ShuffleNet網絡介紹
ShuffleNetV1是曠視科技提出的一種計算高效的CNN模型,和MobileNet, SqueezeNet等一樣主要應用在移動端,所以模型的設計目標就是利用有限的計算資源來達到最好的模型精度。ShuffleNetV1的設計核心是引入了兩種操作:Pointwise Group Convolution和Channel Shuffle,這在保持精度的同時大大降低了模型的計算量。因此,ShuffleNetV1和MobileNet類似,都是通過設計更高效的網絡結構來實現模型的壓縮和加速。
了解ShuffleNet更多詳細內容,詳見論文ShuffleNet。
如下圖所示,ShuffleNet在保持不低的準確率的前提下,將參數量幾乎降低到了最小,因此其運算速度較快,單位參數量對模型準確率的貢獻非常高。
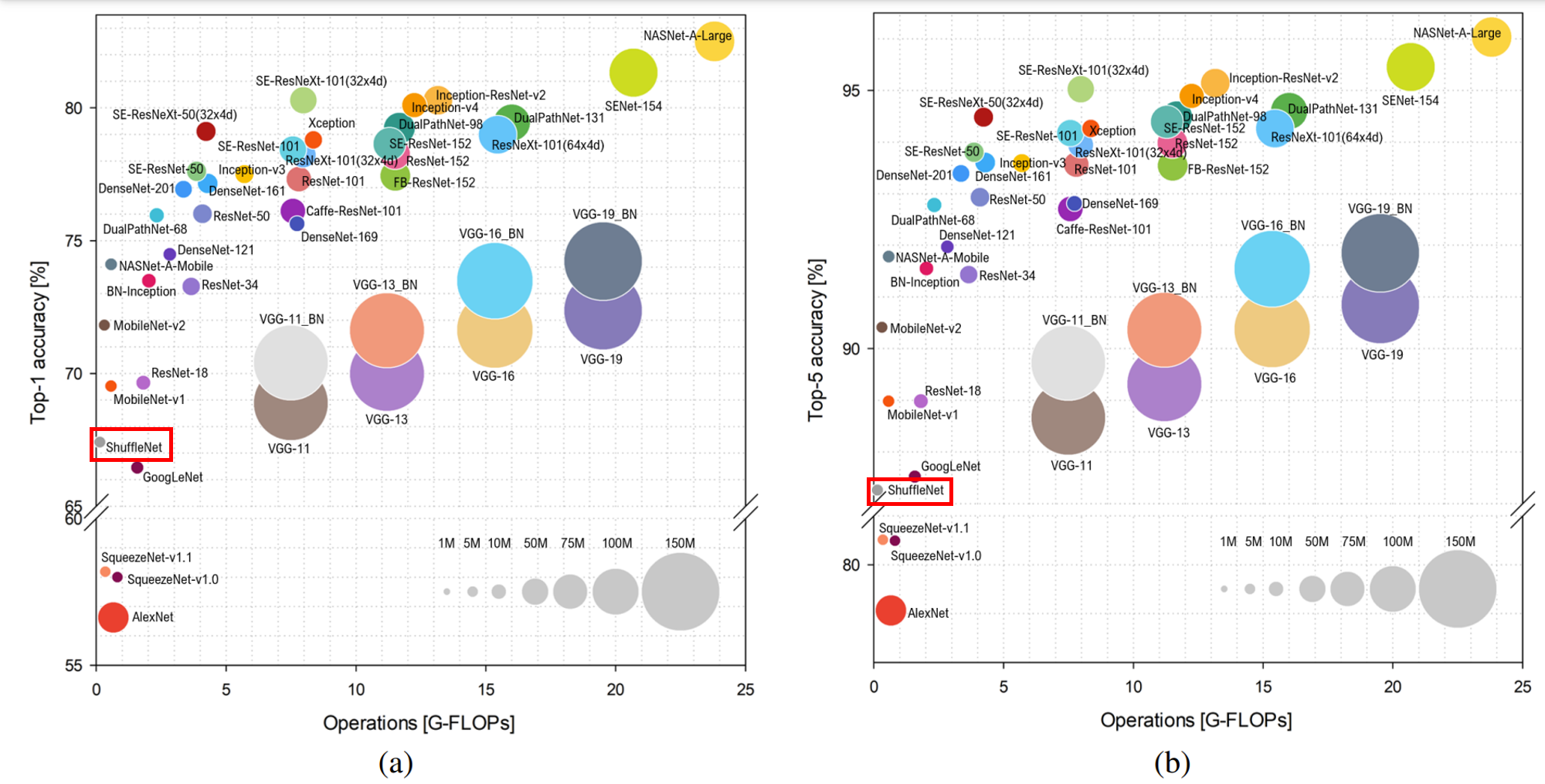
圖片來源:Bianco S, Cadene R, Celona L, et al. Benchmark analysis of representative deep neural network architectures[J]. IEEE access, 2018, 6: 64270-64277.
模型架構
ShuffleNet最顯著的特點在于對不同通道進行重排來解決Group Convolution帶來的弊端。通過對ResNet的Bottleneck單元進行改進,在較小的計算量的情況下達到了較高的準確率。
Pointwise Group Convolution
Group Convolution(分組卷積)原理如下圖所示,相比于普通的卷積操作,分組卷積的情況下,每一組的卷積核大小為in_channels/g*k*k,一共有g組,所有組共有(in_channels/g*k*k)*out_channels個參數,是正常卷積參數的1/g。分組卷積中,每個卷積核只處理輸入特征圖的一部分通道,其優點在于參數量會有所降低,但輸出通道數仍等于卷積核的數量。
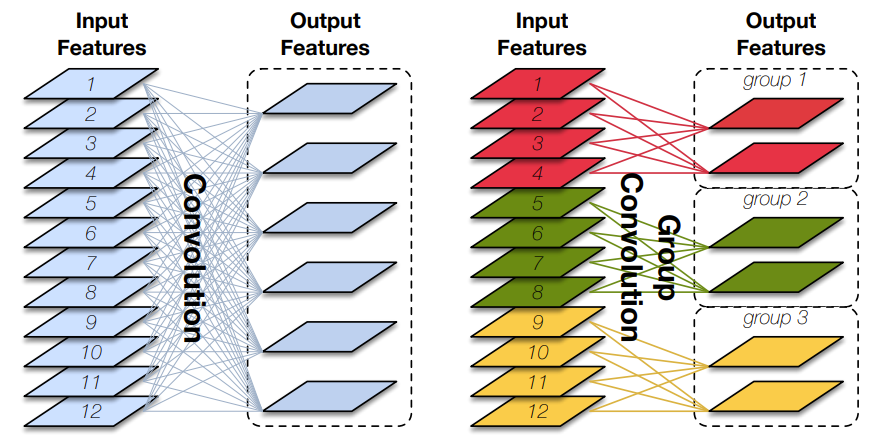
圖片來源:Huang G, Liu S, Van der Maaten L, et al. Condensenet: An efficient densenet using learned group convolutions[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 2752-2761.
Depthwise Convolution(深度可分離卷積)將組數g分為和輸入通道相等的in_channels,然后對每一個in_channels做卷積操作,每個卷積核只處理一個通道,記卷積核大小為1*k*k,則卷積核參數量為:in_channels*k*k,得到的feature maps通道數與輸入通道數相等;
Pointwise Group Convolution(逐點分組卷積)在分組卷積的基礎上,令每一組的卷積核大小為?1×11×1,卷積核參數量為(in_channels/g*1*1)*out_channels。
%%capture captured_output
# 實驗環境已經預裝了mindspore==2.2.14,如需更換mindspore版本,可更改下面mindspore的版本號
!pip uninstall mindspore -y
!pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspore==2.2.14
# 查看當前 mindspore 版本
!pip show mindsporefrom mindspore import nn
import mindspore.ops as ops
from mindspore import Tensor
?
class GroupConv(nn.Cell):def __init__(self, in_channels, out_channels, kernel_size,stride, pad_mode="pad", pad=0, groups=1, has_bias=False):super(GroupConv, self).__init__()self.groups = groupsself.convs = nn.CellList()for _ in range(groups):self.convs.append(nn.Conv2d(in_channels // groups, out_channels // groups,kernel_size=kernel_size, stride=stride, has_bias=has_bias,padding=pad, pad_mode=pad_mode, group=1, weight_init='xavier_uniform'))
?def construct(self, x):features = ops.split(x, split_size_or_sections=int(len(x[0]) // self.groups), axis=1)outputs = ()for i in range(self.groups):outputs = outputs + (self.convs[i](features[i].astype("float32")),)out = ops.cat(outputs, axis=1)return out
?
Channel Shuffle
Group Convolution的弊端在于不同組別的通道無法進行信息交流,堆積GConv層后一個問題是不同組之間的特征圖是不通信的,這就好像分成了g個互不相干的道路,每一個人各走各的,這可能會降低網絡的特征提取能力。這也是Xception,MobileNet等網絡采用密集的1x1卷積(Dense Pointwise Convolution)的原因。
為了解決不同組別通道“近親繁殖”的問題,ShuffleNet優化了大量密集的1x1卷積(在使用的情況下計算量占用率達到了驚人的93.4%),引入Channel Shuffle機制(通道重排)。這項操作直觀上表現為將不同分組通道均勻分散重組,使網絡在下一層能處理不同組別通道的信息。
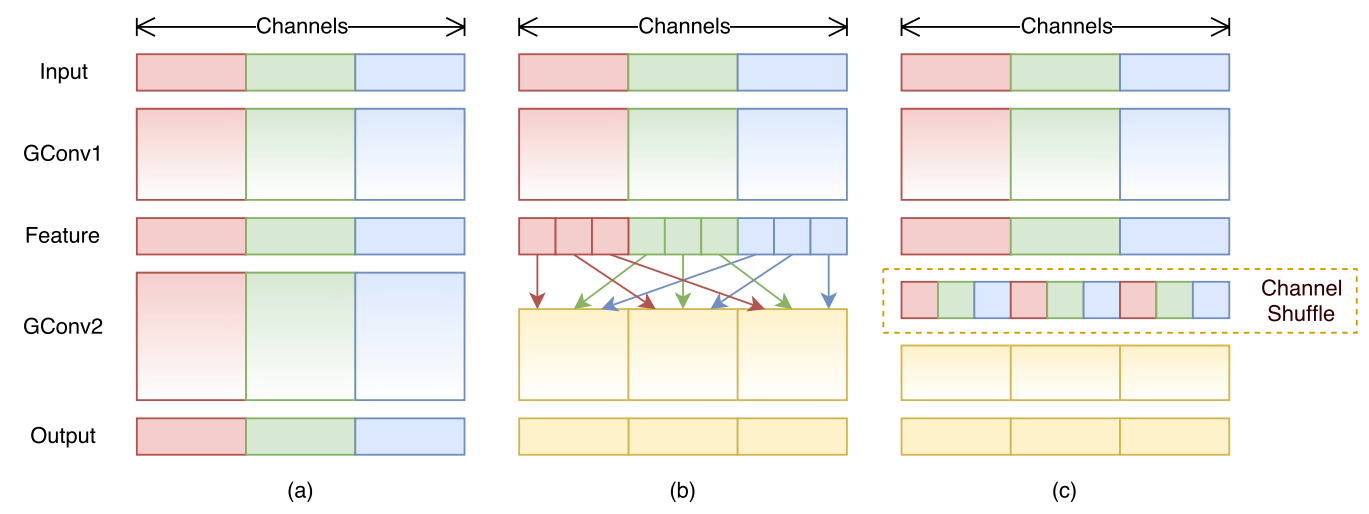
如下圖所示,對于g組,每組有n個通道的特征圖,首先reshape成g行n列的矩陣,再將矩陣轉置成n行g列,最后進行flatten操作,得到新的排列。這些操作都是可微分可導的且計算簡單,在解決了信息交互的同時符合了ShuffleNet輕量級網絡設計的輕量特征。
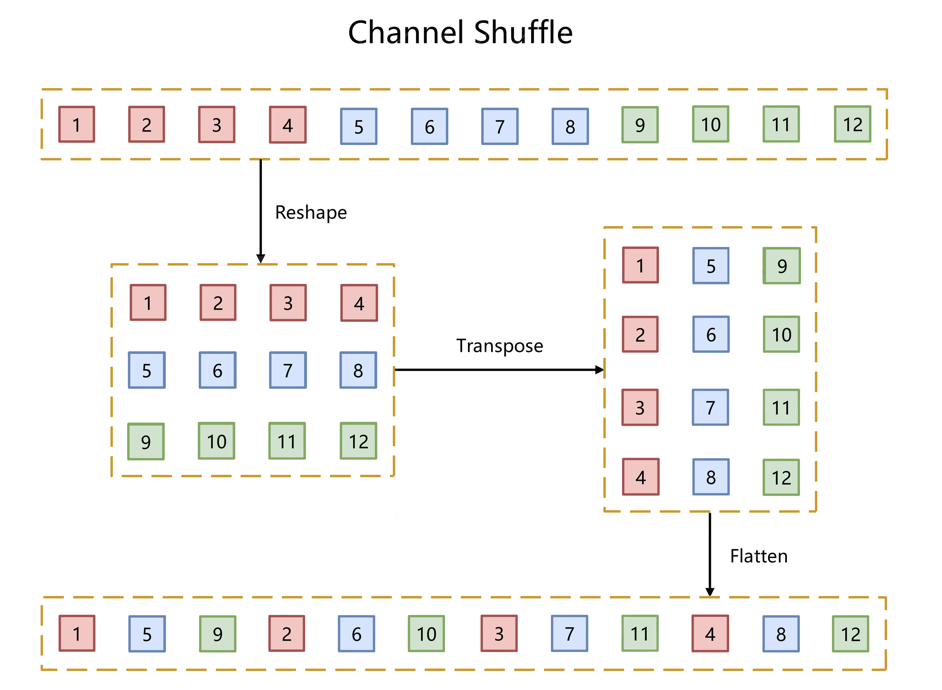
為了閱讀方便,將Channel Shuffle的代碼實現放在下方ShuffleNet模塊的代碼中。
ShuffleNet模塊
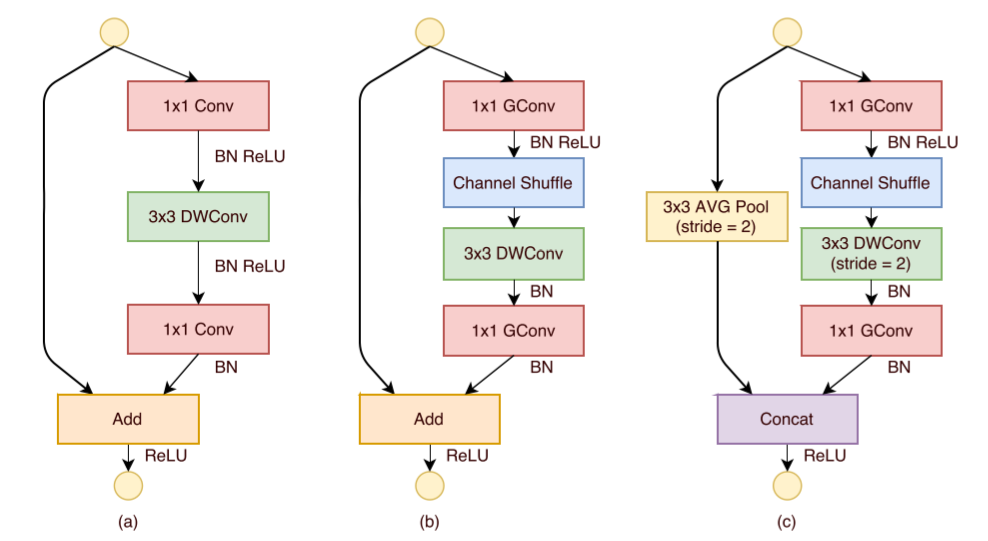
如下圖所示,ShuffleNet對ResNet中的Bottleneck結構進行由(a)到(b), (c)的更改:
-
將開始和最后的1×11×1卷積模塊(降維、升維)改成Point Wise Group Convolution;
-
為了進行不同通道的信息交流,再降維之后進行Channel Shuffle;
-
降采樣模塊中,3×33×3?Depth Wise Convolution的步長設置為2,長寬降為原來的一般,因此shortcut中采用步長為2的3×33×3平均池化,并把相加改成拼接。
class ShuffleV1Block(nn.Cell):def __init__(self, inp, oup, group, first_group, mid_channels, ksize, stride):super(ShuffleV1Block, self).__init__()self.stride = stridepad = ksize // 2self.group = groupif stride == 2:outputs = oup - inpelse:outputs = oupself.relu = nn.ReLU()branch_main_1 = [GroupConv(in_channels=inp, out_channels=mid_channels,kernel_size=1, stride=1, pad_mode="pad", pad=0,groups=1 if first_group else group),nn.BatchNorm2d(mid_channels),nn.ReLU(),]branch_main_2 = [nn.Conv2d(mid_channels, mid_channels, kernel_size=ksize, stride=stride,pad_mode='pad', padding=pad, group=mid_channels,weight_init='xavier_uniform', has_bias=False),nn.BatchNorm2d(mid_channels),GroupConv(in_channels=mid_channels, out_channels=outputs,kernel_size=1, stride=1, pad_mode="pad", pad=0,groups=group),nn.BatchNorm2d(outputs),]self.branch_main_1 = nn.SequentialCell(branch_main_1)self.branch_main_2 = nn.SequentialCell(branch_main_2)if stride == 2:self.branch_proj = nn.AvgPool2d(kernel_size=3, stride=2, pad_mode='same')def construct(self, old_x):left = old_xright = old_xout = old_xright = self.branch_main_1(right)if self.group > 1:right = self.channel_shuffle(right)right = self.branch_main_2(right)if self.stride == 1:out = self.relu(left + right)elif self.stride == 2:left = self.branch_proj(left)out = ops.cat((left, right), 1)out = self.relu(out)return outdef channel_shuffle(self, x):batchsize, num_channels, height, width = ops.shape(x)group_channels = num_channels // self.groupx = ops.reshape(x, (batchsize, group_channels, self.group, height, width))x = ops.transpose(x, (0, 2, 1, 3, 4))x = ops.reshape(x, (batchsize, num_channels, height, width))return x?
構建ShuffleNet網絡
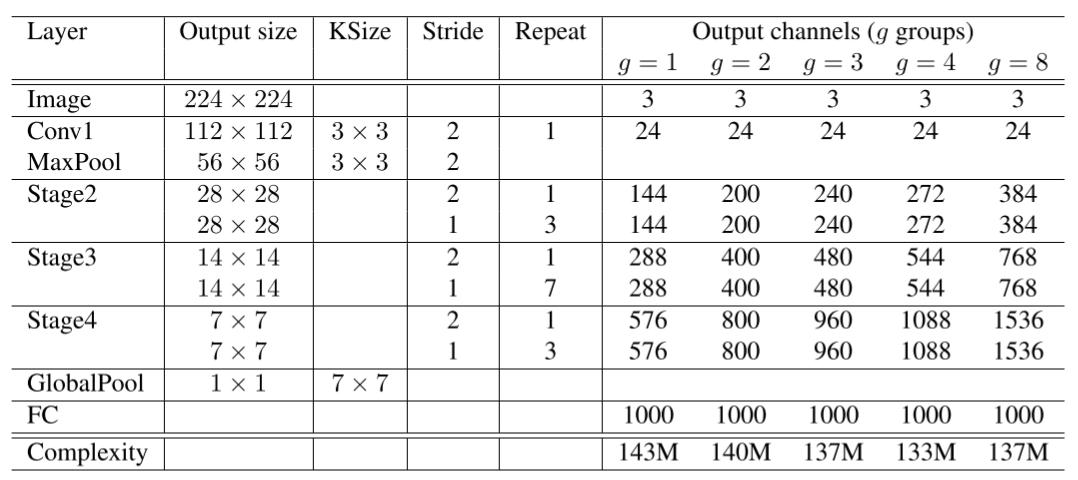
ShuffleNet網絡結構如下圖所示,以輸入圖像224×224224×224,組數3(g = 3)為例,首先通過數量24,卷積核大小為3×33×3,stride為2的卷積層,輸出特征圖大小為112×112112×112,channel為24;然后通過stride為2的最大池化層,輸出特征圖大小為56×5656×56,channel數不變;再堆疊3個ShuffleNet模塊(Stage2, Stage3, Stage4),三個模塊分別重復4次、8次、4次,其中每個模塊開始先經過一次下采樣模塊(上圖(c)),使特征圖長寬減半,channel翻倍(Stage2的下采樣模塊除外,將channel數從24變為240);隨后經過全局平均池化,輸出大小為1×1×9601×1×960,再經過全連接層和softmax,得到分類概率。
class ShuffleNetV1(nn.Cell):def __init__(self, n_class=1000, model_size='2.0x', group=3):super(ShuffleNetV1, self).__init__()print('model size is ', model_size)self.stage_repeats = [4, 8, 4]self.model_size = model_sizeif group == 3:if model_size == '0.5x':self.stage_out_channels = [-1, 12, 120, 240, 480]elif model_size == '1.0x':self.stage_out_channels = [-1, 24, 240, 480, 960]elif model_size == '1.5x':self.stage_out_channels = [-1, 24, 360, 720, 1440]elif model_size == '2.0x':self.stage_out_channels = [-1, 48, 480, 960, 1920]else:raise NotImplementedErrorelif group == 8:if model_size == '0.5x':self.stage_out_channels = [-1, 16, 192, 384, 768]elif model_size == '1.0x':self.stage_out_channels = [-1, 24, 384, 768, 1536]elif model_size == '1.5x':self.stage_out_channels = [-1, 24, 576, 1152, 2304]elif model_size == '2.0x':self.stage_out_channels = [-1, 48, 768, 1536, 3072]else:raise NotImplementedErrorinput_channel = self.stage_out_channels[1]self.first_conv = nn.SequentialCell(nn.Conv2d(3, input_channel, 3, 2, 'pad', 1, weight_init='xavier_uniform', has_bias=False),nn.BatchNorm2d(input_channel),nn.ReLU(),)self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, pad_mode='same')features = []for idxstage in range(len(self.stage_repeats)):numrepeat = self.stage_repeats[idxstage]output_channel = self.stage_out_channels[idxstage + 2]for i in range(numrepeat):stride = 2 if i == 0 else 1first_group = idxstage == 0 and i == 0features.append(ShuffleV1Block(input_channel, output_channel,group=group, first_group=first_group,mid_channels=output_channel // 4, ksize=3, stride=stride))input_channel = output_channelself.features = nn.SequentialCell(features)self.globalpool = nn.AvgPool2d(7)self.classifier = nn.Dense(self.stage_out_channels[-1], n_class)def construct(self, x):x = self.first_conv(x)x = self.maxpool(x)x = self.features(x)x = self.globalpool(x)x = ops.reshape(x, (-1, self.stage_out_channels[-1]))x = self.classifier(x)return x?
模型訓練和評估
采用CIFAR-10數據集對ShuffleNet進行預訓練。
訓練集準備與加載
采用CIFAR-10數據集對ShuffleNet進行預訓練。CIFAR-10共有60000張32*32的彩色圖像,均勻地分為10個類別,其中50000張圖片作為訓練集,10000圖片作為測試集。如下示例使用mindspore.dataset.Cifar10Dataset接口下載并加載CIFAR-10的訓練集。目前僅支持二進制版本(CIFAR-10 binary version)。
from download import downloadurl = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/cifar-10-binary.tar.gz"download(url, "./dataset", kind="tar.gz", replace=True)
import mindspore as ms
from mindspore.dataset import Cifar10Dataset
from mindspore.dataset import vision, transformsdef get_dataset(train_dataset_path, batch_size, usage):image_trans = []if usage == "train":image_trans = [vision.RandomCrop((32, 32), (4, 4, 4, 4)),vision.RandomHorizontalFlip(prob=0.5),vision.Resize((224, 224)),vision.Rescale(1.0 / 255.0, 0.0),vision.Normalize([0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010]),vision.HWC2CHW()]elif usage == "test":image_trans = [vision.Resize((224, 224)),vision.Rescale(1.0 / 255.0, 0.0),vision.Normalize([0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010]),vision.HWC2CHW()]label_trans = transforms.TypeCast(ms.int32)dataset = Cifar10Dataset(train_dataset_path, usage=usage, shuffle=True)dataset = dataset.map(image_trans, 'image')dataset = dataset.map(label_trans, 'label')dataset = dataset.batch(batch_size, drop_remainder=True)return datasetdataset = get_dataset("./dataset/cifar-10-batches-bin", 128, "train")
batches_per_epoch = dataset.get_dataset_size()?
模型訓練
本節用隨機初始化的參數做預訓練。首先調用ShuffleNetV1定義網絡,參數量選擇"2.0x",并定義損失函數為交叉熵損失,學習率經過4輪的warmup后采用余弦退火,優化器采用Momentum。最后用train.model中的Model接口將模型、損失函數、優化器封裝在model中,并用model.train()對網絡進行訓練。將ModelCheckpoint、CheckpointConfig、TimeMonitor和LossMonitor傳入回調函數中,將會打印訓練的輪數、損失和時間,并將ckpt文件保存在當前目錄下。
import time
import mindspore
import numpy as np
from mindspore import Tensor, nn
from mindspore.train import ModelCheckpoint, CheckpointConfig, TimeMonitor, LossMonitor, Model, Top1CategoricalAccuracy, Top5CategoricalAccuracydef train():mindspore.set_context(mode=mindspore.PYNATIVE_MODE, device_target="Ascend")net = ShuffleNetV1(model_size="2.0x", n_class=10)loss = nn.CrossEntropyLoss(weight=None, reduction='mean', label_smoothing=0.1)min_lr = 0.0005base_lr = 0.05lr_scheduler = mindspore.nn.cosine_decay_lr(min_lr,base_lr,batches_per_epoch*250,batches_per_epoch,decay_epoch=250)lr = Tensor(lr_scheduler[-1])optimizer = nn.Momentum(params=net.trainable_params(), learning_rate=lr, momentum=0.9, weight_decay=0.00004, loss_scale=1024)loss_scale_manager = ms.amp.FixedLossScaleManager(1024, drop_overflow_update=False)model = Model(net, loss_fn=loss, optimizer=optimizer, amp_level="O3", loss_scale_manager=loss_scale_manager)callback = [TimeMonitor(), LossMonitor()]save_ckpt_path = "./"config_ckpt = CheckpointConfig(save_checkpoint_steps=batches_per_epoch, keep_checkpoint_max=5)ckpt_callback = ModelCheckpoint("shufflenetv1", directory=save_ckpt_path, config=config_ckpt)callback += [ckpt_callback]print("============== Starting Training ==============")start_time = time.time()# 由于時間原因,epoch = 5,可根據需求進行調整model.train(5, dataset, callbacks=callback)use_time = time.time() - start_timehour = str(int(use_time // 60 // 60))minute = str(int(use_time // 60 % 60))second = str(int(use_time % 60))print("total time:" + hour + "h " + minute + "m " + second + "s")print("============== Train Success ==============")if __name__ == '__main__':train()
?
練好的模型保存在當前目錄的shufflenetv1-5_390.ckpt中,用作評估。
模型評估
在CIFAR-10的測試集上對模型進行評估。
設置好評估模型的路徑后加載數據集,并設置Top 1, Top 5的評估標準,最后用model.eval()接口對模型進行評估。
from mindspore import load_checkpoint, load_param_into_netdef test():mindspore.set_context(mode=mindspore.GRAPH_MODE, device_target="Ascend")dataset = get_dataset("./dataset/cifar-10-batches-bin", 128, "test")net = ShuffleNetV1(model_size="2.0x", n_class=10)param_dict = load_checkpoint("shufflenetv1-5_390.ckpt")load_param_into_net(net, param_dict)net.set_train(False)loss = nn.CrossEntropyLoss(weight=None, reduction='mean', label_smoothing=0.1)eval_metrics = {'Loss': nn.Loss(), 'Top_1_Acc': Top1CategoricalAccuracy(),'Top_5_Acc': Top5CategoricalAccuracy()}model = Model(net, loss_fn=loss, metrics=eval_metrics)start_time = time.time()res = model.eval(dataset, dataset_sink_mode=False)use_time = time.time() - start_timehour = str(int(use_time // 60 // 60))minute = str(int(use_time // 60 % 60))second = str(int(use_time % 60))log = "result:" + str(res) + ", ckpt:'" + "./shufflenetv1-5_390.ckpt" \+ "', time: " + hour + "h " + minute + "m " + second + "s"print(log)filename = './eval_log.txt'with open(filename, 'a') as file_object:file_object.write(log + '\n')if __name__ == '__main__':test()模型預測
在CIFAR-10的測試集上對模型進行預測,并將預測結果可視化。
mport mindspore
import matplotlib.pyplot as plt
import mindspore.dataset as dsnet = ShuffleNetV1(model_size="2.0x", n_class=10)
show_lst = []
param_dict = load_checkpoint("shufflenetv1-5_390.ckpt")
load_param_into_net(net, param_dict)
model = Model(net)
dataset_predict = ds.Cifar10Dataset(dataset_dir="./dataset/cifar-10-batches-bin", shuffle=False, usage="train")
dataset_show = ds.Cifar10Dataset(dataset_dir="./dataset/cifar-10-batches-bin", shuffle=False, usage="train")
dataset_show = dataset_show.batch(16)
show_images_lst = next(dataset_show.create_dict_iterator())["image"].asnumpy()
image_trans = [vision.RandomCrop((32, 32), (4, 4, 4, 4)),vision.RandomHorizontalFlip(prob=0.5),vision.Resize((224, 224)),vision.Rescale(1.0 / 255.0, 0.0),vision.Normalize([0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010]),vision.HWC2CHW()]
dataset_predict = dataset_predict.map(image_trans, 'image')
dataset_predict = dataset_predict.batch(16)
class_dict = {0:"airplane", 1:"automobile", 2:"bird", 3:"cat", 4:"deer", 5:"dog", 6:"frog", 7:"horse", 8:"ship", 9:"truck"}
# 推理效果展示(上方為預測的結果,下方為推理效果圖片)
plt.figure(figsize=(16, 5))
predict_data = next(dataset_predict.create_dict_iterator())
output = model.predict(ms.Tensor(predict_data['image']))
pred = np.argmax(output.asnumpy(), axis=1)
index = 0
for image in show_images_lst:plt.subplot(2, 8, index+1)plt.title('{}'.format(class_dict[pred[index]]))index += 1plt.imshow(image)plt.axis("off")
plt.show()
心得:總的來說,通過這次學習,我對MindSpore和ShuffleNet有了更深入的了解,也積累了寶貴的實踐經驗。我相信,這將對我的職業發展產生積極的影響。




方法)

)












)