2025-04-18 , 由浙江大學、哈爾濱工業大學、郴州市第一人民醫院、新加坡國立大學等機構合作創建了 Eyecare-100K數據集,這是首個涵蓋多種模態、任務和疾病的高質量眼科視覺指令數據集,為眼科智能診斷領域提供了關鍵資源,推動了醫學視覺語言模型(Med-LVLMs)在眼科的精細化理解與應用。
一、研究背景
醫學大型視覺語言模型(Med-LVLMs)在醫療領域展現出巨大潛力,但在眼科智能診斷方面,由于依賴于一般醫療數據和粗粒度的全局視覺理解,其表現受到限制。
目前遇到困難和挑戰:
1、數據方面:缺乏深度標注、高質量、多模態的眼科視覺指令數據。
2、基準測試方面:缺少全面系統的基準測試,無法準確評估 Med-LVLMs 在眼科診斷任務上的表現。
3、模型方面:現有模型架構難以適應眼科病變識別所需的細粒度、區域特定的視覺理解。
數據集地址:Eyecare-100K|眼科圖像分析數據集|疾病診斷數據集
二、 讓我們一起來看一下Eyecare-100K數據集
Eyecare-100K 是一個包含約 10.2 萬對視覺問答(VQA)的高質量眼科視覺指令數據集,覆蓋 8 種成像模態、15 種以上解剖結構和 100 多種眼病。
Eyecare-100K 集成了來自 13 個公共數據集、3 家醫院和 3 個公共醫學案例庫的 58485 張眼科圖像。它涵蓋了熒光素血管造影(FA)、吲哚青綠血管造影(ICGA)、光學相干斷層掃描(OCT)、眼底攝影、超聲生物顯微鏡(UBM)、裂隙燈、熒光素染色成像和計算機斷層掃描(CT)等 8 種成像模態,跨越 15 種解剖結構和 100 多種眼科疾病及罕見病癥,極大地增強了數據集的多樣性和全面性。
數據集構建:
構建過程中,開發了一個多智能體數據引擎,用于從大規模原始數據中提取、清理、標準化信息,并進行專家審核。該引擎包含信息提取器、醫療案例收集器、數據清洗器、問答模板庫、問答生成器和基于人類偏好的審核器等 6 個組件,最終將數據組織成封閉問答(多項選擇題)、開放問答(簡答題)和報告生成(長文本回答)三種類型的 VQA 任務。
數據集特點:
1、多模態:涵蓋多種成像模態,如 FA、ICGA、OCT 等。
2、多任務:支持封閉問答、開放問答和報告生成等多種任務。
3、高質量標注:經過專家審核,確保標注的準確性和標準化。
4、大規模:包含約 10.2 萬對視覺問答,數據量豐富。
基準測試:
基于 Eyecare-100K 構建的 Eyecare-Bench 基準測試,包含約 1.5 萬個測試樣本,覆蓋多種任務、模態和疾病類別。在該基準測試中,EyecareGPT 模型取得了平均準確率 84.56% 的最佳性能,顯著優于其他模型,驗證了數據集的有效性和模型的優越性。

Eyecare-100K 概述。Eyecare-100K 匯集了來自 8 個模態、15 個以上解剖結構和 100 個以上眼科疾病的真實世界眼科數據,支持多模態報告生成和精細視覺問答任務。
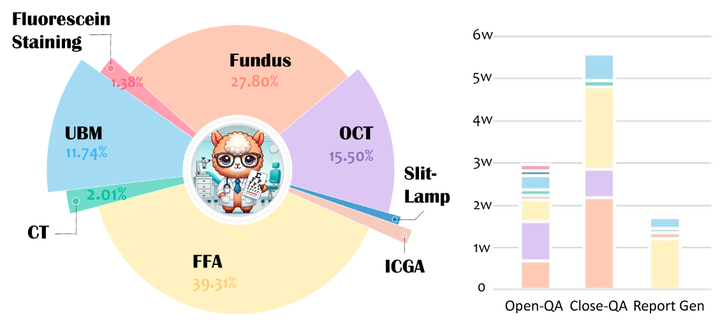
Eyecare-100K 數據統計
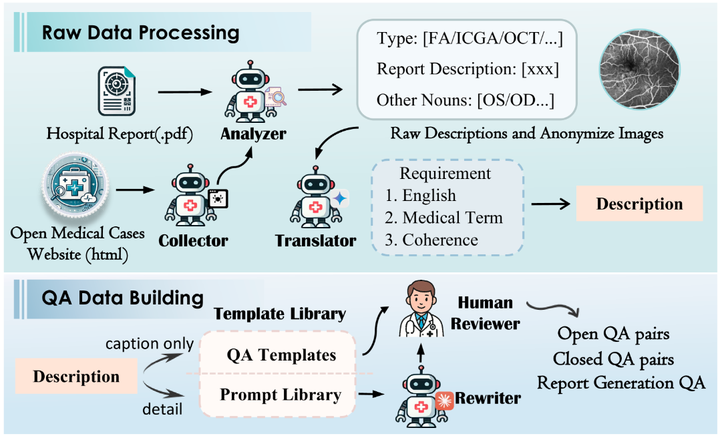
多智能體數據引擎框架
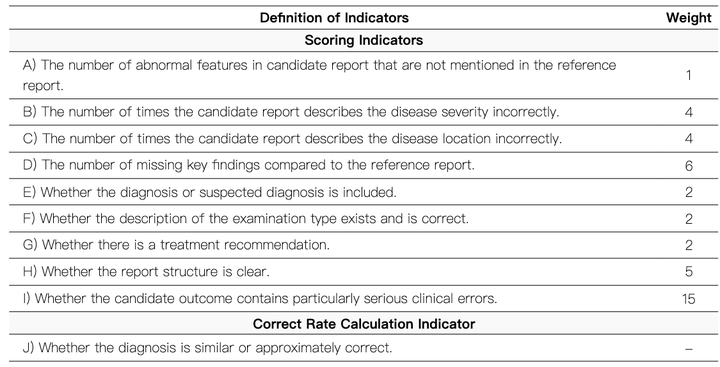
十項評估框架
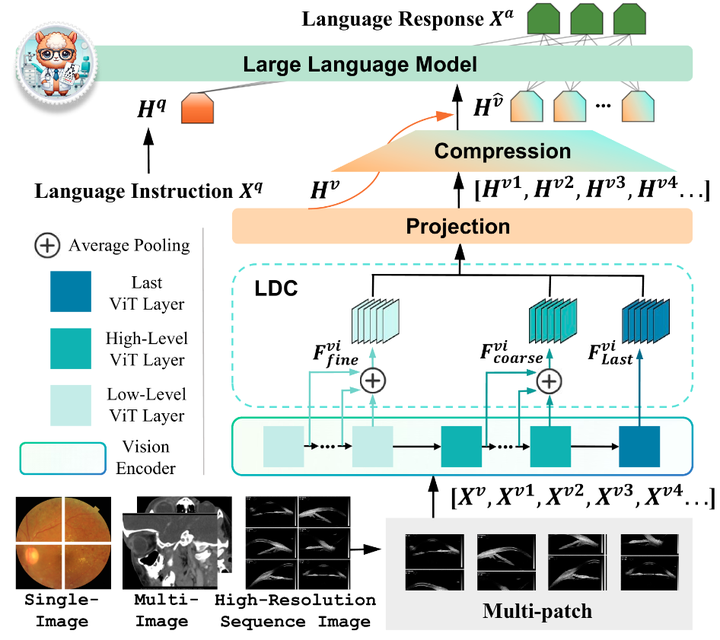
EyecareGPT 的模型架構
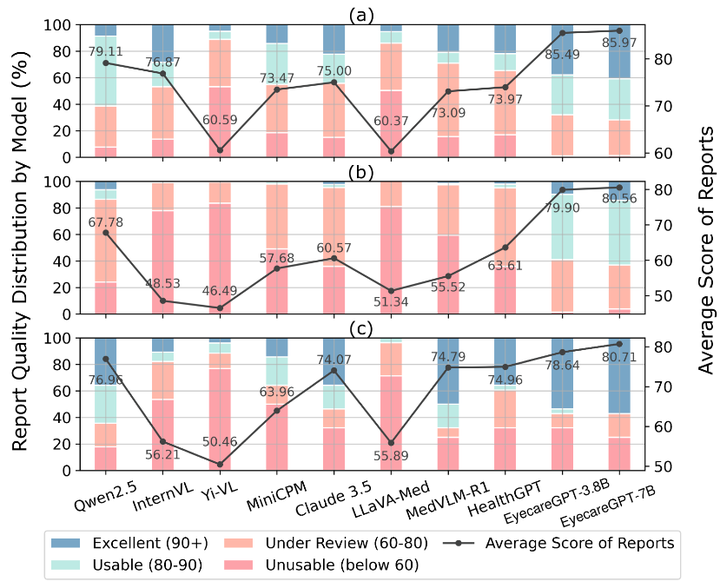
基于 GPT-4 在報告生成任務中評估結果,包括(a)FA,(b)UBM 和(c)CT 模態。
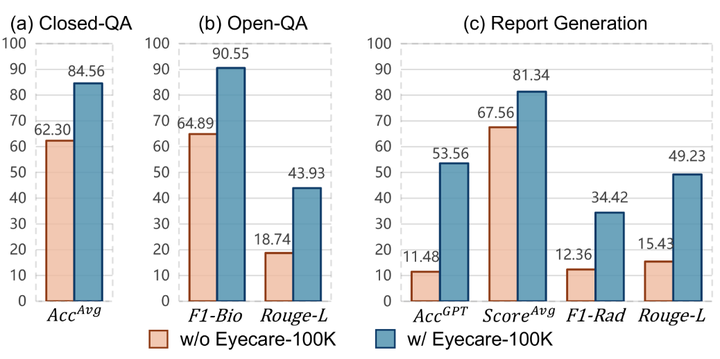
在 Eyecare-100K 上進行微調后的結果。
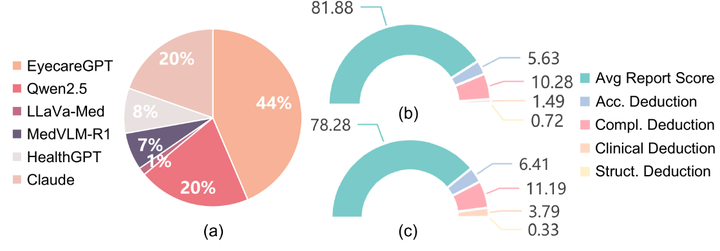
醫生對生成的報告(a)和 EyeEval 可靠性(b、c)的偏好
三、展望Eyecare-100K數據集
以前,醫生診斷糖尿病視網膜病變主要依靠人工檢查眼底照片。這個過程非常耗時,因為醫生需要仔細觀察每一張照片,尋找微血管瘤、出血、滲出物等病變特征。而且,由于人眼的局限性,有時候一些細微的病變可能被遺漏,導致診斷不夠準確。對于大規模的篩查項目來說,這種方式效率低下,很難快速處理大量患者的數據。
現在借助 Eyecare-100K 數據集,那可就不一樣了
這個數據集包含了大量高質量、多模態的眼科圖像以及深度標注信息,涵蓋了多種眼病,包括糖尿病視網膜病變。研究人員利用這個數據集訓練出了更精準的醫學視覺語言模型(如 EyecareGPT),這些模型能夠自動識別眼底照片中的病變特征。
診斷效率大幅提升:模型可以在短時間內處理大量圖像,快速篩查出高風險患者,大大節省了醫生的時間。比如,在一些眼科智能診療中心,患者可以在更近的醫療機構完成眼底檢查,智能系統能夠快速給出初步診斷結果,縮短了患者的等待時間。
診斷準確性提高:由于數據集的標注非常詳細,模型學習到了更豐富的病變特征和診斷知識,能夠更準確地識別病變。這有助于早期發現糖尿病視網膜病變,及時進行干預,減少因延誤治療導致的視力損害。
個性化醫療體驗:基于 Eyecare-100K 訓練的模型還可以生成詳細的診斷報告,為醫生提供更全面的參考信息,幫助制定個性化的治療方案。
更多免費的數據集,請打開:遇見數據集
遇見數據集-讓每個數據集都被發現,讓每一次遇見都有價值。遇見數據集,領先的千萬級數據集搜索引擎,實時追蹤全球數據集,助力把握數據要素市場。![]() https://www.selectdataset.com/
https://www.selectdataset.com/

![[FPGA基礎] RAM篇](http://pic.xiahunao.cn/[FPGA基礎] RAM篇)







)


)
)

)
)


