1. MySQL 索引使用有哪些注意事項呢?
可以從三個維度回答這個問題:索引哪些情況會失效,索引不適合哪些場景,索引規則
索引哪些情況會失效
- 查詢條件包含or,可能導致索引失效
- 如何字段類型是字符串,where時一定用引號括起來,否則索引失效
- like通配符可能導致索引失效。
- 聯合索引,查詢時的條件列不是聯合索引中的第一個列,索引失效。
- 在索引列上使用mysql的內置函數,索引失效。
- 對索引列運算(如,+、-、*、/),索引失效。
- 索引字段上使用(!= 或者 < >,not in)時,可能會導致索引失效。
- 索引字段上使用is null, is not null,可能導致索引失效。
- 左連接查詢或者右連接查詢查詢關聯的字段編碼格式不一樣,可能導致索引失效。
- mysql估計使用全表掃描要比使用索引快,則不使用索引。
索引不適合哪些場景
- 數據量少的不適合加索引
- 更新比較頻繁的也不適合加索引
- 區分度低的字段不適合加索引(如性別)
索引的一些潛規則
- 覆蓋索引
- 回表
- 索引數據結構(B+樹)
- 最左前綴原則
- 索引下推
2. MySQL 遇到過死鎖問題嗎,你是如何解決的?
我排查死鎖的一般步驟是醬紫的:
- 查看死鎖日志show engine innodb status;
- 找出死鎖Sql
- 分析sql加鎖情況
- 模擬死鎖案發
- 分析死鎖日志
- 分析死鎖結果
3. 日常工作中你是怎么優化SQL的?
可以從這幾個維度回答這個問題:
- 加索引
- 避免返回不必要的數據
- 適當分批量進行
- 優化sql結構
- 分庫分表
- 讀寫分離
4. 說說分庫與分表的設計
分庫分表方案,分庫分表中間件,分庫分表可能遇到的問題
分庫分表方案:
- 水平分庫:以字段為依據,按照一定策略(hash、range等),將一個庫中的數據拆分到多個庫中。
- 水平分表:以字段為依據,按照一定策略(hash、range等),將一個表中的數據拆分到多個表中。
- 垂直分庫:以表為依據,按照業務歸屬不同,將不同的表拆分到不同的庫中。
- 垂直分表:以字段為依據,按照字段的活躍性,將表中字段拆到不同的表(主表和擴展表)中。
常用的分庫分表中間件:
- sharding-jdbc(當當)
- Mycat
- TDDL(淘寶)
- Oceanus(58同城數據庫中間件)
- vitess(谷歌開發的數據庫中間件)
- Atlas(Qihoo 360)
分庫分表可能遇到的問題
- 事務問題:需要用分布式事務啦
- 跨節點Join的問題:解決這一問題可以分兩次查詢實現
- 跨節點的count,order by,group by以及聚合函數問題:分別在各個節點上得到結果后在應用程序端進行合并。
- 數據遷移,容量規劃,擴容等問題
- ID問題:數據庫被切分后,不能再依賴數據庫自身的主鍵生成機制啦,最簡單可以考慮UUID
- 跨分片的排序分頁問題(后臺加大pagesize處理?)
5. InnoDB與MyISAM的區別
- InnoDB支持事務,MyISAM不支持事務
- InnoDB支持外鍵,MyISAM不支持外鍵
- InnoDB 支持 MVCC(多版本并發控制),MyISAM 不支持
select count(*) from table時,MyISAM更快,因為它有一個變量保存了整個表的總行數,可以直接讀取,InnoDB就需要全表掃描。- Innodb不支持全文索引,而MyISAM支持全文索引(5.7以后的InnoDB也支持全文索引)
- InnoDB支持表、行級鎖,而MyISAM支持表級鎖。
- InnoDB表必須有主鍵,而MyISAM可以沒有主鍵
- Innodb表需要更多的內存和存儲,而MyISAM可被壓縮,存儲空間較小,。
- Innodb按主鍵大小有序插入,MyISAM記錄插入順序是,按記錄插入順序保存。
- InnoDB 存儲引擎提供了具有提交、回滾、崩潰恢復能力的事務安全,與 MyISAM 比 InnoDB 寫的效率差一些,并且會占用更多的磁盤空間以保留數據和索引
- InnoDB 屬于索引組織表,使用共享表空間和多表空間儲存數據。MyISAM用
.frm、.MYD、.MTI來儲存表定義,數據和索引。
6. 數據庫索引的原理,為什么要用 B+樹,為什么不用二叉樹?
可以從幾個維度去看這個問題,查詢是否夠快,效率是否穩定,存儲數據多少,以及查找磁盤次數,為什么不是二叉樹,為什么不是平衡二叉樹,為什么不是B樹,而偏偏是B+樹呢?
為什么不是一般二叉樹?
如果二叉樹特殊化為一個鏈表,相當于全表掃描。平衡二叉樹相比于二叉查找樹來說,查找效率更穩定,總體的查找速度也更快。
為什么不是平衡二叉樹呢?
我們知道,在內存比在磁盤的數據,查詢效率快得多。如果樹這種數據結構作為索引,那我們每查找一次數據就需要從磁盤中讀取一個節點,也就是我們說的一個磁盤塊,但是平衡二叉樹可是每個節點只存儲一個鍵值和數據的,如果是B樹,可以存儲更多的節點數據,樹的高度也會降低,因此讀取磁盤的次數就降下來啦,查詢效率就快啦。
那為什么不是B樹而是B+樹呢?
- 1)B+樹非葉子節點上是不存儲數據的,僅存儲鍵值,而B樹節點中不僅存儲鍵值,也會存儲數據。innodb中頁的默認大小是16KB,如果不存儲數據,那么就會存儲更多的鍵值,相應的樹的階數(節點的子節點樹)就會更大,樹就會更矮更胖,如此一來我們查找數據進行磁盤的IO次數有會再次減少,數據查詢的效率也會更快。
- 2)B+樹索引的所有數據均存儲在葉子節點,而且數據是按照順序排列的,鏈表連著的。那么B+樹使得范圍查找,排序查找,分組查找以及去重查找變得異常簡單。
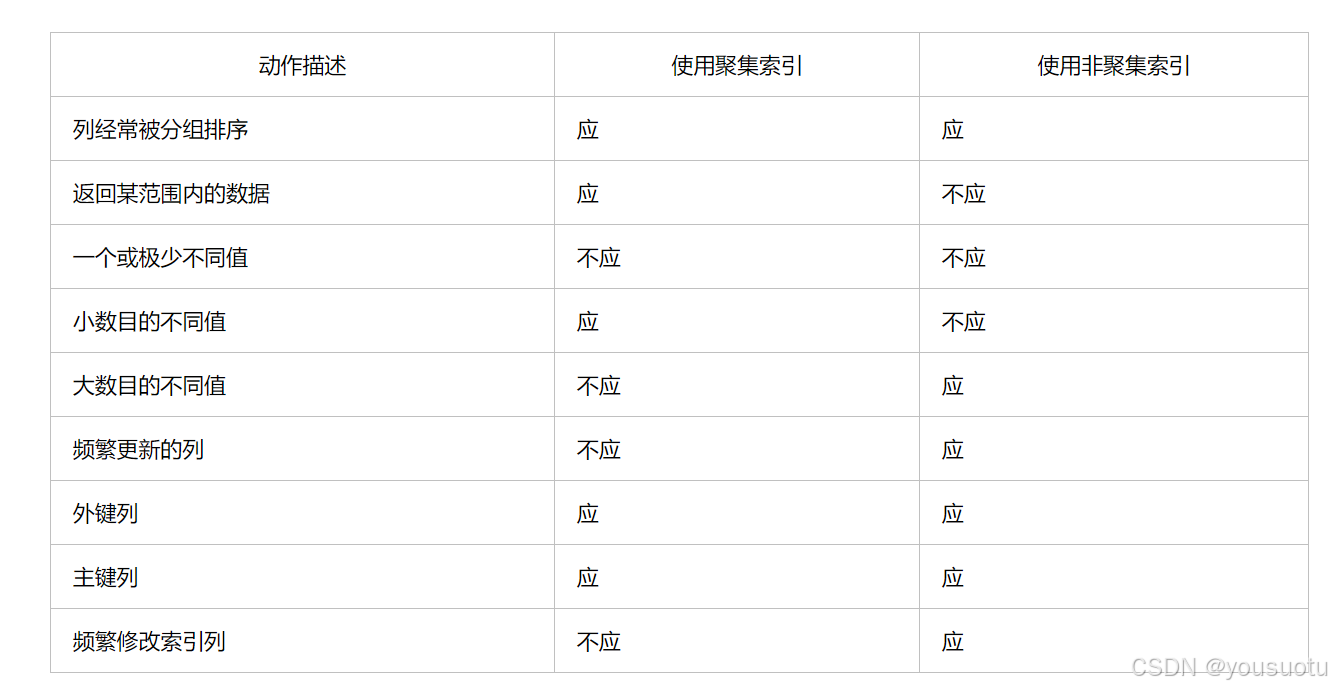
7. 聚集索引與非聚集索引的區別
- 一個表中只能擁有一個聚集索引,而非聚集索引一個表可以存在多個。
- 聚集索引,索引中鍵值的邏輯順序決定了表中相應行的物理順序;非聚集索引,索引中索引的邏輯順序與磁盤上行的物理存儲順序不同。
- 索引是通過二叉樹的數據結構來描述的,我們可以這么理解聚簇索引:索引的葉節點就是數據節點。而非聚簇索引的葉節點仍然是索引節點,只不過有一個指針指向對應的數據塊。
- 聚集索引:物理存儲按照索引排序;非聚集索引:物理存儲不按照索引排序;
何時使用聚集索引或非聚集索引?
8. limit 1000000 加載很慢的話,你是怎么解決的呢?
方案一:如果id是連續的,可以這樣,返回上次查詢的最大記錄(偏移量),再往下limit
select id,name from employee where id>1000000 limit 10.
方案二:在業務允許的情況下限制頁數:
建議跟業務討論,有沒有必要查這么后的分頁啦。因為絕大多數用戶都不會往后翻太多頁。
方案三:order by + 索引(id為索引)
select id,name from employee order by id limit 1000000,10
SELECT a.* FROM employee a, (select id from employee where 條件 LIMIT 1000000,10 ) b where a.id=b.id
方案四:利用延遲關聯或者子查詢優化超多分頁場景。(先快速定位需要獲取的id段,然后再關聯)
9. 如何選擇合適的分布式主鍵方案呢?
- 數據庫自增長序列或字段。
- UUID。
- Redis生成ID
- Twitter的snowflake算法
- 利用zookeeper生成唯一ID
- MongoDB的ObjectId
10. 事務的隔離級別有哪些?MySQL的默認隔離級別是什么?
- 讀未提交(Read Uncommitted)
- 讀已提交(Read Committed)
- 可重復讀(Repeatable Read)
- 串行化(Serializable)
Mysql默認的事務隔離級別是可重復讀(Repeatable Read)
11. 什么是幻讀,臟讀,不可重復讀呢?
- 事務A、B交替執行,事務A被事務B干擾到了,因為事務A讀取到事務B未提交的數據,這就是臟讀
- 在一個事務范圍內,兩個相同的查詢,讀取同一條記錄,卻返回了不同的數據,這就是不可重復讀。
- 事務A查詢一個范圍的結果集,另一個并發事務B往這個范圍中插入/刪除了數據,并靜悄悄地提交,然后事務A再次查詢相同的范圍,兩次讀取得到的結果集不一樣了,這就是幻讀。
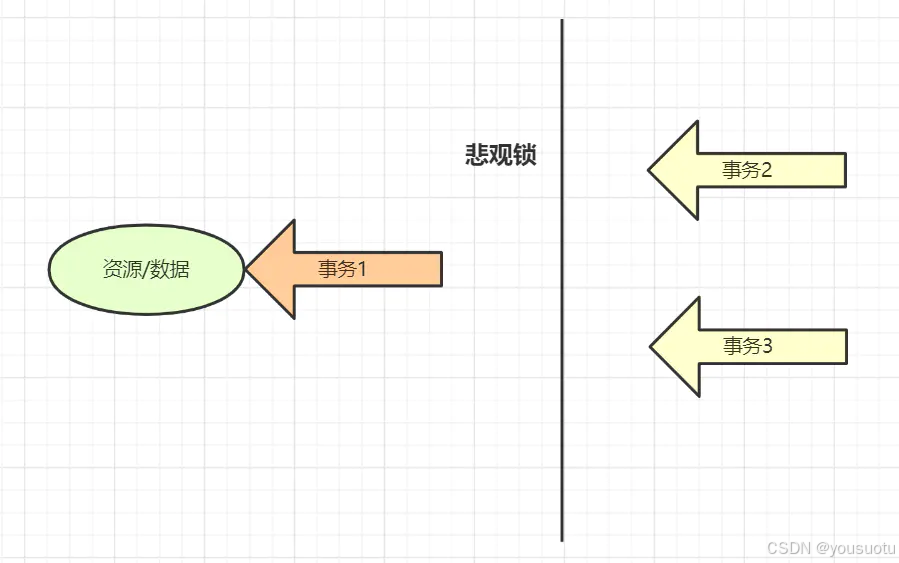
12. 在高并發情況下,如何做到安全的修改同一行數據?
要安全的修改同一行數據,就要保證一個線程在修改時其它線程無法更新這行記錄。一般有悲觀鎖和樂觀鎖兩種方案~
使用悲觀鎖
悲觀鎖思想就是,當前線程要進來修改數據時,別的線程都得拒之門外~
比如,可以使用select…for update ~
select * from User where name=‘jay’ for update
以上這條sql語句會鎖定了User表中所有符合檢索條件(name=‘jay’)的記錄。本次事務提交之前,別的線程都無法修改這些記錄。
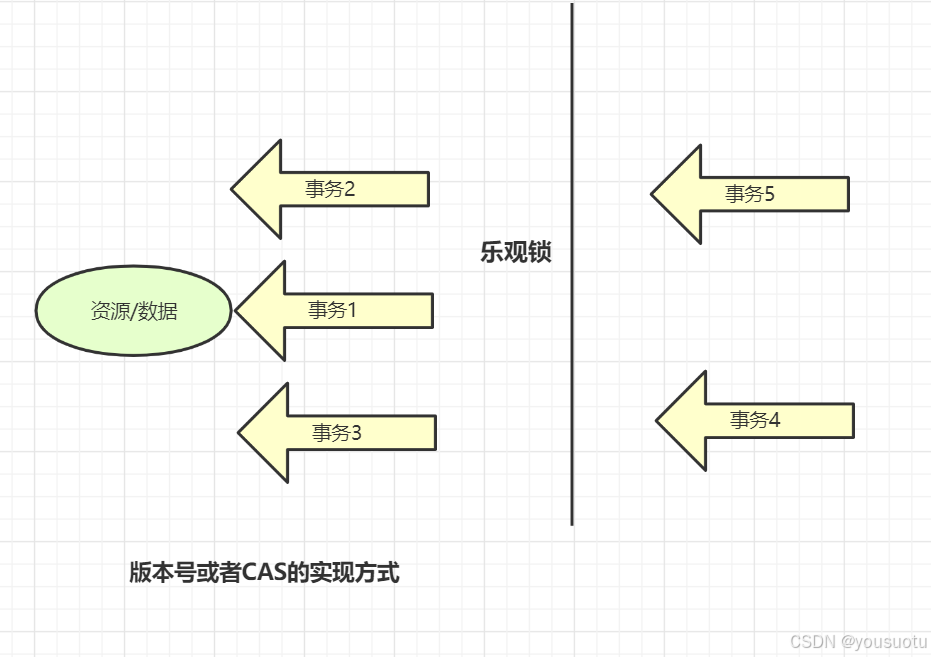
使用樂觀鎖
樂觀鎖思想就是,有線程過來,先放過去修改,如果看到別的線程沒修改過,就可以修改成功,如果別的線程修改過,就修改失敗或者重試。實現方式:樂觀鎖一般會使用版本號機制或CAS算法實現。
13. 數據庫的樂觀鎖和悲觀鎖。
悲觀鎖:
悲觀鎖她專一且缺乏安全感了,她的心只屬于當前事務,每時每刻都擔心著它心愛的數據可能被別的事務修改,所以一個事務擁有(獲得)悲觀鎖后,其他任何事務都不能對數據進行修改啦,只能等待鎖被釋放才可以執行。
樂觀鎖:
樂觀鎖的“樂觀情緒”體現在,它認為數據的變動不會太頻繁。因此,它允許多個事務同時對數據進行變動。實現方式:樂觀鎖一般會使用版本號機制或CAS算法實現。
14. SQL優化的一般步驟是什么,怎么看執行計劃(explain),如何理解其中各個字段的含義。
show status命令了解各種 sql 的執行頻率- 通過慢查詢日志定位那些執行效率較低的 sql 語句
explain分析低效 sql 的執行計劃(這點非常重要,日常開發中用它分析Sql,會大大降低Sql導致的線上事故)
15. select for update有什么含義,會鎖表還是鎖行還是其他。
select for update 含義
select查詢語句是不會加鎖的,但是select for update除了有查詢的作用外,還會加鎖呢,而且它是悲觀鎖哦。至于加了是行鎖還是表鎖,這就要看是不是用了索引/主鍵啦。
沒用索引/主鍵的話就是表鎖,否則就是是行鎖。
16. MySQL事務得四大特性以及實現原理
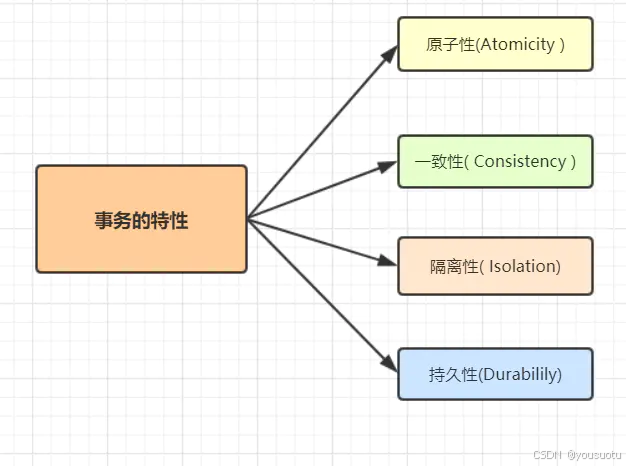
- 原子性: 事務作為一個整體被執行,包含在其中的對數據庫的操作要么全部被執行,要么都不執行。
- 一致性: 指在事務開始之前和事務結束以后,數據不會被破壞,假如A賬戶給B賬戶轉10塊錢,不管成功與否,A和B的總金額是不變的。
- 隔離性: 多個事務并發訪問時,事務之間是相互隔離的,即一個事務不影響其它事務運行效果。簡言之,就是事務之間是進水不犯河水的。
- 持久性: 表示事務完成以后,該事務對數據庫



)





![MySQL基礎 [五] - 表的增刪查改](http://pic.xiahunao.cn/MySQL基礎 [五] - 表的增刪查改)
和Foreign Key(外鍵))


(藍橋杯常考點)—數據結構(進階))





C++版——day7)