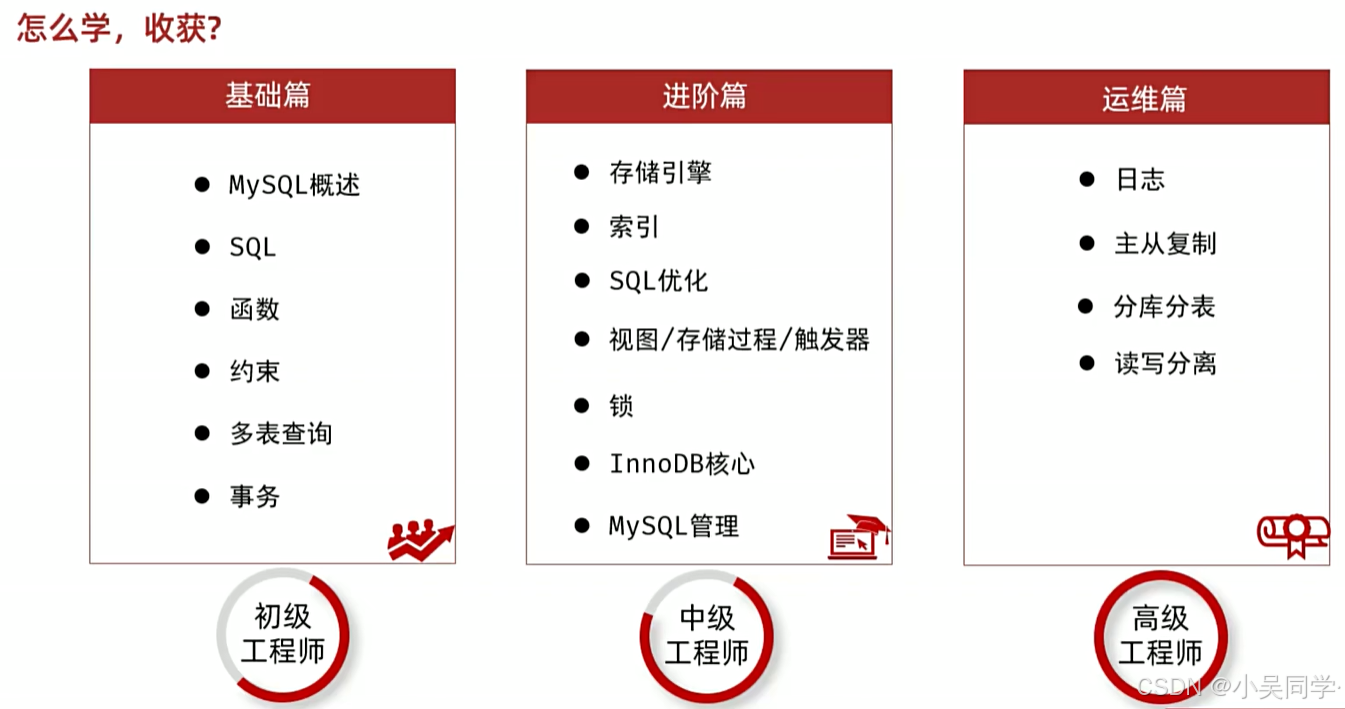
黑馬程序員 MySQL數據庫入門到精通,從mysql安裝到mysql高級、mysql優化全囊括_嗶哩嗶哩_bilibili
一、數據庫相關概念
1、主流的關系型數據庫都支持SQL語言——SQL語言可以操作所有的關系型數據庫
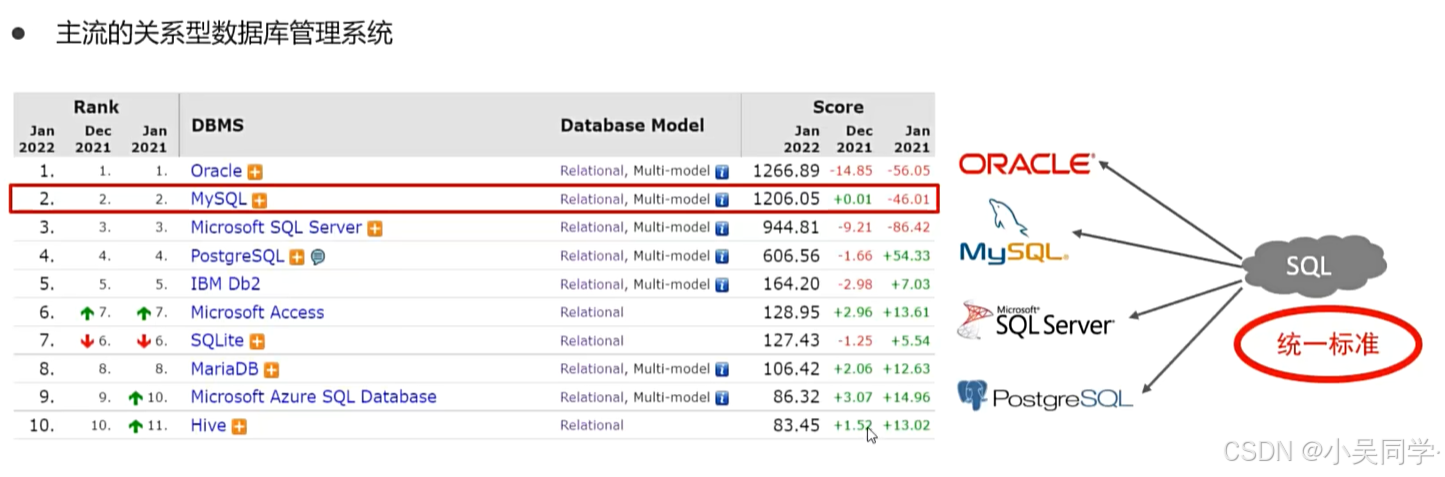
????????像MySQL、Oracle Database、Microsoft SQL Server、IBM Db2等主流的關系型數據庫系統都支持SQL,并將其作為主要的查詢和數據操作語言。這些系統實現了SQL標準的大部分功能,但也添加了各自的擴展和特性。
????????基礎的SELECT、INSERT、UPDATE、DELETE等操作在大多數情況下是兼容的,但在涉及更復雜的查詢或需要利用特定數據庫特性的場合時,就需要針對具體數據庫調整SQL代碼了。【比如二、3、6>分頁查詢,不同關系型數據庫用的不一樣】

2、什么是 關系型數據庫(RDBMS)?

反之,則稱之為“非關系型數據庫”。
二、SQL語句的分類——DDL、DML、DQL、DCL
下圖中,注意SQL語句不區分大小寫,關鍵字建議使用大寫
? ? ? ? 當使用引號時,使用單引號。


1、DDL
1>數據庫操作
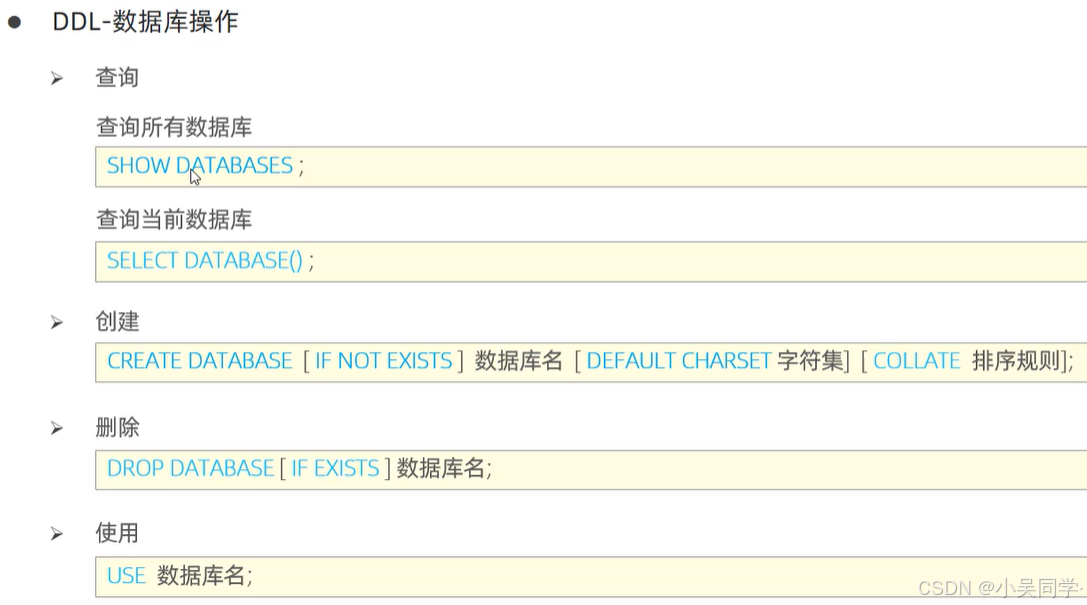
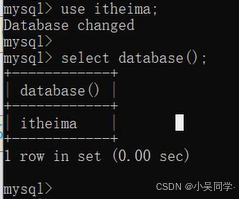
?上圖中,“查詢當前數據庫”是結合“使用”的。“查詢當前數據庫”——就是看當前處于哪個數據庫。
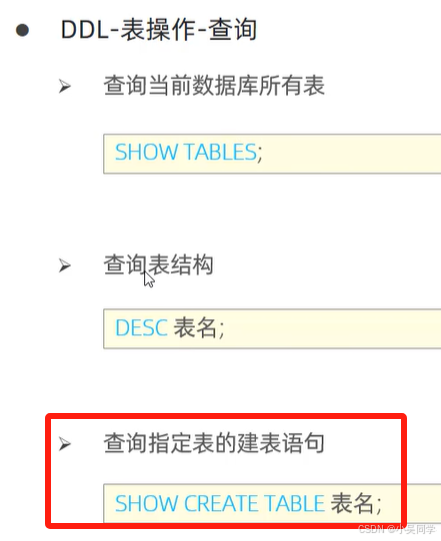
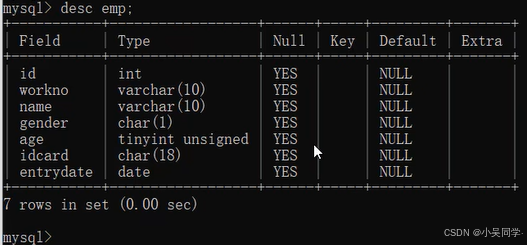
2>表操作——針對表+字段(即列名)
下圖中,在對某個數據庫進行操作時,要先通過上圖的“使用”命令進入該數據庫。
 ?
?
1》數據類型【略】:數值類型、字符串類型、日期時間類型
2》針對表——添加&修改&刪除


下圖中,TRUNCATE是只留下了表的結構,里面的數據都沒有了

3》針對每個字段——添加&修改&刪除



2、DML:對表中內容的增(INSERT)刪(DELETE)改(UPDATE)
1>選擇MySQL圖形化界面
下載DataGrip,其功能比前兩種都要強大。

DataGrip的基本操作,見下述鏈接:
11. 基礎-SQL-圖形化界面工具DataGrip_嗶哩嗶哩_bilibili
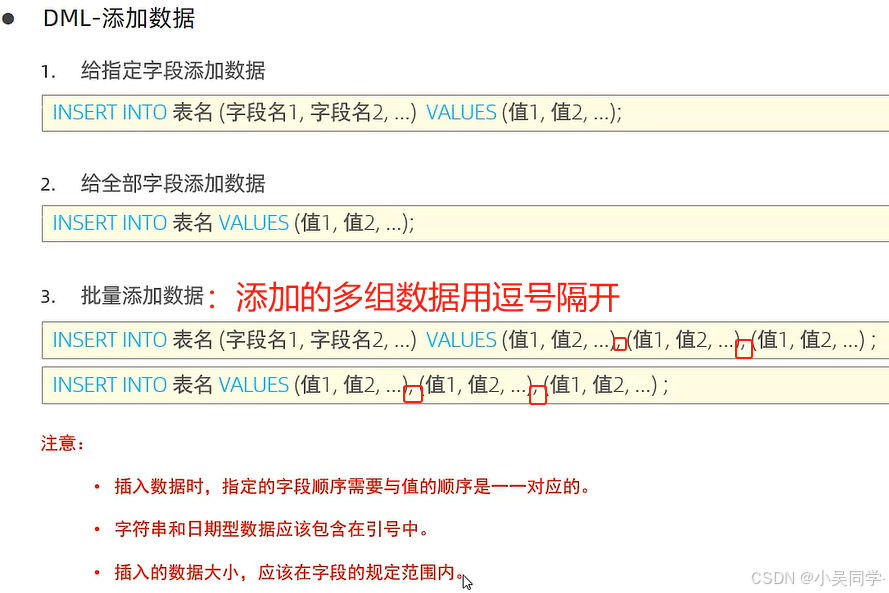
2>增(INSERT)——插入指定字段/全部字段;批量添加數據
? ? ? ? 下圖中,引號是單引號。
3>改(UPDATE)

4>刪(DELETE)

3、DQL:查詢表中內容(SELECT);及其執行順序!
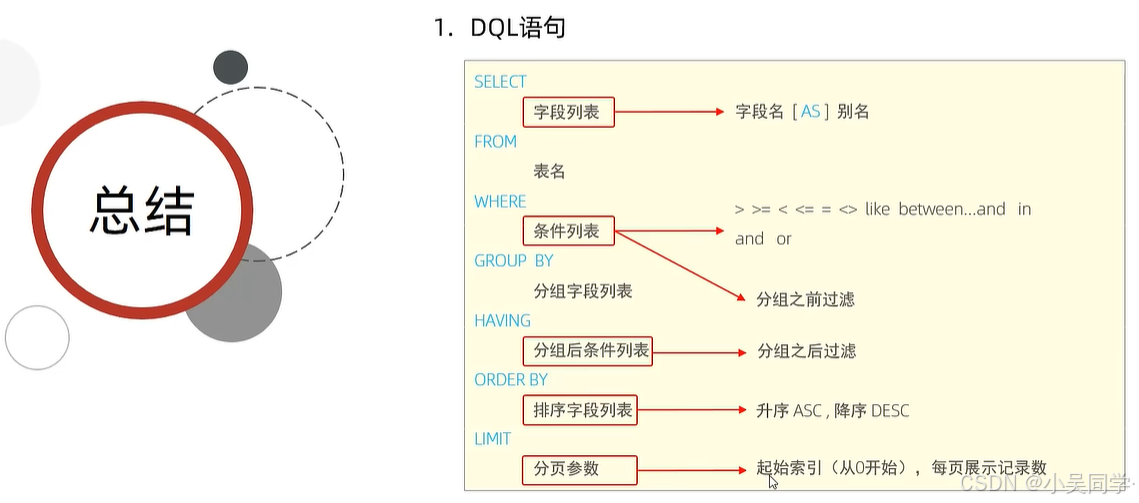
下圖中,講解分組查詢前需要先講聚合函數

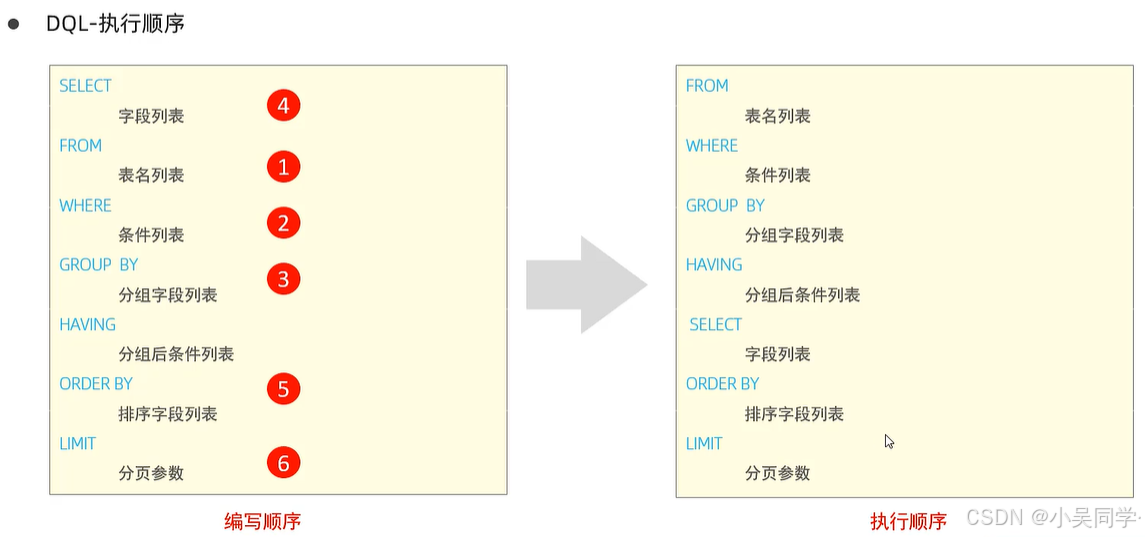
驗證上圖右邊的執行順序:
先執行FROM:如下圖,在FROM后給表加別名,發現其它地方都可以用

WHERE在SELECT之前:如下圖,在SELECT后面給e.age取別名eage,想在WHERE后面使用eage卻報錯。證明WHERE的執行順序在SELECT之前!

SELECT在ORDER BY之前:如下圖,在SELECT后面給e.age取別名eage,可以在ORDER BY后面使用eage。

1>基本查詢

2>條件查詢(WHERE)


注意區別OR和IN,如下圖:
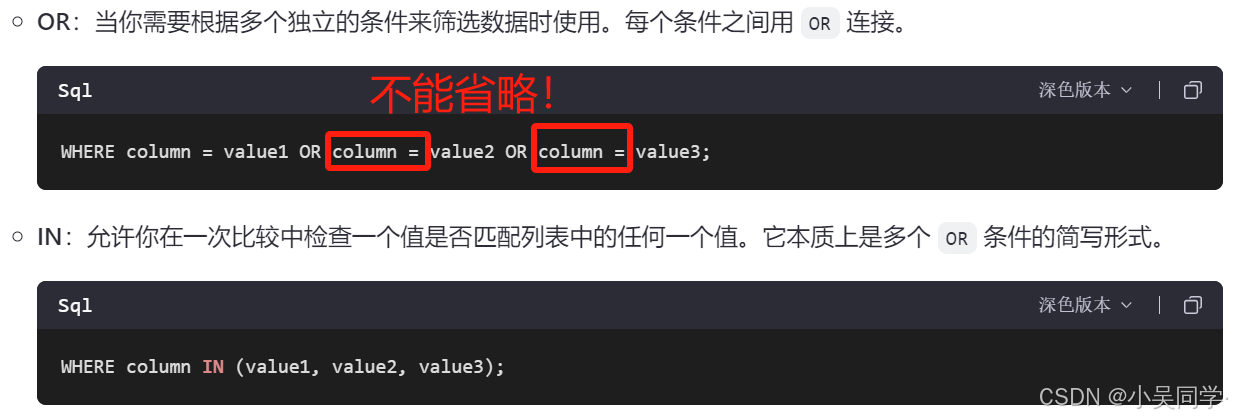
上圖中紅色字體部分“不能省略!”,解釋如下圖:

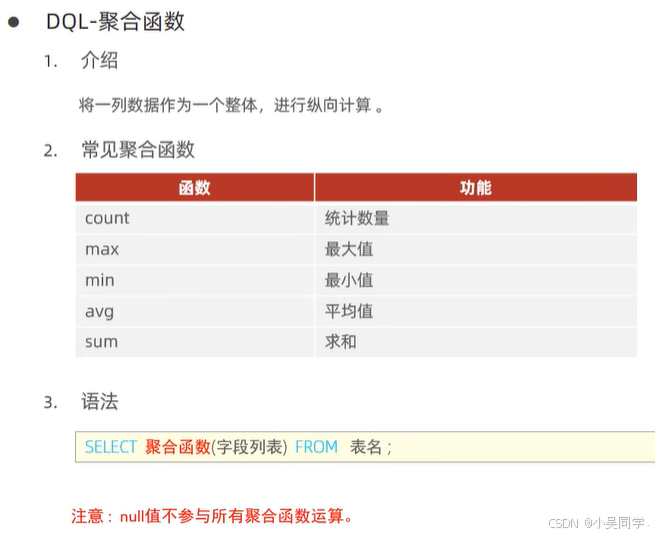
3>聚合函數【講“分組查詢”前得先講聚合函數】:是作用于某一列的,注意NULL值不參與所有聚合函數運算
比如select count(*) from emp; 答案=16,即一共有16行數據。
然而,如果select count(idcard) from emp; 如果idcard有一行的數據為null,那么答案=15。【NULL值不參與所有聚合函數運算】
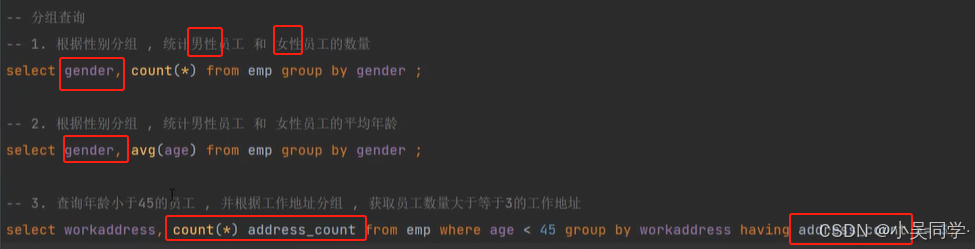
4>分組查詢(GROUP BY)

上圖中,“分組之后,查詢的字段一般為聚合函數和分組字段,查詢其他字段無任何意義。”
? ? ? ? 比如下圖的1.,如果加個name字段,是沒有任何意義的。只是顯示了性別是"女"的第一行數據的女生姓名。如下下圖。
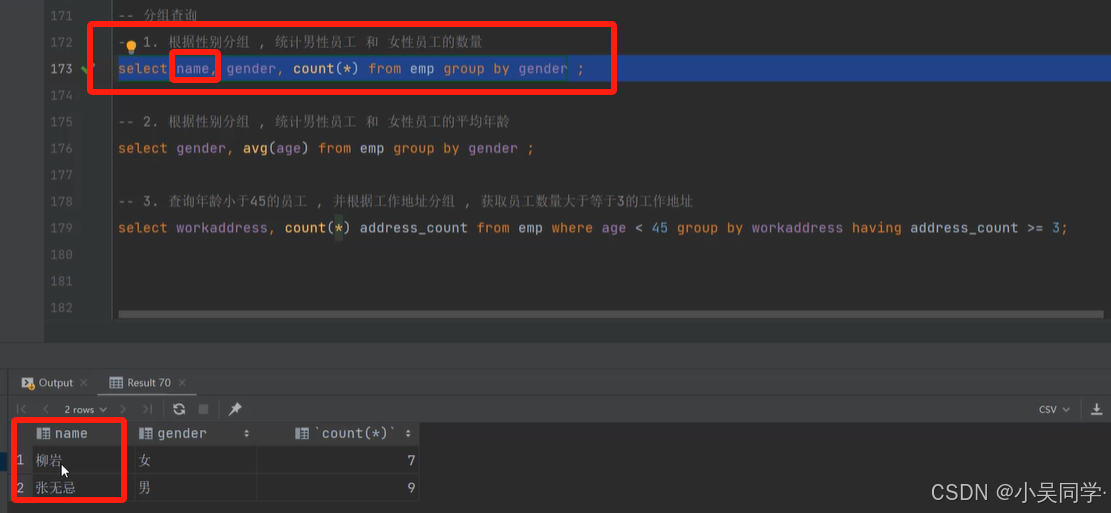
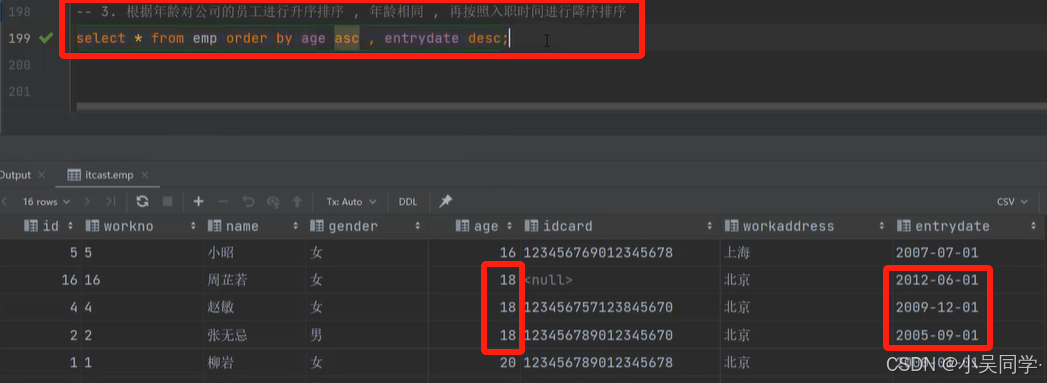
5>排序查詢(ORDER BY)

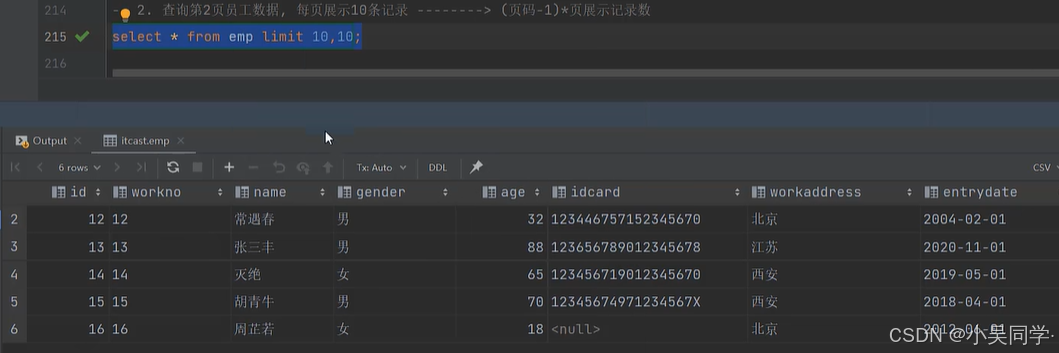
6>分頁查詢(數據庫方言,MySQL中是LIMIT)
下圖中,“查詢記錄數”就是“每頁顯示記錄數”
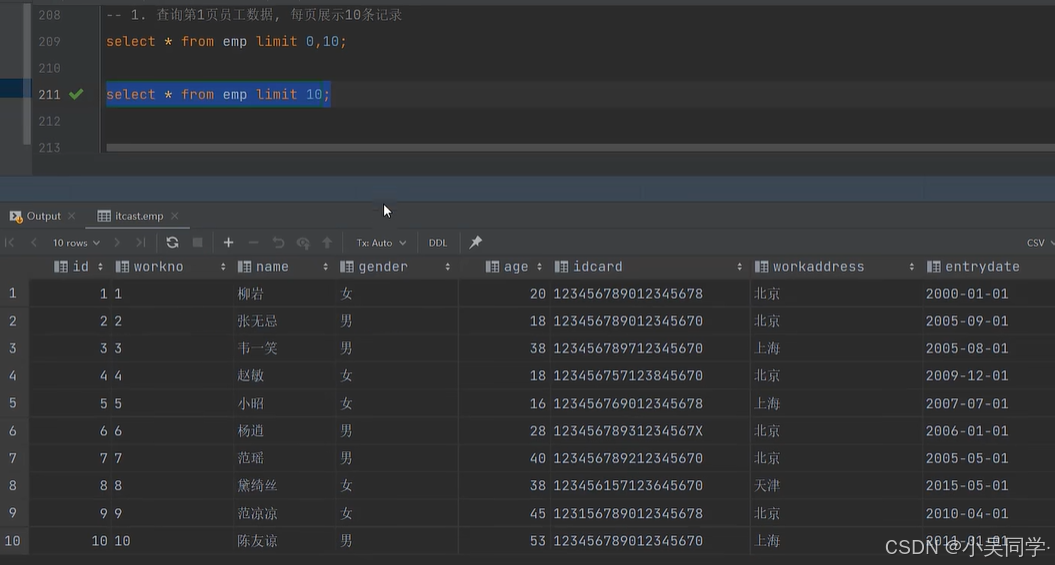
下圖中,起始索引=(2-1)*10=10;“查詢記錄數”就是“每頁顯示記錄數”=10.
????????emp表里一共16行數據,所以第二頁只顯示6行數據。
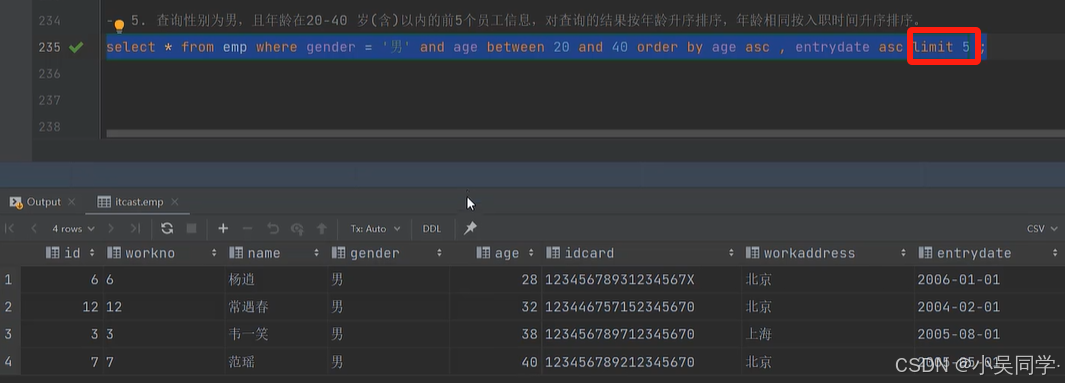
舉例:查詢前5個員工
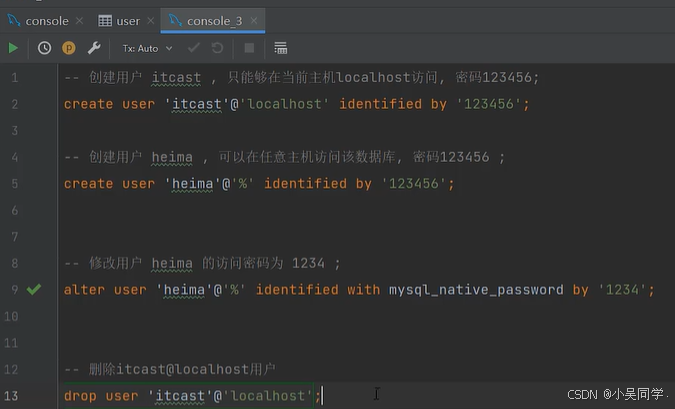
4、DCL:管理數據庫 用戶、控制數據庫的訪問 權限
1>管理用戶
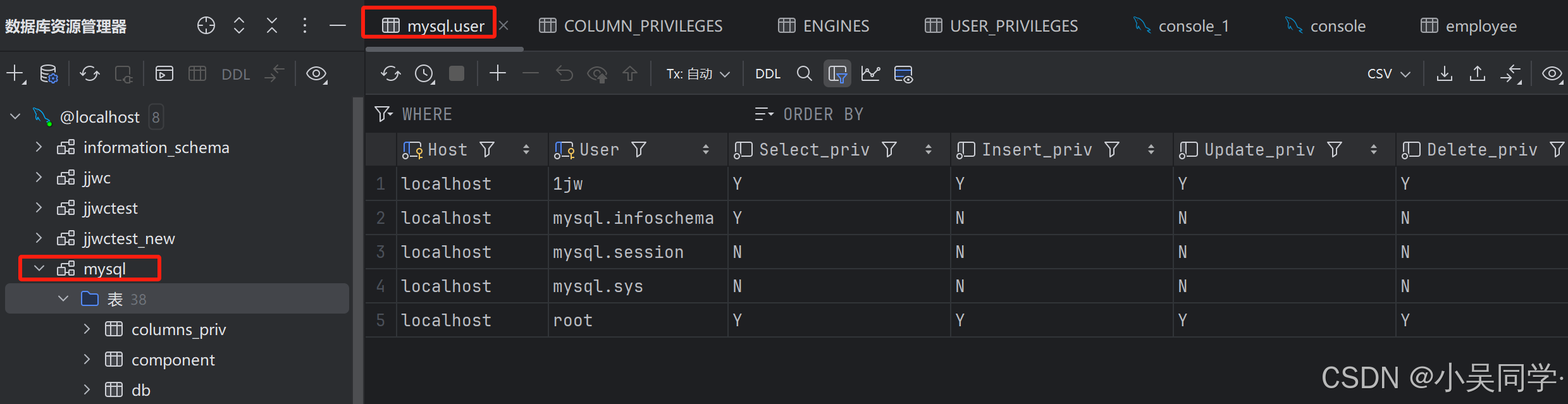
mysql數據庫如下,里面有個user表存儲著使用的用戶。
舉例:
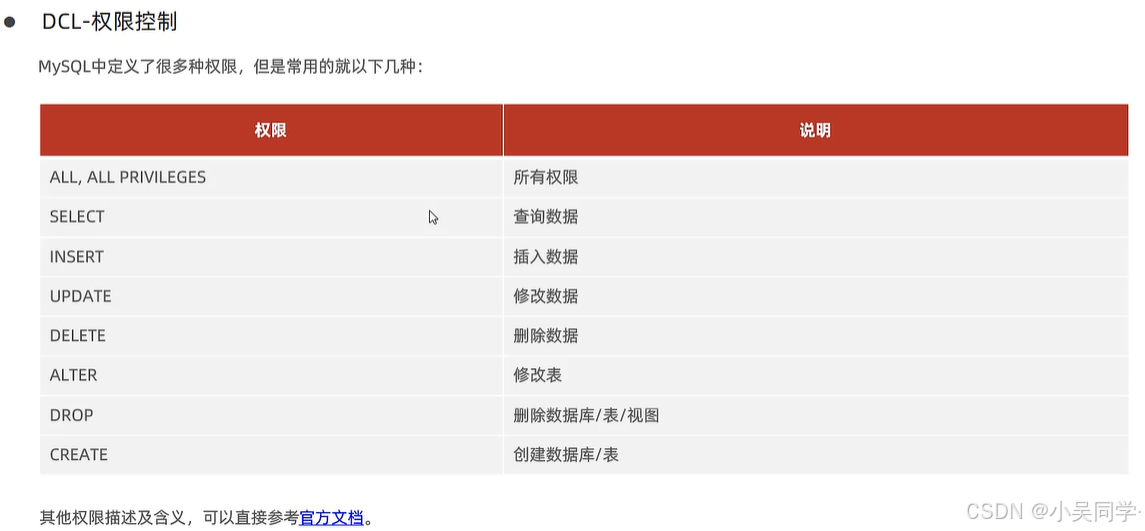
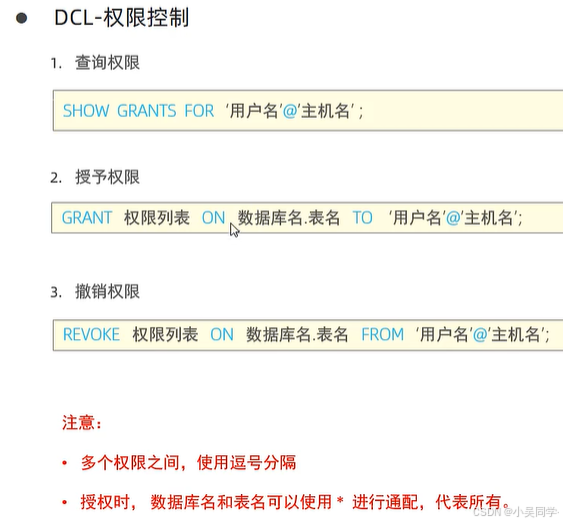
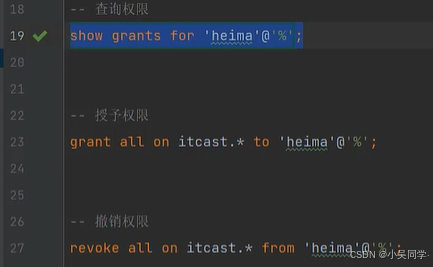
2>權限控制
三、函數
1、聚合函數【見二、3、3>】
2、字符串函數
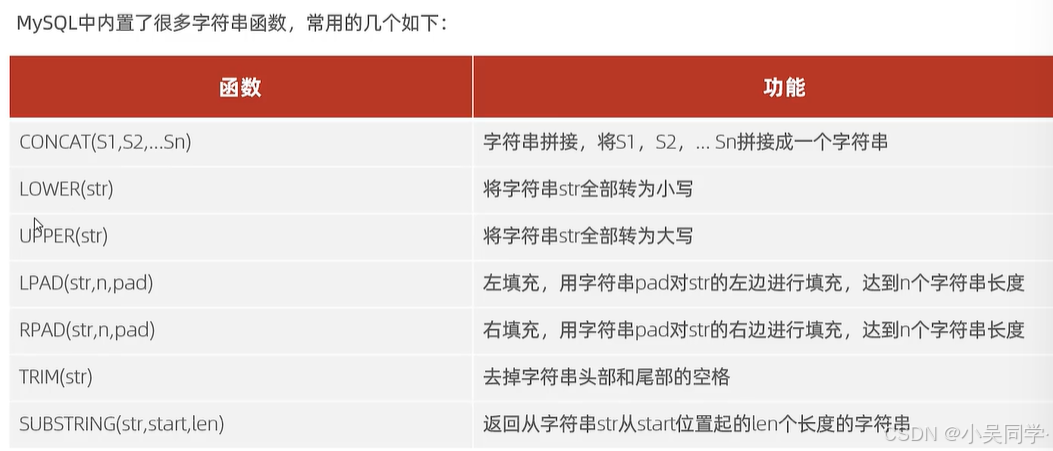
3、數值函數
4、日期函數
5、流程函數
四、約束:作用于表中字段上的規則,在創建/修改表的時候添加約束
1、概述

2、舉例

在上圖創建完表后,插入下圖的兩條數據,不用指定id字段

如下圖所示,id字段會自增
3、外鍵約束:外鍵用來讓兩張表的數據之間建立連接,從而保證數據的一致性和完整性
1>外鍵關聯到另一個表中的字段,被引用的列需要保證其值的 唯一性和非空性
這意味著,被引用的列是 主鍵(Primary Key) 或 唯一約束(Unique Constraint)+ 非空。
????????唯一約束允許列包含空值(除非在定義約束時明確指定了不允許空值)。因此,在確保非空性的前提下,具有唯一約束的列也可以被外鍵引用。
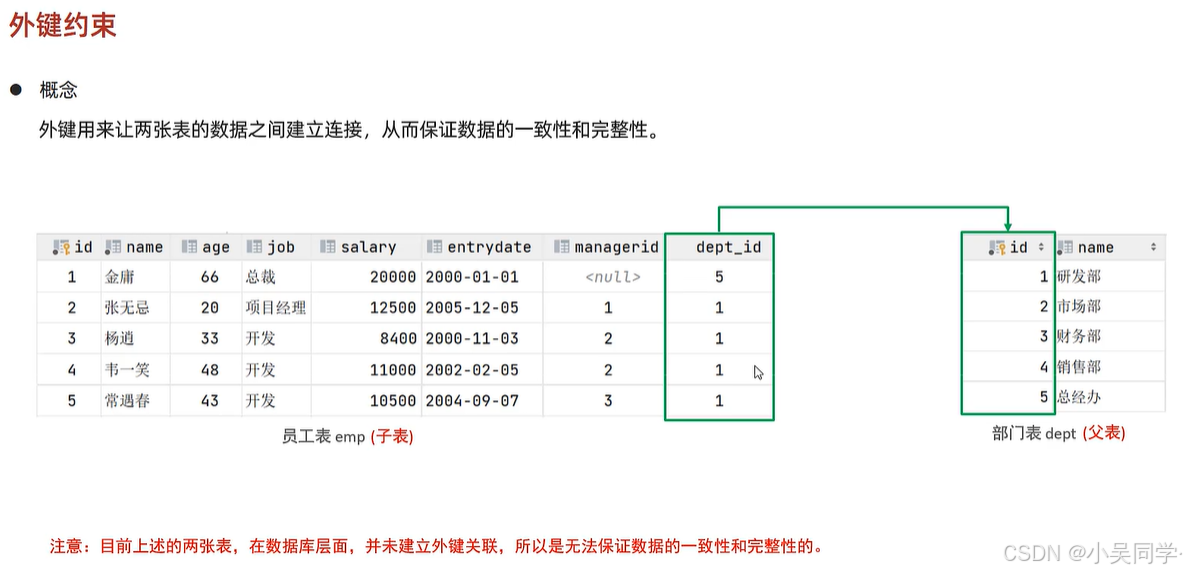
在上圖中,如果在父表dept中刪除了id=1的部門,對子表emp沒有任何影響。這違背了數據的一致性和完整性。

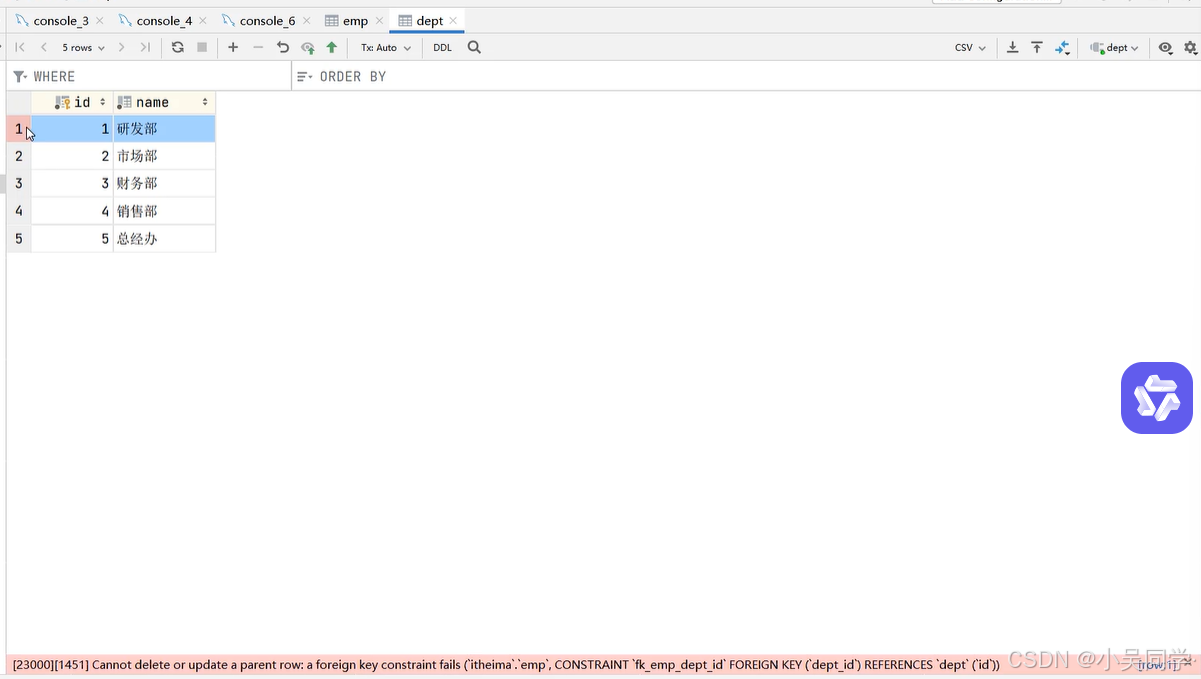
創建表后添加外鍵


現在如果要在父表dept中刪除了id=1的部門,那么會報錯
2>外鍵刪除更新行為【級聯操作等】

1》舉例CASCADE

2》舉例SET NULL

五、多表查詢
1、多表關系:一對多(多對一)、多對多、一對一

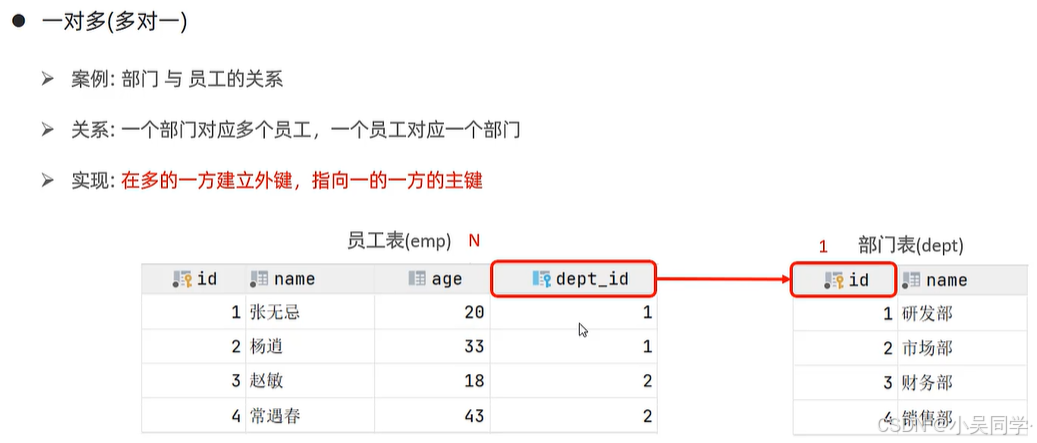

3>一對一:多用于單表拆分
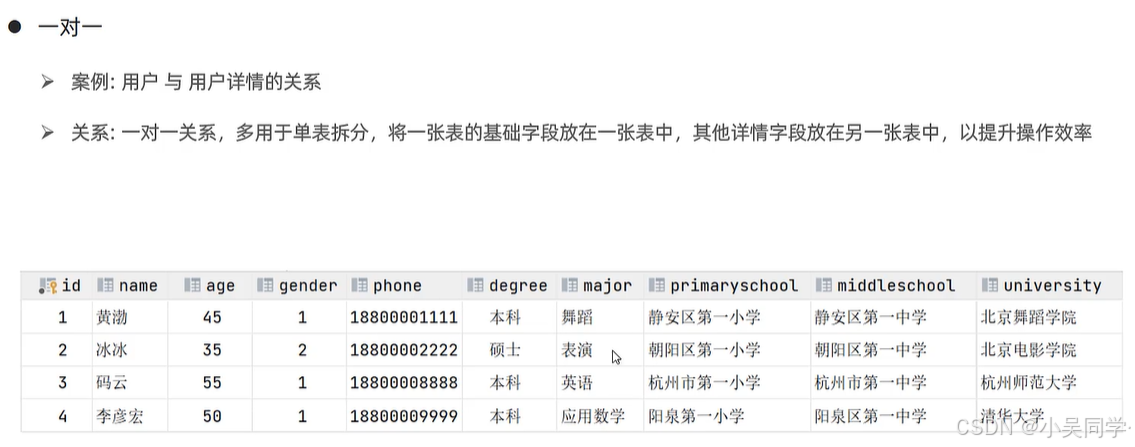
拆分上圖中的表為兩張表,如下圖

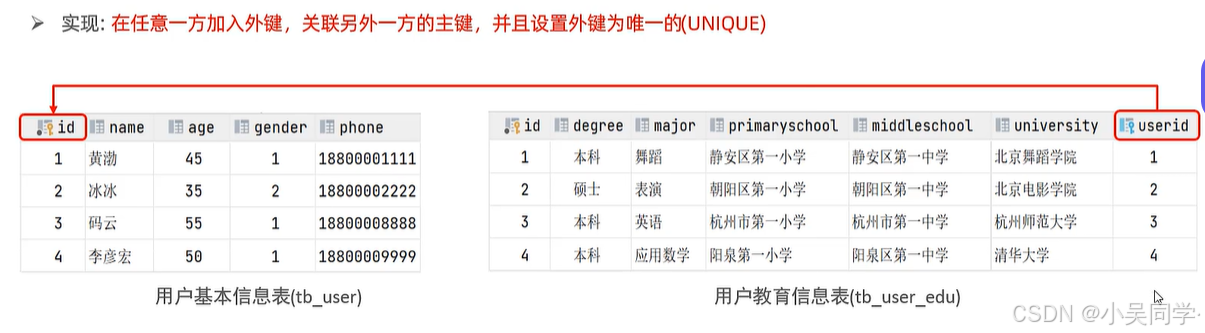
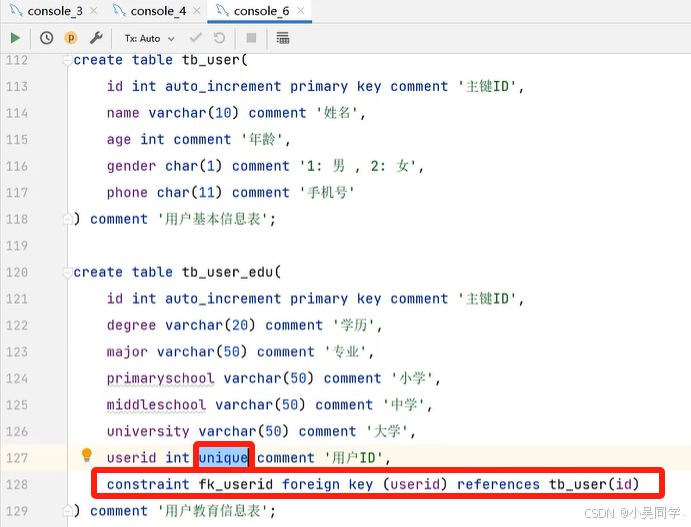
增加外鍵,關聯兩張表。如下圖
? ? ? ? 注意要設置外鍵為唯一的。如下下圖。
2、多表查詢概述:需要消除掉無效的笛卡爾積【常為表取別名:在FROM后面取(因為執行DQL順序是先執行FROM)】

需要消除掉無效的笛卡爾積,只顯示有用的數據

3、多表查詢分類:連接查詢【內、外(左/右)、自連接】、子查詢
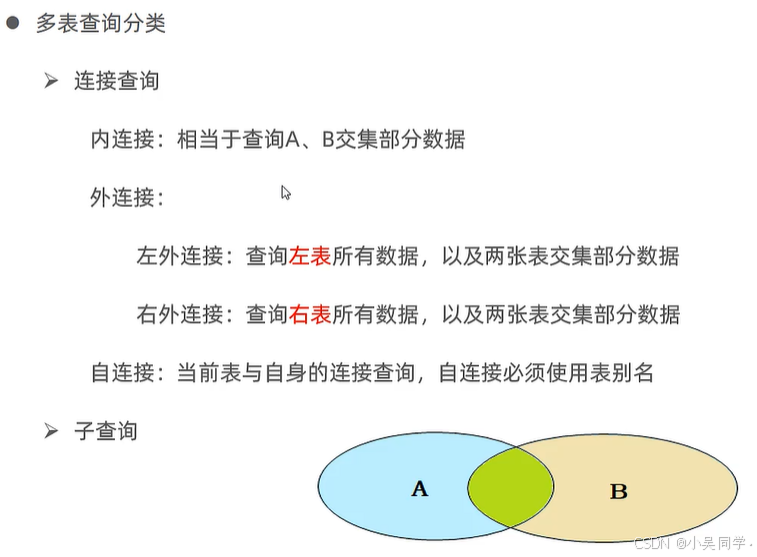
1>內連接(隱式、顯式):查詢兩張表交集的部分


2>外連接(左外、右外):誰取名就以誰為主


3>自連接:自己連接自己
舉例:
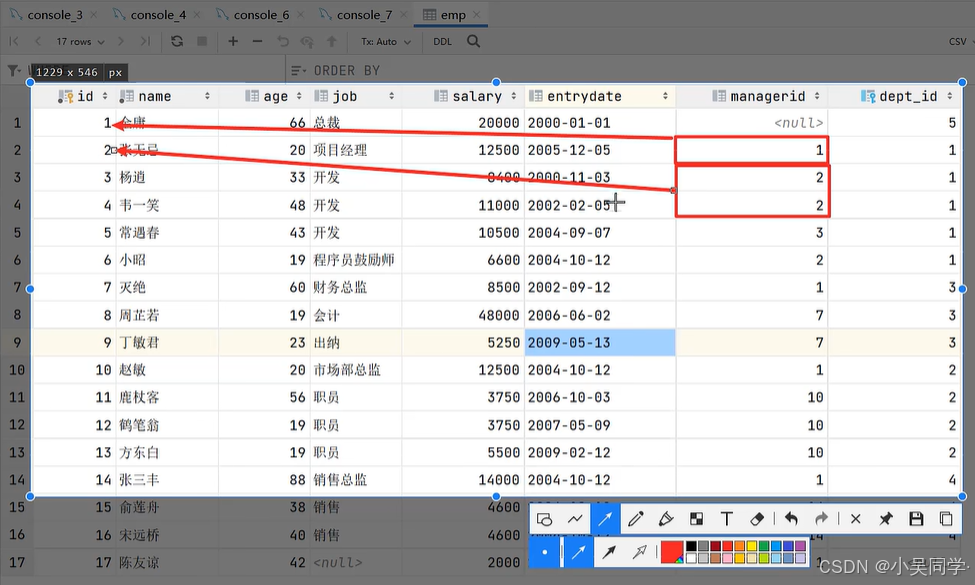
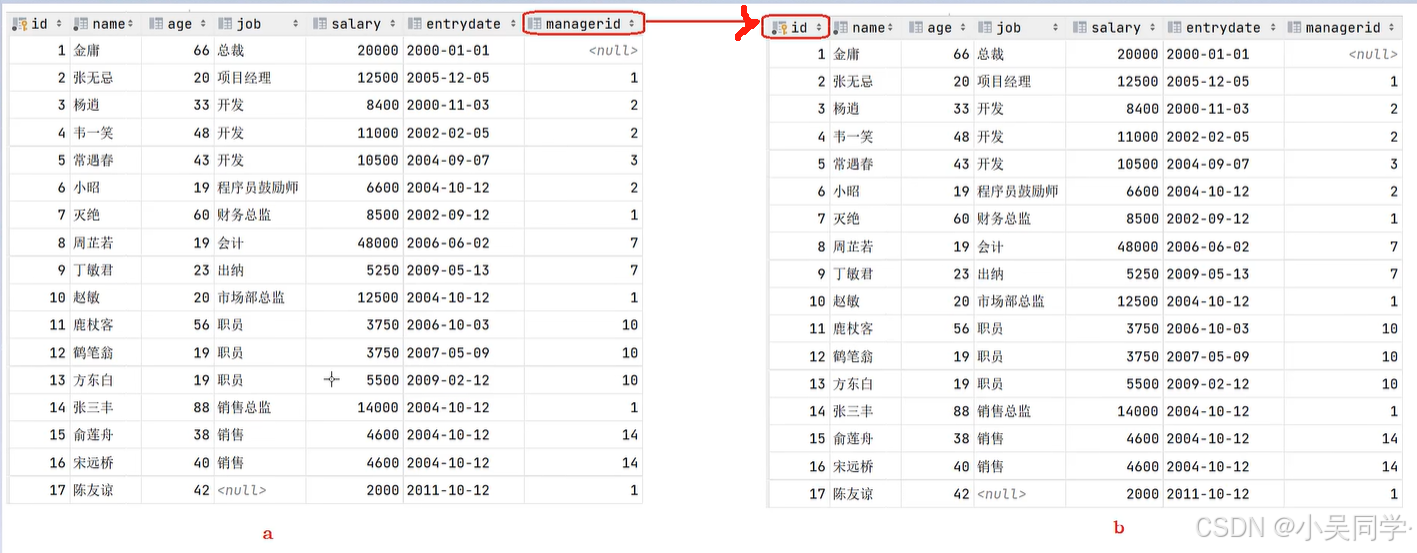
把上圖看作下圖兩張表

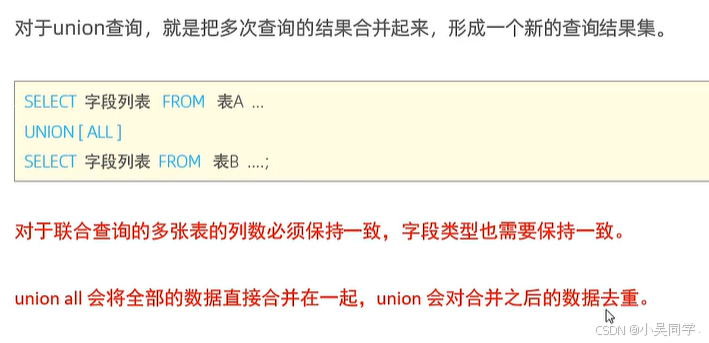
4、聯合查詢(union , union all):把多次查詢的結果合并起來,形成一個新的查詢結果集

5、子查詢(嵌套查詢):SQL語句中嵌套SELECT語句

1>標量子查詢
2>列子查詢
3>行子態詢
4>表子查詢
六、事務
1、事務:一組操作的集合,它是一個不可分割的工作單位(這些操作要么同時成功,要么同時失敗)
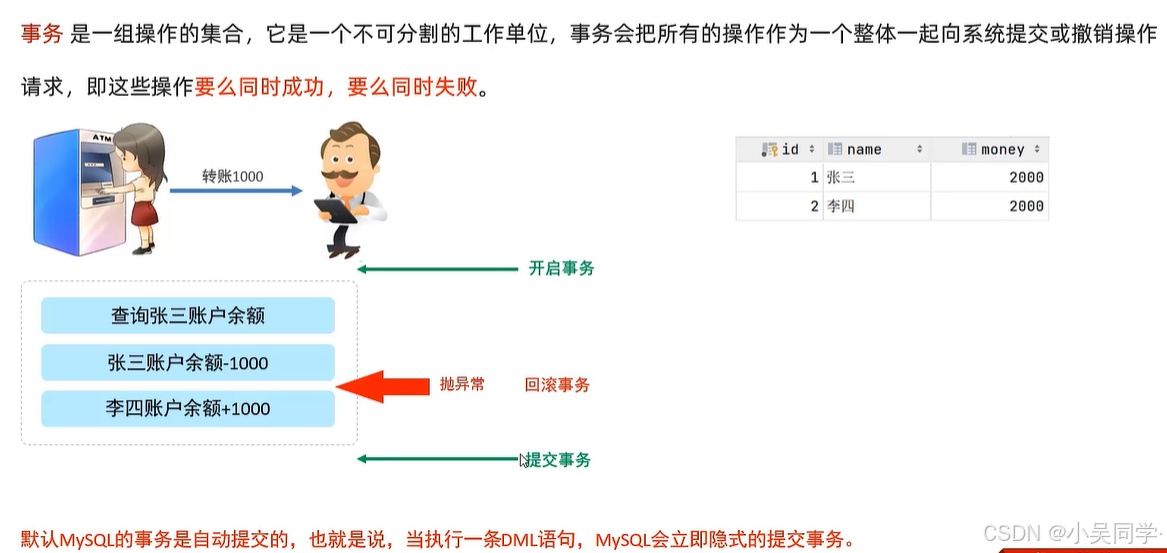
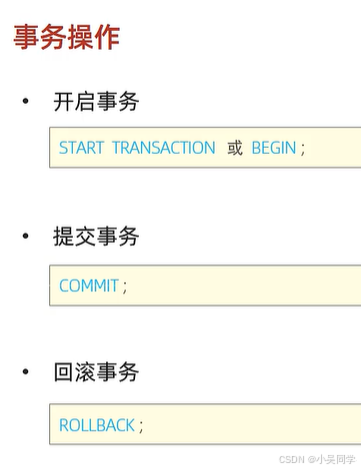
2、事務操作
下面左/右兩圖作用一樣的。
在左圖中,SELECT @@autocommit;
????????如果結果=1,則是自動提交事務;如果結果=0,則是手動提交事務,需要執行commit;
 ?
?
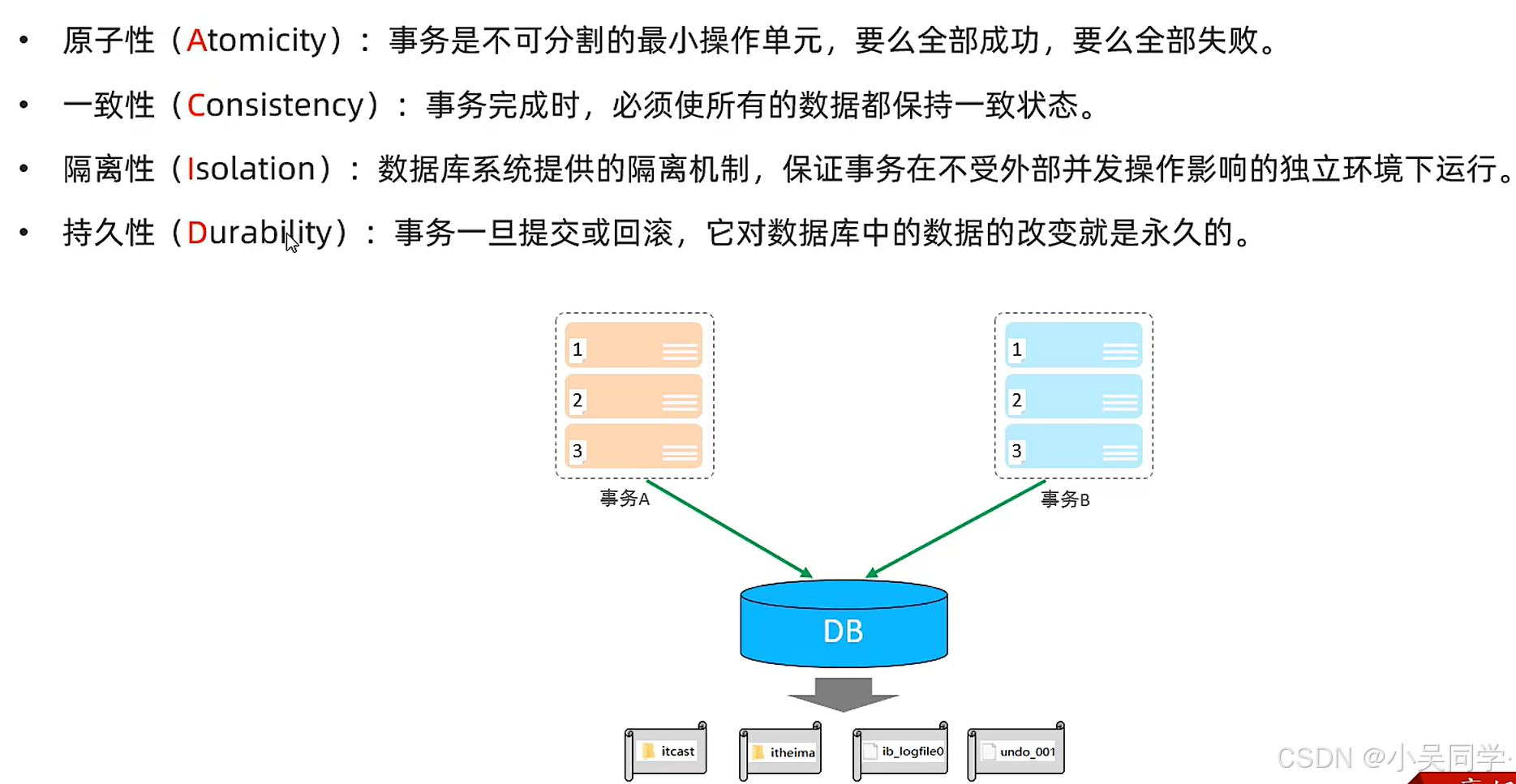
3、事務四大特性(ACID):原子性(A)、一致性(C)、隔離性(I)、持久性(D)
持久性:一旦事務提交,數據就會永久地存儲在磁盤中,如下圖
4、并發事務問題:臟讀、不可重復讀、幻讀

1>臟讀
在下圖中,事務A要執行3個操作。事務A在第二個操作時把id的值更新了,但是此時事務A還沒有提交。事務B卻拿到了更新后的id的值。這種情況稱為”臟讀“。
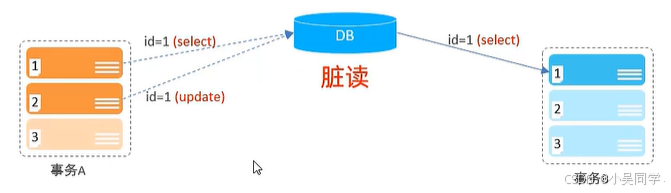
1》問題分析
這屬于典型的“臟讀”問題。
如果事務 A 后續回滾(Rollback),那么事務 B 讀取到的數據實際上是無效的,導致數據不一致。
2》如何避免
提高事務隔離級別到 READ COMMITTED(讀已提交)?或更高。
- READ COMMITTED:確保事務只能讀取已提交的數據,避免臟讀。
2>不可重復讀
在下圖中,事務A要執行4個操作。事務A執行第一個操作時,沒有找到id=1。此后,事務B向數據庫提交了id=1的更新。然后,事務A的第三個操作就讀到了更新后的id數據。這種情況稱為”不可重復讀“。
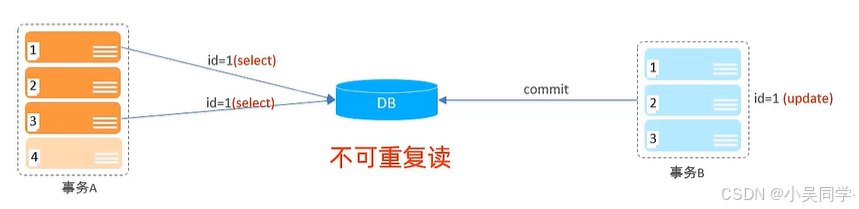
1》問題分析
這屬于“不可重復讀”問題。
事務 A 在同一個事務中對同一條數據的兩次查詢結果不一致,可能導致業務邏輯錯誤
2》如何避免
提高事務隔離級別到 REPEATABLE READ(可重復讀) 或更高。
- REPEATABLE READ:在同一事務中,多次讀取同一數據時,保證結果一致。即確保事務內多次讀取結果一致。
- 不過,在某些數據庫(如 MySQL 的 InnoDB 引擎)中,即使在 REPEATABLE READ 隔離級別下,仍可能出現幻讀問題。
3>幻讀
在下圖中,事務A 執行 id=1(insert)時,由于事務B已經插入了id=1(id是主鍵),那么這句話就會報錯。此時在事務A中再次執行id=1(select),會發現id=1這個主鍵又在了。
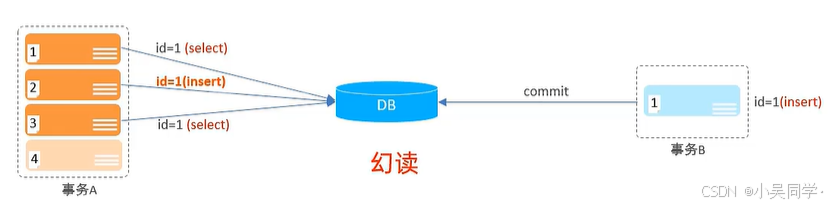
1》問題分析
這屬于“幻讀”問題。
幻讀通常發生在范圍查詢中(例如 SELECT * FROM table WHERE id > 10),但由于主鍵沖突的存在,這種現象也可以被歸類為幻讀的一種表現形式。
2》如何避免
提高事務隔離級別到 SERIALIZABLE(串行化)。
- SERIALIZABLE:最高隔離級別,完全避免臟讀、不可重復讀和幻讀。
- 代價是性能下降,因為事務之間會被串行化執行。
5、事務隔離級別——分析原因見4、
下圖中,?代表允許。
????????SERIALIZABLE(串行化)隔離級別最高,性能卻最差。

舉例:


)
、調參方法)


:編碼注意力機制)

、STM32F1xx_DFP、 ST-Link、STM32CubeMX】)









)

