Linux Ext2 文件系統與軟硬鏈接
- 理解硬件
- 磁盤、服務器、機柜、機房
- 磁盤物理結構
- 磁盤的邏輯結構
- 實際過程
- CHS 與 LBA 地址轉換
- 引入文件系統
- 引入 " 塊 " 概念
- 引入 " 分區 " 概念
- 引入 " inode " 概念
- ext2 文件系統
- 宏觀認識
- Block Group 塊組與其內部構成
- Super Block 超級塊
- GDT(Group Descriptor Table)塊組描述符表
- Block Bitmap 與 Inode Bitmap 位圖
- Inode Table
- Data Block
- inode 和 Data Block 映射
- i_block 尋址
- 具體創建文件過程
- 目錄與文件名
- 部分系統接口介紹
- 打開目錄函數 opendir
- 關閉目錄函數 closedir
- 讀取目錄函數 readdir
- 目錄項結構體 struct dirent
- 路徑解析
- 路徑緩存
- 文件的 ACM 時間戳屬性
- 掛載分區
- 軟硬鏈接
- 創建文件鏈接命令 ln
- 硬鏈接
- 軟鏈接
- 軟硬鏈接對比與其用途
- 硬鏈接與路徑環問題
理解硬件
磁盤、服務器、機柜、機房
機械磁盤 HDD(Mechanical Hard Disk Drive) 在 馮·諾依曼體系結構 中屬于外設,也是計算機中唯一的一個機械設備。其特點為:訪問慢、容量大、價格便宜等等。
固態硬盤 SSD(Solid-State Drive)也是外存。與 HDD 相比,訪問速度快、容量相對小、價格高等等。兩者為互補關系,不過隨著技術發展,SSD 將進一步替代 HDD。
服務器會有專門的插槽,用來插入磁盤存儲數據。多個服務器會放入機柜當中存放,機柜又會存放在專門的機房中統一管理,形成了明顯的層級結構:
| 層級 | 組件 | 功能 | 關系 |
|---|---|---|---|
| 第一層 | 磁盤(HDD/SSD) | 數據存儲的基本物理單元 | 安裝在服務器或存儲設備內部 |
| 第二層 | 服務器 | 提供計算、存儲、網絡服務 | 多塊磁盤組成服務器存儲系統 |
| 第三層 | 機柜 | 集中放置和管理服務器/設備 | 多臺服務器垂直安裝在機柜中 |
| 第四層 | 機房 | 容納 IT 基礎設施的環境 | 多個機柜排列在機房內 |
磁盤物理結構
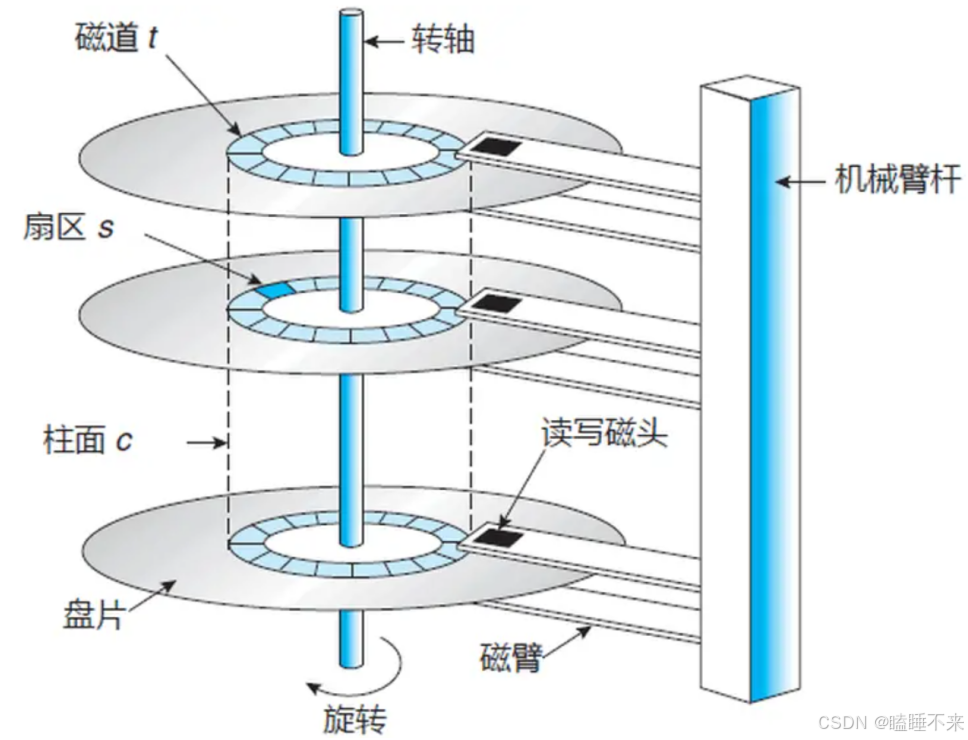
磁盤相關知識:
-
扇區是從磁盤讀出和寫入信息的最小單位,通常大小為 512 字節。
-
磁頭(head)數:每個盤片一般有上下兩面,分別對應 1 個磁頭,共 2 個磁頭。
-
磁道(track)數:磁道是從盤片外圈往內圈編號 0 磁道、1 磁道 …,靠近主軸的同心圓用于停靠磁頭,不存儲數據。
-
柱面(cylinder)數:磁道構成柱面,數量上等同于磁道個數。
-
扇區(sector)數:每個磁道都被切分成很多扇形區域,每道的扇區數量相同。
-
圓盤(platter)數:就是盤片的數量。
-
磁盤容量 = 磁頭數 × 磁道(柱面)數 × 每道扇區數 × 每扇區字節數。
-
注意傳動臂上的磁頭是共進退的

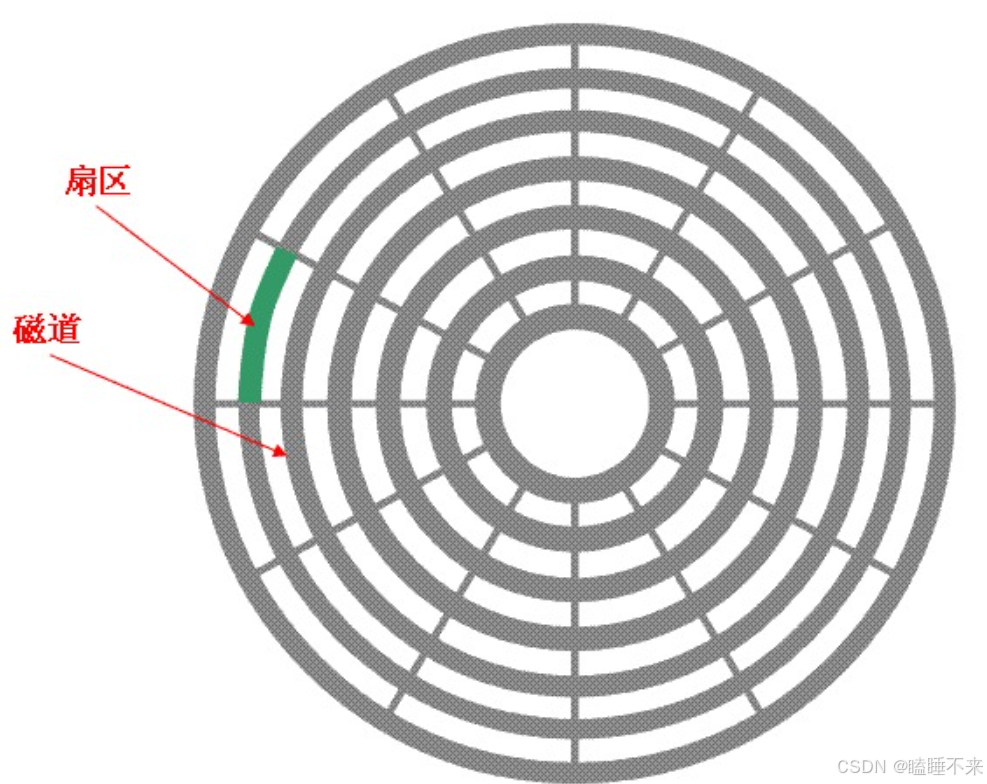
磁盤存儲的基本單元是扇區,通過讀寫扇區將數據進行存儲與修改,那怎樣定位一個扇區呢?
-
定位訪問哪一個柱面(磁道)(cylinder)
-
定位磁頭(header)
-
定位一個扇區(sector)
這就是 CHS(Cylinder-Head-Sector)地址定位方式,通過這三個參數,可以唯一確定磁盤上的一個物理扇區。
CHS 尋址對早期的磁盤非常有效,知道用哪個磁頭,讀取哪個柱面上的第幾扇區就可以讀到數據了。
而 文件 = 內容 + 屬性 其都是數據,即便占據多個扇區,只要我們能定位一個扇區,那就能定位多個關聯的扇區。
但是 CHS 模式支持的硬盤容量有限,因為系統用 8 bit 來存儲磁頭地址,用 10 bit 來存儲柱面地址,用 6 bit 來存儲扇區地址,而一個扇區共有 512 Byte,這樣使用 CHS 尋址一塊硬盤最大容量為 256 × 1024 × 63 × 512 Byte = 8064 MB(若按 1 MB = 1000000 Byte 來算就是 8.4 GB)。現代硬盤和操作系統普遍使用 LBA(邏輯塊地址),直接通過線性編號訪問扇區。
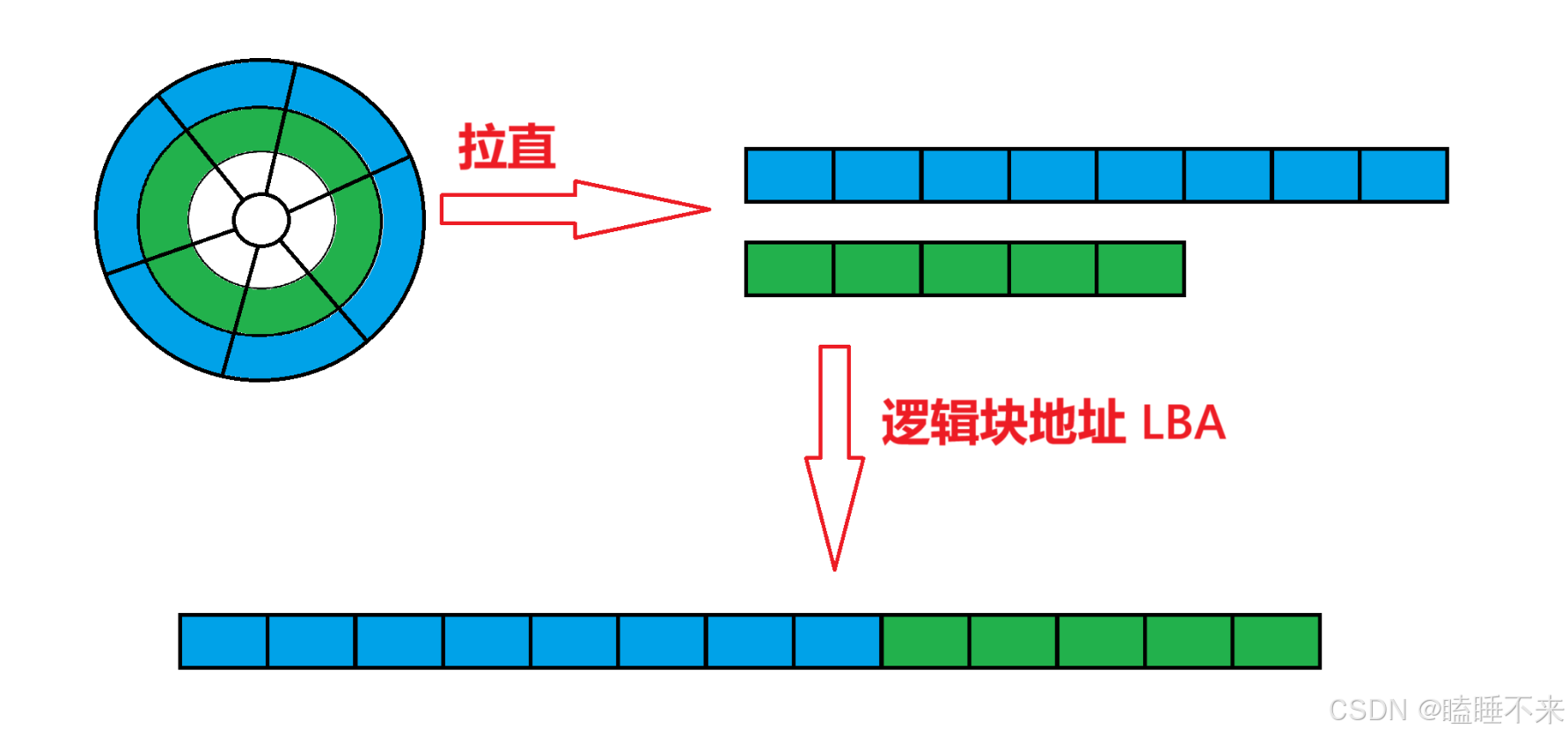
磁盤的邏輯結構
磁盤存儲單元本質上是弧形的,但邏輯上我們可以把磁盤的磁道 " 拉直 " 形成線性結構,這樣每一個扇區,就有了一個線性地址(其實就是數組下標),這種地址叫做邏輯塊地址 LBA(Logical Block Addressing):
實際過程
之前提到過傳動臂上的磁頭是共進退的,其可以在不同柱面同一個磁道同一個扇區進行訪問。
柱面是一個邏輯上的概念,在每一面上相同半徑的磁道邏輯上構成柱面。而磁盤物理上分了很多面,但在我們看來,邏輯上磁盤整體是由 " 柱面 " 卷起來的。
所以,磁盤的真實情況是某一盤面的某一個磁道展開即為一維數組,整個磁盤所有盤面的同一個磁道,即柱面展開為二維數組,整個磁盤就是多張二維的扇區數組表,即三維數組(圓筒形紙舉例):

則尋址一個扇區順序:先找到哪一個柱面(Cylinder),再確定柱面內哪一個磁道(磁頭 Head),最后確定扇區(Sector)。
從 C/C++ 的數組角度來說,不管是幾維的,本質都是一維數組。每一個扇區都有一個下標,其叫做 LBA 就是線性地址。
操作系統只需要使用 LBA 即可,而磁盤在內部需要將 LBA 地址與 CHS 地址相互轉換。
CHS 與 LBA 地址轉換
CHS 轉成 LBA:
-
單個柱面的扇區總數 = 磁頭數 × 每個磁道扇區數
-
LBA = 柱面號C × 單個柱面的扇區總數 + 磁頭號H × 每磁道扇區數 + 扇區號S - 1
-
即:LBA = 柱面號C × (磁頭數 × 每個磁道扇區數) + 磁頭號H × 每磁道扇區數 + 扇區號S - 1
-
扇區號通常是從 1 開始的,而在 LBA 中地址是從 0 開始的
-
柱面和磁道都是從 0 開始編號的
-
總柱面、磁道個數、扇區總數等信息在磁盤內部會自動維護,上層開機的時候會獲取到這些參數。
LBA 轉成 CHS:
-
// :表示除取整
-
柱面號C = LBA // ( 磁頭數 × 每磁道扇區數 )【就是單個柱面的扇區總數】
-
磁頭號H = ( LBA % ( 磁頭數 × 每磁道扇區數 )) // 每磁道扇區數
-
扇區號S = ( LBA % 每磁道扇區數 ) + 1
所以在磁盤使用者看來,根本就不用處理 CHS 地址,而是直接使用 LBA 地址。磁盤內部會自己轉換。
從邏輯結構上看,磁盤就是一個元素為扇區的一維數組,數組的下標就是每一個扇區的 LBA 地址。操作系統使用磁盤時可以只用一個數字訪問磁盤扇區。
引入文件系統
引入 " 塊 " 概念
硬盤是典型的 " 塊 " 設備,操作系統讀取硬盤數據的時候,考慮到效率問題,使用的是一次性連續讀取多個扇區,即一次性讀取一個 " 塊 "(block)。
硬盤的每個分區是被劃分為一個個的 " 塊 “。一個 " 塊 " 的大小是由格式化的時候確定的,并且不可以更改,最常見的是 4 KB,即連續八個扇區組成一個 " 塊 "。” 塊 " 是文件存取的最小單位。
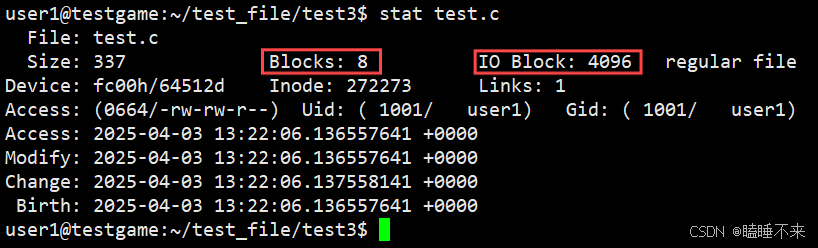
注意:
-
磁盤就是一個三維數組,我們把它看待成為一個 " 一維數組 " ,數組下標則是 LBA,每個元素都是扇區
-
每個扇區都有 LBA,那么 8 個扇區一個塊,每一個塊的地址我們也能算出來。
-
知道 LBA,則塊號 = LBA / 8
-
知道塊號,則 LAB = 塊號 × 8 + n ( n 是塊內第幾個扇區)
引入 " 分區 " 概念
磁盤可以被分成多個分區(partition)。以 Windows 觀點來看,一塊磁盤可能會將它分成 C、D、E 盤。則 C、D、E 就是分區。分區從實質上說就是對硬盤的一種格式化。但是Linux 的設備都是以文件形式存在,那是怎么分區的呢?
柱面是分區的最小單位,我們可以利用參考柱面號碼的方式來進行分區,其本質就是設置每個區的起始柱面和結束柱面號碼。 此時可以將硬盤上的柱面(分區)進行平鋪,將其想象成一個大的平面。
柱面大小一致,扇區個位一致,只要知道每個分區的起始和結束柱面號,就知道每一個柱面多少個扇區,該分區多大也能得出。
引入 " inode " 概念
在上篇文章中我們說過 文件 = 數據 + 屬性,使用 ls -l 命令的時候除了文件名,還能看到文件元數據(屬性):
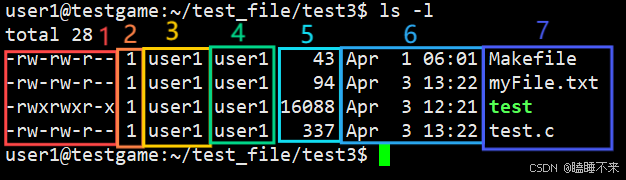
每行包含 7 列:
-
權限模式
-
硬鏈接數
-
文件所有者
-
文件所屬組
-
文件大小
-
最后修改時間
-
文件名
ls -l實際是讀取存儲在磁盤上的文件信息,然后在用戶層顯示出來。
其實這個信息除了通過這種方式來讀取,還有 stat 命令能夠看到更多信息。
到這我們需要思考一個問題,文件數據都儲存在 " 塊 " 中。那么很顯然,我們還必須找到一個地方儲存文件的元信息(屬性信息),比如文件的創建者、文件的創建日期、文件的大小等等。這種儲存文件元信息的區域就叫做 inode(索引節點):
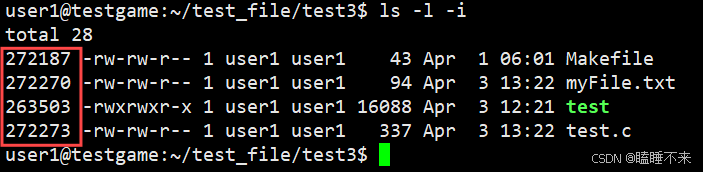
每一個文件都有對應的 inode,里面包含了與該文件有關的一些信息。為了能解釋清楚inode,我們需要了解一下文件系統。
注意:
-
Linux 下文件的存儲是屬性和內容分離存儲的
-
Linux 下,保存文件屬性的集合叫做 inode,一個文件有一個 inode。inode 內有一個唯一的標識符,叫做 inode 號。
我們可以看看文件的屬性 inode 的具體代碼:
/*
* Constants relative to the data blocks
*/
#define EXT2_NDIR_BLOCKS 12
#define EXT2_IND_BLOCK EXT2_NDIR_BLOCKS
#define EXT2_DIND_BLOCK (EXT2_IND_BLOCK + 1)
#define EXT2_TIND_BLOCK (EXT2_DIND_BLOCK + 1)
#define EXT2_N_BLOCKS (EXT2_TIND_BLOCK + 1)/*
* Structure of an inode on the disk
*/
struct ext2_inode {__le16 i_mode; /* File mode */__le16 i_uid; /* Low 16 bits of Owner Uid */__le32 i_size; /* Size in bytes */__le32 i_atime; /* Access time */__le32 i_ctime; /* Creation time */__le32 i_mtime; /* Modification time */__le32 i_dtime; /* Deletion Time */__le16 i_gid; /* Low 16 bits of Group Id */__le16 i_links_count; /* Links count */__le32 i_blocks; /* Blocks count */__le32 i_flags; /* File flags */union {struct {__le32 l_i_reserved1;} linux1;struct {__le32 h_i_translator;} hurd1;struct {__le32 m_i_reserved1;} masix1;} osd1; /* OS dependent 1 */__le32 i_block[EXT2_N_BLOCKS];/* Pointers to blocks */__le32 i_generation; /* File version (for NFS) */__le32 i_file_acl; /* File ACL */__le32 i_dir_acl; /* Directory ACL */__le32 i_faddr; /* Fragment address */union {struct {__u8 l_i_frag; /* Fragment number */__u8 l_i_fsize; /* Fragment size */__u16 i_pad1;__le16 l_i_uid_high; /* these 2 fields */__le16 l_i_gid_high; /* were reserved2[0] */__u32 l_i_reserved2;} linux2;struct {__u8 h_i_frag; /* Fragment number */__u8 h_i_fsize; /* Fragment size */__le16 h_i_mode_high;__le16 h_i_uid_high;__le16 h_i_gid_high;__le32 h_i_author;} hurd2;struct {__u8 m_i_frag; /* Fragment number */__u8 m_i_fsize; /* Fragment size */__u16 m_pad1;__u32 m_i_reserved2[2];} masix2;} osd2; /* OS dependent 2 */
};
-
文件名屬性并未納入到 inode 數據結構內部
-
inode 的大小一般是 128 字節或者 256,這里后面統一標準為 128 字節
-
任何文件的內容大小可以不同,但是屬性大小一定是相同的
到目前為止還有兩個問題:
-
我們已經知道硬盤是典型的 " 塊 " 設備,操作系統讀取硬盤數據的時候,讀取的基本單位是 " 塊 “。” 塊 " 又是硬盤的每個分區下的結構,難道 " 塊 " 是隨意的在分區上排布的嗎?那要怎么找到 " 塊 " 呢?
-
還有就是上面提到的存儲文件屬性的 inode,又是如何放置的呢?
而文件系統就是為了組織管理這些問題的。
ext2 文件系統
宏觀認識
我們想要在硬盤上儲文件,必須先把硬盤格式化為某種格式的文件系統,才能存儲文件。文件系統的目的就是組織和管理硬盤中的文件。
在 Linux 系統中,最常見的是 ext2 系列的文件系統。其早期版本為 ext2,后來又發展出 ext3 和 ext4。ext3 和 ext4 雖然對 ext2 進行了增強,但是其核心設計并沒有發生變化,我們這里以較老的 ext2 作為演示對象。
ext2 文件系統將整個分區劃分成若干個同樣大小的塊組 (Block Group),如下圖所示:
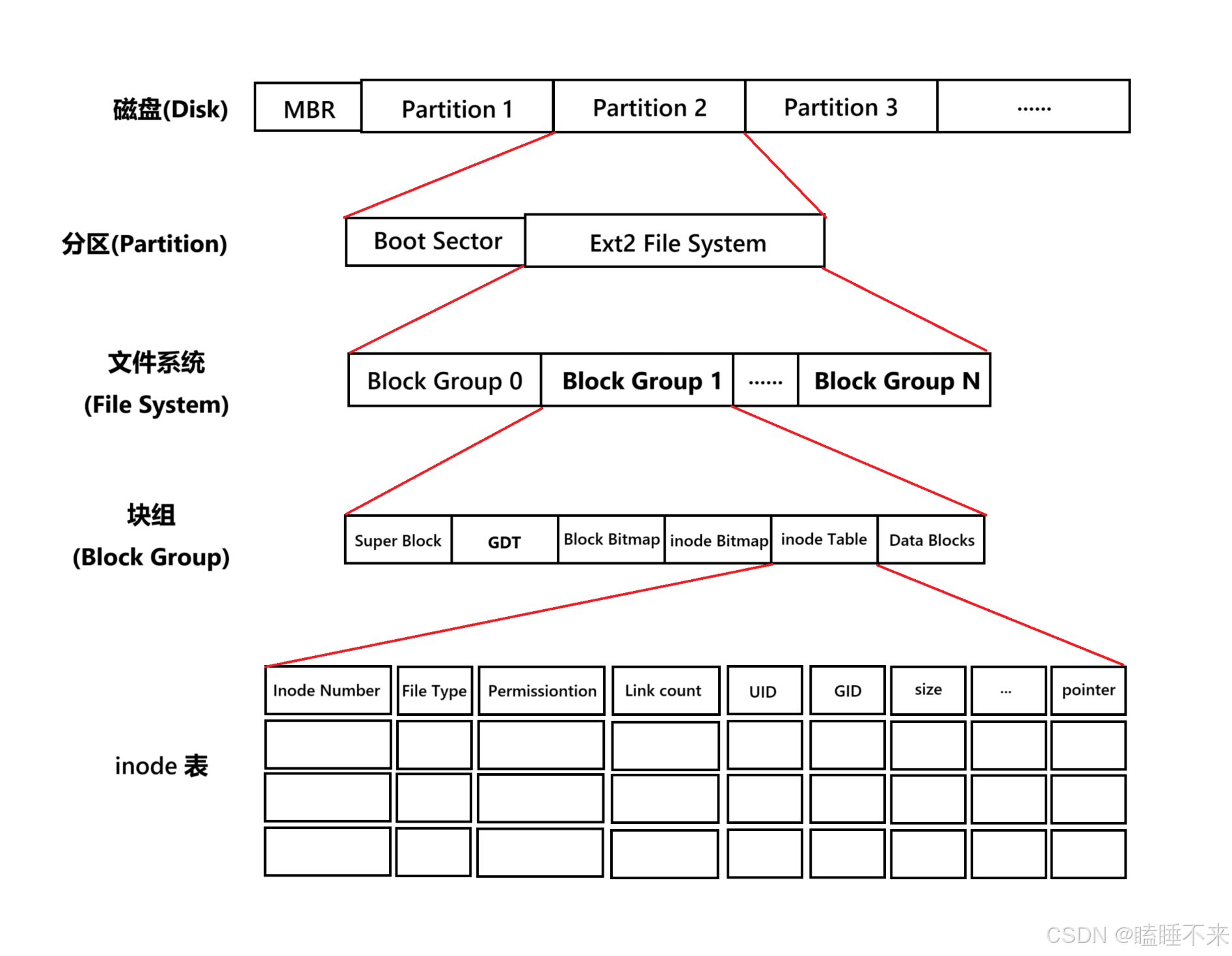
只要能管理一個分區就能管理所有分區,也就能管理所有磁盤文件。
上圖中啟動塊(Boot Block/Sector)的大小是確定的,為 1 KB,由 PC 標準規定,用來存儲磁盤分區信息和啟動信息,任何文件系統都不能修改啟動塊。啟動塊之后才是 ext2 文件系統的開始。
Block Group 塊組與其內部構成
ext2 文件系統會根據分區的大小劃分為 N 個 Block Group。而每個 Block Group 都有著相同的結構組成。
Super Block 超級塊
存放文件系統本身的結構信息,描述整個分區的文件系統信息。記錄的信息主要有:
- bolck 和 inode 的總量
- 未使用的 block 和 inode 的數量
- 一個 block 和 inode 的大小
- 最近一次掛載的時間
- 最近一次寫入數據的時間
- 最近一次檢驗磁盤的時間等其它文件系統的相關信息。
若 Super Block 的信息被破壞,可以說整個文件系統結構就被破壞了。
超級塊在每個塊組的開頭都有一份拷貝(第一個塊組必須有,后面的塊組可以沒有)。 為了保證文件系統在磁盤部分扇區出現物理問題的情況下還能正常工作,就必須保證文件系統的 Super Block 信息在這種情況下也能正常訪問。所以一個文件系統的 Super Block 會在多個 Block Group 中進行備份,這些 Super Block 區域的數據保持一致。
/*
* Structure of the super block
*/
struct ext2_super_block {__le32 s_inodes_count; /* Inodes count */__le32 s_blocks_count; /* Blocks count */__le32 s_r_blocks_count; /* Reserved blocks count */__le32 s_free_blocks_count; /* Free blocks count */__le32 s_free_inodes_count; /* Free inodes count */__le32 s_first_data_block; /* First Data Block */__le32 s_log_block_size; /* Block size */__le32 s_log_frag_size; /* Fragment size */__le32 s_blocks_per_group; /* # Blocks per group */__le32 s_frags_per_group; /* # Fragments per group */__le32 s_inodes_per_group; /* # Inodes per group */__le32 s_mtime; /* Mount time */__le32 s_wtime; /* Write time */__le16 s_mnt_count; /* Mount count */__le16 s_max_mnt_count; /* Maximal mount count */__le16 s_magic; /* Magic signature */__le16 s_state; /* File system state */__le16 s_errors; /* Behaviour when detecting errors */__le16 s_minor_rev_level; /* minor revision level */__le32 s_lastcheck; /* time of last check */__le32 s_checkinterval; /* max. time between checks */__le32 s_creator_os; /* OS */__le32 s_rev_level; /* Revision level */__le16 s_def_resuid; /* Default uid for reserved blocks */__le16 s_def_resgid; /* Default gid for reserved blocks *//** These fields are for EXT2_DYNAMIC_REV superblocks only.** Note: the difference between the compatible feature set and* the incompatible feature set is that if there is a bit set* in the incompatible feature set that the kernel doesn't* know about, it should refuse to mount the filesystem.** e2fsck's requirements are more strict; if it doesn't know* about a feature in either the compatible or incompatible* feature set, it must abort and not try to meddle with* things it doesn't understand...*/__le32 s_first_ino; /* First non-reserved inode */__le16 s_inode_size; /* size of inode structure */__le16 s_block_group_nr; /* block group # of this superblock */__le32 s_feature_compat; /* compatible feature set */__le32 s_feature_incompat; /* incompatible feature set */__le32 s_feature_ro_compat; /* readonly-compatible feature set */__u8 s_uuid[16]; /* 128-bit uuid for volume */char s_volume_name[16]; /* volume name */char s_last_mounted[64]; /* directory where last mounted */__le32 s_algorithm_usage_bitmap; /* For compression *//** Performance hints. Directory preallocation should only* happen if the EXT2_COMPAT_PREALLOC flag is on.*/__u8 s_prealloc_blocks; /* Nr of blocks to try to preallocate*/__u8 s_prealloc_dir_blocks; /* Nr to preallocate for dirs */__u16 s_padding1;/** Journaling support valid if EXT3_FEATURE_COMPAT_HAS_JOURNAL set.*/__u8 s_journal_uuid[16]; /* uuid of journal superblock */__u32 s_journal_inum; /* inode number of journal file */__u32 s_journal_dev; /* device number of journal file */__u32 s_last_orphan; /* start of list of inodes to delete */__u32 s_hash_seed[4]; /* HTREE hash seed */__u8 s_def_hash_version; /* Default hash version to use */__u8 s_reserved_char_pad;__u16 s_reserved_word_pad;__le32 s_default_mount_opts;__le32 s_first_meta_bg; /* First metablock block group */__u32 s_reserved[190]; /* Padding to the end of the block */
};
GDT(Group Descriptor Table)塊組描述符表
塊組描述符表,用于描述塊組屬性信息。整個分區分成多個塊組就對應有多少個塊組描述符。
每個塊組描述符存儲一個塊組的描述信息,如:在這個塊組中從哪里開始是 inode Table,從哪里開始是 Data Blocks,空閑的 inode 和數據塊還有多少個等等。塊組描述符在每個塊組的開頭都有一份拷貝。
// 磁盤級blockgroup的數據結構
/*
* Structure of a blocks group descriptor
*/
struct ext2_group_desc
{__le32 bg_block_bitmap; /* Blocks bitmap block */__le32 bg_inode_bitmap; /* Inodes bitmap */__le32 bg_inode_table; /* Inodes table block*/__le16 bg_free_blocks_count; /* Free blocks count */__le16 bg_free_inodes_count; /* Free inodes count */__le16 bg_used_dirs_count; /* Directories count */__le16 bg_pad;__le32 bg_reserved[3];
};
Block Bitmap 與 Inode Bitmap 位圖
Block Bitmap 中每個 bit 表示一個 Data Block 中哪個數據塊已經被占用,哪個數據塊沒有被占用。
Inode Bitmap 同理,每個 bit 表示一個 inode 是否空閑可用。
Inode Table
-
存放文件屬性如:文件大小、所有者、最近修改時間等。
-
其為當前分組所有 Inode 屬性的集合
-
inode 編號以分區為單位整體劃分,不可跨分區
Data Block
數據區,存放文件內容,也就是一個一個的 Block。根據不同的文件類型有以下幾種情況:
-
對于普通文件,文件的數據存儲在數據塊中。
-
對于目錄,該目錄下的所有文件名和目錄名存儲在所在目錄的數據塊中。除了文件名外,
ls -l命令看到的其它信息保存在該文件的 inode 中。 -
Block 號按照分區劃分,不可跨分區
inode 和 Data Block 映射
i_block 尋址
在 inode 內部中的 i_block 是用來進行 inode 和 block 映射的:
// ......#define EXT2_NDIR_BLOCKS 12
#define EXT2_IND_BLOCK EXT2_NDIR_BLOCKS
#define EXT2_DIND_BLOCK (EXT2_IND_BLOCK + 1)
#define EXT2_TIND_BLOCK (EXT2_DIND_BLOCK + 1)
#define EXT2_N_BLOCKS (EXT2_TIND_BLOCK + 1)// ......__le32 i_block[EXT2_N_BLOCKS];/* Pointers to blocks */// ......
而 i_block 中的 EXT2_N_BLOCKS 是一個宏,值為 15,其中前 12 個指針為直接塊指針,用于直接指向存儲文件內容的普通數據塊(即磁盤上的物理存儲位置)。
如果文件較大,直接塊指針不足以存儲文件所有內容的地址,i_block 會通過多級間接塊索引表指針擴展尋址能力:
-
一級間接塊索引表指針:第 13 個(i_block[12])指向一個塊,這個塊指向多個直接塊指針。
-
二級間接塊索引表指針:第 14 個(i_block[13])指向一個塊,這個塊指向多個一級間接塊索引表指針。
-
三級間接塊索引表指針:第 15 個(i_block[14])指向一個塊,這個塊指向多個二級間接塊索引表指針。
注意,多級間接塊指針本身指向的是也是數據塊,大小同普通數據塊一樣是 4 KB,只是內容存儲的是低一級的塊指針。
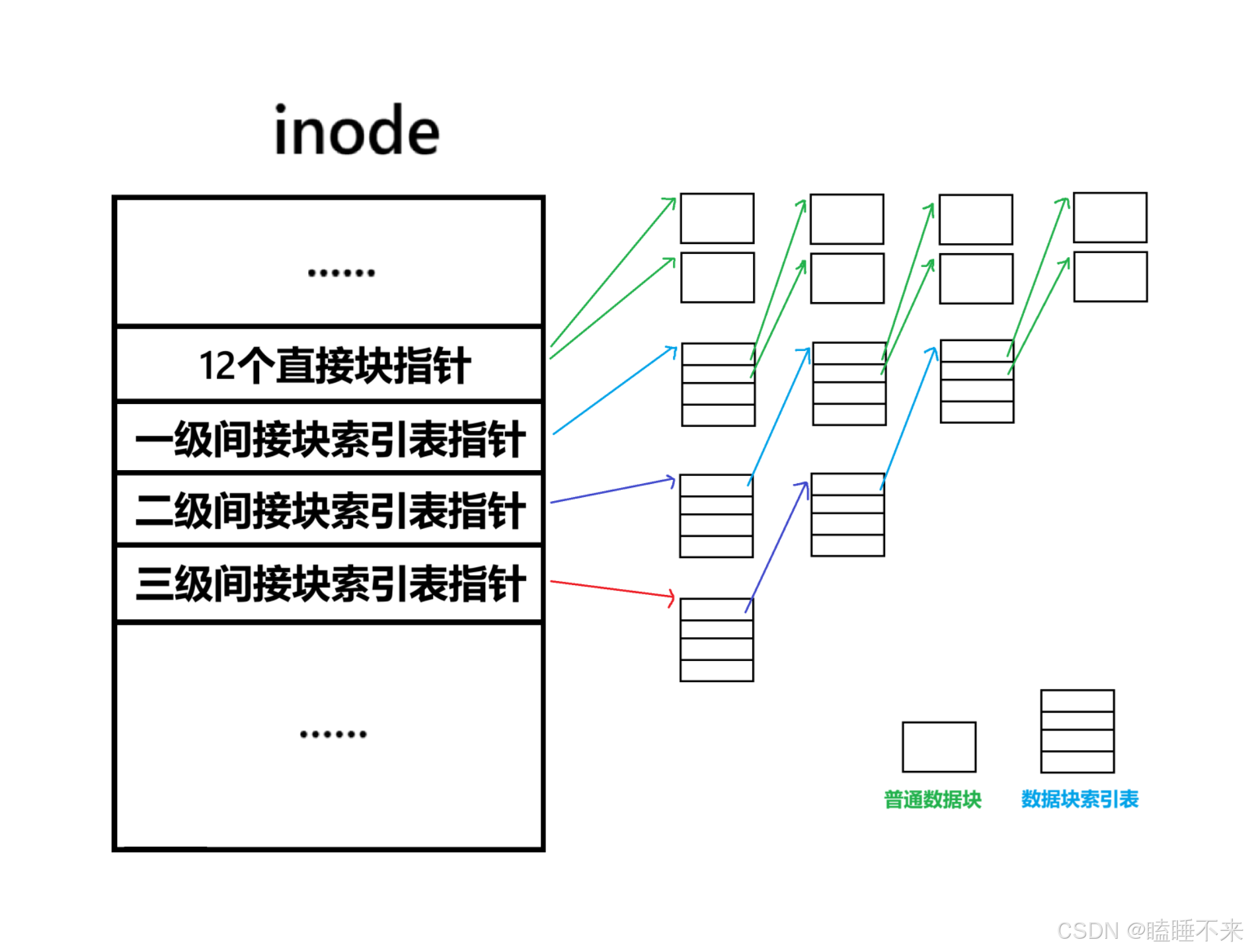
這里統計一下 i_block 尋址能力,假設數據塊大小為 4KB,指針為 4 字節(Byte):
則直接塊指針:12 block -> 12 × 4KB = 48KB 的文件內容
一級間接塊指針:1 block -> 4KB / 4B = 1024 個直接塊指針 -> 1024 × 4KB = 4MB 內容
二級間接塊指針:1024 × 1024 個直接塊指針 -> 4GB 內容
三級間接塊指針:1024 × 1024 × 1024 個直接塊指針 -> 4TB 內容
這樣通過 inode 存儲屬性,使用 i_block 尋找內容,則 文件 = 內容 + 屬性 都能找到。
結論:
-
分區之后的格式化操作,就是對分區進行分組,在每個分組中寫入 Super Block、GDT、Block、Bitmap、Inode 等管理信息,這些管理信息統稱即為文件系統。
-
只要知道文件的 inode 號,就能在指定分區中確定是哪一個分組,在哪一個分組確定是哪一個 inode。
-
拿到 inode 后文件屬性和內容就全部都有了。
具體創建文件過程
創建一個新文件主要有以下 4 個操作:
-
存儲屬性,內核先找到一個空閑的 i 節點(下面是 272273)。然后把文件信息記錄到其中。
-
存儲數據,該文件需要存儲在三個磁盤塊,內核找到了三個空閑塊:300、500、800。將內核緩沖區的第一塊數據復制到 300,下一塊復制到 500,以此類推。
-
記錄分配情況,文件內容按順序 300、500、800 存放。內核在 inode 上的磁盤分布區記錄了上述塊列表。
-
添加文件名到目錄。
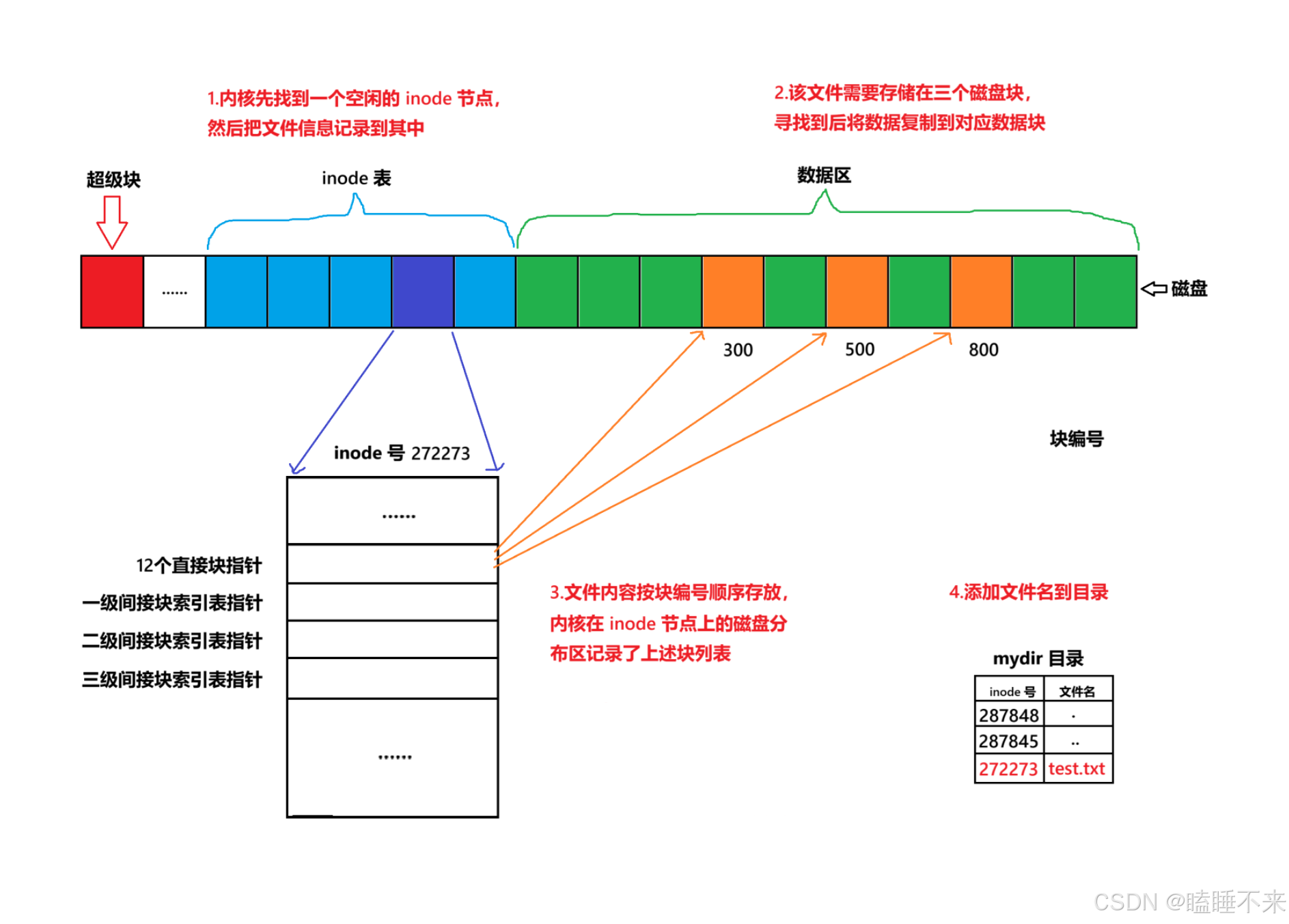
新的文件名 test.txt,Linux 內核只需在當前的目錄中記錄這個文件,將入口(272273,test.txt)添加到目錄文件,然后以 文件名 和 inode 之間的對應關系將文件名和文件的內容及屬性連接起來。
目錄與文件名
我們訪問文件,都是用的文件名,沒用過 inode 號。但其實 Linux 會使用文件名找到其對應的 inode 。
目錄也是文件,但是磁盤上沒有目錄的概念,只有文件的 屬性 + 內容 的概念。而目錄的屬性同其它文件一樣,內容則保存的是 內部的文件名 和 Inode 號 的映射關系。
我們可以使用系統接口打印目錄里的內容,函數等介紹留到下一部分:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <dirent.h>int main(int argc, char* argv[])
{if (argc != 2){ fprintf(stderr, "參數錯誤");exit(EXIT_FAILURE);} DIR* dir = opendir(argv[1]);if (dir == NULL){ perror("opendir");exit(EXIT_FAILURE);} struct dirent* entry;while ((entry = readdir(dir)) != NULL){ // 跳過 "." 和 ".." 目錄項if (strcmp(entry->d_name, ".") == 0 || strcmp(entry->d_name, "..") == 0){ continue;} printf("文件名: %-10s, inode: %lu\n", entry->d_name, (unsigned long)entry->d_ino); } closedir(dir);return 0;
}
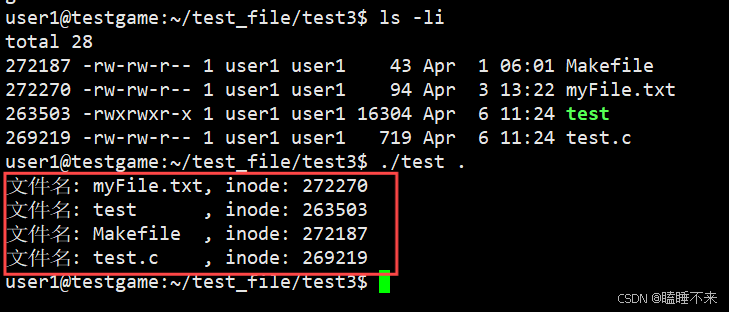
-
所以訪問文件必須打開當前目錄,根據目錄中的文件名獲得對應的 inode 號,然后進行文件訪問。
-
所以訪問文件必須要知道當前工作目錄,本質是必須要打開當前工作目錄文件,查找目錄文件的內容。
部分系統接口介紹
打開目錄函數 opendir
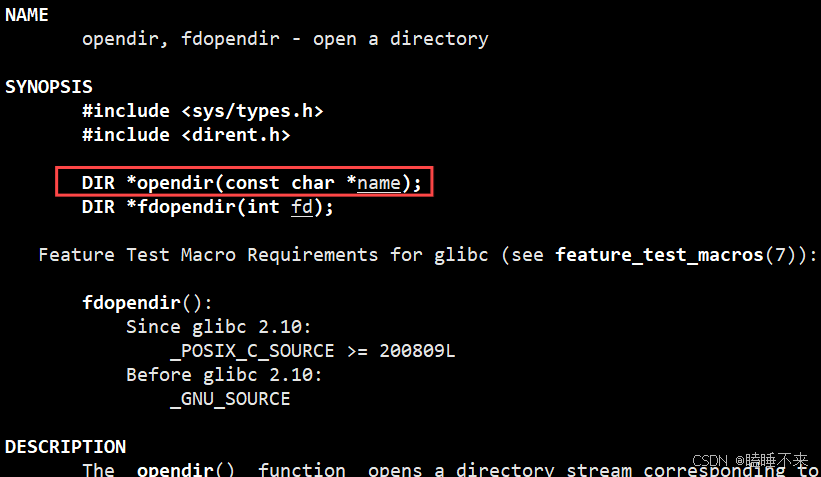
opendir 返回值:成功時返回一個指向 DIR 結構的指針,失敗時返回 NULL,并設置 errno 來指示錯誤類型
opendir 參數 name :要打開的目錄路徑名
關閉目錄函數 closedir
closedir 返回值:成功時返回 0,失敗時返回 -1,并設置 errno 來指示錯誤類型
closedir 參數 dirp :接收由 opendir() 返回的目錄流指針
讀取目錄函數 readdir
readdir 返回值:成功時返回一個指向 struct dirent 的指針,包含下一個目錄項的信息。到達目錄末尾或出錯時返回 NULL(到達末尾不改 errno,出錯時設置 errno)
readdir 參數 dirp :接收由 opendir() 返回的目錄流指針
目錄項結構體 struct dirent
struct dirent {ino_t d_ino; // Inode 號off_t d_off; // 到下一個 dirent 的偏移unsigned short d_reclen; // 本記錄的長度unsigned char d_type; // 文件類型char d_name[256]; // 文件名
};
d_ino (inode number):表示文件的 inode 編號
d_off :表示到下一個目錄項的偏移量
d_reclen :表示本目錄項記錄的總長度,主要用于內部處理
d_type :文件類型信息(非 POSIX 標準,但大多數現代 UNIX 系統支持)
d_name :表示文件名,以 null 結尾
路徑解析
Linux 中所有目錄都是文件,查看目錄內容時需要用上一級目錄打開,而上一級又要從上上級的目錄中打開,類似 " 遞歸 " 一樣,直到遇到 / 根目錄。
而訪問目標文件時,需要把路徑中所有的目錄全部解析,比如:/home/user1/test_file/test3/test.c 要從根目錄開始依次打開每一個目錄,根據目錄名依次訪問每個目錄下指定的目錄,直到訪問到 test.c 停止。這個過程就叫做 Linux 的路徑解析。
所以我們知道訪問文件必須要有 目錄 + 文件名 = 路徑 的這一原因,而根目錄是固定的文件名,其 inode 號無需查找,系統開機之后就一定會知道。
但我們注意到訪問文件時需要路徑,可路徑又由誰提供呢?
-
用戶訪問文件都是 指令/工具 訪問,其本質是進程訪問,進程有 CWD,則進程提供路徑。
-
在磁盤文件系統中,用戶新建的任何文件,都在用戶本身(家目錄)或者系統指定的目錄下新建,這是天然就有的路徑。
-
Linux 系統本身有根目錄,根目錄下又有眾多缺省目錄。
-
可以說 系統 + 用戶 共同構建 Linux 路徑結構。
路徑緩存
Linux 磁盤中,不存在真正的目錄,只有文件。其只保存文件 屬性 + 內容。
原則上訪問任何文件,都要從 / 根目錄開始進行路徑解析。但這樣效率太慢,Linux 會緩存歷史路徑結構,加快訪問。
打開的文件如果是目錄,則需操作系統自己在內存中進行路徑維護,這也是 Linux 產生目錄這一概念的原因。
在 Linux 內核維護樹狀路徑結構的結構體叫做 struct dentry(Linux 內核 2.6.32):
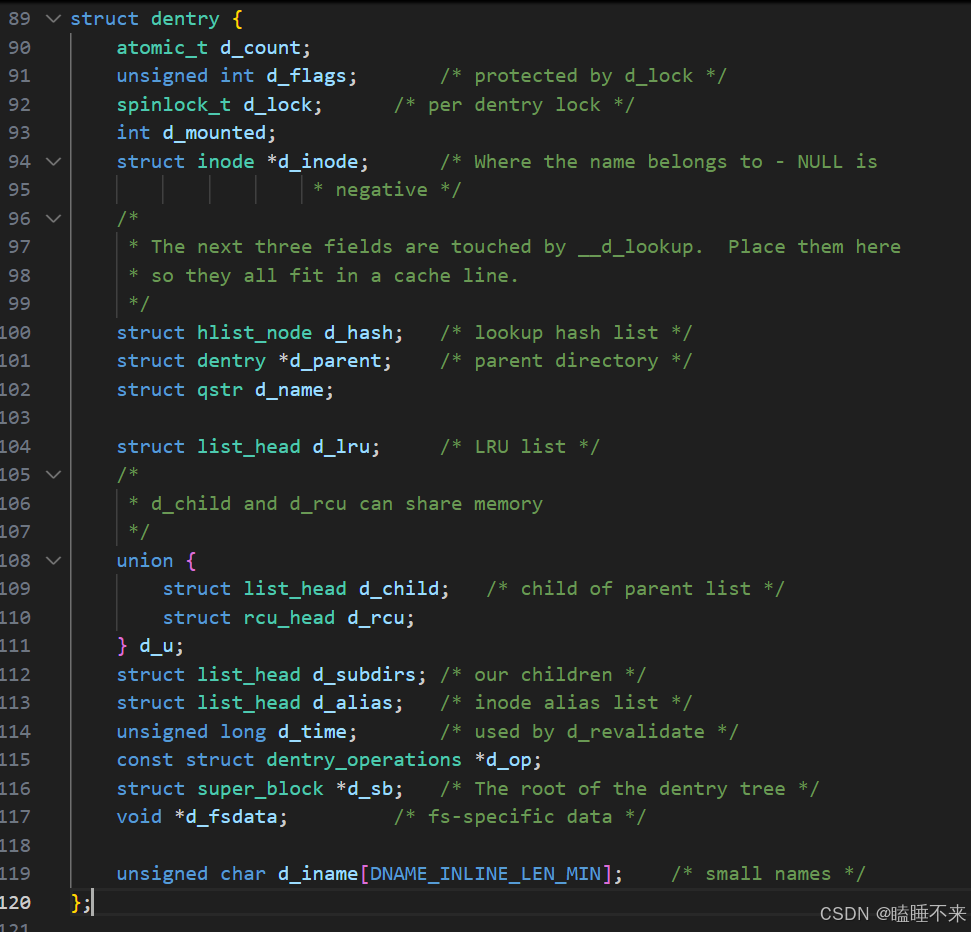
注意:
-
每個文件其實都有對應的 dentry 結構,包括普通文件。這樣所有被打開的文件,就可以在內存中形成整個樹形結構。
-
整個樹形節點也屬于 LRU(Least Recently Used) 結構中,進行節點淘汰。
-
整個樹形節點也會隸屬于 Hash,方便快速查找。
-
更重要的是,這個樹形結構整體構成了 Linux 的路徑緩存結構,訪問任何文件都需要先在這棵樹下根據路徑進行查找,找到就返回屬性 inode 和 內容,沒找到就從磁盤加載路徑,添加 dentry 結構到內存中,緩存新路徑。
文件的 ACM 時間戳屬性
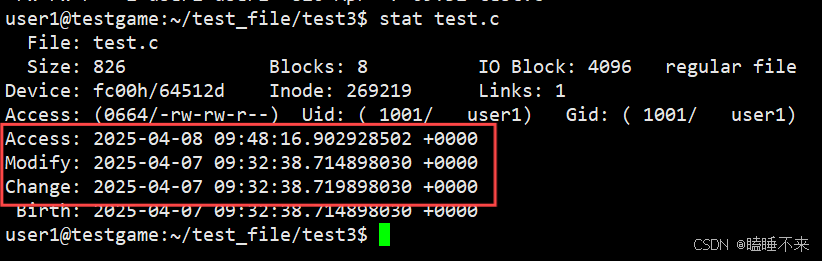
下面解釋一下文件的三個時間:
- Access :最后一次訪問文件內容的時間
- Modify :文件內容最后一次修改的時間
- Change 文件內容(如權限、所有者)最后一次修改的時間
掛載分區
我們已經能夠根據 inode 號在指定分區找文件,也已經能根據目錄文件內容,找指定的 inode,在指定的分區內,我們可以準確查找到目標文件。
可是 inode 不能跨分區,而 Linux 有多個分區,尋找文件的 inode 時怎么知道用戶本身在哪一個分區呢?
-
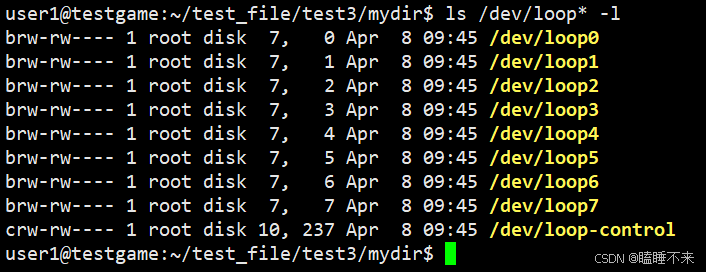
事實上,在 Linux 系統中的
/dev/loop0代表第一個循環設備(loop device)。 -
而循環設備也被稱為回環設備或者 loopback 設備,是一種偽設備(pseudo-device),它允許將文件作為塊設備(block device)來使用。
-
這種機制可以將文件(比如 ISO 鏡像文件)掛載(mount)為文件系統,就像它們是物理硬盤分區或者外部存儲設備一樣。
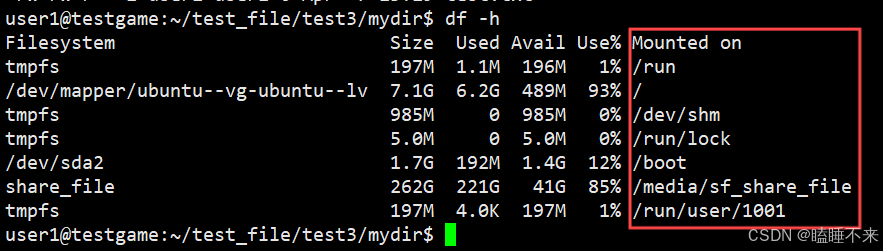
綜上:
-
分區寫入文件系統時,無法直接使用,需要和指定的目錄關聯,進行掛載才能使用。
-
所以可以根據訪問目標文件的 " 路徑前綴 " 準確判斷用戶在哪一個分區。
軟硬鏈接
創建軟硬鏈接可以使用 ln 命令,這里先簡單介紹這個命令。
創建文件鏈接命令 ln
語法:ln [選項] [源文件] [目標文件]
功能:創建文件鏈接
常用選項:
- -s :創建軟鏈接(默認是硬鏈接)
- -f :強制覆蓋已存在的目標文件
- -i :覆蓋前提示確認
- -v :顯示詳細操作信息
- -n :將軟鏈接視為普通文件(避免遞歸鏈接目錄)
硬鏈接
上部分我們知道真正找到磁盤上文件的并不是文件名,而是 inode。其實在 Linux 中可以讓多個文件名對應于同一個 inode。
使用 ln [源文件] [目標文件] 命令可以創建硬鏈接:
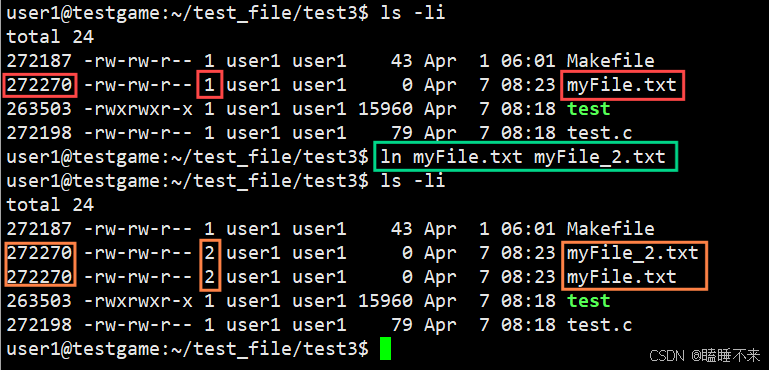
myFile.txt 和 myFile.txt 的鏈接狀態完全相同,他們被稱為指向文件的硬鏈接。內核記錄了這個鏈接數,可以看到兩者的 inode 相同且硬鏈接數為 2。
事實上,我們在刪除文件時干了兩件事情:
- 在目錄中將對應的記錄刪除
- 將硬鏈接數 -1,如果為 0,則將對應磁盤相關 Bitmap 標記為 0,即刪除文件內容。
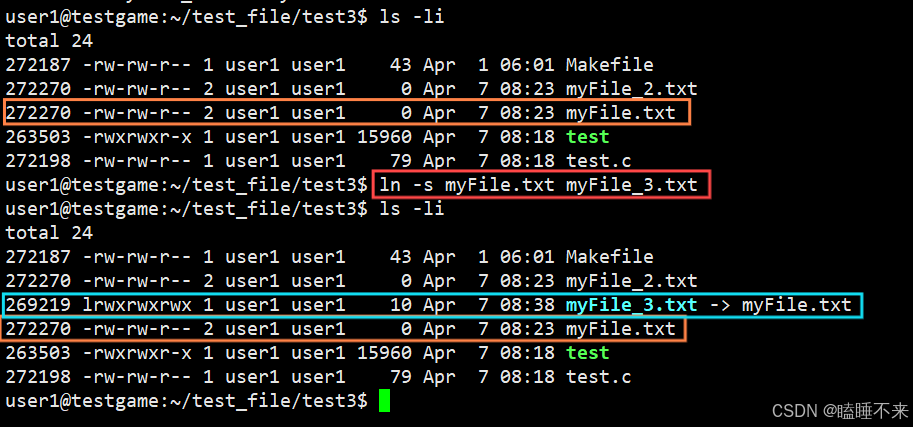
軟鏈接
硬鏈接是通過 inode 引用另外一個文件,而軟鏈接是通過路徑名稱引用另外一個文件。但新的文件和被引用的文件的 inode 不同,這算是一個快捷方式。
Windows 中桌面圖標就是使用軟鏈接的方式,并且將圖標 " 卸載 ",只是將軟鏈接刪掉而已,應用本身還存在于文件系統中,通過尋找對應的 .exe 后綴還可以點擊運行的。
使用命令 ln -s [源文件] [目標文件] 可以創建軟鏈接:
軟硬鏈接對比與其用途
對比:
硬鏈接:
- 硬鏈接不是一個獨立的文件,只是文件名和目標文件 inode 的映射關系。
- 硬鏈接與目標文件共享相同的 inode,刪除目標文件后硬鏈接仍能訪問數據。
- 硬鏈接不能跨文件系統(分區)。
- 不能對目錄創建硬鏈接。
- 硬鏈接和目標文件完全平等,修改其中任一文件會影響其它所有文件。
軟鏈接:
-
軟鏈接是獨立文件,因為它有獨立的 inode 號。
-
軟鏈接可以跨文件系統。
-
可以對目錄創建軟鏈接。
-
刪除源文件后,軟鏈接會失效,成為 " 懸空鏈接 " 。
用途:
硬鏈接:
- Linux 文件中的
.和..就是硬鏈接 - 可以用于文件備份
軟鏈接:
- 類似快捷方式
硬鏈接與路徑環問題
我們注意到,用戶不可以對目錄使用硬鏈接:
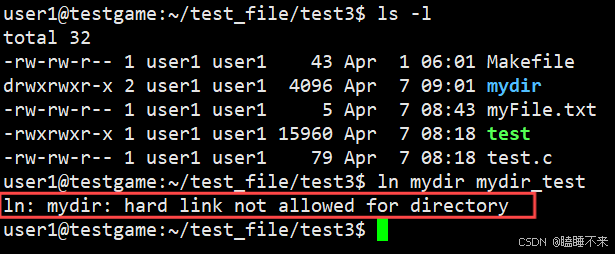
這是因為用戶可能將上級目錄硬鏈接到當前目錄,造成路徑環問題。而有些命令與工具需要遍歷 Linux 的樹狀目錄結構(如 find、tree 等命令),為了安全的考量,Linux 不允許用戶對目錄硬鏈接。
而軟鏈接本身的文件類型被重新劃分為 l 文件類型,遍歷針對 d 類型文件(即目錄),并不會涉及軟鏈接的目錄。
我們注意到 Linux 中的 . 和 .. 本身就是對目錄的硬鏈接,但兩者是由 Linux 自己創建的,其作用是方便命令行操作。本身名字特殊,遍歷 Linux 樹狀目錄結構只需特殊處理即可(例如本文章的 ext2 文件系統 - 目錄與文件名 當中的演示代碼處理)。














)




