前言:
網絡框架的設計離不開 I/O 線程模型,線程模型的優劣直接決定了系統的吞吐量、可擴展性、安全性等。目前主流的網絡框架,在網絡 IO 處理層面幾乎都采用了I/O 多路復用方案(又以epoll為主),這是服務端應對高并發的性能利器。
進一步看,當上升到整個網絡模塊時,另一個常常聽說的模式出現了 ---- 「Reactor 模式」,也叫反應器模式,本質是一個事件轉發器,是網絡模塊核心中樞,負責將讀寫事件分發給對應的讀寫事件處理者,將連接事件交給連接處理者以及業務事件交給業務線程。
1. 前置知識
1.1 io
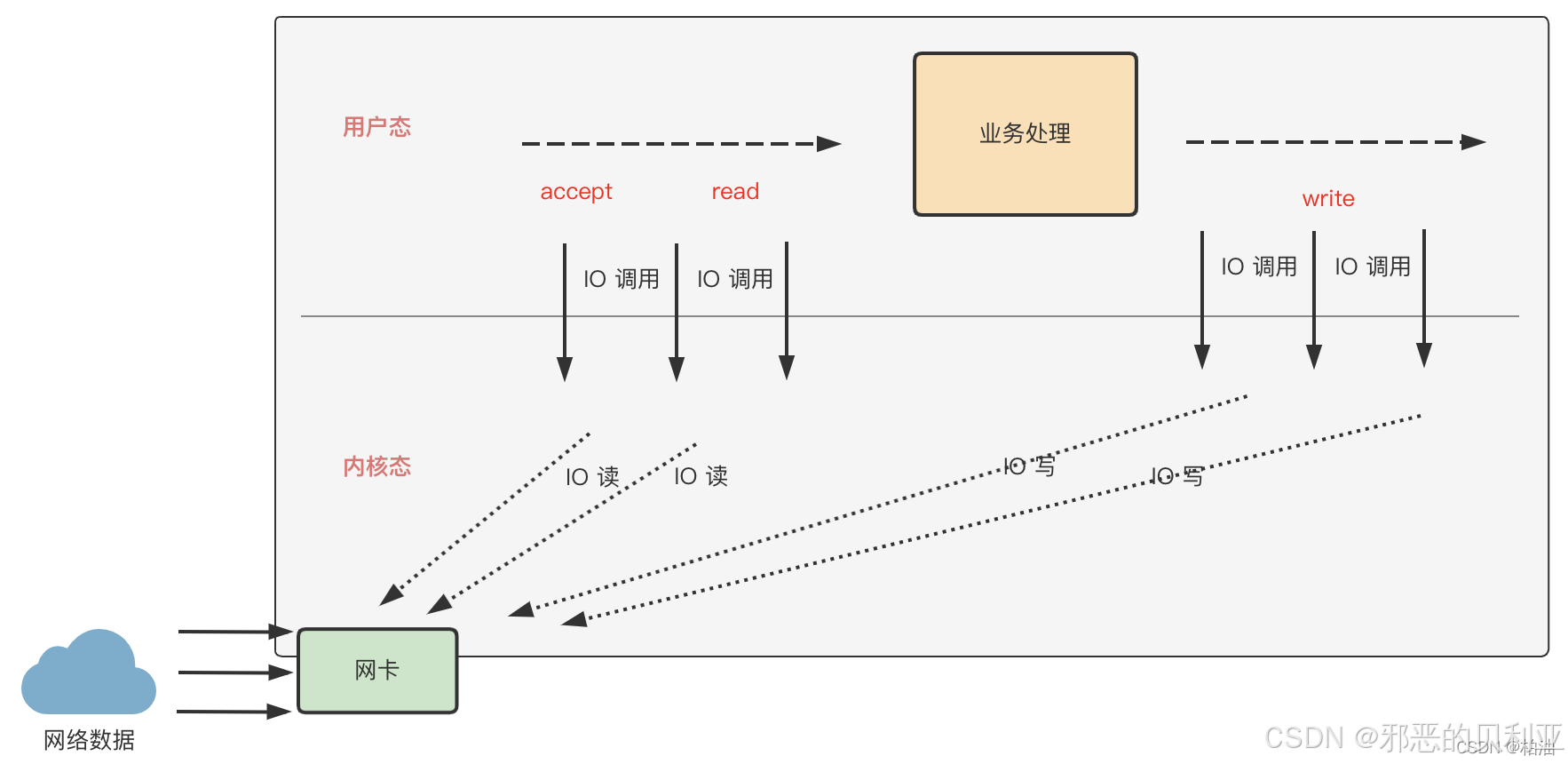
可以看到,網絡請求先后經歷 服務器網卡、內核、連接建立、數據讀取、業務處理、數據寫回等一系列過程。
其中,連接建立(accept)、數據讀取(read)、數據寫回(write)等操作都需要操作系統內核提供的系統調用,最終由內核與網卡進行數據交互,這些 IO 調用消耗一般是比較高的,比如 IO 等待、數據傳輸等。
最初的處理方式是,每個連接都用獨立的一個線程來處理這一系列的操作,即 建立連接、數據讀寫、業務邏輯處理;這樣一來最大的弊端在于,N 個連接就需要 N 個線程資源,消耗巨大。
所以,在網絡模型演化過程中,不斷的對這幾個階段進行拆分,比如,將建立連接、數據讀寫、業務邏輯處理等關鍵階段分開處理。這樣一來,每個階段都可以考慮使用單線程或者線程池來處理,極大的節約線程資源,又能獲得超高性能。
1.1.1 阻塞IO
阻塞IO:通常是用戶態線程通過系統調用阻塞讀取網卡傳遞的數據,我們知道,在 TCP 三次握手建立連接之后,真正等待數據的到來需要一定時間;
這個時候,在該模式下用戶線程會一直阻塞等待網卡數據準備就緒,直到完成數據讀寫完成;可以看到,用戶線程大部分都在等待 IO 事件就緒,造成資源的急劇浪費

1.1.2 非阻塞IO
與阻塞 IO 相反,如果數據未就緒會直接返回,應用層輪詢讀取/查詢,直到成功讀取數據。

這里最后一次 read 調用,獲取數據的過程,是一個同步的過程,是需要等待的過程。這里的同步指的是內核態的數據拷貝到用戶程序的緩存區這個過程。
epoll: 是非阻塞IO的一種特例,也是目前最經典、最常用的高性能IO模型。其具體處理方式是:先查詢 IO 事件是否準備就緒,當 IO 事件準備就緒了,則會真正的通過系統調用實現數據讀寫;
,無論 read 和 send 是阻塞 I/O,還是非阻塞 I/O 都是同步調用。因為在 read 調用時,內核將數據從內核空間拷貝到用戶空間的過程都是需要等待的,也就是說這個過程是同步的,如果內核實現的拷貝效率不高,read 調用就會在這個同步過程中等待比較長的時間
1.1.3 異步IO

- 阻塞 I/O 好比,你去飯堂吃飯,但是飯堂的菜還沒做好,然后你就一直在那里等啊等,等了好長一段時間終于等到飯堂阿姨把菜端了出來(數據準備的過程),但是你還得繼續等阿姨把菜(內核空間)打到你的飯盒里(用戶空間),經歷完這兩個過程,你才可以離開。
- 非阻塞 I/O 好比,你去了飯堂,問阿姨菜做好了沒有,阿姨告訴你沒,你就離開了,過幾十分鐘,你又來飯堂問阿姨,阿姨說做好了,于是阿姨幫你把菜打到你的飯盒里,這個過程你是得等待的。
- 異步 I/O 好比,你讓飯堂阿姨將菜做好并把菜打到飯盒里后,把飯盒送到你面前,整個過程你都不需要任何等待。
1.2 事件驅動
前面我們提到:將一個正常的請求分成多段來看待,每一段都可以分別進行優化(看場景需要)
經典的一種切分方法是將「連接」和「業務線程」分開處理,當「連接層」有事件觸發時提交給「業務線程」,避免了業務線程因「網絡數據處于準備中」導致的長時間等待問題,節省線程資源,這就是大名鼎鼎的事件驅動模型。
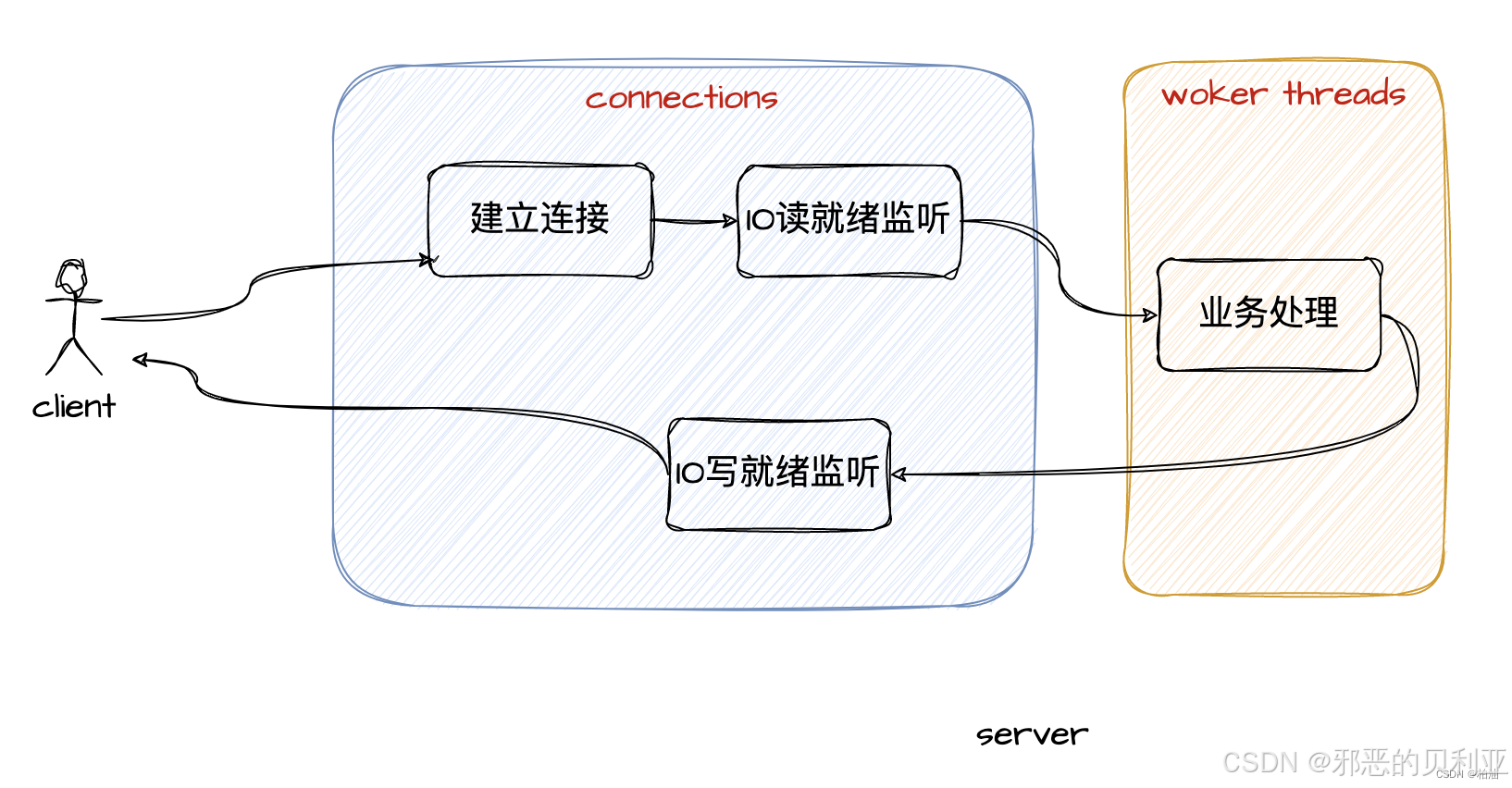
事件驅動的核心是,以事件為連接點,當有IO事件準備就緒時,以事件的形式通知相關線程進行數據讀寫,進而業務線程可以直接處理這些數據,這一過程的后續操作方,都是被動接收通知,看起來有點像回調操作;
這種模式下,IO 讀寫線程、業務線程工作時,必有數據可操作執行,不會在 IO 等待上浪費資源,這便是事件驅動的核心思想。
2 Reactor 模型(同步非阻塞io)
Reactor 翻譯過來的意思是「反應堆」,可能大家會聯想到物理學里的核反應堆,實際上并不是的這個意思。這里的反應指的是「對事件反應」,也就是來了一個事件,Reactor 就有相對應的反應/響應。
事實上,Reactor 模式也叫 Dispatcher 模式,我覺得這個名字更貼合該模式的含義,即 I/O 多路復用監聽事件,收到事件后,根據事件類型分配(Dispatch)給某個進程 / 線程。
Reactor 模式主要由 Reactor 和處理資源池這兩個核心部分組成,它倆負責的事情如下:
- Reactor 負責監聽和分發事件(主進程或者線程)
- 事件類型包含連接事件、讀寫事件;處理資源池負責處理事件,如 read -> 業務邏輯 -> send;(工作者進程或線程)
Reactor 模式是靈活多變的,可以應對不同的業務場景,靈活在于:
- Reactor 的數量可以只有一個,也可以有多個;
- 處理資源池可以是單個進程 / 線程,也可以是多個進程 /線程;
根據以上情況就有以下分類 :(多Reactor 單進程 / 線程)無明顯優勢;
reactor模型主要分類
- 單 Reactor 單進程 / 線程;(Redis)
- 單 Reactor 多線程 / 進程; Muduo
- 多 Reactor 多進程 / 線程;( Nginx)
2.1 單 Reactor 單進程 / 線程

可以看到進程(應用程序)里有 Reactor、Acceptor、Handler 這三個對象:
- Reactor 對象的作用是監聽和分發事件;(主)
- Acceptor 對象的作用是獲取連接;
- Handler 對象的作用是處理業務;
接下來,介紹下「單 Reactor 單進程」這個方案:
- Reactor 對象通過 epoll (IO 多路復用接口) 監聽事件,收到事件后通過 dispatch 進行分發,
- 具體分發給 Acceptor 對象還是 Handler 對象,還要看收到的事件類型;如果是連接建立的事件,則交由 Acceptor 對象進行處理,Acceptor 對象會通過 accept 方法 獲取連接,并創建一個 Handler 對象來處理后續的響應事件;
- 如果不是連接建立事件, 則交由當前連接對應的 Handler 對象來進行響應;Handler 對象通過 read -> 業務處理 -> send 的流程來完成完整的。(回調事件)
優點
單 Reactor 單進程的方案因為全部工作都在同一個進程內完成,所以實現起來比較簡單,不需要考慮進程間通信,也不用擔心多進程競爭。
缺點
- 第一個缺點,因為只有一個進程,無法充分利用 多核 CPU 的性能;
- 第二個缺點,Handler 對象在業務處理時,整個進程是無法處理其他連接的事件的,如果業務處理耗時比較長,那么就造成響應的延遲;
單 Reactor 單進程的方案不適用計算機密集型的場景,只適用于業務處理非常快速的場景(這解釋為什么redis有百萬并發的瓶頸)
2.2 單 Reactor 多線程 / 多進程
- Reactor 對象通過 epoll(IO 多路復用接口) 監聽事件,收到事件后通過 dispatch 進行分發,具體分發給 Acceptor 對象還是 Handler 對象,還要看收到的事件類型;
- 如果是連接建立的事件,則交由 Acceptor 對象進行處理,Acceptor 對象會通過 accept 方法 獲取連接,并創建一個 Handler 對象來處理后續的響應事件;
- 如果不是連接建立事件, 則交由當前連接對應的 Handler 對象來進行響應;
上面的三個步驟和單 Reactor 單線程方案是一樣的,接下來的步驟就開始不一樣了:
- Handler 對象不再負責業務處理,只負責數據的接收和發送,Handler 對象通過 read 讀取到數據后,會將數據發給子線程里的 Processor 對象進行業務處理;
- 子線程里的 Processor 對象就進行業務處理,處理完后,將結果發給主線程中的 Handler 對象,接著由 Handler 通過 send 方法將響應結果發送給 client**;
優點
- 能夠充分利用多核 CPU 的性能
缺點 - 那既然引入多線程,那么自然就帶來了多線程競爭資源的問題。
- 因為一個 Reactor 對象承擔所有事件的監聽和響應,而且只在主線程中運行,在面對瞬間高并發的場景時,容易成為性能的瓶頸的地方
2.3 多 Reactor 多進程 / 線程

- 主線程中的 MainReactor 對象通過 epoll監控連接建立事件,收到事件后通過 Acceptor 對象中的 accept 獲取連接,將新的連接分配給某個子線程;
- 子線程中的 SubReactor 對象將 MainReactor 對象分配的連接加入 select 繼續進行監聽,并創建一個 Handler 用于處理連接的響應事件。
- 如果有新的事件發生時,SubReactor 對象會調用當前連接對應的 Handler 對象來進行響應。
- Handler 對象通過 read -> 業務處理 -> send 的流程來完成完整的業務流程。
多 Reactor 多線程的方案雖然看起來復雜的,但是實際實現時比單 Reactor 多線程的方案要簡單的多,原因如下:
- 主線程和子線程分工明確,主線程只負責接收新連接,
- 子線程負責完成后續的業務處理。主線程和子線程的交互很簡單,主線程只需要把新連接傳給子線程,子線程無須返回數據,直接就可以在子線程將處理結果發送給客戶端。
nginx(多進程)
不是采用標準的,具體差異表現在主進程中僅僅用來初始化 socket,并沒有創建 mainReactor 來 accept 連接,而是由子進程的 Reactor 來 accept 連接,通過鎖來控制一次只有一個子進程進行 accept(防止出現驚群現象),子進程 accept 新連接后就放到自己的 Reactor 進行處理,不會再分配給其他子進程
Proactor(異步非阻塞io)
Proactor 是異步網絡模式, 感知的是已完成的讀寫事件。在發起異步讀寫請求時,需要傳入數據緩沖區的地址(用來存放結果數據)等信息,這樣系統內核才可以自動幫我們把數據的讀寫工作完成,這里的讀寫工作全程由操作系統來做,并不需要像 Reactor 那樣還需要應用進程主動發起 read/write 來讀寫數據,操作系統完成讀寫工作后,就會通知應用進程直接處理數據.
因此,**Reactor 可以理解為「來了事件操作系統通知應用進程,讓應用進程來處理」,而 Proactor 可以理解為「來了事件操作系統來處理,處理完再通知應用進程」。**這里的「事件」就是有新連接、有數據可讀、有數據可寫的這些 I/O 事件這里的「處理」包含從驅動讀取到內核以及從內核讀取到用戶空間。
舉個實際生活中的例子,Reactor 模式就是快遞員在樓下,給你打電話告訴你快遞到你家小區了,你需要自己下樓來拿快遞。而在 Proactor 模式下,快遞員直接將快遞送到你家門口,然后通知你。
無論是 Reactor,還是 Proactor,都是一種基于「事件分發」的網絡編程模式,區別在于 Reactor 模式是基于「待完成」的 I/O 事件,而 Proactor 模式則是基于「已完成」的 I/O 事件。
接下來,一起看看 Proactor 模式的示意圖:

介紹一下 Proactor 模式的工作流程:
- Proactor Initiator 負責創建 Proactor 和 Handler 對象,并將 Proactor 和 Handler 都通過 Asynchronous Operation Processor 注冊到內核;
- Asynchronous Operation Processor 負責處理注冊請求,并處理 I/O 操作;Asynchronous Operation Processor 完成 I/O 操作后通知 Proactor;
- Proactor 根據不同的事件類型回調不同的 Handler 進行業務處理;Handler 完成業務處理;
可惜的是,在 Linux 下的異步 I/O 是不完善的, aio 系列函數是由 POSIX 定義的異步操作接口,不是真正的操作系統級別支持的,而是在用戶空間模擬出來的異步,并且僅僅支持基于本地文件的 aio 異步操作,網絡編程中的 socket 是不支持的,這也使得基于 Linux 的高性能網絡程序都是使用 Reactor 方案。
而 Windows 里實現了一套完整的支持 socket 的異步編程接口,這套接口就是 IOCP,是由操作系統級別實現的異步 I/O,真正意義上異步 I/O,因此在 Windows 里實現高性能網絡程序可以使用效率更高的 Proactor 方案。
)





![MySQL基礎 [五] - 表的增刪查改](http://pic.xiahunao.cn/MySQL基礎 [五] - 表的增刪查改)
和Foreign Key(外鍵))


(藍橋杯常考點)—數據結構(進階))





C++版——day7)
)
)
