單選
1.以下低功耗措施中,哪種不是降低電路翻轉率的方法?
A.在不進行算術運算的時候,使這些模塊的輸入保持不變,不讓新的操作數進來
B.采用Gray 碼或One‐hot 碼作為狀態機編碼
C.減少電路中的glitch
D.重新安排“if‐else”表達試,可將毛刺或快變化信號移至邏輯錐體的前部
正確答案是:D. 重新安排“if-else”表達式,可將毛刺或快變化信號移至邏輯錐體的前部
以下是詳細分析:
低功耗設計與電路翻轉率
在數字電路中,動態功耗主要由信號翻轉(即邏輯電平的變化)引起。降低電路翻轉率是減少動態功耗的重要手段之一。以下是對各選項的分析:
A. 在不進行算術運算的時候,使這些模塊的輸入保持不變,不讓新的操作數進來
是降低電路翻轉率的方法:
如果模塊的輸入保持不變,則輸出也不會發生變化,從而避免了不必要的翻轉。
這是一種有效的低功耗措施。
B. 采用 Gray 碼或 One-hot 碼作為狀態機編碼
是降低電路翻轉率的方法:
Gray 碼:相鄰狀態之間只有一位發生變化,因此狀態切換時的翻轉次數最少。
One-hot 碼:每個狀態僅有一個位為 1,其余位為 0。雖然需要更多的觸發器,但狀態切換時翻轉次數較少。
使用這些編碼方式可以顯著減少狀態機翻轉率。
C. 減少電路中的 glitch
是降低電路翻轉率的方法:
Glitch 是由于組合邏輯的競爭冒險導致的短暫錯誤信號,會引起額外的翻轉。
通過優化邏輯設計、插入寄存器或調整時序,可以減少 glitch,從而降低翻轉率。
D. 重新安排“if-else”表達式,可將毛刺或快變化信號移至邏輯錐體的前部
不是降低電路翻轉率的方法:
將毛刺或快變化信號移至邏輯錐體的前部,可能會增加后續邏輯門的翻轉次數。
毛刺和快變化信號傳播到更多邏輯門后,會導致更多的翻轉,反而可能增加功耗。
因此,這種方法并不能有效降低電路翻轉率。
*2.以下Verilog 代碼中,a=12,b=10.則z的運算結果為:
Input [3:0]a;
Input [3:0] b;
output signed [7:0] z;
wire signed [3:0]c;
assign c= a[3:0]b[3:0];
assign z=c;
A.120
B.‐8
C.8
D.‐120
正確答案是:B. -8
以下是詳細分析:
代碼分析
輸入和輸出定義
a 和 b 是 4 位的有符號數(signed [3:0])。
a = 12,二進制表示為:1100。
b = 10,二進制表示為:1010。
c 是一個 4 位的有符號中間變量(signed [3:0])。
z 是一個 8 位的有符號輸出(signed [7:0])。
計算過程
乘法運算:
Verilog
深色版本
assign c = a[3:0] * b[3:0];
在 Verilog 中,a 和 b 被視為有符號數(signed),因此它們的實際值需要考慮符號位。
a = 12 的二進制表示為 1100,但由于它是有符號數,最高位是符號位。1100 表示的是 -4(以補碼形式解釋)。
b = 10 的二進制表示為 1010,同樣是有符號數,1010 表示的是 -6(以補碼形式解釋)。
c 是一個 4 位的有符號數(signed [3:0]),而乘法結果 24 的二進制表示為 00011000(8 位)。
截斷到 4 位時,只保留低 4 位:1000。
1000 作為有符號數,表示的是 -8(以補碼形式解釋)。
賦值給 z:
Verilog
深色版本
assign z = c;
z 是一個 8 位的有符號數(signed [7:0]),因此會將 c 的值進行符號擴展。
c = -8 的 4 位二進制表示為 1000,符號擴展到 8 位后為 11111000。
11111000 作為有符號數,仍然表示 -8。
選項分析
A. 120:
錯誤。c 被截斷為 4 位,不可能得到 120。
B. -8:
正確。根據上述分析,z 的最終值為 -8。
C. 8:
錯誤。c 的值在截斷后為負數,z 不可能是正數。
D. -120:
錯誤。c 的值被截斷為 4 位,不可能得到 -120。
3.constraint c_0{
src dist {0:=30, [1:3]:=90};
請問如上表達式約束,src數值為0的概率為多大:( )
A. 0.2
B. 0.25
C. 0.1
D. 0.6
正確答案是:C. 0.1
:= 操作符表示值范圍內的每一個值得權重是相同的,:/操作符表示權重平均分到值范圍內的每一個值。
Systemverilog 中權重分布由操作符dist實現,有兩種形式:“:=”或“:/”。
“:=”表示值的權重是相等的,“:/”表示值的權重是均分的。
權重不用百分比表示,權重和也不一定是100.
例如:
src dist {0:=40; [1:3]:=60;};
即src=0 的概率是 40/220,src=1 的概率是 60/220,是 2 的概率是 60/220,是 3 的概率是
60/220.
再例如:
dst dist {0:/40; [1:3]:/60;};
即dst=0 的概率是 40/100,dst=1 的概率是 20/100,是 2 的概率是 20/100,是 3 的概率是
20/100.
綜上:src dist {0:=30; [1:3]:=90;}; dst=0 的概率是 30/(90*3+30)=30/300=0.1
4.分析下面的一段程序,正確的打印結果是:
fork
begin
#20
$ display(“A”);
end
begin
#10
$ display(“B”);
end
join_none
#5
$ display(“C”);
A.CBA
B. BCA
C.ABC
D.C
正確答案是:A.CBA
程序分析
在 SystemVerilog 中,fork…join_none 是一種并發控制結構。以下是代碼的逐步解析:
Systemverilog
深色版本
fork begin #20 $display("A"); end begin #10 $display("B"); end
join_none #5
$display("C");
關鍵點
fork…join_none 的語義:
fork…join_none 啟動多個線程并立即返回,不會等待這些線程完成。
在 fork…join_none 內部啟動的線程會獨立運行,并按照各自的延遲執行。
主進程與子線程的關系:
主進程(即 fork…join_none 之后的代碼)會繼續執行,不受子線程的影響。
子線程的延遲時間是獨立于主進程的。
時間軸分析:
程序的時間軸如下:
#5:主進程打印 “C”。
#10:第一個子線程打印 “B”。
#20:第二個子線程打印 “A”。
逐步執行
fork…join_none 啟動兩個子線程:
第一個子線程:
Systemverilog
深色版本
begin
#20
$display(“A”);
end
延遲 20 個時間單位后打印 “A”。
第二個子線程:
Systemverilog
深色版本
begin
#10
$display(“B”);
end
延遲 10 個時間單位后打印 “B”。
主進程繼續執行:
Systemverilog
深色版本
#5
$display(“C”);
主進程延遲 5 個時間單位后打印 “C”。
時間軸上的事件順序:
時間 = 5:主進程打印 “C”。
時間 = 10:第二個子線程打印 “B”。
時間 = 20:第一個子線程打印 “A”。
打印結果
根據時間軸上的事件順序,打印結果是:
深色版本
C
B
A
因此,正確的答案是:A. CBA
選項分析
A. CBA:
正確。打印順序為 C -> B -> A。
B. BCA:
錯誤。C 應該最先打印,而不是 B。
C. ABC:
錯誤。C 應該最先打印,而不是 A。
D. C:
錯誤。雖然 C 最先打印,但后續的 B 和 A 也會被打印。
5.下面有關Cache的說法哪一個是不正確的?
A. 設置Cache的理論基礎,是程序訪問的局部生原理
B. Cache 與主存統一編址,Cache的地址空間屬于主存的一部分
C. 設置Cache 的目的,是解決CPU和主存之間的速度匹配問題
D. Cache 的功能勻由硬件實現,對程序員是透明的
正確答案是:B. Cache 與主存統一編址,Cache的地址空間屬于主存的一部分
Cache的基本概念
Cache是一種高速緩存存儲器,位于CPU和主存之間,用于暫時存放CPU頻繁訪問的數據和指令,以提高數據訪問速度。下面是對每個選項的具體分析:
A. 設置Cache的理論基礎,是程序訪問的局部性原理
正確:
局部性原理包括時間局部性和空間局部性。時間局部性指的是如果一個信息項正在被訪問,那么在不久的將來它很可能再次被訪問;空間局部性指的是如果一個存儲位置被引用了,那么程序很可能很快會引用鄰近的位置。
這是設計Cache的基礎理論。
B. Cache與主存統一編址,Cache的地址空間屬于主存的一部分
不正確:
在大多數系統中,Cache并不與主存統一編址。Cache有自己的地址映射機制(直接映射、全相聯或組相聯),通過這種方式,Cache可以快速訪問數據而不必占用主存的地址空間。
Cache中的數據是從主存中復制而來,并不是主存地址空間的一部分。
C. 設置Cache的目的,是解決CPU和主存之間的速度匹配問題
正確:
主存的訪問速度遠低于CPU的工作頻率,設置Cache的主要目的是為了減少CPU等待主存數據的時間,從而提高整體性能。
D. Cache的功能均由硬件實現,對程序員是透明的
正確:
Cache的操作是由硬件自動管理的,包括數據的加載、替換等操作,程序員無需關心這些細節,因此對于程序員來說是透明的。
6.對于獨立復位的模塊,只需要考慮對后級模塊的影響,無需考慮對前級模塊的影響。
A.正確
B.錯誤
正確答案是:B. 錯誤
獨立復位模塊的影響
在數字電路設計中,復位信號用于將模塊的內部狀態初始化為已知值。對于具有獨立復位功能的模塊,需要同時考慮其對前級模塊和后級模塊的影響。以下是對該問題的分析:
- 復位信號的基本作用
復位信號通常分為兩種:
同步復位:復位操作與系統時鐘同步。
異步復位:復位操作不依賴于時鐘,隨時可以生效。
獨立復位指的是某個模塊的復位信號與其他模塊的復位信號無直接關聯。 - 對后級模塊的影響
當一個模塊被復位時,其輸出可能會發生變化(例如被清零或設置為某個默認值)。
這種變化會直接影響到后級模塊的輸入信號,從而可能引發后級模塊的狀態變化。
因此,必須考慮復位對后級模塊的影響。 - 對前級模塊的影響
雖然復位信號本身是獨立的,但復位后的模塊行為可能會影響前級模塊。
例如:
如果復位后的模塊停止接收數據(如 FIFO 緩沖區被清空),前級模塊可能會因為無法繼續發送數據而被阻塞。
如果復位后的模塊改變了某些控制信號(如握手信號),這可能會導致前級模塊的行為異常。
因此,也需要考慮復位對前級模塊的影響。 - 結論
獨立復位的模塊不僅會影響后級模塊,還可能間接影響前級模塊。
忽略對前級模塊的影響可能導致設計中的潛在問題(如死鎖、數據丟失等)。
選項分析
A. 正確:
錯誤。獨立復位的模塊需要同時考慮對前級和后級模塊的影響。
B. 錯誤:
正確。題目說法錯誤,復位模塊的設計需要全面考慮前后級的影響。
7.System Verilog 中,下面那種數組在使用前需要先執行new操作( )
A. Dynamic arrays
B. Associative arrays
C. packed array
D. 多維數組
正確答案是:A. Dynamic arrays - Dynamic Arrays(動態數組)
特點:
動態數組的大小在聲明時未指定,而是在運行時通過 new 操作符分配。
動態數組的大小可以動態調整(通過重新調用 new)。
使用前需要執行 new 操作:
在使用動態數組之前,必須先通過 new 指定其大小。例如:
Systemverilog
深色版本
int dyn_array[]; // 聲明一個動態數組
initial begin
dyn_array = new[10]; // 分配大小為 10
end - Associative Arrays(關聯數組)
特點:
關聯數組是一種稀疏數組,使用鍵值對存儲數據。
鍵可以是整數、字符串或其他數據類型。
不需要執行 new 操作:
關聯數組在聲明后即可直接使用,無需顯式分配空間。例如:
Systemverilog
深色版本
int assoc_array[string]; // 聲明一個關聯數組
initial begin
assoc_array[“key1”] = 10; // 直接賦值
end - Packed Array(打包數組)
特點:
打包數組是一種固定大小的數組,通常用于表示位寬較緊湊的數據結構。
打包數組的大小在聲明時確定,無法動態調整。
不需要執行 new 操作:
打包數組在聲明時已分配空間,可以直接使用。例如:
Systemverilog
深色版本
bit [3:0] packed_array [0:3]; // 聲明一個打包數組
initial begin
packed_array[0] = 4’b1010; // 直接賦值
end - 多維數組
特點:
多維數組可以是固定大小的數組,也可以是動態數組或關聯數組的組合。
如果多維數組的維度是固定的,則不需要 new 操作;如果是動態數組的一部分,則需要 new 操作。
是否需要 new 操作取決于具體實現:
例如:
Systemverilog
深色版本
int fixed_array[2][3]; // 固定大小的二維數組,不需要 new
int dyn_array[][]; // 動態二維數組,需要 new
initial begin
dyn_array = new[2]; // 分配第一維
foreach (dyn_array[i]) begin
dyn_array[i] = new[3]; // 分配第二維
end
end
選項分析
A. Dynamic arrays:
正確。動態數組在使用前需要通過 new 操作分配空間。
B. Associative arrays:
錯誤。關聯數組不需要 new 操作,聲明后即可直接使用。
C. packed array:
錯誤。打包數組是固定大小的數組,聲明時已分配空間,不需要 new 操作。
D. 多維數組:
錯誤。多維數組是否需要 new 操作取決于其實現方式。如果包含動態數組部分,則需要 new;否則不需要。
8.System Verilog 中,下面哪種數組在使用前需要執行new操作( )
a.壓縮數組
b.聯合數組
c.動態數組
d.多維數組
正確答案是:c. 動態數組
以下是詳細分析:
SystemVerilog 中的數組類型
在 SystemVerilog 中,數組分為多種類型,不同類型的數組在使用時的要求不同。以下是對選項中提到的數組類型的分析:
a. 壓縮數組(Packed Array)
特點:
壓縮數組是一種固定大小的數組,通常用于表示緊湊的數據結構。
它的大小在聲明時確定,無法動態調整。
是否需要 new 操作:
不需要。壓縮數組在聲明時已經分配了空間,可以直接使用。
示例:
Systemverilog
深色版本
bit [3:0] packed_array [0:3]; // 聲明一個壓縮數組
initial begin
packed_array[0] = 4’b1010; // 直接賦值
end
b. 聯合數組(Associative Array)
特點:
聯合數組是一種稀疏數組,使用鍵值對存儲數據。
鍵可以是整數、字符串或其他數據類型。
是否需要 new 操作:
不需要。聯合數組在聲明后即可直接使用,無需顯式分配空間。
示例:
Systemverilog
深色版本
int assoc_array[string]; // 聲明一個聯合數組
initial begin
assoc_array[“key1”] = 10; // 直接賦值
end
c. 動態數組(Dynamic Array)
特點:
動態數組的大小在聲明時未指定,而是在運行時通過 new 操作符分配。
動態數組的大小可以動態調整(通過重新調用 new)。
是否需要 new 操作:
需要。在使用動態數組之前,必須先通過 new 指定其大小。
示例:
Systemverilog
深色版本
int dyn_array[]; // 聲明一個動態數組
initial begin
dyn_array = new[10]; // 分配大小為 10
end
d. 多維數組(Multidimensional Array)
特點:
多維數組可以是固定大小的數組,也可以是動態數組或聯合數組的組合。
如果多維數組的維度是固定的,則不需要 new 操作;如果是動態數組的一部分,則需要 new 操作。
是否需要 new 操作:
固定大小的多維數組不需要 new 操作。
包含動態數組的多維數組需要 new 操作。
示例:
Systemverilog
深色版本
int fixed_array[2][3]; // 固定大小的二維數組,不需要 new
int dyn_array[][]; // 動態二維數組,需要 new
initial begin
dyn_array = new[2]; // 分配第一維
foreach (dyn_array[i]) begin
dyn_array[i] = new[3]; // 分配第二維
end
end
選項分析
a. 壓縮數組:
錯誤。壓縮數組是固定大小的數組,聲明時已分配空間,不需要 new 操作。
b. 聯合數組:
錯誤。聯合數組不需要 new 操作,聲明后即可直接使用。
c. 動態數組:
正確。動態數組在使用前需要通過 new 操作分配空間。
d. 多維數組:
錯誤。是否需要 new 操作取決于其實現方式。如果包含動態數組部分,則需要 new;否則不需要。
9.下列哪個不是Verilog系統函數( )
A. $ finish
B. $ head
C. $ time
D. $ write
正確答案是:B. $ head
以下是詳細分析:
Verilog 系統函數
Verilog 提供了一些內置的系統函數(以 $ 開頭),用于執行特定的操作,如仿真控制、文件操作、時間獲取等。以下是對選項中提到的系統函數的分析:
A. $finish
功能:
$finish 是一個標準的 Verilog 系統任務,用于終止仿真。
它會立即停止仿真并退出。
示例:
Verilog
深色版本
initial begin#100; // 延遲 100 時間單位$finish; // 終止仿真
end
結論:$finish 是合法的 Verilog 系統函數。
B. $head
功能:
h e a d 并不是 V e r i l o g 的標準系統函數或任務。在 V e r i l o g 或 S y s t e m V e r i l o g 中沒有這樣的定義。結論: head 并不是 Verilog 的標準系統函數或任務。 在 Verilog 或 SystemVerilog 中沒有這樣的定義。 結論: head并不是Verilog的標準系統函數或任務。在Verilog或SystemVerilog中沒有這樣的定義。結論:head 不是合法的 Verilog 系統函數。
C. $time
功能:
$time 是一個標準的 Verilog 系統函數,用于返回當前的仿真時間。
返回值是一個整數,表示從仿真開始到當前的時間單位。
示例:
Verilog
深色版本
initial begin#50;$display("Current simulation time: %0d", $time); // 輸出當前仿真時間
end
結論:$time 是合法的 Verilog 系統函數。
D. $write
功能:
$write 是一個標準的 Verilog 系統任務,用于將信息輸出到仿真器的標準輸出設備(如終端)。
它與 $display 類似,但不會在輸出后自動換行。
示例:
Verilog
深色版本
initial begin$write("Hello, ");$write("World!"); // 輸出 "Hello, World!",不會換行
end
結論:$write 是合法的 Verilog 系統函數。
選項分析
A. f i n i s h :正確。 finish: 正確。 finish:正確。finish 是合法的 Verilog 系統任務。
B. h e a d :錯誤。 head: 錯誤。 head:錯誤。head 不是 Verilog 的標準系統函數。
C. t i m e :正確。 time: 正確。 time:正確。time 是合法的 Verilog 系統函數。
D. w r i t e :正確。 write: 正確。 write:正確。write 是合法的 Verilog 系統任務。
總結
只有 $head 不是 Verilog 的標準系統函數。
正確答案是:B. $head
10.以下Verilog 運算符號中,優先級最高的是?
A.==
B.“
C.!
D.?
正確答案是:C. !
以下是詳細分析:
Verilog 運算符優先級
在 Verilog 中,運算符的優先級決定了表達式中運算符的執行順序。優先級高的運算符會先被計算。以下是對選項中提到的運算符的優先級分析:
A. ==(相等比較運算符)
功能:
== 是關系運算符,用于比較兩個操作數是否相等。
優先級:
關系運算符的優先級較低,低于邏輯運算符和單目運算符。
示例:
Verilog
深色版本
if (a == b) // 比較 a 和 b 是否相等
B. “(字符串字面量)
功能:
在 Verilog 中,” 用于定義字符串字面量,例如 “Hello”。
優先級:
字符串字面量不是運算符,因此沒有優先級的概念。
結論:
該選項無效。
C. !(邏輯非運算符)
功能:
! 是單目邏輯運算符,用于取反一個布爾值。
如果操作數為真(非零),結果為假;如果操作數為假(零),結果為真。
優先級:
單目運算符(如 !、~、& 等)的優先級最高。
示例:
Verilog
深色版本
if (!a) // 如果 a 為假,則條件成立
D. ?:(條件運算符)
功能:
?: 是條件運算符,用于三元表達式。
格式為:條件 ? 表達式1 : 表達式2。
如果條件為真,結果為表達式1;否則為表達式2。
優先級:
條件運算符的優先級非常低,僅高于賦值運算符。
示例:
Verilog
深色版本
assign result = (a > b) ? a : b; // 如果 a > b,result = a;否則 result = b
優先級總結
在 Verilog 中,運算符優先級從高到低的順序大致如下:
單目運算符(如 !、~、& 等)
算術運算符(如 *、/、+、- 等)
關系運算符(如 ==、!=、>、< 等)
條件運算符(如 ?:)
賦值運算符(如 =、<=)
由此可見,! 的優先級最高。
選項分析
A. ==:
錯誤。關系運算符的優先級較低。
B. ":
錯誤。字符串字面量不是運算符,無優先級。
C. !:
正確。單目邏輯非運算符的優先級最高。
D. ?::
錯誤。條件運算符的優先級非常低。
總結
在 Verilog 中,優先級最高的運算是單目邏輯非運算符 !。
正確答案是:C. !
11.模塊只收斂做到0.75V,提壓到0.85V可以正常工作
A.正確
B.錯誤
背景知識
在數字電路設計中,模塊的供電電壓(VDD)對其性能和功能有重要影響。以下是一些關鍵點:
模塊收斂(Module Convergence):
指模塊在特定電壓下能夠滿足時序要求(Setup/Hold 時間等),即模塊在該電壓下正常工作。
提壓(Voltage Scaling):
指提高供電電壓,通常用于改善電路性能(如提高頻率或降低延遲)。
工作電壓范圍:
每個模塊都有一個最低工作電壓(通常稱為“收斂電壓”或“最小工作電壓”),低于該電壓時,模塊可能無法正常工作。
提高供電電壓可以增強電路的驅動能力,從而改善性能和可靠性。
電壓與性能的關系:
降低電壓會減少功耗,但可能導致電路速度下降甚至功能失效。
提高電壓可以提高電路的速度和穩定性,但也會增加功耗。
提壓的作用:
如果一個模塊在較低電壓下(如 0.75V)無法完全收斂(即不能正常工作),提高電壓到更高值(如 0.85V)可能會解決問題。
題目分析
題目描述了一個模塊在 0.75V 下只能部分收斂,而在 0.85V 下可以正常工作。
這種情況是合理的,因為提高電壓可以:
增強晶體管的驅動能力,使得信號傳播更快。
減少噪聲和干擾的影響,從而提高電路的穩定性。
確保邏輯門的輸出達到預期的電平。
因此,提壓到 0.85V 后模塊能夠正常工作是符合實際情況的。
選項分析
A. 正確:
正確。提高電壓可以解決低電壓下的收斂問題。
B. 錯誤:
錯誤。提壓通常可以改善模塊的工作狀態。
總結
提高電壓(從 0.75V 到 0.85V)確實可以使模塊正常工作,因此題目說法正確。
正確答案是:A. 正確
12.異步電路都不需要STA進行約束檢查
A.是
B.否
正確答案是:A.是
解析:STA都是針對同步電路的
13.在設計狀態機時,有兩種常用的編碼方式:one‐hot code、binary code,前者相對于后者的優勢主要體現在
A.實現電路的速度更快
B.實現電路的面積更小
C.編碼方式簡單
D.實現電路的功耗更低
正確答案是:A. 實現電路的速度更快
以下是詳細分析:
狀態機編碼方式
在設計有限狀態機(FSM)時,選擇合適的編碼方式對于性能、面積和功耗都有重要影響。常用的兩種編碼方式為One-Hot編碼和二進制編碼(Binary Code)。
- One-Hot 編碼
特點:
在 One-Hot 編碼中,每個狀態都由一個獨立的比特表示,即在任意時刻只有一個比特為高電平(1),其余比特均為低電平(0)。
如果狀態機有 N 個狀態,則需要 N 個觸發器來實現。 - 二進制編碼(Binary Code)
One-Hot 編碼相對于二進制編碼的優勢
A. 實現電路的速度更快
正確:
速度優勢:One-Hot 編碼減少了狀態解碼所需的邏輯復雜度,因為每個狀態僅涉及單個比特的變化。這使得狀態轉換更加直接和快速,從而提高了電路的整體速度。
簡化狀態解碼:由于每個狀態由單一比特表示,判斷當前狀態非常簡單,只需檢查對應的比特位即可,無需復雜的譯碼邏輯。
B. 實現電路的面積更小
錯誤:
面積劣勢:One-Hot 編碼通常需要更多的觸發器(N 個狀態需要 N 個觸發器)。因此,One-Hot 編碼往往占用更大的硬件資源,導致電路面積增加。
C. 編碼方式簡單
部分正確:
編碼方式:雖然從概念上看,One-Hot 編碼較為直觀(每個狀態對應一個比特),但考慮到實際應用中的狀態數量,其編碼并不一定比二進制編碼簡單。例如,在具有大量狀態的情況下,管理 One-Hot 編碼的狀態轉換可能變得復雜。
D. 實現電路的功耗更低
錯誤:
功耗方面:One-Hot 編碼由于使用了更多的觸發器,可能會消耗更多靜態功耗。此外,每次狀態轉換時,One-Hot 編碼會導致多個觸發器的狀態變化,盡管這些變化通常是簡單的,但與二進制編碼相比,不一定能保證更低的動態功耗。
選項分析
A. 實現電路的速度更快:
正確。One-Hot 編碼通過減少狀態解碼的復雜性,可以加快狀態轉換速度。
B. 實現電路的面積更小:
錯誤。One-Hot 編碼通常需要更多的觸發器,導致電路面積增加。
C. 編碼方式簡單:
部分正確,但從整體設計復雜度來看,并不總是更簡單。
D. 實現電路的功耗更低:
錯誤。One-Hot 編碼可能導致更高的靜態和動態功耗。
總結
One-Hot 編碼相對于二進制編碼的主要優勢在于能夠提高電路的速度。
正確答案是:A. 實現電路的速度更快。
14.對于相同位數輸入的變量比較器,大于和小于的面積是一樣的
A.對
B.錯誤
正確答案是:A. 對
以下是詳細分析:
比較器的基本原理
比較器是一種數字電路,用于比較兩個輸入變量的大小,并輸出比較結果(如大于、小于或等于)。對于相同位數的輸入變量,比較器的設計通常具有對稱性。
大于和小于的邏輯實現
比較器的結構:
假設輸入變量為 A 和 B,它們的位寬均為 n。
比較器會逐位比較 A 和 B 的每一位(從最高有效位到最低有效位),并根據比較結果生成輸出信號。
輸出信號包括:
A > B(大于)
A < B(小于)
A == B(等于)
對稱性:
在硬件實現中,“大于”(A > B)和"小于"(A < B)的邏輯是對稱的。
它們的實現方式幾乎相同,只是在某些邏輯判斷中交換了輸入變量的位置。
硬件資源消耗:
由于 “大于” 和 “小于” 的邏輯完全對稱,它們的硬件實現所需的面積也是一樣的。
實現這些邏輯的操作(如與門、或門、異或門等)數量相同,因此兩者的面積相等。
選項分析
A. 對:
正確。對于相同位數的輸入變量,“大于” 和 “小于” 的邏輯實現是對稱的,因此它們的面積是一樣的。
B. 錯誤:
錯誤。“大于” 和 “小于” 的硬件實現完全對稱,面積沒有差異。
總結
對于相同位數輸入變量的比較器,“大于” 和 “小于” 的邏輯實現對稱,因此它們的面積是一樣的。
正確答案是:A. 對
15.有關綜合的說法,以下哪個選項是錯誤的?
A. 相同的RTL代碼,每次綜合出來的網表可能是不一樣的
B. 綜合網表可用于EDA功能仿真
C. casez 是不可綜合的
D. 時序邏輯always語句中,if‐else如果else的分支缺乏,會綜合成latch
正確答案是:CD. casez 是不可綜合的
以下是詳細分析:
綜合的基本概念
綜合(Synthesis)是將寄存器傳輸級(RTL)代碼轉換為門級網表的過程。在綜合過程中,工具會根據設計規則、約束條件和目標工藝庫生成對應的硬件電路。
選項分析
A. 相同的 RTL 代碼,每次綜合出來的網表可能是不一樣的
正確:
綜合工具在優化過程中可能會受到多種因素的影響,例如綜合工具版本、目標工藝庫、綜合約束(如時序、面積、功耗等)以及隨機種子設置。
這些因素可能導致相同的 RTL 代碼在不同次綜合中生成稍有不同的網表,但其功能是一致的。
B. 綜合網表可用于 EDA 功能仿真
正確:
綜合后的網表是門級描述,可以用于功能仿真(Post-Synthesis Simulation)。
功能仿真驗證的是綜合后的電路是否與原始 RTL 代碼的功能一致。
C. casez 是不可綜合的
錯誤:
casez 是完全可綜合的!
casez 是 Verilog 中的一種條件分支語句,允許使用 ? 表示無關位(don’t care)。它在綜合中非常常用,特別是在處理部分解碼或靈活匹配的情況下。
示例:
Verilog
深色版本
casez (input_signal)
4’b1???: output = 1; // 匹配高兩位為1的情況
4’b01??: output = 2;
default: output = 0;
endcase
因此,casez 是完全可以被綜合工具支持的。
D. 時序邏輯 always 語句中,if-else 如果 else 的分支缺乏,會綜合成 latch
在組合塊中,if語句:
(1) 分支條件不完全,會產生鎖存器。
(2) 分支條件完全,且條件互斥,會產生并行電路,如多路器。
(3) 分支條件完全,且條件非互斥,會產生帶有優先級的串行電路。
在時序塊中,if語句:
(4) 分支條件不完全,會產生帶使能端的D觸發器。
條件完全會在D觸發器的數據輸入端產生如
(2)或(3)的組合電路。
在function 中,if語句
(5)會產生組合電路。條件完全會產生如(2)或(3)的組合電路。條件不完全,則默認其它條件
下被賦值變量的值為0。
總結
選項 C 的說法是錯誤的,因為 casez 是完全可綜合的。
正確答案是:CD. casez 是不可綜合的
16.在Verilog 代碼中,對有符號數進行比特選擇或拼接,其結果是無符號數
A.正確
B.錯誤
分析:
有符號數的比特選擇:當你從一個有符號數中選擇某些位時(例如 a[3:0]),這些被選擇出來的比特將被視為無符號數。這是因為比特選擇操作只是提取出一部分比特,并沒有保留原始數值的符號信息。
有符號數的拼接:當使用拼接操作符 {} 將多個信號組合在一起時,結果同樣不會自動繼承任何部分的符號屬性。拼接的結果是一個無符號數。
在文檔中提到:
Verilog根據表達式中變量的長度對表達式的值自動地進行調整。
當一個負數賦值給無符號變量如reg時,Verilog自動完成二進制補碼計算。
因此,在Verilog中,如果你對有符號數進行比特選擇或拼接,結果將是無符號數。
結論:
正確答案是:A. 正確
https://blog.csdn.net/soulermax/article/details/147078428?sharetype=blogdetail&sharerId=147078428&sharerefer=PC&sharesource=soulermax&spm=1011.2480.3001.8118
17.reg [0:31] little_vect; little_vect[0+:8]是多少?
A. little‐vect[0 : 7]
B. 1ittle_vect[7: 0]
正確答案是:A. little_vect[0 : 7]
解析:
舉例說明:
reg [31:0] big_vect;
reg [0:31] little_vect;
問題:
big_vect[0 +:8] 轉化后一定是 big_vect[較大的數值 : 較小的數值]
little_vect[0 +:8] 轉化后一定是 little_vect[較小的數值 : 較大的數值]
reg [31:0] big_vect;為大端,那么轉化后的也一定是大端,形式不變
big_vect [0+: 8] 從 0 開始,升序,位寬為 8 ======》》》》》big_vect [7 :0]
little_vect [0 +: 8] 從 0 開始,升序,位寬為 8 ======》》》》》little_vect [0 :7]
big_vect [15 ‐: 8] 從 15 開始,降序,位寬為 8 ======》》》》》big_vect [15 :8]
little_vect [15 ‐: 8] 從 15 開始,降序,位寬為 8 ======》》》》》little_vect [8:15]
18.時序邏輯always語句中,if‐else如果else的分支缺乏,會綜合成latch
A.正確
B.錯誤
正確答案是:B. 錯誤
以下是詳細分析:
時序邏輯中的 if-else 語句
在 Verilog 中,always 塊用于描述組合邏輯或時序邏輯。if-else 語句的使用方式會影響綜合結果,特別是在時序邏輯中。
- 時序邏輯的特點
時序邏輯通常由觸發器(如 D 觸發器)實現。
時序邏輯的 always 塊通常包含時鐘信號(如 posedge clk 或 negedge clk)和可選的異步復位/置位信號。
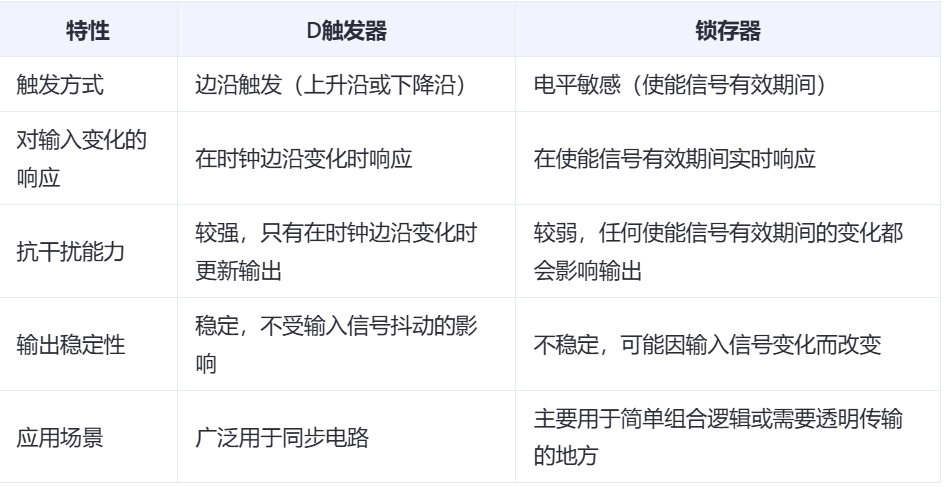
在時序邏輯中,if-else 結構通常用于控制觸發器的更新條件。 - 缺少 else 分支的影響
組合邏輯中的情況:
如果 always 塊描述的是組合邏輯(即敏感列表中沒有時鐘信號),缺少 else 分支會導致綜合工具推斷出鎖存器(latch)。這是因為組合邏輯需要對所有可能的輸入條件給出明確的輸出值,否則電路會保持前一個狀態,形成鎖存器。
時序邏輯中的情況:
在時序邏輯中,always 塊通常只在時鐘邊沿觸發。如果 if-else 語句中缺少 else 分支,綜合工具不會生成鎖存器,而是默認保持當前狀態不變。
這是因為觸發器本身具有存儲特性,在未滿足 if 條件時,觸發器會保持之前的值,而不會引入額外的鎖存器。
示例代碼
以下是一個典型的時序邏輯代碼:
Verilog
深色版本
always @(posedge clk or posedge reset) begin
if (reset)
q <= 0; // 異步復位
else if (enable)
q <= d; // 數據更新
// 缺少 else 分支
end
在這段代碼中,else 分支缺失并不會導致鎖存器的生成。
當 enable 為低電平時,觸發器會保持當前狀態不變(即 q 不會被更新),這是觸發器的默認行為。
總結
在組合邏輯中,缺少 else 分支可能導致鎖存器的生成。
在時序邏輯中,缺少 else 分支不會生成鎖存器,而是保持觸發器的當前狀態。
選項分析
A. 正確:
錯誤。在時序邏輯中,缺少 else 分支不會生成鎖存器。
B. 錯誤:
正確。在時序邏輯中,缺少 else 分支不會生成鎖存器。
最終答案
正確答案是:B. 錯誤
19.關于功耗,以下描述不正確的是:
A.設計者需要關注平均功耗、峰值功耗和功耗跳變
B.改變芯片的供電電壓和時鐘頻率都會對芯片功耗產生影響
C.對于可關斷的摸塊,使用時鐘門控即可降低功耗
D.芯片的功耗會受實際信號的影響,所以功耗測試需要結合業務來開展。
正確答案是:C. 對于可關斷的模塊,使用時鐘門控即可降低功耗
以下是詳細分析:
選項分析
A. 設計者需要關注平均功耗、峰值功耗和功耗跳變
正確:
平均功耗:決定了芯片的整體能耗,對電池供電設備尤為重要。
峰值功耗:影響電源網絡設計和散熱需求,過高的峰值功耗可能導致電源不穩定或芯片損壞。
功耗跳變:快速的功耗變化會引起電源噪聲和電壓波動,可能影響電路的穩定性。
因此,設計者確實需要同時關注這三方面。
B. 改變芯片的供電電壓和時鐘頻率都會對芯片功耗產生影響
正確:
功耗與電壓的平方成正比,與時鐘頻率成正比。因此,降低供電電壓或時鐘頻率都可以顯著降低功耗。
C. 對于可關斷的模塊,使用時鐘門控即可降低功耗
錯誤:
時鐘門控的作用:通過關閉模塊的時鐘信號,可以減少動態功耗(因為沒有時鐘翻轉,觸發器和組合邏輯不會切換狀態)。
但僅靠時鐘門控并不能完全降低功耗:
如果模塊仍然保持供電,即使沒有時鐘信號,靜態功耗(如漏電流)仍然存在。
對于真正需要關斷的模塊,通常需要結合電源門控(Power Gating),即直接切斷模塊的電源,才能有效降低靜態功耗。
因此,僅依賴時鐘門控并不足以完全降低功耗。
D. 芯片的功耗會受實際信號的影響,所以功耗測試需要結合業務來開展
正確:
芯片的實際功耗與輸入信號的特性密切相關。例如,高頻切換的信號會導致更高的動態功耗。
因此,為了準確評估功耗,必須結合具體的業務場景和實際工作負載進行測試。
總結
選項 C 的說法不正確,因為對于可關斷的模塊,僅使用時鐘門控無法完全降低功耗。還需要結合電源門控等技術來進一步優化靜態功耗。
正確答案是:C. 對于可關斷的模塊,使用時鐘門控即可降低功耗
20.一個D觸發器, 其數據Tsu=2ns,Tcq=3ns,Thd=1ns,則此觸發器的最高工作頻率為: (注:Tsu數據相對時鐘的建立時間,Thd數據相對時鐘的保持時間,Tcq輸出相對時鐘的延遲)
A.200MHz
B.500MHz
C.100MEz
D.333MHz
正確答案是:A. 200MHz
Tmin=Tcq+Tgate+Tsu‐Tskew=2+3=5ns
*21.在Verilog HDL 中,timescale 編譯器指令格式為: timescale AB.其中 A 指的是時延精度,
B 指的是時延單位。
A. 正確
B. 錯誤
解析: A是時延單位,B是時延精度。
正確答案是:B. 錯誤
timescale 指令的格式與含義 在 Verilog HDL 中,timescale 編譯器指令用于定義仿真中的時間單位和時間精度。其格式為:
Verilog
深色版本
timescale <時間單位> / <時間精度> 時間單位(A): 表示仿真中延遲值(如 #10)的基本單位。 例如,如果時間單位是 1ns,那么 #10 表示 10 納秒。 時間精度(B): 表示仿真的最小時間分辨率。 時間精度必須小于或等于時間單位。 例如,如果時間精度是 1ps,那么仿真可以分辨到皮秒級的時間變化。 題目分析 題目中說 A 是時延精度,B 是時延單位,這是錯誤的。 正確的說法是: A 是時延單位。 B 是時延精度。 示例 以下是一個 timescale 的使用示例:
Verilog
深色版本
`timescale 1ns / 1ps
時間單位:1ns,表示延遲值的基本單位是納秒。
時間精度:1ps,表示仿真可以分辨到皮秒級別。
如果寫成:
Verilog
深色版本
`timescale 10ns / 1ns
時間單位:10ns,表示延遲值的基本單位是 10 納秒。
時間精度:1ns,表示仿真可以分辨到納秒級別。
總結
根據解析,題目說法錯誤。
正確答案是:B. 錯誤
22.reg signed [0:4] b, b=8’sh8f,賦值后 b 的值是多少?
A. 5’h1F
B. 5’h0F
C. 8’h8F
關鍵點
變量 b 的位寬和符號性
reg signed [0:4] b 表示 b 是一個 5 位有符號寄存器,范圍 -16 到 15。
位序 [0:4]:0 是最高位(MSB),4 是最低位(LSB)。
賦值 8’sh8f 的含義
8’sh8f 表示 8 位有符號十六進制數 0x8F。
二進制形式:8’b1000_1111(最高位 1 表示負數)。
十進制值:
原碼:1000_1111 → -15(假設符號+數值)。
補碼計算:1000_1111 → 取反 0111_0000 → 加 1 → 0111_0001 = -113(正確補碼值)。
賦值時的位寬截斷
b 是 5 位,8’sh8f 是 8 位,賦值時會發生 截斷。
Verilog 截斷規則:
直接取低 5 位(8’sh8f 的低 5 位是 0_1111)。
符號性由目標變量決定(b 是 signed,所以截斷后的 5’b0_1111 會被視為有符號數)。
截斷后的結果
8’sh8f = 8’b1000_1111 → 取低 5 位 0_1111(5’b01111)。
b 是 signed,所以 5’b01111 的十進制值是 +15(最高位 0 為正)。
十六進制表示:5’h0F。
驗證
仿真驗證(假設 b 是 5 位有符號):
verilog
復制
module test;
reg signed [0:4] b;
initial begin
b = 8’sh8f; // 8’b1000_1111 → 截斷為 5’b01111
$display(“b = %h”, b); // 輸出 5’h0F
end
endmodule
輸出:b = 0f(即 5’h0F)。
選項分析
A. 5’h1F → 5’b11111(-1),錯誤(未正確截斷)。
B. 5’h0F → 5’b01111(+15),正確。
C. 8’h8F → 錯誤(b 是 5 位,不能是 8 位)。
結論
正確答案是 B. 5’h0F。
reg signed [0:4] b 和 reg signed [4:0] b 的區別
在 Verilog 中,reg signed [0:4] b 和 reg signed [4:0] b 都聲明了一個 5 位有符號寄存器變量 b,它們的 數值范圍相同(-16 到 15),但在 位序(bit ordering) 和 存儲方式 上有區別:
- 位序(Bit Ordering)不同
(1) reg signed [0:4] b
高位在左,低位在右(Big-Endian 風格,類似于書寫順序)。
b[0] 是符號位(MSB),b[4] 是最低位(LSB)。
示例:
verilog
復制
b = 5’sb10110; // 存儲為:b[0]=1, b[1]=0, b[2]=1, b[3]=1, b[4]=0
(2) reg signed [4:0] b
低位在左,高位在右(Little-Endian 風格,類似于 C 數組)。
b[4] 是符號位(MSB),b[0] 是最低位(LSB)。
示例:
verilog
復制
b = 5’sb10110; // 存儲為:b[4]=1, b[3]=0, b[2]=1, b[1]=1, b[0]=0
2. 賦值和訪問時的差異
(1) 賦值方式
[0:4] 風格:
verilog
復制
b[0] = 1; // 設置符號位
b[4] = 0; // 設置最低位
[4:0] 風格:
verilog
復制
b[4] = 1; // 設置符號位
b[0] = 0; // 設置最低位
(2) 位選擇(Bit-select)
[0:4]:
verilog
復制
wire msb = b[0]; // 取符號位
wire lsb = b[4]; // 取最低位
[4:0]:
verilog
復制
wire msb = b[4]; // 取符號位
wire lsb = b[0]; // 取最低位
3. 對數值的影響
數值計算無區別:
無論是 [0:4] 還是 [4:0],b 的 十進制值相同(由補碼決定)。
例如:
verilog
復制
reg signed [0:4] b1 = 5’b10110; // -10
reg signed [4:0] b2 = 5’b10110; // -10
但位序會影響仿真和調試時的觀察方式。
- 實際應用建議
推薦使用 [4:0](更常見,與 C 語言數組一致)。
[0:4] 在某些舊代碼或特定協議中使用(如某些網絡協議采用 Big-Endian)。
避免混用,否則可能導致位序混亂。
總結
特性 reg signed [0:4] b reg signed [4:0] b
位序 b[0]=MSB, b[4]=LSB b[4]=MSB, b[0]=LSB
賦值風格 Big-Endian(高位在前) Little-Endian(低位在前)
數值范圍 -16 到 15(相同) -16 到 15(相同)
適用場景 舊代碼、某些協議 常見寫法,與 C 語言一致
結論:
功能上無區別(數值計算相同)。
位序不同,影響仿真調試時的觀察方式。
推薦使用 [4:0],除非有特殊需求。
23.在GVIM編譯器中,將全英文的字符串old全部替換成字符串new,正確的命令是:
A. s/o1d/new/
B. s/o1d/new/g
C. s/o1d/new/g
D. s/o1d/new/
:%s/old/new/g
解題步驟
理解操作符:
- ^ 是按位異或(XOR)操作符。
- 是按位取反(NOT)操作符。
計算 a ^ b:
a = 4’b0101 (二進制:0101)
b = 4’b1010 (二進制:1010)
按位異或(XOR)的規則:相同為0,不同為1。
第一位:0 ^ 1 = 1
第二位:1 ^ 0 = 1
第三位:0 ^ 1 = 1
第四位:1 ^ 0 = 1
因此,a ^ b = 4’b1111
計算 ~(a ^ b):
a ^ b = 4’b1111
按位取反(NOT):
~1 = 0
~1 = 0
~1 = 0
~1 = 0
因此,~(a ^ b) = 4’b0000
驗證選項:
A. 4’b0000 → 正確
B. 1’b1 → 錯誤(結果應為4位,且值為0000)
C. 1’b0 → 錯誤(同上)
D. 4’b1111 → 錯誤(這是a ^ b的值,不是取反后的值)
可能的誤區
忽略按位操作的性質:~和^都是按位操作,不是邏輯操作(邏輯操作會返回1位結果)。
混淆和!:!是邏輯非(返回1位),是按位非(返回與輸入相同位寬)。
直接猜測:看到異或后是全1,可能誤以為取反后是全0就是D選項(但D是4’b1111,是未取反的值)。
正確答案
A. 4’b0000
25.timescale 1ns/10ps,其中 1ns 代表 time unit,10ps 代表 time precision.
A.正確
B.錯誤
解題步驟
理解 `timescale:
timescale 是 Verilog 和 SystemVerilog 中的一種編譯指令,用于定義仿真時間單位和精度。
語法:timescale <time_unit> / <time_precision>
<time_unit>:仿真時間的基本單位,所有延遲值均基于此單位。
<time_precision>:仿真時間的精度,即仿真器可以處理的最小時間步長。
題目解析:
timescale 1ns/10ps:
1ns(1 納秒)是 time_unit(時間單位)。
10ps(10 皮秒)是 time_precision(時間精度)。
題目描述“1ns 代表 time unit,10ps 代表 time precision”完全符合 timescale 的定義。
驗證選項:
A. 正確 → 題目描述與 timescale 的定義一致。
B. 錯誤 → 無依據。
可能的誤區
混淆 time_unit 和 time_precision 的順序:
正確的順序是 time_unit 在前,time_precision 在后。
題目描述順序正確。
不理解 time_precision 的作用:
time_precision 是仿真器的最小時間步長,不影響 time_unit 的定義。
題目描述未涉及功能,僅涉及定義,因此無需深入。
正確答案
A. 正確
26.generate for 循環語句中使用的標尺變量可定義為integer
A.正確
B.錯誤
解題步驟
理解 generate for 的作用:
generate for 是 Verilog 中的一種生成塊語法,用于在編譯時根據條件重復生成硬件結構(如模塊實例化、邏輯代碼等)。
它的循環變量(即“標尺變量”)必須在生成塊中聲明,且專門用于控制生成邏輯的迭代。
明確循環變量的類型要求:
Verilog 標準規定:generate for 的循環變量必須聲明為 genvar 類型。
例如:
genvar i; // 正確聲明
generate
for (i = 0; i < 4; i = i + 1) begin
// 實例化模塊或生成邏輯
end
endgenerate
integer 的用途:
integer 是 Verilog 中的一種通用整數類型,主要用于仿真中的行為級建模(如循環計數、臨時變量等)。
不能 用于 generate for 循環的索引變量,因為 generate 塊需要在編譯時展開,而 integer 是動態的、運行時的變量。
驗證題目描述:
題目聲稱“標尺變量可定義為 integer”,這與 Verilog 標準 沖突。
實際開發中,若嘗試用 integer 代替 genvar,編譯器會報錯(例如:Illegal variable declaration in generate loop)。
排除可能的誤區:
混淆 genvar 和 integer:
genvar 是靜態的、編譯時的索引變量,專用于生成塊。
integer 是動態的、運行時的變量,用于行為級代碼(如 always 塊)。
特殊版本的例外?:
無論是 Verilog-2001 還是 SystemVerilog,均嚴格規定 generate for 的循環變量必須為 genvar 類型,無例外。
需要注意三點:
①generate‐for 語句必須用genvar 關鍵字定義for 的索引變量;
②for 的內容必須用begin…end 塊包起來,哪怕只有一句;
③begin…end 塊必須起個名字。
正確答案
B. 錯誤
理由:
generate for 的循環變量必須聲明為 genvar 類型,而非 integer。
試圖使用 integer 會導致編譯錯誤。
27.在PerI 腳本中,使用( )退出當前循環
A. last
B. break
C. next
D. exit
解題步驟
理解 Perl 中的循環控制語句:
Perl 提供了多種循環控制語句,用于控制循環的執行流程。
常見的循環控制語句包括:
last:立即退出當前循環(類似于 C 語言中的 break)。
next:跳過當前循環的剩余部分,直接進入下一次循環(類似于 C 語言中的 continue)。
redo:重新執行當前循環,不更新循環變量。
exit:退出整個程序,而不是僅退出循環。
分析選項:
A. last:
last 是 Perl 中用于立即退出當前循環的關鍵字。
例如:
for my KaTeX parse error: Expected '}', got 'EOF' at end of input: ….10) { if (i == 5) {
last; # 退出循環
}
print “$i\n”;
}
輸出:1 2 3 4(循環在 $i == 5 時退出)。
B. break:
break 是 C 語言中用于退出循環的關鍵字,但在 Perl 中 無效。
若在 Perl 中使用 break,會導致語法錯誤。
C. next:
next 用于跳過當前循環的剩余部分,直接進入下一次循環,而不是退出循環。
例如:
for my KaTeX parse error: Expected '}', got 'EOF' at end of input: …..5) { if (i == 3) {
next; # 跳過本次循環
}
print "KaTeX parse error: Undefined control sequence: \n at position 2: i\?n?"; } 輸出:1 2 4 5…i == 3 時跳過打印)。
D. exit:
exit 用于退出整個程序,而不是僅退出當前循環。
例如:
for my KaTeX parse error: Expected '}', got 'EOF' at end of input: …..5) { if (i == 3) {
exit; # 退出程序
}
print “$i\n”;
}
輸出:1 2(程序在 $i == 3 時終止)。
驗證題目描述:
題目要求“退出當前循環”,last 是唯一符合要求的選項。
其他選項要么無效(break),要么功能不符(next 和 exit)。
排除可能的誤區:
混淆 last 和 break:
last 是 Perl 中的關鍵字,break 是 C 語言中的關鍵字。
混淆 next 和 last:
next 是跳過當前循環,last 是退出循環。
混淆 exit 和 last:
exit 是退出程序,last 是退出循環。
正確答案
A. last
理由:
last 是 Perl 中用于退出當前循環的關鍵字,完全符合題目要求。
其他選項要么無效,要么功能不符。
28.多bit 信號的異步處理時,可以用打兩拍的方式,也可以用異步fifo
A.正確
B.錯誤
解題步驟
- 理解異步信號處理的背景
異步信號:來自不同時鐘域的信號,其時鐘頻率和相位關系不確定。
問題:直接傳遞異步信號可能導致亞穩態(Metastability),即信號在采樣時處于不確定狀態,導致系統錯誤。 - 分析多 bit 信號的處理方法
A. 打兩拍的方式(雙觸發器同步器)
原理:將信號通過兩級觸發器傳遞,第一級用于減少亞穩態概率,第二級用于穩定信號。
適用場景:
單 bit 信號:效果較好,能有效降低亞穩態風險。
多 bit 信號:不適用,因為多 bit 信號可能存在位間偏移(Bit Skew),導致數據不一致。
例如:8-bit 信號中,某些位可能被新值采樣,某些位仍為舊值,導致錯誤。
B. 異步 FIFO
原理:使用雙端口 RAM 和讀寫指針,通過格雷碼(Gray Code)同步讀寫指針,確保數據跨時鐘域傳遞時的一致性。
適用場景:
多 bit 信號:最佳選擇,能有效處理位間偏移和亞穩態問題。
單 bit 信號:也可使用,但通常雙觸發器同步器更簡單高效。
3. 驗證題目描述
題目聲稱“多 bit 信號的異步處理時,可以用打兩拍的方式,也可以用異步 FIFO”。
打兩拍的方式:不適用于多 bit 信號,因為無法解決位間偏移問題。
異步 FIFO:適用于多 bit 信號,是標準解決方案。
因此,題目描述 不完全正確。
4. 排除可能的誤區
混淆單 bit 和多 bit 信號的處理方法:
單 bit 信號:雙觸發器同步器是標準方法。
多 bit 信號:異步 FIFO 是標準方法。
忽略位間偏移問題:
多 bit 信號不能簡單地用雙觸發器同步器處理,因為位間偏移會導致數據錯誤。
跨時鐘域處理中的信號延展(Pulse Stretching)與核心方法配合
- 信號延展(Pulse Stretching)的作用
信號延展是解決 高速→低速時鐘域 單 bit 信號傳輸的補充技術,核心目的是 確保低速時鐘能穩定捕捉高速脈沖。
問題場景:高速時鐘域的脈沖寬度可能小于低速時鐘周期,導致漏采(例如:100MHz 脈沖傳到 10MHz 時鐘域)。
解決方法:將高速脈沖展寬至至少 1.5 倍低速時鐘周期,再通過雙觸發器同步器傳遞。
2. 信號延展與核心方法的配合流程
場景:高速時鐘域 → 低速時鐘域(單 bit 信號)
延展脈沖:
在高速時鐘域,通過計數器或狀態機將短脈沖展寬。
例如:原脈沖寬度為 1 個高速周期 → 展寬至 2-3 個低速周期。
// 脈沖展寬示例(展寬到 3 個高速時鐘周期)
always @(posedge fast_clk) begin
if (pulse_in) stretch_cnt <= 3;
else if (stretch_cnt > 0) stretch_cnt <= stretch_cnt - 1;
end
assign stretched_pulse = (stretch_cnt > 0);
同步處理:
將展寬后的信號通過 雙觸發器同步器 傳遞到低速時鐘域。
always @(posedge slow_clk) begin
sync_reg <= {sync_reg[0], stretched_pulse};
end
assign pulse_out = sync_reg[1];
脈沖還原(可選):
若需要恢復原始脈沖寬度,可在低速域檢測信號邊沿。
多 bit 信號場景
直接使用異步 FIFO,無需信號延展(FIFO 的寫指針更新已隱含速率適配)。
3. 低速→高速時鐘域的補充技術
場景:低速時鐘域 → 高速時鐘域(單 bit 信號)
無需延展:高速時鐘自然能捕捉低速信號,但需注意:
消抖(Debouncing):若低速信號是機械開關等抖動信號,需在低速域先濾波。
同步器仍必要:直接使用雙觸發器同步器消除亞穩態。
多 bit 信號
異步 FIFO 是唯一可靠方案,無需額外處理速率差異。
4. 關鍵配合原則
技術 適用場景 配合方法
信號延展 高速→低速單 bit 短脈沖 延展后 + 雙觸發器同步器
雙觸發器同步器 單 bit 信號(任何方向) 直接使用或配合延展
異步 FIFO 多 bit 信號(任何方向) 獨立使用,無需額外處理速率差異
5. 反例分析
錯誤做法:
對多 bit 信號僅使用延展 + 雙觸發器同步器 → 位間偏移仍會導致數據錯誤。
對低速→高速信號過度延展 → 增加延遲,無實際收益。
正確流程:
判斷信號類型(單 bit / 多 bit)。
判斷時鐘方向(高速→低速 / 低速→高速)。
選擇組合:
單 bit + 高速→低速 → 延展 + 同步器。
多 bit → 異步 FIFO。
總結
信號延展是 高速→低速單 bit 場景 的補充技術,需與雙觸發器同步器配合;而異步 FIFO 是 多 bit 傳輸 的終極解決方案,無需依賴延展。實際設計中需根據信號類型和時鐘關系選擇組合方法。
正確答案
B. 錯誤
理由:
打兩拍的方式 不適用于 多 bit 信號的異步處理,因為它無法解決位間偏移問題。
異步 FIFO 是處理多 bit 異步信號的 標準方法。
因此,題目描述不完全正確。
多選
題目1:initial 和 always 的區別是(多選)
選項:
A. initial 只執行 1 次,always 執行多次
B. initial 不可以被綜合,always 可以綜合
C. always 中時序和過程語句描述與 initial 相同
解題步驟
1. 理解 initial 和 always 的作用
initial塊:- 用于仿真中的初始化操作,僅在仿真開始時執行 一次。
- 不可綜合(即不能用于生成實際硬件電路)。
- 示例:
initial begina = 0; // 初始化信號 a#10; // 延遲 10 個時間單位a = 1; // 修改信號 a end
always塊:- 用于描述硬件行為,根據敏感列表(如時鐘邊沿或信號變化) 重復執行。
- 可綜合(用于生成實際硬件電路)。
- 示例:
always @(posedge clk) beginq <= d; // 在時鐘上升沿更新寄存器 q end
2. 分析選項
A. initial 只執行 1 次,always 執行多次
- 正確:
initial僅在仿真開始時執行一次。always根據敏感列表重復執行。
B. initial 不可以被綜合,always 可以綜合
- 正確:
initial僅用于仿真,不可綜合。always可用于描述硬件行為,可綜合。
C. always 中時序和過程語句描述與 initial 相同
- 錯誤:
initial僅執行一次,通常用于初始化或仿真測試。always根據敏感列表重復執行,用于描述硬件行為。- 兩者的時序和過程語句描述 不同。
3. 驗證題目描述
- 題目要求選擇
initial和always的區別。 - 選項 A 和 B 均正確描述了二者的區別。
- 選項 C 錯誤,可直接排除。
4. 排除可能的誤區
- 混淆
initial和always的執行次數:initial只執行一次,always重復執行。
- 混淆綜合性質:
initial不可綜合,always可綜合。
- 混淆功能描述:
initial用于仿真初始化,always用于硬件行為描述。
正確答案
A. initial 只執行 1 次,always 執行多次
B. initial 不可以被綜合,always 可以綜合
理由:
- A 和 B 均正確描述了
initial和always的區別。 - C 錯誤,因為
always和initial的時序和過程語句描述不同。
題目回顧2
題目:在設計中,可以被用于進行不同時鐘域隔離的 memory 類型為(多選)
選項:
A. two-port Register File
B. single-port RAM
C. single-port Register File
D. dual-port RAM
解題步驟
1. 理解時鐘域隔離的需求
- 時鐘域隔離:在不同時鐘域之間傳遞數據時,需要避免亞穩態(Metastability)和數據不一致問題。
- 解決方案:使用 雙端口存儲器(Dual-port Memory),允許兩個時鐘域獨立訪問數據。
2. 分析各選項
A. two-port Register File
- Register File:一種基于寄存器的存儲器,通常用于小規模數據存儲。
- two-port:支持兩個端口,可以分別連接到不同時鐘域。
- 適用性:可以用于時鐘域隔離,但通常容量較小,適合特定場景。
B. single-port RAM
- single-port:只有一個端口,無法同時支持兩個時鐘域的訪問。
- 適用性:不能用于時鐘域隔離。
C. single-port Register File
- single-port:只有一個端口,無法同時支持兩個時鐘域的訪問。
- 適用性:不能用于時鐘域隔離。
D. dual-port RAM
- dual-port:支持兩個獨立端口,可以分別連接到不同時鐘域。
- 適用性:是時鐘域隔離的 標準解決方案,廣泛應用于跨時鐘域數據傳遞。
3. 驗證題目描述
- 題目要求選擇可用于時鐘域隔離的 memory 類型。
- 雙端口存儲器(two-port Register File 和 dual-port RAM)可以滿足需求。
- 單端口存儲器(single-port RAM 和 single-port Register File)無法滿足需求。
4. 排除可能的誤區
- 混淆端口數量與功能:
- 只有雙端口存儲器才能支持兩個時鐘域的獨立訪問。
- 忽略存儲器的類型:
- Register File 和 RAM 均可用于時鐘域隔離,只要它們是雙端口的。
正確答案
A. two-port Register File
D. dual-port RAM
理由:
- 只有雙端口存儲器(two-port Register File 和 dual-port RAM)可以支持不同時鐘域的隔離訪問。
- 單端口存儲器(single-port RAM 和 single-port Register File)無法滿足需求。
1. 題目內容(題號:3)
題目內容:有如下的代碼,下面 $cast 返回值為 1 的有( )
class A;
endclass;
class B extends A;
endclass;
class C extends B;
endclass;
A a = new(…);
B b = new(…);
C c = new(…);
選項:
A. a = c; $cast(b, a)
B. $cast(b, c)
C. $cast(b, a)
D. a = b; $cast(b, a)
2. 解題步驟
1. 理解 $cast 的作用
$cast是 SystemVerilog 中的動態類型轉換操作,用于在運行時檢查對象類型是否兼容。- 如果轉換成功,返回
1;否則返回0。
2. 分析類繼承關系
- 類繼承關系:
C extends B extends AC是B的子類,B是A的子類。- 因此:
C對象可以賦值給B或A類型變量(向上轉型)。B或A類型變量不能直接賦值給C類型變量(向下轉型需$cast)。
3. 逐項分析選項
A. a = c; $cast(b, a)
a = c:向上轉型,合法。$cast(b, a):將A類型變量a轉換為B類型變量b。a實際指向C對象,C是B的子類,因此轉換成功。
- 返回值:
1
B. $cast(b, c)
$cast(b, c):將C類型變量c轉換為B類型變量b。C是B的子類,向上轉型,合法。
- 返回值:
1
C. $cast(b, a)
$cast(b, a):將A類型變量a轉換為B類型變量b。a實際指向A對象,A不是B的子類,轉換失敗。
- 返回值:
0
D. a = b; $cast(b, a)
a = b:向上轉型,合法。$cast(b, a):將A類型變量a轉換為B類型變量b。a實際指向B對象,B是B的自身類型,轉換成功。
- 返回值:
1
4. 總結
- 返回值為
1的選項:A、B、D - 返回值為
0的選項:C
3. 最終答案
正確答案:A、B、D
理由:
- A、B、D 中的
$cast操作均滿足類型兼容性,轉換成功,返回1。 - C 中的
$cast操作類型不兼容,轉換失敗,返回0。
1. 題目內容(題號:4)
題目內容:如下時鐘組合中,哪些是同步時鐘?
選項:
A. 不同 PLL 產生的相位不同,頻率相同的時鐘
B. 相同 PLL 產生的 2 分頻時鐘和 4 分頻時鐘
C. 同一 PLL 產生的相位相差 180°,頻率相同的時鐘
D. 不同 PLL 產生的頻率不同的時鐘
2. 解題步驟
1. 理解同步時鐘的定義
- 同步時鐘:兩個時鐘信號具有固定的相位關系,且頻率相同或成整數倍關系。
- 關鍵特征:
- 頻率相同或成整數倍關系。
- 相位關系固定(即使有偏移,也是固定的)。
2. 分析各選項
A. 不同 PLL 產生的相位不同,頻率相同的時鐘
- 分析:
- 頻率相同,但相位關系不固定(不同 PLL 可能導致相位漂移)。
- 結論:異步時鐘。
B. 相同 PLL 產生的 2 分頻時鐘和 4 分頻時鐘
- 分析:
- 頻率成整數倍關系(4 分頻是 2 分頻的 2 倍)。
- 來自同一 PLL,相位關系固定。
- 結論:同步時鐘。
C. 同一 PLL 產生的相位相差 180°,頻率相同的時鐘
- 分析:
- 頻率相同,相位關系固定(相差 180°)。
- 結論:同步時鐘。
D. 不同 PLL 產生的頻率不同的時鐘
- 分析:
- 頻率不同,且相位關系不固定。
- 結論:異步時鐘。
3. 總結
- 同步時鐘的選項:B、C
- 異步時鐘的選項:A、D
3. 最終答案
正確答案:B、C
理由:
- B 和 C 中的時鐘頻率相同或成整數倍關系,且相位關系固定,符合同步時鐘的定義。
- A 和 D 中的時鐘頻率相同但相位不固定,或頻率不同,屬于異步時鐘。
好的,后續如果需要輸出公式,我會統一采用 Python 代碼文本形式。以下是更新后的格式示例:
1. 題目內容(題號:5)
題目內容:影響 CMOS 電路動態功耗的因素有哪些?
選項:
A. 工藝
B. 翻轉率
C. 供電電壓
D. 溫度
2. 解題步驟
1. 理解 CMOS 動態功耗的公式
CMOS 電路的動態功耗(P_dynamic)主要由以下公式決定:
P_dynamic = alpha * C * V**2 * f
其中:
alpha:翻轉率(Switching Activity,信號從 0→1 或 1→0 變化的概率)。C:負載電容(與工藝、布線、晶體管尺寸相關)。V:供電電壓。f:時鐘頻率。
2. 分析各選項
A. 工藝
- 影響:工藝決定了晶體管的尺寸、寄生電容
C和漏電特性。 - 是否影響動態功耗:是(工藝影響
C)。
B. 翻轉率
- 影響:翻轉率
alpha直接決定動態功耗。 - 是否影響動態功耗:是(公式中的
alpha)。
C. 供電電壓
- 影響:供電電壓
V以平方關系影響動態功耗。 - 是否影響動態功耗:是(公式中的
V**2)。
D. 溫度
- 影響:溫度主要影響漏電功耗(靜態功耗),對動態功耗無直接影響。
- 是否影響動態功耗:否(動態功耗主要由公式中的
alpha,C,V,f決定)。
3. 總結
- 直接影響動態功耗的選項:A(工藝影響
C)、B(翻轉率)、C(供電電壓)。 - 不直接影響動態功耗的選項:D(溫度)。
3. 最終答案
正確答案:A、B、C
理由:
- 工藝(A)、翻轉率(B)、供電電壓(C)均直接參與動態功耗的計算。
- 溫度(D)主要影響靜態功耗,不直接影響動態功耗。
注:
- 若題目明確區分動態功耗和靜態功耗,溫度(D)不選。
- 若題目未明確區分,需結合上下文判斷(本題選項 D 不選)。
關于溫度對短路功耗的影響
1. 短路功耗的公式
短路功耗(P_short_circuit)的公式為:
P_short_circuit = alpha * f * V_DD * I_peak * t_sc
其中:
alpha:信號翻轉率;f:時鐘頻率;V_DD:電源電壓;I_peak:短路電流峰值;t_sc:短路時間。
2. 溫度對短路功耗的影響
- 溫度升高 → 載流子遷移率降低 →
I_peak下降 → 短路功耗降低。 - 溫度升高 → 閾值電壓
V_th降低 → 晶體管更容易導通,但遷移率下降的效應通常占主導 → 凈效應仍是 短路功耗降低。 - 溫度升高 → 電路延遲增大 →
t_sc略微增加,但電流下降更顯著 → 總體 短路功耗降低。
3. 結論
- 短路功耗受溫度影響(高溫時降低),但動態功耗不受直接影響。
- 原題答案(A/B/C)仍正確,因題目可能默認討論動態功耗(溫度不選)。
- 若題目包含短路功耗,需補充說明溫度的影響。
最終建議
- 考試/做題:按題目明確范圍選擇(動態功耗不選 D,短路功耗需考慮 D)。
- 工程實踐:高溫下總功耗可能因靜態功耗(漏電)上升而增加,但動態和短路功耗可能下降。需結合具體工藝數據。
注:本題選項中未明確區分動態與短路功耗,建議按動態功耗理解(不選 D)。若需嚴謹性,題目應明確功耗類型。
7. 題目內容
Verilog 中關于任務和函數,描述正確的有( )。
1. 解題步驟
1.1 理解任務(Task)和函數(Function)的區別
- 任務(Task):
- 支持時序控制(如
#,@,wait) - 可調用其他任務或函數
- 支持 input/output/inout 端口
- 無返回值
- 支持時序控制(如
- 函數(Function):
- 禁止時序控制(必須單周期完成)
- 僅可調用其他函數
- 必須有 return 返回值
- 僅允許 input 端口
1.2 選項分析
| 選項 | 內容 | 正確性 | 依據 |
|---|---|---|---|
| A | 任務可以調用函數 | ? | 任務允許調用無時序控制的函數 |
| B | 函數可以調用函數 | ? | 函數可嵌套調用,但需保持純組合邏輯 |
| C | 任務可以調用任務 | ? | 任務支持嵌套調用,但需注意避免無限遞歸 |
| D | 函數可以調用任務 | ? | 函數禁止調用含時序控制的任務(違反單周期執行約束) |
2. 最終答案
正確答案:A、B、C
判題依據:
- 函數調用限制(D錯誤)是Verilog語法強制約束,違反將導致編譯錯誤
- 任務調用權限(A/C正確)由其支持時序控制的特性決定
- 函數嵌套調用(B正確)需確保無組合邏輯環路
3. 工程注意事項
- 遞歸風險:任務嵌套調用需設置終止條件(如最大調用深度)
- 仿真性能:函數嵌套層級過多可能導致綜合器優化困難
- 代碼規范:建議任務/函數調用關系繪制成調用關系圖,避免循環依賴
注:SystemVerilog對函數功能有擴展(如void函數),但本題限定Verilog標準語法。
8. 題目內容
邏輯函數可以有的表達式為( )。
1. 解題步驟
1.1 理解邏輯函數的表示形式
邏輯函數是描述輸入與輸出之間邏輯關系的數學函數,常用以下形式表示:
- 真值表(Truth Table):列出所有輸入組合及其對應的輸出值。
- 卡諾圖(Karnaugh Map):用于簡化邏輯表達式的圖形化工具。
- 邏輯表達式(Logical Expression):用邏輯運算符(如與、或、非)表示的代數式。
- 組合圖(Combinational Diagram):用邏輯門(如與門、或門、非門)組成的電路圖。
1.2 分析各選項
| 選項 | 內容 | 正確性 | 依據 |
|---|---|---|---|
| A | 真值表 | ? | 真值表是邏輯函數的標準表示形式之一 |
| B | 卡諾圖 | ? | 卡諾圖用于邏輯函數的簡化和優化 |
| C | 邏輯表達式 | ? | 邏輯表達式是邏輯函數的代數表示形式 |
| D | 組合圖 | ? | 組合圖是邏輯函數的電路實現形式 |
2. 最終答案
正確答案:A、B、C、D
判題依據:
- 真值表、卡諾圖、邏輯表達式和組合圖均是邏輯函數的有效表示形式
- 每種形式在不同場景下有其獨特優勢(如真值表用于驗證,卡諾圖用于簡化,邏輯表達式用于分析,組合圖用于實現)
3. 工程注意事項
- 真值表:適用于輸入變量較少的情況,變量過多時表格規模指數增長
- 卡諾圖:適用于簡化 4-6 變量的邏輯函數,變量過多時難以繪制
- 邏輯表達式:需注意表達式的簡化和優化,避免冗余邏輯
- 組合圖:需考慮邏輯門的延遲和功耗,優化電路設計
注:本題選項 D 中的“組合圖”通常指邏輯門組成的電路圖,是邏輯函數的硬件實現形式。
9. 題目內容
基于FPGA和ASIC芯片設計的差異需要關注的有( )。
1. 解題步驟
1.1 理解FPGA與ASIC的核心差異
| 特性 | FPGA | ASIC |
|---|---|---|
| 可重構性 | 可重復編程 | 固定功能 |
| 開發周期 | 短(直接編程) | 長(需流片) |
| 性能 | 較低(依賴通用邏輯單元) | 高(定制化電路) |
| 功耗 | 較高(靜態功耗大) | 低(優化后靜態功耗小) |
| 成本 | 單件成本高,無流片費用 | 流片成本高,量產成本低 |
1.2 分析各選項的關鍵差異
| 選項 | 內容 | FPGA設計特點 | ASIC設計特點 | 差異點 |
|---|---|---|---|---|
| A | 上下電流程 | 需考慮配置加載順序(如Bitstream加載) | 固定電源時序,需嚴格滿足芯片規格 | FPGA需配置,ASIC需時序驗證 |
| B | 時鐘頻率 | 受布線延遲限制(通常≤500MHz) | 可定制高頻電路(可達GHz) | 頻率上限差異顯著 |
| C | 時鐘復位 | 復位信號需同步化處理 | 復位網絡需全局優化(低偏斜) | 復位網絡設計復雜度不同 |
| D | Memory控制 | 依賴內置Block RAM(固定架構) | 可定制Memory接口(如SRAM/DRAM控制器) | 靈活性不同 |
2. 最終答案
正確答案:A、B、C、D
關鍵差異說明:
- 上下電流程(A):
- FPGA:需管理配置文件的加載順序(如先供電再加載Bitstream)。
- ASIC:需嚴格遵循電源時序要求(如Power-On Reset電路設計)。
- 時鐘頻率(B):
- FPGA:時鐘頻率受布線資源和PLL性能限制。
- ASIC:可通過定制時鐘樹實現更高頻率。
- 時鐘復位(C):
- FPGA:復位信號需同步化以避免亞穩態。
- ASIC:需全局復位網絡優化(如低偏斜復位樹)。
- Memory控制(D):
- FPGA:使用固定架構的Block RAM,接口標準化。
- ASIC:可定制Memory接口(如帶寬、時序優化)。
3. 工程實踐建議
- FPGA設計:
- 優先使用廠商提供的IP核(如Xilinx的Clock Wizard)。
- 避免異步復位,推薦同步復位設計。
- ASIC設計:
- 需進行Sign-off時序分析(如STA)。
- 定制Memory控制器時需考慮工藝庫特性(如SRAM時序模型)。
注:FPGA與ASIC在驗證方法(如仿真覆蓋率要求)、DFT(可測試性設計)等方面也存在顯著差異,但本題未涉及。
10. 題目內容
異步電路的處理方式包括( )。
1. 解題步驟
1.1 理解異步電路的處理方法
異步電路的數據傳輸需要解決亞穩態和信號完整性問題,常用方法包括:
- 握手協議(Handshake Protocol):通過請求(Req)和應答(Ack)信號確保數據安全傳輸。
- 格雷碼(Gray Code)同步:用于多比特信號,每次僅變化1位,降低亞穩態風險。
- 異步FIFO:通過雙端口RAM和格雷碼指針實現跨時鐘域數據緩沖。
- 雙觸發器同步(2-FF Synchronizer):單比特信號的標準同步方法。
1.2 分析各選項
| 選項 | 內容 | 有效性 | 適用場景 |
|---|---|---|---|
| A | 多bit DMUX同步 | ? | DMUX非標準異步處理方法,存在風險 |
| B | 握手協議同步 | ? | 適用于控制信號(如Req/Ack) |
| C | 多bit格雷碼同步 | ? | 適用于狀態機或計數器(如異步FIFO指針) |
| D | 異步FIFO同步 | ? | 多比特數據流的標準解決方案 |
2. 最終答案
正確答案:B、C、D
排除依據:
- 選項A(DMUX同步):非常規方法,無法保證多比特信號的同步可靠性。
- 其他選項:
- 握手協議(B)適用于控制信號同步。
- 格雷碼(C)用于多比特信號的低風險同步。
- 異步FIFO(D)是數據流傳輸的工業標準方案。
3. 工程注意事項
- 格雷碼限制:僅適用于連續變化的信號(如計數器),不適用于隨機多比特數據。
- 異步FIFO深度:需滿足最壞情況下的數據速率差(
深度 > (寫速率 - 讀速率) × 最大延遲)。 - 握手協議開銷:引入額外的延遲(需2次握手完成傳輸)。
注:選項D的“影步FIFO”應為“異步FIFO”,可能是筆誤。

)





)

)




實現步驟及示例)



![【補題】P10424 [藍橋杯 2024 省 B] 好數(數位dp)](http://pic.xiahunao.cn/【補題】P10424 [藍橋杯 2024 省 B] 好數(數位dp))
