1. 預解析的核心目標
瀏覽器在正式解析(Parsing)HTML 前,會啟動一個輕量級的? 預解析器(Pre-Parser),快速掃描文檔內容,實現:
- 提前發現并加載關鍵資源(如 CSS、JavaScript、圖片)。
- 推測性構建部分 DOM 結構,減少主解析器的等待時間。
- 優化網絡請求的優先級,避免資源加載阻塞渲染。
2、具體步驟
- 快速掃描:預解析器逐字節掃描 HTML,識別?資源標簽(如<script>、<link>、<img>)
- 推測性構建DOM:預解析器嘗試構架簡化的DOM結構,供主解析器后續填充
- 主解析器接管:主解析器基于預解析結果繼續處理,跳過已掃描的部分,直接填充或修正 DOM
- 主解析器追上時停止:當主解析器處理到預解析器已掃描的位置時,預解析器退出。
3、預解析的觸發條件與限制
(1)觸發條件:
- HTML 文檔開始加載時自動啟動。
- 遇到 <script async> 或 <link preload>等標簽時增強預加載。
(2)無法預解析的情況:
- 內聯JS會強制主解析器暫停。
- 同步腳本(無async/defer)會阻塞預解析和主解析。
- 主解析器暫停時,預解析器也會被迫停止(因為預解析器需要與主解析器保持同步,避免預測錯誤)。
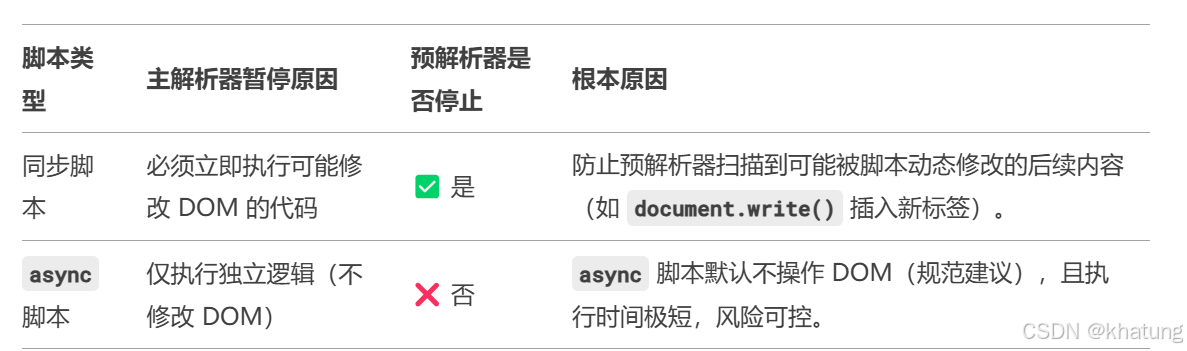
4、主解析器暫停時預解析器的兩種情況:
(1)同步腳本導致的暫停
- 主解析器必須立即下載并執行?腳本(可能修改 DOM)。
- 預解析器強制停止:因為腳本可能通過?document.write()動態插入標簽,預解析器必須等待主解析器執行完畢才能保證預測準確性。
(2)async腳本執行導致的暫停
- 主解析器暫停執行腳本,但預解析器繼續掃描。
- 原因:async?腳本不會通過?document.write()修改 DOM(現代規范已廢棄此用法),且其執行時間極短,預解析器可安全繼續工作。
5. 關注資源優先級
- 預解析器會根據資源類型分配優先級:
- 高優先級:CSS、字體、首屏圖片。
- 低優先級:非首屏圖片、異步腳本。
拓展:
1、資源下載的過程:
觸發下載的時機(預解析器掃描+主解析器處理)—>網絡請求的生命周期(檢查緩存—>建立連接(如果沒有緩存)—>發送請求—>接收響應)
2、資源優先級的設置作用:
- 預解析器在快速掃描 HTML 時,會為發現的資源分配初始優先級
- 解析器不直接控制下載,而是由?瀏覽器網絡棧?根據優先級調度下載任務,保證關鍵路徑資源快速就位
3、主解析器和預解析器的步調:
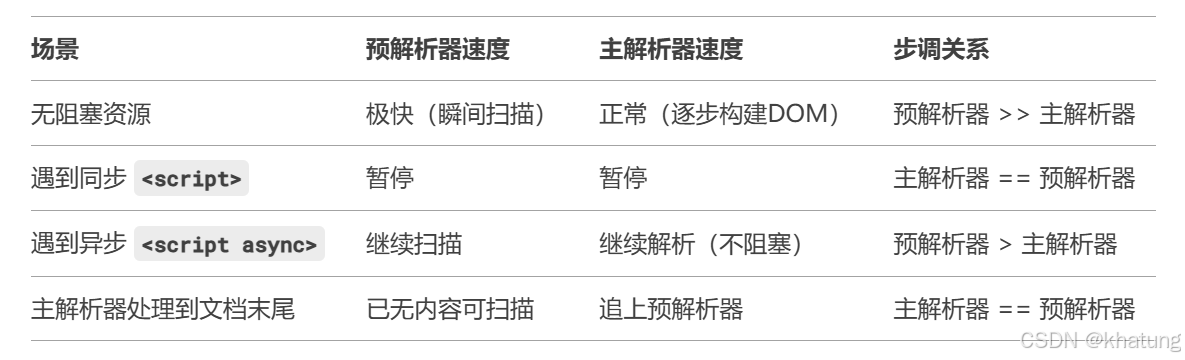
?預解析器在掃描到同步腳本時,會停止,等到主解析器走到這個腳本執行完腳本后,兩個解析器才同時開始往后走,避免腳本修改后續DOM導致預測錯誤






開發指南)

02——Python+PS自動化添加虛線邊框)










