目錄
- 幾何著色器
- 爆破物體
- 法向量可視化
- 實例化(偏移量存在uniform中)
- 實例化數組(偏移量存在頂點屬性中)
- 小行星帶
- 抗鋸齒
- SSAA(Super Sample Anti-aliasing)
- MSAA(Multi-Sampling Anti-aliasing)
- OpenGL中的MSAA
- 離屏MSAA
- 多重采樣紋理附件
- 多重采樣渲染緩沖對象
- 渲染到多重采樣幀緩沖
- 自定義抗鋸齒算法
GitHub主頁:https://github.com/sdpyy1
OpenGL學習倉庫:https://github.com/sdpyy1/CppLearn/tree/main/OpenGLtree/main/OpenGL):https://github.com/sdpyy1/CppLearn/tree/main/OpenGL
幾何著色器
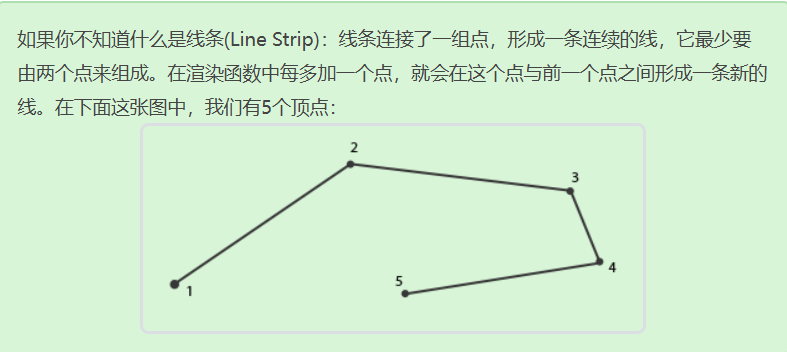
在頂點著色器和片段著色器中間還可以添加一個幾何著色器(Geometry Shader),輸入為圖元,可以將頂點進行隨意的變換。它能夠將(這一組)頂點變換為完全不同的圖元,并且還能生成比原來更多的頂點。
下面是頂點著色器的一個例子
#version 330 core
layout (points) in;
layout (line_strip, max_vertices = 2) out;void main() { gl_Position = gl_in[0].gl_Position + vec4(-0.1, 0.0, 0.0, 0.0); EmitVertex();gl_Position = gl_in[0].gl_Position + vec4( 0.1, 0.0, 0.0, 0.0);EmitVertex();EndPrimitive();
}
其中layout (points) in;用于聲明圖元的類型(可以是點、線、三角形等待),接下來還需要指定輸出的圖元類型,這里輸出的是line_strip,將最大頂點數設置為2個(EmitVertex()最多執行兩次)。
為了生成更有意義的結果,我們需要某種方式來獲取前一著色器階段的輸出。GLSL提供給我們一個名為gl_in的內建(Built-in)變量,在內部看起來(可能)是這樣的:
in gl_Vertex
{vec4 gl_Position;float gl_PointSize;float gl_ClipDistance[];
} gl_in[];
要注意的是,它被聲明為一個數組,因為大多數的渲染圖元包含多于1個的頂點,而幾何著色器的輸入是一個圖元的所有頂點。
下面意思就是在輸入圖元是點時,輸出點是把這個點左移一個單位和右移一個單位的兩個點連成的線
void main() {gl_Position = gl_in[0].gl_Position + vec4(-0.1, 0.0, 0.0, 0.0); EmitVertex();gl_Position = gl_in[0].gl_Position + vec4( 0.1, 0.0, 0.0, 0.0);EmitVertex();EndPrimitive();
}
通過這個幾何著色器,輸入4個頂點渲染時,輸出會變成四條線
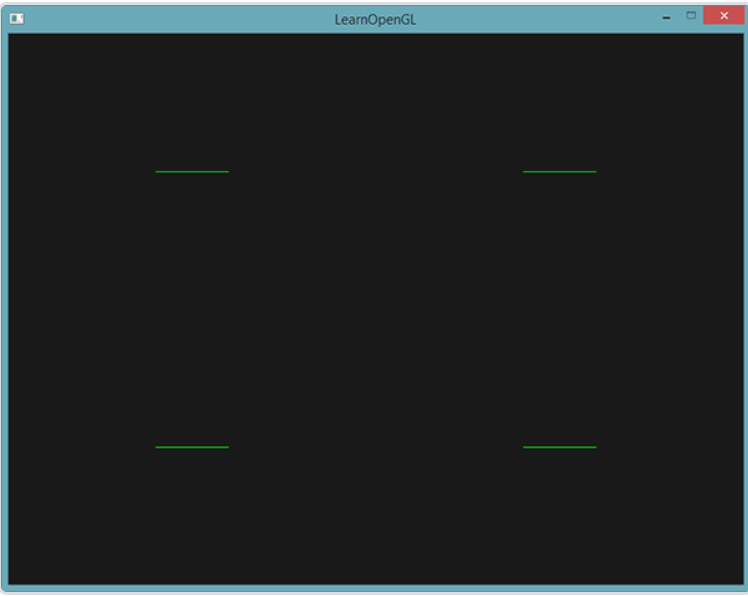
下面來進行實際演示
float points[] = {-0.5f, 0.5f, // 左上0.5f, 0.5f, // 右上0.5f, -0.5f, // 右下-0.5f, -0.5f // 左下
};
shader.use();
glBindVertexArray(VAO);
glDrawArrays(GL_POINTS, 0, 4);
先繪制出4個點

下來創建一個幾何著色器,不做任何處理,直接發射
#version 330 core
layout(points) in;
layout(points, max_vertices = 1) out;
void main(){gl_Position = gl_in[0].gl_Position;EmitVertex();EndPrimitive();
}
shader編譯時添加幾何著色器的編譯
Shader(const char* vertexPath, const char* geometryPath ,const char* fragmentPath){// 1. retrieve the vertex/fragment source code from filePathstd::string vertexCode;std::string fragmentCode;std::string geometryCode;std::ifstream vShaderFile;std::ifstream fShaderFile;std::ifstream gShaderFile;// ensure ifstream objects can throw exceptions:vShaderFile.exceptions (std::ifstream::failbit | std::ifstream::badbit);fShaderFile.exceptions (std::ifstream::failbit | std::ifstream::badbit);gShaderFile.exceptions (std::ifstream::failbit | std::ifstream::badbit);try{// open filesvShaderFile.open(vertexPath);fShaderFile.open(fragmentPath);gShaderFile.open(geometryPath);std::stringstream vShaderStream, fShaderStream, gShaderStream;// read file's buffer contents into streamsvShaderStream << vShaderFile.rdbuf();fShaderStream << fShaderFile.rdbuf();gShaderStream << gShaderFile.rdbuf();// close file handlersvShaderFile.close();fShaderFile.close();gShaderFile.close();// convert stream into stringvertexCode = vShaderStream.str();fragmentCode = fShaderStream.str();geometryCode = gShaderStream.str();}catch (std::ifstream::failure& e){std::cout << "ERROR::SHADER::FILE_NOT_SUCCESSFULLY_READ: " << e.what() << std::endl;}const char* vShaderCode = vertexCode.c_str();const char * fShaderCode = fragmentCode.c_str();const char * gShaderCode = geometryCode.c_str();// 2. compile shadersunsigned int vertex, fragment, geometry;// vertex shaderGL_CALL(vertex = glCreateShader(GL_VERTEX_SHADER));GL_CALL(glShaderSource(vertex, 1, &vShaderCode, NULL));GL_CALL(glCompileShader(vertex));GL_CALL(checkCompileErrors(vertex, "VERTEX"));// 幾何著色器GL_CALL(geometry = glCreateShader(GL_GEOMETRY_SHADER));glShaderSource(geometry, 1, &gShaderCode, NULL);glCompileShader(geometry);GL_CALL(checkCompileErrors(geometry, "GEOMETRY"));// fragment ShaderGL_CALL(fragment = glCreateShader(GL_FRAGMENT_SHADER));GL_CALL(glShaderSource(fragment, 1, &fShaderCode, NULL));GL_CALL(glCompileShader(fragment));GL_CALL(checkCompileErrors(fragment, "FRAGMENT"));// shader ProgramGL_CALL(ID = glCreateProgram());GL_CALL(glAttachShader(ID, vertex));GL_CALL(glAttachShader(ID, fragment));GL_CALL(glAttachShader(ID, geometry));GL_CALL(glLinkProgram(ID));GL_CALL(checkCompileErrors(ID, "PROGRAM"));// delete the shaders as they're linked into our program now and no longer necessaryGL_CALL(glDeleteShader(vertex));GL_CALL(glDeleteShader(fragment));GL_CALL(glDeleteShader(geometry));}
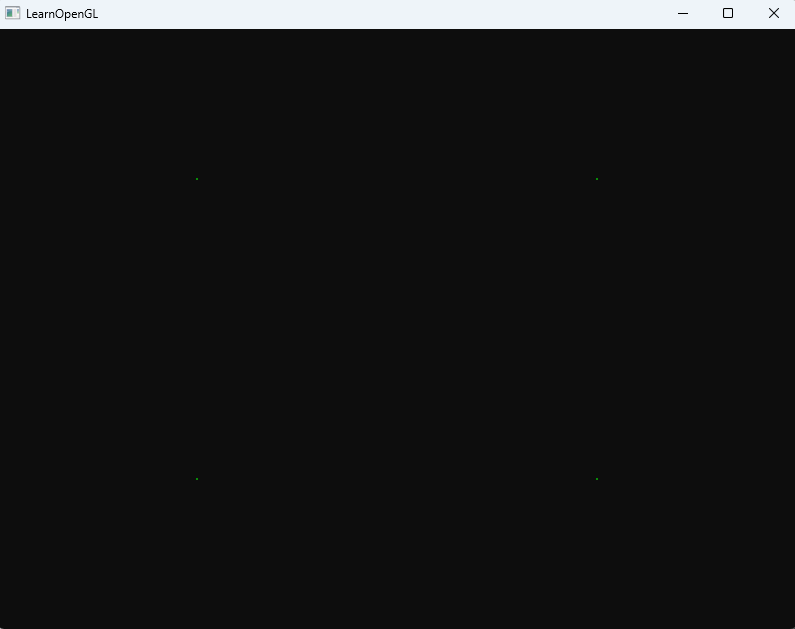
這里要理解最終調用的是畫點的指令glDrawArrays(GL_POINTS, 0, 4);所以幾何著色器運行一次只能得到一個點。通過一個點的位移來得到不同的輸出點,而不是可以一口氣輸入3個點。
修改幾何著色器
#version 330 core
layout (points) in;
layout (triangle_strip, max_vertices = 5) out;void build_house(vec4 position)
{gl_Position = position + vec4(-0.2, -0.2, 0.0, 0.0); // 1:左下EmitVertex();gl_Position = position + vec4( 0.2, -0.2, 0.0, 0.0); // 2:右下EmitVertex();gl_Position = position + vec4(-0.2, 0.2, 0.0, 0.0); // 3:左上EmitVertex();gl_Position = position + vec4( 0.2, 0.2, 0.0, 0.0); // 4:右上EmitVertex();gl_Position = position + vec4( 0.0, 0.4, 0.0, 0.0); // 5:頂部EmitVertex();EndPrimitive();
}
void main() {build_house(gl_in[0].gl_Position);
}

進一步我們可以在幾何著色器中處理顏色
首先在頂點著色器傳遞顏色,用接口快傳遞
#version 330 core
layout (location = 0) in vec2 aPos;
layout (location = 1) in vec3 aColor;out VS_OUT {vec3 color;
} vs_out;void main()
{gl_Position = vec4(aPos.x, aPos.y, 0.0, 1.0);vs_out.color = aColor;
}
注意接收接口塊的時候使用數組接收(應該是為了兼容輸入圖元是三角形的情況),之后還要把顏色輸出
#version 330 core
layout (points) in;
layout (triangle_strip, max_vertices = 5) out;
in VS_OUT {vec3 color;
} gs_in[];
out vec3 fColor;void build_house(vec4 position)
{fColor = gs_in[0].color; // gs_in[0] 因為只有一個輸入頂點gl_Position = position + vec4(-0.2, -0.2, 0.0, 0.0); // 1:左下EmitVertex();gl_Position = position + vec4( 0.2, -0.2, 0.0, 0.0); // 2:右下EmitVertex();gl_Position = position + vec4(-0.2, 0.2, 0.0, 0.0); // 3:左上EmitVertex();gl_Position = position + vec4( 0.2, 0.2, 0.0, 0.0); // 4:右上EmitVertex();gl_Position = position + vec4( 0.0, 0.4, 0.0, 0.0); // 5:頂部EmitVertex();EndPrimitive();
}void main() {build_house(gl_in[0].gl_Position);
}

如果在發射某個頂點時修改了fcolor的值,那這個頂點的數據就會被修改,
gl_Position = position + vec4( 0.0, 0.4, 0.0, 0.0); // 5:頂部fColor = vec3(1.0, 1.0, 1.0);EmitVertex();
所以頂部的顏色設置為了白色,通過插值就有了下圖的效果

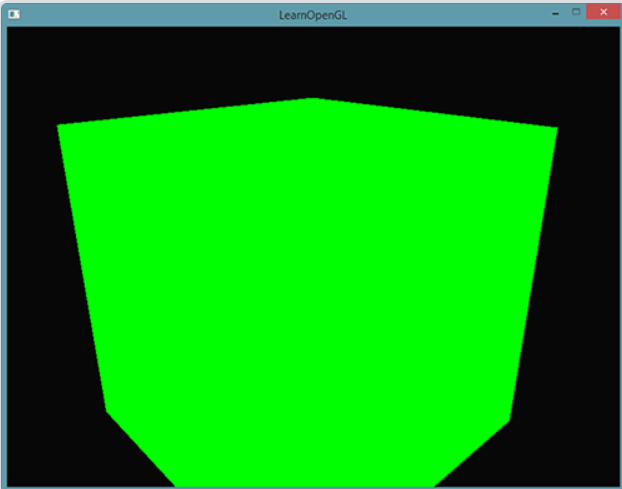
爆破物體
我們將每個三角形在幾何著色器中沿著法向量移動一小段時間。
首先把代碼恢復到展示一個背包的狀態。
幾何著色器輸入是三角形,輸出也是三角形,在發射三個頂點的時候,修改頂點的位置
#version 330 core
layout (triangles) in;
layout (triangle_strip, max_vertices = 3) out;in VS_OUT {vec2 texCoords;
} gs_in[];out vec2 TexCoords; uniform float time;vec4 explode(vec4 position, vec3 normal) { ... }vec3 GetNormal() { ... }void main() { vec3 normal = GetNormal();gl_Position = explode(gl_in[0].gl_Position, normal);TexCoords = gs_in[0].texCoords;EmitVertex();gl_Position = explode(gl_in[1].gl_Position, normal);TexCoords = gs_in[1].texCoords;EmitVertex();gl_Position = explode(gl_in[2].gl_Position, normal);TexCoords = gs_in[2].texCoords;EmitVertex();EndPrimitive();
}
法向量可視化
三角形圖元輸入后額外添加3個法向量方向的點,輸出圖元為線圖,所以會繪制出三角形+三條法線
#version 330 core
layout (triangles) in;
layout (line_strip, max_vertices = 6) out;in VS_OUT {vec3 normal;
} gs_in[];const float MAGNITUDE = 0.4;uniform mat4 projection;void GenerateLine(int index)
{gl_Position = projection * gl_in[index].gl_Position;EmitVertex();gl_Position = projection * (gl_in[index].gl_Position +vec4(gs_in[index].normal, 0.0) * MAGNITUDE);EmitVertex();EndPrimitive();
}void main()
{GenerateLine(0); // 第一個頂點法線GenerateLine(1); // 第二個頂點法線GenerateLine(2); // 第三個頂點法線
}
第一遍用正常的shader進行渲染,第二次渲染用這一套shader,就可以實現如下效果

換個模型
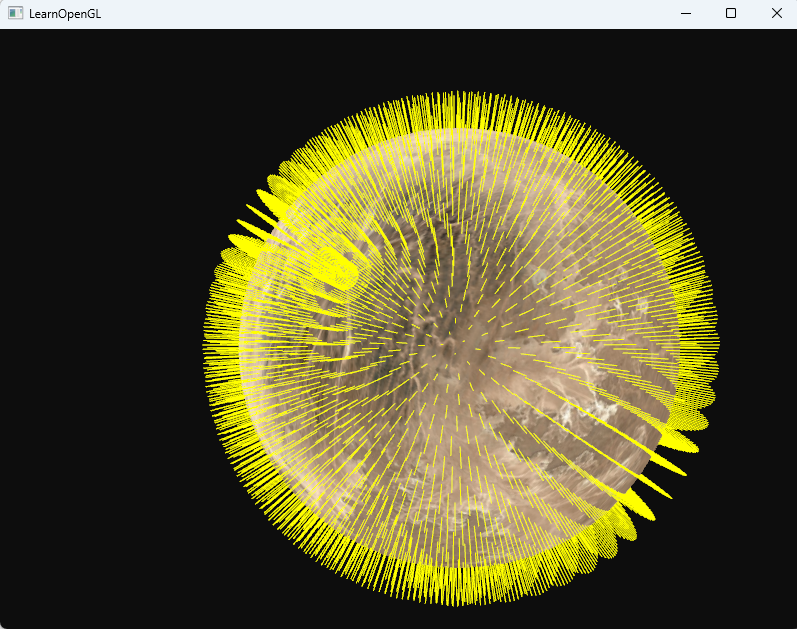
除了讓我們的背包變得毛茸茸之外,它還能讓我們很好地判斷模型的法向量是否準確。你可以想象到,這樣的幾何著色器也經常用于給物體添加毛發(Fur)。
實例化(偏移量存在uniform中)
當一個模型通過修改Model變換矩陣后渲染多份(草地),如果我們需要渲染大量物體時,代碼看起來會像這樣:
for(unsigned int i = 0; i < amount_of_models_to_draw; i++)
{DoSomePreparations(); // 綁定VAO,綁定紋理,設置uniform等glDrawArrays(GL_TRIANGLES, 0, amount_of_vertices);
}
如果像這樣繪制模型的大量實例(Instance),你很快就會因為繪制調用過多而達到性能瓶頸。【因為OpenGL在繪制頂點數據之前需要做很多準備工作(比如告訴GPU該從哪個緩沖讀取數據,從哪尋找頂點屬性,而且這些都是在相對緩慢的CPU到GPU總線(CPU to GPU Bus)上進行的)。所以,即便渲染頂點非常快,命令GPU去渲染卻未必】。
如果我們能夠將數據一次性發送給GPU,然后使用一個繪制函數讓OpenGL利用這些數據繪制多個物體,就會更方便了。這就是實例化(Instancing)。
glDrawArraysInstanced和glDrawElementsInstanced就是用來實例化的,這些渲染函數需要需要一個額外的參數,叫做實例數量(Instance Count)。這樣我們只需要將必須的數據發送到GPU一次,然后使用一次函數調用告訴GPU它應該如何繪制這些實例。
但我們還需要考慮是在不同的位置渲染,出于這個原因,GLSL在頂點著色器中嵌入了另一個內建變量,gl_InstanceID。
在使用實例化渲染調用時,gl_InstanceID會從0開始,在每個實例被渲染時遞增1。比如說,我們正在渲染第43個實例,那么頂點著色器中它的gl_InstanceID將會是42。
具體做法就是在片段著色器中添加一個uniform,表示偏移量數組,剛好用gl_InstanceID可以來表示渲染的id
uniform vec2 offsets[100];
main中:vec2 offset = offsets[gl_InstanceID];gl_Position = vec4(aPos + offset, 0.0, 1.0);
下來就需要填充這些參數了,之后直接調glDrawArraysInstanced(GL_TRIANGLES, 0, 6, 100);來渲染一百次。這樣就是一次性交給GPU100條渲染,每條渲染都有一個gl_InstanceID
調用過程就是每次渲染傳入的gl_InstanceID是不一樣的,所以偏移量也不同。
實例化數組(偏移量存在頂點屬性中)
如果我們渲染個數特別多,偏移量將達到uniform數據上限,替代方案就是實例化數組,他被定義為一個頂點屬性,只有渲染一個新的實例時才會刷新。
可以把在程序中定義的偏移量數組裝在一個VBO中
unsigned int instanceVBO;
glGenBuffers(1, &instanceVBO);
glBindBuffer(GL_ARRAY_BUFFER, instanceVBO);
glBufferData(GL_ARRAY_BUFFER, sizeof(glm::vec2) * 100, &translations[0], GL_STATIC_DRAW);
glBindBuffer(GL_ARRAY_BUFFER, 0);
并設置VAO
glEnableVertexAttribArray(2);
glBindBuffer(GL_ARRAY_BUFFER, instanceVBO);
glVertexAttribPointer(2, 2, GL_FLOAT, GL_FALSE, 2 * sizeof(float), (void*)0);
glBindBuffer(GL_ARRAY_BUFFER, 0);
glVertexAttribDivisor(2, 1);
調用glVertexAttribDivisor告訴了OpenGl該什么時候更新頂點屬性內容到新一組數據,第一個參數是需要的頂點屬性,第二個參數是屬性除數,屬性除數是0,告訴OpenGL我們需要在頂點著色器的每次迭代時更新頂點屬性。將它設置為1時,我們告訴OpenGL我們希望在渲染一個新實例的時候更新頂點屬性。而設置為2時,我們希望每2個實例更新一次屬性,以此類推。我們將屬性除數設置為1,是在告訴OpenGL,處于位置值2的頂點屬性是一個實例化數組。
看下邊這個就懂了,設置屬性位置1,2時還是正常進行,但屬性3不是來自的不是quadVBO(也就是頂點數據),而是來自instanceVBO(就是偏移量數據),它存儲在layout(location = 2),并通過glVertexAttribDivisor來告訴2號參數每個實例化取下一個。
unsigned int quadVAO, quadVBO;glGenVertexArrays(1, &quadVAO);glGenBuffers(1, &quadVBO);glBindVertexArray(quadVAO);glBindBuffer(GL_ARRAY_BUFFER, quadVBO);glBufferData(GL_ARRAY_BUFFER, sizeof(quadVertices), quadVertices, GL_STATIC_DRAW);glEnableVertexAttribArray(0);glVertexAttribPointer(0, 2, GL_FLOAT, GL_FALSE, 5 * sizeof(float), (void*)0);glEnableVertexAttribArray(1);glVertexAttribPointer(1, 3, GL_FLOAT, GL_FALSE, 5 * sizeof(float), (void*)(2 * sizeof(float)));// also set instance dataglEnableVertexAttribArray(2);glBindBuffer(GL_ARRAY_BUFFER, instanceVBO); // this attribute comes from a different vertex bufferglVertexAttribPointer(2, 2, GL_FLOAT, GL_FALSE, 2 * sizeof(float), (void*)0);glBindBuffer(GL_ARRAY_BUFFER, 0);glVertexAttribDivisor(2, 1); // tell OpenGL this is an instanced vertex attribute.
按照這樣理解,那屬性0和屬性1其實事實上就是每個頂點刷新一次,也就是調用了
glVertexAttribDivisor(0,0)和glVertexAttribDivisor(1, 0)
從另外一個角度理解就是這些layout的參數是可以設置刷新時機(每個頂點或每次實例化)的,不過只有在調用實例化繪制方法glDrawArraysInstanced(GL_TRIANGLES, 0, 6, 100);時才會生效
layout (location = 0) in vec2 aPos;
layout (location = 1) in vec3 aColor;
layout (location = 2) in vec2 aOffset;
小行星帶
圍繞星體旋轉的巖石就可以用同一個模型進行渲染。實例化很適合的場景。
如果直接渲染1000次代碼如下
const unsigned int SCR_WIDTH = 800;
const unsigned int SCR_HEIGHT = 600;
// camera
Camera camera(glm::vec3(0.0f, 10.0f, 70.0f));
float lastX = SCR_WIDTH / 2.0f;
float lastY = SCR_HEIGHT / 2.0f;
bool firstMouse = true;
// timing
float deltaTime = 0.0f; // time between current frame and last frame
float lastFrame = 0.0f;int main(){// 初始化窗口GLFWwindow * window = InitWindowAndFunc();stbi_set_flip_vertically_on_load(true);// 啟用深度測試glEnable(GL_DEPTH_TEST);// 加載模型Model rock("./assets/rock/rock.obj");Model planet("./assets/planet/planet.obj");// 加載shaderShader shader("./shader/rockAndPlanet.vert", "./shader/rockAndPlanet.frag");unsigned int amount = 1000;glm::mat4* modelMatrices;modelMatrices = new glm::mat4[amount];srand(static_cast<unsigned int>(glfwGetTime())); // initialize random seedfloat radius = 50.0;float offset = 2.5f;for (unsigned int i = 0; i < amount; i++){glm::mat4 model = glm::mat4(1.0f);// 1. translation: displace along circle with 'radius' in range [-offset, offset]float angle = (float)i / (float)amount * 360.0f;float displacement = (rand() % (int)(2 * offset * 100)) / 100.0f - offset;float x = sin(angle) * radius + displacement;displacement = (rand() % (int)(2 * offset * 100)) / 100.0f - offset;float y = displacement * 0.4f; // keep height of asteroid field smaller compared to width of x and zdisplacement = (rand() % (int)(2 * offset * 100)) / 100.0f - offset;float z = cos(angle) * radius + displacement;model = glm::translate(model, glm::vec3(x, y, z));// 2. scale: Scale between 0.05 and 0.25ffloat scale = static_cast<float>((rand() % 20) / 100.0 + 0.05);model = glm::scale(model, glm::vec3(scale));// 3. rotation: add random rotation around a (semi)randomly picked rotation axis vectorfloat rotAngle = static_cast<float>((rand() % 360));model = glm::rotate(model, rotAngle, glm::vec3(0.4f, 0.6f, 0.8f));// 4. now add to list of matricesmodelMatrices[i] = model;}while (!glfwWindowShouldClose(window)){// 清理窗口glClearColor(0.05f, 0.05f, 0.05f, 1.0f);glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);glm::mat4 projection = glm::perspective(glm::radians(45.0f), (float)SCR_WIDTH / (float)SCR_HEIGHT, 0.1f, 1000.0f);glm::mat4 view = camera.GetViewMatrix();;shader.use();shader.setMat4("projection", projection);shader.setMat4("view", view);// draw planetglm::mat4 model = glm::mat4(1.0f);model = glm::translate(model, glm::vec3(0.0f, -3.0f, 0.0f));model = glm::scale(model, glm::vec3(4.0f, 4.0f, 4.0f));shader.setMat4("model", model);planet.Draw(shader);// draw meteoritesfor (unsigned int i = 0; i < amount; i++){shader.setMat4("model", modelMatrices[i]);rock.Draw(shader);}// 事件處理glfwPollEvents();// 雙緩沖glfwSwapBuffers(window);processFrameTimeForMove();processInput(window);}glfwTerminate();return 0;
}1000次獨立渲染我的4070ts還完全hold住,
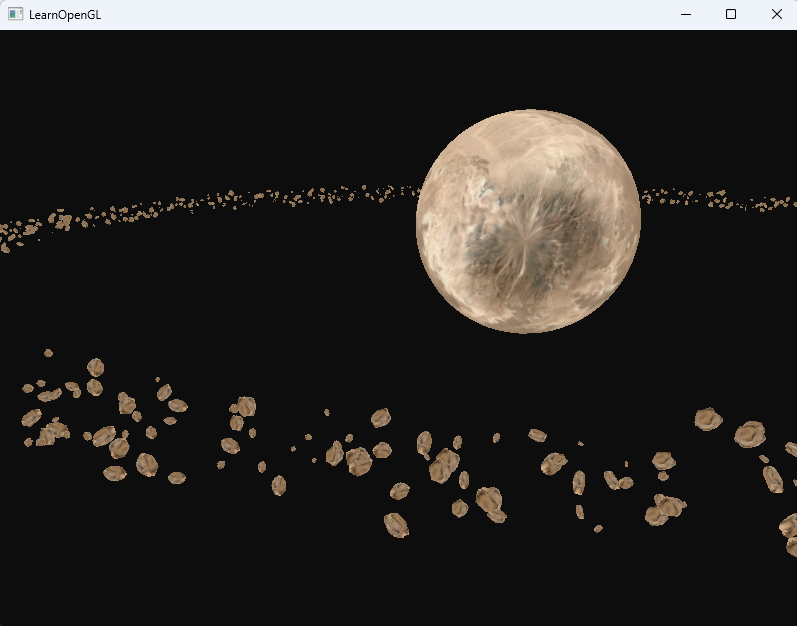
但是到了10000次就開始卡頓了,最后調整到100000次就很卡了
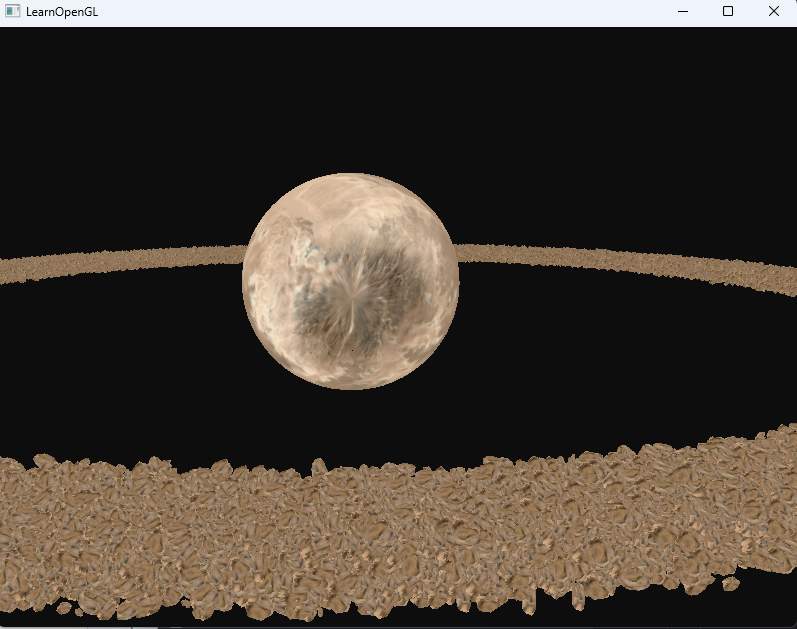
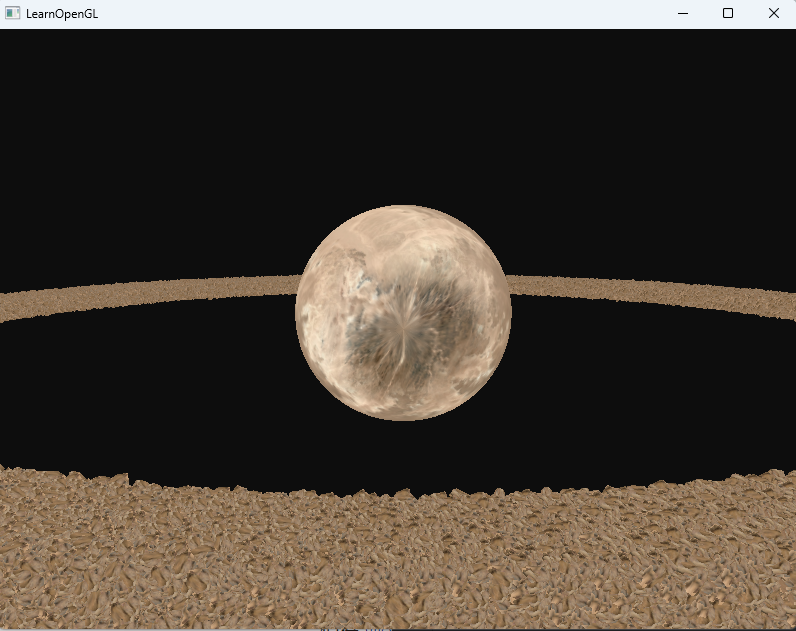
接著調整到100w次,就已經是5s一幀了
下面用實例化數組來進行優化,首先調整頂點著色器來接收數組(直接把Model變換矩陣存在數組里)
#version 330 core
layout (location = 0) in vec3 aPos;
layout (location = 2) in vec2 aTexCoords;
layout (location = 3) in mat4 instanceMatrix;out vec2 TexCoords;uniform mat4 projection;
uniform mat4 view;void main()
{gl_Position = projection * view * instanceMatrix * vec4(aPos, 1.0); TexCoords = aTexCoords;
}
把剛才存放model變換矩陣的數組存入顯存中
// 數組存入VBO中待用unsigned int buffer;glGenBuffers(1, &buffer);glBindBuffer(GL_ARRAY_BUFFER, buffer);glBufferData(GL_ARRAY_BUFFER, amount * sizeof(glm::mat4), &modelMatrices[0], GL_STATIC_DRAW);
修改rock的VAO,讓他接收該VBO,這里注意每個Vertex Attribute槽位最多接收4個分量,如果向存儲4維矩陣,就得綁定4個屬性的位置,但是接收只需要用最前邊的location來接收
for (unsigned int i = 0; i < rock.meshes.size(); i++){unsigned int VAO = rock.meshes[i].VAO;glBindVertexArray(VAO);// set attribute pointers for matrix (4 times vec4)glEnableVertexAttribArray(3);glVertexAttribPointer(3, 4, GL_FLOAT, GL_FALSE, sizeof(glm::mat4), (void*)0);glEnableVertexAttribArray(4);glVertexAttribPointer(4, 4, GL_FLOAT, GL_FALSE, sizeof(glm::mat4), (void*)(sizeof(glm::vec4)));glEnableVertexAttribArray(5);glVertexAttribPointer(5, 4, GL_FLOAT, GL_FALSE, sizeof(glm::mat4), (void*)(2 * sizeof(glm::vec4)));glEnableVertexAttribArray(6);glVertexAttribPointer(6, 4, GL_FLOAT, GL_FALSE, sizeof(glm::mat4), (void*)(3 * sizeof(glm::vec4)));glVertexAttribDivisor(3, 1);glVertexAttribDivisor(4, 1);glVertexAttribDivisor(5, 1);glVertexAttribDivisor(6, 1);glBindVertexArray(0);}
最后渲染巖石的方法改為,因為rock不止一個mesh
for (unsigned int i = 0; i < rock.meshes.size(); i++){glBindVertexArray(rock.meshes[i].VAO);glDrawElementsInstanced(GL_TRIANGLES, static_cast<unsigned int>(rock.meshes[i].indices.size()), GL_UNSIGNED_INT, 0, amount);glBindVertexArray(0);}
直接上100w測試,從5s一幀變為不到1s一幀,提升還是很大的
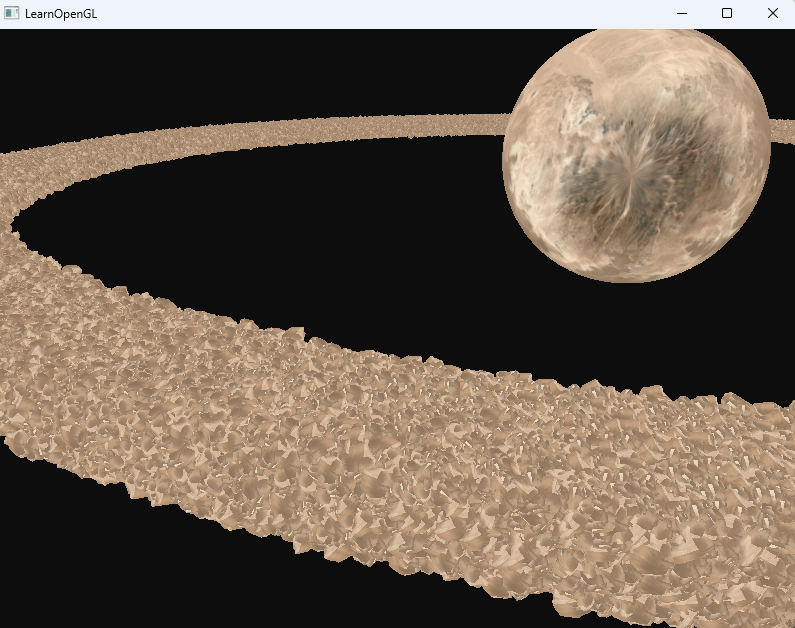
可以看到,在合適的環境下,實例化渲染能夠大大增加顯卡的渲染能力。正是出于這個原因,實例化渲染通常會用于渲染草、植被、粒子,以及上面這樣的場景,基本上只要場景中有很多重復的形狀,都能夠使用實例化渲染來提高性能。
抗鋸齒
這里不過多介紹抗鋸齒的原因,采用一位大佬的話
鋸齒的來源是因為場景的定義在三維空間中是連續的,而最終顯示的像素則是一個離散的二維數組。所以判斷一個點到底沒有被某個像素覆蓋的時候單純是一個“有”或者“沒有"問題,丟失了連續性的信息,導致鋸齒。也叫做走樣Aliasing,所以抗鋸齒就是反走樣(Anti-aliasing)

SSAA(Super Sample Anti-aliasing)
最直接的抗鋸齒方法就是SSAA(Super Sampling AA)。拿4xSSAA舉例子,假設最終屏幕輸出的分辨率是800x600, 4xSSAA就會先渲染到一個分辨率1600x1200的buffer上,然后再直接把這個放大4倍的buffer下采樣致800x600。這種做法在數學上是最完美的抗鋸齒。但是劣勢也很明顯,光柵化和著色的計算負荷都比原來多了4倍,render target的大小也漲了4倍。
之前不是學過OpenGL的離線渲染嗎,就可以先在自定義幀緩沖中渲染一個高分辨的圖片加入到紋理中,在0號幀緩沖中再采樣紋理,即可達到SSAA的目的
MSAA(Multi-Sampling Anti-aliasing)
光柵器是位于最終處理過的頂點之后到片段著色器之前所經過的所有的算法與過程的總和。
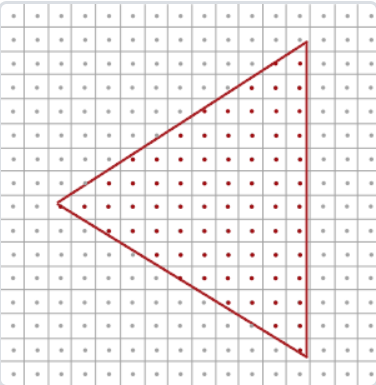
從上圖到下圖就有鋸齒了
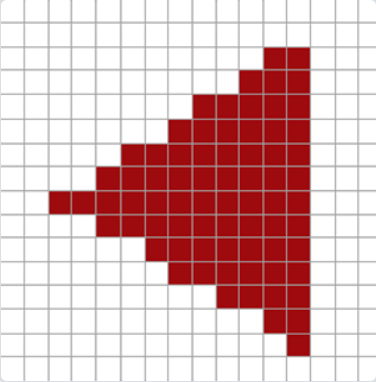
一張圖就解釋MSAA在干什么了。
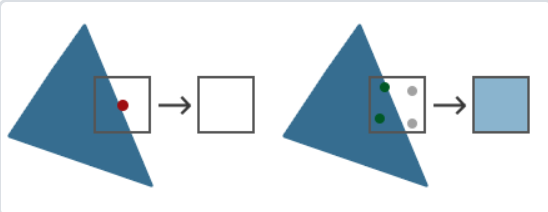
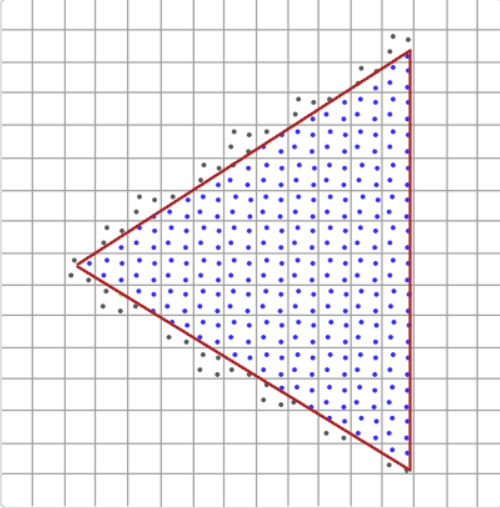
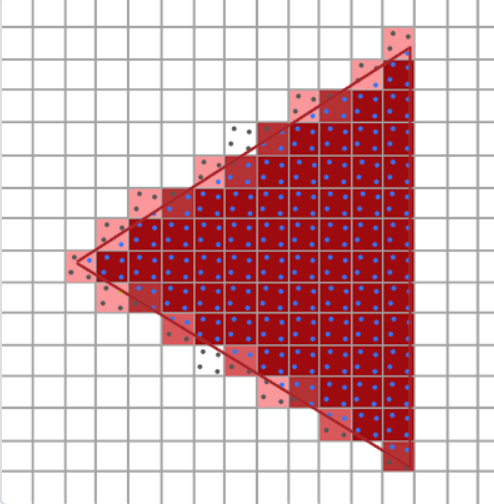
三角形的不平滑邊緣被稍淺的顏色所包圍后,從遠處觀察時就會顯得更加平滑了。
OpenGL中的MSAA
走樣的效果

開啟MSAA需要在創建窗口之前告訴OpenGL需要多重采樣,每個像素有了4個顏色緩沖,4代表每個像素將會被采樣4次(都cover的情況下),每次采樣都會獲得一個子像素值,這些值最終被平均以生成最終的像素顏色
glfwWindowHint(GLFW_SAMPLES, 4);4次采樣發生在光柵化之后,片段著色器執行之前。
光柵化首先將三角形頂點通過視口變換轉變到屏幕坐標上,之后對三角形求包圍盒,變量包圍盒中的像素,判斷那些像素點在三角形內部,通過插值算出該像素對應的UV坐標,利用該坐標去紋理圖片中取顏色。
4個采樣點說明一個像素4個點都需要做一次判斷是否在三角形內部的操作,在三角形內部的點取紋理上采樣,并寫入對應的子顏色緩沖,不在三角形內部的點就不改變目前子顏色緩沖中的值
開啟MSAA(其實默認就是開啟的)
glEnable(GL_MULTISAMPLE);
因為多重采樣的算法都在OpenGL驅動的光柵器中實現了,我們不需要再多做什么。
開啟后

離屏MSAA
由于GLFW負責了創建多重采樣緩沖,啟用MSAA非常簡單。然而,如果我們想要使用我們自己的幀緩沖來進行離屏渲染,那么我們就必須要自己動手生成多重采樣緩沖了。現在,我們確實需要自己創建多重采樣緩沖區。
有兩種方式可以創建多重采樣緩沖,將其作為幀緩沖的附件:紋理附件和渲染緩沖附件
多重采樣紋理附件
為了創建一個支持儲存多個采樣點的紋理,我們使用glTexImage2DMultisample來替代glTexImage2D,它的紋理目標是GL_TEXTURE_2D_MULTISAPLE。
glBindTexture(GL_TEXTURE_2D_MULTISAMPLE, tex);
glTexImage2DMultisample(GL_TEXTURE_2D_MULTISAMPLE, samples, GL_RGB, width, height, GL_TRUE);
glBindTexture(GL_TEXTURE_2D_MULTISAMPLE, 0);
我們使用glFramebufferTexture2D將多重采樣紋理附加到幀緩沖上,但這里紋理類型使用的是GL_TEXTURE_2D_MULTISAMPLE。
glFramebufferTexture2D(GL_FRAMEBUFFER, GL_COLOR_ATTACHMENT0, GL_TEXTURE_2D_MULTISAMPLE, tex, 0);
多重采樣渲染緩沖對象
同樣也是創建RBO并綁定。在設置深度和模板緩沖時,要切換為多重采樣的緩沖
glRenderbufferStorageMultisample(GL_RENDERBUFFER, 4, GL_DEPTH24_STENCIL8, width, height);
渲染到多重采樣幀緩沖
因為多重采樣緩沖有一點特別,我們不能直接將它們的緩沖圖像用于其他運算,比如在著色器中對它們進行采樣。
一個多重采樣的圖像包含比普通圖像更多的信息,我們所要做的是縮小或者還原(Resolve)圖像。多重采樣幀緩沖的還原通常是通過glBlitFramebuffer來完成,它能夠將一個幀緩沖中的某個區域復制到另一個幀緩沖中,并且將多重采樣緩沖還原。
glBindFramebuffer(GL_READ_FRAMEBUFFER, multisampledFBO);
glBindFramebuffer(GL_DRAW_FRAMEBUFFER, 0);
glBlitFramebuffer(0, 0, width, height, 0, 0, width, height, GL_COLOR_BUFFER_BIT, GL_NEAREST);
自定義抗鋸齒算法
將一個多重采樣的紋理圖像不進行還原直接傳入著色器也是可行的。GLSL提供了這樣的選項,讓我們能夠對紋理圖像的每個子樣本進行采樣,所以我們可以創建我們自己的抗鋸齒算法。在大型的圖形應用中通常都會這么做。
要想獲取每個子樣本的顏色值,你需要將紋理uniform采樣器設置為sampler2DMS,而不是平常使用的sampler2D:
uniform sampler2DMS screenTextureMS;
使用texelFetch函數就能夠獲取每個子樣本的顏色值了:
vec4 colorSample = texelFetch(screenTextureMS, TexCoords, 3); // 第4個子樣本


復現)



![Visio繪圖工具全面科普:解鎖專業圖表繪制新境界[特殊字符]](http://pic.xiahunao.cn/Visio繪圖工具全面科普:解鎖專業圖表繪制新境界[特殊字符])


)



)





