Spark-Streaming簡介
? ? ? 概述:用于流式數據處理,支持Kafka、Flume等多種數據輸入源,可使用Spark原語運算,結果能保存到HDFS、數據庫等。它以DStream(離散化流)為抽象表示,是RDD在實時場景的封裝,具有易用、容錯、易整合到Spark體系的特點。
? ? ? ?架構:1.5版本前通過設置靜態參數限制Receiver數據接收速率,1.5版本起引入背壓機制,依據JobScheduler反饋動態調整Receiver數據接收率 ,可通過“spark.streaming.backpressure.enabled”控制是否啟用。
DStream實操-WordCount案例:
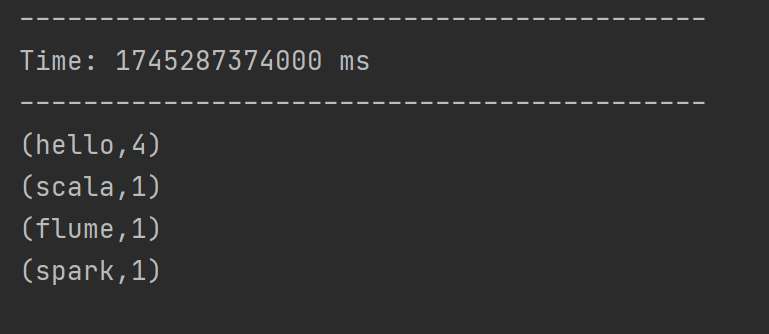
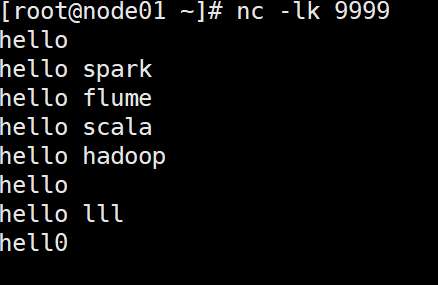
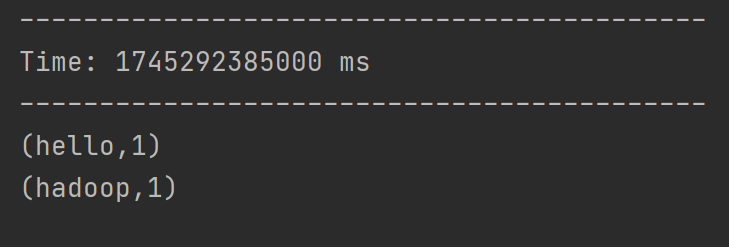
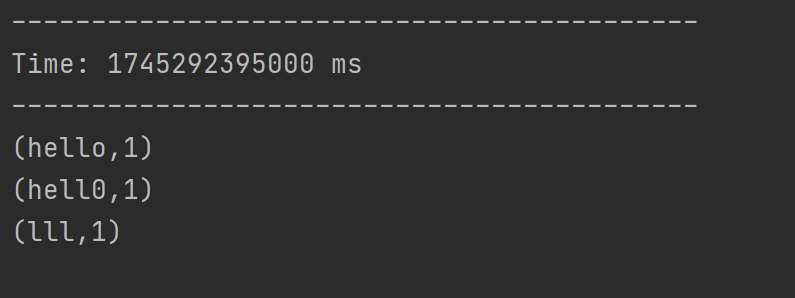
? ? ? 添加相關依賴后,編寫代碼從指定端口讀取數據,經flatMap、map、reduceByKey等操作統計單詞出現次數,啟動netcat發送數據后即可運行。
案例代碼:
 ?
?
 ?
?
?
?
?Spark-Streaming核心編程
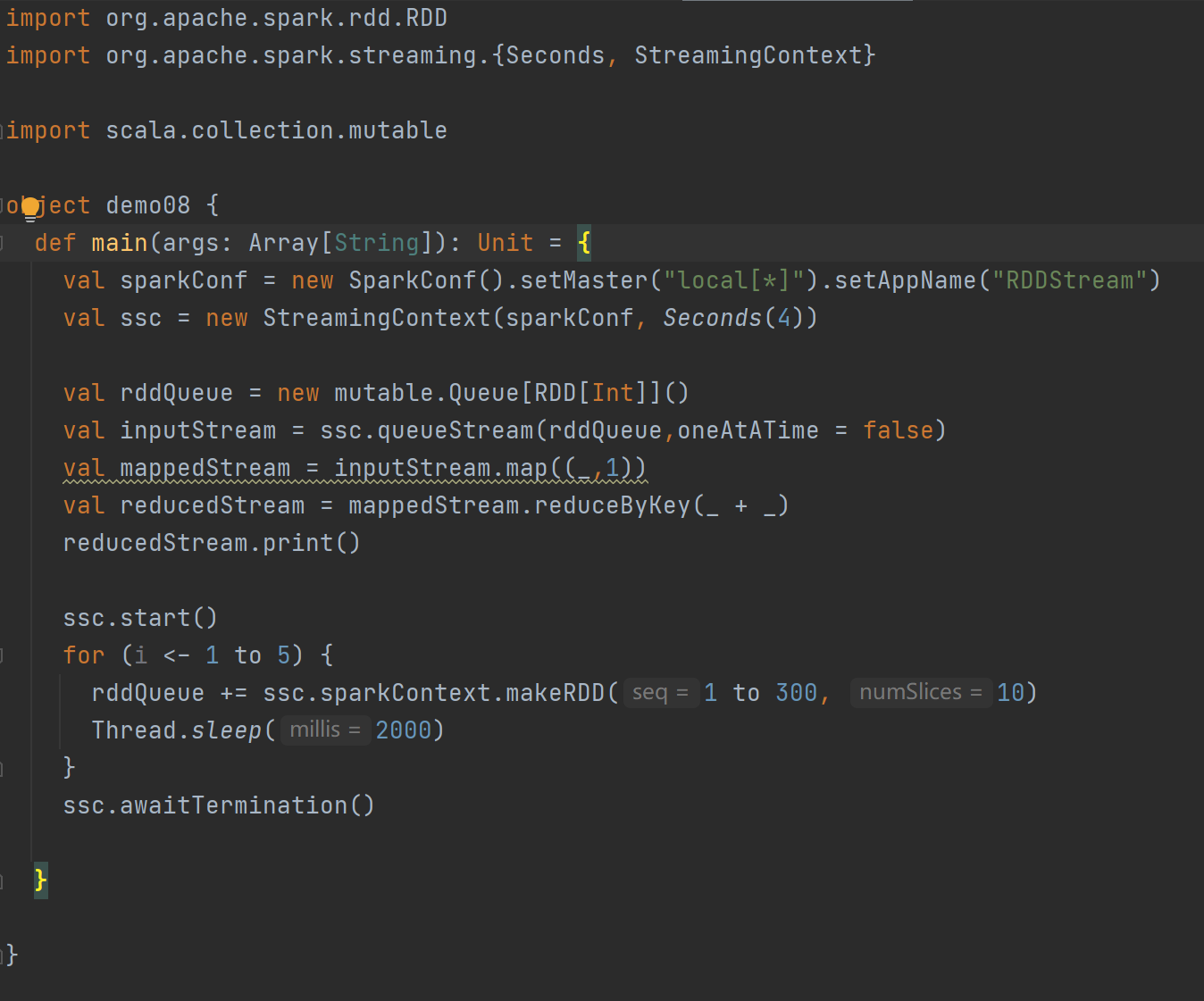
DStream創建 - RDD隊列:
? ? ? 使用ssc.queueStream(queueOfRDDs)創建DStream,計算wordcount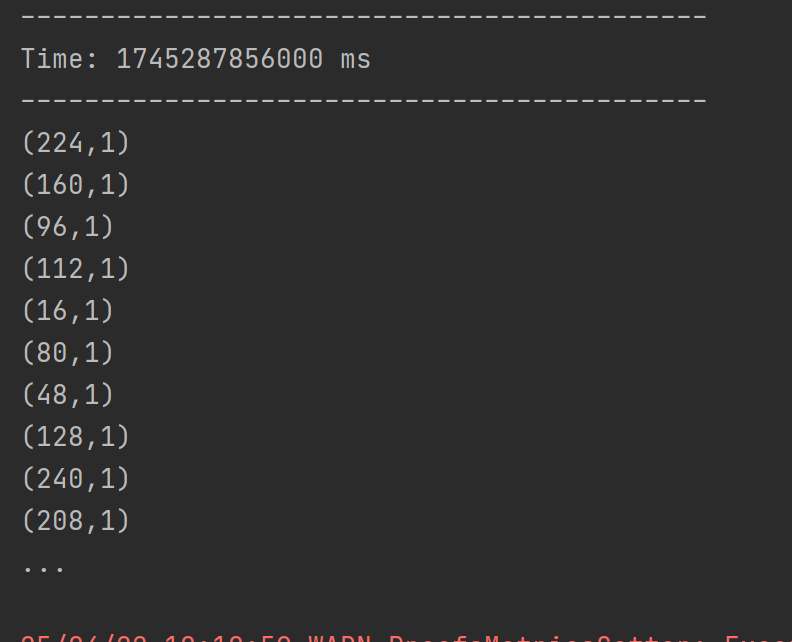
?
案例代碼
?
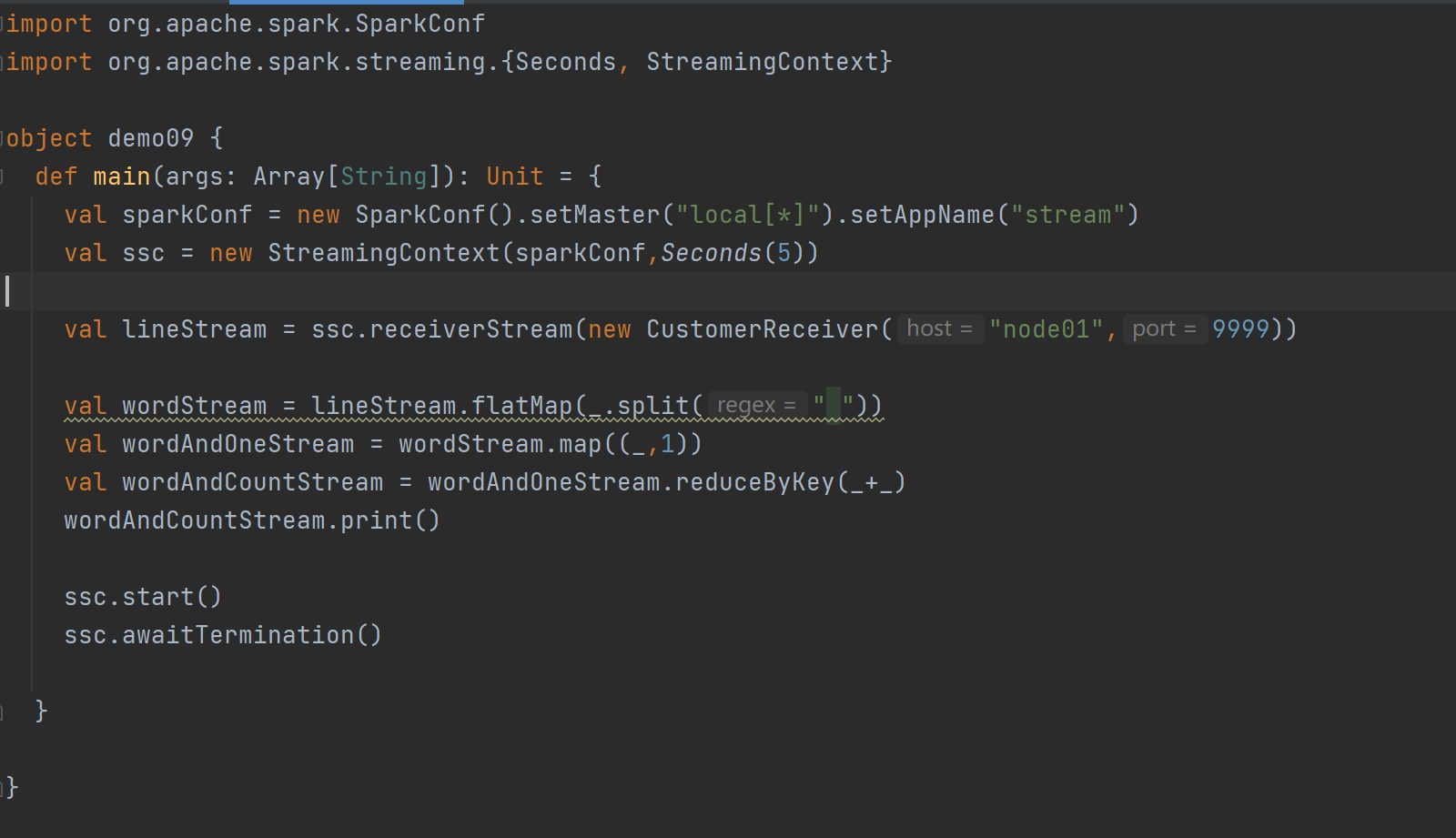
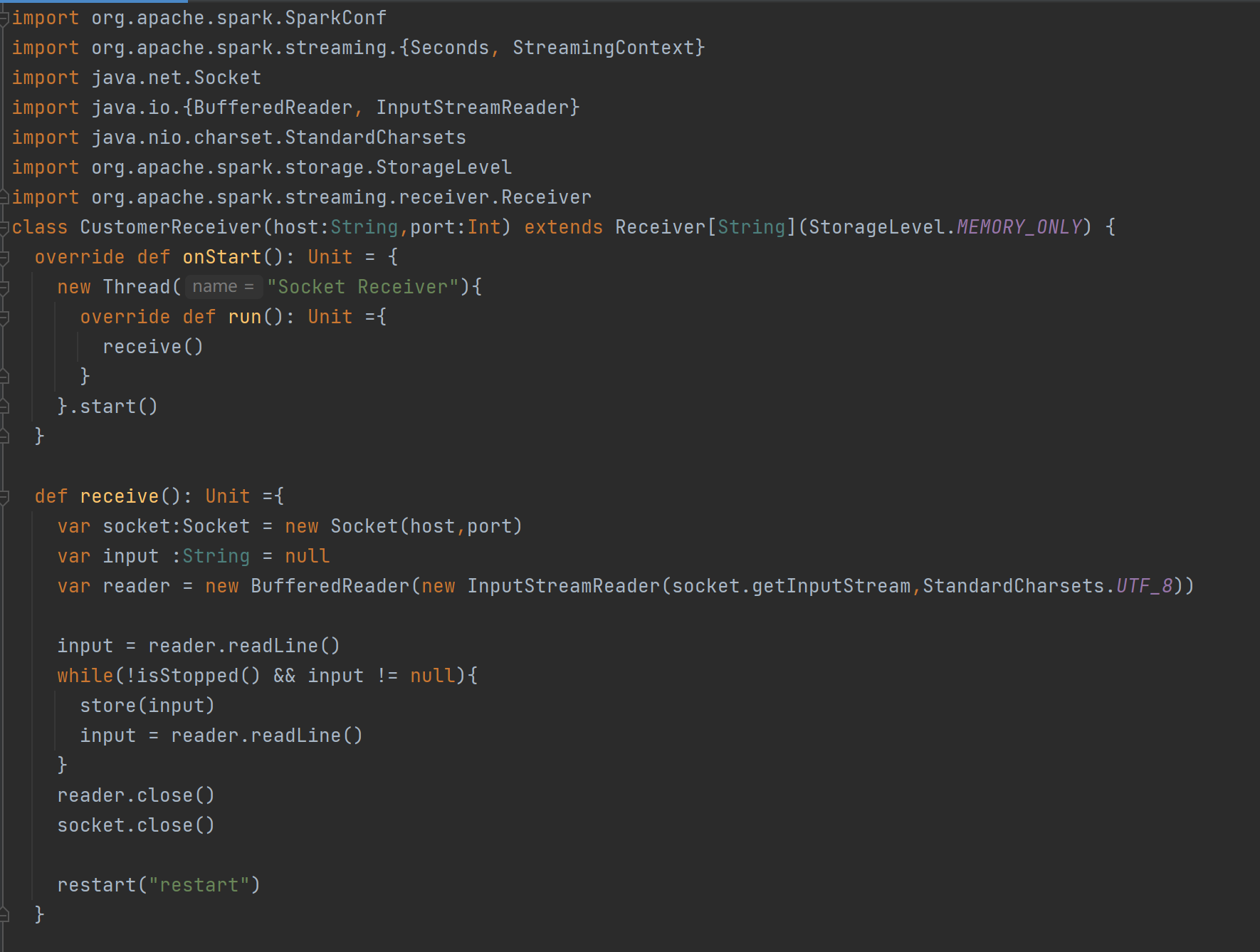
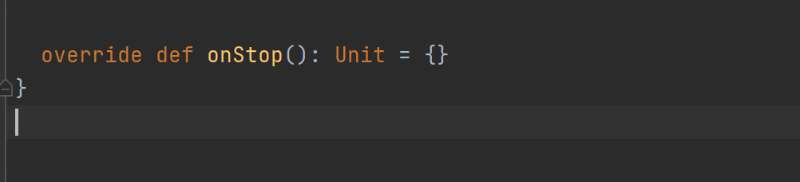
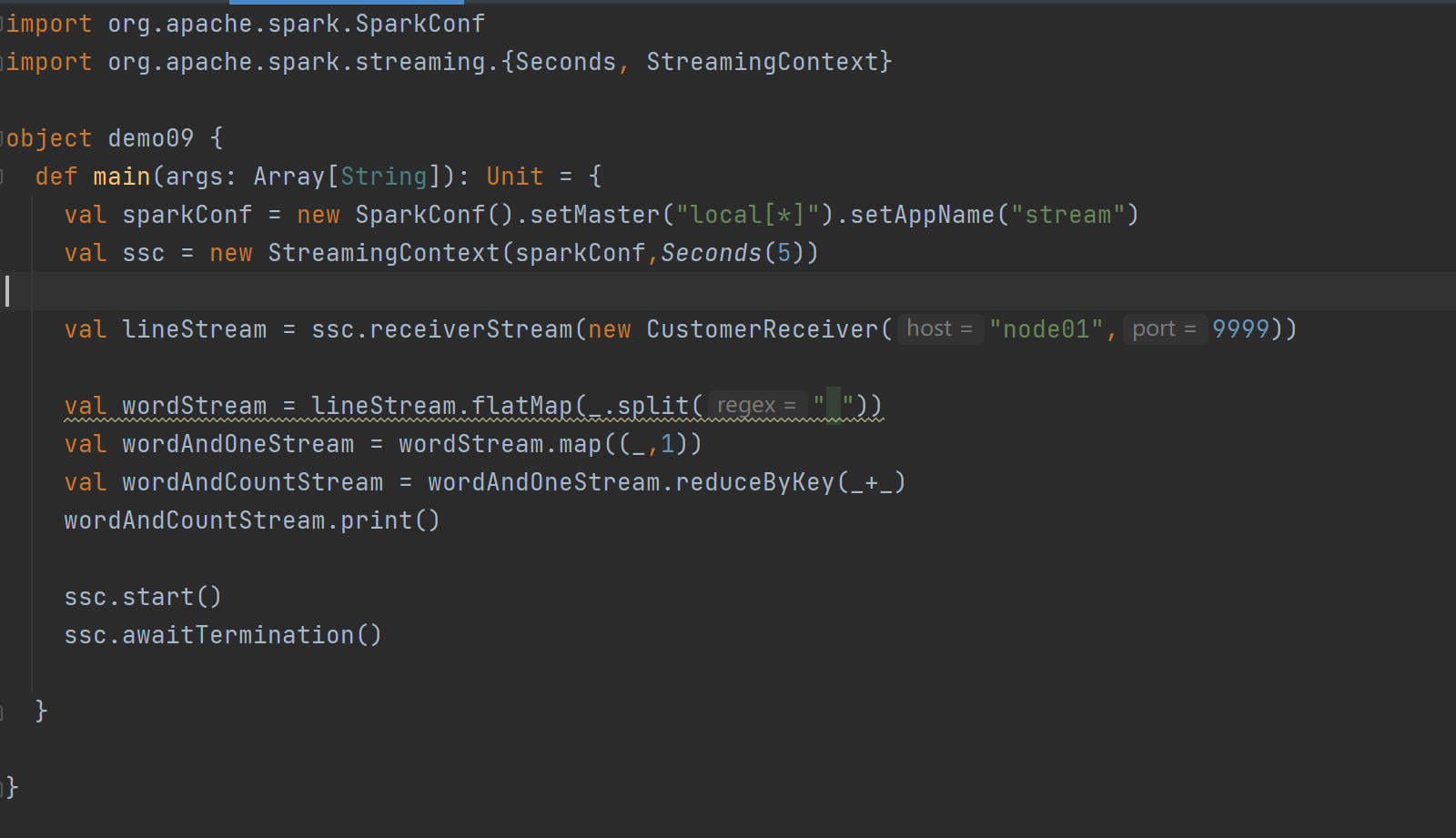
DStream創建 - 自定義數據源:
? ? ?自定義數據源需繼承Receiver并實現onStart、onStop方法。案例中自定義數據源監控指定端口獲取內容,在使用時通過ssc.receiverStream引入,進而進行數據處理。
 ?
?
 ?
?
 ?
?
?
?
?


)



)

雙鏈表)
)









)