了解混合專家 (MoE)
混合專家 (MoE) 是一種機器學習技術,它將多個“專家”神經網絡模型組合成一個更大的模型。MoE 的目標是通過組合專業專家(每個專家專注于不同的子領域)來提高 AI 系統的準確性和能力。

MoE 模型的一些關鍵特征:
- 由多個專家神經網絡組成,專注于更大問題空間的專門子域
- 包括門控網絡,用于確定針對每個輸入使用哪個專家
- 專家可以根據自己的專業調整不同的神經網絡架構
- 訓練同時涉及專家和門控網絡
- 可以比單一模型更好地對復雜多樣的數據集進行建模
例如,專注于計算機視覺任務的 MoE 模型可以有專門識別不同類型物體(如人、建筑物、汽車等)的專家。門控網絡將確定針對輸入圖像的每個區域使用哪個專家。
MoE 提供的一些好處:
- 通過結合專家來提高準確性
- 可擴展性,因為可以為新任務/數據添加專家
- 由于每個專家都專注于一個子領域,因此具有可解釋性
- 模型優化,因為專家可以有不同的架構
MoE 在提升 AI 系統的大型神經網絡建模能力方面表現出了巨大的潛力。然而,如何有效地訓練和部署 MoE 模型(尤其是在非常大規模的情況下)仍然存在挑戰。
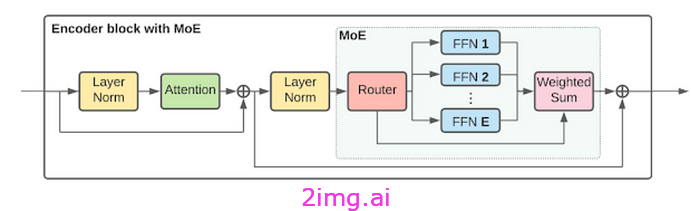
混合專家 (MoE) 架構
混合專家模型由幾個協同工作的關鍵組件組成:
專家神經網絡
專家是專注于解決特定類型的問題或處理某些輸入模式的個體專業模型。通常,神經網絡用于利用表征學習。每個專家只能看到一部分數據。
例如,在文本分類中,一位專家可能專注于檢測垃圾郵件,而另一位專家則專注于識別積極情緒。
他們通常同時接受發送給他們的樣本的訓練。現代 MoE 可能包含數百或數千名專家。
門控網絡
門控網絡負責根據可學習的注意力得分將每個輸入查詢動態路由到相關專家網絡。它查看輸入特征和全局上下文,并輸出要激活的專家的軟概率分布。
由于每個樣本只需要執行稀疏的專家子集,因此將專家混合模型確立為條件計算模型。門控網絡決定激活整體模型的哪些部分。
路由器
路由器接收門控分布和查詢輸入,并選擇一個或多個專家網絡進行相應處理。常見的選擇方法包括 top-k、噪聲 top-k 和更復雜的分層混合,以減少計算負載。
在某些版本中,路由器會查詢多個專家并根據標準化分數組合他們的輸出。
需要進步
雖然 MoE 已顯示出顯著的準確性和能力提升,但要真正釋放下一代 AI 所需的極端規模的模型能力,還需要取得一些重要的進步:
更高效的推理
由于每個示例的門控成本,使用非常大的 MoE 模型運行推理(進行預測)可能具有挑戰性且成本高昂。隨著模型規模的增加,如果不進行優化,門控計算會變得非常緩慢且成本高昂。
訓練穩定性和收斂性
隨著專家數量的增加,MoE 模型的訓練過程趨于不穩定,難以收斂到最優解。我們需要在訓練方法上取得新進展,以利用數千甚至數百萬專家。
專用硬件
為了提供速度、規模和成本效益,訓練和運行大型 MoE 模型推理所需的計算硬件可能需要專門化。
模型并行性
為了達到全腦水平智能所需的大規模,將 MoE 訓練和推理分散到多個設備(如多 GPU 或云基礎設施)上的極端模型并行性將至關重要。
我相信基于 MoE 的模型有潛力解鎖變革性的下一代人工智能——將模型從狹義或專業智能推進到通用人工智能 (AGI)。但仍需取得一些重要進展,以改進大規模推理、訓練效率并利用專用硬件。
大規模 MoE 推理
在極大規模下運行基于 MoE 的模型推理面臨著幾個獨特的優化挑戰:
每個示例的門控成本
每個推理查詢都需要先通過門控網絡來確定路由到相關專家。對于巨型模型,這種每個示例的門控成本可能會變得非常緩慢且昂貴。
高內存帶寬使用率
門控計算需要同時集中訪問所有專家的信息以確定路由,從而導致非常頻繁的隨機內存訪問模式。這限制了沒有內存優化的推理吞吐量。
更有效的大規模 MoE 推理的一些進步包括:
門控共享
門控網絡計算在輸入示例批次之間共享。通過批處理,每個示例的成本被攤銷,從而使門控函數更加高效。
專家級并行
專家本身被分布在多個加速器上進行并行計算,從而增加了總推理吞吐量。
分級門控
多級分級門控網絡用于擁有專門的本地路由器,這些路由器將信息全局傳輸給相關專家。這在保持效率的同時提高了準確性。
模型壓縮
蒸餾和修剪等模型壓縮技術的變體被應用于門控網絡和專家,以優化內存使用和訪問模式。
專用硬件
Google TPU-v4 Pod 等定制硬件具有針對 MoE 等模型量身定制的內置軟件和內存優化,可將推理速度提高 10 倍以上。
隨著模型規模從現在起增加 100 倍甚至 1000 倍,圍繞分層門控、自動專家架構搜索和硬件-軟件協同設計等領域的新優化可能會出現,以保持可處理的推理。
MoE 推理引擎的效率對于實現全腦規模智能至關重要,它可以無縫處理跨文本、圖像、語音、代碼、控制策略和任何數據模式的多領域推理。
教育部培訓的進步
盡管 MoE 有望通過整合眾多專家來提高模型能力,但模型訓練過程帶來了一些挑戰,尤其是在極端規模下。最近的一些進展使大規模 MoE 訓練更加穩定和可實現:
一對一專家數據映射
訓練數據的獨特子集可以明確映射到相關專家,從而使他們在語義上進行專門化。這提高了整體收斂性。
異步模型復制
專家集異步復制以創建維護訓練進度的備份。刪除表現不佳的專家不會丟失關鍵訓練信號。
可學習的門控邏輯
使門控邏輯本身的某些部分可微分且可調,有助于在專家不斷進行專業化迭代時動態路由數據。允許自我調整以實現穩定性。
專家架構搜索
根據實時訓練收斂情況自動搜索專家神經架構構建塊。通過學習路由可以完全避免不良架構。
基于噪聲的專家正則化
在訓練期間向專家可用性中隨機注入像 Dropout 這樣的噪聲使得路由對缺失專家具有魯棒性,避免在特定的專家子集上過度擬合。
這些創新共同提高了訓練穩定性。這使得 MoE 模型擁有數千名專家,而之前的研究只有數百名專家。
然而,關于如何用數百萬甚至數十億專家訓練模型的最佳技術,仍有許多懸而未決的問題。必須出現圍繞漸進分層訓練、循環、終身專家重放和沖突處理的新方法,以防止天文規模的有害專家干擾。
下一代人工智能用例
高效大規模推理、穩定分布式訓練和專業硬件優化等領域的進步將有助于在未來幾年內實現具有數千億到數萬億個參數的 MoE 模型。如此巨大的擴展能帶來什么?
多任務、多模式人工智能助手
人類可以在視覺、語言、聲音和其他感官模式之間無縫切換。同樣,擁有 1000 倍以上專家的全腦 MoE 模型可以同時處理文本、圖像、語音、視頻和感官流。這使得多任務 AI 助手能夠共享全模式表示和專業知識。
超個性化推薦
細粒度的專家專業化允許不同的專家對電影、旅游目的地、播客、書籍等不同領域的用戶興趣進行建模。通過為每個用戶動態組合專業專家,他們可以根據狹窄的領域提供個性化推薦。
科學與技術發現
領域專家組可以吸收全部科學論文、患者健康數據、基因數據集或任何技術資料,從而識別新的聯系。這加速了假設的產生和實驗,促進了科學和工程領域的進步。
穩健的控制政策
大量專家可以專注于處理跨環境、任務、干擾和執行器動態的機器人控制的極端情況。通過混合和匹配專業專家來處理新場景,MoE 系統可以一起學習穩健的策略。
所涵蓋的專業知識的廣度、學習新領域的速度以及通過發明動態組合專業技能的方法而實現的任務靈活性是擴大的 MoE 模型的獨特優勢,是任何其他技術都無法比擬的。
挑戰與未來方向
雖然最近的進展表明,基于 MoE 的模型有潛力擴展到數萬億個參數,從而實現多任務、多模式 AI,但仍存在許多懸而未決的挑戰:
信息隔離
確保有用的專業化而不受有害干擾需要專家之間保持信息隔離。過早的沖突會導致混亂的表述。自上而下的信號必須集中專業知識,自下而上的混亂檢測需要通過門控調整來解決。
發明缺失的專家
數十億專家無法手動列舉所有有用的技能。必須發明自動化流程,通過重組基本技能來為稀有任務產生專家。終身自我監督的長尾需求聚類至關重要。
新興系統性
簡單的記憶無法捕捉底層結構。門控和專家聚類數據之間的交互必須產生系統解開的概念表征。應該會出現類似語法的組合概括。
高效的信用分配
隨著數十億專家獨立進步,確定系統進步的因果貢獻對于有針對性的放大來說變得極為復雜。無關信號會稀釋需要稀疏性的有用方向。
安全探索
對新可能性的無限想象需要在實現之前判斷其是否符合倫理道德。驅動全能專家的好奇心必須以同情心為首要因素。
未來的方向包括圍繞一致性、最佳傳輸、共識動態和信息瓶頸開發數學框架,這些框架專門針對 MoE 系統獨有的動態和規模而設計。

結論
推進混合專家技術以實現解決多領域挑戰的下一代人工智能需要重新思考學習、泛化、因果關系和安全的基本原則,同時在特定規模的訓練、推理和硬件架構上進行創新。未來十年的 MoE 有望成為人工智能革命的激動人心的前沿!

操作步驟)




元數據和文檔 URL)
enclave多線程測試,以及EPC內存測試)











