lightgbm:
一、位置:
相比XGB,LGBM有更高效的計算效率和更低的內存占用,并且面對高維數據,LGBM算法擁有更好的過擬合特性,這使得在建模數據量日趨增加的今天,LGBM會更適合作為前期探索性建模的模型
CatBoost算法同樣在訓練效率上比XGB更快,并且更加自動化——在特征衍生和超參數優化已經成為機器學習模型訓練標配的今天,CatBoost能夠(一定程度上)實現對輸入的特征進行自動特征衍生和對超參數進行自動超參數優化。
LGBM以犧牲極小的計算精度為代價,將GBDT的計算效率提升了近20倍
方法:
LGBM充分借鑒了XGB提出的一系列提升精度的優化策略,同時在此基礎之上進一步提出了一系列的數據壓縮和決策樹建模流程的優化策略。
二、優化點在三個方面:
數據壓縮:
1.全樣本上連續變量分箱(連續變量離散化):等寬分箱,
2.同時帶入離散特征和離散后的連續變量進行離散特征捆綁(合并)降維:互斥特征捆綁(Exclusive Feature Bundling, EFB)算法
降維且不讓精度下降太多
獨熱編碼逆向過程:
如果兩個變量互斥(我取1你就不取1,不會同時取得非0)
沖突比例:沖突樣本占非全0樣本比例
圖著色問題:如果兩個特征互斥比例小于設定的閾值,則沒有邊相連。然后對圖著色,用盡可能少的顏色對圖染色,相鄰節點不同色。
從度最大的點出發,開始著色。
最后賦予新特征取值:不同顏色取不同的值
原理思考:如果沖突比例過大,新生成的值會很多,特征壓縮效果太大
3.最終在每次構建一顆樹之前進行樣本下采樣:基于梯度的單邊采樣(Gradient-based One-Side Sampling, GOSS)的方法
目的:壓縮數據集并且不太降低精度。
計算樣本梯度,小梯度樣本進行抽樣,再結合大梯度樣本一起建模。
為了還原原始數據集梯度,用膨脹系數,最終數據集樣本梯度=大樣本梯度+小樣本梯度*膨脹系數
而膨脹系數=(1-大梯度樣本比例)/小梯度樣本閾值
注意點:
top_rate越大other_rate越小好一些。
以上方法只適用于lightgbm,不能單獨使用
建模優化方法:
1.直方圖優化算法:通過直方圖的形式更加高效簡潔的表示每次分裂前后數據節點的核心信息,并且父節點和子節點也可以通過直方圖減法計算直接算得,從而加速數據集分裂的計算過程
用直方圖代替原始數據集來訓練,大幅加快決策樹生長過程。
直方圖:每個特征的梯度和 、hess和圖
2.leaf wise tree growth的葉子節點優先的決策樹生長策略:LGBM則允許決策樹生長過程優先按照節點進行分裂,即允許決策樹“有偏”的生長
希望精度提升,過擬合風險更大些。
3.LGBM決策樹生長的增益計算公式
圖?
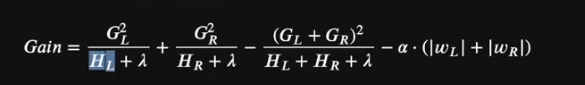
對于實際計算過程的優化:例如Voting Parallel(投票特征并行)方法、特征多線程并行處理方法、GPU加速方法和分布式計算
三、超參數
LGBMClassifier特殊參數:
Boosting過程控制超參數:boosting_type(提升類型,如gbdt、dart、goss、rf)
與之相關的是subsample_for_bin參數:subsample_for_bin:該參數表示對連續變量進行分箱時(直方圖優化過程)抽取樣本的個數,默認取值為200000,當實際抽樣個數大于輸入訓練數據樣本數量時,會帶入全部樣本進行計算。而如果boosting_type選擇的是goss,則在直方圖優化時會自動完成抽樣,具體抽樣策略是:會保留所有較小梯度的樣本(即那些已經被模型很好擬合的樣本),并對較大梯度的樣本進行采樣。這種策略能夠在加速訓練(大梯度樣本的貢獻)的同時有效防止過擬合(小梯度樣本的貢獻)。因此,如果boosting_type選擇的是 "goss",。則subsample_for_bin參數會失去作用,此時無論subsample_for_bin取值多少都不影響最終結果。
特征和數據處理類超參數則主要與數據采樣有關:包含subsample(樣本子集的比例)、subsample_freq(進行子采樣的頻率)、colsample_bytree(列采樣的比例)
subsample:模型訓練時抽取的樣本數量,取值范圍為 (0, 1],表示抽樣比例,默認為1.0
subsample_freq:抽樣頻率,表示每隔幾輪進行一次抽樣,默認取值為0,表示不進行隨機抽樣(如果它為0,則不論subsample是多少,都不抽樣)
colsample_bytree:在每次迭代(樹的構建)時,隨機選擇特征的比例,取值范圍為 (0, 1],默認為1.0?
特征和數據處理類超參數:
注意:
LGBM和RF的不同特征抽樣(分配)規則:LGBM和隨機森林不同,隨機森林是每棵樹的每次分裂時都隨機分配特征,而LGBM是每次構建一顆樹時隨機分配一個特征子集,這顆樹在成長過程中每次分裂都是依據這個特征子集進行生長。
LGBMRegressor:
和LGBMClassifier只有兩點不同,其一是LGBMRegressor沒有class_weight參數,其二則是LGBMRegressor的損失函數和LGBMClassifier完全不同。
損失函數:包含了GBDT和XGB的各類回歸類損失函數
?




![[python] set](http://pic.xiahunao.cn/[python] set)







)


)


)
