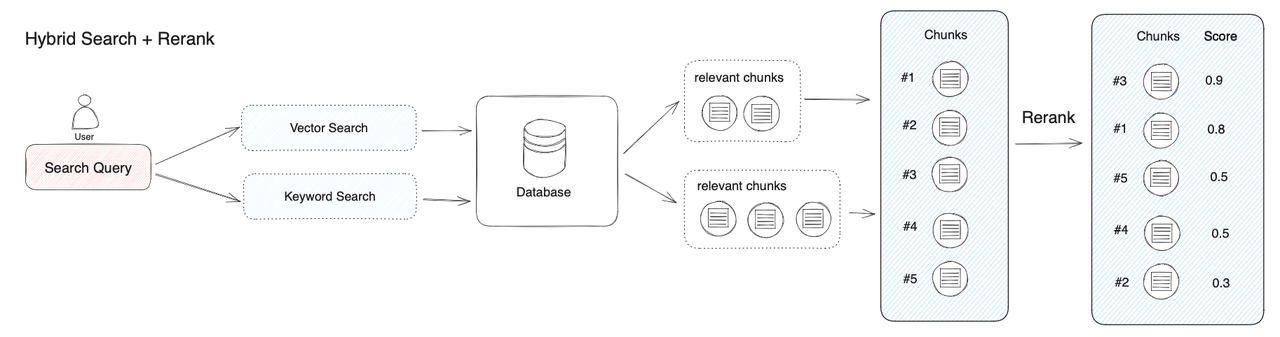
一.RAG 基本架構
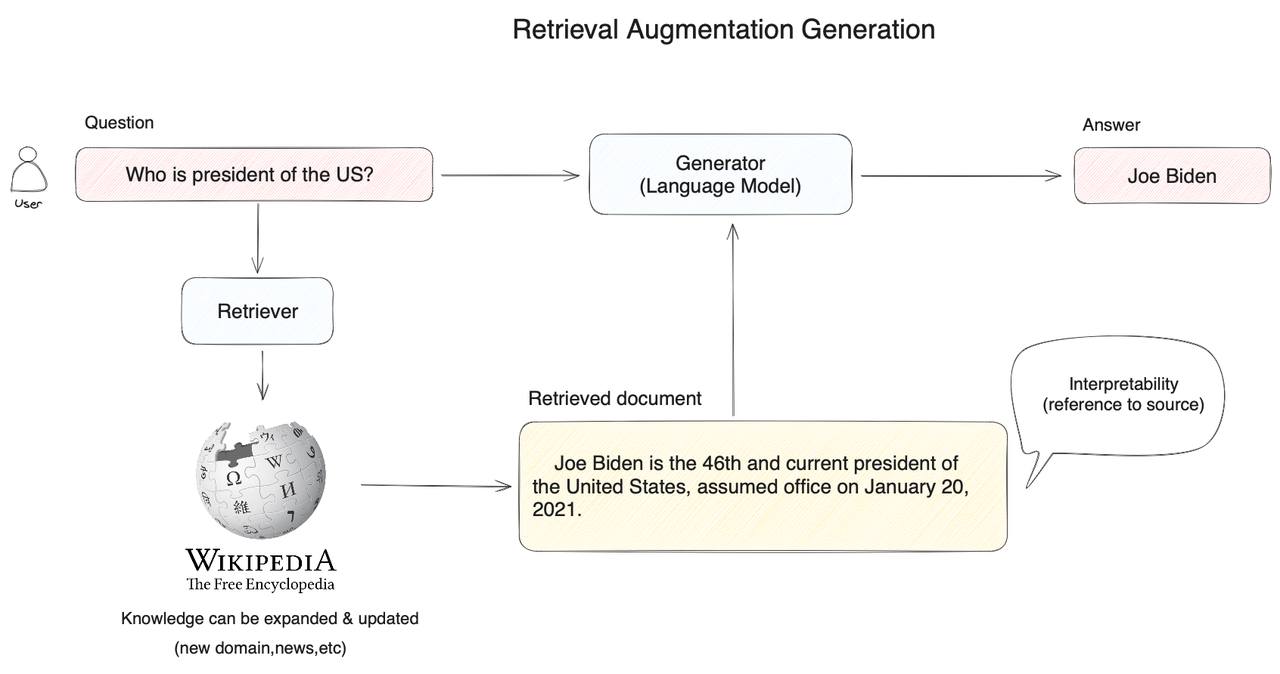
當用戶提問 “美國總統是誰?” 時,系統并不是將問題直接交給大模型來回答,而是先將用戶問題在知識庫中進行向量搜索,通過語義相似度匹配的方式查詢到相關的內容(拜登是美國現任第46屆總統…),然后再將用戶問題和搜索到的相關知識提供給大模型,使得大模型獲得足夠完備的知識來回答問題,以此獲得更可靠的問答結果。
二.混合檢索
1.為什么需要混合檢索
向量檢索優勢:復雜語義的文本查找,相近語義理解,多語言理解,多模態理解,容錯性。傳統關鍵詞搜索優勢:精確匹配,少量字符的匹配,傾向低頻詞匯的匹配。向量檢索和關鍵詞檢索在檢索領域各有其優勢。混合檢索通過多個檢索系統的組合,實現了多個檢索技術之間的互補。
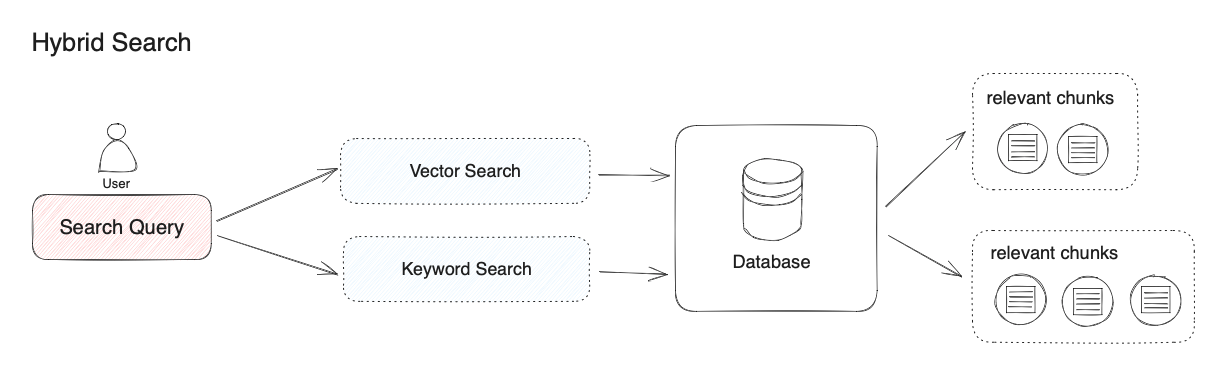
2.向量檢索
通過生成查詢嵌入并查詢與其向量表示最相似的文本分段。
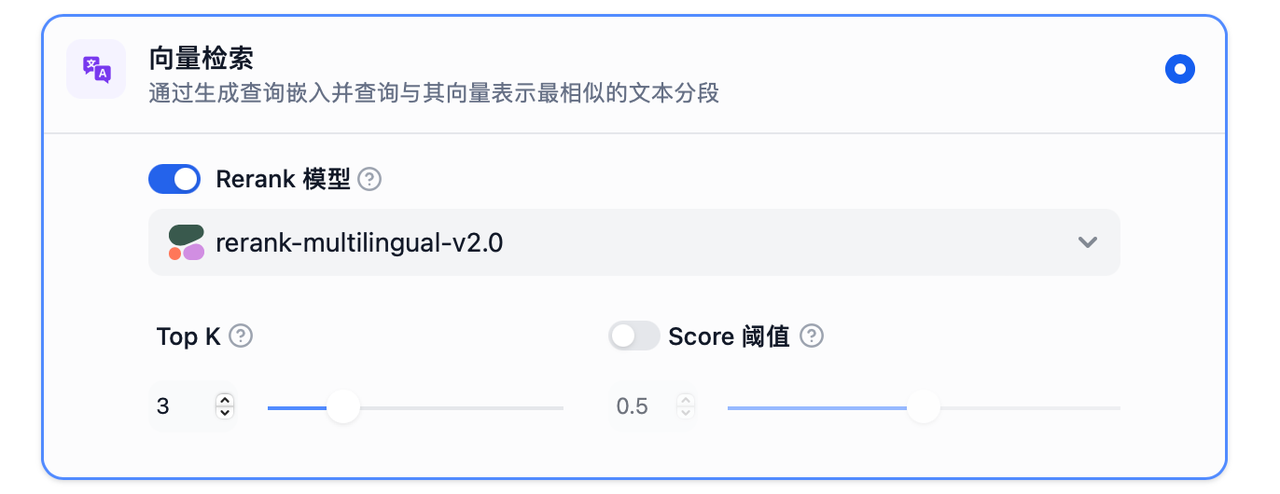
TopK:用于篩選與用戶問題相似度最高的文本片段。系統同時會根據選用模型上下文窗口大小動態調整片段數量。系統默認值為 3 。
Score 閾值:用于設置文本片段篩選的相似度閾值,即:只召回超過設置分數的文本片段。系統默認關閉該設置,即不會對召回的文本片段相似值過濾。打開后默認值為 0.5 。
Rerank 模型:可以在"模型供應商"頁面配置 Rerank 模型的 API 秘鑰之后,在檢索設置中打開"Rerank 模型",系統會在語義檢索后對已召回的文檔結果再一次進行語義重排序,優化排序結果。設置 Rerank 模型后,TopK 和 Score 閾值設置僅在 Rerank 步驟生效。
3.全文檢索
索引文檔中的所有詞匯,從而允許用戶查詢任意詞匯,并返回包含這些詞匯的文本片段。
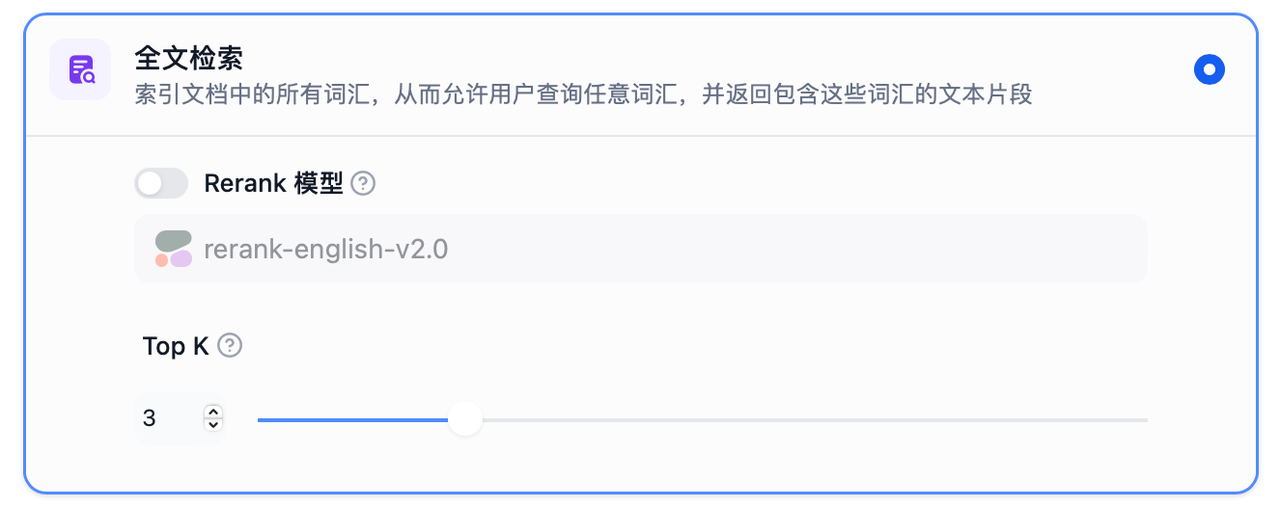
TopK:用于篩選與用戶問題相似度最高的文本片段。系統同時會根據選用模型上下文窗口大小動態調整片段數量。系統默認值為 3 。
Rerank 模型:可在"模型供應商"頁面配置 Rerank 模型的 API 秘鑰之后,在檢索設置中打開"Rerank 模型",系統會在全文檢索后對已召回的文檔結果再一次進行語義重排序,優化排序結果。設置 Rerank 模型后,TopK 和 Score 閾值設置僅在 Rerank 步驟生效。
4.混合檢索
同時執行全文檢索和向量檢索,并應用重排序步驟,從兩類查詢結果中選擇匹配用戶問題的最佳結果,需配置 Rerank 模型 API。
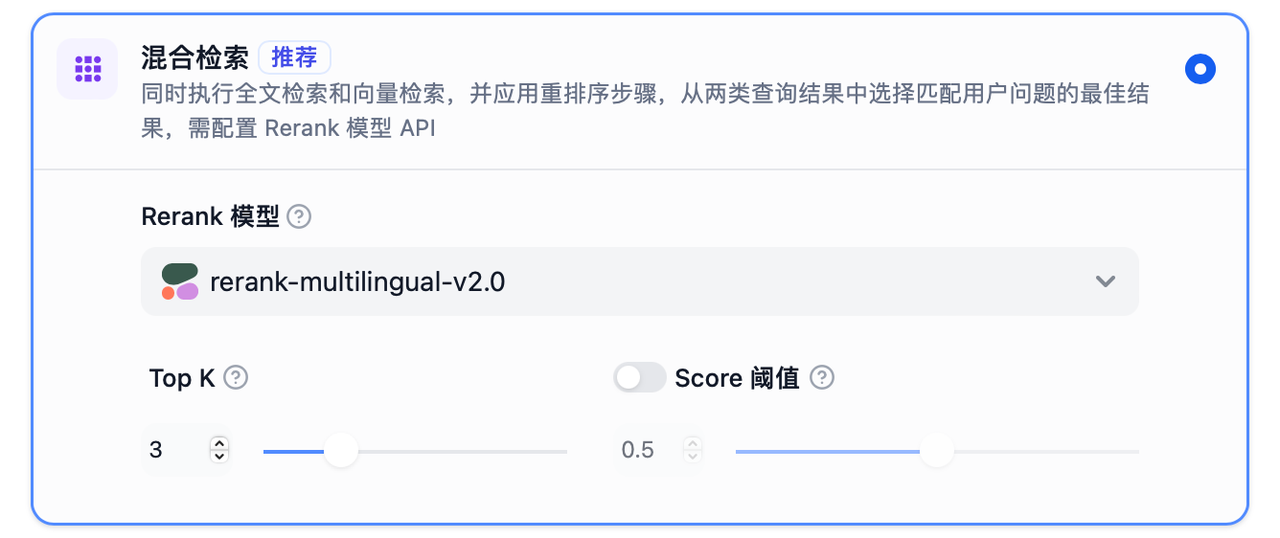
TopK:用于篩選與用戶問題相似度最高的文本片段。系統同時會根據選用模型上下文窗口大小動態調整片段數量。系統默認值為 3 。
Rerank 模型:可在"模型供應商"頁面配置 Rerank 模型的 API 秘鑰之后,在檢索設置中打開"Rerank 模型",系統會在混合檢索后對已召回的文檔結果再一次進行語義重排序,優化排序結果。設置 Rerank 模型后,TopK 和 Score 閾值設置僅在 Rerank 步驟生效。
5.創建數據集時設置檢索模式
通過進入“數據集->創建數據集”頁面并在檢索設置中設置不同的檢索模式:
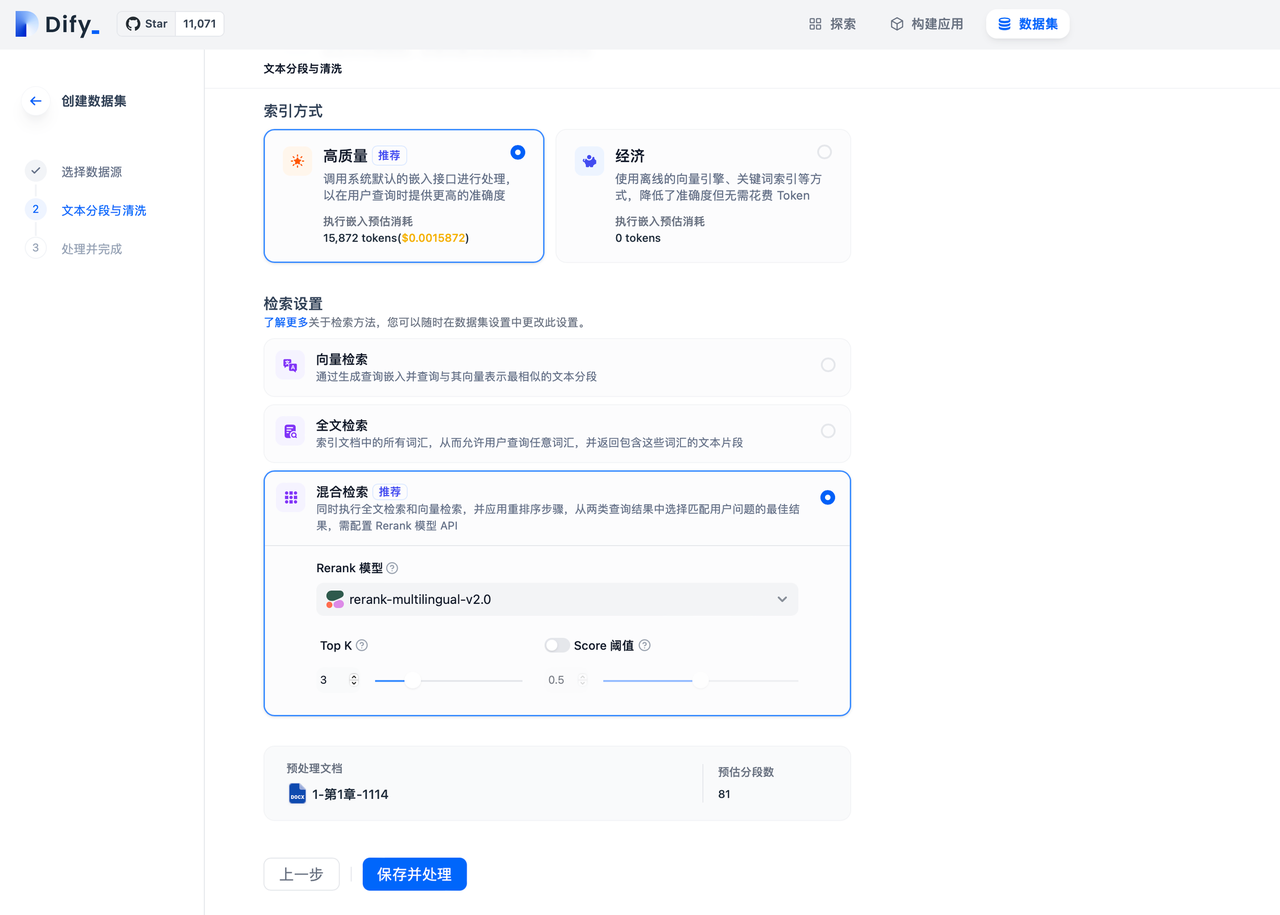
6.數據集設置中修改檢索模式
通過進入“數據集->選擇數據集->設置”頁面中可以對已創建的數據集修改不同的檢索模式。
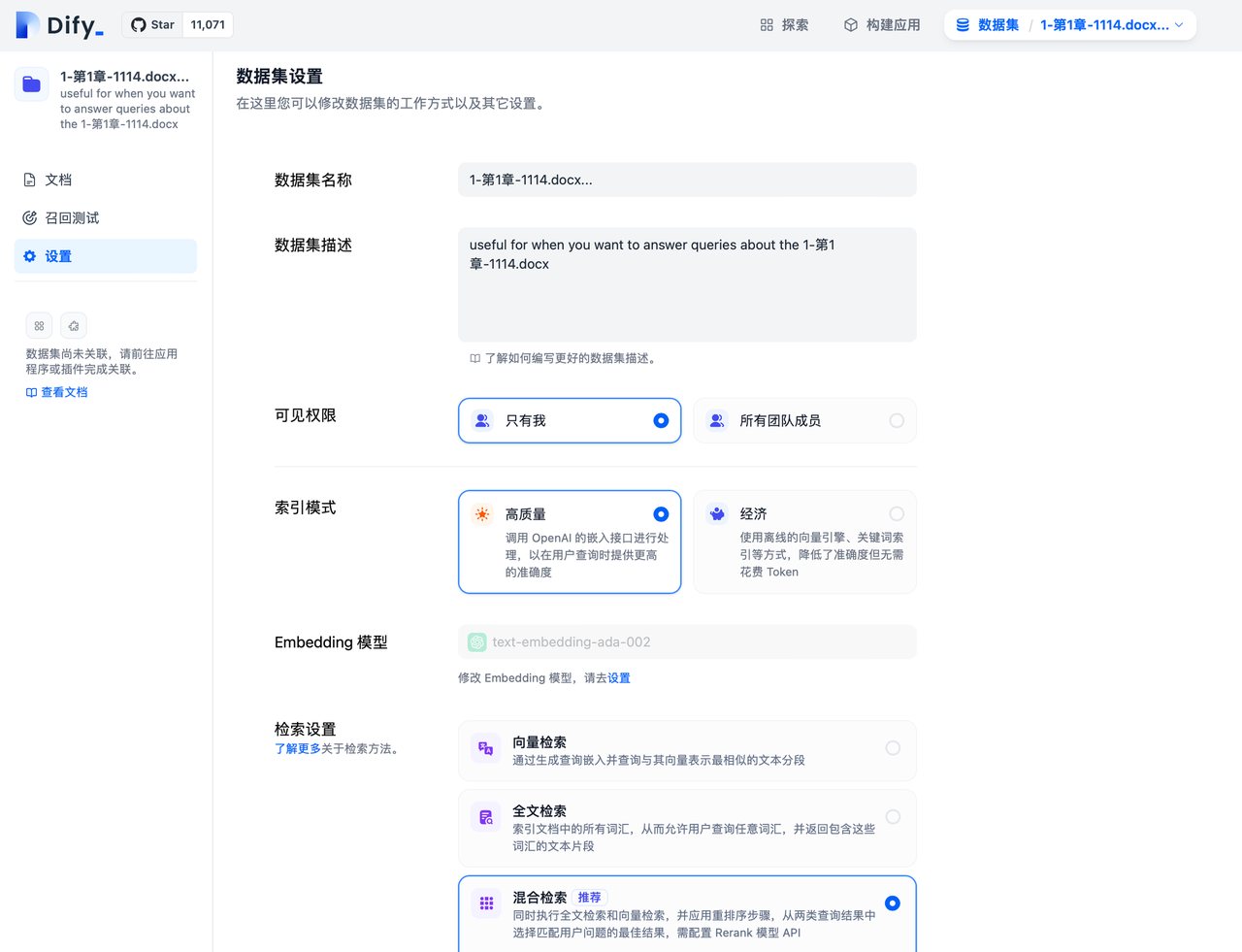
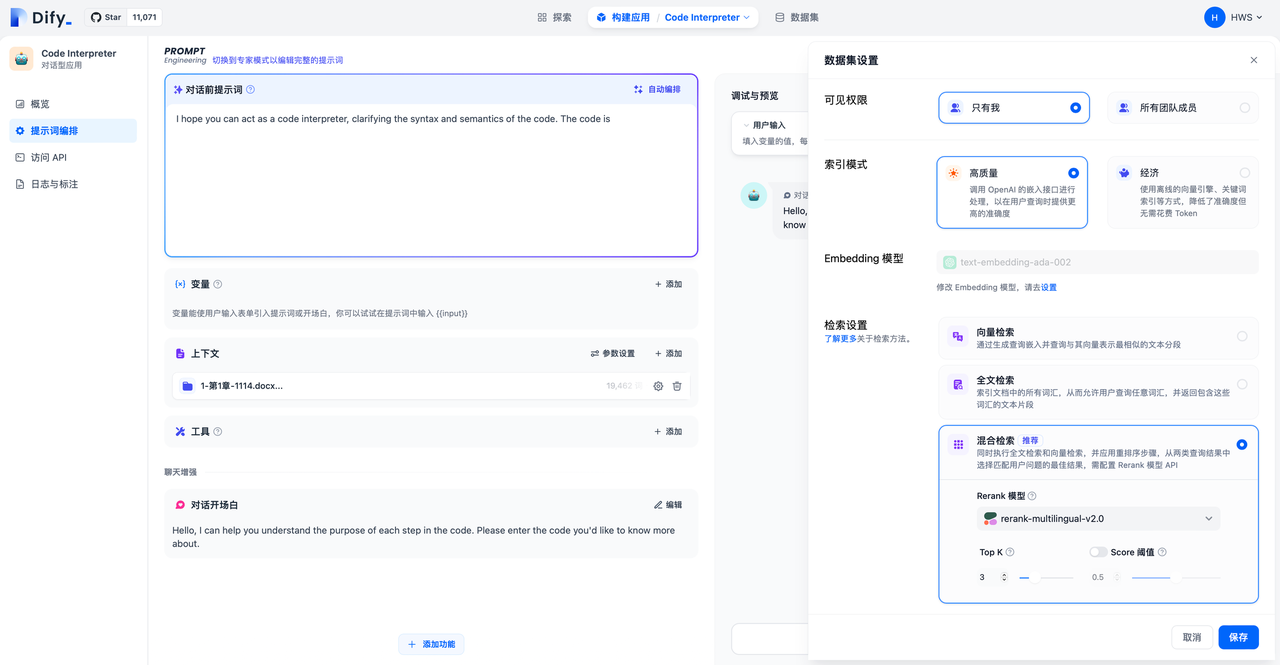
7.提示詞編排中修改檢索模式
通過進入“提示詞編排->上下文->選擇數據集->設置”頁面中可以在創建應用時修改不同的檢索模式。
三.重排序
1.為什么需要重排序
重排序模型會計算候選文檔列表與用戶問題的語義匹配度,根據語義匹配度重新進行排序,從而改進語義排序的結果。其原理是計算用戶問題與給定的每個候選文檔之間的相關性分數,并返回按相關性從高到低排序的文檔列表。常見的 Rerank 模型如:Cohere rerank、bge-reranker 等。重排序一般都放在搜索流程的最后階段,非常適合用于合并和排序來自不同檢索系統的結果。
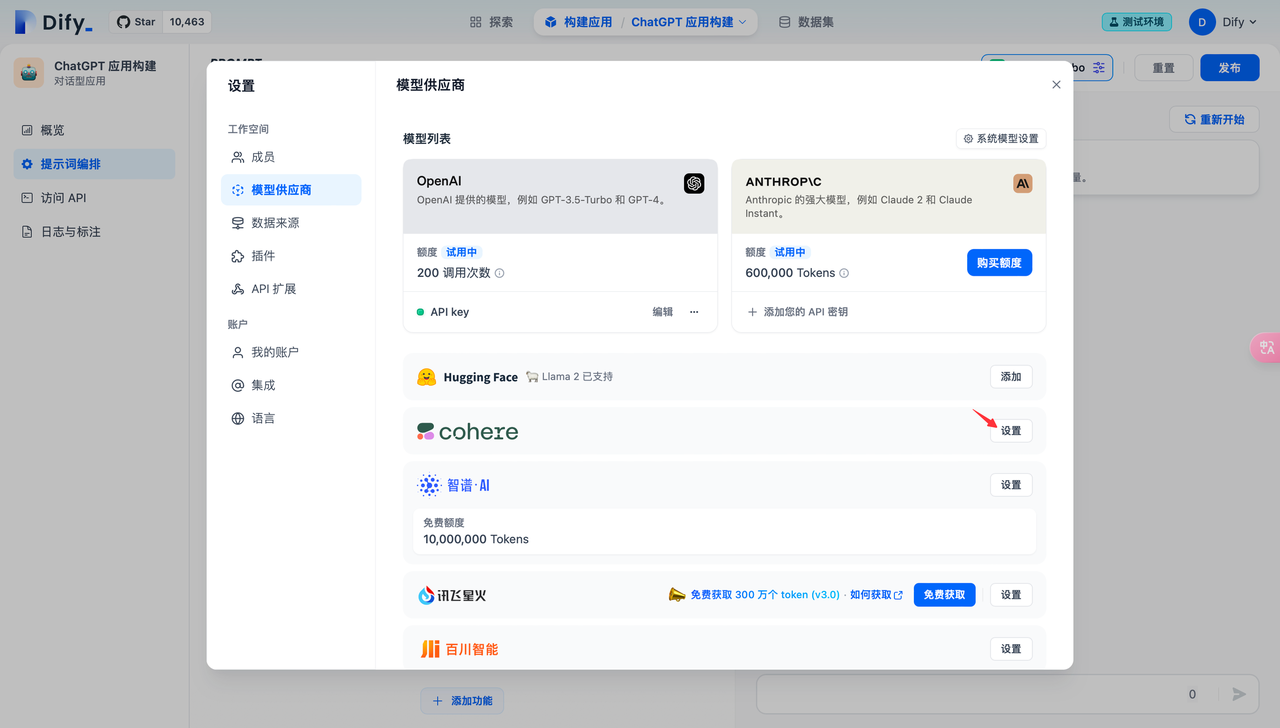
2.如何配置 Rerank 模型
Dify 目前已支持 Cohere Rerank 模型,通過進入“模型供應商-> Cohere”頁面填入 Rerank 模型的 API 秘鑰:
3.如何獲取 Cohere Rerank 模型
登錄:https://cohere.com/rerank,在頁內注冊并申請 Rerank 模型的使用資格,獲取 API 秘鑰。
4.數據集檢索模式中設置 Rerank 模型
通過進入“數據集->創建數據集->檢索設置”頁面并在添加 Rerank 設置。除了在創建數據集可以設置 Rerank ,也可在已創建的數據集設置內更改 Rerank 配置,在應用編排的數據集召回模式設置中更改 Rerank 配置。
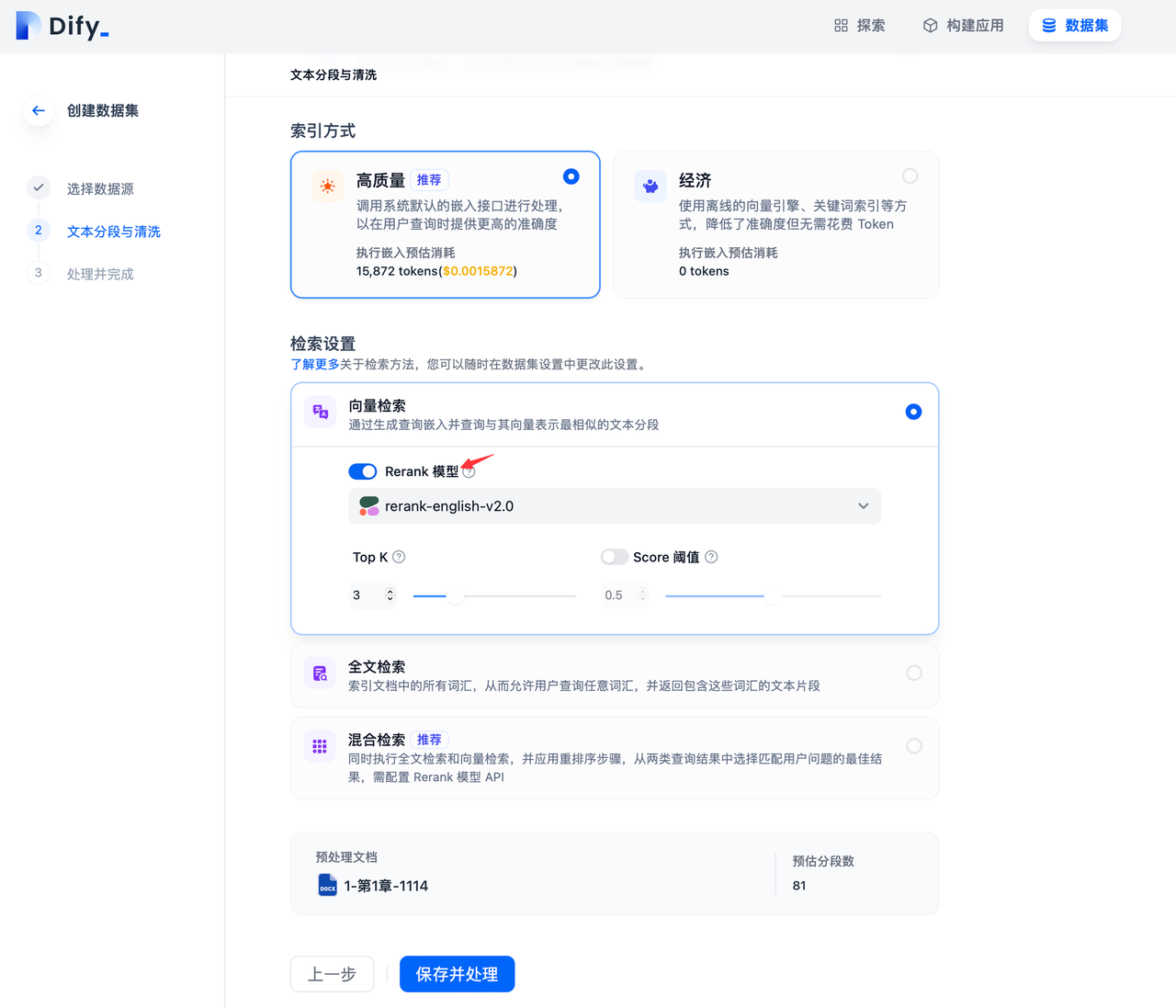
TopK:用于設置 Rerank 后返回相關文檔的數量。
Score 閾值:用于設置 Rerank 后返回相關文檔的最低分值。設置 Rerank 模型后,TopK 和 Score 閾值設置僅在 Rerank 步驟生效。
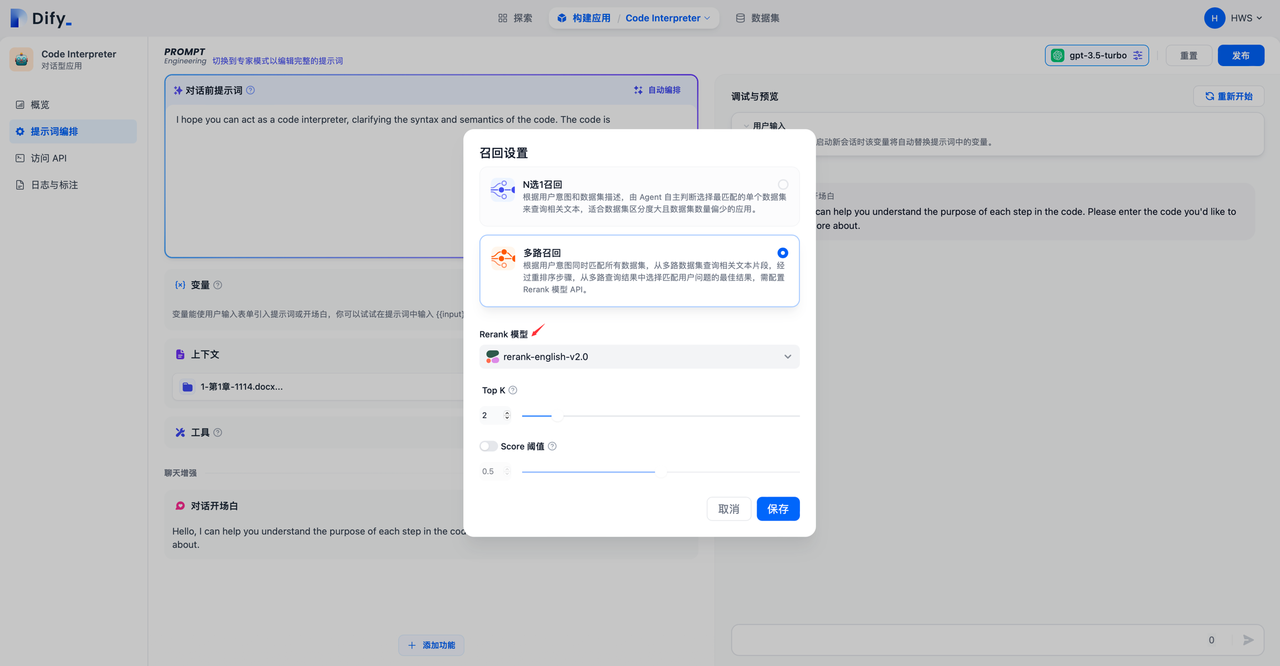
5.數據集多路召回模式中設置 Rerank 模型
通過進入“提示詞編排->上下文->設置”頁面中設置為多路召回模式時需開啟 Rerank 模型。
四.召回模式
當用戶構建知識庫問答類的 AI 應用時,如果在應用內關聯了多個數據集,Dify 在檢索時支持兩種召回模式:N選1召回模式和多路召回模式。
1.N選1召回模式
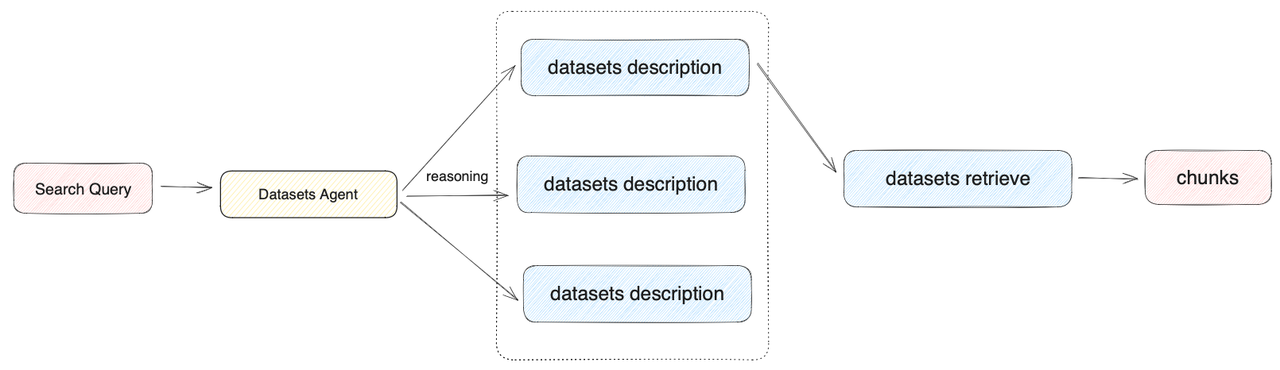
在用戶上傳數據集時,系統將自動為數據集創建一個摘要式的描述。為了在該模式下獲得最佳的召回效果,可以"數據集->設置->數據集描述"中查看到系統默認創建的摘要描述,并檢查該內容是否可以清晰的概括數據集的內容。根據用戶意圖和數據集描述,由 Agent 自主判斷選擇最匹配的單個數據集來查詢相關文本,適合數據集區分度大且數據集數量偏少的應用。
提示:OpenAI Function Call已支持多個工具調用,Dify將在后續版本中升級該模式為"N選M召回"。
2.多路召回模式(推薦)
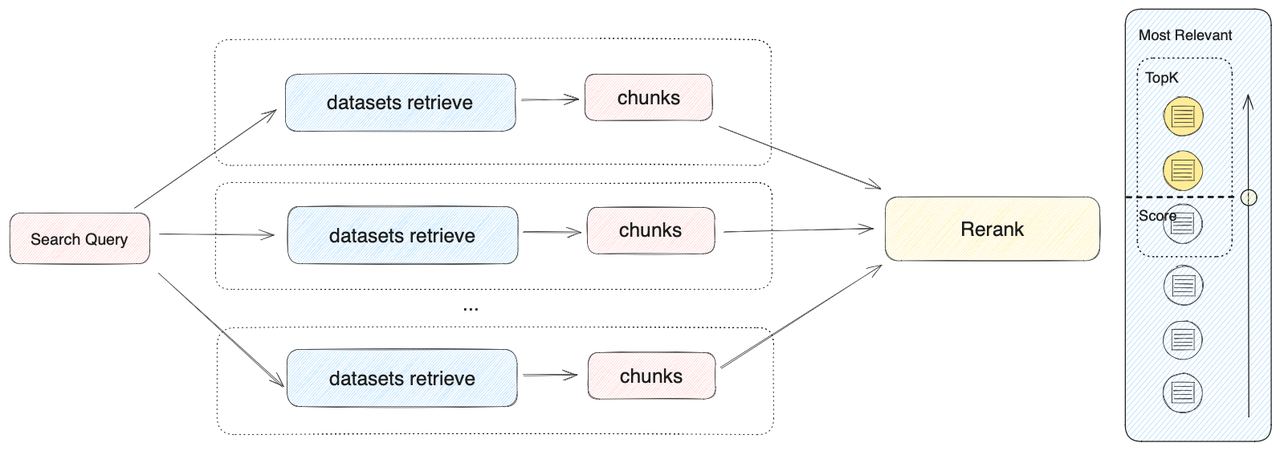
根據用戶意圖同時匹配所有數據集,從多路數據集查詢相關文本片段,經過重排序步驟,從多路查詢結果中選擇匹配用戶問題的最佳結果,需配置 Rerank 模型 API。在多路召回模式下,檢索器會在所有與應用關聯的數據集中去檢索與用戶問題相關的文本內容,并將多路召回的相關文檔結果合并,并通過 Rerank 模型對檢索召回的文檔進行語義重排序。
參考文獻
[1] 檢索增強生成(RAG):https://docs.dify.ai/v/zh-hans/learn-more/extended-reading/retrieval-augment
[2] 知識庫:https://docs.dify.ai/v/zh-hans/guides/knowledge-base
[3] Unstructured:https://docs.unstructured.io/welcome
[4] dify源碼解析-RAG:https://zhuanlan.zhihu.com/p/704341817

)
)








)


——函數)
)

)

