佳實踐技術,下面我們就通過Flink的2015年發布的《Apache Flink: Stream and Batch Processing in a Single Engine》這篇論文,去一探究竟。
摘要
Apache Flink 是一個用于處理流數據和批數據的開源系統。Flink 基于這樣一種理念構建:許多類型的數據處理應用,包括實時分析、持續數據管道、歷史數據處理(批處理)以及迭代算法(機器學習、圖分析),都可以表示為有容錯能力的流水線數據流并加以執行。在本文中,我們介紹 Flink 的架構,并詳細闡述如何將(看似多樣的)一系列用例統一在單一執行模型之下。
1. 引言
傳統上,數據流處理(例如復雜事件處理系統所代表的)和靜態(批量)數據處理(例如 MPP 數據庫和 Hadoop 所代表的)被視為兩種截然不同的應用類型。它們使用不同的編程模型和 API 進行編程,并由不同的系統執行(例如,像 Apache Storm、IBM Infosphere Streams、Microsoft StreamInsight 或 Streambase 這樣的專用流處理系統,與關系數據庫或 Hadoop 執行引擎,包括 Apache Spark 和 Apache Drill 相對)。傳統上,批數據處理在使用場景、數據規模和市場中占據了最大份額,而流數據分析主要服務于特定應用。
然而,越來越明顯的是,如今大量的大規模數據處理用例處理的數據實際上是隨著時間不斷生成的。這些連續的數據流例如來自網絡日志、應用程序日志、傳感器,或者是數據庫中應用程序狀態的變化(事務日志記錄)。如今的設置并沒有將這些流視為流,而是忽略了數據生成的連續性和及時性。相反,數據記錄(通常是人為地)被批量處理成靜態數據集(例如,按小時、天或月的數據塊),然后以與時間無關的方式進行處理。數據收集工具、工作流管理器和調度器協調批次的創建和處理,而這實際上是一個連續的數據處理管道。像 “lambda 架構”[21] 這樣的架構模式將批處理和流處理系統結合起來,實現多條計算路徑:一條用于及時獲取近似結果的快速流處理路徑,以及一條用于后期獲取準確結果的批處理離線路徑。所有這些方法都存在高延遲(由批次導致)、高復雜性(連接和協調多個系統,并兩次實現業務邏輯)以及任意的不準確性等問題,因為時間維度并沒有由應用程序代碼明確處理。
Apache Flink 遵循一種范式,即在編程模型和執行引擎中,將數據流處理作為實時分析、連續流和批處理的統一模型。結合允許對數據流進行準任意重放的持久化消息隊列(如 Apache Kafka 或 Amazon Kinesis),流處理程序在實時處理最新事件、在大窗口中定期連續聚合數據,或處理數 TB 的歷史數據之間沒有區別。相反,這些不同類型的計算只是在持久化流中的不同點開始處理,并在計算過程中維護不同形式的狀態。通過高度靈活的窗口機制,Flink 程序可以在同一操作中計算早期近似結果以及延遲準確結果,從而無需為這兩種用例組合不同的系統。Flink 支持不同的時間概念(事件時間、攝入時間、處理時間),以便為程序員在定義事件應如何關聯方面提供高度的靈活性。
同時,Flink 認識到現在以及將來都存在對專用批處理(處理靜態數據集)的需求。對靜態數據的復雜查詢仍然很適合批處理抽象。此外,對于遺留的流處理用例實現,以及對于尚不知道在流數據上執行此類處理的高效算法的分析應用程序,仍然需要批處理。批處理程序是流處理程序的特殊情況,其中流是有限的,并且記錄的順序和時間無關緊要(所有記錄隱含地屬于一個涵蓋所有的窗口)。然而,為了以具有競爭力的易用性和性能支持批處理用例,Flink 有一個用于處理靜態數據集的專用 API,對連接或分組等操作符的批處理版本使用專用的數據結構和算法,并使用專用的調度策略。結果是,Flink 在流運行時之上呈現為一個成熟且高效的批處理器,包括用于圖分析和機器學習的庫。Flink 源自 Stratosphere 項目 [4],是 Apache 軟件基金會的頂級項目,由一個龐大且活躍的社區開發和支持(撰寫本文時,有超過 180 名開源貢獻者),并在多家公司的生產環境中使用。
本文的貢獻如下:
- 我們提出了一種流和批數據處理的統一架構,包括僅與靜態數據集相關的特定優化。
- 我們展示了如何將流處理、批處理、迭代和交互式分析表示為容錯的流數據流(在第 3 節)。
- 我們討論了如何通過展示流處理、批處理、迭代和交互式分析如何表示為流數據流,在這些數據流之上構建一個具有靈活窗口機制的成熟流分析系統(在第 4 節),以及一個成熟的批處理器(在第 4.1 節)。
2. 系統架構
在本節中,我們將 Flink 的架構闡述為一個軟件棧和一個分布式系統。雖然 Flink 的 API 棧在不斷發展,但我們可以區分出四個主要層:部署層、核心層、API 層和庫層。
Flink 的運行時與應用程序編程接口(APIs)
圖 1 展示了 Flink 的軟件堆棧。Flink 的核心是分布式數據流引擎,用于執行數據流程序。一個 Flink 運行時程序是由有狀態算子組成的有向無環圖(DAG),這些算子通過數據流相互連接。Flink 中有兩個核心 API:用于處理有限數據集的數據集(DataSet)API(通常稱為批處理),以及用于處理可能無限的數據流的數據流(DataStream)API(通常稱為流處理)。Flink 的核心運行時引擎可以看作是一個流式數據流引擎,DataSet 和 DataStream 這兩個 API 所創建的運行時程序都能由該引擎執行。因此,它作為一個通用架構,對有界(批處理)和無界(流處理)處理進行了抽象。在核心 API 之上,Flink 集成了特定領域的庫和 API,用于生成 DataSet 和 DataStream API 程序,目前有用于機器學習的 FlinkML、用于圖處理的 Gelly 以及用于類似 SQL 操作的 Table。
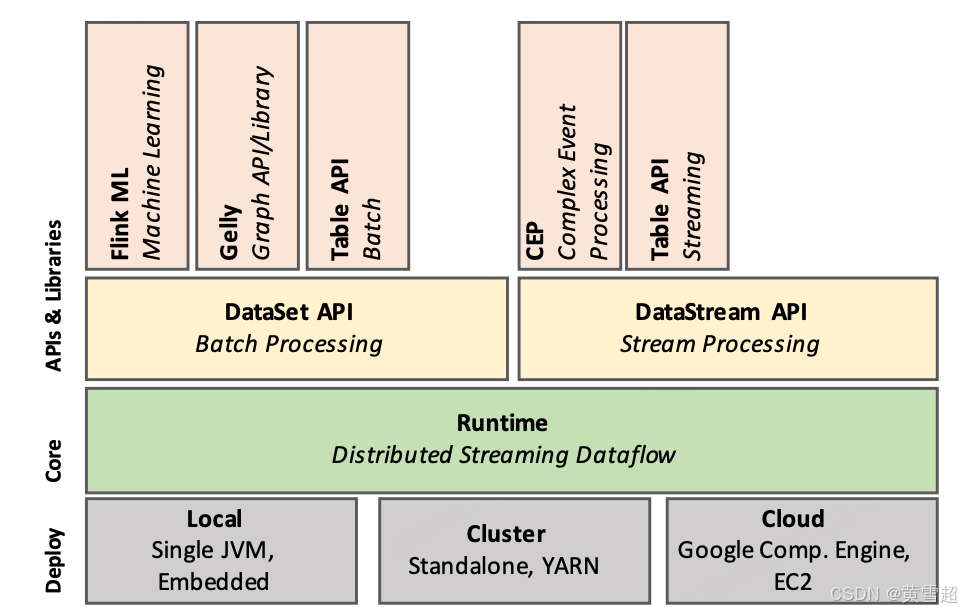
圖 1:Flink 軟件堆棧
如圖 2 所示,一個 Flink 集群包含三種類型的進程:客戶端、作業管理器(Job Manager)以及至少一個任務管理器(Task Manager)。客戶端獲取程序代碼,將其轉換為數據流圖,然后提交給作業管理器。在這個轉換階段,還會檢查算子之間交換數據的數據類型(模式),并創建序列化器和其他特定于類型 / 模式的代碼。DataSet 程序還會經歷基于成本的查詢優化階段,類似于關系型查詢優化器所執行的物理優化(更多細節見 4.1 節)。
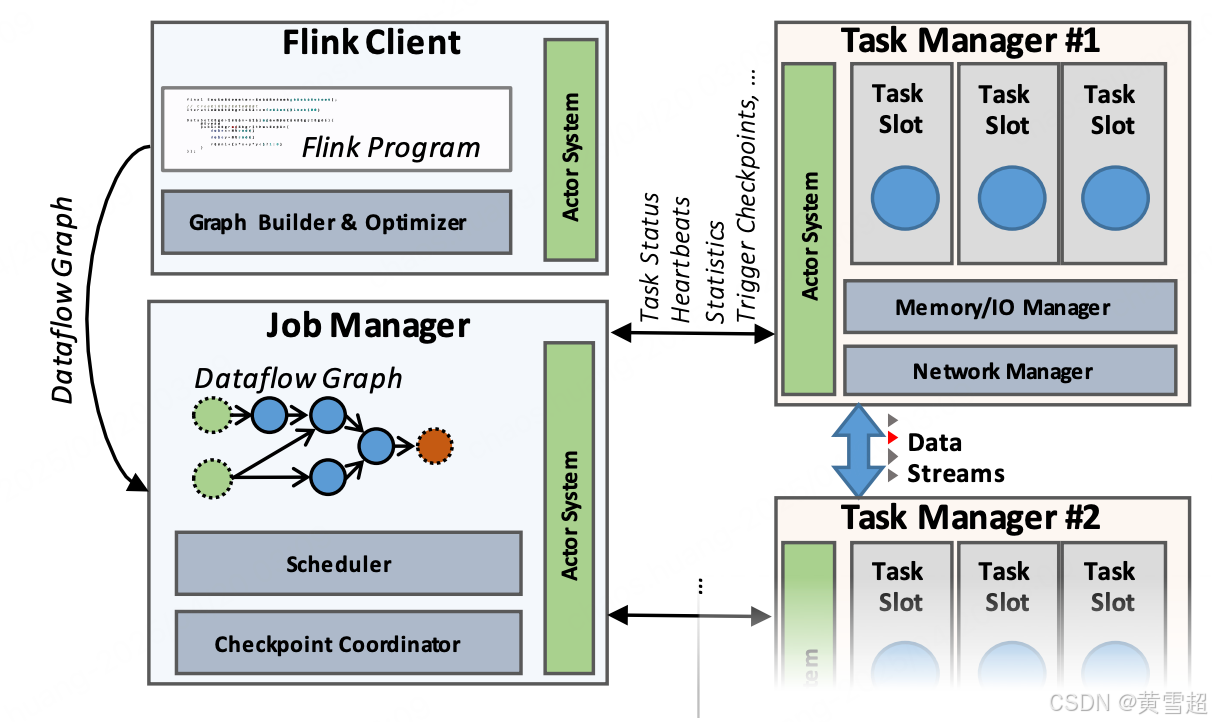
圖 2:Flink 進程模型
作業管理器協調整個數據流的分布式執行。它跟蹤每個算子和數據流的狀態與進度,調度新的算子,并協調查點和恢復。在高可用設置中,作業管理器會在每次檢查點時將一組最小化的元數據持久化到一個容錯存儲中,以便備用的作業管理器能夠重構檢查點并從該點恢復數據流的執行。實際的數據處理在任務管理器中進行。一個任務管理器執行一個或多個生成數據流的算子,并向作業管理器報告它們的狀態。任務管理器維護緩沖池以緩沖或具體化數據流,并維護網絡連接以便在算子之間交換數據流。
關鍵詞拓展介紹:
- 有向無環圖(Directed Acyclic Graph, DAG):在計算機科學中,尤其是在數據流處理和分布式計算領域經常使用。它是一種有向圖,其中從任何節點出發沿著有向邊前進,都無法回到該節點,即不存在回路。在 Flink 中,將運行時程序表示為 DAG 有助于清晰地描述算子之間的數據流動和依賴關系,使得系統能夠高效地調度和執行任務。例如,在一個數據處理流程中,可能先有數據讀取算子,然后數據經過過濾算子、轉換算子等,這些算子按照特定順序連接形成 DAG,Flink 可以基于此進行優化和并行執行。
- 算子(Operator):是 Flink 數據處理的基本單元,負責對數據流中的數據執行特定操作,如過濾、轉換、聚合等。每個算子都有輸入和輸出,輸入來自上游算子的數據流,處理后的數據通過輸出傳遞給下游算子。有狀態算子意味著算子在處理數據過程中會維護一些狀態信息,比如窗口聚合算子需要記住窗口內的數據以進行計算。
- 序列化器(Serializer):在分布式系統中,數據需要在不同節點之間傳輸,而不同節點的內存布局和數據表示可能不同。序列化器的作用就是將數據對象轉換為字節流的形式,以便在網絡上傳輸或存儲,在接收端再通過反序列化將字節流恢復為原始的數據對象。在 Flink 中,根據數據類型和模式創建合適的序列化器,能確保數據在不同算子和節點間準確無誤地傳輸。
- 基于成本的查詢優化(Cost - based Query Optimization):是一種數據庫查詢優化技術,它通過評估不同查詢執行計劃的成本(如 CPU 使用、內存占用、I/O 操作等),選擇成本最低的執行計劃來提高查詢性能。在 Flink 的 DataSet 程序中應用這種優化,與關系型數據庫的物理優化類似,能夠根據數據量、算子復雜度等因素,合理安排數據處理的順序和方式,從而提升批處理的效率。?
3 通用架構:流式數據流
盡管用戶可以使用多種 API 編寫 Flink 程序,但所有 Flink 程序最終都會編譯為一種通用表示形式:數據流圖。數據流圖由 Flink 的運行時引擎執行,該運行時引擎是批處理(DataSet)和流處理(DataStream)API 之下的通用層。
3.1 數據流圖
如圖 3 所示,數據流圖是一種有向無環圖(DAG),它由以下部分組成:(i)有狀態算子;(ii)數據流,這些數據流表示由某個算子產生的數據,可供其他算子使用。由于數據流圖是以數據并行的方式執行的,算子會被并行化為一個或多個稱為子任務的并行實例,數據流也會被拆分為一個或多個流分區(每個產生數據的子任務對應一個分區)。有狀態算子(無狀態算子是其特殊情況)實現所有的處理邏輯(例如,過濾、哈希連接和流窗口函數)。其中許多算子是知名算法經典版本的實現。在第 4 節中,我們將詳細介紹窗口算子的實現。數據流以各種模式在產生數據和使用數據的算子之間分發數據,例如點對點、廣播、重新分區、扇出和合并。
關鍵詞拓展介紹:
- 數據并行(Data - parallel):是分布式計算中的一種并行計算方式,它將數據劃分為多個部分,不同的計算節點或任務并行處理不同的數據部分。在 Flink 中,通過將算子并行化為子任務,每個子任務處理數據流的一個分區,從而實現數據并行。這樣可以充分利用集群的計算資源,提高處理大規模數據的效率。例如,在處理一個大數據集的聚合操作時,可以將數據集分成多個部分,由不同的子任務并行計算各個部分的聚合結果,最后再合并這些結果得到最終的聚合值。
- 點對點(Point - to - point):一種數據傳輸模式,在該模式下,數據從一個特定的生產者直接傳輸到一個特定的消費者,就像在一條專用的通道上傳輸數據,一對一的關系非常明確。在 Flink 的數據流中,如果一個算子的某個子任務只將數據發送給另一個算子的特定子任務,這就是點對點的數據分發模式。
- 廣播(Broadcast):在這種數據分發模式中,一個算子產生的數據會被復制并發送到下游算子的所有并行實例(子任務)。常用于需要將一些全局配置信息或字典數據等發送給所有處理節點的場景。例如,在一個流處理任務中,如果需要所有節點都依據相同的規則進行數據過濾,就可以將這些規則以廣播的方式發送給所有相關算子的子任務。
- 重新分區(Re - partition):指改變數據流中數據分區方式的操作。在 Flink 中,數據最初可能以某種分區方式分布,但根據后續算子的需求,可能需要重新分區,以實現更好的并行處理效果。比如,為了進行更高效的聚合操作,可能需要將原本按照某種鍵值隨機分布的數據,重新按照聚合鍵進行分區。
- 扇出(Fan - out):類似于廣播,但可能不是發送到所有下游實例,而是根據一定規則將數據分發給多個下游實例。例如,一個算子根據數據的不同特征,將數據分別發送到不同功能的下游算子進行處理,就像將一條數據 “扇出” 到多個分支。
- 合并(Merge):與扇出相反,它是將多個數據流合并為一個數據流的操作。在 Flink 中,多個上游算子產生的數據流可以通過合并操作匯聚到一個下游算子進行統一處理。例如,在進行多源數據的聯合分析時,就需要先將不同來源的數據流合并。
?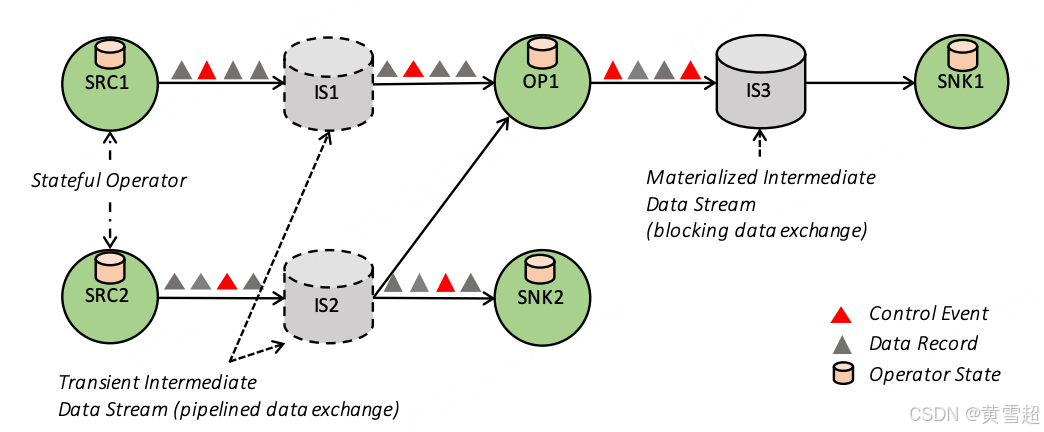
圖 3:一個簡單的數據流圖
3.2 通過中間數據流進行數據交換
Flink 的中間數據流是算子之間數據交換的核心抽象。中間數據流代表了對算子產生的數據的一種邏輯引用,這些數據可以被一個或多個算子使用。中間流之所以是邏輯上的,是因為它們所指向的數據可能會也可能不會在磁盤上物化。數據流的特定行為由 Flink 的高層進行參數化設置(例如,DataSet API 使用的程序優化器)。
流水線式與阻塞式數據交換:流水線式中間流在并發運行的生產者和消費者之間交換數據,從而實現流水線式執行。因此,流水線式流會將消費者的背壓反饋給生產者,通過中間緩沖池提供一定的彈性,以補償短期的吞吐量波動。Flink 在連續流程序以及批處理數據流的許多部分都使用流水線式流,盡可能避免數據物化。另一方面,阻塞式流適用于有界數據流。阻塞式流會在將數據提供給消費者之前,先緩沖產生數據的算子的所有數據,從而將產生數據的算子和消費數據的算子分隔為不同的執行階段。阻塞式流自然需要更多內存,經常會溢出到二級存儲,并且不會傳遞背壓。它們用于在需要時將連續的算子相互隔離,以及在諸如排序合并連接等可能導致分布式死鎖的具有打破流水線的算子的場景中使用。
平衡延遲與吞吐量:Flink 的數據交換機制圍繞緩沖區的交換來實現。當生產者端的數據記錄準備好時,它會被序列化并拆分成一個或多個緩沖區(一個緩沖區也可以容納多條記錄),這些緩沖區可以轉發給消費者。緩沖區會在以下兩種情況之一被發送給消費者:(i)一旦緩沖區滿了;(ii)當達到超時條件時。這使得 Flink 可以通過將緩沖區大小設置為較高的值(例如,幾千字節)來實現高吞吐量,通過將緩沖區超時時間設置為較低的值(例如,幾毫秒)來實現低延遲。圖 4 展示了在 30 臺機器(120 個核心)上的一個簡單流過濾(grep)作業中,緩沖區超時時間對記錄傳輸的吞吐量和延遲的影響。Flink 可以實現 20 毫秒的可觀測的 99% 延遲。相應的吞吐量是每秒 150 萬個事件。隨著我們增加緩沖區超時時間,我們會看到延遲隨著吞吐量的增加而增加,直到達到最大吞吐量(即緩沖區填滿的速度比超時到期的速度快)。在緩沖區超時時間為 50 毫秒時,集群達到每秒超過 8000 萬個事件的吞吐量,99% 延遲為 50 毫秒。
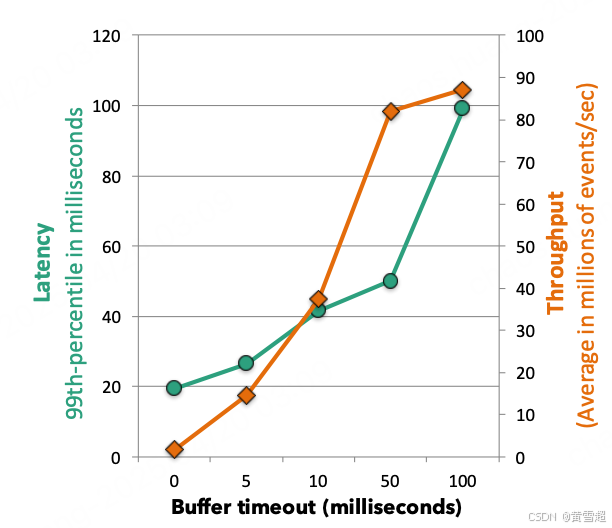
圖 4:緩沖區超時對延遲和吞吐量的影響
控制事件:除了交換數據,Flink 中的流還會傳遞不同類型的控制事件。這些是由算子注入到數據流中的特殊事件,并與流分區內的所有其他數據記錄和事件按順序傳遞。接收算子在這些事件到達時,通過執行特定操作來做出反應。Flink 使用多種特殊類型的控制事件,包括:
- 檢查點屏障,通過將流劃分為檢查點前和檢查點后的數據來協調檢查點(在 3.3 節討論),
- 水位線,用于表示流分區內事件時間的進展(在 4.1 節討論),
- 迭代屏障,用于表示流分區已到達超步(superstep)的末尾,用于基于循環數據流的批量 / 陳舊同步并行迭代算法(在 5.3 節討論)。
如前所述,控制事件假定流分區會保留記錄的順序。為此,Flink 中消耗單個流分區的一元算子保證記錄的先進先出(FIFO)順序。然而,接收多個流分區的算子會按到達順序合并流,以跟上流的速率并避免背壓。因此,Flink 中的流數據流在任何形式的重新分區或廣播之后,都不提供順序保證,處理亂序記錄的責任留給算子實現。我們發現這種安排提供了最有效的設計,因為大多數算子不需要確定性順序(例如,哈希連接、映射),而需要補償亂序到達的算子,例如事件時間窗口,可以作為算子邏輯的一部分更有效地做到這一點。
關鍵詞拓展介紹:
- 背壓(Back Pressure):在數據處理系統中,當數據的生產速度超過了消費速度時,就會出現背壓現象。在 Flink 的流水線式數據交換中,消費者處理數據較慢時,會導致數據在中間緩沖區堆積,最終影響到生產者的生產速度,這種從消費者向生產者反饋的壓力就是背壓。通過中間緩沖池的彈性機制,Flink 可以在一定程度上應對背壓,避免系統崩潰。
- 物化(Materialization):在數據處理中,物化指將邏輯上的數據(如中間計算結果)實際存儲到物理介質
3.3 容錯
Flink 提供可靠的執行,具備嚴格的 “精確一次處理” 一致性保證,并通過檢查點和部分重執行來處理故障。為了有效地提供這些保證,系統的一般假設是數據源是持久且可重放的。此類數據源的示例包括文件和持久消息隊列(例如,Apache Kafka)。在實際應用中,通過在源算子的狀態中保留預寫日志,非持久數據源也可以被納入其中。
Apache Flink 的檢查點機制基于分布式一致性快照的概念,以實現 “精確一次處理” 的保證。數據流可能具有無界性,這使得故障恢復時的重新計算不太現實,因為對于長時間運行的作業,可能需要重放數月的計算。為了限制恢復時間,Flink 會定期對算子的狀態進行快照,包括輸入流的當前位置。
核心挑戰在于在不停止拓撲執行的情況下,對所有并行算子進行一致性快照。本質上,所有算子的快照都應對應于計算中的相同邏輯時間。Flink 中使用的機制稱為異步屏障快照(ABS [7])。屏障是注入到輸入流中的控制記錄,它們對應于一個邏輯時間,并在邏輯上將流分為兩部分:其影響將包含在當前快照中的部分,以及稍后將被快照的部分。
一個算子從上游接收屏障,首先執行對齊階段,確保已接收所有輸入的屏障。然后,算子將其狀態(例如,滑動窗口的內容或自定義數據結構)寫入持久存儲(例如,存儲后端可以是 HDFS 等外部系統)。一旦狀態備份完成,算子就將屏障轉發到下游。最終,所有算子都將記錄其狀態的快照,全局快照也就完成了。例如,在圖 5 中,我們展示了快照 t2 包含所有算子狀態,這些狀態是在 t2 屏障之前消耗所有記錄的結果。異步屏障快照與用于異步分布式快照的 Chandy - Lamport 算法有相似之處 [11]。然而,由于 Flink 程序的有向無環圖(DAG)結構,異步屏障快照不需要對正在傳輸中的記錄進行檢查點操作,而僅依賴對齊階段將這些記錄的所有影響應用到算子狀態上。這保證了需要寫入可靠存儲的數據量保持在理論最小值(即僅算子的當前狀態)。
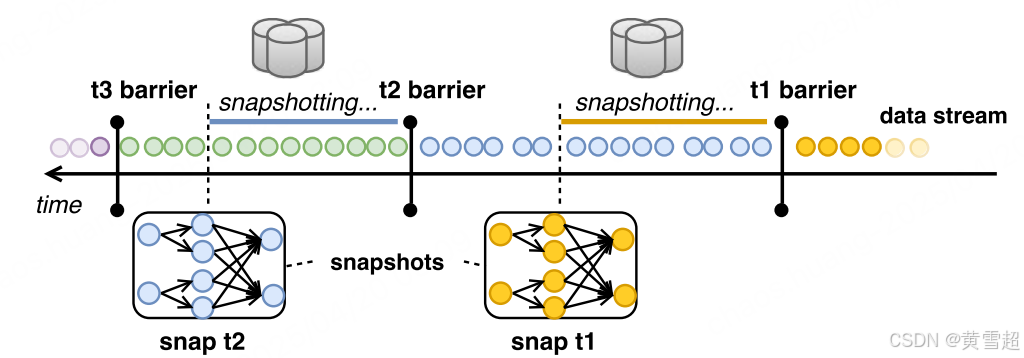
圖 5:異步屏障快照
從故障中恢復時,會將所有算子狀態恢復到上次成功快照時的相應狀態,并從有快照的最新屏障處重新啟動輸入流。恢復時所需的最大重新計算量限制在兩個連續屏障之間的輸入記錄數量。此外,通過額外重放直接上游子任務中緩沖的未處理記錄,還可以對失敗的子任務進行部分恢復 [7]。
異步屏障快照具有幾個優點:i)它保證精確一次的狀態更新,且從不暫停計算;ii)它與其他形式的控制消息完全解耦(例如,由觸發窗口計算的事件解耦,從而不將窗口機制限制為檢查點間隔的倍數);iii)它與用于可靠存儲的機制完全解耦,允許根據 Flink 使用的更大環境,將狀態備份到文件系統、數據庫等。
關鍵詞拓展介紹:
- 精確一次處理(Exactly - Once Processing):這是流處理系統中非常重要的一致性語義,意味著無論系統發生何種故障,每個輸入記錄都只會對最終結果產生一次影響。Flink 通過異步屏障快照等機制來確保這一語義,避免數據重復處理或處理不足的情況。
- 預寫日志(Write - Ahead Log,WAL):一種日志記錄策略,在對數據進行實際修改之前,先將修改操作記錄到日志中。這樣在系統故障后,可以通過重放日志來恢復數據到故障前的狀態。在 Flink 處理非持久數據源時,利用預寫日志可模擬數據源的持久性和可重放性。
- 有向無環圖(Directed Acyclic Graph,DAG):在 Flink 程序中,DAG 用于表示數據流的拓撲結構,節點表示算子,邊表示數據流的流向。DAG 結構使得 Flink 能夠有效地對作業進行調度和優化,并且在異步屏障快照機制中,這種結構簡化了檢查點的處理過程,使得無需對正在傳輸中的記錄進行檢查點操作。
- 異步屏障快照(Asynchronous Barrier Snapshotting):是 Flink 實現分布式一致性檢查點的關鍵技術。在分布式流處理系統中,為了保證在故障發生時能夠恢復到某個一致狀態,需要定期對系統狀態進行快照。異步屏障快照通過在數據流中插入特殊的屏障(barrier)來標記快照的邊界。這些屏障異步地在數據流中傳播,使得各個算子可以獨立地對自己的狀態進行快照,而不會阻塞數據流的正常處理。這樣既保證了系統的高可用性,又能在不影響正常數據處理的情況下獲取準確的系統狀態快照,以便在故障恢復時使用。
3.4 迭代數據流
增量處理和迭代對于圖處理和機器學習等應用至關重要。數據并行處理平臺對迭代的支持通常依賴于為每次迭代提交一個新作業,或者通過向正在運行的有向無環圖(DAG)添加額外節點 [6, 25] 或反饋邊 [23]。
Flink 中的迭代是作為迭代步驟來實現的,這些特殊算子自身可以包含一個執行圖(圖 6)。為了維持基于有向無環圖的運行時和調度器,Flink 允許存在迭代 “頭” 和迭代 “尾” 任務,它們通過反饋邊隱式連接。這些任務的作用是為迭代步驟建立一個活動反饋通道,并為處理該反饋通道內傳輸的數據記錄提供協調。實現任何類型的結構化并行迭代模型(如批量同步并行(BSP)模型)都需要協調,這是通過控制事件來實現的。我們將分別在 4.4 節和 5.3 節解釋迭代在 DataStream 和 DataSet API 中是如何實現的。
關鍵詞拓展介紹:
- 增量處理(Incremental Processing):在數據處理場景中,增量處理指的是系統能夠處理新到達的數據,并基于之前處理的結果,以一種逐步的、遞增的方式更新最終的處理結果,而不需要重新處理所有數據。例如在機器學習模型訓練中,新的數據樣本到達時,模型可以基于之前訓練得到的參數,增量地更新模型,而無需從頭開始訓練。
- 批量同步并行(Bulk Synchronous Parallel,BSP)模型:一種并行計算模型,在該模型中,計算被組織成一系列的超步(superstep)。在每個超步中,所有處理器并行執行本地計算,然后進行同步通信,交換數據。這種模型的特點是簡單且易于理解和實現,常用于大規模數據并行計算,例如圖算法和機器學習算法的實現。在 Flink 中,實現類似 BSP 模型的迭代時,通過迭代 “頭” 和 “尾” 任務以及控制事件來協調各部分的工作,以達到同步和數據交換的目的。
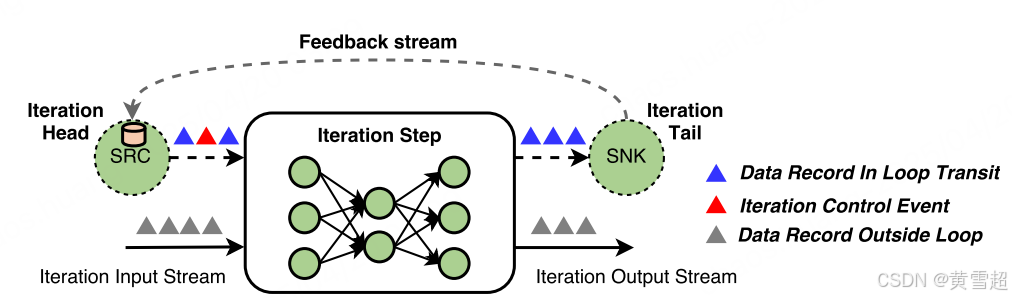
圖 6:Apache Flink 的迭代模型
4. 基于數據流的流分析
Flink 的 DataStream API 在 Flink 運行時之上實現了一個完整的流分析框架,其中包括管理時間的機制,例如亂序事件處理、定義窗口,以及維護和更新用戶定義的狀態。流處理 API 基于 DataStream 的概念,DataStream 是給定類型元素的(可能無界的)不可變集合。由于 Flink 的運行時已經支持流水線式的數據傳輸、連續的有狀態算子,以及用于一致性狀態更新的容錯機制,因此在其之上構建流處理器本質上歸結為實現一個窗口系統和一個狀態接口。如前所述,這些對于運行時來說是不可見的,運行時將窗口僅僅視為有狀態算子的一種實現。
4.1 時間的概念
Flink 區分了兩種時間概念:i)事件時間,它表示事件產生的時間(例如,與來自傳感器(如移動設備)的信號相關聯的時間戳);ii)處理時間,它是處理數據的機器的掛鐘時間。
在分布式系統中,事件時間和處理時間之間存在任意偏差 [3]。這種偏差可能意味著基于事件時間語義獲取答案時會出現任意延遲。為了避免任意延遲,這些系統會定期插入稱為水位線的特殊事件,以標記全局進度。例如,在時間推進的情況下,水位線包含一個時間屬性 t,表示所有小于 t 的事件都已進入算子。水位線有助于執行引擎以正確的事件順序處理事件,并通過統一的進度度量對諸如窗口計算之類的操作進行序列化。
水位線起源于拓撲結構的數據源,在那里我們可以確定未來元素中固有的時間。水位線從數據源傳播到數據流的其他算子。算子決定如何對水位線做出反應。簡單操作,如 map 或 filter 只是轉發它們接收到的水位線,而更復雜的基于水位線進行計算的算子(例如事件時間窗口)首先計算由水位線觸發的結果,然后再轉發水位線。如果一個操作有多個輸入,系統僅將傳入水位線中的最小值轉發給該算子,從而確保結果的正確性。
基于處理時間的 Flink 程序依賴于本地機器時鐘,因此時間概念不太可靠,這可能導致恢復時重放不一致。然而,它們具有較低的延遲。基于事件時間的程序提供了最可靠的語義,但由于事件時間與處理時間的滯后,可能會出現延遲。Flink 引入了第三種時間概念,作為事件時間的一種特殊情況,稱為攝入時間,即事件進入 Flink 的時間。這實現了比事件時間更低的處理延遲,并且與處理時間相比能得到更準確的結果。
關鍵詞拓展介紹:
- DataStream API:Flink 用于流處理的核心 API,它提供了豐富的操作符(如 map、filter、window 等)來處理無界數據流。通過 DataStream API,開發者可以方便地構建復雜的流處理應用,實現實時數據處理和分析。例如在實時監控系統中,可以使用 DataStream API 對傳感器實時發送的數據進行處理和分析。
- 事件時間(Event - Time):在流處理中,事件時間是事件實際發生的時間,它通常通過事件攜帶的時間戳來表示。使用事件時間可以確保流處理結果的準確性,不受數據到達處理系統的順序和時間的影響。例如在電商訂單處理中,以訂單生成時間(事件時間)來統計不同時間段的訂單量,能更真實地反映業務情況。
- 處理時間(Processing - Time):指數據在 Flink 算子中實際被處理的時間,即機器的系統時鐘時間。基于處理時間的處理具有較低的延遲,但由于不同機器的時鐘可能存在偏差,以及故障恢復等情況,可能導致結果的不一致性。例如在實時流量統計場景中,如果使用處理時間,統計結果會受到系統處理速度和機器時鐘的影響。
- 水位線(Watermark):是 Flink 中用于處理亂序事件的關鍵機制。它是一種特殊的事件,用于告知流處理引擎某個時間點之前的數據已經全部到達,從而可以觸發相關窗口操作的計算。例如在一個實時計算每 5 分鐘內訂單金額總和的任務中,如果設置了合適的水位線,即使訂單數據亂序到達,也能在水位線到達后準確計算出每個 5 分鐘窗口內的訂單金額總和。
- 攝入時間(Ingestion - Time):作為事件時間的特殊情況,它是事件進入 Flink 系統的時間。攝入時間在一定程度上平衡了事件時間的準確性和處理時間的低延遲特性。在一些對延遲有一定要求,同時又希望結果相對準確的場景中比較適用
4.2 有狀態流處理
雖然 Flink 的 DataStream API 中的大多數算子看似是無副作用的函數式算子,但它們為高效的有狀態計算提供支持。狀態對于許多應用至關重要,例如機器學習模型構建、圖分析、用戶會話處理以及窗口聚合。根據用例的不同,存在大量不同類型的狀態。例如,狀態可以簡單到像一個計數器或求和值,也可以更復雜,比如機器學習應用中常用的分類樹或大型稀疏矩陣。流窗口是有狀態算子,它將記錄分配到作為算子狀態一部分保存在內存中的持續更新的存儲桶中。
在 Flink 中,狀態通過以下方式被顯式化并整合到 API 中:i)提供算子接口或注解,以便在算子作用域內靜態注冊顯式局部變量;ii)提供算子狀態抽象,用于聲明分區的鍵值狀態及其相關操作。用戶還可以使用系統提供的 StateBackend 抽象來配置狀態的存儲和檢查點方式,從而在流應用中實現高度靈活的自定義狀態管理。Flink 的檢查點機制(在 3.3 節中討論)保證任何已注冊的狀態都是持久的,并具有精確一次更新語義。
關鍵詞拓展介紹:
- 有狀態流處理(Stateful Stream Processing):在流處理場景中,有狀態流處理指的是算子在處理數據流時,能夠記住之前處理過的數據的某些信息(即狀態),并基于這些狀態對新到來的數據進行處理。與無狀態算子(如簡單的 map 和 filter 算子,它們處理每個數據元素時不依賴之前元素的信息)不同,有狀態算子可以根據過去的數據做出更復雜的決策。例如在實時計算用戶活躍度時,算子需要記住每個用戶之前的活動記錄(狀態),以便計算當前的活躍度。
- StateBackend:Flink 中的 StateBackend 是一個重要的抽象概念,用于定義狀態如何存儲和管理。它主要有三種類型:MemoryStateBackend、FsStateBackend 和 RocksDBStateBackend。MemoryStateBackend 將狀態存儲在內存中,適合數據量較小且對性能要求極高的場景,但在發生故障時恢復能力有限。FsStateBackend 將狀態存儲在文件系統(如 HDFS)中,適合中等規模數據,具有較好的故障恢復能力。RocksDBStateBackend 則利用 RocksDB 這種嵌入式數據庫來存儲狀態,適用于大規模狀態存儲,并且在處理海量數據時能提供較好的性能和可靠性。用戶可以根據應用的需求選擇合適的 StateBackend 來優化狀態管理。
4.3 流窗口
對無界流的增量計算,常常是在不斷演變的邏輯視圖上進行評估的,這些邏輯視圖被稱作窗口。Apache Flink 在有狀態算子中融入了窗口機制,它通過一個由三個核心函數構成的靈活聲明來配置:一個窗口分配器,以及可選的一個觸發器和一個移除器。
這三個函數既可以從一組常見的預定義實現(例如滑動時間窗口)中選擇,也可以由用戶顯式定義(即用戶自定義函數)。
更具體地說,分配器負責將每條記錄分配到邏輯窗口。例如,在事件時間窗口的情況下,這一分配決策可以基于記錄的時間戳。請注意,在滑動窗口的情形下,一個元素可能屬于多個邏輯窗口。可選的觸發器定義了與窗口定義相關的操作何時執行。最后,可選的移除器決定每個窗口內保留哪些記錄。Flink 的窗口分配過程獨具優勢,能夠涵蓋所有已知的窗口類型,如周期性時間窗口和計數窗口、標點窗口、地標窗口、會話窗口和增量窗口。需要注意的是,Flink 的窗口功能能夠無縫處理亂序數據,與 Google Cloud Dataflow [3] 類似,并且原則上包含了這些窗口模型。例如,下面是一個窗口定義,窗口范圍為 6 秒,每 2 秒滑動一次(窗口分配器)。一旦水位線越過窗口末尾,就計算窗口結果(觸發器)。
stream.window(SlidingTimeWindows.of(Time.of(6, SECONDS), Time.of(2, SECONDS)).trigger(EventTimeTrigger.create())
全局窗口會創建單個邏輯組。下面的示例定義了一個全局窗口(即窗口分配器),每 1000 個事件調用一次操作(即觸發器),同時保留最后 100 個元素(即移除器)。
stream.window(GlobalWindow.create()).trigger(Count.of(1000)).evict(Count.of(100))
請注意,如果上述流在進行窗口操作之前按鍵分區,那么上述窗口操作就是局部的,因此無需在工作節點之間進行協調。這種機制可用于實現各種各樣的窗口功能 [3]。
關鍵詞拓展介紹:
- 窗口分配器(Window Assigner):它是決定數據記錄如何被分配到不同窗口的組件。除了示例中的滑動時間窗口分配器?
SlidingTimeWindows,還有滾動時間窗口分配器?TumblingTimeWindows,它將數據按照固定的時間長度切分成不重疊的窗口;會話窗口分配器?SessionWindows,會根據數據記錄的時間間隔來劃分窗口,如果間隔超過一定時間,則認為是新的會話窗口。不同的窗口分配器適用于不同的業務場景,比如在統計網站每小時的訪問量時,適合使用滾動時間窗口;而在分析用戶的一次連續操作行為時,會話窗口更為合適。- 觸發器(Trigger):用于確定窗口內的計算何時被觸發。除了示例中的事件時間觸發器?
EventTimeTrigger,還有處理時間觸發器?ProcessingTimeTrigger,它基于處理時間來觸發窗口計算;計數觸發器?CountTrigger,當窗口內的數據記錄數量達到設定值時觸發計算。選擇合適的觸發器能確保窗口計算在恰當的時機執行,滿足不同的業務需求,比如在實時監控系統中,可能希望每收集到一定數量的數據就進行一次計算,這時計數觸發器就比較適用。- 移除器(Evictor):它決定窗口內的數據記錄在何時被移除。在示例中使用的計數移除器?
CountEvictor,會按照設定的數量保留窗口內的記錄。還有時間移除器?TimeEvictor,可以根據數據記錄的時間戳來移除窗口內較早的數據。移除器可以幫助控制窗口內的數據量,避免內存占用過高,同時也能對窗口內的數據進行篩選,只保留對計算有價值的數據。- 全局窗口(GlobalWindow):全局窗口會將所有數據記錄分配到同一個窗口中。通常需要結合特定的觸發器和移除器來使用,因為如果沒有這些控制,窗口內的數據會持續累積。全局窗口在一些特殊場景下很有用,例如對整個數據流進行全局統計時,可以使用全局窗口結合合適的觸發器和移除器來實現。
4.4 異步流迭代
流中的循環對于多種應用至關重要,例如增量構建和訓練機器學習模型、強化學習以及圖近似計算 [9, 15]。在大多數此類情況下,反饋循環無需協調。異步迭代滿足了流應用程序的通信需求,并且與基于有限數據上結構化迭代的并行優化問題有所不同。如 3.4 節和圖 6 所示,當未啟用任何迭代控制機制時,Apache Flink 的執行模型已涵蓋異步迭代。此外,為符合容錯保證,反饋流在隱式迭代頭算子中被視為算子狀態,并且是全局快照的一部分 [7]。DataStream API 允許顯式定義反饋流,并且可以輕易地支持流上的結構化循環 [23] 以及進度跟蹤 [9]。
關鍵詞拓展介紹:
- 異步流迭代(Asynchronous Stream Iterations):在流計算場景下,它為一些需要循環處理數據的應用提供了有效的解決方案。例如在機器學習模型的增量訓練中,新的數據不斷流入,模型需要基于新數據不斷更新自身狀態。異步流迭代允許這種更新操作異步進行,不會阻塞整個流處理流程,提高了系統的處理效率和響應性。
- 反饋流(Feedback Streams):在異步流迭代中,反饋流起著關鍵作用。它攜帶了經過一輪處理后的結果數據,這些數據會被反饋到流處理的起始階段,參與下一輪的計算。比如在一個不斷優化推薦模型的流處理系統中,每次根據新用戶行為數據調整推薦模型后,模型生成的推薦結果(構成反饋流)會被送回與新的用戶行為數據一起,再次優化推薦模型。在 Flink 中,反饋流作為算子狀態的一部分,被納入全局快照,這保證了在出現故障時,系統能夠恢復到故障前的迭代狀態,繼續進行迭代計算,從而確保了容錯性。
5. 基于數據流的批處理分析
有界數據集是無界數據流的一種特殊情況。因此,一個將其所有輸入數據插入到一個窗口中的流處理程序可以構成一個批處理程序,并且上述 Flink 的特性應能完全涵蓋批處理。然而,其一,語法(即批處理計算的 API)可以簡化(例如,無需人為定義全局窗口);其二,處理有界數據集的程序適合進行額外的優化、更高效的容錯記錄管理以及分階段調度。
Flink 對批處理的處理方式如下:
- 批處理計算與流計算由相同的運行時執行。運行時可執行文件可以通過阻塞數據流進行參數化,以便將大型計算分解為依次調度的孤立階段。
- 當定期快照的開銷過高時,將其關閉。取而代之的是,通過從最新的物化中間流(可能是數據源)重放丟失的流分區來實現故障恢復。
- 阻塞算子(例如排序)僅僅是一些碰巧會阻塞直到消耗完其全部輸入的算子實現。運行時并不知道某個算子是否阻塞。這些算子使用 Flink 提供的托管內存(可以在 JVM 堆上或堆外),如果其輸入超出內存限制,則可以溢出到磁盤。
- 專門的 DataSet API 為批處理計算提供了常見的抽象,即有界且容錯的 DataSet 數據結構以及對 DataSet 的轉換操作(例如連接、聚合、迭代)。
- 查詢優化層將 DataSet 程序轉換為高效的可執行程序。
下面我們將更詳細地描述這些方面。
關鍵詞拓展介紹:
- 有界數據集與無界數據流關系:從概念上,有界數據集可以看作是在某個時間點數據停止流入的無界數據流。在 Flink 中基于這種關系,使得流處理的很多機制可以復用在批處理上。例如流處理中的窗口機制,在批處理場景下,可將整個有界數據集視為一個窗口數據來處理。
- 批處理運行時:與流計算共用運行時,這體現了 Flink 統一流批處理的設計理念。通過阻塞數據流參數化運行時可執行文件來分階段調度計算,這樣做可以更好地管理資源和控制計算流程。例如在處理大規模批數據時,將計算分成多個階段依次執行,避免一次性加載過多數據導致內存溢出等問題。
- 故障恢復策略:批處理中,當定期快照開銷大時,采用從最新物化中間流重放丟失流分區的方式恢復故障。物化中間流是在計算過程中,將某些中間結果數據持久化存儲下來,這樣在出現故障時,可以從這些持久化的數據重新開始計算,減少了重新計算的范圍,提高恢復效率。比如在一個多步驟的批處理作業中,中間步驟的結果被物化存儲,若后續步驟出現故障,可從物化的中間結果處重新啟動作業。
- 阻塞算子:像排序這樣的阻塞算子在 Flink 批處理中,會一直阻塞直到處理完所有輸入數據。Flink 提供的托管內存可用于這些算子的計算,并且支持內存溢出到磁盤,這使得即使處理超出內存容量的數據也能順利進行。例如在對一個非常大的數據集進行排序時,數據可能無法一次性全部加載到內存,此時算子可以將部分數據暫存到磁盤,分批處理完成排序操作。
- DataSet API:它是 Flink 為批處理專門設計的 API,提供了 DataSet 數據結構以及各種對 DataSet 的轉換操作。DataSet 數據結構是有界且容錯的,這意味著在批處理過程中,如果出現故障,能夠根據容錯機制恢復到之前的狀態繼續處理。例如在進行兩個大表的連接操作時,使用 DataSet API 可以方便地定義連接邏輯,并且不用擔心數據丟失或處理中斷等問題。
- 查詢優化層:這一層的作用是將用戶編寫的 DataSet 程序轉換為更高效的可執行程序。它會對程序中的算子操作進行分析和優化,例如對算子的執行順序進行調整、對數據的傳輸方式進行優化等,以提高批處理作業的執行效率。比如在一個包含多個聚合和連接操作的批處理作業中,查詢優化層可以根據數據的特點和操作的依賴關系,合理安排操作順序,減少數據傳輸和中間結果存儲的開銷。
5.1 查詢優化
Flink 的優化器基于并行數據庫系統的技術,如計劃等價、成本建模和有趣屬性傳播。然而,構成 Flink 數據流程序的、任意的、大量使用用戶定義函數(UDF)的有向無環圖(DAG),不允許傳統優化器直接應用數據庫技術 [17],因為算子向優化器隱藏了它們的語義。出于同樣的原因,基數估計和成本估算方法同樣難以應用。Flink 的運行時支持各種執行策略,包括重新分區和廣播數據傳輸,以及基于排序的分組和基于排序與哈希的連接實現。Flink 的優化器基于有趣屬性傳播的概念枚舉不同的物理計劃,使用基于成本的方法在多個物理計劃中進行選擇。成本包括網絡和磁盤 I/O 以及 CPU 成本。為了克服存在 UDF 時的基數估計問題,Flink 的優化器可以使用程序員提供的提示信息。
關鍵詞拓展介紹:
- 計劃等價(Plan Equivalence):在數據庫查詢優化中,計劃等價指不同的查詢執行計劃可以產生相同的結果。例如,對于一個簡單的查詢 “從表 A 和表 B 中選擇滿足特定條件的數據”,可能有多種連接順序(先連接 A 和 B,或者先對 A 進行過濾再與 B 連接等),這些不同的連接順序形成的執行計劃在結果上是等價的,但執行效率可能不同。Flink 優化器利用計劃等價的概念,嘗試找出執行效率最高的計劃。
- 成本建模(Cost Modeling):用于估算不同查詢執行計劃的成本。成本通常包括網絡傳輸數據的開銷(網絡 I/O)、讀寫磁盤數據的開銷(磁盤 I/O)以及 CPU 處理數據的開銷。通過對這些成本因素進行建模和估算,優化器可以比較不同物理計劃的成本,選擇成本最低的計劃來執行。例如,對于一個涉及大量數據從一個節點傳輸到另一個節點進行連接操作的計劃,其網絡 I/O 成本會比較高;而如果有一個計劃可以在本地節點通過磁盤緩存數據完成連接,磁盤 I/O 成本可能會高,但網絡 I/O 成本會降低,優化器通過成本建模來綜合評估哪種計劃更優。
- 有趣屬性傳播(Interesting - property Propagation):這里的有趣屬性可以是數據的某些特性,如數據的排序情況、數據的基數(大致的數據量)等。優化器在構建執行計劃時,會根據算子的輸入輸出數據的有趣屬性進行傳播和推導。例如,如果一個算子對輸入數據有排序要求,那么上游算子輸出數據如果已經是有序的(這就是一個有趣屬性),可以減少額外的排序操作,提高執行效率。優化器通過有趣屬性傳播,在不同的物理計劃中找到利用這些屬性來優化執行的方案。
- 基數估計(Cardinality Estimation):在查詢優化中,準確估計每個算子輸出數據的大致數量(基數)非常重要。因為這會影響到內存使用、數據傳輸量以及執行計劃的選擇等。例如,在連接操作中,如果能準確估計連接后的數據基數,就可以更好地分配內存和選擇合適的連接算法(如哈希連接適用于較小基數的數據等)。但在 Flink 中,由于 UDF 的存在,數據的處理邏輯變得復雜,難以準確估計基數。例如一個 UDF 可能根據復雜的業務邏輯對數據進行過濾或轉換,使得原始數據的基數變化難以預測。
5.2 內存管理
Flink 以數據庫技術為基礎,將數據序列化到內存段中,而非在 JVM 堆中分配對象來表示處于緩沖狀態的傳輸中的數據記錄。像排序和連接這類操作,盡可能直接對二進制數據進行處理,將序列化與反序列化的開銷降至最低,且在必要時將部分數據溢出到磁盤。為處理任意對象,Flink 使用類型推斷和自定義序列化機制。通過基于二進制表示及堆外內存進行數據處理,Flink 成功降低了垃圾回收開銷,還采用了緩存高效且穩健的算法,這些算法在內存壓力下也能平穩擴展。
關鍵詞拓展介紹:
- 內存段(Memory Segments):Flink 中的內存段是一種低層級的內存分配單元,它獨立于 JVM 堆內存。這意味著內存段不受 JVM 垃圾回收機制的常規影響,極大減少了因垃圾回收導致的性能抖動。例如,在執行大規模數據集的排序操作時,數據可直接存儲在內存段中,排序操作直接在這些內存段上執行,避免了因在 JVM 堆中頻繁創建和銷毀對象而引發的大量垃圾回收活動。
- 序列化(Serialization):將對象轉換為二進制數據流的過程。在 Flink 中,數據在進入內存段存儲或在網絡中傳輸前,會進行序列化。這樣做的好處是,二進制數據占用空間通常比對象在內存中的表示形式更小,且更利于直接在內存段上進行處理。例如,一個包含復雜對象的數據集在進行網絡傳輸時,序列化后的數據能以更緊湊的形式傳輸,減少網絡帶寬占用。
- 反序列化(Deserialization):與序列化相反,是將二進制數據流恢復為對象的過程。當數據從內存段中取出用于進一步處理,或在接收端接收到序列化數據后,需要進行反序列化。在 Flink 中,盡量減少序列化和反序列化的開銷是提高性能的關鍵,因為這兩個過程通常比較耗時。例如,對于頻繁處理的數據,如在一個持續運行的流處理作業中,減少不必要的序列化和反序列化操作,能顯著提升系統整體性能。
- 類型推斷(Type Inference):Flink 通過分析數據的使用方式或上下文來自動確定數據類型的機制。這在處理任意對象時非常有用,因為它無需程序員顯式指定所有數據類型,減少了編程工作量,同時也能更好地適配不同類型的數據。例如,在處理一個包含多種數據類型的輸入流時,Flink 可以根據流中數據的初始幾個記錄推斷出數據類型,從而選擇合適的序列化和處理方式。
- 自定義序列化機制(Custom Serialization Mechanisms):Flink 允許用戶根據自身需求定義特定的序列化方式。這在處理一些復雜對象或不常見數據類型時特別有用。例如,對于一些包含自定義數據結構或加密數據的對象,默認的序列化方式可能不適用,用戶可以通過實現自定義序列化機制,確保這些對象能正確地序列化和反序列化,同時也可以優化序列化過程以滿足性能需求。
5.3 批處理迭代
過去,迭代圖分析、并行梯度下降和優化技術等已在批量同步并行(Bulk Synchronous Parallel,BSP)和陳舊同步并行(Stale Synchronous Parallel,SSP)等模型的基礎上得以實現。
Flink 的執行模型通過使用迭代控制事件,允許在其之上實現任何類型的結構化迭代邏輯。例如,在 BSP 執行的情況下,迭代控制事件標記著迭代計算中超級步(superstep)的開始和結束。最后,Flink 引入了進一步新穎的優化技術,如增量迭代(delta iterations)的概念 [14],該技術可以利用稀疏計算依賴關系。Flink 的圖 API Gelly 已經在使用增量迭代技術。
關鍵詞拓展介紹:
- 批量同步并行(Bulk Synchronous Parallel,BSP)模型:一種并行計算模型,它將計算過程劃分為一系列的超級步(superstep)。在每個超級步中,所有處理器并行執行本地計算,然后進行全局同步,交換數據。這種模型的優點是簡單、易于理解和編程,適用于許多需要全局同步的算法,如迭代圖分析算法。例如,在 PageRank 算法中,可以在每個超級步中計算節點的 PageRank 值,并在同步階段交換信息以更新下一輪計算的值。
- 陳舊同步并行(Stale Synchronous Parallel,SSP)模型:對 BSP 模型的一種改進,在 SSP 模型中,處理器之間的同步不必是嚴格一致的。某些處理器可以使用稍微陳舊的數據進行計算,而不是等待所有處理器都完成上一步計算并同步數據。這種模型在處理大規模數據和分布式計算時,可以減少同步帶來的等待時間,提高計算效率,特別適用于對數據一致性要求不是特別嚴格的算法,如一些機器學習中的梯度下降算法,在一定程度上允許陳舊數據不會顯著影響最終結果的收斂。
- 迭代控制事件(Iteration - control events):Flink 中用于控制迭代邏輯的事件機制。通過這些事件,可以明確標記迭代的開始、結束以及其他關鍵階段,使得任何類型的結構化迭代邏輯能夠基于 Flink 執行模型順利實現。例如,在實現迭代圖分析算法時,可以利用迭代控制事件來管理每一輪迭代中節點數據的更新和同步操作,確保算法按照預期的迭代步驟執行。
- 增量迭代(Delta Iterations):Flink 引入的一種優化技術,它利用稀疏計算依賴關系。在某些迭代計算中,并不是每次迭代都需要對所有數據進行完整計算,可能只有部分數據的變化會影響到下一次迭代的結果。增量迭代技術專注于這些發生變化的數據(即增量部分)進行計算,從而減少不必要的計算量,提高計算效率。在圖計算場景中,如果只有少數節點的屬性發生變化,增量迭代可以只針對這些節點及其相關聯的邊進行計算,而不是對整個圖進行全面計算。
- Gelly:Flink 的圖計算 API,它提供了一系列用于圖分析和處理的工具和算法。Gelly 基于 Flink 的執行模型,支持各種圖算法的實現,并且已經應用了增量迭代等優化技術,幫助用戶高效地處理大規模圖數據。例如,用戶可以使用 Gelly 輕松實現如最短路徑算法、社區發現算法等常見的圖分析任務。
6. 相關工作
如今,有大量用于分布式批處理和流分析處理的引擎。我們在下面對主要系統進行分類。
- 批處理:Apache Hadoop 是基于 MapReduce 范式進行大規模數據分析的最受歡迎的開源系統之一 [12]。Dryad [18] 在基于通用有向無環圖(DAG)的數據流中引入了嵌入式用戶定義函數,并且由 SCOPE [26] 進行了擴展,SCOPE 是基于 Dryad 的一種語言和 SQL 優化器。Apache Tez [24] 可以看作是 Dryad 中所提理念的開源實現。大規模并行處理(MPP)數據庫 [13],以及像 Apache Drill 和 Impala [19] 這樣的最新開源實現,將其應用程序編程接口(API)限制為 SQL 變體。與 Flink 類似,Apache Spark [25] 是一個數據處理框架,它實現了基于有向無環圖(DAG)的執行引擎,提供 SQL 優化器,執行基于驅動程序的迭代,并將無界計算視為微批處理。相比之下,Flink 是唯一結合了以下幾點的系統:(i)一個分布式數據流運行時,它利用流水線式流執行來處理批處理和流工作負載;(ii)通過輕量級檢查點實現精確一次的狀態一致性;(iii)原生迭代處理;(iv)復雜的窗口語義,支持亂序處理。
- 流處理:在學術和商業流處理系統方面已有大量前期工作,如 SEEP、Naiad、微軟 StreamInsight 和 IBM Streams。這些系統中的許多都基于數據庫領域的研究 [1, 5, 8, 10, 16, 22, 23]。上述大多數系統要么(i)是學術原型,要么(ii)是閉源商業產品,要么(iii)無法在商用服務器集群上進行橫向擴展計算。數據流方面的最新方法實現了橫向可擴展性和組合數據流操作符,但狀態一致性保證較弱(例如,Apache Storm 和 Samza 中的至少一次處理)。值得注意的是,諸如 “亂序處理”(OOP)[20] 等概念受到了極大關注,并被 MillWheel [2] 采用,MillWheel 是谷歌內部版本,后來成為 Apache Beam / Google Dataflow [3] 的商業執行器。MillWheel 作為精確一次低延遲流處理和亂序處理概念的驗證,因此對 Flink 的發展產生了很大影響。據我們所知,Flink 是唯一滿足以下幾點的開源項目:(i)支持事件時間和亂序事件處理;(ii)提供具有精確一次保證的一致性托管狀態;(iii)實現高吞吐量和低延遲,同時適用于批處理和流處理。
關鍵詞拓展介紹:
- MapReduce 范式:一種編程模型和相關實現,用于在大型集群上處理海量數據。它將數據處理過程分為兩個主要階段:Map(映射)階段和 Reduce(歸約)階段。在 Map 階段,輸入數據被分割成多個小塊,每個小塊由一個 Map 任務處理,生成一系列鍵值對。在 Reduce 階段,具有相同鍵的所有值被收集到一起,并由 Reduce 任務進行合并或聚合操作。例如,在統計文本文件中每個單詞出現次數的任務中,Map 階段可以將每個單詞映射為鍵值對(單詞,1),Reduce 階段將相同單詞的計數進行累加。
- 有向無環圖(Directed Acyclic Graph, DAG):在數據處理中,DAG 常用于描述任務之間的依賴關系。圖中的節點表示任務,邊表示任務之間的數據流動方向,并且不存在環,即任務之間的依賴關系不會形成循環引用。例如,在一個復雜的數據處理流程中,可能有數據讀取、清洗、轉換、聚合等多個任務,這些任務之間的先后順序和數據流向可以用 DAG 來清晰表示,以確保任務按照正確的順序執行,避免出現死循環或不合理的依賴。
- 輕量級檢查點(Lightweight Checkpointing):Flink 中用于實現精確一次狀態一致性的重要機制。它通過定期記錄任務的狀態信息,在發生故障時能夠快速恢復到故障前的狀態,而不會丟失或重復處理數據。輕量級意味著這種檢查點機制在記錄狀態時盡量減少對正常處理流程的影響,開銷相對較小。例如,在一個長時間運行的流處理作業中,可能每間隔一定時間或處理一定數量的數據后進行一次輕量級檢查點操作,這樣當系統出現故障重啟后,可以從最近的檢查點處繼續處理,保證數據處理的準確性和連續性。
- 亂序處理(Out-of-order Processing, OOP):在流處理中,數據到達系統的順序可能與它們實際發生的順序不一致,亂序處理就是指系統能夠正確處理這種情況的能力。比如在處理物聯網設備產生的傳感器數據時,由于網絡延遲等原因,較晚發生的事件數據可能會比早期發生的事件數據晚到達處理系統。支持亂序處理的系統能夠根據事件自身攜帶的時間戳(如事件時間),在一定的時間窗口內等待遲到的數據,從而正確地對數據進行排序和處理,保證結果的準確性。
- Apache Storm:一個開源的分布式實時計算系統,主要用于處理高吞吐量的數據流。它能夠在集群環境中快速處理大量的實時數據,具有高容錯性。Storm 采用 “至少一次” 的處理語義,意味著在處理過程中數據可能會被重復處理,但能保證數據不會丟失。例如,在實時分析社交媒體數據的場景中,Storm 可以快速地對大量的推文進行實時處理,如情感分析、關鍵詞提取等。
- Apache Samza:同樣是一個分布式流處理框架,它構建在 Kafka 之上,利用 Kafka 的消息隊列特性來實現數據的可靠傳輸和存儲。Samza 也采用 “至少一次” 的處理語義,適用于需要處理大規模流數據的應用場景,如實時日志分析等。它支持水平擴展,能夠在集群中動態增加或減少處理節點,以適應不同的數據負載。
- Apache Beam / Google Dataflow:Apache Beam 是一個統一的編程模型,用于定義批處理和流處理作業,它可以在不同的執行引擎上運行,如 Apache Flink 和 Google Cloud Dataflow。Google Dataflow 是 Google 基于 Apache Beam 模型提供的云數據處理服務。通過 Beam,開發者可以使用統一的編程接口編寫代碼,而無需關心底層具體的執行引擎細節,提高了代碼的可移植性和復用性。例如,開發者可以編寫一個數據處理作業,既可以在本地使用 Flink 執行,也可以部署到 Google Cloud 上使用 Dataflow 執行。
- MillWheel:Google 開發的流處理系統,它為精確一次低延遲流處理和亂序處理概念提供了實踐驗證。MillWheel 在處理大規模流數據時,能夠保證數據僅被處理一次,同時實現較低的處理延遲,并且有效地處理亂序到達的數據。它的設計理念和技術實現對后來的流處理系統,如 Flink,產生了重要的影響,許多概念和技術被 Flink 借鑒和采用。
8. 結論
在本文中,我們介紹了 Apache Flink,這是一個實現了通用數據流引擎的平臺,旨在執行流分析和批分析。Flink 的數據流引擎將算子狀態和邏輯中間結果視為一等公民,并被具有不同參數的批處理和數據流應用程序編程接口(API)所使用。構建在 Flink 流數據流引擎之上的流 API 提供了保存可恢復狀態以及對數據流窗口進行分區、轉換和聚合的方法。雖然從理論上講,批處理計算是流計算的一種特殊情況,但 Flink 對其進行了特殊處理,通過使用查詢優化器優化其執行,并通過實現阻塞算子,在內存不足時優雅地溢出到磁盤。
參考文獻
[1] D. J. Abadi, Y. Ahmad, M. Balazinska, U. Cetintemel, M. Cherniack, J.-H. Hwang, W. Lindner, A. Maskey, A. Rasin,E. Ryvkina, et al. The design of the Borealis stream processing engine. CIDR, 2005.
[2] T. Akidau, A. Balikov, K. Bekiroglu, S. Chernyak, J. Haberman, R. Lax, S. McVeety, D. Mills, P. Nordstrom, and S. Whittle. Millwheel: fault-tolerant stream processing at Internet scale. PVLDB, 2013.
[3] T. Akidau, R. Bradshaw, C. Chambers, S. Chernyak, R. J. Fernandez-Moctezuma, R. Lax, S. McVeety, D. Mills, F. Perry, E. Schmidt, et al. The dataflow model: a practical approach to balancing correctness, latency, and cost in massive-scale, unbounded, out-of-order data processing. PVLDB, 2015.
[4] A. Alexandrov, R. Bergmann, S. Ewen, J.-C. Freytag, F. Hueske, A. Heise, O. Kao, M. Leich, U. Leser, V. Markl, F. Naumann, M. Peters, A. Rheinlaender, M. J. Sax, S. Schelter, M. Hoeger, K. Tzoumas, and D. Warneke. The stratosphere platform for big data analytics. VLDB Journal, 2014.
[5] A. Arasu, B. Babcock, S. Babu, J. Cieslewicz, M. Datar, K. Ito, R. Motwani, U. Srivastava, and J. Widom. Stream: The stanford data stream management system. Technical Report, 2004.
[6] Y. Bu, B. Howe, M. Balazinska, and M. D. Ernst. HaLoop: Efficient Iterative Data Processing on Large Clusters. PVLDB, 2010.
[7] P. Carbone, G. Fora, S. Ewen, S. Haridi, and K. Tzoumas. Lightweight asynchronous snapshots for distributed dataflows. arXiv:1506.08603, 2015.
[8] B. Chandramouli, J. Goldstein, M. Barnett, R. DeLine, D. Fisher, J. C. Platt, J. F. Terwilliger, and J. Wernsing. Trill: a high-performance incremental query processor for diverse analytics. PVLDB, 2014.
[9] B. Chandramouli, J. Goldstein, and D. Maier. On-the-fly progress detection in iterative stream queries. PVLDB, 2009.
[10] S. Chandrasekaran and M. J. Franklin. Psoup: a system for streaming queries over streaming data. VLDB Journal, 2003.
[11] K. M. Chandy and L. Lamport. Distributed snapshots: determining global states of distributed systems. ACM TOCS,1985.
[12] J. Dean et al. MapReduce: simplified data processing on large clusters. Communications of the ACM, 2008.
[13] D. J. DeWitt, S. Ghandeharizadeh, D. Schneider, A. Bricker, H.-I. Hsiao, R. Rasmussen, et al. The gamma database machine project. IEEE TKDE, 1990.
[14] S. Ewen, K. Tzoumas, M. Kaufmann, and V. Markl. Spinning Fast Iterative Data Flows. PVLDB, 2012.
[15] J. Feigenbaum, S. Kannan, A. McGregor, S. Suri, and J. Zhang. On graph problems in a semi-streaming model.Theoretical Computer Science, 2005.
[16] B. Gedik, H. Andrade, K.-L. Wu, P. S. Yu, and M. Doo. Spade: the system s declarative stream processing engine. ACM SIGMOD, 2008.
[17] F. Hueske, M. Peters, M. J. Sax, A. Rheinlander, R. Bergmann, A. Krettek, and K. Tzoumas. Opening the Black Boxes in Data Flow Optimization. PVLDB, 2012.
[18] M. Isard, M. Budiu, Y. Yu, A. Birrell, and D. Fetterly. Dryad: distributed data-parallel programs from sequential building blocks. ACM SIGOPS, 2007.
[19] M. Kornacker, A. Behm, V. Bittorf, T. Bobrovytsky, C. Ching, A. Choi, J. Erickson, M. Grund, D. Hecht, M. Jacobs, et al. Impala: A modern, open-source sql engine for hadoop. CIDR, 2015.
[20] J. Li, K. Tufte, V. Shkapenyuk, V. Papadimos, T. Johnson, and D. Maier. Out-of-order processing: a new architecture for high-performance stream systems. PVLDB, 2008.
[21] N. Marz and J. Warren. Big Data: Principles and best practices of scalable realtime data systems. Manning Publications Co., 2015.
[22] M. Migliavacca, D. Eyers, J. Bacon, Y. Papagiannis, B. Shand, and P. Pietzuch. Seep: scalable and elastic event processing. ACM Middleware’10 Posters and Demos Track, 2010.
[23] D. G. Murray, F. McSherry, R. Isaacs, M. Isard, P. Barham, and M. Abadi. Naiad: a timely dataflow system. ACM SOSP, 2013.
[24] B. Saha, H. Shah, S. Seth, G. Vijayaraghavan, A. Murthy, and C. Curino. Apache tez: A unifying framework for modeling and building data processing applications. ACM SIGMOD, 2015.
[25] M. Zaharia, M. Chowdhury, M. J. Franklin, S. Shenker, and I. Stoica. Spark: Cluster Computing with Working Sets. USENIX HotCloud, 2010.
[26] J. Zhou, P.-A. Larson, and R. Chaiken. Incorporating partitioning and parallel plans into the scope optimizer. IEEE ICDE, 2010.


)







技術的實例)
編寫單元測試)
文件存儲服務S3 介紹使用代碼集成)


 是誰提出的)

)

