(一)Spark概述
Spark是一種基于內存的快速、通用、可拓展的大數據分析計算引擎。Hadoop是一個分布式系統基礎架構。
1)官網地址:Apache Spark? - Unified Engine for large-scale data analytics
2)文檔查看地址:Redirecting…
3)下載地址:Downloads | Apache Spark
https://archive.apache.org/dist/spark/
(二)為什么我們需要Spark
? 處理速度
? Hadoop:Hadoop MapReduce 基于磁盤進行數據處理,數據在 Map 和 Reduce 階段會頻繁地寫入磁盤和讀取磁盤,這使得數據處理速度相對較慢,尤其是在處理迭代式算法和交互式查詢時,性能會受到較大影響。
? Spark:Spark 基于內存進行計算,能將數據緩存在內存中,避免了頻繁的磁盤 I/O。這使得 Spark 在處理大規模數據的迭代計算、交互式查詢等場景時,速度比 Hadoop 快很多倍。例如,在機器學習和圖計算等需要多次迭代的算法中,Spark 可以顯著減少計算時間。
? 編程模型
? Hadoop:Hadoop 的 MapReduce 編程模型相對較為底層和復雜,開發人員需要編寫大量的代碼來實現數據處理邏輯,尤其是在處理復雜的數據轉換和多階段計算時,代碼量會非常龐大,開發和維護成本較高。
? Spark:Spark 提供了更加簡潔、高層的編程模型,如 RDD(彈性分布式數據集)、DataFrame 和 Dataset 等。這些抽象使得開發人員可以用更簡潔的代碼來實現復雜的數據處理任務,同時 Spark 還支持多種編程語言,如 Scala、Java、Python 等,方便不同背景的開發人員使用。
? 實時性處理
? Hadoop:Hadoop 主要用于批處理任務,難以滿足實時性要求較高的數據處理場景,如實時監控、實時推薦等。
? Spark:Spark Streaming 提供了強大的實時數據處理能力,它可以將實時數據流分割成小的批次進行處理,實現準實時的數據分析。此外,Spark 還支持 Structured Streaming,提供了更高級的、基于 SQL 的實時流處理模型,使得實時數據處理更加容易和高效。
? HadoopMR框架,從數據源獲取數據,經過分析計算之后,將結果輸出到指定位置,核心是一次計算,不適合迭代計算。
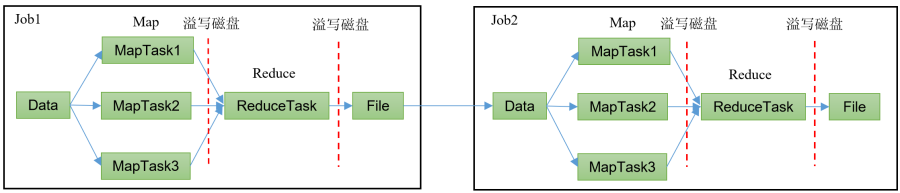
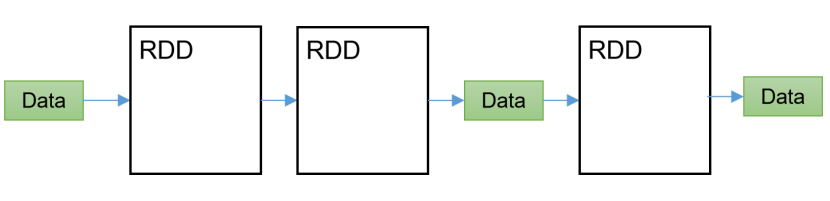
Spark框架,支持迭代式計算,圖形計算
(三)Spark與Hadoop:對比與聯系
? 在大數據處理領域,Spark和Hadoop是兩個極具影響力的技術框架。它們各自有著獨特的特點和優勢,同時也存在著緊密的聯系。本文將從多個角度對Spark和Hadoop進行對比,并探討它們之間的聯系,幫助讀者更好地理解這兩個框架在大數據處理中的角色。
1、對比
(一)性能
? Hadoop:Hadoop的性能主要受限于其MapReduce模型。MapReduce是一種基于磁盤的計算模型,數據需要在磁盤和內存之間頻繁地進行讀寫操作,這導致了處理速度相對較慢。不過,Hadoop在處理大規模數據時具有較高的容錯性和可靠性,能夠保證數據的完整性和一致性。
Spark:Spark的性能優勢在于其內存計算能力。Spark將數據存儲在內存中進行處理,減少了磁盤I/O操作,從而大大提高了數據處理的速度。Spark的處理速度比Hadoop快10 - 100倍,尤其在處理復雜的迭代計算任務時,Spark的優勢更加明顯。此外,Spark還支持多種優化技術,如數據緩存、任務調度優化等,進一步提升了性能。
(二)易用性
? Hadoop:Hadoop的MapReduce編程模型相對復雜,需要開發者編寫大量的代碼來實現數據處理邏輯。對于初學者來說,學習曲線較陡峭。此外,Hadoop的生態系統雖然豐富,但各個組件之間的集成和配置也需要一定的技術門檻。
Spark:Spark提供了更簡潔易用的API,支持多種編程語言,如Scala、Java、Python等。Spark的編程模型更加直觀,開發者可以更快速地實現數據處理邏輯。Spark還提供了豐富的內置庫和工具,如Spark SQL、Spark Streaming、MLlib等,使得開發者可以輕松地進行批處理、實時流處理、機器學習等多種任務。
?(三)適用場景
? Hadoop:Hadoop適合處理大規模的離線數據處理任務,如日志分析、數據挖掘等。由于其高容錯性和可靠性,Hadoop在處理大規模數據時能夠保證數據的完整性和一致性。此外,Hadoop的生態系統豐富,可以與其他大數據工具(如Hive、Pig等)集成,滿足多種數據處理需求。
Spark:Spark適合處理對實時性要求較高的數據處理任務,如實時數據分析、機器學習等。由于其內存計算能力,Spark能夠快速處理數據,滿足實時性需求。此外,Spark還適合處理復雜的迭代計算任務,如機器學習算法中的梯度下降等。Spark的多計算模式支持使其在多種應用場景中都具有廣泛的應用價值。
2、聯系
?(一)數據存儲
? Hadoop的HDFS是Spark的數據存儲基礎。Spark可以與HDFS無縫集成,直接讀取和寫入HDFS中的數據。這種集成使得Spark可以充分利用HDFS的分布式存儲能力和高容錯性,保證數據的安全性和可靠性。同時,Spark也可以與其他分布式存儲系統(如Amazon S3、HBase等)集成,進一步擴展了數據存儲的選擇范圍。
?(二)生態系統
? Hadoop和Spark都擁有豐富的生態系統。Hadoop的生態系統包括HDFS、MapReduce、Hive、Pig等組件,這些組件相互配合,能夠滿足多種數據處理需求。Spark的生態系統則包括Spark SQL、Spark Streaming、MLlib等庫和工具,這些工具使得Spark在批處理、實時流處理、機器學習等領域具有強大的功能。此外,Spark還可以與Hadoop的生態系統中的組件進行集成,如Spark可以與Hive集成,使用Hive的SQL語法進行數據查詢和分析;Spark也可以與HBase集成,進行實時數據存儲和查詢。
(三)計算模型
? Spark的計算模型在一定程度上繼承了Hadoop的MapReduce模型。Spark的RDD(Resilient Distributed Dataset)是其核心數據結構,它類似于MapReduce中的Map和Reduce任務的輸出結果。RDD具有容錯性、可并行計算等特點,使得Spark能夠高效地進行分布式計算。同時,Spark在MapReduce模型的基礎上進行了改進和優化,引入了內存計算、DAG(Directed Acyclic Graph)調度等技術,提高了計算效率和性能。
3、總結
? Spark和Hadoop在大數據處理領域都具有重要的地位。Hadoop以其高容錯性、高可靠性和可擴展性,適合處理大規模的離線數據處理任務;Spark則以其內存計算能力、高性能和多計算模式支持,適合處理對實時性要求較高的數據處理任務。兩者在數據存儲、生態系統和計算模型等方面存在著緊密的聯系,可以相互配合,共同滿足大數據處理的多種需求。在實際應用中,企業可以根據自身的需求和場景,選擇合適的框架或將其組合使用,以實現高效、可靠的大數據處理。
? 隨著大數據技術的不斷發展,Spark和Hadoop也在不斷地進行改進和優化。未來,它們將在大數據處理領域繼續發揮重要作用,為企業的數字化轉型和數據驅動決策提供有力支持。
希望這篇文章能夠幫助你更好地了解Spark和Hadoop之間的對比和聯系。如果你對這兩個框架還有其他疑問或想要深入了解某個方面的內容,歡迎在評論區留言,我會為你解答。
)











繪制車輛運動軌跡(仿高德))






