摘要
? ? ? ? 本篇文章以實現簡單的第一范式 RAG-Naive RAG為目標,并最終創建并實現一個基于RAG的論文分析器的項目。
LangChain 文檔加載
????????文檔加載是 RAG 流程的起點,它負責從各種數據源讀取原始文檔,將其轉化為程序可處理的格式。LangChain 支持多種文檔類型的加載,具體支持的加載文檔類型,可以參考我寫的這篇文章:
langchain框架-文檔加載器詳解-CSDN博客
- 接下來,我將以ArxivLoader 論文加載器為示例,基于langchain實現一個論文文檔加載器:
- 首先閱讀項目源碼說明得知,使用ArxivLoader 需要安裝兩個模塊 arxiv 和 pyMuPDF:
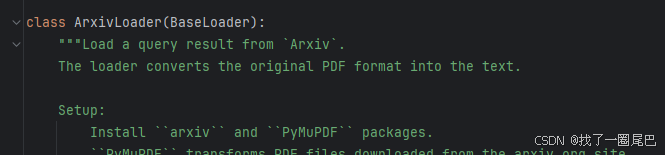
pip install -U arxiv pymupdf- 注意:pymupdy 依賴需要Visual Studio 工具包的支持,如果沒有安裝的話會報python 依賴加載異常。
- 繼續閱讀源碼說明確定其參數:
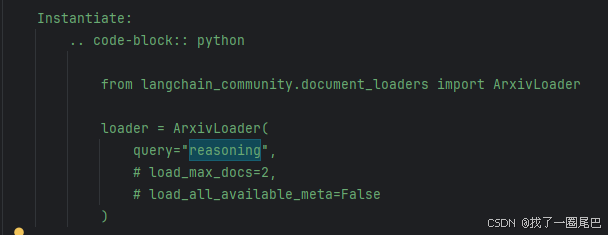
- 示例代碼
def load_arxiv_paper(arxiv_id):try:# 初始化ArxivLoaderloader = ArxivLoader(query=arxiv_id,load_max_docs=1, # 限制加載文檔數量load_all_available_meta=True # 加載所有可用的元數據)# 加載論文文檔documents = loader.load()logger.info(f"成功加載論文,標題: {documents[0].metadata.get('Title', 'Unknown')}")return documentsexcept Exception as e:logger.error(f"加載論文時發生錯誤: {str(e)}")return None- ?并將最終結果打印并保存到文件中緩存,整個文檔加載的流程就結束了。
# 論文的arxiv IDarxiv_id = "2402.19473"# 加載論文documents = load_arxiv_paper(arxiv_id)if not documents:return# 存入 getParper.txt 文件中。with open("getPaper.txt", "w", encoding="utf-8") as f:for doc in documents:f.write(doc.page_content + "\n")exit()- 最終獲取展示:注意ArxivLoader最終獲取的論文只是文本部分,不能包含圖片部分的內容。

LangChain 文本分割
? ? ????????在完成文檔加載之后,對加載的文檔進行合理的文本分割顯得尤為重要。因為在檢索增強生成(RAG)流程中,優質的文本分塊方式對最終結果有著顯著影響。
????????考慮到本項目所涉及的論文為英文文檔,并且為了確保論文內容的連貫性,我們決定采用語義分割的策略。具體而言,我們將借助 LangChain 框架中的 NLTKTextSplitter 工具。該工具依托自然語言工具包(NLTK),能夠精準地按照句子對文本進行分割,從而為后續的 RAG 任務奠定堅實基礎。
? ? ? ? Langchain 框架中包含了很多文本分割方法,如果讀者想系統學習langchain 的文本分割,可以參考我寫的以下文章:
langchain框架-文檔分割器詳解(官方庫)-CSDN博客
langchain框架-文檔分割器詳解(非官方庫)-CSDN博客
langchain框架-文檔分割器總結即補充-CSDN博客
NLTK 語料包下載
? ? ? ? 使用NLTKTextSplitter 需要先下載NLTK 語料工具包。但由于網絡等原因,我們可能無法正常下載該工具包。我們可以采用網絡代理的方式,如果不能用代理的小伙伴,可以下載我的上傳資源進行練習。具體的代碼如下:
def getNLTKData():import nltkos.environ['http_proxy'] = 'http://127.0.0.1:33210'os.environ['https_proxy'] = 'http://127.0.0.1:33210'# 指定自定義的數據目錄custom_data_dir = 'E:\\nltk_data'nltk.data.path.append(custom_data_dir)# 下載資源if not os.path.exists(os.path.join(custom_data_dir, 'tokenizers', 'punkt')):nltk.download('punkt', download_dir=custom_data_dir)if not os.path.exists(os.path.join(custom_data_dir, 'tokenizers', 'punkt_tab')):nltk.download('punkt_tab', download_dir=custom_data_dir)CSDN語料包下載地址
https://download.csdn.net/download/weixin_41645817/90627575
分割文本方法
def process_documents(documents):if not documents:return Nonetry:# 初始化文本分割器nltk_splitter = NLTKTextSplitter(chunk_size=1000,chunk_overlap=200,)# 分割文檔texts = nltk_splitter.split_documents(documents)logger.info(f"文檔已分割為 {len(texts)} 個片段")return textsexcept Exception as e:print(e)logger.error(f"處理文檔時發生錯誤: {str(e)}")return None執行并保存
# 處理文檔split_documents = process_documents(documents)if not split_documents:return# 將分割后的文本存入 getPaperChunk2.json 文件中chunks_data = {"total_chunks": len(split_documents),"chunks": []}for index, text in enumerate(split_documents, 1):chunk_info = {"chunk_id": f"chunk_{index}","page_content": text.page_content}chunks_data["chunks"].append(chunk_info)# 將JSON數據寫入文件with open("getPaperChunk2.json", "w", encoding="utf-8") as f:json.dump(chunks_data, f, ensure_ascii=False, indent=4)print(f"成功保存 {len(split_documents)} 個文本塊到 getPaperChunk2.json")LangChain 嵌入模型
? ? ? ? 實現文本切分后,我們需要將切分的文檔進行向量化處理,在這里我將使用ZhipuAIEmbeddings 進行文檔的向量化處理,主要是因為我買了智譜AI embedding-3 的流量包了哈。小伙伴們可以自行選擇向量化模型,LangChain 框架也集成了眾多embeddings類的實現,具體可以參考我的這篇文章:
LangChain框架-嵌入模型詳解-CSDN博客
LangChain 向量存儲
? ? ? ? 文本向量化后,我們需要將向量化后的數據存入到向量數據庫中。LangChain 框架集成了眾多向量數據庫的實現,我們可以很方便的通過LangChain 將數據存入到向量數據庫。在這里,我將使用一款基于內存的輕量級數據庫Faiss 作為示例進行向量存儲。如果您想系統性的學習LangChain 向量存儲部分,可以參考我的這篇文章:
LangChain框架-向量存儲詳解-CSDN博客
向量化與向量存儲代碼示例
-
安裝zhipuai,faiss-cpu 依賴
pip install zhipuai,faiss-cpu
-
向量化并存入Faiss庫
def create_vector_store(documents):if not documents:logger.warning("沒有文檔需要處理")return Nonetry:# 使用絕對路徑存儲緩存cache_dir = os.path.join(os.path.dirname(__file__), "cache")os.makedirs(cache_dir, exist_ok=True)store = LocalFileStore(cache_dir)# 創建向量存儲underlying_embeddings = ZhipuAIEmbeddings(model="embedding-3",api_key=os.getenv("ZHIPUAI_API_KEY"),)cached_embedder = CacheBackedEmbeddings.from_bytes_store(underlying_embeddings, store, namespace=underlying_embeddings.model)# 批量處理文檔batch_size = 30vector_stores = []for i in range(0, len(documents), batch_size):batch_texts = documents[i:i + batch_size]try:batch_vector_store = FAISS.from_documents(documents=batch_texts,embedding=cached_embedder)vector_stores.append(batch_vector_store)logger.info(f"成功處理第 {i//batch_size + 1} 批文檔")except Exception as batch_error:logger.error(f"處理第 {i//batch_size + 1} 批文檔時出錯: {str(batch_error)}")continueif not vector_stores:logger.error("沒有成功創建任何向量存儲")return None# 合并所有批次的向量存儲merged_store = vector_stores[0]for store in vector_stores[1:]:merged_store.merge_from(store)logger.info(f"向量存儲創建成功,共處理 {len(documents)} 個文檔")return merged_storeexcept Exception as e:print(e)logger.error(f"創建向量存儲時發生錯誤: {str(e)}")return None????????這段代碼實現了一個向量存儲創建功能,主要包含以下幾個關鍵部分:
-
使用LocalFileStore實現本地緩存存儲,避免重復計算向量;
-
使用智譜AI的embedding模型將文本轉換為向量,并通過CacheBackedEmbeddings進行緩存管理;
-
采用批處理方式,每批處理30個文檔,(智譜AI 的最大批處理數量為64)
-
使用FAISS創建向量存儲
-
將所有批次的向量存儲合并成一個完整的向量庫。
????????這種實現方式既保證了處理大量文檔的效率,又通過緩存機制優化了性能。
? ? ? ? cache中最終緩存的向量數據展示:
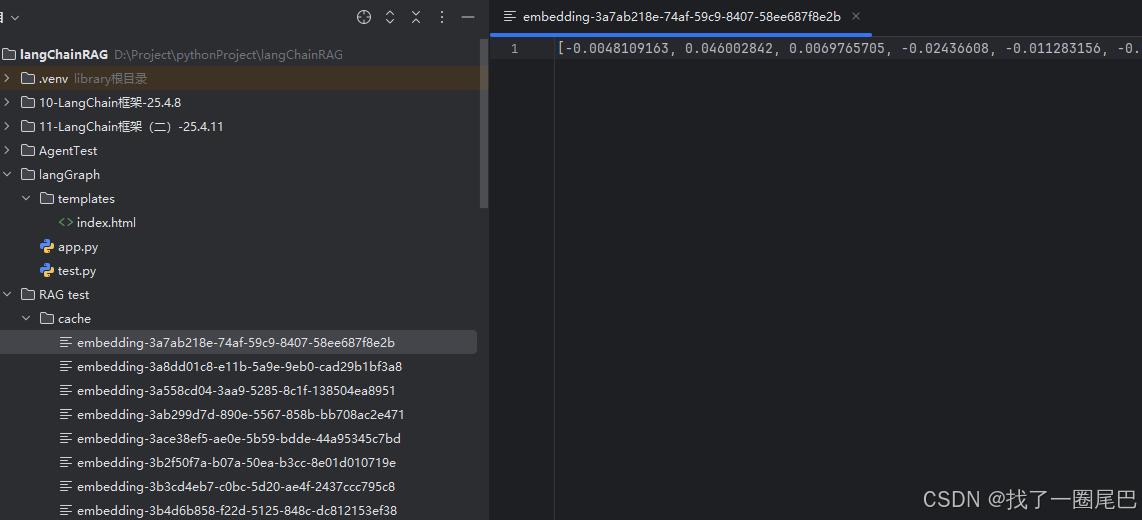
流程調用
# 創建向量存儲vectorstore = create_vector_store(split_documents)if not vectorstore:returnprint("向量存儲創建成功")LangChain 檢索器
????????通過langchain 框架,我們可以很容易的將向量存儲轉換為檢索器對象。如果您想系統性的學習langchain 的檢索器,可以參考我的這篇文章:
LangChain框架-檢索器詳解-CSDN博客
????????示例項目將向量存儲轉化為檢索器,最后使用了invoke()方法,接收檢索的對象文檔。代碼以及最終的檢索結果如下:
處理代碼
retriever = vectorstore.as_retriever()
doc =retriever.invoke("這篇論文講述了什么內容?")
print(doc)LLM內容整合
? ? ? ? 最后,我們可以通過調用DeepSeek,再對檢索器檢索的內容進行總結。在這里我使用了ChatPromptTemplate 對話提示詞模板和 create_stuff_documents_chain?處理文檔問答的工具鏈形成一個最終答案,代碼如下:
system_prompt = ChatPromptTemplate.from_messages([("system", """根據提供的上下文: {context} \n\n 使用回答問題: {input}""")])# 初始化大模型llm = ChatOpenAI(api_key=os.getenv("DEEPSEEK_API_KEY"),base_url="https://api.deepseek.com/v1",model="deepseek-chat")# 構建鏈 這個鏈將文檔作為輸入,并使用之前定義的提示模板和初始化的大模型來生成答案chain = create_stuff_documents_chain(llm,system_prompt)res = chain.invoke({"input": "這篇論文講述了什么內容?", "context": all_context})print("最終答案:" +res)最終結果展示
最終答案:這篇論文是一篇關于**檢索增強生成(Retrieval-Augmented Generation, RAG)**的系統性綜述,旨在全面梳理RAG的基礎理論、優化方法、多模態應用、基準測試、當前局限及未來方向。以下是核心內容總結:
---
### **1. 研究背景與動機**
- **AIGC的挑戰**:盡管生成式AI(如大模型)取得顯著進展,但仍面臨知識更新滯后、長尾數據處理、數據泄露風險、高訓練/推理成本等問題。
- **RAG的作用**:通過結合信息檢索(IR)與生成模型,RAG能夠動態檢索外部知識庫中的相關內容,提升生成結果的準確性和魯棒性,同時降低模型幻覺(hallucination)。---
### **2. 主要貢獻**
- **全面性綜述**:覆蓋RAG的**基礎框架**(檢索器Retriever與生成器Generator的協同)、**優化方法**(輸入增強、檢索器改進、生成器調優等)、**跨模態應用**(文本、圖像、視頻等)、**評測基準**及未來挑戰。
- **填補空白**:相比已有研究(如Zhao et al.僅關注多模態應用或忽略基礎理論),本文首次系統整合RAG的全鏈條技術,強調其在多領域的適用性。---
### **3. 核心內容**
- **RAG基礎**(Section II-III) ?
? 介紹檢索器(如稠密檢索Dense Retrieval)與生成器(如LLMs)的協同機制,以及如何通過檢索動態增強生成過程。
??
- **優化方法**(Section III-B) ?
? 提出5類增強策略: ?
? - **輸入增強**:如查詢轉換(Query2Doc、HyDE生成偽文檔擴展查詢語義)。 ?
? - **檢索器改進**:優化索引結構或相似度計算。 ?
? - **生成器調優**:利用檢索結果指導生成。 ?
? - **結果后處理**:對輸出進行過濾或重排序。 ?
? - **端到端優化**:聯合訓練檢索與生成模塊。- **多模態應用**(Section IV) ?
? 超越文本生成,探討RAG在圖像、視頻、音頻等模態中的獨特應用(如跨模態檢索增強生成)。- **評測與挑戰**(Section V-VI) ?
? 分析現有基準(如檢索質量、生成效果評估),指出RAG的局限性(如檢索效率、多模態對齊)及未來方向(如輕量化部署、動態知識更新)。---
### **4. 論文結構**
1. **引言**:RAG的動機與綜述范圍。 ?
2. **基礎理論**:檢索器與生成器的協同機制。 ?
3. **優化方法**:輸入、檢索、生成等環節的增強策略。 ?
4. **多模態應用**:跨領域案例(如醫療、金融、創作)。 ?
5. **評測基準**:現有評估框架與指標。 ?
6. **局限與展望**:技術瓶頸與潛在解決方案。 ?
7. **結論**:總結RAG的價值與發展路徑。---
### **5. 創新點**
- **多模態視角**:強調RAG在非文本領域的潛力(如視覺問答、視頻摘要)。 ?
- **技術整合**:首次系統化分類RAG優化方法(如輸入端的查詢轉換策略)。 ?
- **實踐指導**:為研究者提供跨領域應用的設計思路(如如何選擇檢索源或生成模型)。---
### **總結**
該論文是RAG領域的里程碑式綜述,不僅梳理了技術脈絡,還指出了未來研究方向(如高效檢索算法、多模態泛化能力),對學術界和工業界均有重要參考價值。
完整的代碼腳本
import json
import logging
import osfrom dotenv import load_dotenv
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain.embeddings import CacheBackedEmbeddings
from langchain.storage import LocalFileStore
from langchain_community.chat_models import ChatOpenAI
from langchain_community.document_loaders import ArxivLoader
from langchain_community.embeddings import ZhipuAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_core.prompts import ChatPromptTemplate
from langchain_text_splitters import NLTKTextSplitterlogger = logging.getLogger('my_logger')
# 加載 .env 文件中的環境變量
load_dotenv()def getNLTKData():import nltk# 指定自定義的數據目錄custom_data_dir = 'D:\\nltk_data'nltk.data.path.append(custom_data_dir)# 下載資源if not os.path.exists(os.path.join(custom_data_dir, 'tokenizers', 'punkt')):os.environ['http_proxy'] = 'http://127.0.0.1:33210'os.environ['https_proxy'] = 'http://127.0.0.1:33210'nltk.download('punkt', download_dir=custom_data_dir)nltk.download('punkt_tab', download_dir=custom_data_dir)def load_arxiv_paper(arxiv_id):try:# 初始化ArxivLoaderloader = ArxivLoader(query=arxiv_id,load_max_docs=1, # 限制加載文檔數量load_all_available_meta=True # 加載所有可用的元數據)# 加載論文文檔documents = loader.load()logger.info(f"成功加載論文,標題: {documents[0].metadata.get('Title', 'Unknown')}")return documentsexcept Exception as e:logger.error(f"加載論文時發生錯誤: {str(e)}")return Nonedef process_documents(documents):if not documents:return Nonetry:# 初始化文本分割器nltk_splitter = NLTKTextSplitter(chunk_size=1000,chunk_overlap=200,)# 分割文檔texts = nltk_splitter.split_documents(documents)logger.info(f"文檔已分割為 {len(texts)} 個片段")return textsexcept Exception as e:print(e)logger.error(f"處理文檔時發生錯誤: {str(e)}")return Nonedef create_vector_store(documents):if not documents:logger.warning("沒有文檔需要處理")return Nonetry:# 使用絕對路徑存儲緩存cache_dir = os.path.join(os.path.dirname(__file__), "cache")os.makedirs(cache_dir, exist_ok=True)store = LocalFileStore(cache_dir)# 創建向量存儲underlying_embeddings = ZhipuAIEmbeddings(model="embedding-3",api_key=os.getenv("ZHIPUAI_API_KEY"),)cached_embedder = CacheBackedEmbeddings.from_bytes_store(underlying_embeddings,store,namespace=underlying_embeddings.model)# 批量處理文檔batch_size = 30vector_stores = []for i in range(0, len(documents), batch_size):batch_texts = documents[i:i + batch_size]try:batch_vector_store = FAISS.from_documents(documents=batch_texts,embedding=cached_embedder)vector_stores.append(batch_vector_store)logger.info(f"成功處理第 {i // batch_size + 1} 批文檔")except Exception as batch_error:logger.error(f"處理第 {i // batch_size + 1} 批文檔時出錯: {str(batch_error)}")continueif not vector_stores:logger.error("沒有成功創建任何向量存儲")return None# 合并所有批次的向量存儲merged_store = vector_stores[0]for store in vector_stores[1:]:merged_store.merge_from(store)logger.info(f"向量存儲創建成功,共處理 {len(documents)} 個文檔")return merged_storeexcept Exception as e:print(e)logger.error(f"創建向量存儲時發生錯誤: {str(e)}")return Nonedef NaiveRAG_main(arxiv_id, input):getNLTKData()# 加載論文documents = load_arxiv_paper(arxiv_id)if not documents:return# 存入 getParper.txt 文件中。with open("getPaper.txt", "w", encoding="utf-8") as f:for doc in documents:f.write(doc.page_content + "\n")# 處理文檔split_documents = process_documents(documents)if not split_documents:return# 將分割后的文本存入 getPaperChunk2.json 文件中chunks_data = {"total_chunks": len(split_documents),"chunks": []}for index, text in enumerate(split_documents, 1):chunk_info = {"chunk_id": f"chunk_{index}","page_content": text.page_content}chunks_data["chunks"].append(chunk_info)# 將JSON數據寫入文件with open("getPaperChunk2.json", "w", encoding="utf-8") as f:json.dump(chunks_data, f, ensure_ascii=False, indent=4)print(f"成功保存 {len(split_documents)} 個文本塊到 getPaperChunk2.json")# 創建向量存儲vectorstore = create_vector_store(split_documents)if not vectorstore:returnprint("向量存儲創建成功")retriever = vectorstore.as_retriever()doc = retriever.invoke(input)print(doc)system_prompt = ChatPromptTemplate.from_messages([("system", """根據提供的上下文: {context} \n\n 使用回答問題: {input}""")])# 初始化大模型llm = ChatOpenAI(api_key=os.getenv("DEEPSEEK_API_KEY"),base_url="https://api.deepseek.com/v1",model="deepseek-chat")# 構建鏈 這個鏈將文檔作為輸入,并使用之前定義的提示模板和初始化的大模型來生成答案chain = create_stuff_documents_chain(llm, system_prompt)res = chain.invoke({"input": input, "context": doc})print("最終答案:" + res)if __name__ == '__main__':NaiveRAG_main(arxiv_id="2402.19473", input="這篇論文講述了什么內容?")
requirements.txt依賴
logger~=1.4
langchain~=0.3.23
langchain-community~=0.3.21
langchain-text-splitters~=0.3.8
pandas~=2.2.3
arxiv~=2.2.0
pymupdf~=1.25.5
python-dotenv~=1.1.0
zhipuai~=2.1.5.20250415
總結
? ? ? ? 本篇文章以實現第一范式 RAG-Naive RAG為目標,使用langchain框架構造了一個基于Naive RAG的論文分析器的項目。然而隨著研究的深入,人們發現 Naive RAG 在檢索質量、響應生成質量以及增強過程中存在挑戰。于是 Advanced RAG 范式被提出,它在數據索引、檢索前和檢索后都進行了額外處理,如通過更精細的數據清洗等方法提升文本的一致性、準確性和檢索效率,在檢索前對問題進行重寫、路由和擴充等,檢索后對文檔庫進行重排序、上下文篩選與壓縮等。接下來小編會以LangChain 框架實現RAG 的第二范式Advanced RAG為目標,對Naive RAG項目進行重構。感興趣的小伙伴請關注小編的RAG 專欄,后續小編還會對Modular RAG 和 Agentic RAG 進行學習和總結,敬請期待!




)


)




)






