目錄
軟件包管理器yum
Linux開發工具vim
vim的基本概念
?vim的三種常用模式
vim的簡單配置
vim常用模式的基本操作
命令模式
底行模式
處理vim打開文件報錯的問題
?Linux編譯器-gcc/g++使用
為什么我們可以用C/C++做開發呢?
預處理(進行宏替換)
編譯(生成匯編)
匯編(生成機器可識別代碼)
鏈接(生成可執行文件或庫文件)
.o和庫是如何鏈接的(靜態鏈接和動態鏈接)
動態庫文件和靜態庫文件
動態庫和靜態庫理解
控制鏈接方式的選擇
動態鏈接和靜態鏈接的優缺點
Linux調試器 - gdb
gdb使用須知
gdb命令匯總
Linux項目自動化構建工具 - make/Makefile
依賴關系和依賴方法
多文件編譯
make原理
項目清理
為什么不會允許多次make呢??(重點)
stat指令
?Linux第一個小程序 - 進度條
行緩沖區的概念
\r和\n
軟件包管理器yum
Linux開發工具vim
vim的基本概念
vim在我們做開發的時候,主要解決我們編寫代碼的問題,本質上就是一個多模式的文本編輯器。
每個Linux賬戶都獨有一個vim編輯器。
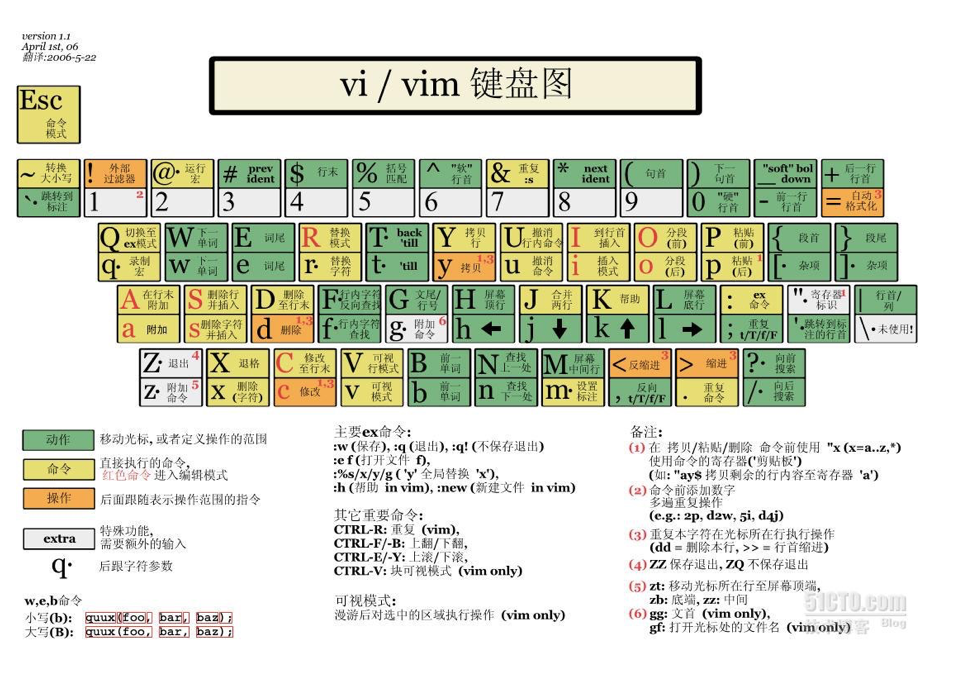

?vim的三種常用模式
創建vim文件:vim 文件名? ?(如果該文件沒有創建,必須保存后才會創建出來)
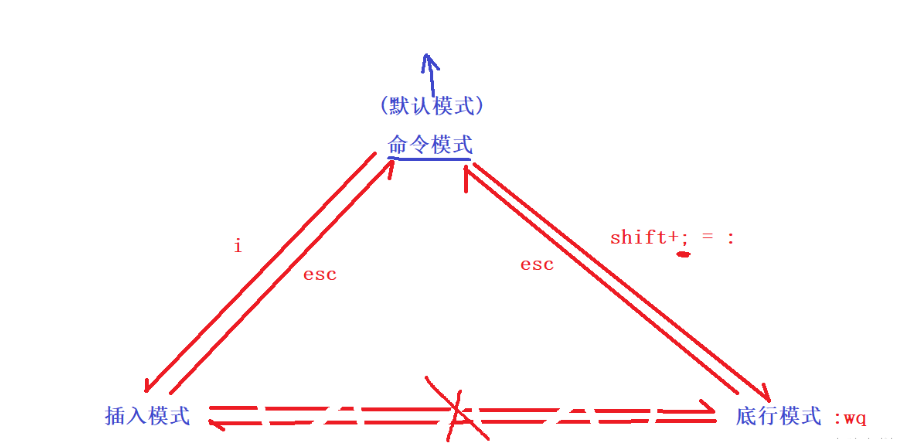
vim最常用的三種模式:命令模式(command mode)、底行模式(last line mode)、插入模式(insert mode)
命令模式
每次打開?vim 編輯器,默認進入的就是命令行模式

命令行模式下無法在打開的文件里插入任何數據,只能執行對應的指令
底行模式
底行模式由命令模式進入?,輸入:(即shift+;)?

:是提示符,表示當前處于底行模式
從底行模式退出,按?ESC鍵?即可。且退出到命令模式
插入模式
?插入模式由命令模式進入,輸入‘i’?


INSERT是提示符,表示當前處于插入模式
只有在插入模式下才可以對打開的文件進行寫操作,即編寫程序
從插入模式退出,按?ESC鍵即可。且退出到命令模式
三種模式的相互轉換
vim的簡單配置
【配置文件的位置】
- 在目錄/etc/下面,有個名為vimrc的文件,這是系統中公共的配置文件,對所有用戶都有效。
- 在每個用戶的主目錄/home/xxx下,都可以自己建立私有的配置文件,命名為“.vimrc”,這是該用戶私有的配置文件,僅對該用戶有效。
例如,普通用戶在自己的主目錄下建立了“.vimrc”文件后,在文件當中輸入set?nu指令并保存,下一次打開vim的時候就會自動顯示行號。
vim的配置比較復雜,某些vim配置還需要使用插件,建議不要自己一個個去配置。比較簡單的方法是直接執行以下指令(想在哪個用戶下讓vim配置生效,就在哪個用戶下執行該指令,不推薦直接在root下執行):
curl -sLf https://gitee.com/HGtz2222/VimForCpp/raw/master/install.sh -o ./install.sh && bash ./install.sh然后按照提示輸入root密碼:
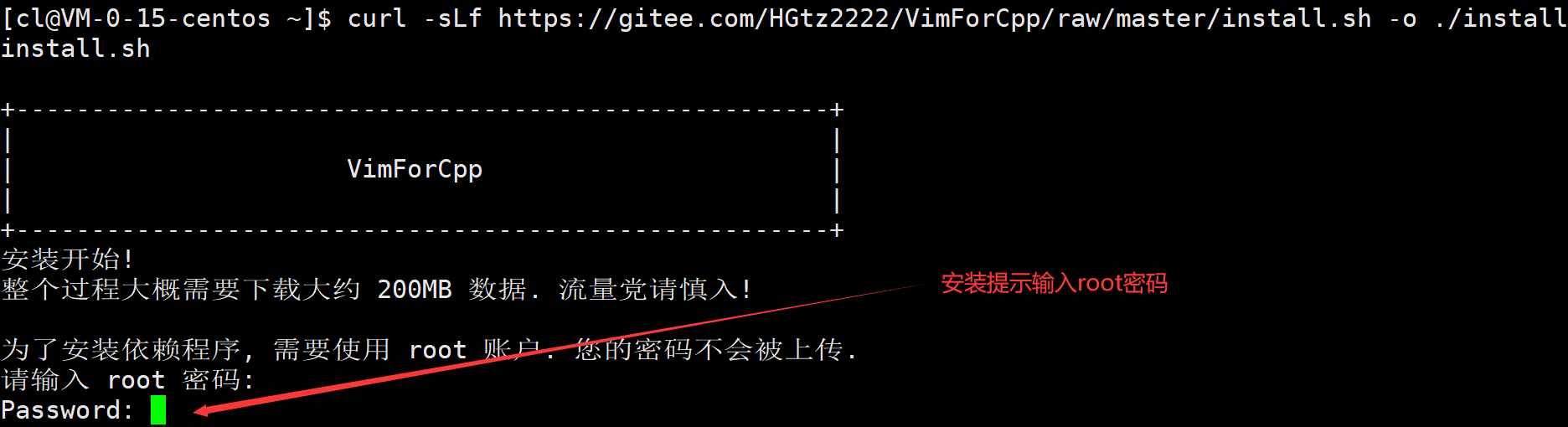
然后等待安裝配置,最后手動執行source ~/.bashrc即可。

配置完成后,像什么自動補全、行號顯示以及自動縮進什么的就都有了。?
vim常用模式的基本操作
命令模式
【移動光標】
1)按「k」:光標上移。
2)按「j」:光標下移。
3)按「h」:光標左移。
4)按「l」:光標右移。
5)按「$」:移動到光標所在行的行尾。
6)按「^」:移動到光標所在行的行首。
7)按「gg」:移動到文本開始。
8)按「Shift+g」:移動到文本末尾。
9)按「n+Shift+g」:移動到第n行行首。
10)按「n+Enter」:當前光標向下移動n行。
11)按「w」:光標從左到右,從上到下的跳到下一個字的開頭。
12)按「e」:光標從左到右,從上到下的跳到下一個字的結尾。
12)按「b」:光標從右到左,從下到上的跳到上一個字的開頭
【刪除】
1)按「x」:刪除光標所在位置的字符。
2)按「nx」:刪除光標所在位置開始往后的n個字符。
3)按「X」:刪除光標所在位置的前一個字符。
4)按「nX」:刪除光標所在位置的前n個字符。
5)按「dd」:刪除光標所在行。
6)按「ndd」:刪除光標所在行開始往下的n行。
【復制粘貼】
1)按「yy」:復制光標所在行到緩沖區。
2)按「nyy」:復制光標所在行開始往下的n行到緩沖區。
3)按「yw」:將光標所在位置開始到字尾的字符復制到緩沖區。
4)按「nyw」:將光標所在位置開始往后的n個字復制到緩沖區。
5)按「p」:將已復制的內容在光標的下一行粘貼上。
6)按「np」:將已復制的內容在光標的下一行粘貼n次。
【剪切】
1)按「dd」:剪切光標所在行。
2)按「ndd」:剪切光標所在行開始往下的n行。
3)按「p」:將已剪切的內容在光標的下一行粘貼上。
4)按「np」:將已剪切的內容在光標的下一行粘貼n次。
【撤銷】
1)按「u」:撤銷。
2)按「Ctrl+r」:恢復剛剛的撤銷。
【大小寫切換】
1)按「~」:完成光標所在位置字符的大小寫切換。
2)按「n~」:完成光標所在位置開始往后的n個字符的大小寫切換。
【替換】
1)按「r」:替換光標所在位置的字符。
2)按「R」:替換光標所到位置的字符,直到按下「Esc」鍵為止。
【更改】
1)按「cw」:將光標所在位置開始到字尾的字符刪除,并進入插入模式。
2)按「cnw」:將光標所在位置開始往后的n個字刪除,并進入插入模式。
【翻頁】
1)按「Ctrl+b」:上翻一頁。
2)按「Ctrl+f」:下翻一頁。
3)按「Ctrl+u」:上翻半頁。
4)按「Ctrl+d」:下翻半頁。
底行模式
在使用底行模式之前,記住先按「Esc」鍵確定你已經處于命令模式,再按「:」即可進入底行模式。
【行號設置】
1)「set?nu」:顯示行號。
2)「set?nonu」:取消行號。
【保存退出】
1)「w」:保存文件。
2)「q」:退出vim,如果無法離開vim,可在「q」后面跟一個「!」表示強制退出。
3)「wq」:保存退出。
【分屏指令】
1)「vs?文件名」:實現多文件的編輯。
2)「Ctrl+w+w」:光標在多屏幕下進行切換。
【執行指令】
1)「!+指令」:在不退出vim的情況下,可以在指令前面加上「!」就可以執行Linux的指令,例如查看目錄、編譯當前代碼等。
處理vim打開文件報錯的問題
如果我們在用vim編輯器處理文件時錯誤的退出當前的編輯(例如直接關閉云服務器或者虛擬機),那么再次用vim打開相同的文件時,就會出現如下報錯信息:
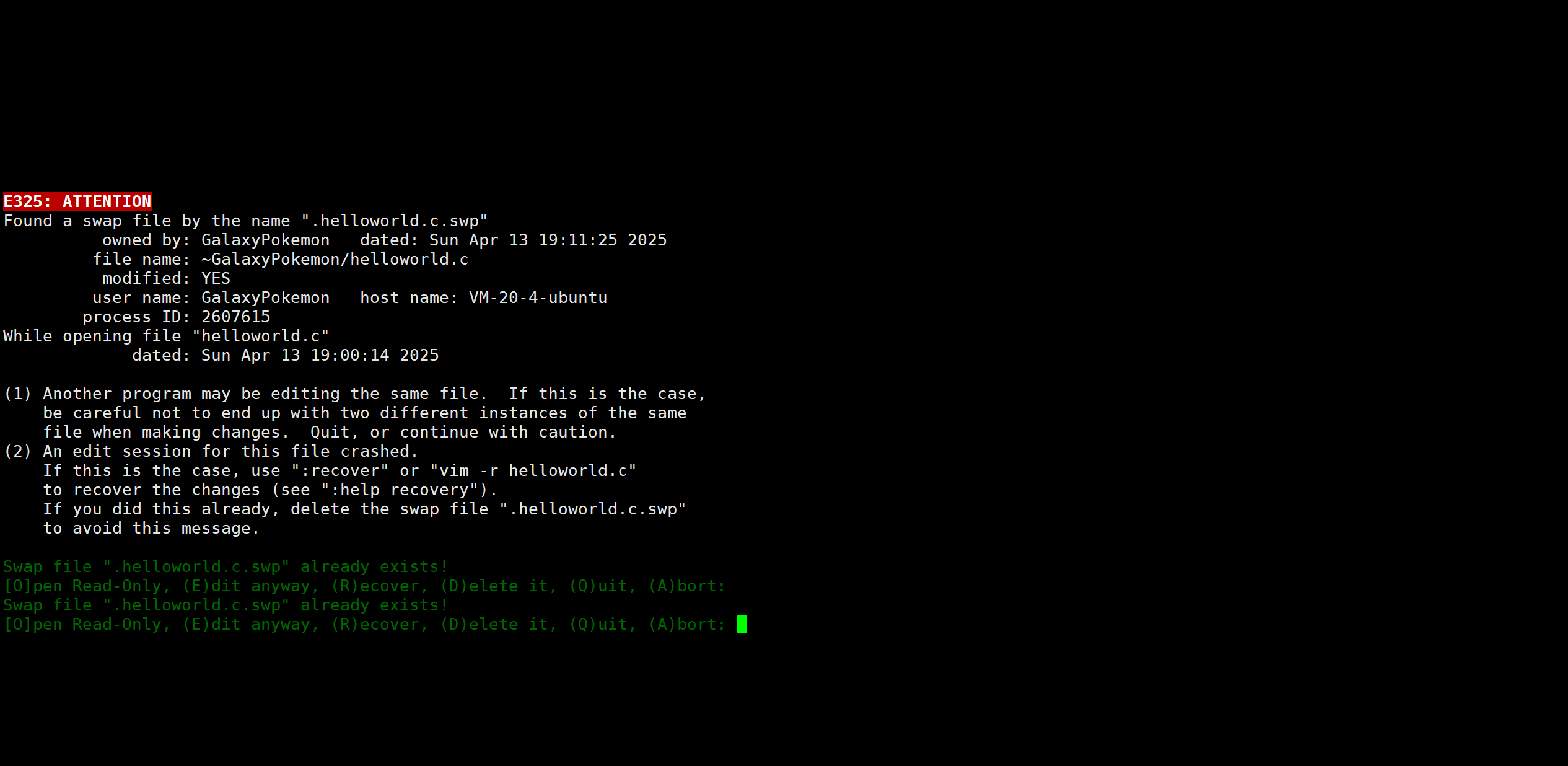
我們按如下的步驟解決:
- 第一步:選擇R(ecover)選項,即輸入字符e,之后會進入vim編輯器,直接進入底行模式正常退出即可
- 第二步:繼續用vim打開該文件,此時同樣會彈出相同的報錯信息,這次選擇(D)elele it選項,即輸入字符d,之后就會進入vim編輯器,此時問題已經得到解決,可以正常進行編寫代碼了。
?Linux編譯器-gcc/g++使用
為什么我們可以用C/C++做開發呢?
無論是在windows、還是Linux中,C++的開發環境不僅僅指的是vs、gcc、g++,更重要的是語言本身的頭文件(函數的聲明)和庫文件(函數的實現)。所以我們在安裝這些軟件的時候,同時也選擇了相關的開發包,會同步下載對應的頭文件和庫文件。
所以任何一款編譯型語言的使用,都必要需要安裝相應的開發包(頭文件和庫文件)
查看頭文件:ls /usr/include/
 ?
?
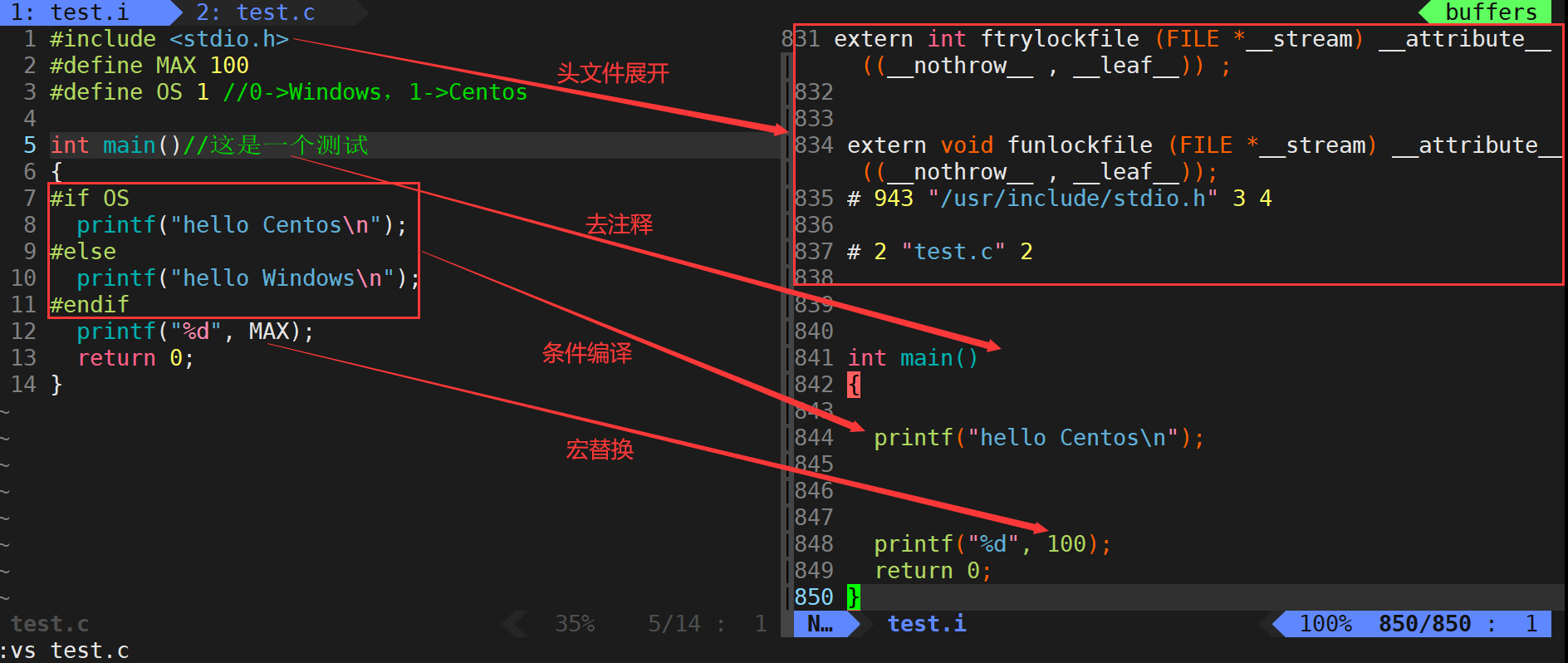
預處理(進行宏替換)
預處理階段會涉及到很多操作
去注釋
注釋我們一般用于對我們的代碼進行解釋說明,但并不參與編譯,所以是可以直接去掉的,節省文件的大小。
頭文件展開
頭文件里面包含了我們需要的一些函數的聲明,由于在鏈接之前各個文件都是獨立進行編譯和轉匯編的,所以頭文件將函數聲明展示出來其實就是為了在編譯過程的時候告訴編譯器,這個函數是存在的,一定要放行,而最后的函數定義一般得等到鏈接的時候才能找到。
條件編譯
條件編譯其實就是有選擇的編譯,比較常見的一種情況比如說我們要通過打印來觀察代碼的運行情況(調試),但是僅僅只是為了起到一個調試的作用,所以我們調試后還要刪掉其實有點可惜,所以我們可以通過條件編譯來對他進行保留,在必要的時候啟動這段代碼或者是去掉這段代碼。
gcc -E test.c -o test.i告訴gcc,從現在開始進行程序編譯,從預處理工作就停下來,不要往前走了??
- 預處理功能主要包括頭文件展開、去注釋、宏替換、條件編譯等。
- 預處理指令是以#開頭的代碼行。
- -E選項的作用是讓gcc/g++在預處理結束后停止編譯過程。
- -o選項是指目標文件,“xxx.i”文件為已經過預處理的原始程序。
 ?
?
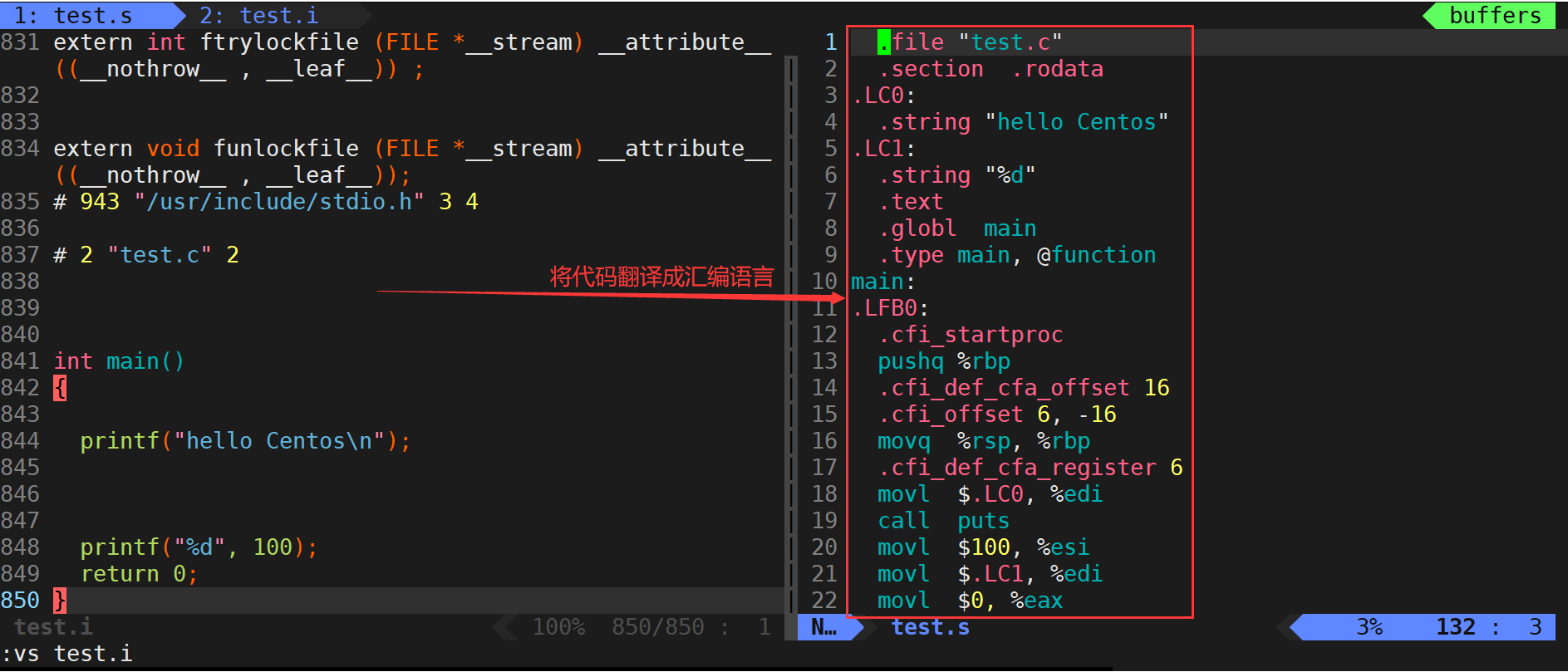
編譯(生成匯編)
gcc -S test.i -o test.s告訴gcc,從現在開始進行程序編譯,將編譯過程做完就停下來??
- 在這個階段中,gcc/g++首先檢查代碼的規范性、是否有語法錯誤等,以確定代碼的實際要做的工作,在檢查無誤后,將代碼翻譯成匯編語言。
- 用戶可以使用-S選項來進行查看,該選項只進行編譯而不進行匯編,生成匯編代碼。
- -o選項是指目標文件,“xxx.s”文件為已經過翻譯的原始程序。
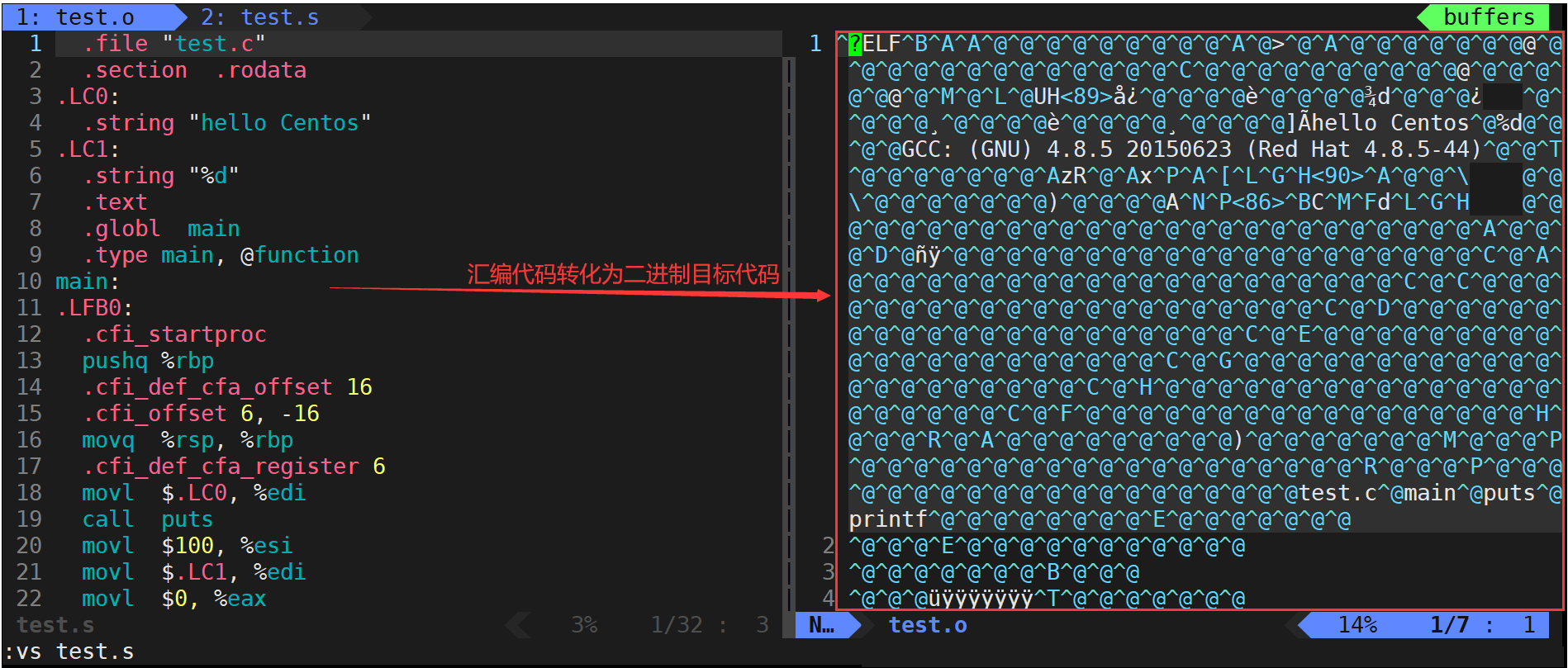
匯編(生成機器可識別代碼)
gcc -c test.s -o test.o- 匯編階段是把編譯階段生成的“xxx.s”文件轉成目標文件。
- 使用-c選項就可以得到匯編代碼轉化為“xxx.o”的二進制目標代碼了。
告訴gcc,從現在開始進行程序編譯,匯編結束就停下來
注意:有執行權限和具有可執行能力是兩回事,就好比一個富二代,他有繼承家產的權利,但是他未必就有管理家業的能力。所以.o文件是無法運行的!!需要經過鏈接才行!!?
鏈接(生成可執行文件或庫文件)
gcc test.o -o test- 在成功完成以上步驟之后,就進入了鏈接階段。
- 鏈接的主要任務就是將生成的各個“xxx.o”文件進行鏈接,生成可執行文件。
- gcc/g++不帶-E、-S、-c選項時,就默認生成預處理、編譯、匯編、鏈接全過程后的文件。
- 若不用-o選項指定生成文件的文件名,則默認生成的可執行文件名為a.out。
將目標文件和庫進行鏈接,就得到了可執行程序
注意:?鏈接后生成的也是二進制文件。
明明已經生成了機器可以讀懂的文件,為什么還需要鏈接才能運行呢?
原因就在于我們當前的文件并只有函數調用、函數聲明,卻沒有函數方法,所以必須要和庫(C語言標準庫,本質上就是一個文件)鏈接,函數的方法就存在于庫中(其實就是把源文件.c經過一定的編譯,然后打包,最后只給你提供一個文件)這樣做有兩個好處:
- 方便源文件的隱藏(未來我們想把程序給別人用,但不希望他看到源碼,也可以這樣)
- 不讓我們做重復工作(幫我們造好了輪子),站在巨人的肩膀上 。
所以軟件=頭文件的方法+庫文件提供的方法實現+你的代碼。
個人覺得在日常的學習中,我們要盡可能地去嘗試自己造輪子,研究底層,扎實內功,這樣才可能應對未來的一些更復雜的情況,而在以后工作的時候,盡可能用一些已經寫好的高效的代碼,避免重復工作。而如果需要自己造輪子,早期的學習就會給你提供很大的幫助。
.o和庫是如何鏈接的(靜態鏈接和動態鏈接)
動態庫文件和靜態庫文件
- 在Linux中:?.so(動態庫)? .a(靜態庫)
- 命名規則:libname.so.XXX
- 在windows中:.dll(動態庫)? .lib(靜態庫)
在Linux中,通過 ls /usr/lib64/ld-linux-x86-64.so*? 可以看到我們的動態庫文件

還有之前我們知道其實指令的本質就是可執行程序,所以我們也可以去查看指令所依賴的動態庫,我們會發現大部分都是用C的庫
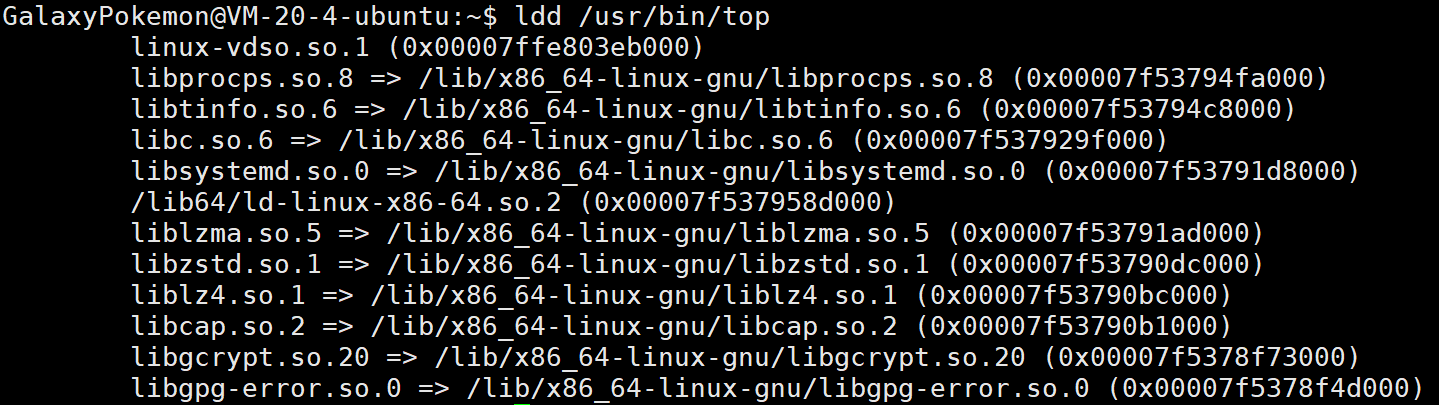
靜態庫的文件默認是沒有安裝的,需要通過以下指令去手動安裝
C靜態庫:sudo yum install -y glibc-static
C++靜態庫:sudo yum install -y libstdc++-static
動態庫和靜態庫理解
1. 假設我們考上了一所高中,這里不讓上網,但是你是一個喜歡打游戲的人,你通常會將打游戲這件事列入到自己每天的計劃表中,而你的學校附近恰好有一個網吧,你在將計劃進行到規定時間的時候就會翻墻出去上網,然后再回來。
- 自己的計劃表——可執行程序
- 學校——編譯器
- 網吧——動態庫
- 網吧里的電腦——庫文件
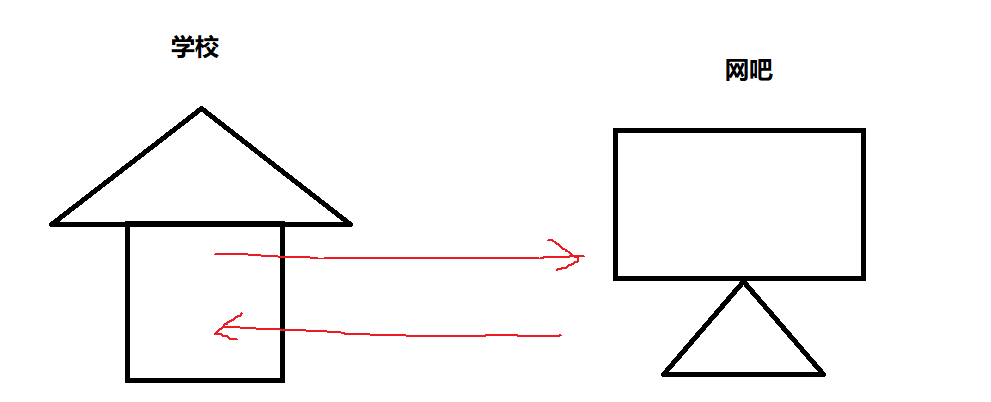
也就是說當程序執行到某個地方時,他會跳出到動態庫繼續執行,然后再回來,這個過程就是動態鏈接。
2. 假設有一天網吧老板突然被舉報,并且沒有營業執照而被迫查封,這個時候我的計劃就無法如期進行了,并且影響的不只是你,還有學校其他喜歡打游戲的人!
所以動態庫不能缺失!!一旦缺失影響的不僅僅是一個程序,而是多個程序都會崩潰!
3. 突然有一天學校允許學生上網了,這個時候網吧老板捕捉到了商機,把網吧的電腦搬出來開了一家二手電腦專賣店,然后喜歡打游戲的同學都過來購買了電腦了!!
二手電腦專賣店——靜態庫
二手電腦——庫文件
?也就是說,靜態庫進行靜態鏈接的時候,會將自己的方法拷貝到目標程序中,該程序以后不用再依賴靜態庫!!
4. 有一天那個老板又被舉報查封了,但是這個時候學校里的學生卻沒有感到傷心,因為大家都有自己的電腦了,店查不查封對他們沒什么影響。
所以靜態鏈接的程序并不依賴靜態庫,即使靜態庫丟失了程序也可以正常運行!
控制鏈接方式的選擇
當我們不做限制時,會默認使用動態鏈接。我們可以使用file指令進行查看。

其次,我們還可以使用ldd指令查看動態鏈接的可執行文件所依賴的庫。

(圖中的/lib64/libc.so.6就是當前云服務器當中的C標準庫)。?
雖然gcc和g++默認采用的是動態鏈接,但如果我們需要使用靜態鏈接,帶上-static選項即可。?
如果沒有-static,默認編譯可能會出現三種情況:動態鏈接->靜態鏈接->報錯。而有了static,就會去掉第一種情況,即靜態鏈接->報錯
gcc helloworld.c -o helloworld_s -static此時生成的可執行文件就是靜態鏈接的了。?

?我們可以查看源代碼相同,但鏈接方式不同而生成的兩個可執行程序test和test_s的大小。

這也證明了動態鏈接比較節省空間,而靜態鏈接比較浪費空間。?
動態鏈接和靜態鏈接的優缺點
動態庫:
- 優點:動態庫是共享庫,可以有效節省資源(磁盤空間、內存空間、網絡空間)
- 缺點:動態庫一旦缺失,所有的程序將無法運行
靜態庫:
- 優點:不依賴庫,程序可以獨立運行
- 缺點:體積大,消耗資源
?一般來說,我們在實際應用中更傾向于使用動態鏈接,因為體積大所帶來的影響是很大的,比方說你下個游戲要1G,但是用靜態鏈接可能就需要上百G,所以無論是我們還是Linux默認,都是會盡量選擇動態鏈接。
Linux調試器 - gdb
gdb使用須知
程序發布方式:
?1、debug版本:程序本身會被加入更多的調試信息,以便于進行調試。
?2、release版本:不會添加任何調試信息,是不可調試的。
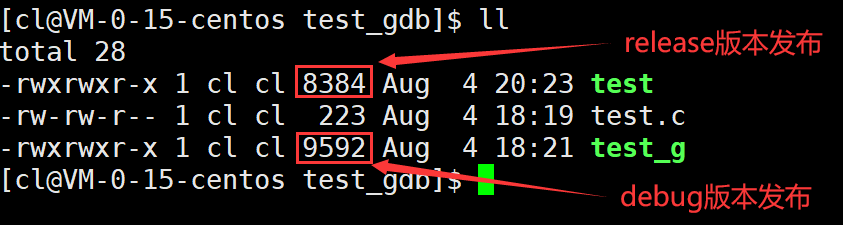
在Linux當中gcc/g++默認生成的可執行程序是release版本的,是不可被調試的。如果想生成debug版本,就需要在使用gcc/g++生成可執行程序時加上-g選項。

對同一份源代碼分別生成其release版本和debug版本的可執行程序,并通過ll指令可以看到,debug版本發布的可執行程序的大小比release版本發布的可執行程序的大小要大一點,其原因就是以debug版本發布的可執行程序當中包含了更多的調試信息。
gdb命令匯總
【進入gdb】
指令:?gdb?文件名
【調試】
1)「run/r」:運行代碼(啟動調試)。
2)「next/n」:逐過程調試。
3)「step/s」:逐語句調試。
4)「until?行號」:跳轉至指定行。
5)「finish」:執行完當前正在調用的函數后停下來(不能是主函數)。
6)「continue/c」:運行到下一個斷點處。
7)「set?var?變量=x」:修改變量的值為x。
【顯示】
1)「list/l?n」:顯示從第n行開始的源代碼,每次顯示10行,若n未給出則默認從上次的位置往下顯示.。
2)「list/l?函數名」:顯示該函數的源代碼。
3)「print/p?變量」:打印變量的值。
4)「print/p?&變量」:打印變量的地址。
5)「print/p?表達式」:打印表達式的值,通過表達式可以修改變量的值。
6)「display?變量」:將變量加入常顯示(每次停下來都顯示它的值)。
7)「display?&變量」:將變量的地址加入常顯示。
8)「undisplay?編號」:取消指定編號變量的常顯示。
9)「bt」:查看各級函數調用及參數。
10)「info/i?locals」:查看當前棧幀當中局部變量的值。
【斷點】
1)「break/b?n」:在第n行設置斷點。
2)「break/b?函數名」:在某函數體內第一行設置斷點。
3)「info?breakpoint/b」:查看已打斷點信息。
4)「delete/d?編號」:刪除指定編號的斷點。
5)「disable?編號」:禁用指定編號的斷點。
6)「enable?編號」:啟用指定編號的斷點。
【退出gdb】
1)「quit/q」:退出gdb。
Linux項目自動化構建工具 - make/Makefile
為什么我們會需要自動化構建工具?
? ? ? ? 一個工程中的源文件不計數,其按類型、功能、模塊分別放在若干個目錄中,make?le定義了一系列的 規則來指定,哪些文件需要先編譯,哪些文件需要后編譯,哪些文件需要重新編譯,甚至于進行更復雜的功能操作。
? ? ?所以,make?le帶來的好處就是——“自動化編譯”,一旦寫好,只需要一個make命令,整個工程完全自動編譯,極大的提高了軟件開發的效率。
?make是一條命令,Makefile是一個文件,兩個搭配使用,完成項目自動化構建。
依賴關系和依賴方法
在使用make/Makefile前我們首先應該理解各個文件之間的依賴關系以及它們之間的依賴方法。
依賴關系:?文件A的變更會影響到文件B,那么就稱文件B依賴于文件A。?
- 例如,test.o文件是由test.c文件通過預處理、編譯以及匯編之后生成的文件,所以test.c文件的改變會影響test.o,所以說test.o文件依賴于test.c文件。
依賴方法:?如果文件B依賴于文件A,那么通過文件A得到文件B的方法,就是文件B依賴于文件A的依賴方法。(就是二者通過什么方法聯系起來的)
- 例如,test.o依賴于test.c,而test.c通過gcc -c test.c -o test.o指令就可以得到test.o,那么test.o依賴于test.c的依賴方法就是gcc -c test.c -o test.o。
多文件編譯
當你的工程當中有多個源文件的時候,應該如何進行編譯生成可執行程序呢?

首先,我們可以直接使用gcc指令對多個源文件進行編譯,進而生成可執行程序。
gcc -o 輸出文件名 源文件
但進行多文件編譯的時候一般不使用源文件直接生成可執行程序,而是先用每個源文件各自生成自己的二進制文件,然后再將這些二進制文件通過鏈接生成可執行程序。

原因:
- 若是直接使用源文件生成可執行程序,那么其中一個源文件進行了修改,再生成可執行程序的時候就需要將所以的源文件重新進行編譯鏈接。
- 而若是先用每個源文件各自生成自己的二進制文件,那么其中一個源文件進行了修改,就只需重新編譯生成該源文件的二進制文件,然后再將這些二進制文件通過鏈接生成可執行程序即可。
注意:?編譯鏈接的時候不需要加上頭文件,因為編譯器通過源文件的內容可以知道所需的頭文件名字,而通過頭文件的包含方式(“尖括號”包含和“雙引號”包含),編譯器可以知道應該從何處去尋找所需頭文件。
但是隨著源文件個數的增加,我們每次重新生成可執行程序時,所需輸入的gcc指令的長度與個數也會隨之增加。這時我們就需要使用make和Makefile了,這將大大減少我們的工作量。
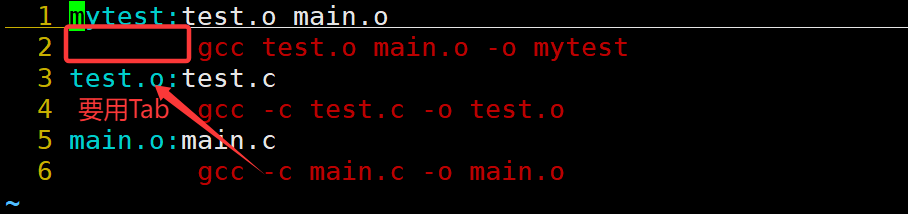
步驟一:?在源文件所在目錄下創建一個名為Makefile/makefile的文件。

步驟二:?編寫Makefile文件。
Makefile文件最簡單的編寫格式是,先寫出文件的依賴關系,然后寫出這些文件之間的依賴方法,依次寫下去。

在 Makefile 中,命令行必須以制表符(Tab)開頭,而不是空格。
 ?
?
我們會發現這個過程其實有點像是函數調用,特別像遞歸,形成了makefile的自動推導
所以其實我們亂序也可以,因為他會自己去找,如果找不到就會報錯。
?編寫完畢Makefile文件后保存退出,然后在命令行當中執行make指令便可以生成可執行程序,以及該過程產生的中間產物。

Makefile文件的簡寫方式:
- $@:表示依賴關系中的目標文件(冒號左側)。
- $^:表示依賴關系中的依賴文件列表(冒號右側全部)。
- $<:表示依賴關系中的第一個依賴文件(冒號右側第一個)。
例如以上Makefile文件可以簡寫為:
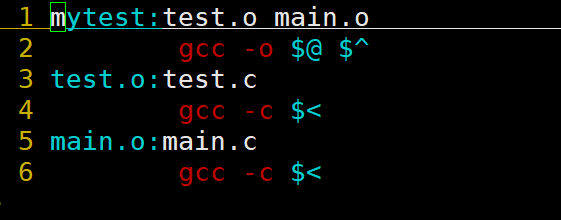
說明:?gcc/g++攜帶-c選項時,若不指定輸出文件的文件名,則默認輸出文件名為xxx.o,所以這里也可以不用指定輸出文件名
make原理
- make會在當前目錄下找名字為“Makefile”或“makefile”的文件。
- 如果找到,它會找文件當中的第一個目標文件,在上面的例子中,它會找到mytest這個文件,并把這個文件作為最終的目標文件。
- 如果mytest文件不存在,或是mytest所依賴的后面的test.o文件和main.o文件的文件修改時間比mytest文件新,那么它就會執行后面的依賴方法來生成mytest文件。
- 如果mytest所依賴的test.o文件不存在,那么make會在Makefile文件中尋找目標為test.o文件的依賴關系,如果找到則再根據其依賴方法生成test.o文件(類似于堆棧的過程)。
- 當然,你的test.c文件和main.c文件是存在的,于是make會生成test.o文件和main.o文件,然后再用test.o文件和main.o文件生成最終的mytest文件。
- make會一層又一層地去找文件的依賴關系,直到最終編譯出第一個目標文件。
- 在尋找的過程中,如果出現錯誤,例如最后被依賴的文件找不到,那么make就會直接退出,并報錯。
項目清理
在我們每次重新生成可執行程序前,都應該將上一次生成可執行程序時生成的一系列文件進行清理,但是如果我們每次都手動執行一系列指令進行清理工作的話,未免有些麻煩,因為每次清理時執行的都是相同的清理指令,這時我們可以將項目清理的指令也加入到Makefile文件當中。
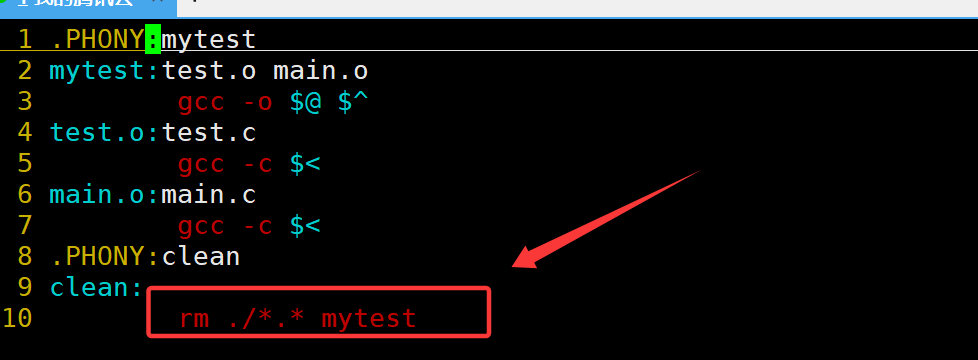
想clean這種,沒有被第一個目標文件直接或間接關聯,那么它后面所定義的命令將不會被自動執行,但我們可以顯示要make執行。
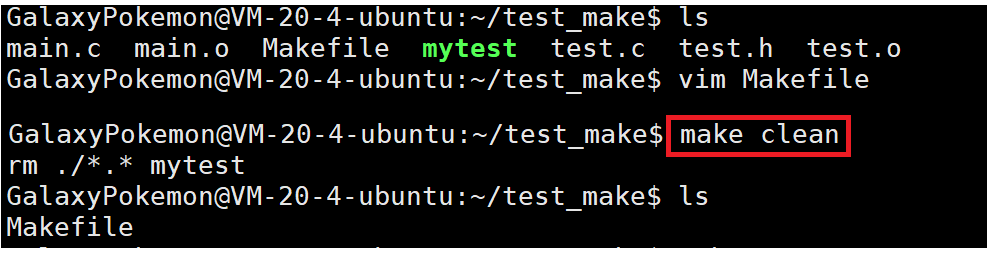
注:?一般將這種clean的目標文件設置為偽目標,用.PHONY修飾,偽目標的特性是:總是被執行。
為什么make執行前面的,而make clean執行后面的呢?
原因就是因為,如果make沒有指定的話,默認就是從第一行開始掃描到第一個make就執行,所以建議將編譯的工作放到最前面,然后把清理的工作寫到后面!!
為什么不會允許多次make呢??(重點)
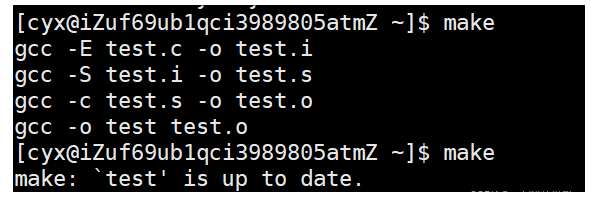
?我們會發現我們make一次之后,就不然我們繼續make了。這是為啥呢?
為了提高編譯效率!如果我們的文件相較于之前沒有發生過任何的變化,那么就不能進行make(因為系統覺得沒必要,純屬浪費時間),如果相較于之前的內容有更新過,那么就會重新形成一次新的可執行程序覆蓋掉。
那么我們的系統究竟是如何做到判斷這個文件是否被更新過呢??難道是將文件掃描一遍??顯然不現實。其原理如下:
首先,可執行程序一定是由源文件形成的,所以源文件的最近修改時間一定比可執行程序的最近時間要老——>推到得出,如果我們的源文件的最近修改文件比可執行程序時間新,那么就說明這個文件被修改過!!!
總結:只需要比較可執行程序的時間和源文件的最近修改時間即可!
- .exe比.c老,說明被修改過,需要重新編譯
- .exe比.c新,說明沒有被修改過,就不需要重新編譯(提高了編譯效率!)
stat指令
stat指令是查看文件或者文件系統的詳細信息
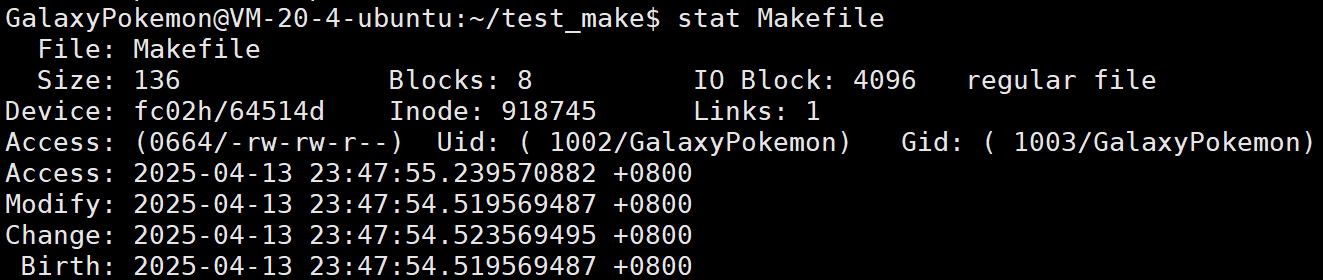
?Access表示訪問時間,任何增刪查改都算訪問操作
Modify表示修改文件內容的時間
Change表示修改文件屬性的時間
按道理來說,Access的修改頻率應該是最高的,但有些時候是無意義的,并且由于磁盤是屬于外部設備,如果頻繁訪問的話,效率是極低的,所以在設計的時候,Access的時間其實是取決于另外兩個時間的!!
(1)當僅讀取或者訪問文件文件時,只有Access會改變
(2)當修改文件內容時,Modify(文件內容)和Change(文件大小)都會改變,Access不一定改變
(3)當修改文件權限屬性時, 只有Change會改變
.PHONY:
? ? 所以make會根據源文件和目標文件的新舊,判定是否需要重新執行依賴關系進行編譯,那么如果我們希望依賴關系總是被執行,就需要.PHONY:(偽目標)
? ? ?.PHONY:其實就是告訴make,這個目標是我的朋友,只要他想編你就讓他編,不要阻攔,所以這個關鍵詞常用在clean的身上。
在一個文件不存在的時候,touch的作用是將該文件新建出來,但是如果這個文件存在的話,touch就可以將三個時間都修改成當前的時候,或者是用-a -m -c 選項來強制修改其中一個。
?Linux第一個小程序 - 進度條
行緩沖區的概念
首先,我們來感受一下行緩沖區的存在,在Linux當中以下代碼的運行結果是什么樣的?
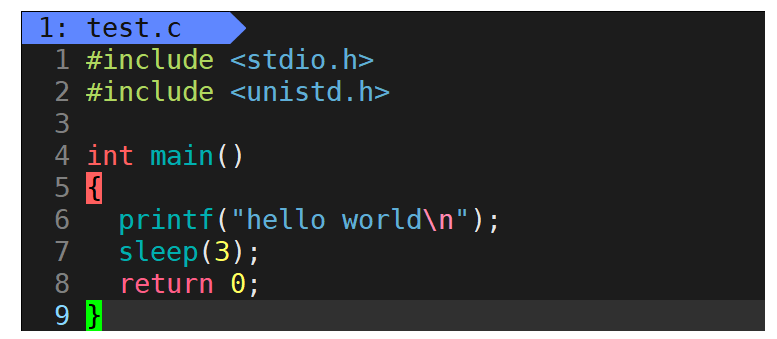
對于此代碼,大家應該都沒問題,當然是先輸出字符串hello world然后休眠3秒之后結束運行。那么對于以下代碼呢?
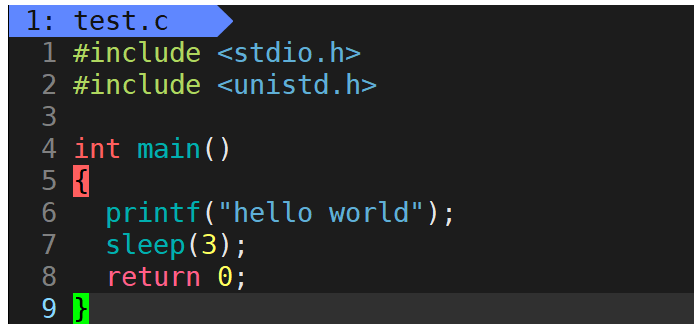
可以看到代碼中僅僅刪除了字符串后面的’\n’,那么代碼的運行結果還與之前相同嗎?答案否定的,該代碼的運行結果是:先休眠3秒,然后打印字符串hello world之后結束運行。該現象就證明了行緩沖區的存在。
顯示器對應的是行刷新,即當緩沖區當中遇到’\n’或是緩沖區被寫滿才會被打印出來,而在第二份代碼當中并沒有’\n’,所以字符串hello world先被寫到緩沖區當中去了,然后休眠3秒后,直到程序運行結束時才將hello world打印到顯示器當中。
\r和\n
- \r:?回車,使光標回到本行行首。
- \n:?換行,使光標下移一格。
而我們鍵盤上的Enter鍵實際上就等價于\n+\r。

既然是\r是使光標回到本行行首,那么如果我們向顯示器上寫了一個數之后再讓光標回到本行行首,然后再寫一個數,不就相當于將前面一個數字覆蓋了嗎?
但這里有一個問題:不使用’\n’進行換行怎么將緩沖區當中數據打印出來?
這里我們可以使用fflush函數,該函數可以刷新緩沖區,即將緩沖區當中的數據刷新當顯示器當中。
參數可以是:標準輸出(stdin)、標準輸入(stdout)、標準錯誤(stderr)?
對此我們可以編寫一個倒計時的程序。
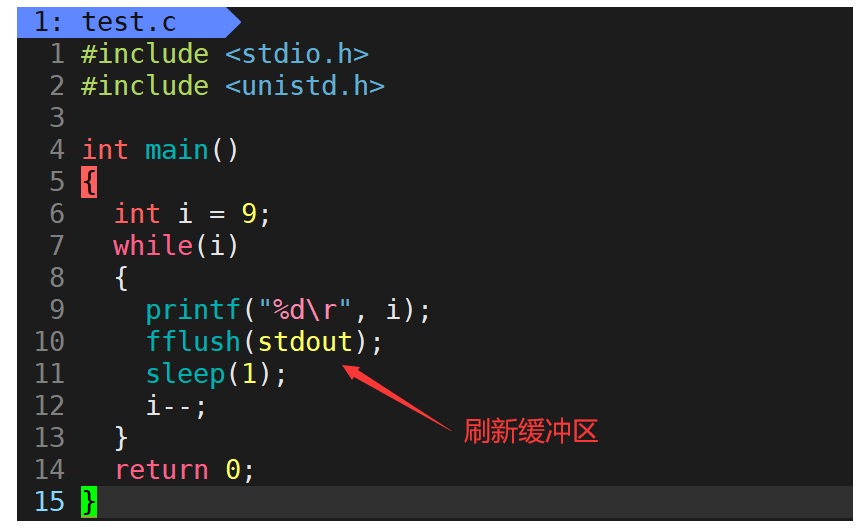
在輸出下一個數之前都讓光標先回到本行行首,就得到了倒計時的效果。




:拾遺 - imgproc 基礎操作(上))

)







Kafka核心原理揭秘:從入門到企業級實戰應用)




CPU,GPU,DPU的區別)
