目錄
1 Secondary NameNode的角色定位與常見誤解
2 核心職責詳解
2.1 核心功能職責
2.2 與NameNode的協作關系
3 運行機制深度剖析
3.1 檢查點觸發機制
3.2 元數據合并流程
4 與Hadoop 2.0+ HA架構的對比
5 配置調優指南
5.1 關鍵配置參數
5.2 性能優化建議
6 實踐應用
6.1 監控指標
6.2 故障恢復步驟
7 總結
1 Secondary NameNode的角色定位與常見誤解
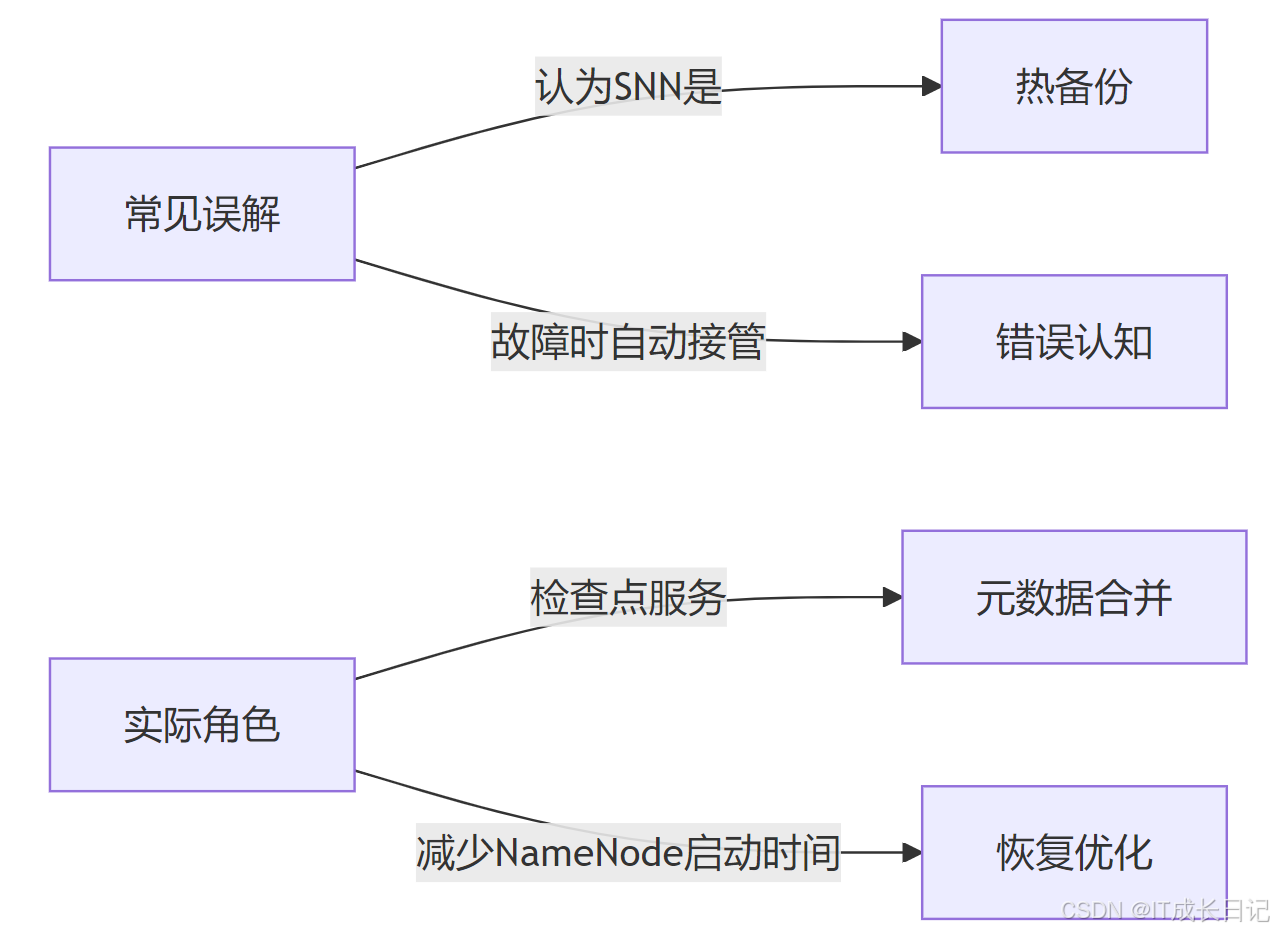
Secondary NameNode(SNN)是HDFS架構中 最容易被誤解的組件之一。經常誤以為它是NameNode的熱備份,但實際上它的核心角色是 檢查點(checkpoint)服務。
2 核心職責詳解
2.1 核心功能職責
- 定期合并FsImage和EditLog:創建新的文件系統快照
- 檢查點管理:控制元數據合并的頻率和時機
- NameNode恢復輔助:提供較新的FsImage加速啟動
2.2 與NameNode的協作關系
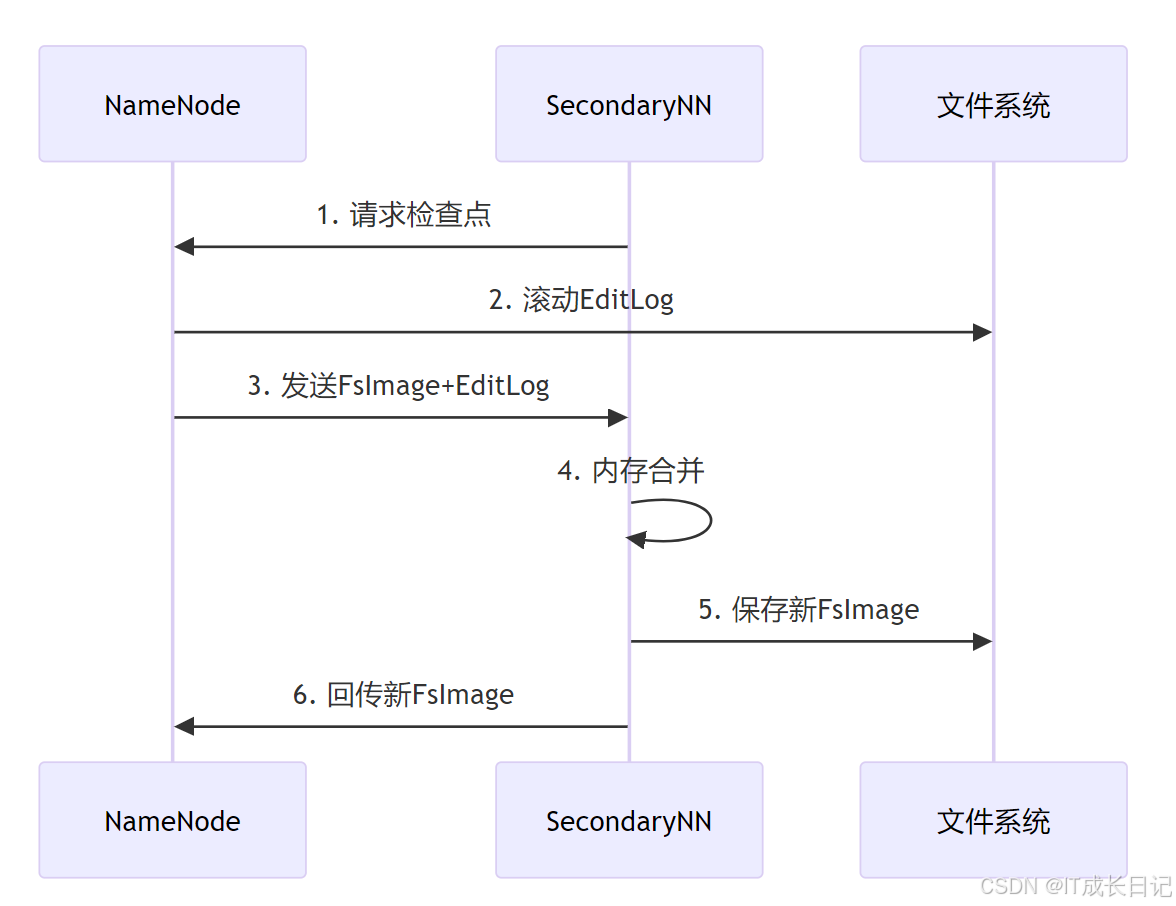
3 運行機制深度剖析
3.1 檢查點觸發機制
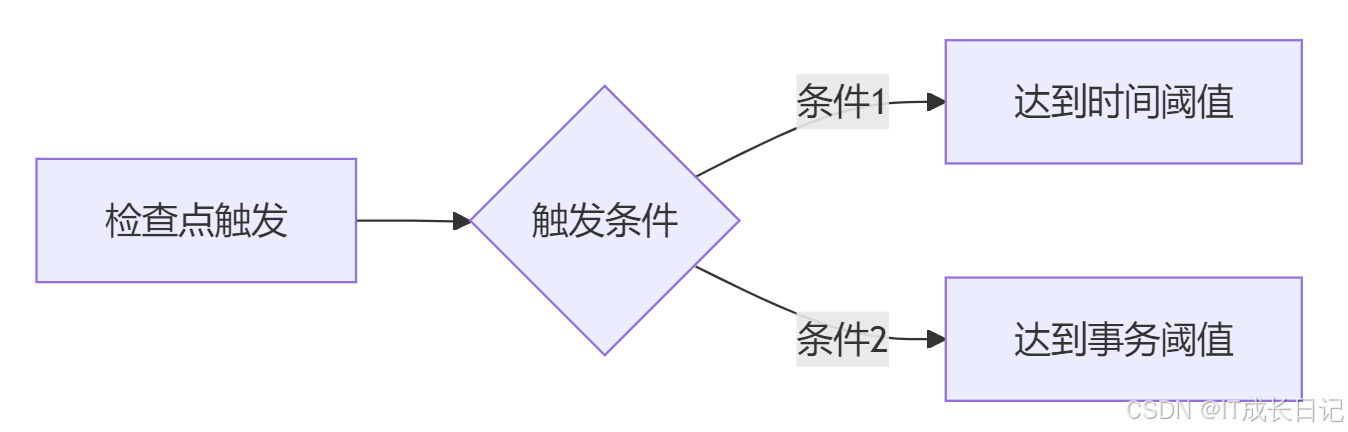
- 時間閾值:dfs.namenode.checkpoint.period(秒)
- 事務閾值:dfs.namenode.checkpoint.txns
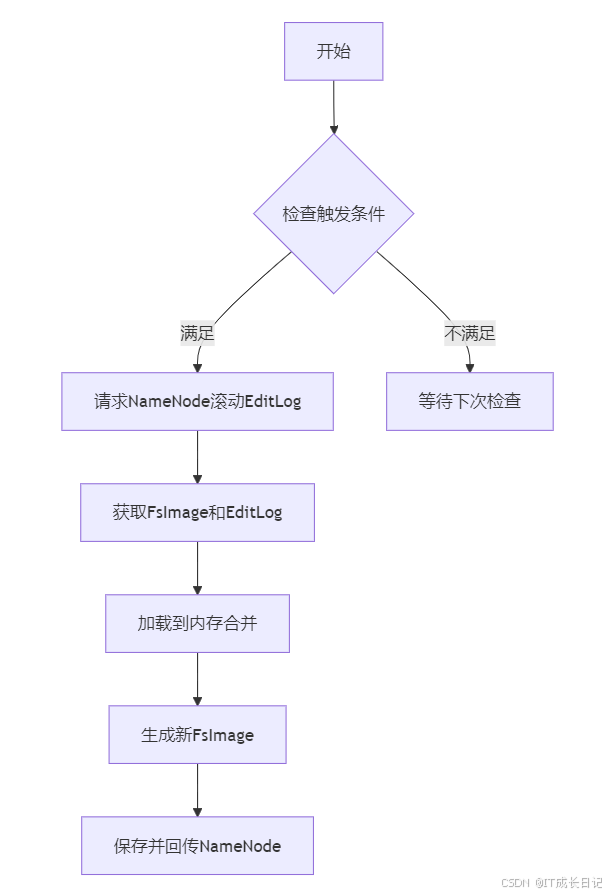
3.2 元數據合并流程
4 與Hadoop 2.0+ HA架構的對比
| 特性 | Secondary NameNode | HA Standby NameNode |
| 實時性 | 定期合并(非實時) | 實時同步EditLog |
| 故障恢復 | 不能自動接管 | 自動故障轉移 |
| 元數據一致性 | 合并期間可能丟失部分操作 | 完全一致 |
| 資源消耗 | 需要獨立服務器 | 與Active NN共享JournalNodes |
5 配置調優指南
5.1 關鍵配置參數
<!-- hdfs-site.xml -->
<property><name>dfs.namenode.checkpoint.period</name><value>3600</value> <!-- 合并間隔(秒) -->
</property>
<property><name>dfs.namenode.checkpoint.txns</name><value>1000000</value> <!-- 最大未合并事務數 -->
</property>
<property><name>dfs.namenode.checkpoint.dir</name><value>file://${hadoop.tmp.dir}/dfs/namesecondary</value>
</property>5.2 性能優化建議
- 獨立服務器部署:避免與DataNode爭搶資源
- SSD存儲FsImage:加速合并過程
- 調整合并頻率:根據集群寫負載調整周期
6 實踐應用
6.1 監控指標
| 指標名稱 | 健康閾值 | 監控方法 |
| 上次檢查點時間 | 小于 checkpoint.period | hdfs dfsadmin -metasave |
| 合并持續時間 | 小于300秒 | SNN日志分析 |
| FsImage大小增長趨勢 | 平穩增長 | 定期檢查文件大小 |
6.2 故障恢復步驟
# 當NameNode元數據損壞時,可從SNN恢復
hdfs namenode -importCheckpoint7 總結
Secondary NameNode作為傳統HDFS架構的重要組件,在保證元數據可靠性方面發揮了關鍵作用。理解其工作原理不僅有助于維護Hadoop 1.x集群,更能深刻理解現代HDFS HA架構的設計哲學。對于新建集群,建議直接采用HA架構;而對于遺留系統,合理配置SNN仍是保障數據安全的重要手段。



![LINUX基礎 [四] - Linux工具](http://pic.xiahunao.cn/LINUX基礎 [四] - Linux工具)



:拾遺 - imgproc 基礎操作(上))

)







Kafka核心原理揭秘:從入門到企業級實戰應用)

