1. 作者介紹
郭建東,男,西安工程大學電子信息學院,2024級研究生
研究方向:機器視覺與人工智能
電子郵件:1229963266@qq.com
高金年,男,西安工程大學電子信息學院,2024級研究生,張宏偉人工智能課題組
研究方向:機器人與智能裝備控制技術
電子郵件:2432529790@qq.com
2. 調用通義千問實現語音合成并將合成的音頻通過揚聲器播放
2.1.通義千問語音合成簡介
通義千問是阿里云推出的一個大型語言模型,基于先進的深度學習技術打造,能夠理解和生成自然語言,在多輪對話、知識問答等多種應用場景中發揮重要作用。
優點:它具有高度準確的語言理解能力,能精準把握用戶問題和意圖;支持多種語言輸入輸出,如中文、英文等;還具備出色的多輪對話支持能力,可依據上下文進行交互,提供自然流暢的對話體驗。
2.2語音合成
語音合成,又稱文本轉語音(Text-to-Speech,TTS),是將文本轉換為自然語音的技術。該技術基于機器學習算法,通過學習大量語音樣本,掌握語言的韻律、語調和發音規則,從而在接收到文本輸入時生成真人般自然的語音內容。
作用:在通義千問的應用生態中,語音合成技術至關重要。它將模型生成的文本轉化為語音,實現了人機交互的語音化,讓用戶能通過語音接收信息,極大地提升了交互的便捷性和自然度。
例如在智能客服場景中,用戶提問后,通義千問給出的回答可通過語音合成直接播報,無需用戶閱讀文字,尤其適用于不方便看屏幕的場景,提高了服務效率和用戶體驗。
2.3.通義千問語音合成算法
- CosyVoice 模型介紹:
CosyVoice是通義實驗室依托大規模預訓練語言模型,深度融合文本理解和語音生成的新一代生成式語音合成大模型,在自然語音生成方面表現卓越。支持多語言生成,涵蓋中文、英文、日文、粵語和韓語五種語言,滿足不同地區用戶的需求;具備強大的音色和情感控制能力,僅需3 - 10秒的原始音頻,就能生成模擬音色,包含韻律和情感等細節,還能通過富文本或自然語言形式對生成語音的情感和韻律進行細粒度控制,使生成的語音更加生動自然。 - 語音合成算法原理
(1) 文本分析:對輸入的文本進行深入分析,包括詞匯、語法、語義理解,識別文本中的關鍵詞、短語結構以及語義關系,為后續的語音參數生成提供基礎。例如分析句子“今天天氣真好”,確定“今天”是時間詞,“天氣真好”表達積極的天氣狀況描述。
(2) 聲學模型:根據文本分析結果,結合聲學知識,預測生成語音所需的聲學參數,如基頻、共振峰、時長等,這些參數決定了語音的音高、音色和語速等特征。
(3) 波形生成:利用預測得到的聲學參數,通過特定的算法生成語音波形,最終轉化為可播放的音頻信號。
3. 代碼實現
3.1開通服務并獲取 API - KEY
(1) 百度搜索阿里云
(2) 注冊賬號

3)擊右側控制臺
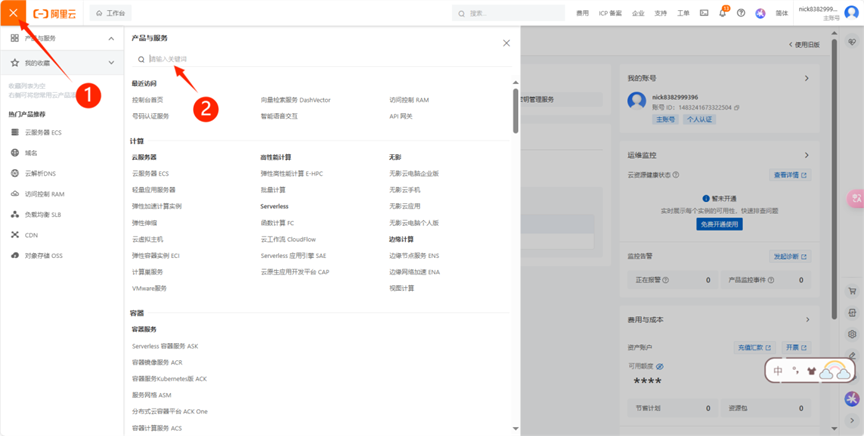
(4) 點擊左邊導航搜索向量檢索服務DashVector
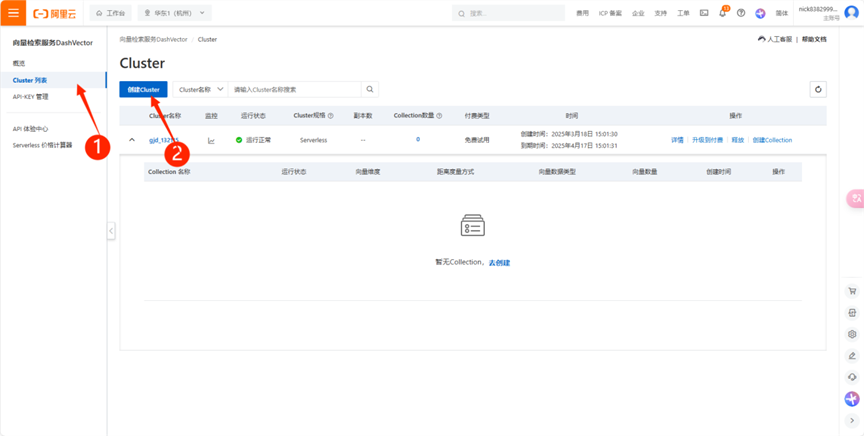
(5) 在Cluster列表中,點擊創建Cluster
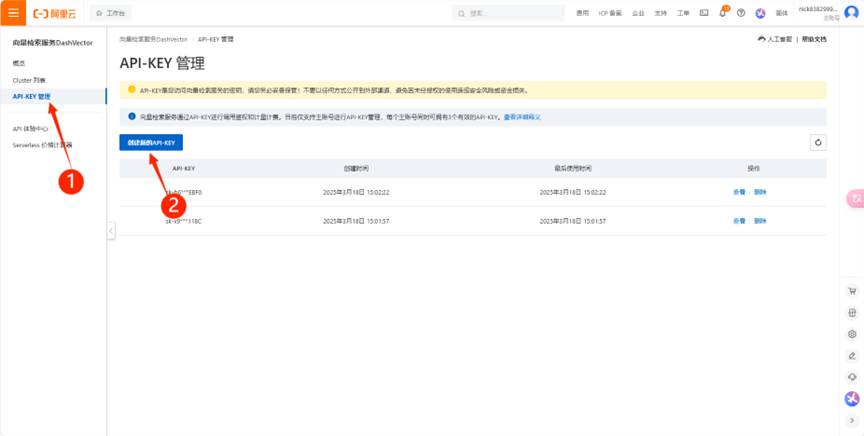
(6) 在API-KEY管理中,創建自己的API-KEY密鑰
3.2將獲取的 API - KEY配置到環境變量
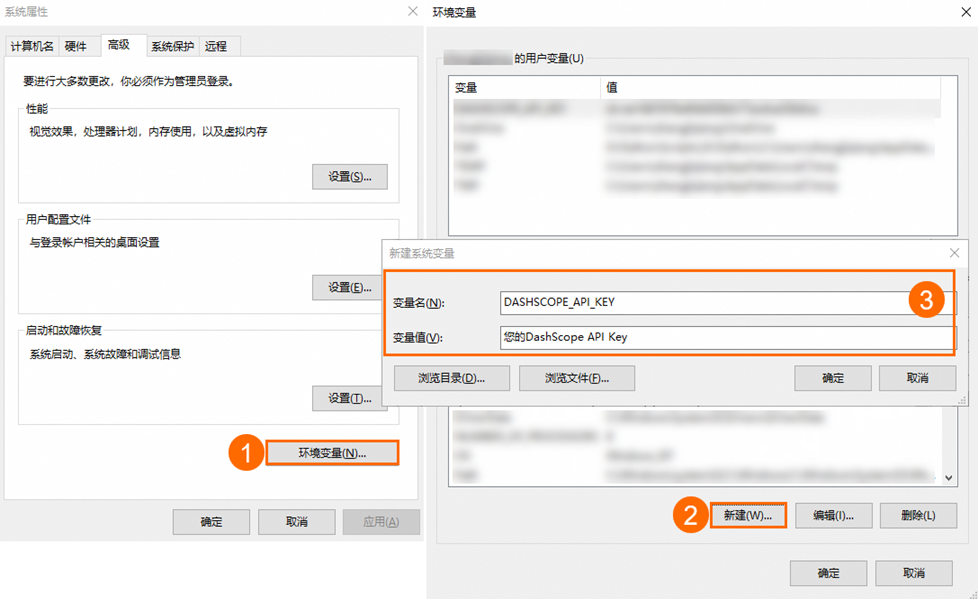
(1) 在Windows系統桌面中按Win+Q鍵,在搜索框中搜索編輯系統環境變量,單擊打開系統屬性界面。
(2) 在系統屬性窗口,單擊環境變量,然后在系統變量區域下單擊新建,變量名填DASHSCOPE_API_KEY,變量值填入您的DashScope API Key。
(3) 依次單擊三個窗口的確定,關閉系統屬性配置頁面,完成環境變量配置。
(4) 打開CMD(命令提示符)窗口或Windows PowerShell窗口,執行如下命令檢查環境變量是否生效。
CMD查詢命令:echo %DASHSCOPE_API_KEY%

3.3 安裝最新版 SDK
通過運行以下命令安裝DashScope Python SDK:pip install -U dashscope
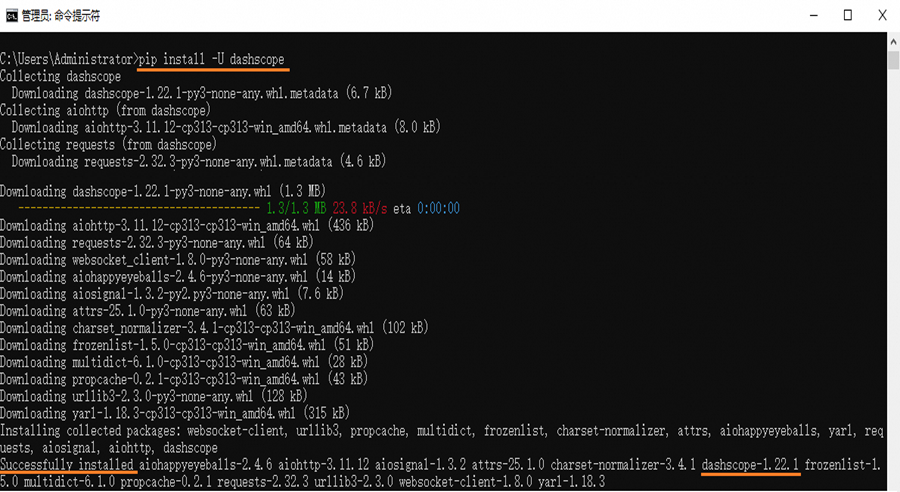
當終端出現Successfully installed … dashscope-x.x.x的提示后,表示您已經成功安裝DashScope Python SDK。
3.4 安裝需要的庫
(1) 首先需要創建虛擬環境
(2) 在搜索欄中輸入Windows PowerShell,以 管理員身份 運行(避免權限問題)。
(3) 創建一個新虛擬環境,名字為py39_env(可以自己改)。

(4) 激活環境。

(5) 安裝需要的庫

3.5運行代碼
若沒有將API Key配置到環境變量中,需將下面這行代碼注釋放開,并將apiKey替換為自己的API Key——# dashscope.api_key = “apiKey”
import pyaudio
import dashscope
from dashscope.audio.tts_v2 import *from http import HTTPStatus
from dashscope import Generation# 若沒有將API Key配置到環境變量中,需將下面這行代碼注釋放開,并將apiKey替換為自己的API Key
# dashscope.api_key = "apiKey"
model = "cosyvoice-v1"
voice = "longxiaochun"class Callback(ResultCallback):_player = None_stream = Nonedef on_open(self):print("websocket is open.")self._player = pyaudio.PyAudio()self._stream = self._player.open(format=pyaudio.paInt16, channels=1, rate=22050, output=True)def on_complete(self):print("speech synthesis task complete successfully.")def on_error(self, message: str):print(f"speech synthesis task failed, {message}")def on_close(self):print("websocket is closed.")# stop playerself._stream.stop_stream()self._stream.close()self._player.terminate()def on_event(self, message):print(f"recv speech synthsis message {message}")def on_data(self, data: bytes) -> None:print("audio result length:", len(data))self._stream.write(data)def synthesizer_with_llm():callback = Callback()synthesizer = SpeechSynthesizer(model=model,voice=voice,format=AudioFormat.PCM_22050HZ_MONO_16BIT,callback=callback,)messages = [{"role": "user", "content": "請介紹一下你自己"}]responses = Generation.call(model="qwen-turbo",messages=messages,result_format="message", # set result format as 'message'stream=True, # enable stream outputincremental_output=True, # enable incremental output )for response in responses:if response.status_code == HTTPStatus.OK:print(response.output.choices[0]["message"]["content"], end="")synthesizer.streaming_call(response.output.choices[0]["message"]["content"])else:print("Request id: %s, Status code: %s, error code: %s, error message: %s"% (response.request_id,response.status_code,response.code,response.message,))synthesizer.streaming_complete()print('requestId: ', synthesizer.get_last_request_id())if __name__ == "__main__":synthesizer_with_llm()
4.參考鏈接
https://help.aliyun.com/zh/model-studio/user-guide/text-to-speech?spm=a2c4g.11186623.help-menu-2400256.d_1_0_4.53e247bbJYVV91&scm=20140722.H_2842586._.OR_help-T_cn~zh-V_1
(點擊CosyVoice的將LLM生成的文本實時轉成語音并通過揚聲器播放模塊,點擊Python運行的代碼進行復制。)





)


)




)





