使用Github Action自動同步obisidian和hexo倉庫,避免手動操作。
本文首發于?慕雪的寒舍
1. 煩惱
先來說說慕雪現在的筆記和博客是怎么管理的吧,我正在使用兩套筆記軟件
- 思源筆記:私密性高一些,不是博客的筆記都在這里面。由于思源筆記不是markdown編輯器,不能直接和hexo對接;
- obisdian:專門管理hexo的博客;
然后我的hexo博客和obsidian又有分離,hexo配置倉庫是一個單獨的git倉庫(后文簡稱為hexo倉庫),obsidian博客庫也是一個單獨的git倉庫(后文簡稱為obisidian倉庫)。
我采用的操作特別繁瑣,步驟如下:
- 在obsidian里面寫好博客之后,手動使用FreeFileSync軟件,將
obisidian/blog目錄同步到hexo/source/_posts目錄中(這兩個目錄完全一樣); - 然后再到hexo本地倉庫中執行hexo三板斧命令,給新的博客生成abbrlink,push到hexo的github倉庫;
- 再用FreeFileSync反向將
hexo/source/_posts目錄同步回obisidian/blog目錄,因為新的博客會多出abbrlink;
是不是聽起來都頭大了?
2. 曾經的想法
先前我一直在想怎么讓這套流程簡化,考慮過幾個方案都不太滿意。我想過直接把obsidian vaults丟到hexo/source/_posts目錄里面,但是考慮到我的obsidian中還有博客模板這種不需要上傳到博客里面的內容,此項并不方便(雖然hexo其實可以跳過渲染某些md文件)
現在就想出了自動化的方案,也就是用github action來同步obsidian和hexo的倉庫,當obisidian/blog目錄有變動的時候,觸發action,自動將這個目錄的內容拷貝到hexo/source/_posts倉庫目錄中,并push到hexo倉庫。
這里就有一個問題,abbrlink是基于hexo插件生成的,如果用這種方式那就沒辦法給新的博客md文件生成一個固定abbrlink了。不管是怎么讓github action執行hexo g命令,最后都會出現遠程倉庫md文件中有abbrlink,但本地需要pull才能更新的問題,這會對我后續的博客編寫和git操作帶來不便(畢竟之前都是無腦push上去的)
之前每次想折騰github action的時候就會發現這個問題(由于沒記筆記導致折騰的時候忘記了之前為啥沒搞定……),然后又不了了之。
今天突然想起來,既然問題是在abbrlink插件上,那我不用hexo來生成abbrlink不就行了?反正abbrlink本質上和隨機數沒啥關系,我只要給新的博客手動加上一個和其他博客不沖突的abbrlink不就ok了?
注:hexo的abbrlink插件是通過crc16/crc32算法計算得到文件的abbrlink的,并非隨機數生成。但對于abbrlink的作用來看,只要博客上每個文章都有一個獨立的abbrlink其實就夠了,所以abbrlink說它是隨機數也沒啥問題。
解決方法明了:用別的方法給新博客生成abbrlink,然后再用github action自動化同步obsidian倉庫和hexo倉庫。
3. 解決步驟
3.1. 生成abbrlink的python腳本
其實obsidian中是有一個abbrlink插件的,首先感謝插件作者能提供一個hexo-abbrlink插件的替代品。但是,這個插件不太符合本人的需求,因為它直接針對于obsidian全局,會把我的其他文件以及博客模板文件都加上abbrlink。
折騰了一會后,感覺不如返璞歸真,直接寫個python腳本,把所有博客文件的abbrlink遍歷出來,然后生成30個不沖突的abbrlink寫入到一個文件里面,每次寫新博客的時候從這個文件里面取一個abbrlink出來用就完事啦!
說干就干,GPT,啟動!
# 生成不沖突的abbrlink
import yaml
import re
import os
import randomMD_FILE_PATH = '../../Notes/CODE'
"""博客md文件路徑"""
NEW_ABBRLINK_SIZE = 20
"""生成幾個abbrlink"""
NEW_ABBRLINK_MD_FILE = '../../Notes/ABBRLINK歸檔.md'
"""生成的abbrlink寫入這個md文件里面"""def extract_front_matter(file_path):"""提取 Markdown 文件中的 front-matter 內容。假設 front-matter 是以 '---' 包圍的 YAML 格式內容。"""with open(file_path, 'r', encoding='utf-8') as file:content = file.read()# 使用正則表達式匹配 front-mattermatch = re.match(r'---\n(.*?)\n---\n', content, re.DOTALL)if match:front_matter = match.group(1)return yaml.safe_load(front_matter) # 使用 yaml 解析 front-matterelse:return Nonedef remove_front_matter(file_path):"""移除 Markdown 文件中的 front-matter 部分,返回去除 front-matter 后的內容。"""with open(file_path, 'r', encoding='utf-8') as file:content = file.read()# 使用正則表達式去除 front-mattercleaned_content = re.sub(r'---\n(.*?)\n---\n', '', content, flags=re.DOTALL)return cleaned_contentdef update_front_matter(file_path, new_front_matter):"""更新 Markdown 文件中的 front-matter 內容。"""with open(file_path, 'r+', encoding='utf-8') as file:content = file.read()# 使用正則表達式替換 front-matternew_front_matter_str = yaml.dump(new_front_matter, default_flow_style=False)content = re.sub(r'---\n(.*?)\n---\n', f'---\n{new_front_matter_str}\n---\n', content, flags=re.DOTALL)# 寫回文件with open(file_path, 'w', encoding='utf-8') as file:file.write(content)def extract_front_matter_from_dir(directory_path):"""遍歷指定目錄及其子目錄下的所有 .md 文件,提取它們的 front-matter 內容,并將所有內容添加到列表中。"""front_matter_list = []# 遍歷目錄中的所有文件和子目錄for root, dirs, files in os.walk(directory_path):for filename in files:file_path = os.path.join(root, filename)# 只處理 .md 文件if filename.endswith('.md'):front_matter = extract_front_matter(file_path)if front_matter:front_matter_list.append(front_matter)return front_matter_listdef generate_unique_10digit_numbers(existing_numbers, n):"""生成 n 個不在 existing_numbers 列表中的 10 位數字。:param existing_numbers: 已存在的整數列表:param n: 需要生成的數字數量:return: 不重復的 10 位數字列表"""unique_numbers = set(existing_numbers) # 將現有的數字轉換為集合,加速查找generated_numbers = []# 如果現有數字數量已經非常大,可能無法生成足夠的唯一數字if len(unique_numbers) > 9999999999 - 1000000000:return Nonewhile len(generated_numbers) < n:num = random.randint(1000000000, 9999999999) # 隨機生成一個10位數字if num not in unique_numbers:generated_numbers.append(num)unique_numbers.add(num) # 將新生成的數字添加到現有數字集合中return generated_numbersdef write_int_list_to_md(file_path, int_list):"""將整數列表的成員按行寫入一個Markdown文件。:param file_path: Markdown文件的路徑:param int_list: 要寫入文件的整數列表"""with open(file_path, 'w', encoding='utf-8') as file:for number in int_list:file.write(f"{number}\n") # 每個數字寫一行# 示例使用
if __name__ == "__main__":# 假設 markdown 文件目錄路徑為 "../../Notes/CODE"file_path = MD_FILE_PATH# 提取所有 .md 文件的 front-matterfront_matter_list = extract_front_matter_from_dir(file_path)# 打印所有文件的 front-matterif not front_matter_list:print("沒有找到 front-matter 或目錄為空。")os.abort()abbrlink_list = []for fm in front_matter_list:# print(f"文件的 front-matter 內容:", fm)if 'abbrlink' not in fm:print(f"ERR! abbrlink not in {fm}")continuelink = int(fm['abbrlink'])if link in abbrlink_list:print(f"ERR! {link} in abbrlink list!")continueabbrlink_list.append(link)# 獲取新的abbrlinknew_abbrlink = generate_unique_10digit_numbers(abbrlink_list, NEW_ABBRLINK_SIZE)for link in new_abbrlink:print(link)print("Gen abbrlink success")write_int_list_to_md(NEW_ABBRLINK_MD_FILE, new_abbrlink)print("Write abbrlink to", NEW_ABBRLINK_MD_FILE)腳本運行效果如下,會生成新的abbrlink鏈接數字,然后寫入到指定的md文件中。這樣在obsidian里面就能看到這個md文件,取用里面的abbrlink了。用完了之后再手動執行一下腳本更新abbrlink就完事啦。
? python3 gen_abbrlink.py
8608489065
7885829874
8484489314
4284761477
1589125738
9151131777
4800824161
7141292217
2714461943
5131440419
2816690027
9574459795
6572894529
2920325088
2724835080
7631222809
1802821635
3120273636
2860205445
3100823185
Gen abbrlink success
Write abbrlink to ../../Notes/ABBRLINK歸檔.md
3.2. Github Action配置
接下來就是配置Github Action來同步兩個倉庫了。讓GPT寫了個大概,發現GPT在瞎說,它給出https的倉庫clone鏈接,并表示用自帶的GITHUB_TOKEN就能克隆私有倉庫了,但實際上完全沒用。最后還是得用老辦法ssh密鑰對來實現。
首先使用如下命令生成一個ssh密鑰,彈出的提示中填寫一個文件名字(不然會覆蓋默認目錄的ssh密鑰對)
ssh-keygen -t rsa -C "github action"
然后,搞清楚同步的方向,我的需要是將obsidian倉庫中的內容同步到hexo倉庫,所以公鑰放在hexo倉庫,私鑰放在obsidian倉庫中。
在hexo倉庫(被推送的倉庫)中,倉庫設置Settings->Deploy keys->Add deploy key添加公鑰,命名為HEXO_PUB_KEY。注意需要勾選允許write寫入倉庫,不然默認權限只允許pull和clone倉庫。
在obsidian倉庫中,倉庫設置Settings->Secrets and variables->Secrets添加私鑰,命名為HEXO_PRI_KEY。
最后的Github Action Workflow文件如下,將該文件寫入obsidian倉庫的.github/workflows/sync-code-to-posts.yml即可,每個步驟都寫了注釋。
name: Sync CODE to _postson:push:paths:- 'Notes/CODE/**' # 監聽 CODE 文件夾內的文件變化,沒有變化不會觸發actionjobs:sync:runs-on: ubuntu-lateststeps: # 檢出 obsidian 倉庫的代碼- name: Checkout muob repositoryuses: actions/checkout@v3# 設置 Git 配置- name: Set up Gitenv:ACTIONS_KEY: ${{ secrets.HEXO_PRI_KEY }}run: |mkdir -p ~/.ssh/echo "$ACTIONS_KEY" > ~/.ssh/id_rsachmod 700 ~/.sshchmod 600 ~/.ssh/id_rsassh-keyscan github.com >> ~/.ssh/known_hostsgit config --global user.name "musnows"git config --global user.email "ezplayingd@126.com"git config --global core.quotepath falsegit config --global i18n.commitEncoding utf-8 git config --global i18n.logOutputEncoding utf-8 # 克隆 HexoBlog 倉庫(私有倉庫),使用 ssh 來進行認證- name: Checkout HexoBlog repositoryrun: |git clone git@github.com:musnows/Hexo-Blog.git HexoBlog# 同步文件:將 obsidain 倉庫中的 CODE 文件夾內容復制到 HexoBlog 倉庫的 _posts 文件夾- name: Sync files from CODE to _postsrun: |rsync -av --delete Notes/CODE/ HexoBlog/source/_posts/# 提交更改并推送到 HexoBlog 倉庫- name: Commit and push changes to HexoBlog repositoryrun: |cd HexoBloggit add .git commit -m "Sync CODE to _posts at $(TZ='Asia/Shanghai' date '+%Y-%m-%d %H:%M:%S')"git push origin hexo第二步的Git操作中,我們將倉庫配置的secrets.HEXO_PRI_KEY映射成環境變量ACTIONS_KEY,然后寫入執行action的ubuntu環境的~/.ssh/id_rsa私鑰文件中,這樣就能操作另外一個倉庫了。
第四步的Sync操作使用了rsync命令
rsync -av --delete 源文件夾 目標文件夾
解釋一下這里的幾個命令參數,-a用于保持文件的原有屬性,-v代表verbose,會輸出詳細的日志,--delete用于在目標目錄中刪除源目錄中不存在的文件(同步刪除操作)。
4. 測試效果
我在目錄中創建了一個測試文件,push到了遠端倉庫中,觸發了action

hexo配置倉庫成功被push了,有更新的文件也是在obsidain倉庫中被修改的文件,符合預期。
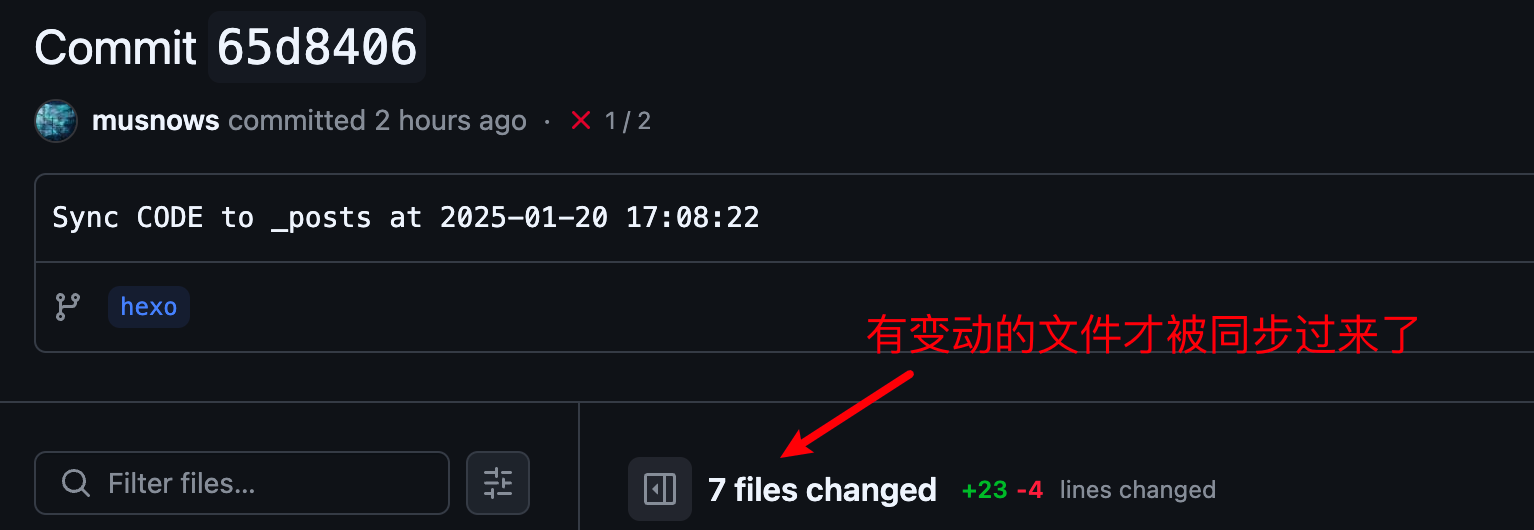
這樣就搞定啦!以后我只需要push博客到obsidian倉庫中,就能自動同步到hexo倉庫內了。不需要手動做那部分繁瑣的操作









填充每個節點的下一個右側節點指針)


)


)



 部署yolo HLS和Verilog 分別干什么)