25年3月來自上海交大、上海AI實驗室、同濟大學和MAGIC的論文“ChatBEV: A Visual Language Model that Understands BEV Maps”。
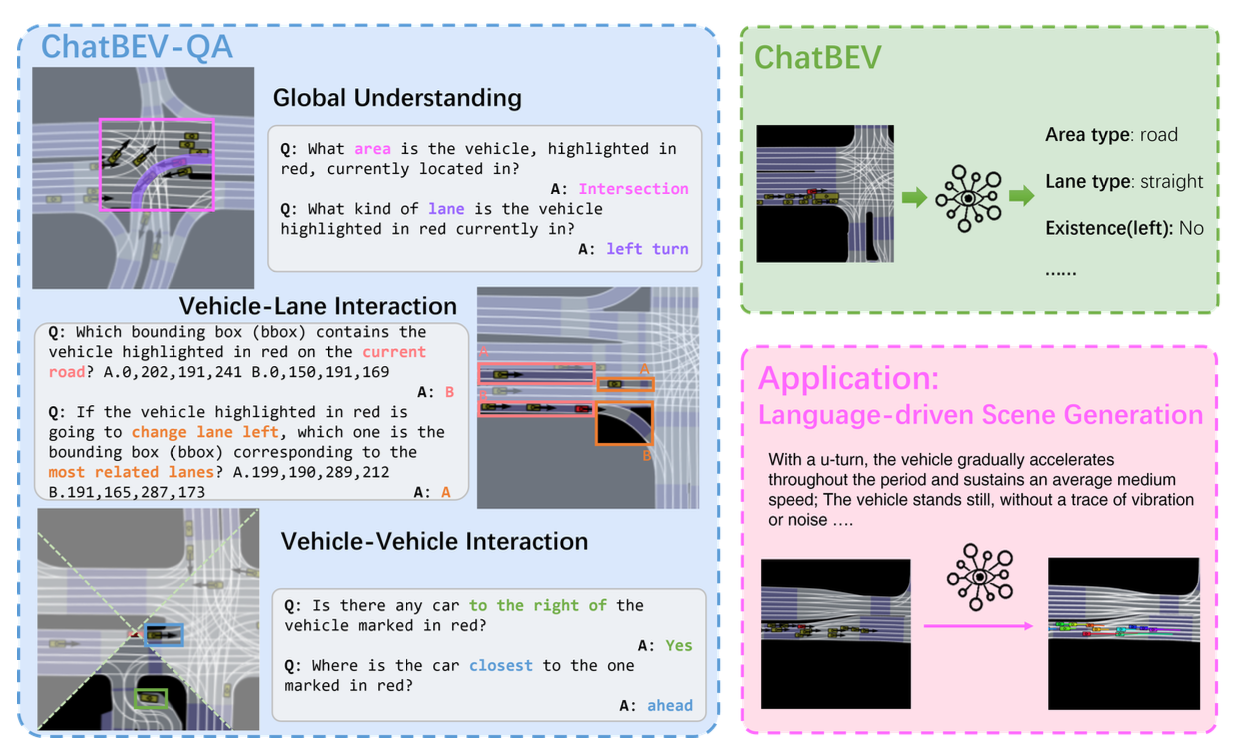
交通場景理解對于智能交通系統和自動駕駛至關重要,可確保車輛安全高效地運行。雖然 VLM 的最新進展已顯示出整體場景理解的前景,但 VLM 在交通場景中的應用(尤其是使用 BEV 地圖)仍未得到充分探索。現有方法通常受任務設計和數據量限制的影響,從而阻礙全面的場景理解。為了應對這些挑戰,推出 ChatBEV-QA,這是一個BEV VQA 基準,包含超過 137,000 個問題,旨在涵蓋廣泛的場景理解任務,包括全局場景理解、車輛-車道交互和車輛-車輛交互。該基準使用數據收集流水線構建,為 BEV 地圖生成可擴展且信息豐富的 VQA 數據。進一步微調專門的視覺語言模型 ChatBEV,使其能夠解釋不同的問題提示并從 BEV 地圖中提取相關的上下文-覺察信息。此外,提出一種語言驅動的交通場景生成流程,其中 ChatBEV 有助于地圖理解和文本對齊的導航指導,顯著增強真實一致的交通場景的生成。
如圖所示ChatBEV-QA和以此微調的ChatBEV模型:
自動化數據構建流程
本文提出一個三步自動化流程,用于從 nuPlan [7] 數據集生成 ChatBEV-QA 數據,如圖 a 所示。首先,設計各種問題以涵蓋全面理解任務。然后,提取必要的注釋并生成信息豐富的 BEV 地圖。最后,VQA 生成器根據問題、注釋和 BEV 地圖創建 VQA 數據。
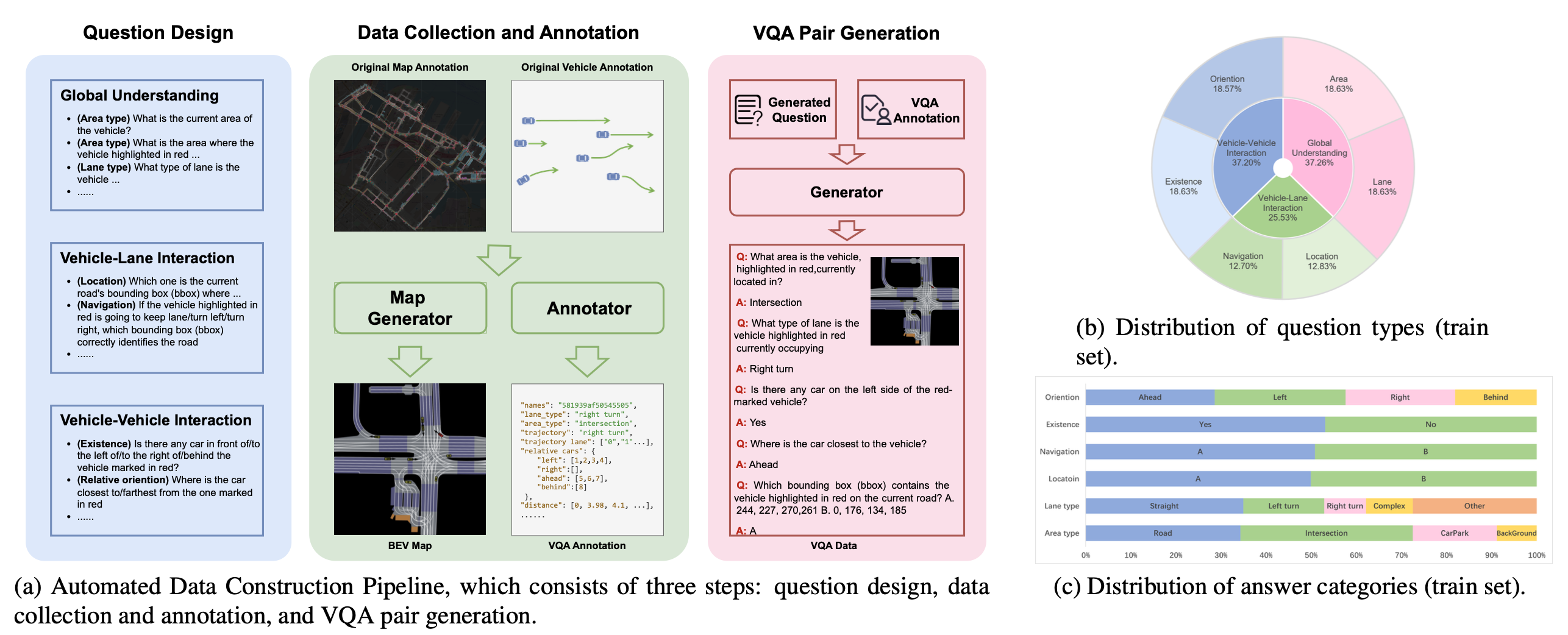
步驟 1:問題設計。從三個方面獲得全面理解,并據此進一步開發六種不同類型的問題:
全局理解:識別更廣泛的環境背景對于預測車輛行為至關重要。不同的場景會產生不同的運動模式,例如,交叉路口的車輛更有可能轉彎,而停車場的車輛則傾向于保持靜止。為了捕捉這些上下文信息,引入兩個關鍵問題:區域類型(用于對周圍環境進行分類,例如交叉路口、停車場)和車道類型(用于指定車道類別,例如直行、左轉),從而有助于更精確地預測車輛行為。
車-車道交互:近期研究經常忽略車-車道交互,而車-車道交互對于響應道路特征、交通規則和環境因素的自適應導航至關重要。為了增強該領域的推理能力,引入兩個關鍵方面:位置(用于識別車輛占用的精確車道)和導航(根據左轉或直行等特定引導確定最相關的車道)。這些考慮因素有助于實現更明智的軌跡預測和穩健的場景理解。
車-車交互:車-車交互對于空間關系建模至關重要,直接影響行為協調。為了評估這些相互作用,引入兩個關鍵方面:存在性(確定特定方向上附近車輛的存在)和相對方向(評估最近和最遠車輛的方向)。這些考慮因素增強了對交通動態的理解,并改進了預測模型。
這些問題提供了一個結構化的框架,用于理解場景中車輛行為和相互作用的各個維度。為了增加多樣性,為每種問題類型設計多個模板。
步驟 2:數據收集和注釋。nuPlan 的原始注釋涵蓋車輛位置、速度和車道細節等基本信息。增強數據集,并設計一個標注器,它具有廣泛的基于規則函數,可以提取高級語義信息并適用于所設計的問題。通過一個迭代的人工參與審查過程,嚴格改進函數的設計,以確保其輸出與人類判斷緊密一致。對于場景中每個時間步的每輛車,利用包含以下字段的設計函數生成 JSON 格式的輸出:1). 區域類型,指示車輛當前所處的區域類型;2). 車道類型,指定車輛當前所處車道的類型;3). 軌跡,描述接下來 50 個時間步長內與車輛軌跡對應的類別;4). 軌跡車道,捕獲接下來 50 幀內與軌跡對應的所有車道 ID。5). 相關車輛,存儲位于車輛周圍四個方向上的其他車輛的 ID;6). 距離,計算當前車輛與場景中所有其他車輛之間的距離,如上圖 a 的第二部分所示。
然后,根據 nuPlan 的原始地圖和軌跡注釋為每個場景中的每輛車生成 BEV 地圖,坐標原點放在本車的位置。感興趣的車輛以紅色突出顯示以引起注意,箭頭指示其運動方向。生成的 BEV 地圖清楚地標記車道邊界和區域劃分,為車輛與車道交互和整體理解提供必要的信息。
步驟 3:VQA 對生成。有了問題模板和注釋,可以通過 VQA 生成器生成問答對。對于車道類型和區域類型的問題,生成器隨機選擇一個模板并使用相應的注釋文本作為答案。對于位置和導航問題,通過提供多項選擇題來簡化問題。具體來說,提供兩個邊框:一個正確,一個來自非重疊車道的干擾項。位置問題的正確答案,是當前車道的地面真值邊框,而對于導航問題,用真值軌跡類型作為問題提示,正確答案對應于與真值實軌跡相關的車道邊框。對于存在性和相對方向性問題,生成器首先選擇一個方向,然后根據空間關系標注得出答案。
原始 nuPlan 數據集呈現長尾分布,例如直車道上車輛數量較多,而轉彎車道上車輛相對較少,這導致答案類別分布不平衡,可能會使模型性能偏向更常見的場景。為了緩解這個問題,采用一種隨機欠采樣技術,在數據集構建過程中選擇性地從占多數的類別中移除一定比例的樣本,從而促進更均衡的分布。
數據集統計數據和指標
由于整個 nuPlan 數據集非常龐大,從 nuPlan-mini 拆分中構建數據,從而提供更小、更易于管理的子集。總體而言,ChatBEV-QA 包含 25331 張 BEV 圖像的 137818 個問答對,其中 21634 張 BEV 圖像上有 116112 個問題用于訓練,3697 張 BEV 圖像上有 21706 個問題用于測試,平均每張圖像約有 5.44 個問題。上圖 b 和上圖 c 分別顯示訓練集上每個問題的問題類型和答案分布,突出顯示 ChatBEV-QA 的均衡組成。此外,設計的自動化數據創建流程允許無縫擴展到完整的 nuPlan 數據集,從而有助于獲取更多數據用于未來的實驗。這是一個專注于 BEV 地圖的 VQA 數據集,旨在全面理解場景及其中各種元素之間的相互作用。 由于設計的問題的答案屬于特定集合,因此用 Top-1 準確率作為評估指標,這與以往 VQA 研究中常用的做法一致。還分別評估不同類型問題的表現,以便更詳細地了解模型在場景理解各個方面的表現。
ChatBEV 系列模型
除了擬議的數據集外,本文還提供基線模型。由于 BEV 表示固有的緊湊性,其包含不同于自然圖像的特定結構和與任務相關的語義信息,現有的 VLM 直接應用于此任務已被證明不夠充分。為了解決這個問題,通過使用 LoRA 進行視覺指令調整,對幾個高級 VLM [15, 24, 27, 27] 進行微調,并根據 BEV 地圖理解的獨特需求進行定制。根據不同的基礎 VLM,經過微調的模型分別表示為 ChatBEV-LLaVA-1.5-7b、ChatBEV-LLaVA-1.5-13b、ChatBEV-BLIP 和 ChatBEV-InternLM-XComposer2,在捕捉 BEV 地圖中的空間關系和上下文推理方面表現出不同程度的性能,其中 ChatBEV-LLaVA-1.5-13b 的性能優于其他模型。
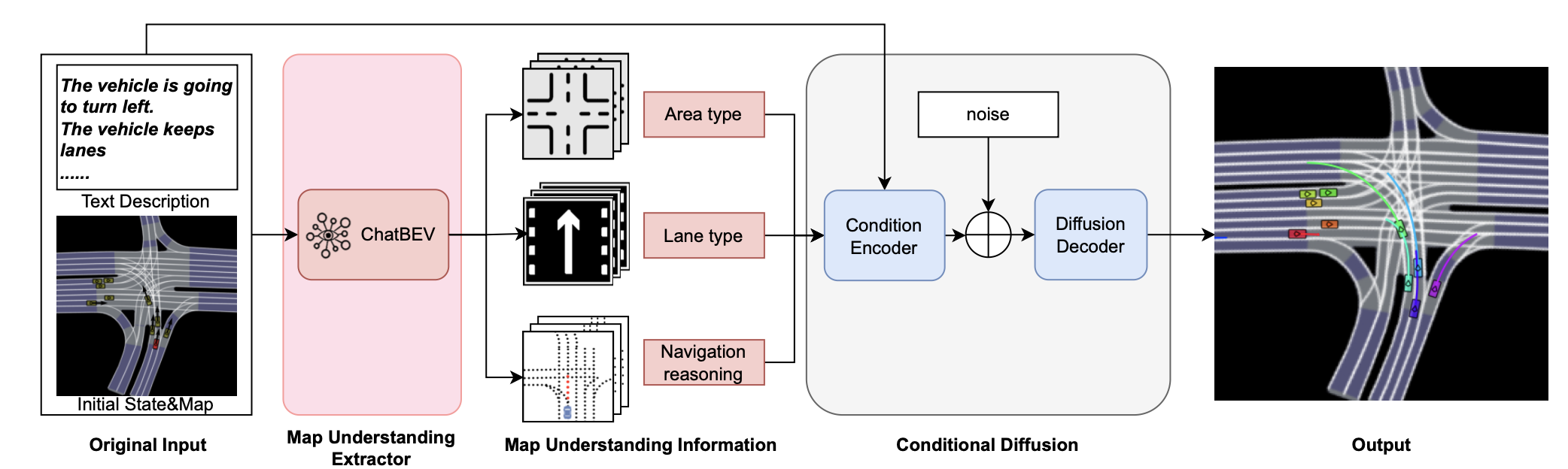
本文提出一種基于擴散的架構,其中 ChatBEV 充當地圖理解提取器,提供全面的場景理解,從而生成更精確、更符合上下文的輸出。推理過程如圖所示。
問題表述
按照 [53, 54] 將場景生成任務表述為一個模仿學習問題。從數學上講,給定一個包含 N 輛車的場景,將所有車輛在 T 個時間步長內的狀態定義為 S = [S_1, S_2, ···, S_N],其中 S_i = [s1_i, s1_i,···, sT_i],st_i = (xt_i, y_it, v_it, θ_it) 表示車輛 i 在第 t 個時間步長的當前狀態(二維位置、速度和偏航角)。類似地,可以定義相應的動作A,這里A_i = [a0_i, a1_i,···,aT?1_i],每個 at_i=(v ?_it, θ ?_it) 是車輛 i 在第 t 個時間步的動作(加速度和偏航角速度)。狀態 s_it+1 可以通過單輪車動力學模型f計算得出,s_it+1 = f (s_it, a_it)。整體軌跡表示為 τ = [A, S]。用 C = (I, D, Sh, M) 表示決策相關上下文,其中I是局部語義圖,D是文本描述,Sh = [S?H, · · · , S^0] 表示車輛的 H 個先前狀態,M 是額外的 BEV 圖理解信息。目標是根據與決策相關的背景生成真實且文本一致的交通軌跡。
地圖理解提取器
給定場景中車輛的初始狀態和相應的文本描述,首先提取地圖理解信息 M,并將其與原始輸入集成,形成下一個模塊的最終輸入。
這里,考慮兩種有助于后續場景生成的地圖理解信息,包括全局理解信息 V 和場景推理信息 P。考慮到車輛對場景的整體理解(例如其當前所在的區域和車道)會影響其特定的運動模式,引入全局理解信息 V = [R, L],它是區域類型 one-hot 向量 R 和車道類型 one-hot 向量 L 的串聯。為了提供更精確且文本對齊的導航引導,引入導航推理信息,表示為 P。它表示車輛根據文本中描述的軌跡類型可能選擇的最可能車道的中心線數據。這里 N_s 表示相關車道數,N_p 表示每條車道中心線的點數,d 表示每個點的維度。
在訓練過程中,通過將車輛的初始位置轉換為區域和車道類型的 one-hot 向量來獲得全局理解。導航推理基于真值軌跡附近的道路。在推理過程中,根據文本描述生成一張 BEV 圖像和一個問題。經過微調的 ChatBEV 會檢索區域、車道類型以及合理車道的邊框。通過收集該邊框內的所有車道,最終完成導航推理。
條件擴散
條件編碼器。條件編碼器旨在有效地集成各種條件輸入,并提供信息豐富的條件嵌入,從而促進后續的解碼過程。在提取器之后,條件編碼器為每個場景接受三種類型的輸入:初始狀態 S^h、文本描述 D 和地圖理解信息 M = ([R, L], P)。對于每個輸入,使用相應的前饋編碼模塊提取嵌入,然后沿時間維度廣播,之后將它們連接起來形成最終的條件嵌入 E。
擴散解碼器。給定條件輸入,擴散解碼器通過迭代細化噪聲數據在每個時間步生成預測軌跡。這里采用 CTG++ [53] 作為擴散解碼器模塊。該過程首先將來自條件編碼器的條件嵌入與來自前饋模塊的預測未來軌跡嵌入沿時間維度連接起來。正弦位置編碼應用于公司內時間動態。采用去噪步驟 k 的正弦位置編碼來融入時間動態。編碼后的軌跡,經過時間注意模塊來捕捉智體關系,然后經過空間注意模塊來捕捉幾何關系。之后,地圖注意層,將車道點轉換為車道向量,從而通過多頭注意機制實現地圖-覺察。最后,將編碼后的軌跡投影回輸入維度,生成預測的動作軌跡,再經過動態函數計算得出結果。

)
)

)
)



)




)




