? ? 在數據分析領域,Python的Pandas庫是一個不可或缺的工具。它提供了高效的數據結構和數據分析工具,使得數據處理變得簡單而直觀。本文將詳細介紹Pandas庫的基本功能、常見用法,并通過示例代碼演示如何使用Pandas進行數據處理。最后,我將用表格的形式梳理總結Pandas庫的常用函數及其參數用法。資源綁定附上完整資源供讀者參考學習!
一、Pandas庫簡介
1.1 什么是Pandas?
Pandas是一個開源的Python庫,專為數據分析而設計。它提供了兩種主要的數據結構:Series(一維數組)和DataFrame(二維表格),使得數據處理更加高效和便捷。
1.2 Pandas的主要特點
-
數據結構:提供了
Series和DataFrame兩種數據結構,適合處理結構化數據。 -
數據讀取:支持多種數據格式的讀取,如CSV、Excel、SQL數據庫等。
-
數據清洗:提供了處理缺失值、重復值、異常值等功能。
-
數據轉換:支持數據的篩選、排序、分組、聚合等操作。
-
數據可視化:集成了Matplotlib,方便進行數據可視化。
1.3 Pandas的應用場景
-
數據分析:用于清洗、轉換和分析數據。
-
數據科學:在數據科學項目中進行數據預處理。
-
金融分析:處理時間序列數據和金融數據。
-
機器學習:作為數據預處理工具,為機器學習模型提供輸入數據。
二、Pandas庫的常見用法
2.1 安裝和導入Pandas
Python
# 安裝Pandas
pip install pandas# 導入Pandas
import pandas as pd2.2 數據讀取
2.2.1 讀取CSV文件
Python
import pandas as pd
# 讀取CSV文件
df = pd.read_csv('2001-2017年北京市水資源情況信息.csv',encoding='gbk')# 顯示前5行數據
print(df.head())

2.2.2 讀取Excel文件
Python
?
# 讀取Excel文件
df = pd.read_excel('data.xlsx')# 顯示前5行數據
print(df.head())?
2.3 數據的基本操作
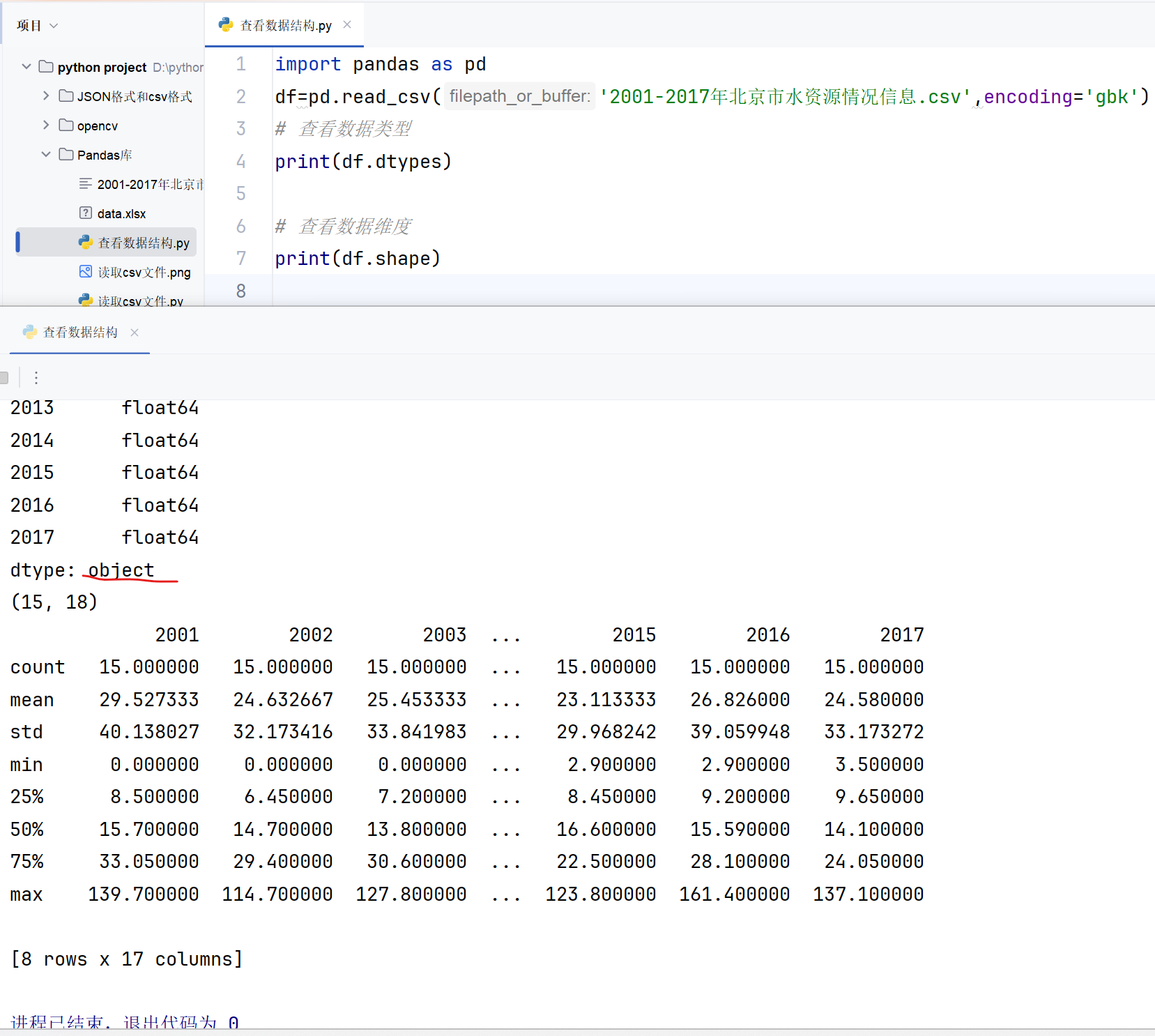
2.3.1 查看數據結構
Python
import pandas as pd
df=pd.read_csv('2001-2017年北京市水資源情況信息.csv',encoding='gbk')
# 查看數據類型
print(df.dtypes)# 查看數據維度
print(df.shape)# 查看數據描述性統計
print(df.describe())
2.3.2 篩選數據
Python
import pandas as pd
df=pd.read_excel('data.xlsx')
# 按列名篩選
print(df['姓名'])# 按條件篩選
print(df[df['總成績'] > 90])# 多條件篩選
print(df[(df['平時成績'] > 90) & (df['總成績'] >90)])
2.3.3 排序數據
Python
import pandas as pd
df=pd.read_excel('data.xlsx')
# 按某一列排序
df_sorted = df.sort_values(by='總成績', ascending=False)
print(df_sorted)# 按多列排序
df_sorted = df.sort_values(by=['平時成績', '總成績'], ascending=[False, True])
print(df_sorted)
2.4 數據清洗
2.4.1 處理缺失值
Python
import pandas as pd
df=pd.read_excel('data.xlsx')
# 查看缺失值
print(df.isnull().sum())# 刪除缺失值
df_cleaned = df.dropna()# 填充缺失值
df_filled = df.fillna(value=0)
2.4.2 處理重復值
Python
import pandas as pd
df=pd.read_excel('data.xlsx')
# 查找重復值
print(df.duplicated())# 刪除重復值
df_unique = df.drop_duplicates()

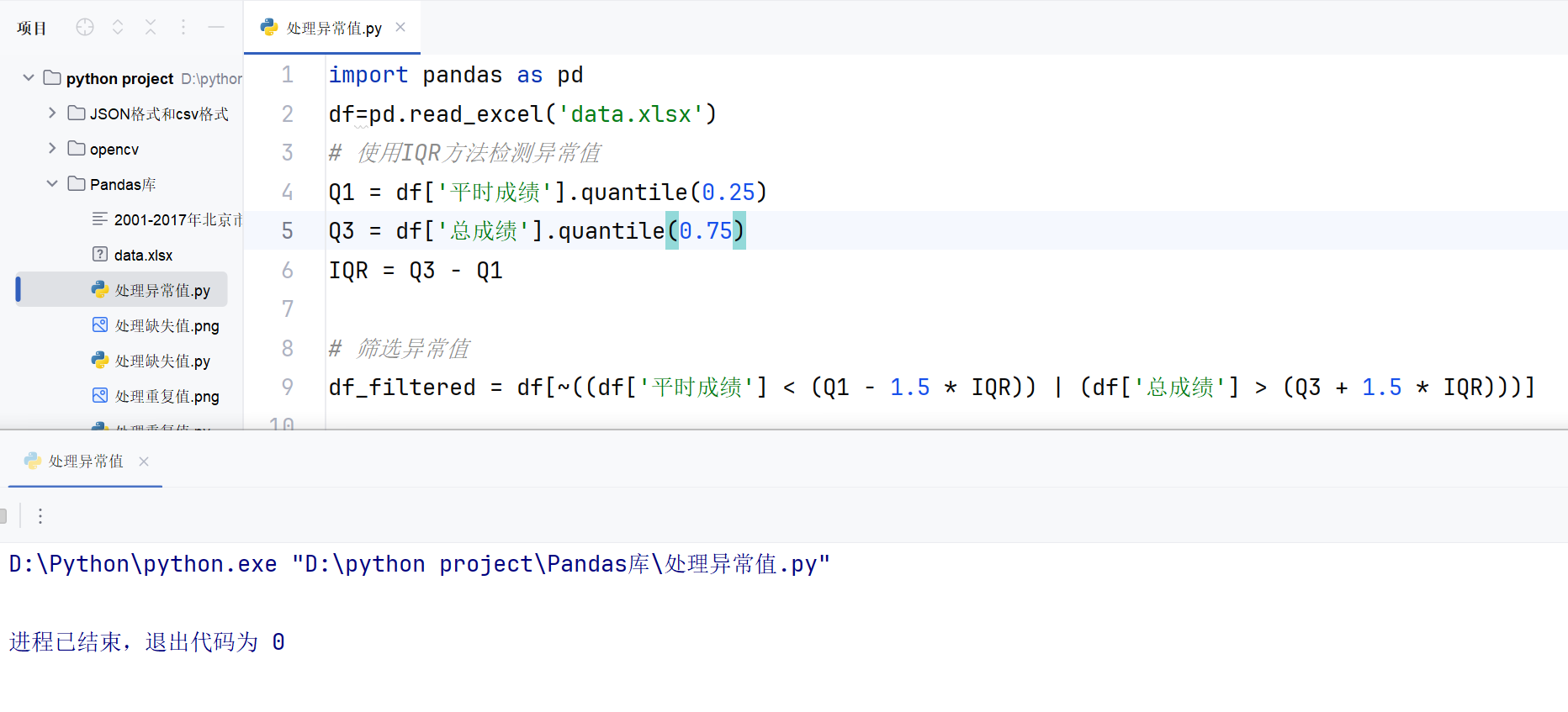
2.4.3 處理異常值
Python
import pandas as pd
df=pd.read_excel('data.xlsx')
# 使用IQR方法檢測異常值
Q1 = df['平時成績'].quantile(0.25)
Q3 = df['總成績'].quantile(0.75)
IQR = Q3 - Q1# 篩選異常值
df_filtered = df[~((df['平時成績'] < (Q1 - 1.5 * IQR)) | (df['總成績'] > (Q3 + 1.5 * IQR)))]
2.5 數據可視化
2.5.1 繪制柱狀圖
Python
import pandas as pd
import matplotlib.pyplot as pltplt.rcParams['font.sans-serif'] = ['SimHei']
df=pd.read_excel('data.xlsx')df['總成績'].value_counts().plot(kind='bar')
plt.show()

2.5.2 繪制折線圖
Python
import pandas as pd
import matplotlib.pyplot as pltplt.rcParams['font.sans-serif'] = ['SimHei']
df=pd.read_excel('data.xlsx')df.plot(x='姓名', y='平時成績', kind='line')
plt.show()
2.5.3 繪制散點圖
Python
import pandas as pd
import matplotlib.pyplot as pltplt.rcParams['font.sans-serif'] = ['SimHei']
df=pd.read_excel('data.xlsx')df.plot(x='學院', y='總成績', kind='scatter')
plt.show()
三、Pandas常用函數及參數總結
| 函數 | 參數 | 說明 | 示例 |
|---|---|---|---|
read_csv | filepath,?sep,?header | 讀取CSV文件 | pd.read_csv('data.csv', sep=',', header=0) |
read_excel | filepath,?sheet_name | 讀取Excel文件 | pd.read_excel('data.xlsx', sheet_name='Sheet1') |
read_sql_query | sql,?con | 從SQL數據庫讀取數據 | pd.read_sql_query("SELECT * FROM table", conn) |
head | n | 顯示前n行數據 | df.head(5) |
tail | n | 顯示后n行數據 | df.tail(5) |
describe | include,?exclude | 顯示數據的描述性統計 | df.describe(include='all') |
dtypes | - | 顯示數據類型 | df.dtypes |
shape | - | 顯示數據維度 | df.shape |
sort_values | by,?ascending | 按列排序 | df.sort_values(by='column', ascending=False) |
groupby | by | 按列分組 | df.groupby('column') |
sum | axis,?numeric_only | 求和 | df.sum(axis=0, numeric_only=True) |
mean | axis,?numeric_only | 求平均值 | df.mean(axis=0, numeric_only=True) |
dropna | axis,?how,?thresh | 刪除缺失值 | df.dropna(axis=0, how='any', thresh=2) |
fillna | value,?method | 填充缺失值 | df.fillna(value=0, method='ffill') |
duplicated | subset,?keep | 查找重復值 | df.duplicated(subset=['column1', 'column2'], keep='first') |
drop_duplicates | subset,?keep | 刪除重復值 | df.drop_duplicates(subset=['column1', 'column2'], keep='first') |
value_counts | normalize,?dropna | 計算唯一值的頻率 | df['column'].value_counts(normalize=True, dropna=False) |
plot | x,?y,?kind | 繪制圖表 | df.plot(x='column1', y='column2', kind='scatter') |
四、總結
Pandas庫是Python數據分析的核心工具之一,提供了豐富的功能和便捷的操作方式。通過本文的介紹和示例代碼,相信你已經對Pandas庫有了初步的了解。以下是Pandas庫的主要優勢:
-
高效的數據結構:
Series和DataFrame使得數據處理更加直觀和高效。 -
豐富的數據操作:支持數據讀取、清洗、轉換、分析和可視化等多種操作。
-
廣泛的適用性:適用于數據分析、數據科學、金融分析等多個領域。
希望本文能幫助你更好地理解和使用Pandas庫,提高數據分析的效率和質量。如果你有任何問題或建議,歡迎在評論區留言!資源綁定附上完整資源供讀者參考學習!

:編碼注意力機制)

、STM32F1xx_DFP、 ST-Link、STM32CubeMX】)









)




)
和env(safe-area-inset-bottom)在uniapp中的使用方法解析)