文章:ECIR 2025會議
一、動機
背景:利用LLMs強大的能力,將一個查詢(query)和一組候選段落作為輸入,整體考慮這些段落的相關性,并對它們進行排序。
先前的研究基礎上進行擴展 [14,15],這些研究使用 RankGPT 作為教師模型,將排序結果蒸餾到 listwise 學生重排序模型中。其中一個代表性模型是 RankZephyr [15],它在排序效果上縮小了與 GPT-4 的差距,甚至在某些情況下超過了這個閉源的教師模型。
大型語言模型(LLMs)推動了listwise重排序研究的發展,并取得了令人印象深刻的最先進成果。然而,這些模型龐大的參數數量和有限的上下文長度限制了其在重排序任務中的效率。
二、解決方法
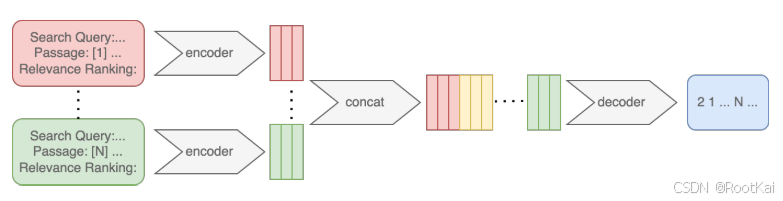
LiT5模型架構:
?
模型遵循 FiD 架構,編碼器會將每個段落與查詢(query)逐對分別編碼。對于每個查詢–段落對,輸入提示(prompt)的格式如下:
-
以 Search Query: 開頭,接著是查詢內容;
-
然后是 Passage:,后面帶有一個唯一的編號(例如 [1]、[2]);
-
最后是該段落的文本;
-
提示的結尾是 Relevance Ranking:,用于引導模型生成排序結果。
解碼器隨后會對所有段落的編碼表示進行處理,根據與查詢的相關性,生成一個按編號排序的結果(從最相關到最不相關),例如:“3 1 2 ...”。
LiT5 模型的設計和創新,它通過采用 RankZephyr 作為教師模型,利用 FiD 架構 和 蒸餾技術,有效地訓練了一個能夠處理更多段落(最多100個段落)的高效排序模型,突破了傳統模型在處理段落數量上的限制,并且能夠節省計算成本。
三、訓練模型
數據集:
?MS MARCO v1 passage ranking 數據集中隨機抽取了 20K 個查詢,對于每個查詢,我們從 MS MARCO v1 和 v2 數據集中各自檢索了 100 個段落。
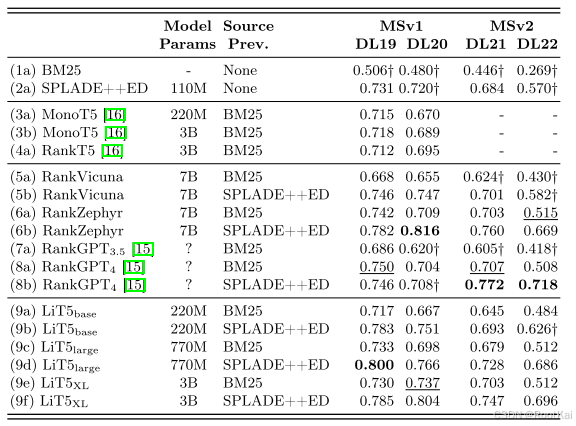
實驗結果:

:一種輕量化的動態稀疏門控網絡)





)





![MySQL基礎 [五] - 表的增刪查改](http://pic.xiahunao.cn/MySQL基礎 [五] - 表的增刪查改)
和Foreign Key(外鍵))


(藍橋杯常考點)—數據結構(進階))

