CGAN 原理及實現
- 一、CGAN 原理
- 1.1 基本概念
- 1.2 與傳統GAN的區別
- 1.3 目標函數
- 1.4 損失函數
- 1.5 條件信息的融合方式
- 1.6 與其他GAN變體的對比
- 1.7 CGAN的應用
- 1.8 改進與變體
- 二、CGAN 實現
- 2.1 導包
- 2.2 數據加載和處理
- 2.3 構建生成器
- 2.4 構建判別器
- 2.5 訓練和保存模型
- 2.6 繪制訓練損失
- 2.7 圖片轉GIF
- 2.8 模型加載和生成
一、CGAN 原理
1.1 基本概念
條件生成對抗網絡(Conditional GAN, CGAN)是GAN的一種擴展,它在生成器和判別器中都加入了額外的條件信息 y y y。這個條件信息可以是類別標簽、文本描述或其他形式的輔助信息。
1.2 與傳統GAN的區別
- 傳統GAN: G ( z ) G(z) G(z) → 生成樣本, D ( x ) D(x) D(x) → 判斷真實/生成
CGAN: G ( z ∣ y ) G(z|y) G(z∣y) → 基于條件 y y y 生成樣本, D ( x ∣ y ) D(x|y) D(x∣y) → 基于條件 y y y 判斷真實/生成
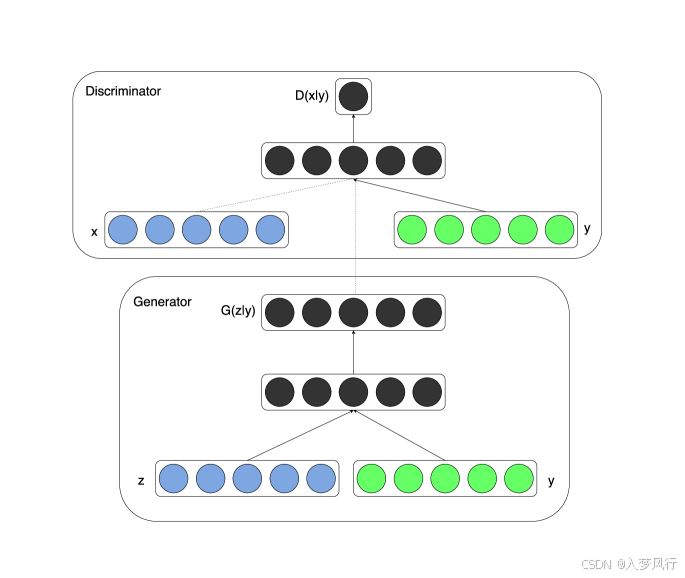
1.3 目標函數
CGAN的目標函數可以表示為: m i n G m a x D V ( D , G ) = 𝔼 x ~ p data [ l o g D ( x ∣ y ) ] + 𝔼 z ~ p z ( z ) [ l o g ( 1 ? D ( G ( z ∣ y ) ∣ y ) ) ] min_G max_D V(D,G) = 𝔼_{x \sim p_{\text{data}}}[log D(x|y)] + 𝔼_{z \sim p_z(z)}[log(1 - D(G(z|y)|y))] minG?maxD?V(D,G)=Ex~pdata??[logD(x∣y)]+Ez~pz?(z)?[log(1?D(G(z∣y)∣y))],其中 y y y 是條件信息。
1.4 損失函數
(1) 判別器(Discriminator)的損失函數
\space ? \space ?判別器需要同時判斷:
真實圖像是否真實(且匹配其標簽)生成圖像是否虛假(且匹配其標簽)
損失函數公式:
L D = E x , y ~ p data [ log ? D ( x ∣ y ) ] ? 真實樣本損失 + E z ~ p z , y ~ p labels [ log ? ( 1 ? D ( G ( z ∣ y ) ∣ y ) ] ? 生成樣本損失 \mathcal{L}_D = \underbrace{\mathbb{E}_{x,y \sim p_{\text{data}}}[\log D(x|y)]}_{\text{真實樣本損失}} + \underbrace{\mathbb{E}_{z \sim p_z, y \sim p_{\text{labels}}}[\log (1 - D(G(z|y)|y)]}_{\text{生成樣本損失}} LD?=真實樣本損失 Ex,y~pdata??[logD(x∣y)]??+生成樣本損失 Ez~pz?,y~plabels??[log(1?D(G(z∣y)∣y)]??
(2)生成器(Generator)的損失函數
\space ? 生成器的目標是欺騙判別器,使其認為生成的圖像是真實的(且匹配條件標簽 y y y)。
損失函數公式:
L G = E z ~ p z , y ~ p labels [ log ? ( 1 ? D ( G ( z ∣ y ) ∣ y ) ] ? 原始形式 或 ? E z , y [ log ? D ( G ( z ∣ y ) ∣ y ) ] ? 改進形式 \mathcal{L}_G = \underbrace{\mathbb{E}_{z \sim p_z, y \sim p_{\text{labels}}}[\log (1 - D(G(z|y)|y)]}_{\text{原始形式}} \quad \text{或} \quad \underbrace{-\mathbb{E}_{z,y}[\log D(G(z|y)|y)]}_{\text{改進形式}} LG?=原始形式 Ez~pz?,y~plabels??[log(1?D(G(z∣y)∣y)]??或改進形式 ?Ez,y?[logD(G(z∣y)∣y)]??
1.5 條件信息的融合方式
在損失計算中,條件標簽通過以下方式參與:
- 生成器輸入:噪聲
z和標簽y拼接后輸入生成器gen_input = torch.cat([z, label_embed], dim=1) # z: [batch, z_dim], label_embed: [batch, embed_dim] - 判別器輸入:圖像和標簽拼接后輸入判別器
# 圖像x: [batch, C, H, W], 標簽擴展為 [batch, embed_dim, H, W] label_expanded = label_embed.unsqueeze(-1).unsqueeze(-1).expand(-1, -1, H, W) disc_input = torch.cat([x, label_expanded], dim=1) # 沿通道維度拼接
1.6 與其他GAN變體的對比
| 損失函數特性 | 標準GAN | 條件GAN(CGAN) | WGAN-GP |
|---|---|---|---|
| 判別器輸出 | 概率值 (0~1) | 條件概率值 | 未限制的分數 |
| 生成器目標 | 欺騙判別器 | 生成符合標簽的圖像 | 最小化Wasserstein距離 |
| 梯度穩定性 | 易崩潰 | 依賴條件強度 | 通過梯度懲罰穩定 |
1.7 CGAN的應用
- 圖像生成:根據類別標簽生成特定類型的圖像
- 圖像到圖像轉換:如將語義標簽圖轉換為真實圖像
- 文本到圖像生成:根據文本描述生成圖像
- 數據增強:為特定類別生成額外的訓練樣本
1.8 改進與變體
- AC-GAN:輔助分類器GAN,在判別器中增加分類任務
- InfoGAN:學習可解釋的潛在表示
- StackGAN:分階段生成高分辨率圖像
- ProGAN:漸進式生成高分辨率圖像
條件GAN通過引入條件信息,使得生成過程更加可控,能夠生成特定類別的樣本,在實際應用中具有廣泛的用途。
二、CGAN 實現
2.1 導包
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from torchvision import datasets, transforms
from torchvision.utils import save_image
import numpy as npimport os
import time
import matplotlib.pyplot as plt
from tqdm.notebook import tqdm # 判斷是否存在可用的GPU
device=torch.device("cuda:0" if torch.cuda.is_available() else "cpu")# 設置日志
time_str = time.strftime("%Y-%m-%d_%H-%M-%S", time.localtime()) # 生成當前時間格式(例如:2024-03-15_14-30-00)
log_dir = os.path.join("./logs/cgan", time_str) # 設置日志路徑,格式如:./logs/cgan/2024-03-15_14-30-00
os.makedirs(log_dir, exist_ok=True) # 自動創建目錄
writer = SummaryWriter(log_dir=log_dir) # 初始化 SummaryWriteros.makedirs("./img/cgan_mnist", exist_ok=True) # 存放生成樣本目錄
os.makedirs("./model", exist_ok=True) # 模型存放目錄
2.2 數據加載和處理
# 加載 MNIST 數據集
def load_data(batch_size=64,img_shape=(1,32,32)):transform = transforms.Compose([transforms.Resize((img_shape[1],img_shape[2])),transforms.ToTensor(), # 將圖像轉換為張量transforms.Normalize(mean=[0.5], std=[0.5]) # 歸一化到[-1,1]])# 下載訓練集和測試集train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)# 創建 DataLoadertrain_loader = DataLoader(dataset=train_dataset, batch_size=batch_size, num_workers=2,shuffle=True)test_loader = DataLoader(dataset=test_dataset, batch_size=batch_size, num_workers=2,shuffle=False)return train_loader, test_loader
2.3 構建生成器
class Generator(nn.Module):"""生成器"""def __init__(self, img_shape=(1,32,32),latent_dim=100,num_classes=10,label_embed_dim=10):"""Args:img_shape (int, optional): 生成圖片大小,默認CHW=1*32*32latent_dim (int, optional): 潛在噪聲向量的維度。默認100維,作為生成器的隨機輸入種子。 num_classes (int, optional): 類別數量。默認10(例如MNIST的0-9數字分類)。決定標簽嵌入矩陣的行數。label_embed_dim (int, optional): 標簽嵌入向量的維度。默認10維。將離散標簽映射為連續向量的維度,影響條件信息的表達能力。 """super(Generator, self).__init__()# 定義嵌入層 [batch_szie]-> [batch_size,label_embed_dim]=[64,10]self.label_embed = nn.Embedding(num_classes, label_embed_dim) # num_classes 個類別, label_embed_dim 維嵌入# 定義網絡塊def block(in_feat, out_feat, normalize=True):layers = [nn.Linear(in_feat, out_feat)]if normalize:layers.append(nn.BatchNorm1d(out_feat, 0.8))layers.append(nn.LeakyReLU(negative_slope=0.2, inplace=True))return layers# 定義模型架構self.model = nn.Sequential(*block(latent_dim + label_embed_dim, 128, normalize=False),*block(128, 256),*block(256, 512),*block(512, 1024),nn.Linear(1024, int(np.prod(img_shape))), # [batch_size,1024]-> [batch_size,1*32*32]nn.Tanh() # 輸出歸一化到[-1,1] )def forward(self, z, labels):# 嵌入標簽 [batch_size]-> [batch_size,label_embed_dim]=[64,10]label_embed = self.label_embed(labels)# 拼接嵌入標簽和噪聲 ->[batch_size,latent_dim + label_embed_dim]=[64,100+10]gen_input = torch.cat([label_embed, z], dim=1)# 生成圖片-> [batch_size,C,H,W]=[64,1,32,32]img = self.model(gen_input) # -> [batch_size,C*H*W]=[64,1*32*32]img = img.view(img.shape[0], *img_shape) # [batch_size,C*H*W]-> [batch_size,C,H,W]=[64,1,32,32]return img
2.4 構建判別器
class Discriminator(nn.Module):"""判別器"""def __init__(self, img_shape=(1,32,32),label_embed_dim=10):super(Discriminator, self).__init__()# 定義嵌入層 [batch_szie]-> [batch_size,label_embed_dim]=[64,10]self.label_embed = nn.Embedding(num_classes, label_embed_dim) # num_classes 個類別, label_embed_dim 維嵌入# 定義模型結構self.model = nn.Sequential(nn.Linear(label_embed_dim+ int(np.prod(img_shape)), 512), # [64,10+1*32*32]-> [64,512]nn.LeakyReLU(negative_slope=0.2, inplace=True),nn.Linear(512, 512),nn.Dropout(0.4),nn.LeakyReLU(negative_slope=0.2, inplace=True),nn.Linear(512, 512),nn.Dropout(0.4),nn.LeakyReLU(negative_slope=0.2, inplace=True),nn.Linear(512, 1),)def forward(self, img, labels):# 嵌入標簽 [batch_size]-> [batch_size,label_embed_dim]=[64,10]label_embed = self.label_embed(labels)# 輸入圖片展平[64,1,32,32]-> [64,1*32*32]img=img.view(img.shape[0], -1)# 拼接嵌入標簽和輸入圖片 ->[batch_size,label_embed_dim + C*H*W]=[64,10+1*32*32]dis_input = torch.cat([label_embed, img], dim=1)# 進行判定validity = self.model(dis_input)return validity # -> [64,1]
2.5 訓練和保存模型
1. 定義保存生成樣本
def sample_image(G,n_row, batches_done,latent_dim=100,device=device):"""Saves a grid of generated digits ranging from 0 to n_classes"""# 隨機噪聲-> [n_row ** 2,latent_dim]=[100,100]z=torch.normal(0,1,size=(n_row ** 2,latent_dim),device=device) #從正態分布中抽樣# 條件標簽->[100]labels = torch.arange(n_row, dtype=torch.long, device=device).repeat_interleave(n_row)gen_imgs = G(z, labels)save_image(gen_imgs.data, "./img/cgan_mnist/%d.png" % batches_done, nrow=n_row, normalize=True)
2. 訓練和保存
# 設置超參數
batch_size = 64
epochs = 200
lr= 0.0002
latent_dim=100 # 生成器輸入噪聲向量的長度(維數)
sample_interval=400 #每400次迭代保存生成樣本
img_shape = (1,32,32) # 圖片大小
num_classes=10 # 分類數
label_embed_dim=10 # 嵌入維數# 加載數據
train_loader,_= load_data(batch_size=batch_size,img_shape=img_shape)# 實例化生成器G、判別器D
G=Generator().to(device)
D=Discriminator().to(device)# 設置優化器
optimizer_G = torch.optim.Adam(G.parameters(), lr=lr,betas=(0.5, 0.999))
optimizer_D = torch.optim.Adam(D.parameters(), lr=lr,betas=(0.5, 0.999))# 損失函數
loss_fn=nn.BCEWithLogitsLoss()# 開始訓練
dis_costs,gen_costs = [],[] # 記錄生成器和判別器每次迭代的開銷(損失)
start_time = time.time() # 計時器
loader_len=len(train_loader) #訓練集加載器的長度
for epoch in range(epochs):# 進入訓練模式G.train()D.train()#記錄生成器G和判別器D的總損失(1個 epoch 內)gen_loss_sum,dis_loss_sum=0.0,0.0loop = tqdm(train_loader, desc=f"第{epoch+1}輪")for i, (real_imgs, real_labels) in enumerate(loop):real_imgs=real_imgs.to(device) # [B,C,H,W]real_labels=real_labels.to(device) # [B]# 平滑真假標簽,2維[B,1]valid_labels = torch.empty(real_imgs.shape[0], 1, device=device).uniform_(0.9, 1.0).requires_grad_(False) # 替代1.0fake_labels = torch.empty(real_imgs.shape[0], 1, device=device).uniform_(0.0, 0.1).requires_grad_(False) # 替代0.0# -----------------# 訓練生成器# -----------------# 獲取噪聲樣本[batch_size,latent_dim]及對應的條件標簽 [batch_size]z=torch.normal(0,1,size=(real_imgs.shape[0],latent_dim),device=device) #從正態分布中抽樣gen_labels = torch.randint(0, num_classes, (real_imgs.shape[0],), device=device, dtype=torch.long) # 0~9整數之間,隨機抽 real_imgs.shape[0]次# 計算生成器損失gen_imgs=G(z,gen_labels)gen_loss=loss_fn(D(gen_imgs,gen_labels),valid_labels)# 更新生成器參數optimizer_G.zero_grad() #梯度清零gen_loss.backward() #反向傳播,計算梯度optimizer_G.step() #更新生成器# -----------------# 訓練判別器# -----------------# 計算判別器損失# Step-1:對真實圖片損失valid_loss=loss_fn(D(real_imgs,real_labels),valid_labels)# Step-2:對生成圖片損失fake_loss=loss_fn(D(gen_imgs.detach(),gen_labels),fake_labels)# Step-3:整體損失dis_loss=(valid_loss+fake_loss)/2.0# 更新判別器參數optimizer_D.zero_grad() #梯度清零dis_loss.backward() #反向傳播,計算梯度optimizer_D.step() #更新判斷器 # 對生成器和判別器每次迭代的損失進行累加gen_loss_sum+=gen_lossdis_loss_sum+=dis_lossgen_costs.append(gen_loss.item())dis_costs.append(dis_loss.item())# 每 sample_interval 次迭代保存生成樣本batches_done = epoch * loader_len + iif batches_done % sample_interval == 0:sample_image(G=G,n_row=10, batches_done=batches_done)# 更新進度條loop.set_postfix(mean_gen_loss=f"{gen_loss_sum/(loop.n + 1):.8f}",mean_dis_loss=f"{dis_loss_sum/(loop.n + 1):.8f}")writer.add_scalars(main_tag="Train Losses", tag_scalar_dict={"Generator": gen_loss,"Discriminator": dis_loss,},global_step=batches_done # X軸坐標)
writer.close()
print('總共訓練用時: %.2f min' % ((time.time() - start_time)/60))#僅保存模型的參數(權重和偏置),靈活性高,可以在不同的模型結構之間加載參數
torch.save(G.state_dict(), "./model/CGAN_G.pth")
torch.save(D.state_dict(), "./model/CGAN_D.pth")
2.6 繪制訓練損失
# 創建畫布
plt.figure(figsize=(10, 5))
ax1 = plt.subplot(1, 1, 1)# 繪制曲線
ax1.plot(range(len(gen_costs)), gen_costs, label='Generator loss', linewidth=2)
ax1.plot(range(len(dis_costs)), dis_costs, label='Discriminator loss', linewidth=2)ax1.set_xlabel('Iterations', fontsize=12)
ax1.set_ylabel('Loss', fontsize=12)
ax1.set_title('CGAN Training Loss', fontsize=14)
ax1.legend(fontsize=10)
ax1.grid(True, linestyle='--', alpha=0.6)ax2 = ax1.twiny() # 創建共享Y軸的新X軸
newlabel = list(range(epochs+1)) # Epoch標簽 [0,1,2,...]
iter_per_epoch = len(train_loader) # 每個epoch的iteration次數
newpos = [e*iter_per_epoch for e in newlabel] # 計算Epoch對應的iteration位置ax2.set_xticks(newpos[::10])
ax2.set_xticklabels(newlabel[::10]) ax2.xaxis.set_ticks_position('bottom')
ax2.xaxis.set_label_position('bottom')
ax2.spines['bottom'].set_position(('outward', 45)) # 坐標軸下移45點
ax2.set_xlabel('Epochs') # 設置軸標簽
ax2.set_xlim(ax1.get_xlim()) # 與主X軸范圍同步plt.tight_layout()
plt.savefig('cgan_loss.png', dpi=300)
plt.show()


2.7 圖片轉GIF
from PIL import Imagedef create_gif(img_dir="./img/cgan_mnist", output_file="./img/cgan_mnist/cgan_figure.gif", duration=100):images = []img_paths = [f for f in os.listdir(img_dir) if f.endswith(".png")]img_paths_sorted = sorted(img_paths,key=lambda x: (int(x.split('.')[0]), # (如 400.png 的 400)))for img_file in img_paths_sorted:img = Image.open(os.path.join(img_dir, img_file))images.append(img)images[0].save(output_file, save_all=True, append_images=images[1:], duration=duration, loop=0)print(f"GIF已保存至 {output_file}")
create_gif()

2.8 模型加載和生成
#載入訓練好的模型
G = Generator() # 定義模型結構
G.load_state_dict(torch.load("./model/CGAN_G.pth",weights_only=True,map_location=device)) # 加載保存的參數
G.to(device) # 將模型移動到設備(GPU 或 CPU)
G.eval() # 將模型設置為評估模式# 獲取噪聲樣本[10,100]及對應的條件標簽 [10]
z=torch.normal(0,1,size=(10,100),device=device) #從正態分布中抽樣
gen_labels = torch.arange(10, dtype=torch.long, device=device) #0~9整數#生成假樣本
gen_imgs=G(z,gen_labels).view(-1,32,32) # 4維->3維
gen_imgs=gen_imgs.detach().cpu().numpy()# #繪制
plt.figure(figsize=(3, 2))
for i in range(10):plt.subplot(2, 5, i + 1) plt.xticks([], []) plt.yticks([], []) plt.imshow(gen_imgs[i], cmap='gray') plt.title(f"Figure {i}", fontsize=5)
plt.tight_layout()
plt.show()






)



—— 子串、普通數組、矩陣)









