推薦算法工程師面試題
- 二分類的分類損失函數?
????二分類的分類損失函數一般采用交叉熵(Cross Entropy)損失函數,即CE損失函數。二分類問題的CE損失函數可以寫成: 其中,y是真實標簽,p是預測標簽,取值為0或1。
其中,y是真實標簽,p是預測標簽,取值為0或1。
- 多分類的分類損失函數(Softmax)?
????多分類的分類損失函數采用Softmax交叉熵(Softmax Cross Entropy)損失函數。Softmax函數可以將輸出值歸一化為概率分布,用于多分類問題的輸出層。Softmax交叉熵損失函數可以寫成: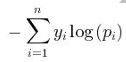 ,其中,n是類別數,yi是第i類的真實標簽,pi是第i類的預測概率。
,其中,n是類別數,yi是第i類的真實標簽,pi是第i類的預測概率。
- 關于梯度下降的sgdm,adagrad,介紹一下。
- SGD(Stochastic Gradient Descent)是最基礎的梯度下降算法,每次迭代隨機選取一個樣本計算梯度并更新模型參數
- SGDM(Stochastic Gradient Descent withMomentum)在SGD的基礎上增加了動量項,可以加速收斂
- Adagrad(AdaptiveGradient)是一種自適應學習率的梯度下降算法,它根據每個參數的梯度歷史信息調整學習率,可以更好地適應不同參數的變化范圍。
- 為什么不用MSE分類用交叉熵?
????MSE(Mean Squared Error)損失函數對離群點敏感,而交叉嫡(CrossEntropy)損失函數在分類問題中表現更好,因為它能更好地刻畫分類任務中標簽概率分布與模型輸出概率分布之間的差異。
- yolov5相比于之前增加的特性有哪些?
????YOLOv5相比于之前版本增加了一些特性,包括:使用CSP(Cross StagePartial)架構加速模型訓練和推理;采用Swish激活函數代替ReLU;引入多尺度訓l練和測試,以提高目標檢測的精度和召回率;引入AutoML技術,自動調整超參數以優化模型性能。
- 可以介紹一下attention機制嗎?
????Attention機制是一種用于序列建模的技術,它可以自適應地對序列中的不同部分賦予不同的權重,以實現更好的特征表示。在Attention機制中,通過計算查詢向量與一組鍵值對之間的相似度,來確定每個鍵值對的權重,最終通過加權平均的方式得到Attention向量.
- 關于attention機制,三個矩陣KQ,KV,K.的作用是什么?
????在Attention機制中,KQV是一組與序列中每個元素對應的三個矩陣,其中K和V分別代表鍵和值,用于計算對應元素的權重,Q代表查詢向量,用于確定權重分配的方式。三個矩陣K、Q、V在Attention機制中的具體作用如下:
- K(Key)矩陣:K矩陣用于計算每個元素的權重,是一個與輸入序列相同大小的矩陣。通過計算查詢向量Q與每個元素的相似度,確定每個元素在加權平均中所占的5比例。
- Q(Query)向量:Q向量是用來確定權重分配方式的向量,與輸入序列中的每個元素都有一個對應的相似度,可以看作是一個加權的向量。
- V(Value)矩陣:V矩陣是與輸入序列相同大小的矩陣,用于給每個元素賦予一個對應的特征向量。在Attention機制中,加權平均后的向量就是V矩陣的加權平均向量。
????通過K、Q、V三個矩陣的計算,Attention機制可以自適應地為輸入序列中的每個元素分配一個權重,以實現更好的特征表示。
- 介紹一下文本檢測EAST。
????EAST(Efficient and Accurate Scene Text)是一種用于文本檢測的神經網絡模型。EAST通過以文本行為單位直接預測文本的位置、方向和尺度,避免了傳統方法中需要多次檢測和合并的過程,從而提高了文本檢測的速度和精度。EAST采用了一種新的訓練方式,即以真實文本行作為訓練樣本,以減少模型對背景噪聲的干擾,并在測試階段通過非極大值抑制(NMS)算法進行文本框的合并。
- 編程題(講思路):給定兩個字符串s,在$字符串中找到包含t字符串的最小字串。
????給定兩個字符串s、t,可以采用滑動窗口的方式在s中找到包含t的最小子串。具體做法如下:
- 定義兩個指針left和right,分別指向滑動窗口的左右邊界。
- 先移動ight指針,擴展滑動窗口,直到包含了t中的所有字符。
- 移動left指針,縮小滑動窗口,直到無法再包含t中的所有字符。
- 記錄當前滑動窗口的長度,如果小于之前記錄的長度,則更新最小長度和最小子串。
- 重復(2)到(4)步驟,直到ight指針到達s的末尾為止。
算法工程師暑期實習面試題
- 如何理解交叉熵的物理意義
????交叉熵是一種用于比較兩個概率分布之間的差異的指標。在機器學習中,它通常用于比較真實標簽分布與模型預測分布之間的差異。
- 過擬合如何去解決?
????L1正則為什么能夠使得參數稀疏,從求導的角度闡述。過擬合的解決方法有很多:數據的角度:獲取和使用更多的數據(數據集增強)模型角度:降低模型復雜度、L1L2 Dropout正則化、Early stopping(提前終止)
????模型融合的角度:使用bagging等模型融合方法。L1正則化在損失函數中加入參數的絕對值之和,可以使得一些參數變得非常小或者為零,從而使得模型更加稀疏,減少過擬合的風險。從求導的角度來看:L1正則化添加了個與模型參數絕對值成正比的項到損失函數中,即λ|w|,λ是正則化系數,w是模型參數。進行求導,可以得到: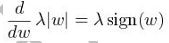 其中sign()是符號函數。這個導數是常數,不像L2正則化的導數那樣與參數的大小成正比。
其中sign()是符號函數。這個導數是常數,不像L2正則化的導數那樣與參數的大小成正比。
????當使用梯度下降進行優化時,L1正則化會持續地從權重中減去一個恒定的值(取決于其符號),導致許多權重減少到零。而L2正則化會持續地從權重中減去一個與權重大小成正比的值,這不太可能導致權重完全達到零。因此,L1正則化傾向于產生稀疏的權重向量,其中大多數權重為零,而L2正則化則更可能使所有權重都接近于零但不完全為零。
- 類別不平衡是如何去處理的?如果進行采樣,策略是什么?
????類別不平衡可以通過對數據進行采樣來處理。一種常用的采樣策略是欠采樣,即隨機從多數類中選擇一部分樣本使得樣本平衡。另一種常用的采樣策略是過采樣,即從少數類中復制一些樣本使得樣本平衡。還有一種策略是生成新的少數類樣本,比如SMOTE算法,其中通過對少數類樣本進行隨機插值來生成新的樣本。
- 介紹一下attention,做過哪些嘗試和改進。
????Attention是一種機器學習中的技術,主要用于提取輸入序列中的關鍵信息。在自然語言處理和圖像處理中,Attention機制已經成為了重要的技術。對于Attention的一些實現方法和改進,一種常見的Attention實現方法是Soft Attention,它可以用于提取序列數據中的重要信息。另外,還有些改進方法,比如Muti-Head Attention和Self-Attention等,可以進一步提高Attention的性能。
- 對于一個時間順序的推薦數據,如何劃分訓練集和驗證集,能不能隨機?
????對于時間順序的推薦數據,通常可以使用時間軸來劃分訓練集和驗證集。具體地,可以選取一段時間作為訓練集,另一段時間作為驗證集。如果數據量足夠大,也可以將數據隨機劃分為訓練集和驗證集。但是,需要注意的是,在時間序列數據中,訓練集和驗證集應該按照時間順序進行劃分,以保證模型的泛化能力。
- 欠擬合如何去解決,訓練過程不收斂如何去解決?
????欠擬合的解決方法有很多,其中一個是增加模型的復雜度。可以增加模型的參數數量、增加網絡層數、使用更復雜的模型結構等來提高模型的擬合能力。另外,還可以嘗試調整學習率、修改損失函數、增加訓練數據等方法。如果訓練過程不收斂,可能是學習率過大或者網絡結構不合理導致的。可以嘗試減小學習率、使用不同的優化器、增加網絡層數等方法來解決這個問題。
- 正則化和最大似然的關系。
????正則化和最大似然有一定的關系。最大似然是一種用于估計模型參數的方法,其目標是找到使得觀測數據出現的概率最大的模型參數。正則化是一種對模型參數進行限制的方法,可以使得模型參數更加穩定和泛化能力更強。在最大似然估計中,通過添加正則化項可以達到類似的目的,即防止模型過擬合。常見的正則化方法包括L1正則化和L2正則化。
- Leetcode:數組中第K大的元素。
????難度:【中等】三種思路:一種是直接使用sorted函數進行排序,一種是使用小頂堆,一種是使用快排(雙指針+分治)。
- 方法一:直接使用sorted函數進行排序代碼如下:
class Solution:def findKthLargest(self,nums:List[int],k:int)->int:return sorted(nums,reverse =True)[k-1]
- 方法二:使用堆XX維護一個size為k的小頂堆,把每個數丟進去,如果堆的size>k,就把堆頂pop掉(因為它是最小的),這樣可以保證堆頂元素一定是第k大的數。代碼如下:
class Solution:def findKthLargest(self,nums:List[int],k:int)->int:heap = []for num in nums:heappush(heap,num)if len(heap)>k:heappop(heap)return heap[0]
????時間復雜度:O(nlogk)空間復雜度:O(k)
- 方法三:雙指針+分治partition部分定義兩個指針left和right,還要指定一個中心pivot(這里直接取最左邊的元素為中心,即nums[i])不斷將兩個指針向中間移動,使得大于pivot的元素都在pivot的右邊,小于pivot的元素都在pivot的左邊,注意最后滿足時,left是和right相等的,因此需要將pivot賦給此時的let或right。.然后再將中心點的索引和k-1進行比較,通過不斷更新let和right找到最終的第k個位置。代碼如下:
class Solution:def findKthLargest(self,nums:List[int],k:int)->int:left,right,target =0,len(nums)-1,k-1while True:pos=self.partition(nums,left,right)if pos ==target:return nums[pos]elif pos>target:right=pos-1else:left = pos + 1def partition(self,nums,left,right):pivot=nums[left]while left right:while nums[right]<=pivot and left<right:right-=1nums[left]=nums[right]while nums[left]>pivot and left<right:left += 1nums[right]nums[left]nums[left] = pivotreturn left
視覺算法工程師面試題
- C++編譯的過程,從源碼到二進制:
????C++源碼經過以下幾個步驟進行編譯,從源碼轉換為可執行的二進制文件:
- 預處理(Preprocessing):預處理器根據源碼中的預處理指令,如# include、define等,對源碼進行文本替換、宏展開等處理。
- 編譯(Compilation):編譯器將預處理后的源碼轉換為匯編語言代碼,也稱為匯編源碼。
- 匯編(Assembly):匯編器將匯編語言代碼轉換為機器語言指令,生成目標文件(通常為二進制文件)。
- 鏈接(Linking):鏈接器將目標文件與系統庫、用戶自定義的庫進行鏈接,生成可執行文件。鏈接器將目標文件中的符號(如函數、變量等)與其對應的定義進行匹配,解析符號的引用關系,生成最終的可執行文件。
- 加載(Loading):操作系統將可執行文件加載到內存中,并將程序的控制權轉交給程序的入口點,從而開始執行程序。
- C++最小的編譯單元:
????C++中最小的編譯單元是函數。函數在編譯時被編譯器獨立地編譯成目標文件,然后通過鏈接器將目標文件與其他目標文件或庫文件鏈接成最終的可執行文件。
- C+靜態庫和動態庫的區別:
????靜態庫(Static Library)在鏈接時會被完整地復制到可執行文件中,程序運行時不需要外部的庫文件支持。而動態庫(Dynamic Library)在鏈接時并不會被復制到可執行文件中,而是在程序運行時由操作系統動態加載到內存中并共享使用。因此,靜態庫會增加可執行文件的大小,而動態庫可以在多個可執行文件之間共享,減小了可執行文件的大小。
- 說一下C+中的share_ptr
????share_ptr是C++11引入的智能指針,用于管理動態分配的對象的所有權。它使用引用計數的方式來自動釋放資源,避免了內存泄漏。share_ptr允許多個share_ptr對象共享同一個對象,當最后一個指向對象的share_ptr被銷毀時,它會自動釋放資源。
- C++中new和make_shared創建出來的差異點
- new和make_shared都用于在堆上分配動態內存并創建對象。其中,new是C++中的關鍵字,返回的是裸指針,需要手動管理內存釋放:而make_shared是C++11引入的函數模板,返回的是一個shared_ptr對象,使用引用計數管理內存,無需手動釋放
差異點:
- make_shared通常比new效率更高,因為它在一次內存分配中同時分配了對象和控制塊(用于管理引用計數),減少了內存分配的次數,提高了性能。
- make_shared可以避免潛在的內存泄漏,因為它將對象和引用計數塊一同存儲在連續的內存塊中,確保了對象和引用計數塊的一致性,避免了因為異常導致的資源泄漏。
- 使用shared_ptr時,建議優先使用make_shared,因為它更加安全和高效,能夠減少內存分配次數,提高性能。
- C++中左值和右值的概念:
- 左值(Lvalue)是指具有持久性、可以被命名的表達式或對象,它們具有內存地址。左值可以出現在賦值、取址、函數調用等操作中,并且可以被修改。
- 右值(Rvalue)是指臨時的、沒有持久性的表達式或對象,它們不能被命名,通常用于初始化或者臨時計算。右值不能出現在賦值的左側,但可以出現在賦值的右側,并且可以被移動或者轉移所有權。
- C++11引入了右值引用(Rvalue reference),通過&&表示,用于標識對右值的引用,右值引用可以用于實現移動語義和完美轉發(perfect forwarding),提高了性能和靈活性。
- C++中的STL(Standard Template Library)里面有以下常用的容器:
- vector:動態數組,支持隨機訪問.
- list:雙向鏈表,支持快速插入和刪除。
- deque:雙端隊列,支持隨機訪問。
- queue:隊列,先進先出(FIFO)。
- stack:棧,后進先出(LIFO)。
- set:集合,自動排序且元素唯一。
- map:映射,鍵值對容器,自動排序且鍵唯一。
- unordered_set:無序集合,哈希實現,元素唯一。
- unordered_map:無序映射,鍵值對容器,哈希實現。
8、C++中map和unordered_map的區別:
- 排序:map中的鍵值對默認按照鍵的大小進行排序,而unordered_map沒有固定的排序,是無序的。
- 實現:map通常使用紅黑樹(平衡二叉搜索樹)實現,而unordered_map使用哈希表實現。
- 性能:unordered_map在插入刪除和查找操作上通常具有更好的平均性能,因為哈希表具有較快的查找和插入速度,而map則對鍵進行排序可能會導致性能略低。
- 內存占用:unordered_map通常占用更多的內存,因為哈希表需要額外的存儲空間來存儲哈希函數和桶(bucket)的信息,而map使用紅黑樹存儲,不需要額外的存儲空間。
- 查找效率:在大數據量的情況下,unordered_map通常比map更快,因為哈希表具有O(1)的平均查找復雜度,而紅黑樹具有OogN)的平均查找復雜度。
- 迭代順序:mp中的元素按照鍵的大小進行排序,可以通過迭代器按照順序訪問,而unordered_map中的元素沒有固定的順序。
- 適用場景:map適用于需要按照鍵的大小進行排序或者需要有序訪問的場景,而unordered_map適用于不需要排序或者對訪問順序無要求的場景,且在性能要求較高的情況下可以考慮使用unordered_map

)


安裝步驟)


——client子窗口功能)
-張量拼接操作)
)









