1 ES介紹及基本概念
ElasticSearch是一個基于Lucene 的分布式、高擴展、高實時的基于RESTful 風格API的搜索與數據分析引擎。
RESTful 風格API的特點:
- 接受HTTP協議的請求,返回HTTP響應;
- 請求的參數是JSON,返回響應的內容也是JSON格式;
- 請求的類型(GET、POST、PUT、DELETE)就代表對資源的操作類型。
1.1 基本概念
在Elasticsearch(ES)的體系中,各核心概念清晰且獨特,支撐著其強大的搜索與數據分析能力:
- 字段(Field):字段代表一種屬性,類似于關系型數據庫表中的列。在數據庫里,每一行數據由多個屬性值構成,比如員工表中,“姓名”“年齡”“職位”這些列就是字段,對應具體員工的數據,如“張三”“30”“工程師”就是字段值。在ES中,一個字段同樣承載特定的屬性信息,像一篇博客文章,“標題”“發布時間”“內容”等都可作為字段。
- 文檔(Document):ES的數據存儲方式與傳統關系型數據庫截然不同,所有數據均以JSON格式的document形式存在。document作為ES索引與搜索的最小數據單元,類比于數據庫中的一行數據。以電商平臺為例,一條商品信息記錄就是一個document,它由“商品名稱”“價格”“庫存”“描述”等多個字段值組成,可能像這樣:
{"商品名稱": "智能手表","價格": 1299,"庫存": 50,"描述": "具備多種健康監測功能的智能手表"
}
- 映射(Mapping):Mapping用于定義document中每個字段的類型、字段所采用的分詞器等細節,其作用等同于關系型數據庫中的表結構,為數據的存儲與處理提供規范。例如,在一個新聞資訊索引中,“標題”字段可定義為字符串類型,并使用標準分詞器,以便對標題進行合理切分用于搜索;“發布時間”字段定義為日期類型,方便按時間范圍檢索新聞。通過這樣的映射定義,ES能更高效地管理和利用數據。
- 索引(Index):Index是Elasticsearch存儲數據的載體,可理解為關系型數據庫中的數據庫概念,用于存放一類相同或相似的document。假設運營一個在線圖書館系統,可能會有“小說類書籍索引”“學術文獻索引”等。“小說類書籍索引”中存放的就是所有小說書籍相關的document,每個document包含書籍的名稱、作者、出版社、內容簡介等信息。
- 類型(Type):Type屬于邏輯層面的數據分類方式,一種Type類似于一張表,像常見的用戶表、訂單表等。在Elasticsearch 6.X版本中,默認Type為_doc ;而到了ES 7.x版本,Type這一概念已被移除 。在早期的論壇系統ES應用中,可能會設置“用戶類型”和“帖子類型”,“用戶類型”的document存儲用戶的賬號、密碼、注冊時間等信息;“帖子類型”的document存放帖子的標題、內容、發布者、發布時間等數據。但在7.x及之后版本,不再使用這種多類型區分方式,而是更強調數據的統一索引管理 。
1.2 ES原理與倒排索引
1.2.1 ES整體原理概述
ES 是一個分布式的搜索與數據分析引擎,基于 Lucene 構建。它將數據存儲在分布式的節點上,以實現高可用性、高擴展性和高性能。其核心工作流程圍繞索引和搜索兩個關鍵環節。在索引階段,數據被處理并構建索引結構;搜索階段則依據構建好的索引快速檢索出符合條件的數據。
1.2.2 倒排索引的概念
傳統數據庫使用的是正向索引,即從文檔 ID 到文檔內容及單詞位置的映射。而倒排索引恰恰相反,是從單詞到包含該單詞的文檔 ID 列表的映射。簡單來說,倒排索引就是將文檔中的每個單詞提取出來,記錄每個單詞在哪些文檔中出現過以及出現的位置等信息。
例如,有以下兩篇技術博客文章:
文章 1(ID=1):“Elasticsearch 是強大的搜索工具,適用于大數據場景。”
文章 2(ID=2):“學習技術博客寫作,掌握搜索技巧很重要,比如使用 Elasticsearch。”
倒排索引構建過程如下:
| 單詞 | 包含該單詞的文檔ID列表 |
|---|---|
| Elasticsearch | 1, 2 |
| 是 | 1 |
| 強大的 | 1 |
| 搜索 | 1, 2 |
| 工具 | 1 |
| 適用于 | 1 |
| 大數據 | 1 |
| 場景 | 1 |
| 學習 | 2 |
| 技術博客 | 2 |
| 寫作 | 2 |
| 掌握 | 2 |
| 技巧 | 2 |
| 很重要 | 2 |
| 比如 | 2 |
| 使用 | 2 |
這樣在搜索時,根據輸入的關鍵詞能快速定位到包含該關鍵詞的文檔,大大提高搜索效率。
1.2.3 以技術博客網站文章檢索為例
假設一個技術博客網站有大量文章,存儲在ES中。當用戶在搜索框輸入關鍵詞“Elasticsearch”進行檢索時,ES的工作流程如下:
- 用戶輸入:用戶在博客網站搜索框輸入“Elasticsearch”。
- 請求發送:網站將搜索請求發送給ES服務器。
- 倒排索引查詢:ES在倒排索引中查找“Elasticsearch”這個單詞,找到對應的文檔ID列表,即[1, 2]。
- 文檔獲取:根據文檔ID,從存儲文檔的地方獲取對應的兩篇文章內容。
- 結果返回:將這兩篇文章的相關信息(如標題、摘要等)返回給用戶展示。
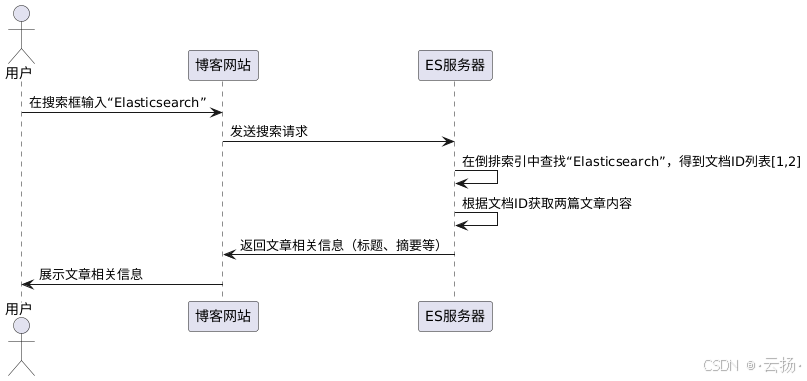
通過這種基于倒排索引的機制,ES能夠快速準確地從海量的技術博客文章中找到用戶需要的內容,為用戶提供高效的搜索體驗 。
2 ES環境搭建
2.1 Windows版安裝步驟
2.1.1 ElasticSearch安裝
- 安裝Java環境:下載并安裝JDK(Java Development Kit),并配置好Java環境變量。具體可參考相關Java安裝教程。
- 下載安裝包:從ElasticSearch官網下載適合Windows系統的zip安裝包。
注意:不要下載最新版本,最好根據IK分詞器的版本來下載,不然可能會沒有對應的分詞器版本
-
解壓文件:將下載后的zip文件解壓到指定目錄,例如
D:\elasticsearch。 -
啟動服務:進入解壓目錄下的
bin目錄,雙擊elasticsearch.bat文件啟動ElasticSearch服務。啟動后,在瀏覽器地址欄輸入http://localhost:9200/,若能看到ElasticSearch相關信息,說明啟動成功。

-
安裝為Windows服務(可選) :
- 設置環境變量:右鍵點擊“此電腦”,選擇“屬性”,點擊“高級系統設置”,在彈出窗口中點擊“環境變量”。在系統變量中新建變量,變量名可設為
ELASTICSEARCH_HOME,變量值為ElasticSearch的安裝目錄(如D:\elasticsearch);然后在Path變量中添加%ELASTICSEARCH_HOME%\bin。 - 安裝服務:以管理員身份運行命令提示符,進入ElasticSearch的
bin目錄,執行elasticsearch-service.bat install命令安裝服務。可使用elasticsearch-service.bat start啟動服務、elasticsearch-service.bat stop停止服務、elasticsearch-service.bat remove移除服務。
- 設置環境變量:右鍵點擊“此電腦”,選擇“屬性”,點擊“高級系統設置”,在彈出窗口中點擊“環境變量”。在系統變量中新建變量,變量名可設為
-
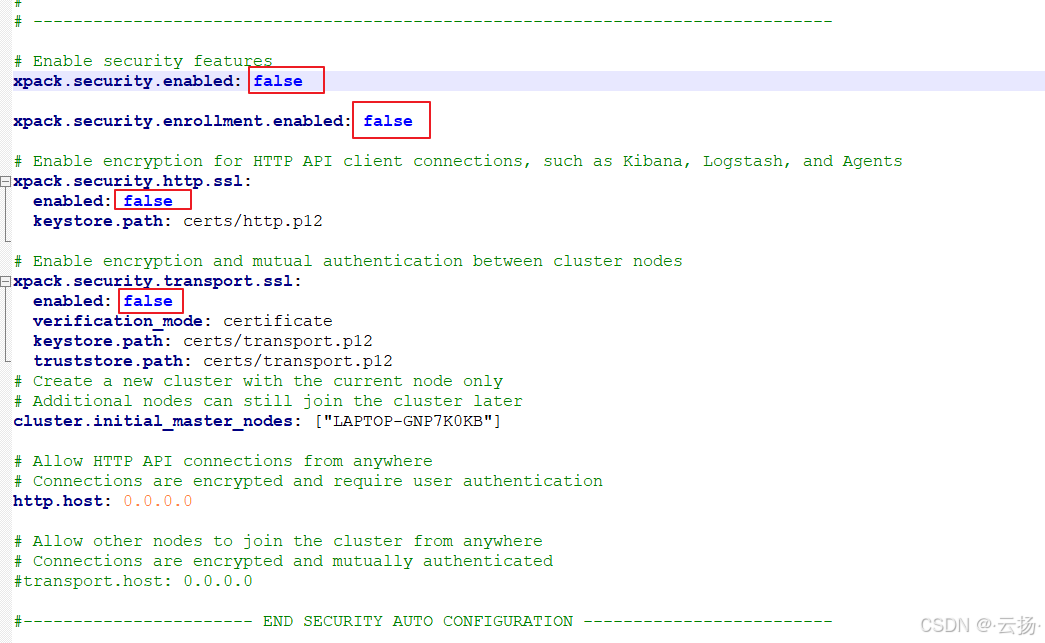
修改 Elasticsearch 配置為 HTTP(不推薦用于生產環境):如果發現啟動ES后無法訪問,打開 Elasticsearch 安裝目錄下的 config 文件夾,找到
elasticsearch.yml文件,修改配置之后再重啟ElasticSearch,即可正常訪問。
2.1.2 Kibana安裝
- 下載安裝包:從Kibana官網下載與ElasticSearch版本匹配的Windows版
.zip安裝包。 - 解壓文件:在D盤新建
kibana目錄,將下載的.zip文件解壓到該目錄下,解壓后得到kibana-版本號-windows-x86_64文件夾(即$KIBANA_HOME)。 - 配置文件:打開
$KIBANA_HOME\config\kibana.yml配置文件,設置elasticsearch.url為指向ElasticSearch實例地址,默認http://localhost:9200一般無需修改。如果ElasticSearch服務地址有變化,需相應調整。 - 啟動服務:進入
$KIBANA_HOME\bin目錄,雙擊kibana.bat啟動Kibana。啟動后可在瀏覽器輸入http://localhost:5601訪問Kibana界面。
2.1.3 IK分詞器安裝
- 下載:根據ElasticSearch版本,從https://github.com/medcl/elasticsearch-analysis-ik/releases下載對應的IK分詞器壓縮包。例如,若ElasticSearch是7.10.1版本,則下載
ik-710.1.zip。 - 解壓與放置:解壓下載的文件,將解壓后的文件夾復制到ElasticSearch安裝目錄下的
plugins文件夾內,并將文件夾重命名為analysis-ik。比如ElasticSearch安裝在D:\elasticsearch,則將文件夾復制到D:\elasticsearch\plugins\analysis-ik。 - 重啟ElasticSearch:以管理員身份運行
bin目錄下的elasticsearch.bat重啟ElasticSearch,即可加載IK分詞器。可通過發送請求測試分詞效果,如使用Postman等工具。
2.2 Ubuntu版(Linux版)安裝步驟
2.2.1 ElasticSearch安裝
- 下載和解壓:
- 從ElasticSearch官網(https://www.elastic.co/cn/downloads/elasticsearch )選擇合適版本下載,然后上傳到Ubuntu服務器。也可在命令行執行
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-版本號-linux-x86_64.tar.gz下載(下載速度可能較慢)。 - 執行解壓縮命令
tar -zxvf elasticsearch-版本號-linux-x86_64.tar.gz -C /usr/local。
- 從ElasticSearch官網(https://www.elastic.co/cn/downloads/elasticsearch )選擇合適版本下載,然后上傳到Ubuntu服務器。也可在命令行執行
- 配置JDK(若有沖突):新版本ElasticSearch壓縮包自帶JDK,若Ubuntu已安裝JDK且版本不符,啟動時會報錯。可切換到解壓目錄的
bin目錄,執行export JAVA_HOME=/usr/local/elasticsearch-版本號/jdk指定使用自帶JDK 。 - 創建專用用戶:
root用戶不能直接啟動ElasticSearch,需創建專用用戶,如user-es。使用命令useradd user-es創建用戶,passwd user-es設置密碼 。 - 修改配置文件:進入
config文件夾,編輯elasticsearch.yml文件。可修改http.port等參數,如http.port: 19200。還可根據需求配置集群相關參數等。 - 解決內存權限問題:若啟動報錯
max virtual memory areas vm.max_map_count (65530) is too low, increase to at least (262144),切換到root用戶(sudo su),編輯/etc/sysctl.conf文件,在文件末尾添加vm.max_map_count=262144,保存退出后執行sysctl -p刷新配置 。 - 啟動服務:切換到專用用戶(
su user-es),進入ElasticSearch的bin目錄,執行./elasticsearch啟動服務。啟動成功后可通過http://服務器IP:端口號(如http://127.0.0.1:19200)訪問,出現相關信息則安裝成功。

2.2.2 Kibana安裝
- 下載和解壓:從Kibana官網(https://www.elastic.co/cn/downloads/kibana )下載與ElasticSearch版本匹配的安裝包,例如
kibana-版本號-linux-x86_64.tar.gz。使用命令wget https://artifacts.elastic.co/downloads/kibana/kibana-版本號-linux-x86_64.tar.gz下載后,執行tar -zxvf kibana-版本號-linux-x86_64.tar.gz解壓 。 - 修改配置文件:進入解壓后的目錄,編輯
config/kibana.yml文件,配置內容如下:
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.url: "http://服務器IP:9200"
kibana.index: ".kibana"
將服務器IP替換為實際ElasticSearch服務器的IP地址。
3. 啟動服務:切換到解壓目錄的bin目錄,執行./kibana &(&表示在后臺運行)啟動Kibana。啟動過程中若ElasticSearch未啟動會有警告,連接成功后可通過瀏覽器訪問http://服務器IP:5601 。
2.2.3 IK分詞器安裝
- 下載:根據ElasticSearch版本,從https://github.com/medcl/elasticsearch-analysis-ik/releases下載對應的IK分詞器壓縮包。
- 解壓與放置:解壓下載的文件,將解壓后的文件夾(需命名為
analysis-ik)復制到ElasticSearch安裝目錄下的plugins文件夾內。比如ElasticSearch安裝在/usr/local/elasticsearch-版本號,則將文件夾復制到/usr/local/elasticsearch-版本號/plugins/analysis-ik。 - 重啟ElasticSearch:切換到啟動ElasticSearch的專用用戶,進入ElasticSearch的
bin目錄,執行./elasticsearch重啟服務,即可加載IK分詞器。
3 RESTful API操作ES
3.1 操作索引
- 添加索引
PUT user
向Elasticsearch集群添加名為user的索引。若索引已存在,會返回相應錯誤提示。
- 查詢單個索引
GET /teacher
獲取名為teacher的索引的相關信息,如索引的基本設置、映射等。若索引不存在,會返回404錯誤。
- 查詢多個索引
GET /user,student
同時獲取user和student兩個索引的相關信息。可一次性查看多個索引的狀態,方便對比和管理。
- 查詢所有索引
GET /_all
返回Elasticsearch集群中的所有索引的相關信息。在管理多個索引,需要快速了解整體索引情況時使用。
- 刪除索引
DELETE /student
從Elasticsearch集群中刪除名為student的索引及其包含的所有文檔數據。刪除操作不可逆,謹慎使用。
- 打開索引
POST /student/_open
將處于關閉狀態的student索引打開,使其可進行數據的讀寫和查詢操作。索引關閉時,對其進行的任何數據操作都會失敗。
- 關閉索引
POST /student/_close
關閉student索引,關閉后索引不可讀寫,但索引數據仍存儲在磁盤上。可用于在維護索引或減少資源占用時臨時關閉索引。
3.2 數據類型
3.2.1 簡單數據類型
我們先來看一個簡單的映射定義:
PUT teacher/_mapping
{"properties": {"id": {"type": "integer" },"name": {"type": "text"},"isMale": {"type": "boolean"}}
}
在定義映射的時候,類比于定義數據庫中的表結構,我們需要指明每一個字段的名稱,數據類型等等信息,所以我們先得了解映射中包含的數據類型。
-
字符串
- text:會分詞,不支持聚合
- keyword:不會分詞,將全部內容作為一個詞條,支持聚合
-
數值:long, integer, short, byte, double, float, half_float, scaled_float
-
布爾:boolean
-
二進制:binary
-
范圍類型:integer_range,float_range, long_range, double_range, date_range
-
日期:date
3.2.2 復雜數據類型
- 數組:[ ] 沒有專門的數組類型,ES會自動處理數組類型數據
比如說 給某一個字段 定義為 integer類型,那么這個字段是可以存儲 integer數組的,ES會自動處理
- 對象:{ } Object: object(for single JSON objects 單個JSON對象)
3.3 操作映射
- 給已存在索引添加映射
PUT /user/_mapping
{"properties":{"id": {"type":"integer"},"name":{"type":"keyword"},"age":{"type":"long"}}
}
為已存在的user索引添加字段映射,定義id為整數類型、name為關鍵詞類型、age為長整型。添加映射時,字段類型一旦確定,后續修改會受限制。
- 創建索引并指定映射
PUT teacher
{"mappings": {"properties": {"tid":{"type": "integer"},"tname":{"type": "text"}}}
}
創建名為teacher的索引,并同時指定其映射,定義tid為整數類型、tname為文本類型。在創建索引時規劃好映射,能確保數據存儲和查詢的準確性。
- 查詢映射
GET /teacher/_mapping
獲取teacher索引的映射信息,包括字段類型、分詞器設置等。方便查看索引的結構定義,排查查詢問題。
- 修改映射(只能添加字段)
PUT /teacher/_mapping
{"properties":{"height":{"type":"float"},"weight":{"type":"double"}}
}
向teacher索引的映射中添加height和weight字段,分別為浮點型和雙精度型。Elasticsearch不支持直接修改已存在字段的類型,只能添加新字段。
3.4 操作文檔
- 添加文檔 - 指定文檔id
POST /user/_doc/1
{"id": 1001,"name":"賈寶玉","age":15
}
向user索引中添加一個文檔,并指定文檔的id為1。若指定id的文檔已存在,會覆蓋原有文檔。
- 添加文檔 - 不指定文檔id
POST /user/_doc
{"id":1002,"name":"賈迎春","age":13
}
向user索引添加文檔,Elasticsearch會自動生成一個唯一的文檔id。適用于對文檔id無特定要求的場景。
- 查詢文檔 - 根據文檔id查詢
GET /user/_doc/1
GET /user/_doc/NsORPo0BJehhapNsslSw
根據文檔id獲取user索引中的文檔。若文檔不存在,會返回404錯誤。
- 查詢文檔 - 查詢所有文檔
GET /user/_search
獲取user索引中的所有文檔。在數據量較大時,可能需要結合分頁參數使用,避免一次性返回過多數據。
- 修改文檔 - 直接覆蓋
POST /user/_doc/1
{"id": 2001,"name":"劉姥姥","age":80
}
用新的文檔數據覆蓋user索引中id為1的文檔。會完全替換原有文檔內容,包括所有字段。
- 修改指定字段
POST /user/_update/1
{"doc": {"name":"賈璉","age": 30}
}
僅修改user索引中id為1的文檔的name和age字段,其他字段保持不變。比直接覆蓋更靈活,可減少數據傳輸量。
- 刪除文檔(指定文檔id)
DELETE /user/_doc/1
刪除user索引中id為1的文檔。刪除操作不可逆,操作前需確認數據是否不再需要。
3.5 IK分詞器測試
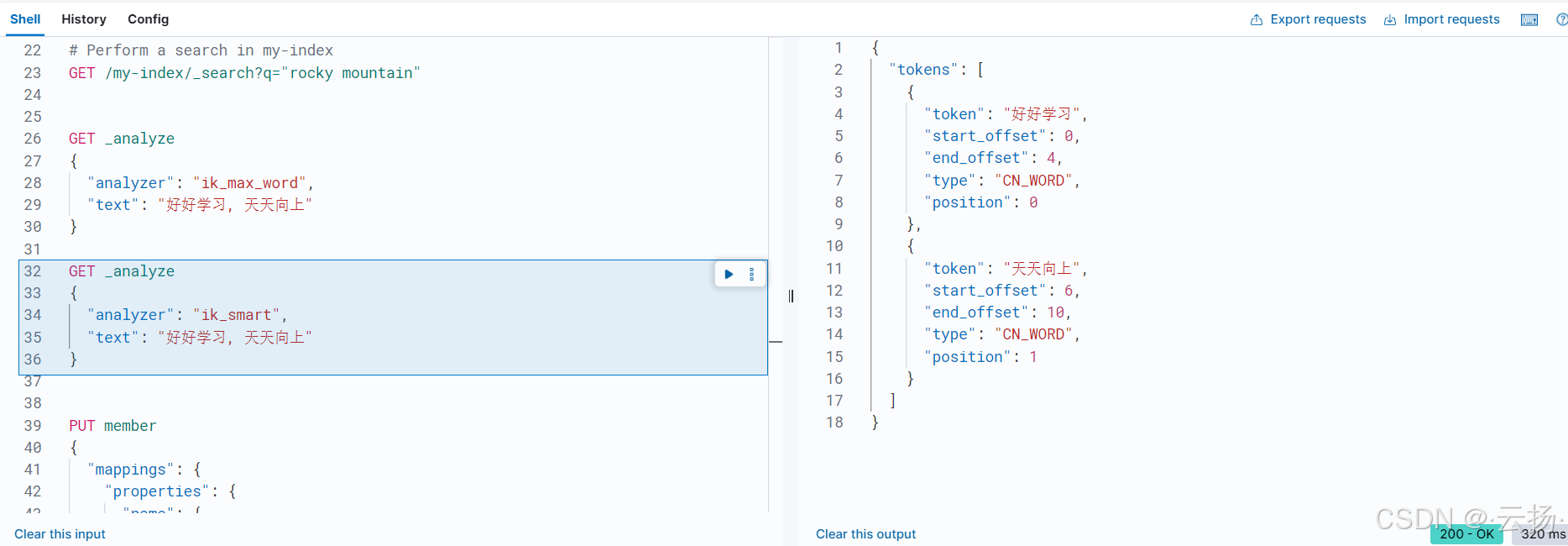
- ik_max_word分詞模式
GET /_analyze
{"text": "湖南是全國唯一一個叫湖南的省份","analyzer": "ik_max_word"
}
使用ik_max_word分詞器對文本進行分詞,它會盡可能細粒度地切分文本,如上述文本會被切分成“湖南”“是”“全國”“唯一”“一個”“叫”“湖南”“的”“省份”等多個詞條。
- ik_smart分詞模式
GET /_analyze
{"text": "湖南是全國唯一一個叫湖南的省份","analyzer": "ik_smart"
}
ik_smart分詞器的粒度更粗,會對文本進行更合理的合并切分,上述文本可能被切分成“湖南”“是”“全國”“唯一一個”“叫”“湖南的省份”等詞條。
- 使用ES自帶的分詞器
GET /_analyze
{"text": "stone is best man, ciggar is handsome man","analyzer": "standard"
}
使用ES自帶的standard分詞器對英文文本進行分詞,它會按空格和標點符號進行切分,并將單詞轉換為小寫形式,如上述文本會被切分成“stone”“is”“best”“man”“ciggar”“is”“handsome”“man”等詞條。
3.6 ES批量操作
- 創建索引并設置映射
DELETE /teacher
PUT /teacher
{"mappings": {"properties": {"id":{"type": "integer"},"name":{"type": "text","analyzer": "ik_max_word"},"age":{"type": "integer"}}}
}
先刪除可能存在的teacher索引,再創建新的teacher索引,并設置其映射。其中name字段使用ik_max_word分詞器進行分詞。
- 查詢索引中的所有文檔
GET /teacher/_search
獲取teacher索引中的所有文檔,用于查看當前索引中的數據內容。
- 批量操作
POST /_bulk
{"create":{"_index":"teacher","_id":"1"}}
{"id":1,"name":"金角大王","age":30}
{"create":{"_index":"teacher","_id":"2"}}
{"id":2,"name":"銀角大王","age":20}
{"create":{"_index":"teacher","_id":"3"}}
{"id":3,"name":"小鉆風","age":10}
{"delete":{"_index":"teacher","_id":"1"}}
{"update":{"_index":"teacher","_id":"2"}}
{"doc":{"name":"獅駝嶺","age":1000}}
在一次請求中對teacher索引執行多個操作,包括創建文檔(create)、刪除文檔(delete)和更新文檔(update)。批量操作可減少網絡請求次數,提高數據處理效率。
- 創建另一個索引并設置映射
PUT /member
{"mappings": {"properties": {"id":{"type": "integer"},"name":{"type": "keyword"},"addr":{"type": "text","analyzer": "ik_max_word"},"gender":{"type": "keyword"},"money":{"type": "integer"}}}
}
創建名為member的索引,并設置其映射。addr字段使用ik_max_word分詞器,方便對地址進行分詞查詢。
- 查詢索引信息
GET /member/_search
GET /member/_mapping
分別查詢member索引中的所有文檔和獲取member索引的映射信息,用于了解索引的數據和結構。
3.7 ES高級查詢
- match_all查詢
GET /member/_search
{"query": {"match_all": {}},"from": 0,"size": 3
}
查詢member索引中的所有文檔,并指定從第0條開始,返回3條數據。常用于獲取索引的部分數據樣本,或在不關心具體查詢條件時獲取全部數據。
- term查詢
GET /member/_search
{"query": {"term": {"addr": {"value": "山區"}}}
}
在member索引中查詢addr字段值為“山區”的文檔。term查詢不會對搜索關鍵字進行分詞,直接與目標字段進行精確匹配。
- 全文查詢 - match
GET /member/_search
{"query": {"match": {"addr": "湖北武漢"}}
}
對member索引的addr字段進行全文查詢,會對搜索關鍵字“湖北武漢”進行分詞,然后與addr字段的分詞結果進行匹配。默認取并集,即只要匹配到其中一個分詞結果的文檔就會被返回。
- 模糊查詢 - 通配符查詢
GET /member/_search
{"query": {"wildcard": {"addr": {"value": "武?"}}}
}
在member索引中查詢addr字段值以“武”開頭且后面跟任意一個字符的文檔。?表示占位,*表示通配任意多個字符。
- 正則查詢
GET /member/_search
{"query": {"regexp": {"addr": "[A-Z a-z 0-9_]+(.)*"}}
}
使用正則表達式對member索引的addr字段進行查詢,匹配由字母、數字、下劃線組成且后面可跟任意字符的地址。
- 前綴查詢
GET /member/_search
{"query": {"prefix": {"addr": {"value": "青"}}}
}
在member索引中查詢addr字段值以“青”開頭的文檔。前綴查詢不太適用于text類型字段,因為text類型字段會被分詞,可能導致查詢結果不準確。
- queryString多條件查詢
GET /member/_search
{"query": {"query_string": {"fields": ["addr","gender"], "query": "武漢 AND 男"}}
}
在member索引中查詢addr字段包含“武漢”且gender字段為“男”的文檔。注意AND和OR要大寫,且不要使用simple_query_string,它不會識別AND或OR關鍵字。
- 排序查詢
GET /member/_search
{"query": {"match_all": {}},"sort": [{"money": {"order": "asc"}}]
}
查詢member索引中的所有文檔,并按money字段的值進行升序排序。可根據需求指定其他字段進行排序,以及選擇升序(asc)或降序(desc)。
- 范圍查詢
GET /member/_search
{"query": {"range": {"money": {"gte": 300,"lte": 600}}},"sort": [{"money": {"order": "desc"}}],"from": 0,"size": 3
}
在member索引中查詢money字段值在300到600之間的文檔,并按money字段的降序排序,返回前3條數據。
3.8 bool查詢
- must條件
GET /member/_search
{"query": {"bool": {"must": [{"term": {"addr": {"value": "武漢"}}},{"term": {"gender": {"value": "女"}}}]}}
}
查詢member索引中addr字段為“武漢”且gender字段為“女”的文檔,會計算文檔的近似度得分。must條件下的所有子條件都必須滿足才能匹配到文檔。
- filter條件
GET /member/_search
{"query": {"bool": {"filter": [{"match": {"addr": "湖北武漢"}},{"range": {"money": {"gte": 200,"lte": 500}}}]}}
}
查詢member索引中addr字段包含“湖北武漢”且money字段值在200到500之間的文檔,filter不會計算近似度得分,查詢效率更高,適用于不需要計算得分的精確過濾場景。
- must_not條件
GET /member/_search
{"query": {"bool": {"must_not": [{"match": {"addr": "武漢"}},{"term": {"gender": {"value": "女"}}}]}}
}
查詢member索引中addr字段不包含“武漢”且gender字段不為“女”的文檔,同樣不會計算近似度得分。
- should條件
GET /member/_search
{"query": {"bool": {"should": [{"term": {"addr": {"value": "武漢"}}},{"term": {"gender": {"value": "女"}}}]}}
}
查詢member索引中addr字段為“武漢”或者gender字段為“女”的文檔,會計算近似度得分。只要滿足should中的一個子條件,文檔就可能被返回。
- 綜合練習
GET /member/_search
{"query": {"bool": {"filter": [{"range": {"money": {"gte": 200,"lte": 600}}},{"term": {"gender": "男"}}],"must": [{"match": {"addr": "湖北武漢"}}]}}
}
查詢member索引中money字段值在200到600之間、gender為“男”且addr包含“湖北武漢”的文檔。
4 技術派整合ES
4.1 構造 RestHighLevelClient 客戶端
- 引入依賴:在
paicoding-service模塊的 pom 文件中,我們需要引入 es 和 es-client 相關的依賴。具體的依賴配置如下:
<!--引入es-high-level-client相關依賴 start-->
<dependency><groupId>org.elasticsearch</groupId><artifactId>elasticsearch</artifactId><version>6.8.2</version>
</dependency><dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-client</artifactId><version>6.8.2</version>
</dependency>
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>6.8.2</version>
</dependency>
- 配置 yml 文件:在
paicoding-web模塊的src->main->resource-env->dev->application-dal.yml中,配置 ES 的相關信息。具體配置如下:
# elasticsearch配置
elasticsearch:# 是否開啟ES?本地啟動如果沒有安裝ES,可以設置為false關閉ESopen: false# es集群名稱clusterName: elasticsearchhosts: 127.0.0.1:9200userName: elasticpassword: elastic# es 請求方式scheme: http# es 連接超時時間connectTimeOut: 1000# es socket 連接超時時間socketTimeOut: 30000# es 請求超時時間connectionRequestTimeOut: 500# es 最大連接數maxConnectNum: 100# es 每個路由的最大連接數maxConnectNumPerRoute: 100
在配置 yml 文件時,一定要注意格式的正確性,避免因格式錯誤導致配置失效。
- 編寫 config 配置類
RestHighLevelClient:配置類的作用是將 RestHighLevelClient 客戶端的創建交由 Spring 管理。具體的配置類代碼如下:
/*** es配置類** @author ygl* @since 2023-05-25**/
@Slf4j
@Data
@Configuration
// 下面這個表示只有 elasticsearch.open = true 時,采進行es的配置初始化;當不使用es時,則不會實例 RestHighLevelClient
@ConditionalOnProperty(prefix = "elasticsearch", name = "open")
@ConfigurationProperties(prefix = "elasticsearch")
public class ElasticsearchConfig {// 是否開啟ESprivate Boolean open;// es host ip 地址(集群)private String hosts;// es用戶名private String userName;// es密碼private String password;// es 請求方式private String scheme;// es集群名稱private String clusterName;// es 連接超時時間private int connectTimeOut;// es socket 連接超時時間private int socketTimeOut;// es 請求超時時間private int connectionRequestTimeOut;// es 最大連接數private int maxConnectNum;// es 每個路由的最大連接數private int maxConnectNumPerRoute;/*** 如果@Bean沒有指定bean的名稱,那么這個bean的名稱就是方法名*/@Bean(name = "restHighLevelClient")public RestHighLevelClient restHighLevelClient() {// 此處為單節點esString host = hosts.split(":")[0];String port = hosts.split(":")[1];HttpHost httpHost = new HttpHost(host, Integer.parseInt(port));// 構建連接對象RestClientBuilder builder = RestClient.builder(httpHost);// 設置用戶名、密碼CredentialsProvider credentialsProvider = new BasicCredentialsProvider();credentialsProvider.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials(userName, password));// 連接延時配置builder.setRequestConfigCallback(requestConfigBuilder -> {requestConfigBuilder.setConnectTimeout(connectTimeOut);requestConfigBuilder.setSocketTimeout(socketTimeOut);requestConfigBuilder.setConnectionRequestTimeout(connectionRequestTimeOut);return requestConfigBuilder;});// 連接數配置builder.setHttpClientConfigCallback(httpClientBuilder -> {httpClientBuilder.setMaxConnTotal(maxConnectNum);httpClientBuilder.setMaxConnPerRoute(maxConnectNumPerRoute);httpClientBuilder.setDefaultCredentialsProvider(credentialsProvider);return httpClientBuilder;});return new RestHighLevelClient(builder);}
}
需要注意的是,在 yml 中的 elasticsearch.hosts 配置中,不要添加 https 前綴,只需填寫 127.0.0.1:9200 即可,否則在配置類中創建 HttpHost 時會出錯。
4.2 技術派首頁全局查詢走 ES 數據庫
在進行 ES 查詢整合之前,我們先來了解一下大致的邏輯:
- 根據查詢條件在 ES 中查詢數據。
- 從查詢結果中提取出 id,并將這些 id 添加到 ids 集合中。
- 使用 ids 集合去 MySQL 數據庫中查詢相應的數據。
通過這種方式,可以大大提高查詢的效率,相比直接在 MySQL 中進行 like% 值 % 的查詢,性能有顯著提升。
在 paicoding-service 模塊的 ArticleReadServiceImpl 類中,我們需要注入 RestHighLevelClient 客戶端,然后編寫實現代碼。具體代碼如下:
public List<SimpleArticleDTO> querySimpleArticleBySearchKey(String key) {// TODO 當KEY為空時,返回熱門推薦if (StringUtils.isBlank(key)) {return Collections.emptyList();}key = key.trim();SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();MultiMatchQueryBuilder multiMatchQueryBuilder = QueryBuilders.multiMatchQuery(key,ESFieldConstant.ES_FIELD_TITLE,ESFieldConstant.ES_FIELD_SHORT_TITLE);searchSourceBuilder.query(multiMatchQueryBuilder);SearchRequest searchRequest = new SearchRequest(new String[]{ESIndexConstant.ES_INDEX_ARTICLE}, searchSourceBuilder);SearchResponse searchResponse = null;try {searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);} catch (IOException e) {e.printStackTrace();}SearchHits hits = searchResponse.getHits();SearchHit[] hitList = hits.getHits();List<Integer> ids = new ArrayList<>();for (SearchHit documentFields : hitList) {ids.add(Integer.parseInt(documentFields.getId()));}if (ObjectUtils.isEmpty(ids)) {return null;}List<ArticleDO> records = articleDAO.selectByIds(ids);return records.stream().map(s -> new SimpleArticleDTO().setId(s.getId()).setTitle(s.getTitle())).collect(Collectors.toList());
}
4.3 兼容未安裝 ES 繼續走 MySQL 查詢
考慮到有些小伙伴可能沒有安裝 ES 和 Canal,為了保證代碼在這種情況下也能正常運行,我們進行了兼容性處理,使得在未安裝 ES 時,首頁查詢依然可以走 MySQL 數據庫。
首先,在 yml 中增加了是否開啟 ES 的配置項:
# elasticsearch配置
elasticsearch:# 是否開啟ES?本地啟動如果沒有安裝ES,可以設置為false關閉ESopen: true# es集群名稱clusterName: elasticsearchhosts: 127.0.0.1:9200userName: elasticpassword: elastic# es 請求方式scheme: http# es 連接超時時間connectTimeOut: 1000# es socket 連接超時時間socketTimeOut: 30000# es 請求超時時間connectionRequestTimeOut: 500# es 最大連接數maxConnectNum: 100# es 每個路由的最大連接數maxConnectNumPerRoute: 100
然后,在 Service 層將 open 值注入:
@Value("${elasticsearch.open}")
private Boolean openEs;
最后,在業務層的代碼中實現兼容邏輯:
@Override
public List<SimpleArticleDTO> querySimpleArticleBySearchKey(String key) {// TODO 當KEY為空時,返回熱門推薦if (StringUtils.isBlank(key)) {return Collections.emptyList();}// 如果沒有開啟ES,那么繼續從MYSQL中獲取數據if (!openEs) {List<ArticleDO> records = articleDAO.listSimpleArticlesBySearchKey(key);return records.stream().map(s -> new SimpleArticleDTO().setId(s.getId()).setTitle(s.getTitle())).collect(Collectors.toList());}// ES整合邏輯key = key.trim();SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();MultiMatchQueryBuilder multiMatchQueryBuilder = QueryBuilders.multiMatchQuery(key,ESFieldConstant.ES_FIELD_TITLE,ESFieldConstant.ES_FIELD_SHORT_TITLE);searchSourceBuilder.query(multiMatchQueryBuilder);SearchRequest searchRequest = new SearchRequest(new String[]{ESIndexConstant.ES_INDEX_ARTICLE}, searchSourceBuilder);SearchResponse searchResponse = null;try {searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);} catch (IOException e) {e.printStackTrace();}SearchHits hits = searchResponse.getHits();SearchHit[] hitList = hits.getHits();List<Integer> ids = new ArrayList<>();for (SearchHit documentFields : hitList) {ids.add(Integer.parseInt(documentFields.getId()));}if (ObjectUtils.isEmpty(ids)) {return null;}List<ArticleDO> records = articleDAO.selectByIds(ids);return records.stream().map(s -> new SimpleArticleDTO().setId(s.getId()).setTitle(s.getTitle())).collect(Collectors.toList());
}
5 ES集群相關知識
5.1 ES集群基礎概念
- 定義與組成:Elasticsearch(ES)集群是由多個ES節點組成的集合 ,節點間協同工作,實現數據存儲、搜索及分析功能。
- 優勢
- 效率提升:多節點并行處理搜索請求,相比單節點搜索效率更高。
- 存儲擴容:突破單節點磁盤空間限制,利用多個節點存儲資源,擴大數據存儲容量。
- 高可用性:部分節點故障時,集群仍能對外提供服務,保障整體可用性。
5.2 ES集群節點
- 節點類型
- 主節點(Master Node):負責管理集群元數據,如索引創建、刪除,分片分配,監控節點狀態等。為防止腦裂,一般設置奇數個主節點。腦裂是指在集群中,多個節點都認為自己是主節點,導致集群出現多個“大腦”,從而使集群狀態混亂、數據不一致等問題。設置奇數個主節點,是因為在選舉主節點時,奇數個節點能避免出現平局情況,降低腦裂風險 。
- 數據節點(Data Node):用于存儲數據,執行數據的增、刪、改、查及聚合操作,需根據數據量和查詢需求合理配置資源。
- 協調節點(Coordinate Node):不承擔主節點和數據節點功能,專門負責接收請求、轉發請求至其他節點、匯總返回數據。大規模集群并發查詢量大時,可添加獨立協調節點。
- Ingest節點:對文檔數據進行預處理,如通過管道實現數據轉換與豐富,可按需水平擴展。一個節點可兼具多種角色,小規模集群可不嚴格區分。
- 節點協作:數據節點向主節點發送心跳數據包匯報狀態,主節點依此監控集群狀態。
5.3 ES集群分片
- 主分片(Primary Shard)
- 定義:將索引文檔數據分散存儲的單元,所有主分片數據合起來構成完整索引數據,主分片數量至少為1 。
- 作用:承載索引的原始數據存儲,是數據寫入和讀取的基礎單元。
- 副本分片(Replica Shard)
- 定義:主分片的備份,數量大于等于0 。
- 作用:提高數據可用性和查詢性能,主分片故障時可頂替提供服務,還可分擔查詢負載。
- 分片規則
- 主分片和副本分片不能存儲在同一節點上。
- 單節點ES可有多主分片,但無副本分片。
- 創建索引時可指定主、副本分片數量,索引創建后,主分片數量不可更改,僅副本分片數量可調整。

5.4 文檔在ES集群中的操作
-
存儲流程
- 用戶將存儲請求發送到集群中任意一個節點。
- 接收請求的節點通過文檔路由,把數據發送給對應的主分片。
- 主分片將數據同步給它的所有副本分片。

-
搜索流程
- 用戶向集群中任意一個節點發起搜索請求。
- 接收請求的節點(協調節點)把每個主分片和它的副本分片看作“同一組”分片,從中選擇一組有完整數據的分片(默認輪訓選擇),然后分發請求。
- 被選中的分片進行查詢,之后返回結果。
- 協調節點把收到的結果聚合,返回給用戶。

5.5 ES 集群相關問題及解決
- 腦裂問題:因網絡問題,集群被分成兩個,出現兩個 “大腦”(主節點) ,導致數據不一致 。解決方法包括設置
- 最小主節點數量,計算公式為
discovery.zen.minimum_master_nodes: (有master資格節點數/2) + 1; - 設置專門奇數個主節點;
- 采用單播發現機制(關閉多播發現機制
discovery.zen.ping.multicast.enabled: false,配置單播發現主節點 ip 地址discovery.zen.ping.unicast.hosts : ("master1", "master2", "master3") ); - 配置選舉發現數,延長 ping master 等待時長(如
discovery.zen.ping_timeout: 30 ,discovery.zen.minimum_master_nodes: 2) 。
- 最小主節點數量,計算公式為
- 分片數量配置:索引分片數指定后一般不可更改,除非重做索引 。ElasticSearch 推薦最大 JVM 堆空間 30 - 32G ,可據此估算分片數量,如預計數據量 200GB ,最多分配 7 - 8 個分片 。初始階段,可按節點數量的 1.5 - 3 倍創建分片,如 3 個節點,分片數最多不超 9 個 。對于基于日期、搜索少、數據量小(如每個索引 1GB 甚至更小 )的索引需求,如日志管理,建議分配 1 個分片 。

6 總結
本文全面講解 ElasticSearch(ES)相關知識。ES 是基于 Lucene 的分布式搜索與分析引擎,有分布式、高擴展、高實時特性,采用 RESTful 風格 API 。介紹了字段、文檔等基本概念,基于倒排索引的原理。詳述 Windows 和 Ubuntu 版搭建步驟,RESTful API 操作及 ES 集成。還提及 ES 集群中的腦裂問題,主節點在管理集群元數據中起關鍵作用,為防止腦裂,通常設置奇數個主節點,避免選舉時出現平局,降低集群狀態混亂、數據不一致等風險。
7 參考鏈接
- 技術派實現ES查詢
- 項目倉庫(GitHub)
- 項目倉庫(碼云)
)

)


復現)



![Visio繪圖工具全面科普:解鎖專業圖表繪制新境界[特殊字符]](http://pic.xiahunao.cn/Visio繪圖工具全面科普:解鎖專業圖表繪制新境界[特殊字符])


)



)


