目錄
1、只出現一次的數字
2、寶石與石頭
3、壞鍵盤打字
4、復制帶隨機指針的鏈表
5、大量數據去重
6、大量數據重復次數
7、前K個高頻單詞
1、只出現一次的數字
oj:136. 只出現一次的數字 - 力扣(LeetCode)

思路:
1. 使用 Set2. 遍歷數組,如果Set中不包含當前元素,就add,包含就remove
3. 最后Set中剩的一個元素就是要找的元素
public int singleNumber(int[] nums) {//HashSet<Integer> set = new HashSet<>();TreeSet<Integer> set = new TreeSet<>();for(int x : nums) {if(!set.contains(x)) {set.add(x);}else {set.remove(x);}}//此時集合中只有一個元素了for(int x : nums) {if(set.contains(x)) {return x;}}return -1;}2、寶石與石頭
oj:771. 寶石與石頭 - 力扣(LeetCode)

思路:
1. 將寶石字符串轉化為一個字符數組,并把數組中每個字符都保存到Set集合中
2. 遍歷石頭字符串,如果當前位置的石頭在Set集合中存在,就把計數器++,最后返回計數器
public int numJewelsInStones(String jewels, String stones) {HashSet<Character> set = new HashSet<>();for(char ch : jewels.toCharArray()) {set.add(ch);}int count = 0;for(char ch : stones.toCharArray()) {if(set.contains(ch)) {count++;}}return count;}3、壞鍵盤打字
牛客:舊鍵盤 (20)__牛客網
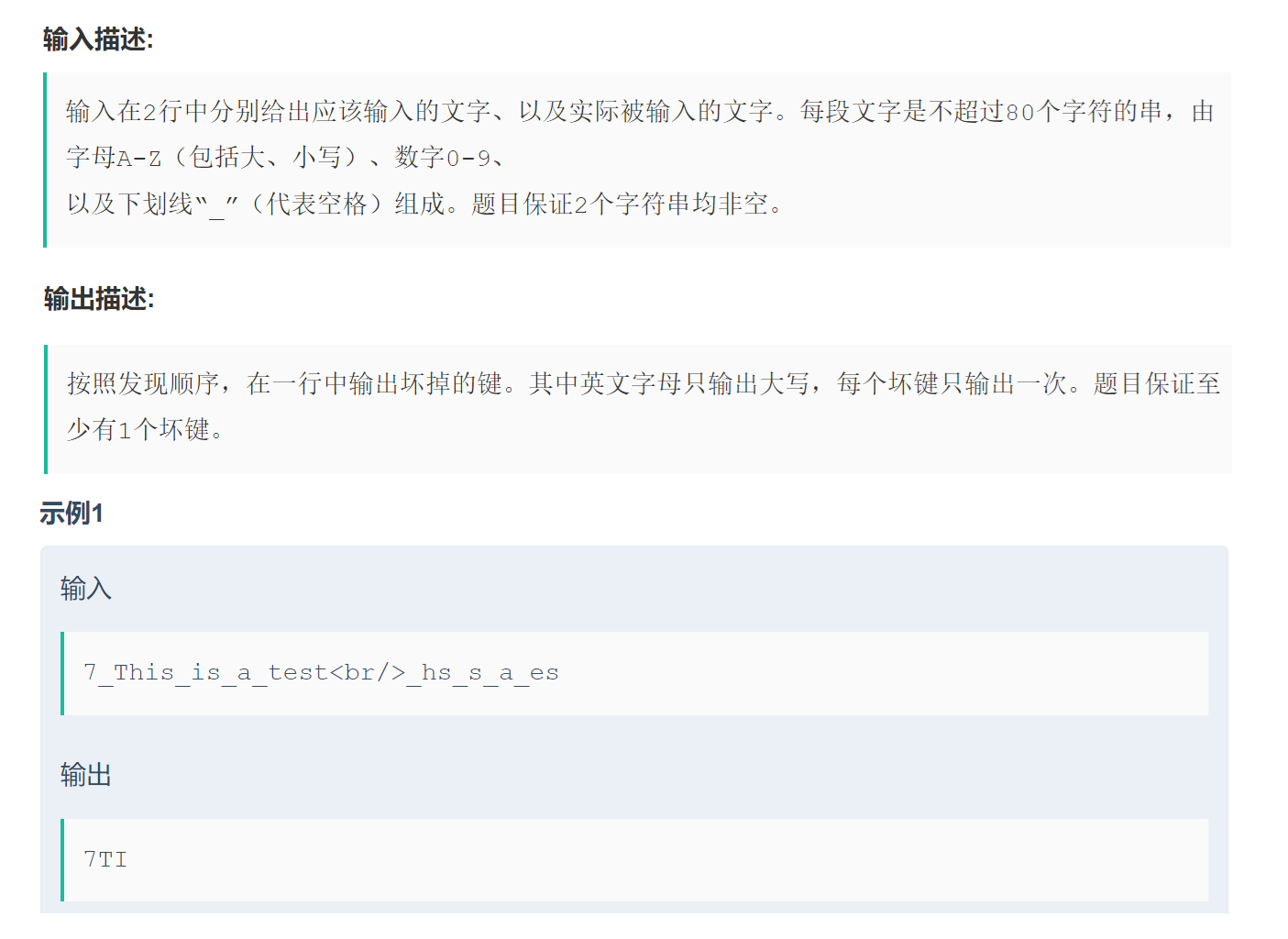
思路:
1. 將第二行字符串轉化成大寫,然后遍歷這個字符串,把每個字符都放在set中
2.?將第一行字符串轉化成大寫,然后遍歷這個字符串,把每個字符都放在set2中,當前字符在set中沒有并且在set2中也沒有,就打印
public static void main(String[] args) {Scanner in = new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的區別while (in.hasNextLine()) { // 注意 while 處理多個 caseString str1 = in.nextLine();String str2 = in.nextLine();func(str1,str2);}}private static void func(String str1,String str2) {HashSet<Character> set = new HashSet<>();for(char ch : str2.toUpperCase().toCharArray()) {set.add(ch);}HashSet<Character> set2 = new HashSet<>();for(char ch : str1.toUpperCase().toCharArray()) {if(!set.contains(ch) && !set2.contains(ch)) {System.out.print(ch);set2.add(ch);}}}4、復制帶隨機指針的鏈表
oj:138. 隨機鏈表的復制 - 力扣(LeetCode)
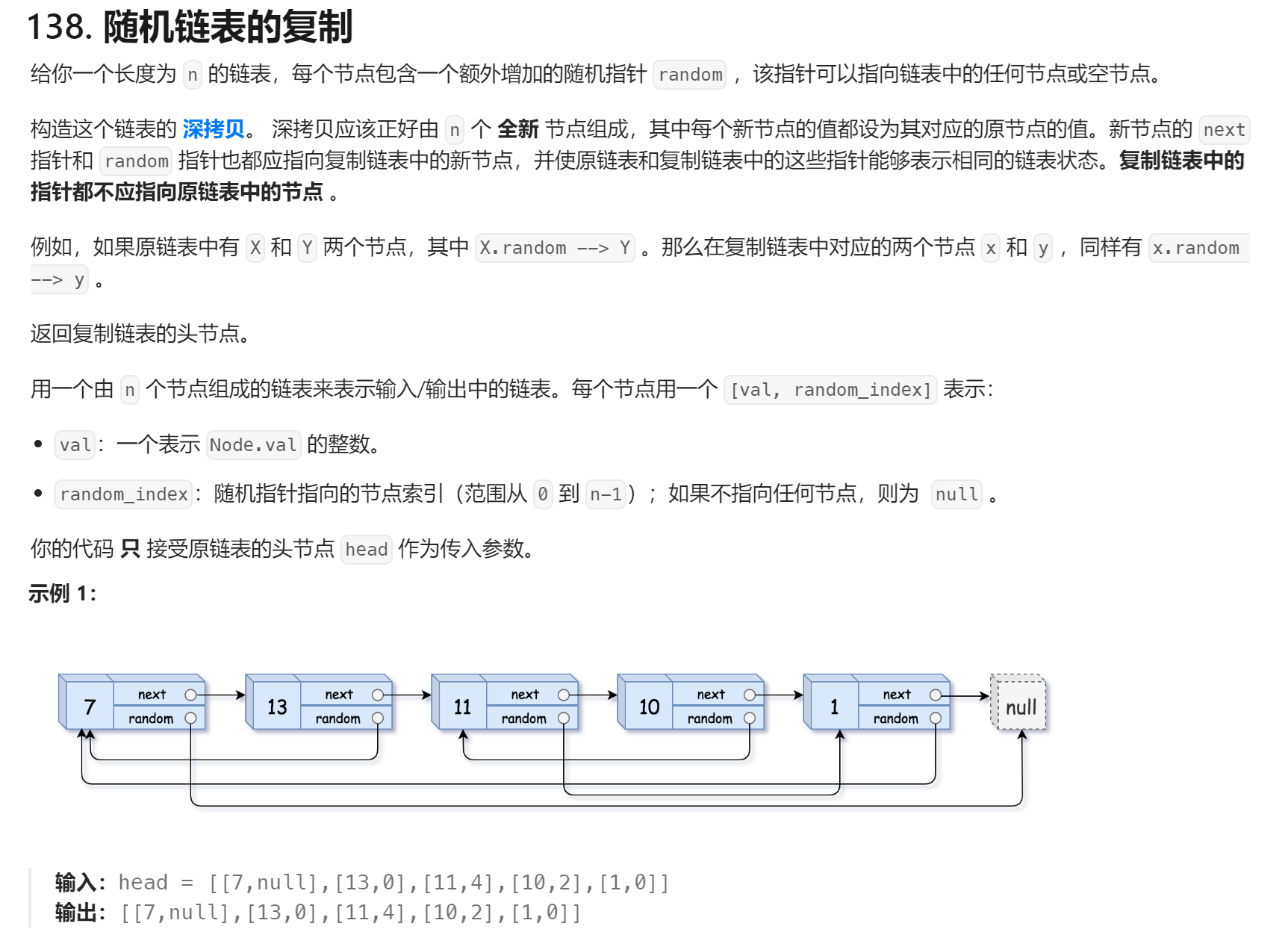
思路:
1. 遍歷鏈表,每遍歷到一個結點,就創建一個新結點,并把這兩個結點的地址以鍵值對的形式保存到Map中
2. 通過Map修改指向
????????map.get(cur).next = map.get(cur.next);
????????map.get(cur).random = map.get(cur.random);
3. 返回新鏈表的頭結點
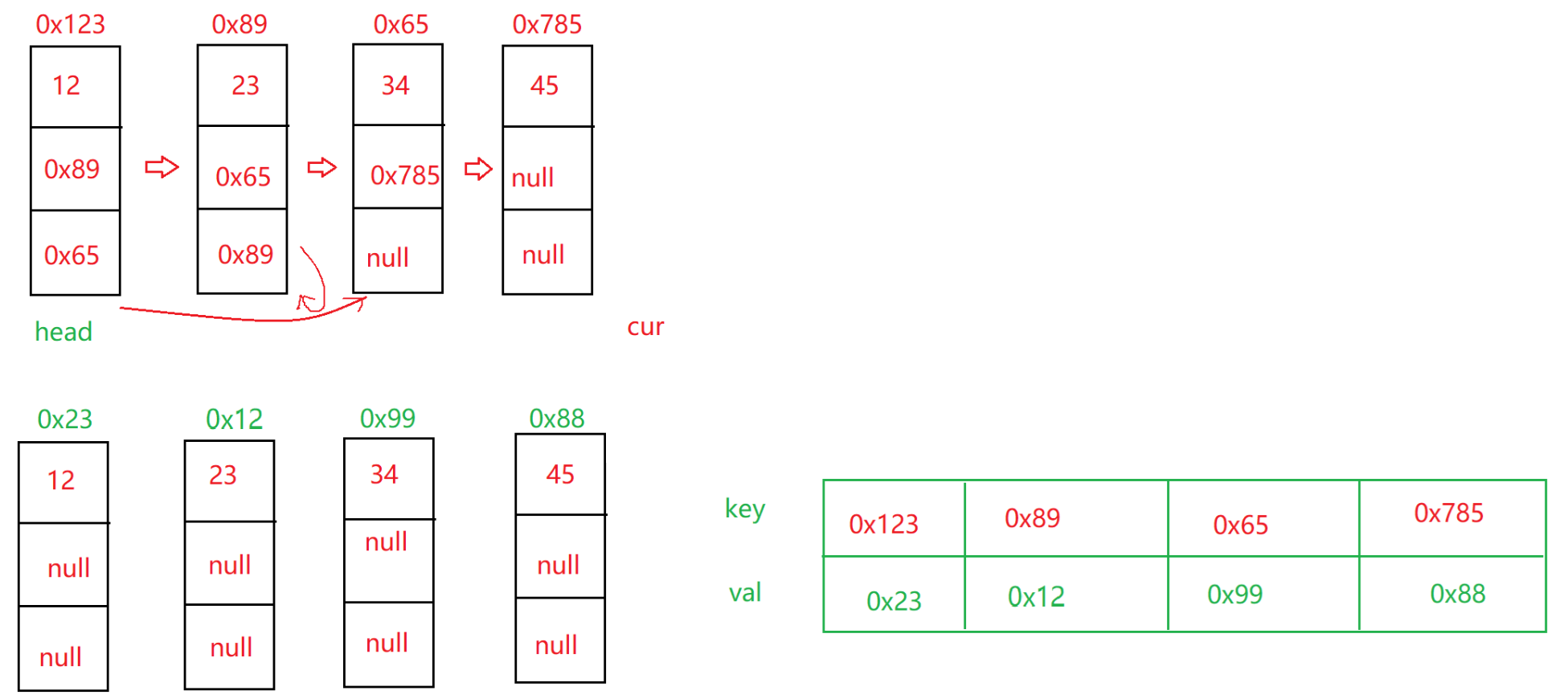
public Node copyRandomList(Node head) {Map<Node,Node> map = new HashMap<>();Node cur = head;//1. 第一次遍歷鏈表 存儲對應關系while(cur != null) {Node node = new Node(cur.val);map.put(cur,node);cur = cur.next;}//2. 第2次遍歷鏈表 開始修改每個節點的指向cur = head;while(cur != null) {map.get(cur).next = map.get(cur.next);map.get(cur).random = map.get(cur.random);cur = cur.next;}//3、返回head對應的地址return map.get(head);}5、大量數據去重
有10W個數據如何去除重復的數據,重復的數據只保留一份
public static void main(String[] args) {int[] array = {1,2,3,3,2};HashSet<Integer> set = new HashSet<>();for (int i = 0; i < array.length; i++) {set.add(array[i]);}System.out.println(set);}6、大量數據重復次數
有10W個數據,統計每個數據出現的次數
public static void main12(String[] args) {int[] array = {1,2,3,3,2};Map<Integer,Integer> map = new HashMap<>();for(Integer x : array) {if(map.get(x) == null) {//第一次存放map.put(x,1);}else {//其他情況在原來的基礎上加 1int val = map.get(x);map.put(x,val+1);}}for(Map.Entry<Integer,Integer> entry : map.entrySet()) {System.out.println("key: "+entry.getKey()+" val: "+entry.getValue());}}7、前K個高頻單詞
oj:692. 前K個高頻單詞 - 力扣(LeetCode)

public List<String> topKFrequent(String[] words, int k) {//1、先統計單詞出現的次數->存儲到了map當中Map<String,Integer> map = new HashMap<>();for(String word : words) {if(map.get(word) == null) {map.put(word,1);}else {int val = map.get(word);map.put(word,val+1);}}//2、遍歷好統計好的Map,把每組數據存儲到小根堆當中PriorityQueue<Map.Entry<String,Integer>> minHeap =new PriorityQueue<>(new Comparator<Map.Entry<String, Integer>>() {@Overridepublic int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) {//放元素的時候 如果頻率相同 我們轉變為大根堆-》按照單詞的字典序if(o1.getValue().compareTo(o2.getValue()) == 0) {// 也可以直接減return o2.getKey().compareTo(o1.getKey());}return o1.getValue().compareTo(o2.getValue());}});for(Map.Entry<String,Integer> entry : map.entrySet()) {if(minHeap.size() < k) {minHeap.offer(entry);}else {//你要找最大的頻率的單詞Map.Entry<String,Integer> top = minHeap.peek();if(top.getValue().compareTo(entry.getValue()) < 0) {minHeap.poll();minHeap.offer(entry);}else {//def->2 abc-> 2if(top.getValue().compareTo(entry.getValue()) == 0) {if(top.getKey().compareTo(entry.getKey()) > 0) {minHeap.poll();minHeap.offer(entry);}}}}}List<String> ret = new ArrayList<>();//放到了小根堆 2 3 4for (int i = 0; i < k; i++) {Map.Entry<String,Integer> top = minHeap.poll();ret.add(top.getKey());}// 2 3 4 -> 4 3 2Collections.reverse(ret);return ret;})




)







)
)
等級考試試卷(六級)真題)

 和main.go的使用規范)

